


Як працюють пошукові системи на базі ШІ

Автор: Ryan Law
Директор із контент-маркетингу в Ahrefs
Що насправді відбувається, коли ви просите ChatGPT порекомендувати найкращі накладні навушники для занять спортом?
Як пошукові системи на базі ШІ генерують відповіді й обирають рекомендації продуктів? Чим вони відрізняються від традиційних пошукових систем на кшталт Google (і де вони перетинаються)?
І найголовніше: як допомогти вашому вебсайту, бренду й продуктам з’являтися у видачі?
Дякуємо Gianluca Fiorelli та Mark Williams-Cook за рецензування й участь у підготовці цього розділу.
Що таке пошукові системи на базі ШІ?
Пошукові системи на базі ШІ — це системи запитань і відповідей, які використовують великі мовні моделі (LLM) для пошуку інформації та генерування відповідей.
Між традиційними пошуковими системами та пошуковими системами на базі ШІ є кілька суттєвих відмінностей (хоча ці відмінності зменшуються, оскільки в традиційні пошукові системи додається дедалі більше функцій ШІ):
- Замість одноразових запитів користувачі можуть ставити уточнювальні запитання й продовжувати розмову.
- Замість ранжованого списку посилань пошукові системи на базі ШІ надають прямі відповіді й рекомендації (і ці відповіді можуть регулярно змінюватися).
- Замість того щоб спрямовувати користувачів із на ваш вебсайт, система дає відповіді на запити безпосередньо в інтерфейсі чату (що зменшує кількість кліків на вебсайт).
Ось як виглядає типовий інтерфейс пошуку на базі ШІ, подібний до того, що ви бачите в ChatGPT, Claude або режимі ШІ:

- Розмовний запит. Запитання користувача.
- Повідомлення про забезпечення ресурсами. Повідомлення, яке показує, що LLM вирішила знайти додаткову інформацію для використання у своїй відповіді.
- Відповідь. Відповідь на користувацький запит, згенерована ШІ.
- Згадка. Об’єкт (як-от бренд чи продукт), згаданий безпосередньо в тексті відповіді.
- Цитування. URL-адреси джерел, використані для генерування відповіді; зазвичай наведені наприкінці.
Щоб потрапляти до подібних відповідей, спершу потрібно зрозуміти ключові процеси, завдяки яким працюють пошукові системи на базі ШІ.
Як працює навчання
LLM навчають на величезних обсягах контенту. Фактично вони «прочитали» всю Вікіпедію, весь набір даних Common Crawl, усі Google Books і багато мільйонів сторінок вебконтенту.
Ці навчальні дані допомагають сформувати для LLM «розуміння» світу. Якщо ваша компанія з виробництва навушників багато разів згадується в її навчальних даних — у релевантному контексті та поряд із позитивними характеристиками («найкраще співвідношення ціни й якості», «чудово для спортзалу» тощо) — є висока ймовірність, що вашу компанію згадуватимуть у відповідях LLM на запити, пов’язані з навушниками.
Чи знали ви?
Цей процес навчання значно складніший, ніж описано тут. Під час попереднього навчання видаляють HTML, очищають дані від персональної інформації, прибирають небажані слова й фільтрують контент за мовами. Далі на етапі подальшого навчання мовну модель навчають діяти як корисний чат-асистент (а не просто прогнозувати наступний токен). Щоб дізнатися більше, подивіться відео Андрея Карпати Deep Dive into LLMs like ChatGPT (Детальний аналіз LLM на прикладі ChatGPT).


Саме тут SEO на основі об’єктів стає критично важливим. Якщо ваш бренд стабільно з’являється в графах знань, правильно структурований за допомогою розмітки Schema та згадується разом із релевантними об’єктами у високоякісному контенті всією мережею, ви формуєте сильніший «сигнал об’єкта» у навчальних даних.

Gianluca Fiorelli, Консультант зі стратегічного й міжнародного SEO / ШІ-пошуку
Важливо, що LLM мають низку характерних особливостей:
- Вони ймовірнісні: на один і той самий запит щоразу можуть надаватися різні відповіді. Через цю ймовірнісну природу «оптимізація під запит» не працює так, як для ключових слів. Натомість варто мислити розподілами: яка ймовірність того, що ваш бренд з’явиться у 100 подібних запитах? Саме тому відстеження середньої видимості на великій кількості запитів ефективніше, ніж орієнтування на кілька окремих.
- Їхні знання мають обмеження за датою. За замовчуванням знання LLM обмежені тим, що містилося в наборі даних на момент навчання конкретної моделі. Кожну модель навчають один раз на зрізі даних до конкретної дати. Нові моделі з актуальнішою межею знань випускаються періодично (приблизно раз на пів року).
- Вони схильні до галюцинацій. Можуть упевнено стверджувати речі, які не відповідають дійсності. LLM генерують текст, передбачаючи, які слова ймовірно йдуть будуть наступними, не перевіряючи факти. Хоча їх навчають бути корисними й точними, вони не мають вбудованого механізму перевірки фактів, саме тому забезпечення ресурсами через вебпошук є таким важливим.
Помилково вважати, що LLM оновлюються подібно до програмних патчів. Насправді кожну модель навчають один раз на фіксованому наборі даних. Коли виходить нова модель зі свіжішою датою зрізу знань, це повністю нова модель, навчена з нуля, а не оновлення наявної.
Gianluca Fiorelli, Консультант зі стратегічного й міжнародного SEO / ШІ-пошуку
Пошукова система, яка допускає галюцинації та надає застарілу інформацію, навряд чи буде корисною. Саме тому LLM долають частину цих обмежень за допомогою процесу, відомого як забезпечення ресурсами.
Як працюють забезпечення ресурсами й RAG
LLM можуть перевіряти й покращувати свої відповіді двома способами: за допомогою інструментів (як-от калькуляторів чи інших API даних) або шляхом отримання додаткової інформації з зовнішніх джерел. Другий процес технічно називається Retrieval-Augmented Generation (RAG).
Коли користувач вводить запитання, LLM фактично оцінює: «Чи я вже знаю відповідь, чи варто отримати додаткову інформацію?» Якщо модель може з високою впевненістю передбачити наступні токени (наприклад, для запитів, що рідко змінюються, на кшталт «яка функція еритроцитів?»), вона, ймовірно, відповість на основі своїх базових знань. Якщо ж упевненість низька (для більш мінливих запитів, як-от «яка бюджетна кавомолка найкраща?»), вона може скористатися інструментом пошуку, щоб знайти релевантну інформацію в інших джерелах в інтернеті.
LLM налаштовані так, щоб розпізнавати типи запитів, що потребують додаткової інформації, зокрема:
- Теми поза межами навчання моделей. «Які внутрішні чинники ранжування використовує Keywords Explorer від Ahrefs?»
- Теми, для яких важлива актуальна інформація або інформація, що швидко застаріває. «Яким було останнє базове оновлення Google і коли його було запущено?»
- Теми, що прямо вказують на потребу вебпошуку. «Знайди в інтернеті популярні тактики лінкбілдингу у 2026 році».
- Запити, де потрібні джерела й підтвердження. «Надай джерела, які підтверджують, що Google використовує сигнали залученості користувачів у своєму алгоритмі».
Деякі моделі LLM частіше запускають додаткові пошуки (наприклад, моделі «глибокого дослідження», які спеціально налаштовані на виконання кількох RAG-пошуків).
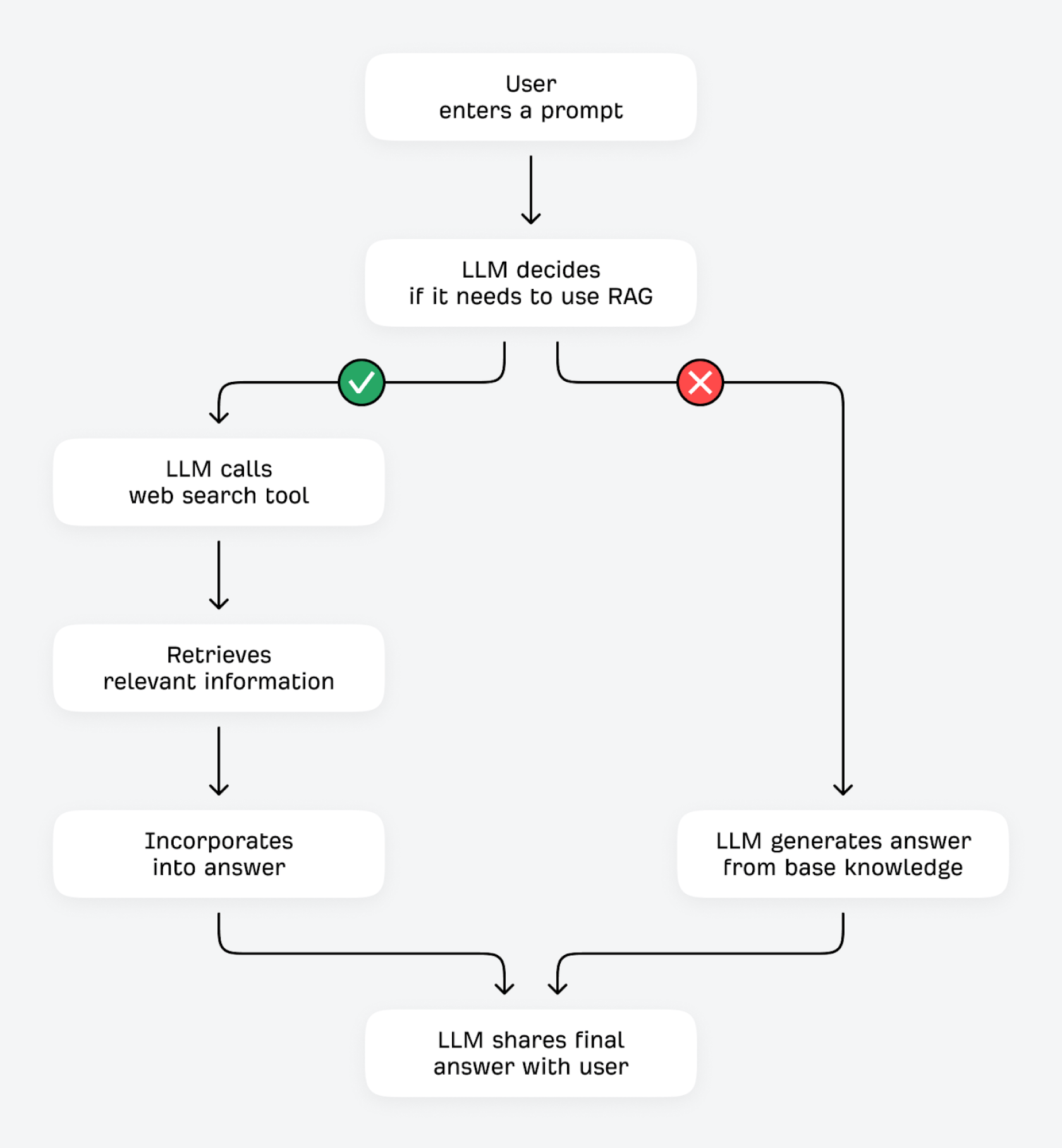
Цей процес пошуку перевіреної інформації за допомогою RAG (часто його називають «забезпеченням ресурсами») має кілька переваг. Велика мовна модель може підвищити фактичну точність і зменшити кількість галюцинацій, звіряючи свої відповіді зі сторонніми джерелами. Вона здатна знаходити й надавати актуальну інформацію, навіть якщо її навчальні дані вже частково застаріли. Також вона може давати детальніші й розгорнутіші відповіді з кращою прозорістю та посиланнями на джерела.
Пошукові системи на базі ШІ виконують забезпечення ресурсами за допомогою процесу, відомого як розгалуження запитів.
Як працює розгалуження запиту
Власне, саме розгалуження запиту пояснює, чому традиційне SEO є надзвичайно важливим для видимості в ШІ-пошуку.
Щоб отримувати актуальну інформацію, асистенти ШІ, як-от ChatGPT, Gemini й Perplexity, використовують пошукові індекси, наприклад, Google, Bing і Brave.
Вибір пошукової системи важливий, адже кожна з них використовує власні алгоритми ранжування, індекси й охоплення: видимість бренду в Пошуку Google може сильніше вплинути на вашу присутність у режимі ШІ, ніж у ChatGPT, який значно більше покладається на Bing.
| Пошукова система на базі ШІ | Пошукові індекси, що використовуються для забезпечення ресурсами |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Коли запускається вебпошук, LLM запитує релевантні результати зі свого пошукового індексу. Пошуковий індекс повертає список результатів, а LLM обирає найрелевантніші сторінки для сканування, оцінюючи, зокрема, назву сторінки, вміст показаного фрагмента сторінки та її актуальність (наскільки нещодавно її опублікували).
Чому SEO є критично важливим для ШІ-пошуку
Варто ще раз наголосити: традиційні пошукові системи, як-от Google і Bing, відіграють ключову роль у тому, який контент пошукові системи на базі ШІ згадують і цитують у своїх відповідях.
Інакше кажучи, високі позиції в традиційному пошуку підвищать вашу видимість у ШІ-пошуку.
Але що саме шукає LLM?
LLM використовують процес, що називається розгалуженням запитів. Багато запитів, введених у ChatGPT та інші пошукові системи на базі ШІ, є надзвичайно довгими, розмовними й часто повністю унікальними. Пошук у Google за цими точними запитами не завжди дає корисний контент.
Тож замість того, щоб виконувати вебпошук за точним запитом користувача…
«Я розробляю контент-стратегію на 6 місяців для B2B SaaS-компанії середнього розміру, що продає аналітичний продукт для брендів електронної комерції. Компанія…»

…LLM використовують цей початковий запит, щоб згенерувати серію коротших, пов’язаних запитів і тим самим допомогти отримати релевантну інформацію.
Ці розгалужені запити також генеруються великою мовною моделлю, тому вони недетерміновані: навіть для однакового пошуку вони можуть змінюватися з часом.

Mark Williams-Cook, Засновник, AlsoAsked
SEO-фахівцям має бут знайомий цей процес: ці пов’язані запити дуже схожі на довгі ключові слова, допоміжні наміри й запитання з розділу «Інші також запитують»:
- Поширені фреймворки контент-стратегії B2B SaaS
- Приклади контенту TOFU проти BOFU для SaaS
- Оновлення контенту та найкращі практики внутрішніх посилань
- Метрики зростання демо, що зумовлене контентом
Насправді лише 12 % посилань, які цитують ChatGPT, Gemini та Copilot, потрапляють до найкращих 10 результатів Google за початковим запитом користувача. Однак це не означає, що традиційне ранжування втратило значення. Пошукові системи на базі ШІ знаходять контент, генеруючи кілька пошукових запитів, і ці розгалужені запити часто є більш традиційними, орієнтованими на ключові слова, де ваша робота з SEO має вирішальне значення.

Розгалуження запитів дає більше свободи: вам не потрібно вгадувати, які саме розмовні запити використовуватимуть користувачі. Натомість варто орієнтуватися на розкладені на складники запити, тобто семантичні компоненти, які LLM природно генеруватимуть. Це дуже схоже на традиційний аналіз ключових слів: [тема] + [уточнення], запити на порівняння, визначення й контент із «найкращими практиками». Ваші наявні SEO-дослідження, ймовірно, вже охоплюють цей простір розгалуження.
Gianluca Fiorelli, Консультант зі стратегічного й міжнародного SEO / ШІ-пошуку
Як працюють отримання даних, поділ на фрагменти й синтез відповіді
Коли LLM знаходить релевантні сторінки в пошуковому індексі, вона не читає їх повністю. Натомість сторінки розбиваються на невеликі текстові фрагменти, і модель зосереджується на найбільш релевантних запиту фрагментах (іноді доповнюючи їх).
Зазвичай ці фрагменти містять від кількох сотень до кількох тисяч слів, і це лише невелика частина більшості вебсторінок. Водночас LLM працює в межах суворих обмежень контекстного вікна: вона може опрацювати лише обмежений обсяг тексту, зокрема запит користувача, усі отримані фрагменти й власну відповідь. Це означає, що модель має дуже вибірково підходити до того, який контент отримувати й включати.
Ось приклад:
| Вміст повної сторінки | >«Забезпечення ресурсами — це процес, у межах якого модель отримує зовнішні джерела, витягує релевантні факти й використовує їх, щоб зменшити кількість галюцинацій і підвищити актуальність відповіді.… Потім вона сканує кілька джерел, зіставляє інформацію та синтезує відповідь замість дослівного копіювання. Цей етап синтезу допомагає уникнути надмірної залежності від одного джерела». |
| Фрагмент | «Пояснює, як асистенти використовують вебпошук для отримання зовнішніх джерел і зменшення галюцинацій, ґрунтуючи відповіді на знайдених фактах». |
| Розгортання (рядки 1–2) | «Забезпечення ресурсами — це процес, у межах якого модель отримує зовнішні джерела, витягує релевантні факти й використовує їх, щоб зменшити кількість галюцинацій і підвищити актуальність відповіді. Перед запуском вебпошуку модель оцінює, чи потрібна для запиту актуальна або придатна для перевірки інформація». |
| Розгортання (рядки 33–34) | «Потім вона сканує кілька джерел, зіставляє інформацію та синтезує відповідь замість дослівного копіювання. Цей етап синтезу допомагає уникнути надмірної залежності від одного джерела». |
Зробіть контент зрозумілим для LLM
Це важливо: коли пошукові системи на базі ШІ отримують ваш контент з інтернету, вони бачать лише часткові фрагменти, а не всю сторінку. Щоб підвищити ймовірність цитування в LLM, релевантність і цінність вашої сторінки мають бути зрозумілими для LLM навіть без доступу до всієї сторінки.
Потім пошукова система на базі ШІ інтегрує цей текст у процес генерування відповіді.
Неопрацьований вебконтент інтегрується у відповідь моделі: фрагменти тексту або даних, витягнуті на попередньому етапі, додаються до контексту моделі фактично як підказка: «ось контекст із мережі, що може бути корисним; тепер дай відповідь на запитання користувача, використовуючи цю інформацію».
Як обирають джерела для цитування
Далі модель генерує відповідь, поєднуючи свої власні знання з отриманим контентом, і надає її користувачеві. Зазвичай така відповідь містить цитування: клацні URL-адреси з посиланнями на джерела, використані під час забезпечення ресурсами.
Не кожна сторінка, яку знаходить пошукова система на базі ШІ, потрапляє до фінальної відповіді з посиланням. Модель обирає, які джерела цитувати, зважаючи на кілька чинників:
- Релевантність. Наскільки знайдений контент прямо пов’язаний із конкретними твердженнями у відповіді.
- Актуальність. Наскільки актуальним є джерело.
- Різноманітність. Рівень різноманітності джерел цитування (пошукові системи на базі ШІ часто віддають перевагу цитуванню кількох різних джерел над багаторазовим цитуванням того самого).
Це означає, що навіть якщо ваш контент буде знайдено й опрацьовано, це не гарантує видимого цитування; контент має бути безпосередньо релевантним до конкретного твердження у відповіді.
Як працює персоналізація
Це основа того, як працюють пошукові системи на базі ШІ, але є додатковий рівень складності: персоналізація.
ChatGPT та інші пошукові системи на базі ШІ можуть персоналізувати результати для окремих користувачів, тож один і той самий запит може давати різні відповіді для різних людей. Персоналізація може залежати від кількох чинників, зокрема:
- Поточний контекст розмови. Попередні повідомлення в тому самому чаті впливатимуть на відповідь на поточний запит. Якщо ви зазначите, що в туристичному спорядженні цінуєте «довговічність», ChatGPT, ймовірно, врахує цей критерій у пошуку, коли пізніше в чаті ви запитаєте «рекомендації рюкзаків».
- Пам’ять. Багато LLM мають функцію пам’яті, яка дає змогу системі зберігати конкретні факти або вподобання між розмовами. Наприклад, за ввімкненої пам’яті ChatGPT може визначати й запам’ятовувати деталі, якими ви ділилися (як-от ваше ім’я чи інтереси), і використовувати їх у наступних розмовах для персоналізації відповідей.
- Місце, час і дата. Багато пошукових систем на базі ШІ можуть визначати ту чи іншу інформацію про вас і підлаштовувати під неї відповіді: від використання IP-адреси для приблизного визначення місця (для запитів на кшталт «бранч поруч») до дати й часу (наприклад, для запиту «список речей для походу» узимку може порадити 4-сезонний намет, а влітку — 3-сезонний намет).
- Системні запити. Будь-які конкретні вподобання, зазначені в системному повідомленні, впливатимуть на відповіді (наприклад, якщо додати «пам’ятай, що я веган» до системного запиту, це вплине на відповіді на запити на кшталт «ідеї здорового сніданку»).
Ось аналогія, яка допоможе зрозуміти системні запити. Уявіть, що ви граєте у футбол: «тренувальні дані» — це всі ваші багаторічні тренування, довгострокова м’язова пам’ять. А системний запит — це те, що тренер каже вам безпосередньо перед виходом на поле. Це потужна короткострокова пам’ять, яка з більшою ймовірністю впливає на результат.
Mark Williams-Cook, Засновник, AlsoAsked

Тому варто відстежувати середню видимість вашого бренду й вебсайту з часом і за багатьма запитами, а не зациклюватися на відповіді на один конкретний запит.
Підсумки
Кожна пошукова система на базі ШІ (від ChatGPT до Perplexity та режиму ШІ в Google) дещо відрізняється, але базові процеси залишаються однаковими. І що важливо для SEO-фахівців і маркетологів: традиційні пошукові системи, як-от Google і Bing, забезпечують значну частину інфраструктури, потрібної для роботи ШІ-пошуку. Оптимізація під ШІ-пошук значною мірою спирається на найкращі практики традиційного SEO.
Додаткові статті
Раян Лоу — директор із контент-маркетингу в Ahrefs із понад 13-річним досвідом роботи письменником, контент-стратегом, керівником команд, директором із маркетингу, віцепрезидентом, CMO та засновником агентства. Він допоміг десяткам компаній, серед яких Google, Zapier, GoDaddy, Clearbit та Algolia, покращити контент-маркетинг і SEO. Також він є письменником-романістом та автором двох курсів із контент-маркетингу.
Опануйте SEO крок за кроком
Як працюють пошукові системи
Перш ніж почати вивчати SEO, потрібно зрозуміти, як працюють пошукові системи.
Основи SEO
Дізнайтеся, як налаштувати свій вебсайт для успіху в SEO, і дізнайтеся про чотири основні аспекти SEO.
Дослідження ключових слів
Відправною точкою в SEO є розуміння того, що шукають ваші цільові клієнти.
SEO-контент
Дізнайтеся, як створити контент, який займає місце в пошукових системах.
Внутрішня оптимізація сторінки
Саме тут ви оптимізуєте список сторінок, що допоможуть пошуковим системам їх зрозуміти.
Лінкбілдінг
Дізнайтеся, як створити контент, який займає місце в пошукових системах.
Технічне SEO
Запобігайте технічним проблемам, які заважають Google отримувати доступ до вашого вебсайту та правильно аналізувати його.
Локальне SEO
Дізнайтеся, як покращити свою видимість у локальних результатах пошуку й залучити більше клієнтів із вашого району.
Що означає ШІ для SEO
Сьогодні неможливо говорити про SEO, не згадуючи генеративний ШІ.
Як працюють пошукові системи на базі ШІ
Дізнайтеся, як саме пошукові системи на базі ШІ, як-от ChatGPT, генерують відповіді й обирають, які бренди й продукти згадувати.