On s’est tous habitués aux petits liens bleus numérotés dans les réponses de ChatGPT. Ce sont les citations qui viennent appuyer ses réponses avec des informations externes.
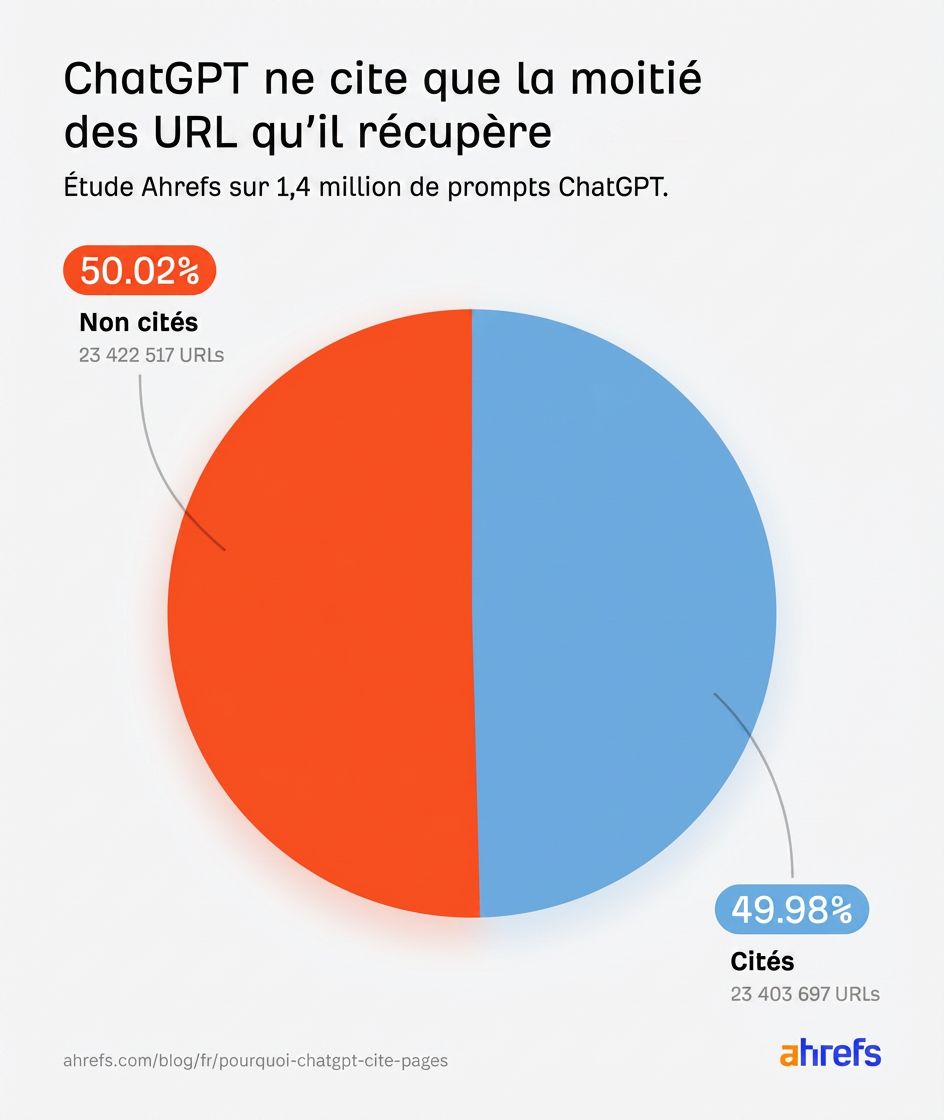
Pourquoi une page reçoit-elle le crédit pendant qu’une autre, que l’IA a pourtant clairement récupérée, n’obtient rien ?
Selon les études de l’expert IA Dan Petrovic, quand ChatGPT récupère des résultats, chacun revient avec le titre de la page, un bref extrait ou résumé, l’URL et un numéro d’identifiant.

ChatGPT utilise ces données pour décider quelles pages méritent d’être ouvertes et, au final, citées dans sa réponse.
Cela signifie qu’il existe une couche de filtrage avant que ChatGPT ouvre et lise le contenu réel de votre page. Le titre, l’extrait et l’URL font tout le travail lors de cette première décision.
On voulait donc savoir : qu’est-ce qui influence réellement cette décision ? Une similarité sémantique plus élevée entre les données de récupération d’une page et la requête de l’utilisateur augmente-t-elle la probabilité d’être cité ? Quels champs comptent le plus ? Les URL lisibles par les humains surpassent-elles les URL opaques ?
Pour le découvrir, on a analysé 1,4 million de prompts ChatGPT 5.2 de février 2025 (desktop) avec l’aide du data scientist d’Ahrefs Xibeijia Guan.
Mais avant d’aborder les résultats, vous devez comprendre comment ChatGPT rassemble ses sources, car toutes les URL n’entrent pas dans le système de la même façon.
Quand ChatGPT récupère des résultats, il catégorise les sources à l’aide d’un champ interne appelé ref_type (en gros, un label pour le canal de récupération par lequel l’URL est arrivée).
On a découvert cinq catégories : search, news, reddit, youtube et academia.
Les taux de citation entre ces catégories sont extrêmement inégaux :
| Type de source (ref_type) | Taux de citation | Nombre total de points de données |
|---|---|---|
| search (recherche) | 88,46 % | 25 563 589 |
| news (actualités) | 12,01 % | 3 940 537 |
| 1,93 % | 16 182 976 | |
| youtube | 0,51 % | 953 693 |
| academia (académique) | 0,40 % | 185 337 |
L’index « search » général domine (à la fois en volume et en taux de citation) et 88 % des URL qui finissent par être citées par ChatGPT proviennent directement de la recherche.
Si vous voulez être cité par ChatGPT, vous devez figurer dans ce pool de sélection de recherche. Ce qui signifie que votre contenu doit être classé.
Ce n’est pas une nouveauté. La plupart des gens savent déjà que le positionnement joue un rôle, mais il est toujours utile d’avoir davantage de données pour l’étayer.
Les verticales spécialisées comme YouTube (par exemple youtube.com) et Academia (par exemple arXiv.org) sont en revanche intégrées à grande échelle mais finissent presque jamais à la surface en tant que citations réelles.
<sidenote>Le ref_type « search » inclut également des résultats provenant de Reddit et de YouTube. Toute page issue de ces plateformes qui apparaît via une recherche web classique y sera comptabilisée.</sidenote>
Les ref_type distincts « Reddit » et « YouTube » représentent probablement des résultats supplémentaires, c’est-à-dire ceux récupérés via des intégrations API dédiées, en plus de ceux déjà renvoyés par la recherche web.
C’est pourquoi le volume sur ces canaux est si élevé : ChatGPT complète ses résultats de recherche avec un flux séparé de contenu Reddit et YouTube.
C’est important pour interpréter le reste de l’analyse.
En moyenne, ChatGPT extrait environ 16,57 URL citées et environ 16,58 URL non citées par prompt.
Mais comme Reddit représente 67,8 % du pool non cité, toute comparaison agrégée entre « cité » et « non cité » revient en réalité à comparer des résultats de recherche à des sorties de l’API Reddit. Ce n’est pas une comparaison équitable.
C’est pourquoi, tout au long de cette recherche, on a isolé l’analyse par ref_type autant que possible pour éviter cette distorsion.
C’est probablement le résultat le plus frappant du jeu de données.
Reddit dispose de son propre ref_type dédié dans le système de récupération de ChatGPT, avec plus de 16 millions de points de données dans notre jeu de données.
Pourtant, il est cité à un taux de seulement 1,93 %.
Et 67,8 % de toutes les URL non citées proviennent de Reddit.
Autrement dit : ChatGPT utilise Reddit de manière intensive pour comprendre les sujets, évaluer le consensus et construire le contexte, mais il ne donne presque jamais crédit à Reddit.
Il apprend de la foule, puis cite une autre institution.
Comme on l’a brièvement évoqué, quand ChatGPT récupère des résultats de recherche, chacun revient avec un ensemble de champs incluant un titre, une URL, et parfois un extrait (un court passage du contenu de la page stocké dans les données de récupération de ChatGPT).
On s’attendait à ce qu’avoir davantage de ces champs renseignés soit corrélé à des taux de citation plus élevés.
Au premier coup d’œil, les données agrégées semblaient raconter une histoire différente : les pages non citées ont en réalité plus de champs renseignés dans les données de récupération de ChatGPT que les pages citées.
Les URL non citées avaient des snippets (et notamment des extraits) dans 14,81 % des cas contre 4,36 % pour les URL citées, et étaient bien plus susceptibles de porter une date de publication (92,72 % contre 35,98 %).
On a failli retenir ça comme un résultat, mais heureusement on ne l’a pas fait.
En creusant, on a constaté que cet écart était presque entièrement un artefact de composition des données, causé par Reddit et les mécanismes du pipeline de récupération de ChatGPT.
Comme le pool non cité est massivement dominé par Reddit (67,8 %), et que le contenu Reddit extrait via API porte naturellement des métadonnées pub_date, le chiffre de 92,72 % est un artefact Reddit et pas un signal sur la façon dont ChatGPT évalue les pages web en général.
L’écart sur les extraits s’explique différemment. Selon les recherches de David McSweeney sur le processus de récupération de ChatGPT, le modèle abandonne en réalité le champ extrait (le court passage de contenu) une fois qu’il a décidé de citer une URL, et ouvre la page complète à la place.
Il ne s’agit donc pas d’une préférence de ChatGPT pour les pages sans extraits. Le faible pourcentage d’extraits pour les pages citées est probablement un sous-produit du fonctionnement du pipeline.
Quand on a isolé les données au seul ref_type « search » (en excluant Reddit, les actualités, YouTube et le reste) le tableau est devenu bien plus clair :
| ref_type search | Contient un extrait | Contient une date de publication | Nombre total d’URL |
|---|---|---|---|
| Citées | 2,52 % | 33,79 % | 22 612 529 |
| Non citées | 0,09 % | 49,00 % | 2 951 060 |
Les données d’extraits (snippet data) sont quasiment inexistantes pour les deux groupes au sein de la verticale search. Ce n’est pas un signal exploitable. Et les pourcentages de date de publication sont plus proches, mais les pages search non citées sont toujours légèrement plus susceptibles de porter une pub_date (49 %) que les pages citées (33,79 %).
Les différences qu’on observait initialement entre les URL citées et non citées semblent avoir été faussées par la composition des données et les mécaniques de récupération. Le moindre signal (s’il en existe un) est noyé dans le bruit.
Conclusion honnête : on ne peut pas tirer de conclusions solides sur le rôle que jouent les snippets ou les dates de publication dans la citation à partir de ces données.Ce problème s’applique probablement aussi à d’autres études sur les citations. Toute recherche comparant des URL « citées » et « non citées » sans tenir compte de l’origine de ces URL risque de confondre des particularités des données avec de vrais schémas.
Ouvrez Brand Radar, configurez votre marque et vos concurrents, puis rendez-vous directement dans le rapport Pages citées.
Ensuite, filtrez les réponses dans lesquelles des concurrents sont cités mais pas vous.
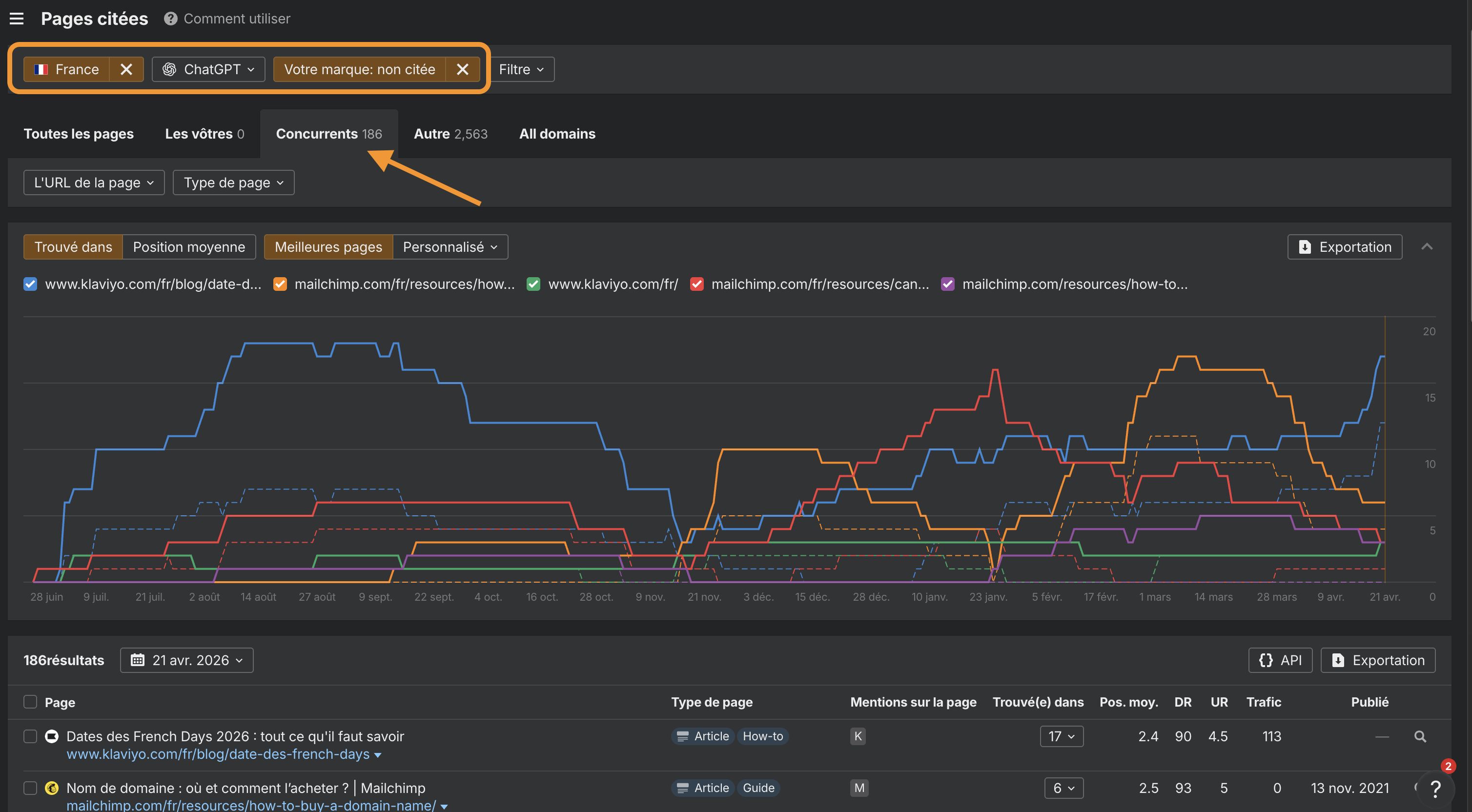
Cette analyse des écarts vous donne une liste concrète de contenus à créer, actualiser ou restructurer.
Pour déterminer ce qui est « citable », ChatGPT estime la pertinence (dans un processus parfois décrit comme un « scoring sémantique ») pour juger si un article et une requête sont liés.
Comme ChatGPT est un modèle à code source fermé, on n’a pas de visibilité sur la façon exacte dont il détermine la pertinence en interne.
Dans cette étude, on a donc utilisé la similarité cosinus calculée à partir d’embeddings générés par des modèles open source, pour quantifier et “approximer” le fonctionnement probable de ChatGPT.
ChatGPT confronte les URL à ses propres « fanout queries » — les sous-questions qu’il génère en interne (à partir du prompt initial de l’utilisateur) pour rechercher des faits spécifiques.
Les données confirment que la pertinence du titre par rapport aux fanout queries est un facteur important dans la citation :
- Prompt vs. titre d’URL citée : 0,602
- Prompt vs. titre d’URL non citée : 0,484
- Fanout query vs. titre d’URL citée (correspondance maximale) : 0,656
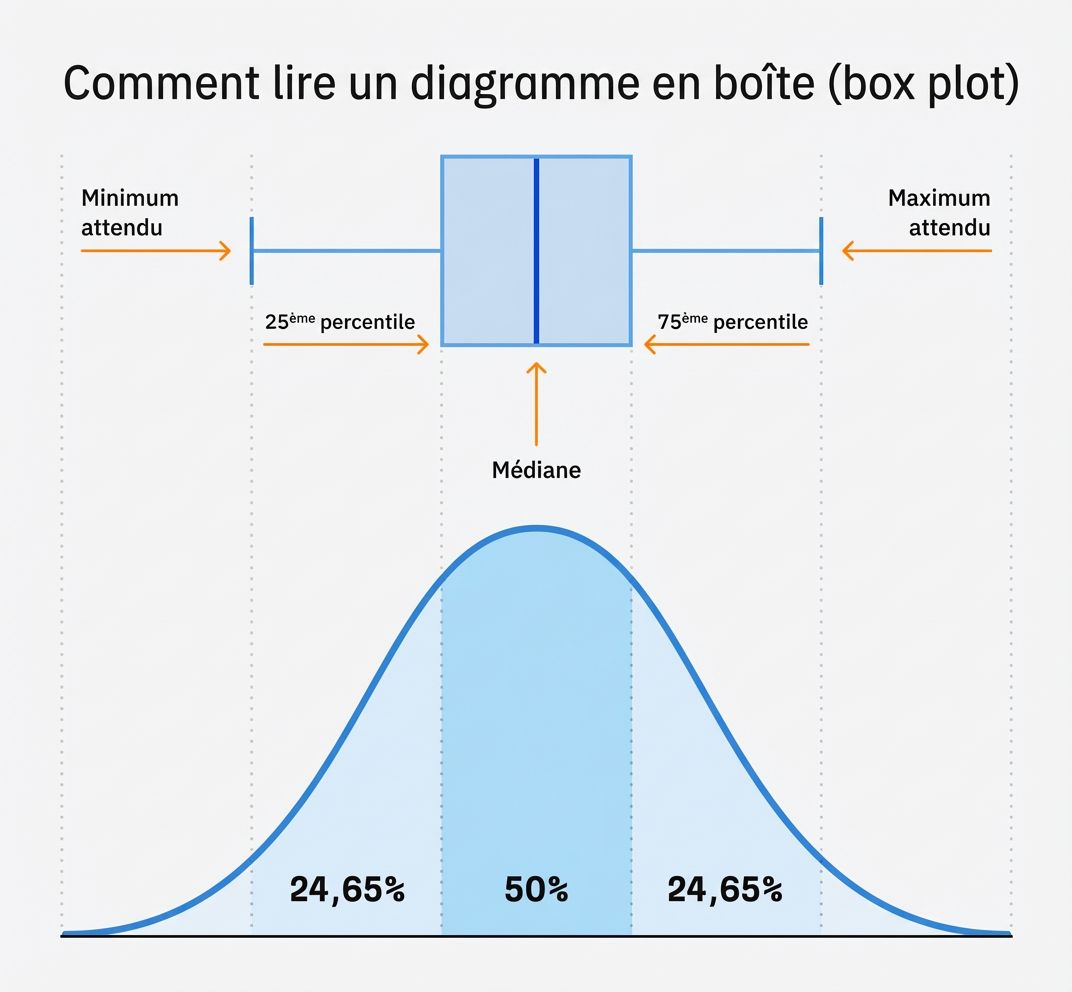
Je vous laisse continuer votre lecture :
Les box plots racontent l’histoire clairement. Sur tous les ref_types, les URL citées ont systématiquement une similarité plus élevée entre leur titre et le prompt original :
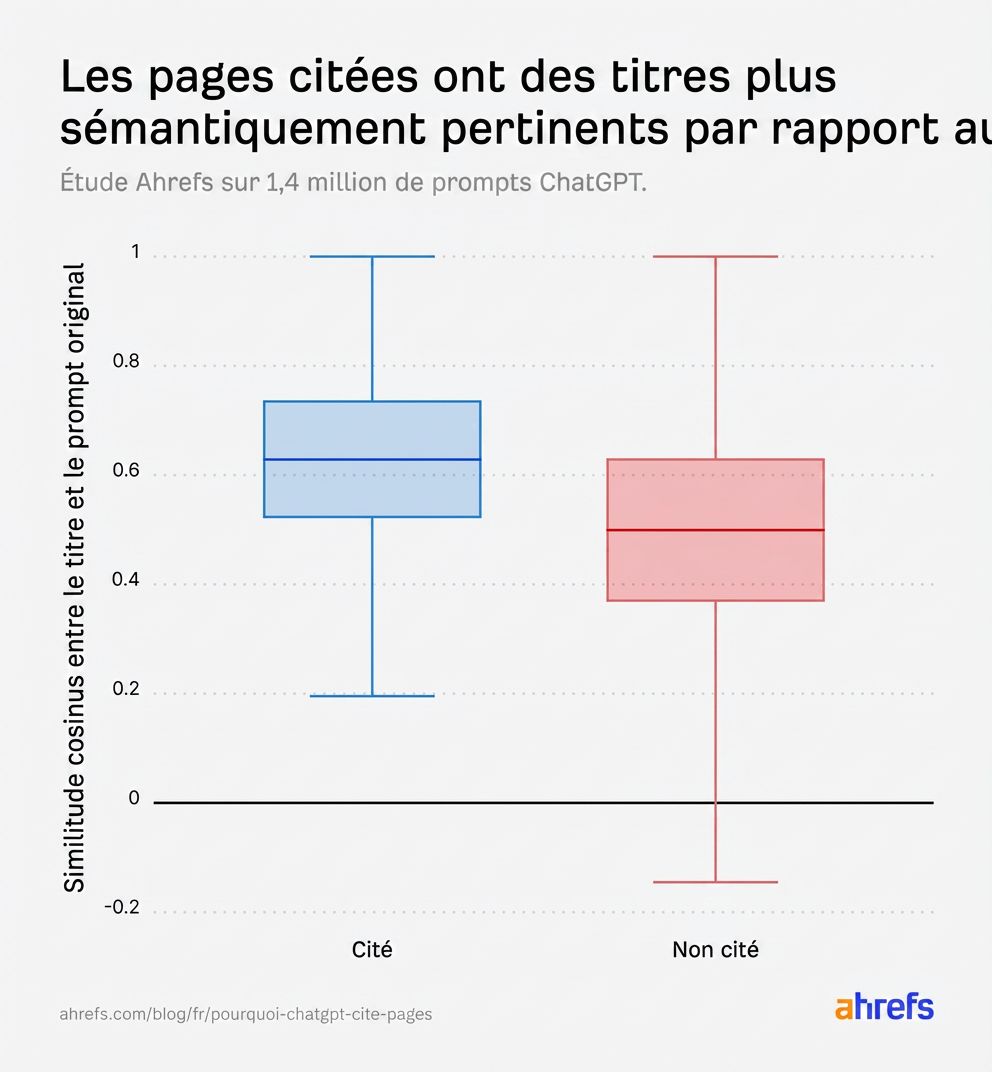
L’écart se creuse encore davantage quand on compare avec les fanout queries plutôt qu’avec le prompt original. Ce résultat confirme que créer du contenu pertinent par rapport aux sous-questions internes de ChatGPT est ce qui drive vraiment la sélection :
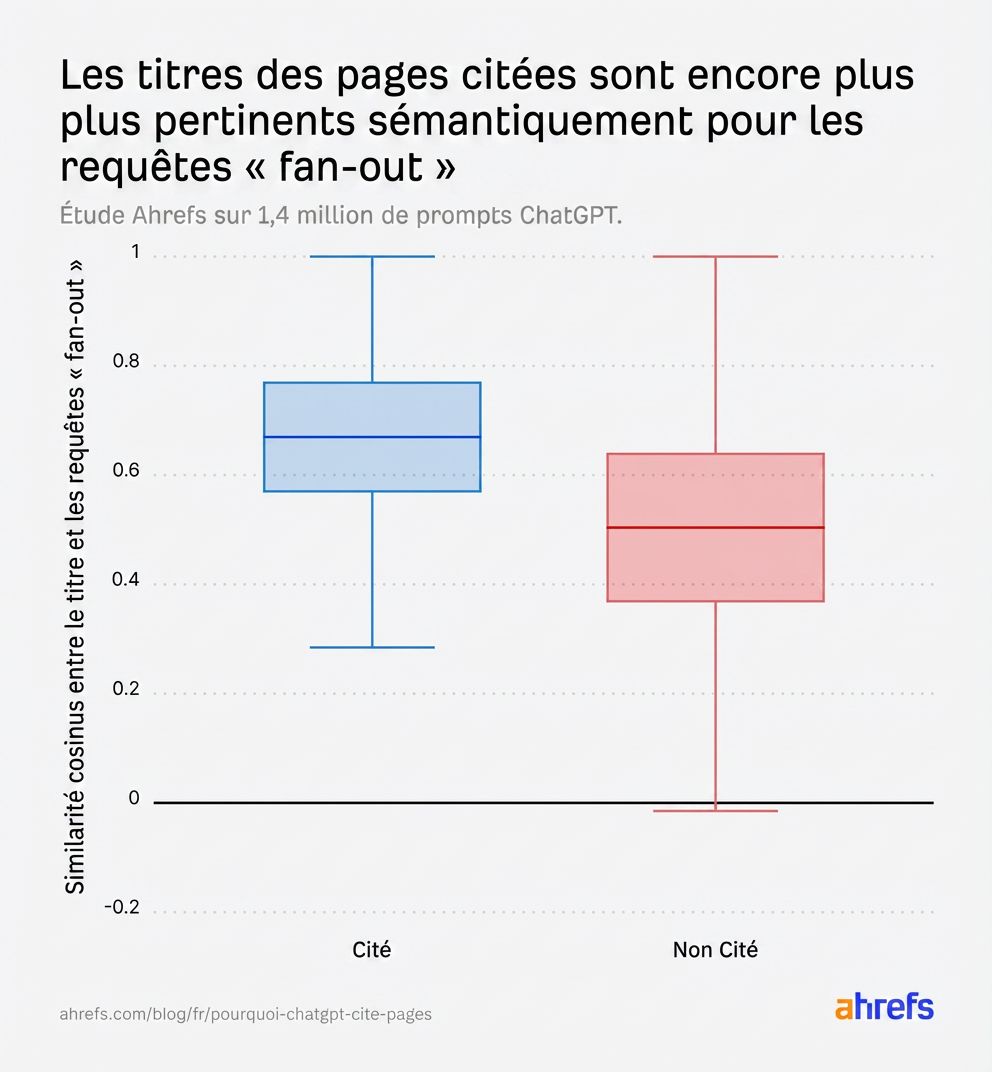
Quand on isole spécifiquement le ref_typesearch, le schéma devient encore plus net. Les pages citées sont clairement plus pertinentes, et la distribution des pages non citées chute significativement :
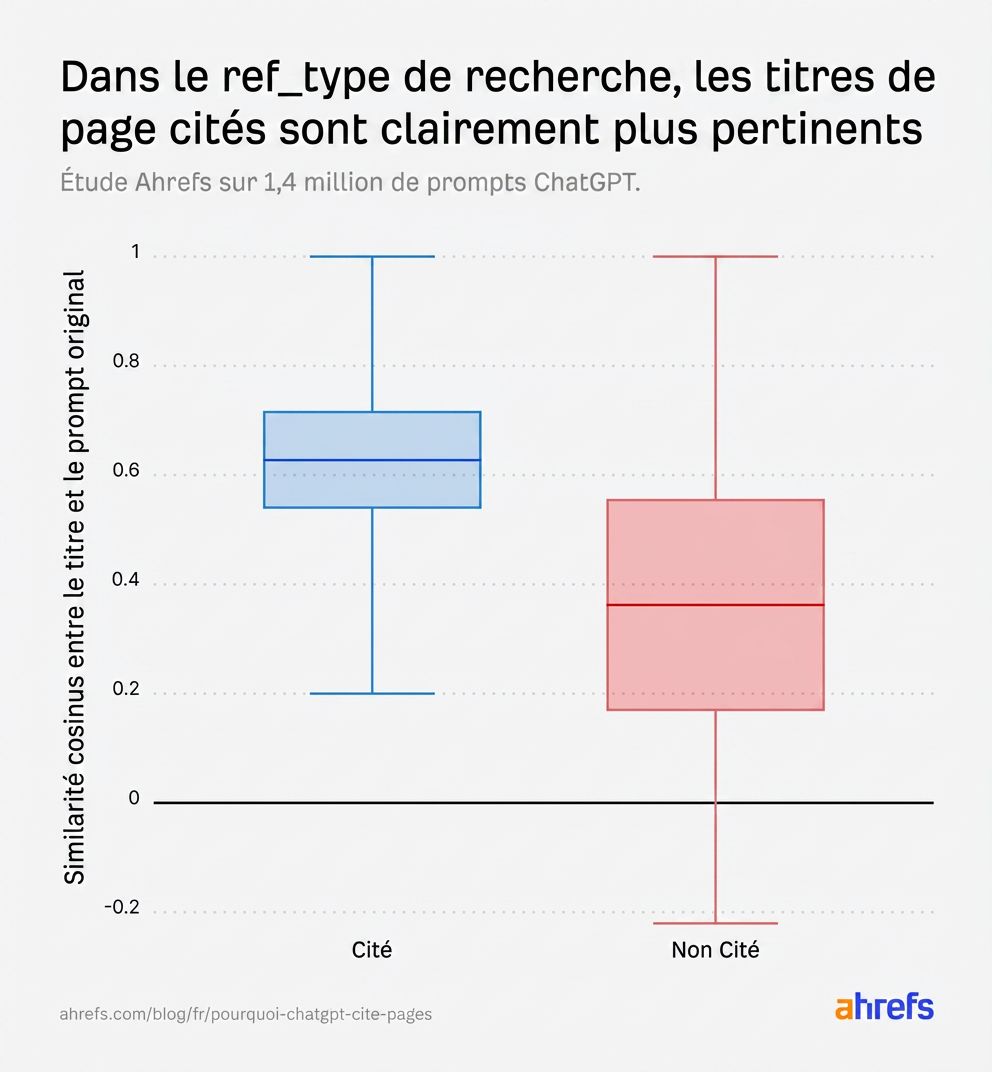
On a également constaté que les résultats de recherche avec des slugs d’URL en langage naturel avaient un taux de citation de 89,78 %, contre 81,11 % pour ceux qui n’en avaient pas.
Concrètement, si votre URL et votre titre ne s’alignent pas sémantiquement avec les fanout queries internes de l’IA, vous avez moins de chances d’être cité.
C’est l’ensemble réel de sous-questions auxquelles votre contenu doit répondre.
Ensuite, utilisez l’AI Content Helper pour vérifier dans quelle mesure votre page couvre les sujets que ces fanout queries abordent. Il mesure la similarité cosinus entre votre contenu et les sujets que la SERP ou la réponse IA cherche à couvrir. Il peut ajouter certaines parties en surbrillance colorée au fil de votre rédaction, montrant quelles lacunes persistent.
Si la page d’un concurrent est citée pour une requête alors que la vôtre ne l’est pas, c’est l’un des moyens les plus rapides de diagnostiquer pourquoi.
Il est communément admis que les contenus plus récents sont davantage cités par l’IA. Notre propre étude portant sur 17 millions de citations le confirme. On a constaté que ChatGPT citait des URL vieilles de 458 jours de moins que les résultats organiques de Google. C’est la préférence de fraîcheur la plus marquée de toutes les plateformes qu’on a testées.
Cette étude ne contredit pas cette tendance, mais elle ajoute une couche de nuance supplémentaire.
Par exemple, quand on examine l’index search, les pages citées couvrent un large spectre d’âges : la médiane est d’environ 500 jours (~1,3 ans), avec certaines pages citées ayant plus de 2 700 jours (~7,4 ans).
L’âge médian est en réalité bien inférieur à celui de notre étude initiale sur la fraîcheur mentionnée ci-dessus (958 jours en juillet contre 500 jours dans ce jeu de données), ce qui suggère que ChatGPT penche encore plus vers le récent dans ses préférences de citation.
Cela dit, on a aussi constaté que les pages non citées sont massivement très récentes.
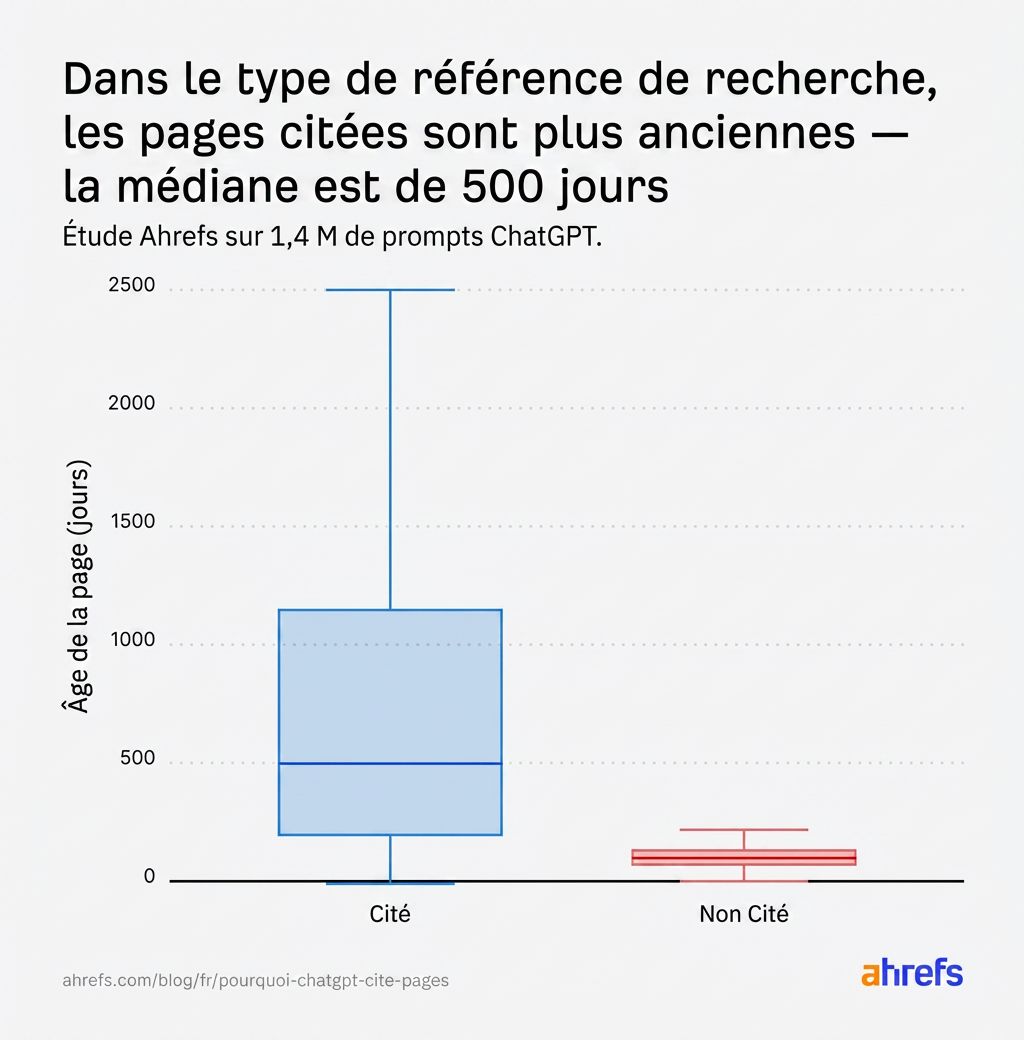
Donc, au sein d’un même ensemble de résultats récupérés pour un prompt, ce sont les pages plus anciennes et mieux établies qui tendent à être citées, et le contenu le plus récent qui tend à être écarté.
Autrement dit, ChatGPT préfère le contenu frais, mais tend à citer comparativement du contenu « plus ancien » plus souvent. Ça semble contre-intuitif, mais les deux choses peuvent être vraies en même temps.
Sur la population globale des citations IA, ChatGPT penche effectivement vers le plus récent comparé aux résultats Google, et même par rapport à ses propres préférences de citation de l’année dernière.
Mais au sein d’un ensemble de récupération donné, la fraîcheur seule ne suffit pas. La pertinence fait toujours le gros du travail.
Une nouvelle page qui correspond bien aux fanout queries sera citée. Une nouvelle page qui n’y correspond pas sera récupérée, puis ignorée.
Il vaut aussi la peine de souligner que le pool de pages non citées (~3M) au sein du ref_type search est bien plus petit que le groupe cité (~23M), ce qui limite la confiance avec laquelle on peut interpréter l’écart d’âge.
C’est dans la catégorie « actualité » que la fraîcheur compte le plus.
Dans cette catégorie, les scores de pertinence du titre pour les pages citées et non citées sont presque identiques :
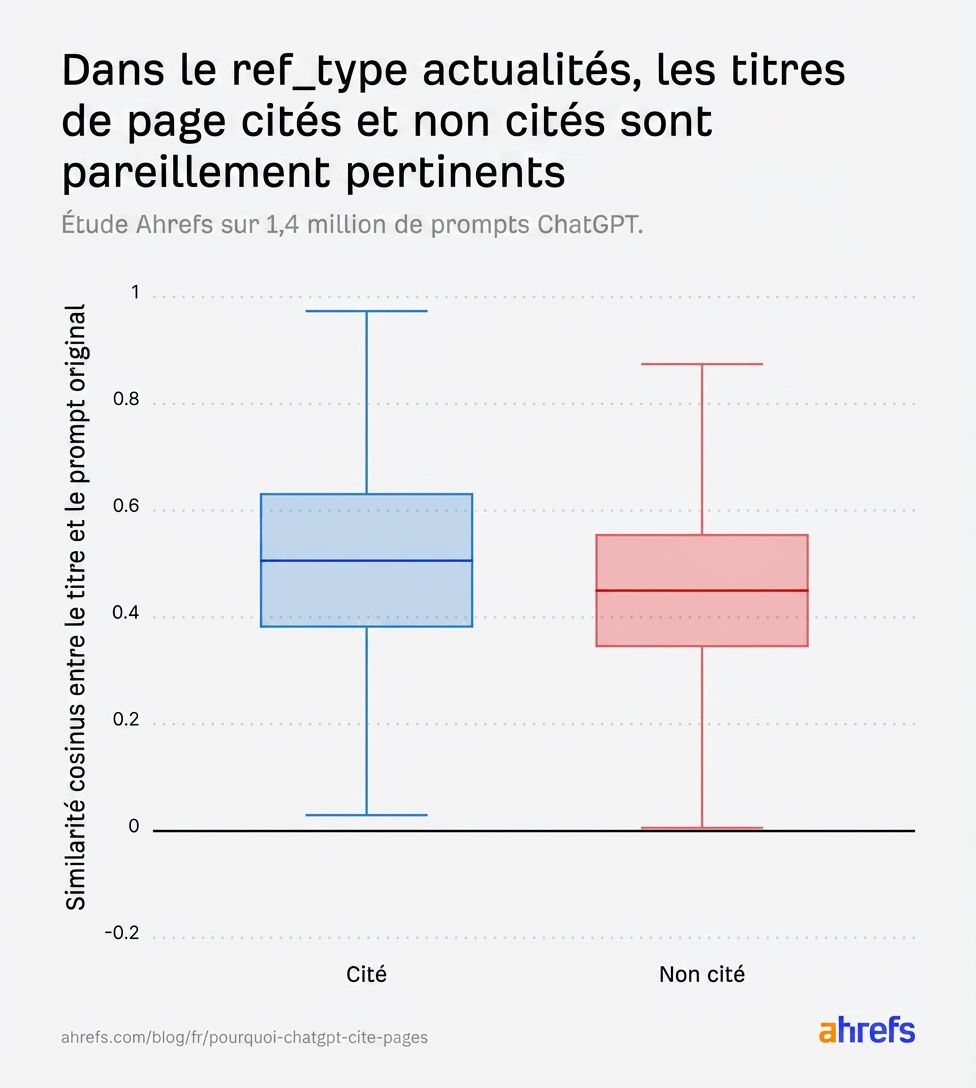
L’IA ne peut pas décider sur la seule base de la pertinence, alors elle se rabat sur un critère de départage temporel : l’âge de la page. Les pages d’actualités citées penchent vers le plus récent :
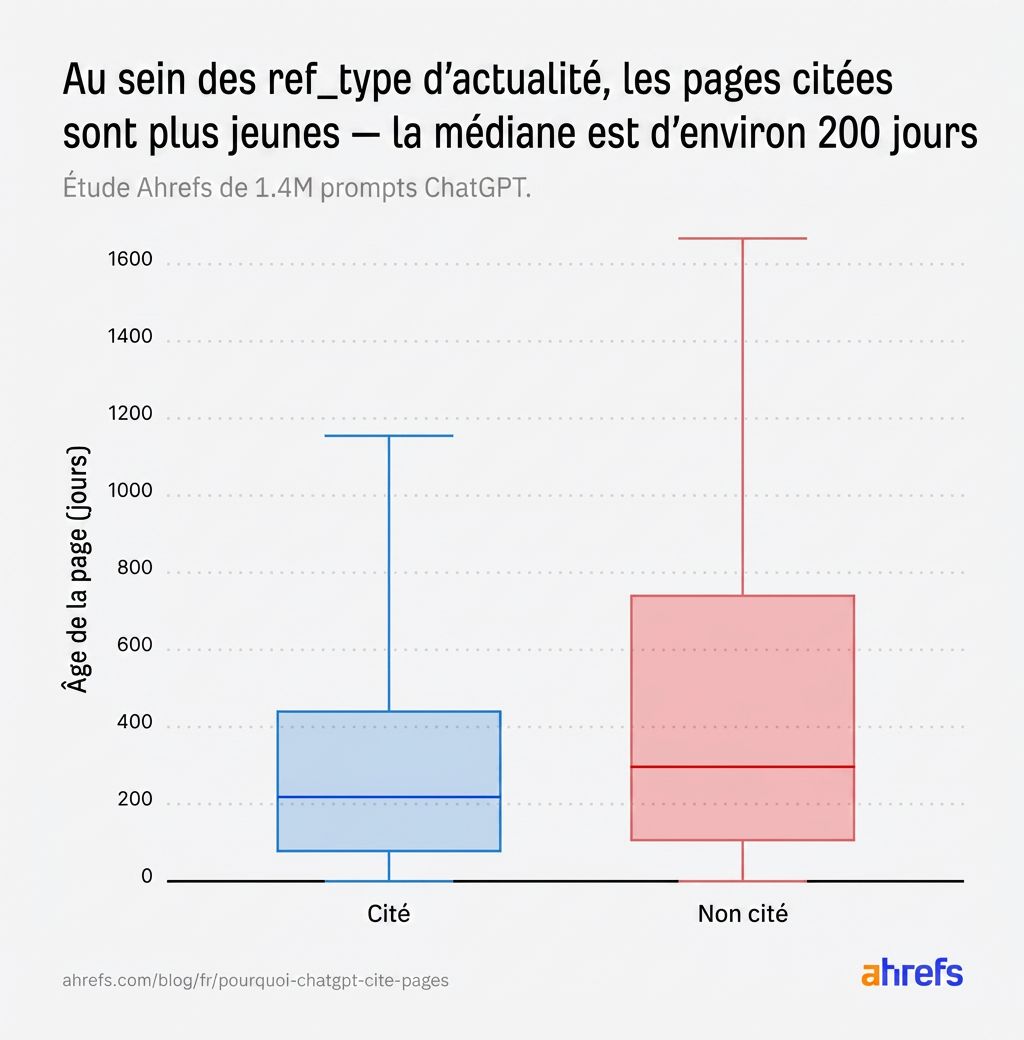
Pour les requêtes d’actualité, les pages plus récentes ont un avantage clair, même quand les scores de pertinence entre pages citées et non citées sont similaires.
Soyez le premier à couvrir des actualités sur certains sujets grâce à Ahrefs Firehose, notre API de surveillance web en temps réel qui vous donne un flux continu de données issu de notre immense infrastructure de crawl.
Par exemple, si vous travaillez dans le journalisme SaaS, vous pouvez suivre les modifications de contenu sur des pages comme le blog officiel de Google, pour être le premier à couvrir une nouvelle mise à jour Google dès qu’elle est publiée.
Ensuite, utilisez l’historique des mentions dans le rapport Réponses IA de Brand Radar pour suivre si votre visibilité sur ChatGPT augmente après publication.
Les 1,4 million de prompts dressent un tableau assez clair. ChatGPT est un éditeur exigeant. Il favorise son index de recherche général, utilise la similarité sémantique pour sélectionner et citer ses sources, et traite Reddit comme un manuel dont il est gêné d’admettre la lecture.
Mais ces données nous ont aussi appris une leçon de prudence analytique.
Les comparaisons agrégées entre des URL « citées » et « non citées » peuvent induire en erreur si le pool non cité est dominé par un seul type de source avec ses propres mécaniques de récupération.
Ce qui semblait initialement être un paradoxe (des pages moins optimisées citées davantage) s’est révélé être une question de composition du jeu de données.
On aurait très mal interprété ces données si on n’avait pas isolé par ref_type.
Concrètement, les pages qui sont citées sont celles dont les titres et le contenu correspondent aux questions que ChatGPT pose en coulisses, et qui remontent via le bon canal de récupération.

