AI (artificial intelligence /人工知能)は 3 つの異なるレイヤーから知識を得ています。トレーニングデータ、検索システム、そして API や MCP のようなライブツールアクセスです。
それぞれのデータレイヤーには固有の長所と短所があります。AI が自信満々に間違ったことを教えてきた経験、あるツールは先週のニュースを知っているのに別のツールは知らない理由、あるいは競合の製品ばかり言及されて自社製品が無視される理由、こうした疑問の答えは、ほぼ例外なく「どのレイヤーがその質問に回答したか」に帰着します。
この記事では、生成 AI の知識が実際にどこから来ているのかをわかりやすく解説し、AI の回答をどこまで信頼すべきかを考える材料を提供します。
トレーニングデータ:AI に知識を教える大規模データセット
AI モデルが最初の質問に答えるよりずっと前に、「トレーニング」と呼ばれるフェーズを経ています。
トレーニングでは、モデルが数十億件のテキスト、画像、コードの例、公開ウェブクロール、書籍、Wikipedia、コードリポジトリ、ライセンスされたデータベースなど、を取り込み、それらすべてにわたるパターンを学習します。トレーニングが終わるころには、モデルはその時点までの人類の知識の統計的スナップショットを事実上記憶した状態になります。
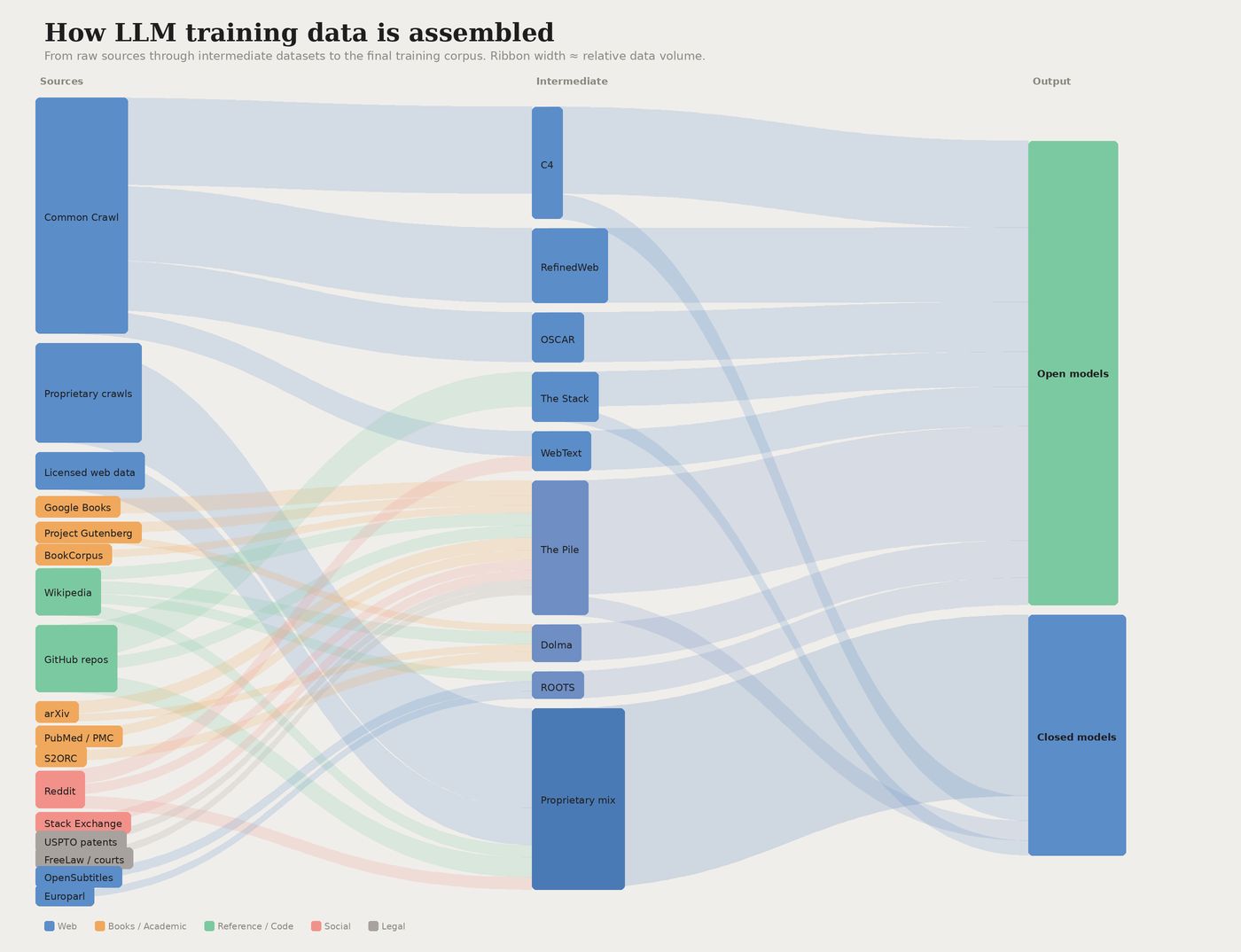
これが AI モデルの「世界の理解」を形成するプロセスです。トレーニングデータにおけるさまざまなエンティティの出現頻度(たとえばブランド名や製品名、「Patagonia(パタゴニア)」や「PRISTINE(プリスティン)」など)、そしてそれらと共起しやすい単語(「環境にやさしい」「高品質」など)が、モデルのブランド理解を方向づけます。
ジャンルカ・フィオレッリさんは次のように説明しています。
LLM は、ブランドと「ジム」や「ノイズキャンセリング」のような概念との関係を学習します。こうした意味的な関連付けが、ブランドが言及されるかどうか、そしてどのように言及されるかに直接影響するのです。
トレーニングの規模は想像しにくいほど膨大です。主要モデルのトレーニングデータは数兆トークン(おおよそ単語の断片)単位で測定されます。コストを見ればその規模感がわかります。GPT‑4 のトレーニングには推定 7,800 万ドル がかかり、Google の Gemini Ultra は約 1 億 9,100 万ドル かかっています。
AI トレーニングデータセットの世界市場は 2025 年に 32 億ドル に達し、2033 年までに 163 億ドルに成長すると予測されています。年平均成長率 22.6% という数字は、データが AI 開発の中核にいかに位置づけられているかを物語っています。
ここで理解すべき決定的に重要なポイントがあります。トレーニングが終了した瞬間、モデルの知識は凍結されます。新しい出来事を学習することはできません。昨日の出来事も、先月の出来事も、トレーニングデータのカットオフ日以降に起きたことも、モデルは一切知りません。
一部のプロバイダーは定期的に新しいデータでモデルをファインチューニングしていますが、それでも離散的なプロセスです。継続的にニュースを読んでいるというよりは、ソフトウェアアップデートをリリースするようなものです。
もう一つの主要な障害モードはハルシネーション(幻覚)です。信頼できるトレーニングデータがない場合、モデルはそれらしく聞こえるもので空白を埋めます、架空の引用、捏造された統計、自信に満ちた的外れな回答などです(実際に、Ahrefs は架空ブランドで AI を騙す実験を実施ました)。
架空のペーパーウェイト会社を設定し、そのブランドについて事実ではないストーリーを意図的に 3 つ作成し、それらをオンライン上で広めた実験で、AI がこれらの偽情報を事実のように使用していたのです。
グラウンディングと RAG(検索拡張生成)とは
AI に最新情報へのアクセスを与える仕組み
Retrieval-Augmented Generation (検索拡張生成:RAG)は、知識カットオフ問題を回避するために使われる主要な手法です。
トレーニング中に学んだ内容だけに依存するのではなく、RAG を使えばモデルは質問された瞬間に関連文書を取得し、その文書をコンテキストとして回答を生成できます。
たとえるなら、持ち込み不可の試験と持ち込み可の試験の違いです。トレーニングのみのモデルは記憶だけで回答しなければなりません。RAG 対応のモデルはまず情報を調べてから回答できます。結果として、回答はより最新で、原理的にはより検証可能です。なぜなら、統計的パターンマッチングではなく、実際に取得されたコンテンツに基づいているからです。
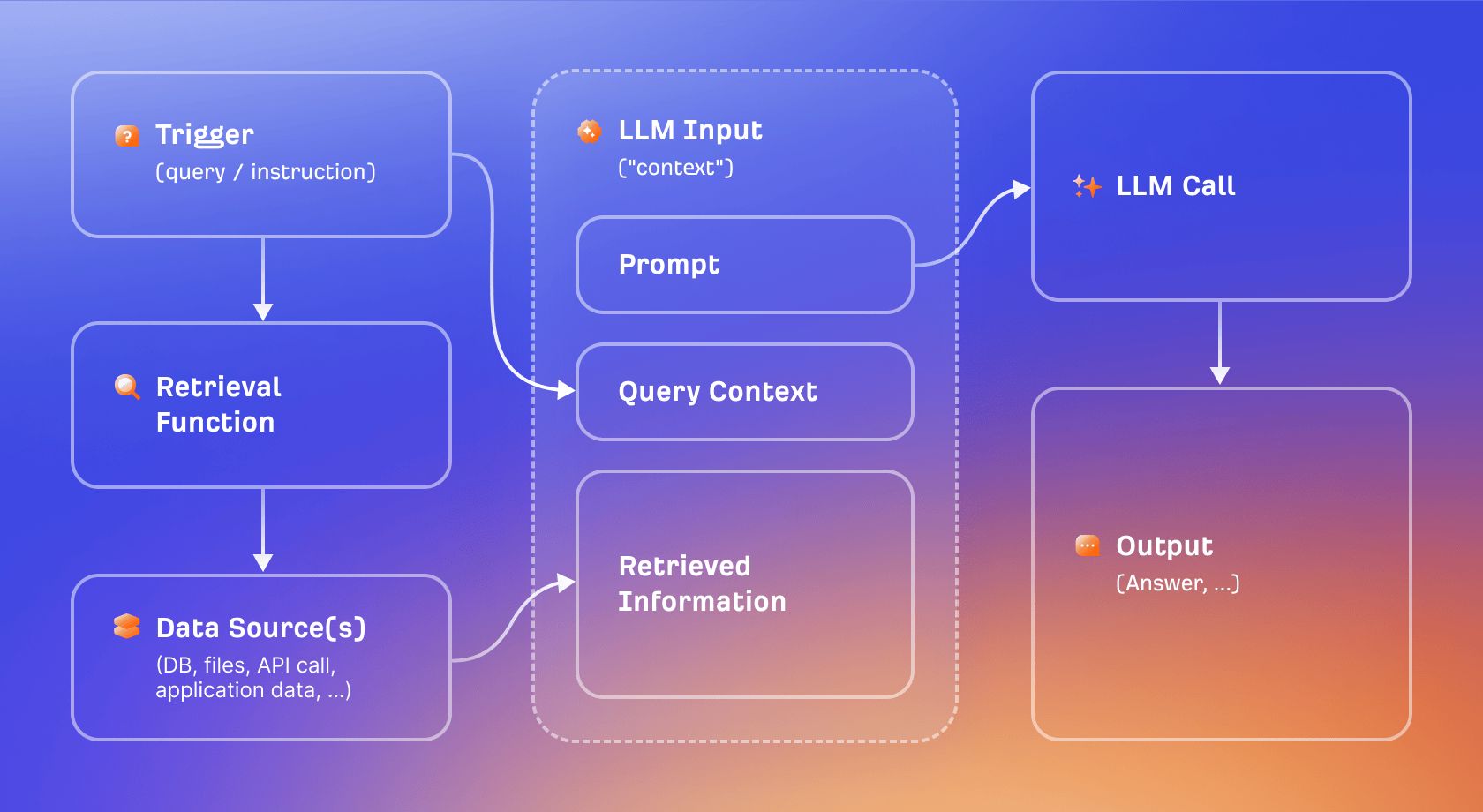
「グラウンディング」は、この固定化をより広く指す用語です。AI の回答がグラウンディングされているとき、特定の取得ソースに紐づけられており、ハルシネーションのリスクが大幅に低減します。
ブリトニー・ミュラーさんは次のように説明しています。
グラウンディングは「グラウンドトゥルース(ground truth)」に由来し、統計学、そしてもともとは地図学に根ざしています。文字通り「外に出て、自分の地図が現実と一致しているか検証する」という意味でした。
ChatGPT や Gemini のような AI 検索エンジンは、このグラウンディングプロセスに Google や Bing のような従来型の検索インデックスを利用しています。だからこそ、優れた SEO を行い、従来型の検索で上位にランクインすることは、AI での可視性向上にもつながります。AI が検索するクエリに対して検索インデックスで上位に表示されるほど、回答に取得・引用される可能性が高まるのです。

すべての AI 製品が RAG を使っているわけではありません。たとえば、ブラウジングを無効にした ChatGPT のベースセッションは純粋にトレーニングベースであり、最新情報へのアクセスもライブソースに対して回答を検証する手段もありません。
トレードオフはスピードとシンプルさです。トレーニングのみの応答は高速ですが、永遠に時代遅れのままです。RAG はレイテンシを増加させ、新たな障害モード(検索エラー、誤ったソースや低品質なソースの取得)を生みますが、最新性を実現します。
MCP と API:AI エージェントやツールがリアルタイムでアクセス範囲を拡張する仕組み
RAG は AI の回答に最新情報を取り込む方法の一つです。しかし、現代の AI システムはさらに先へ進んでおり、会話の途中で外部ツールを呼び出す能力をモデルに与えています。これが AI エージェントの領域です。
AI エージェントは単にドキュメントを検索するだけではありません。API へのクエリ、検索の実行、コードの実行、ライブデータソースとのやり取りを、タスク処理の一環として行えます。
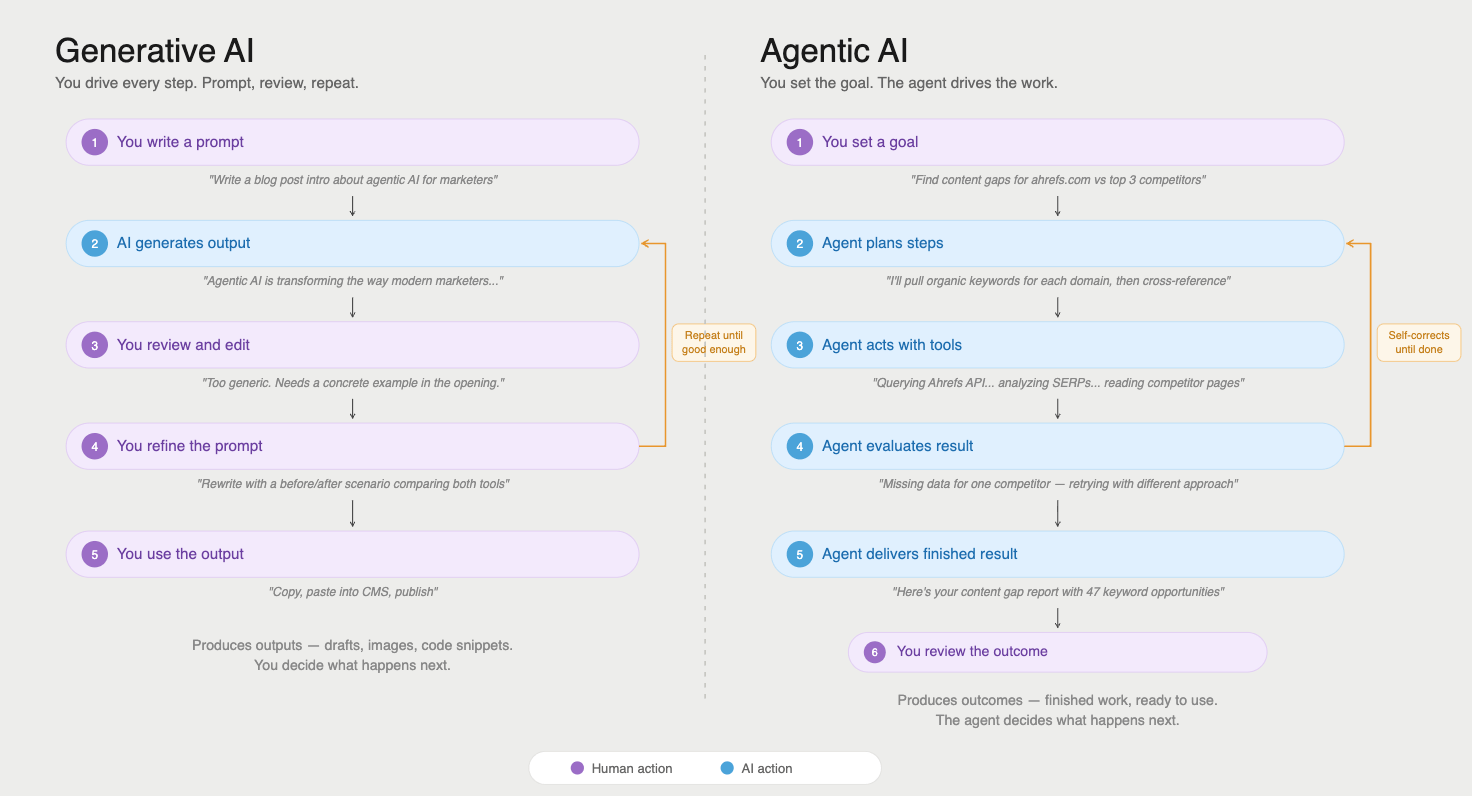
このための新たなインフラとして登場したのが Model Context Protocol(MCP)です。AI モデルが外部データソースと構造化された方法で接続するための標準規格です。
具体的な例を挙げましょう。Ahrefs は MCP インテグレーション を提供しており、AI エージェントがタスク中に Ahrefs のデータを直接クエリできます。キーワード指標、被リンクデータ、競合インサイトを、ユーザーがワークフローを離れることなく取得可能です。
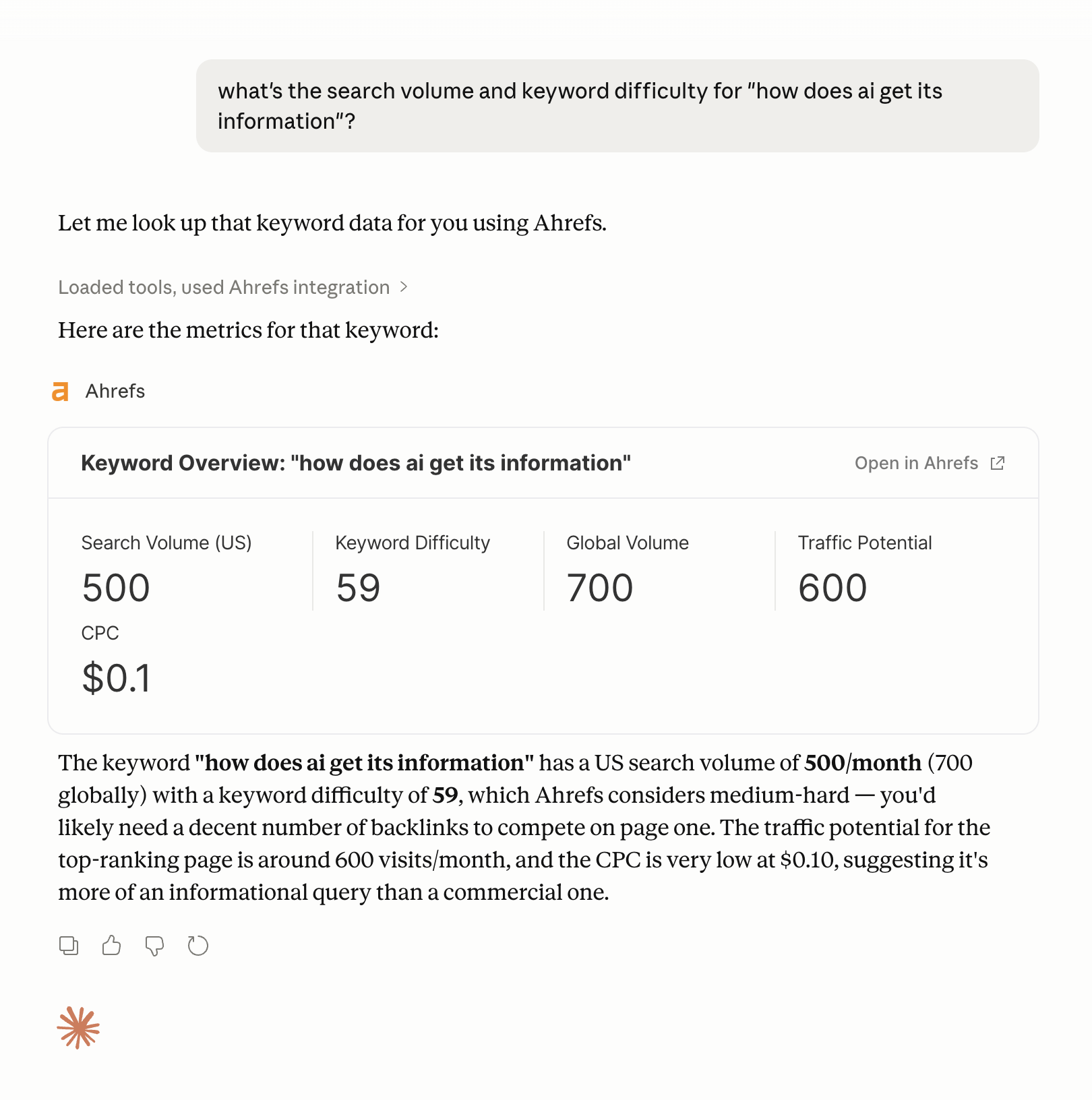
Ahrefs の Agent A はこれをさらに進化させたものです。Ahrefs の完全な内部データセット、キーワードデータ、サイト指標、競合インテリジェンスなど、に直接かつ無制限にアクセスできるマーケティング AI です。
トレーニングデータから SEO インサイトを推測する(古くなる)モデルや、公開ソースから検索する(不完全な)モデルとは異なり、Agent A は実際のデータを使って動作します。
マーケティングや SEO のタスクにおいて、これは非常に大きな違いです。Agent A は、手取り足取りのサポートなしに、多くの SEO やマーケティングワークフローをこなせます。
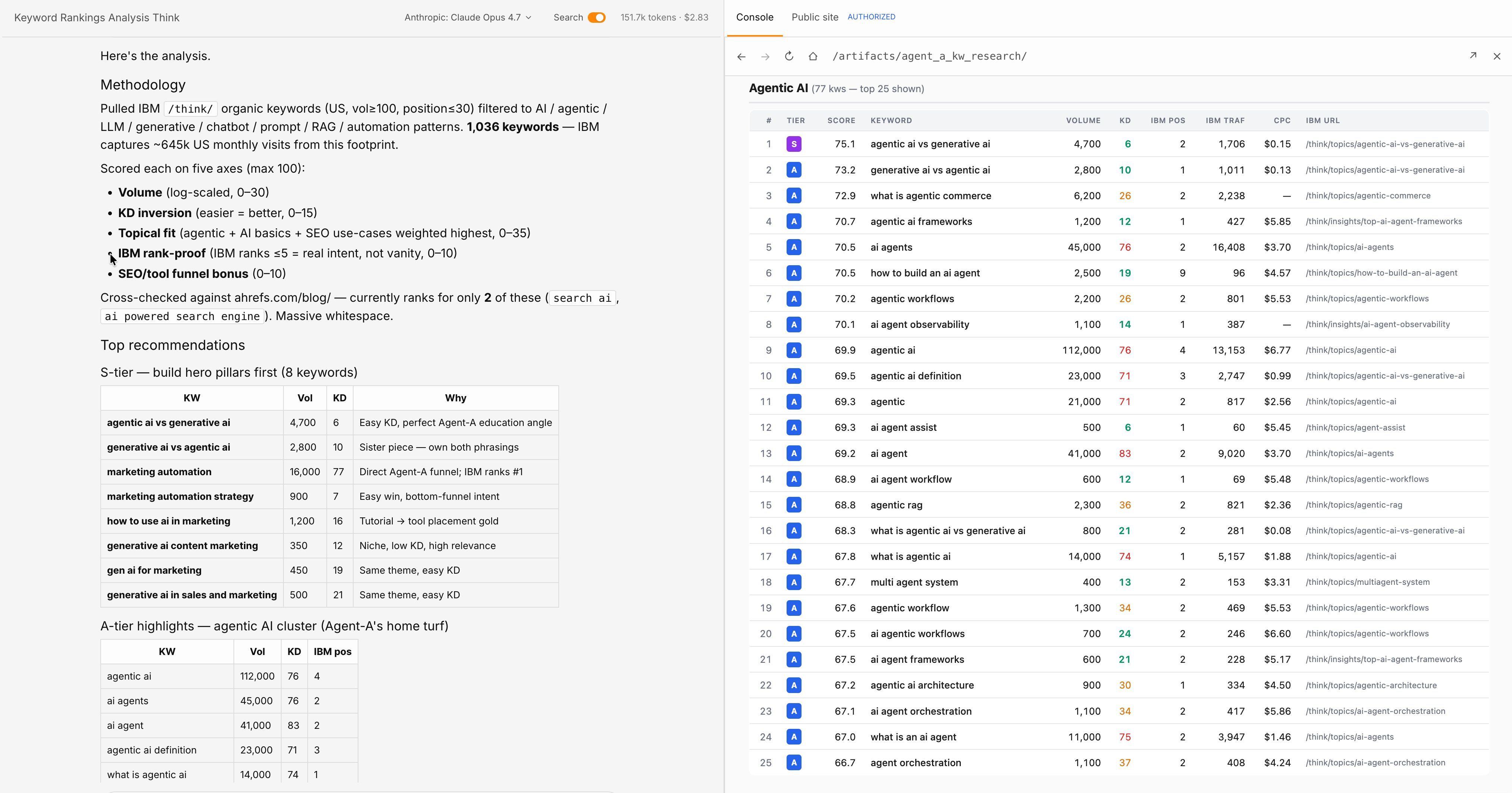
より広い原則として、ツールで拡張された AI は、呼び出すツールの信頼性に依存します。API が不正確なデータを返せば、AI は自信満々に不正確な回答を生成します。モデルの知性がガベージ入力から守ってくれるわけではありません。しかし、ツール統合がもたらすのは、どんなトレーニングデータセットでもカバーしきれないほどモデルのリーチを拡張することです。
AI にブランドを見つけてもらい、信頼されるために必要なこと
AI がどこから情報を得ているかを理解すれば、引用される可能性を最大化するためにブランドがどこに存在すべきかが見えてきます。
- オフサイトでの言及
AI にブランドを正確に表現してもらいたい場合、出発点は自社ウェブサイトではなく、オフサイトでの言及です。モデルはトレーニングに使ったソース、報道記事、サードパーティのレビュー、フォーラムのディスカッション、Wikipedia の記事、権威ある出版物での引用、からブランドを学習します。自社ドメインにしか存在しないブランドは、モデルのトレーニングデータにとってほぼ見えない存在です。 - クエリファンアウト
ブランド認知の先には、クエリファンアウト、AI システムがコアトピックの周辺で生成する関連質問、について考える必要があります。「プロジェクト管理ソフトウェア」でランクインしているブランドは、「スプリントレビューの進め方」や「アジャイルとウォーターフォールの違い」のようなコンテンツも狙うべきです。ユーザーが最初のクエリからフォローアップする際に AI システムが表示するのは、まさにこうした質問だからです。コアトピックの周辺のセマンティックな領域を網羅するコンテンツを作成すれば、ファンアウト時に表示される確率が高まります。 - AI からのアクセシビリティ
技術的なアクセシビリティも依然として重要です。クリーンな HTML、高速な読み込み時間、適切に設定された robots.txt ファイルは、AI クローラーがコンテンツを読めるかどうかに影響します。llms.txt は LLM がサイト構造をナビゲートするのを助けるための提案中の標準ですが、2026 年時点で主要な LLM プロバイダーがこれを尊重すると確認したケースはありません(そのため、時間をかける必要はありません)。 - 構造化された正確な情報を公開する
AI モデルはトレーニングデータと RAG の両方でウェブコンテンツを参照します。自社サイトの情報が明確で、最新かつ構造化されていれば、AI が正しい回答を生成する可能性が高まります。テクニカルなアクセシビリティも依然として重要です。また、llms.txt の導入も検討する価値があります。 - API や MCP による連携を検討する
自社の製品やサービスに関するリアルタイムデータ、在庫状況、価格、機能情報など、を AI エージェントに直接提供できれば、大きな競争優位になります。Ahrefs はすでに MCP 連携を提供しています。MCP サーバーとは何かについてもぜひ確認してください。 - AI がブランドについて何を言っているかをモニタリングする
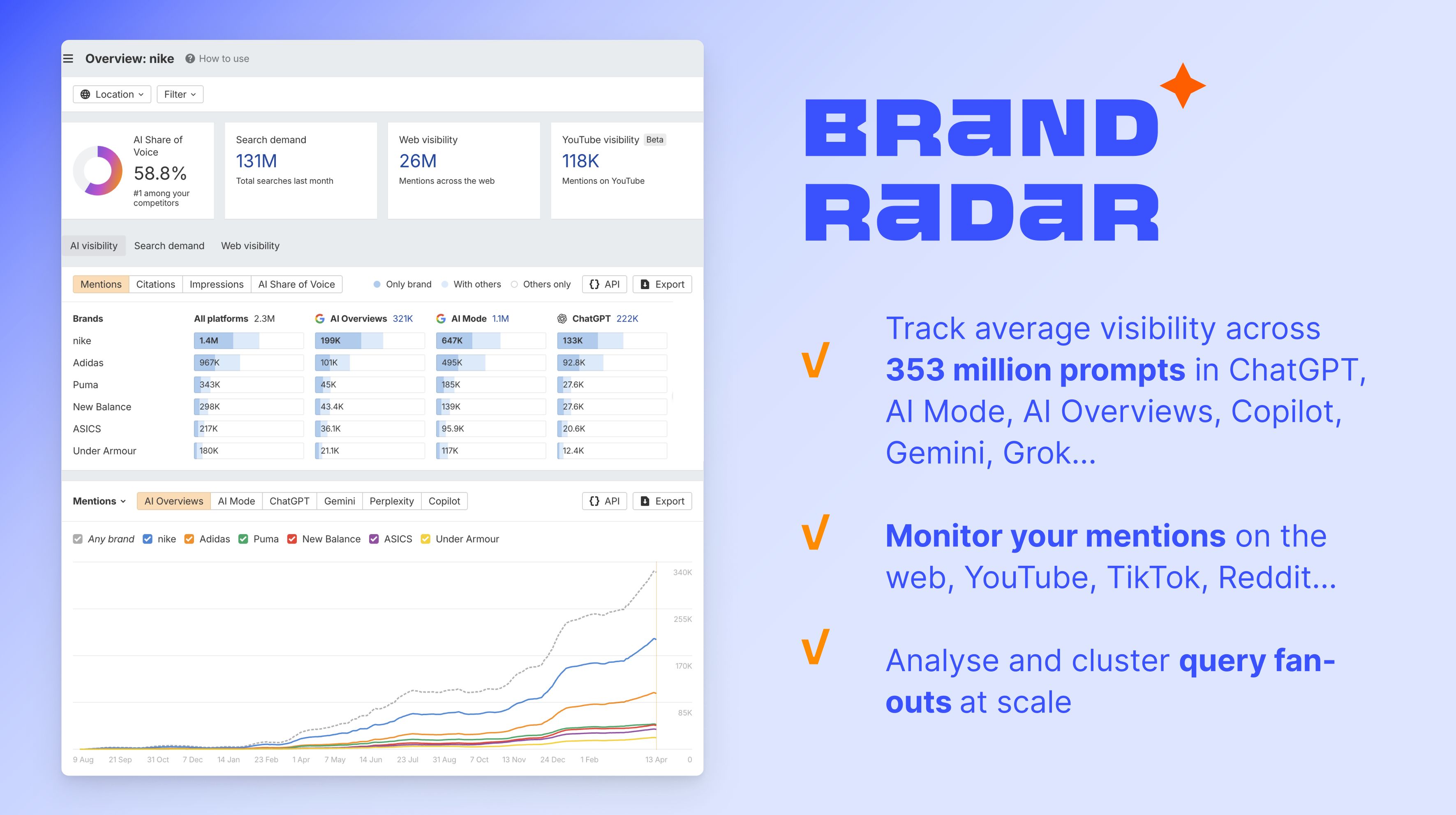
AI の回答は、トレーニングデータの古さや RAG ソースの偏りによって、不正確になることがあります。ブランドレーダーのようなツールを使えば、AI モデルが自社ブランドをどのように言及しているかを追跡できます。使い方の詳細はこちらの記事をご覧ください。
こうした取り組みが実際にどう機能しているかを測定するには、Ahrefs のブランドレーダーが役立ちます。ChatGPT、Gemini、Perplexity、AI Overview(AI による概要)、AI Model Grok など多数のプラットフォームにわたる AI シェアオブボイスをトラッキングし、AI 生成の回答で自社ブランドが競合と比較してどの程度言及されているかを可視化します。詳しい使い方はこちらの記事をご覧ください。

Ahrefs をもっと活用 👉
▶︎ Ahrefs 公式ブログ — 本社発信の記事
▶︎ Ahrefs Canny — 開発チームへ意見を送る
▶︎ X 公式アカウント— 最新情報をリアルタイムで
▶︎ YouTube 公式チャンネル— 動画コンテンツをチェック
▶︎ Ahrefs note — 日本チーム発信の記事

