Cada capa de datos tiene sus propios pros y contras, así que si alguna vez te has preguntado por qué una IA te dijo algo incorrecto con total seguridad, por qué una herramienta parece conocer las noticias de la semana pasada y otra no, o por qué el producto de tu competidor se menciona muchísimo mientras que el tuyo no, la respuesta casi siempre se remonta a qué capa respondió a tu pregunta.
Este artículo es una explicación sencilla de dónde proviene realmente el conocimiento de la IA, y por qué eso importa para saber cuánto deberías confiar en una respuesta determinada.
Antes de que un modelo de IA responda una sola pregunta, pasa por una fase llamada entrenamiento.
Durante el entrenamiento, el modelo ingiere miles de millones de ejemplos de texto, imágenes y código (rastreos web públicos, libros, Wikipedia, repositorios de código, bases de datos con licencia) y aprende a predecir patrones en todos ellos. Para cuando termina el entrenamiento, el modelo ha memorizado de manera efectiva una instantánea estadística del conocimiento humano hasta ese momento.
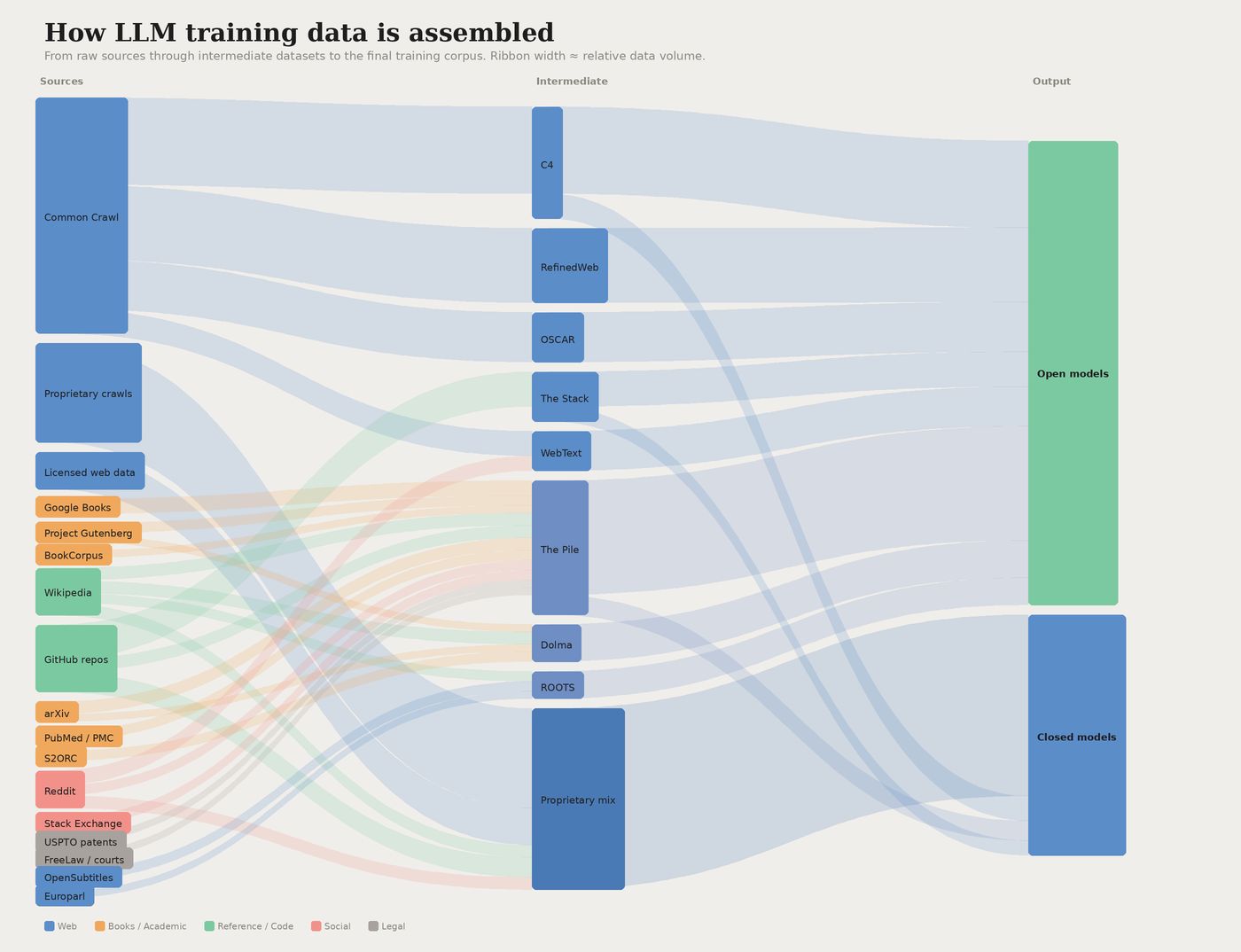
Una visualización de las fuentes de datos comunes utilizadas en el entrenamiento de grandes modelos de lenguaje.
Así es como los modelos de IA desarrollan su “comprensión” del mundo. La aparición de diferentes entidades en los datos de entrenamiento (como el nombre de tu marca o tus productos: piensa en “Patagonia” o “Nanopuff Hoody”), y las palabras con las que comúnmente coexisten (como “respetuoso con el medio ambiente” o “alta calidad”), da forma a la comprensión que tiene el modelo sobre tu marca.
Como explica Gianluca Fiorelli:
Los LLM aprenden las relaciones entre tu marca y conceptos como ‘gimnasio’ o ‘cancelación de ruido’. Estas asociaciones semánticas influyen directamente en si se te menciona y de qué manera.

La escala implicada en el entrenamiento es casi difícil de imaginar. Los datos de entrenamiento para los modelos principales se miden en billones de tokens (aproximadamente, fragmentos de palabras). Los costes te dan una idea de lo que eso requiere: entrenar GPT-4 costó unos 78 millones de dólares; Gemini Ultra de Google costó alrededor de 191 millones de dólares.
El mercado global de conjuntos de datos de entrenamiento de IA fue de 3.200 millones de dólares en 2025, y se proyecta que alcance los 16.300 millones de dólares para 2033 (una tasa de crecimiento anual del 22,6 % que refleja lo central que se han vuelto los datos para toda la empresa).
Aquí está lo más importante que debes entender: una vez que finaliza el entrenamiento, el conocimiento del modelo se congela. No puede aprender de nuevos eventos. No tiene idea de lo que pasó ayer, o el mes pasado, o después de cualquier fecha en que se cortaron sus datos de entrenamiento.
Algunos proveedores ajustan periódicamente sus modelos con datos más nuevos, pero eso sigue siendo un proceso discreto (más parecido a publicar una actualización de software que a leer las noticias de forma continua).
El otro gran fallo es la alucinación. Cuando un modelo no tiene datos de entrenamiento fiables a los que recurrir, llena el vacío con algo que suena plausible: una cita inventada, una estadística falsa o una no-respuesta confiada (como la AI Overview de Google citando un artículo satírico del Día de los Inocentes como una fuente factual).
El modelo no tenía forma de saber que el artículo era una broma; simplemente parecía lo suficientemente autoritativo como para encajar en el patrón.
La Generación Aumentada por Recuperación (RAG, por sus siglas en inglés) es la técnica principal utilizada para solucionar el problema del límite de conocimiento.
En lugar de depender puramente de lo que el modelo aprendió durante el entrenamiento, el RAG permite al modelo extraer documentos relevantes en el momento en que se hace una pregunta, para luego usar esos documentos como contexto al generar una respuesta.
Piensa en ello como la diferencia entre un examen a libro cerrado y uno a libro abierto. Un modelo basado únicamente en el entrenamiento tiene que responder de memoria. Un modelo habilitado con RAG puede buscar la información primero y luego responder. El resultado es más actual y, en principio, más verificable, porque la respuesta se fundamenta en contenido recuperado real en lugar de en la coincidencia de patrones estadísticos.
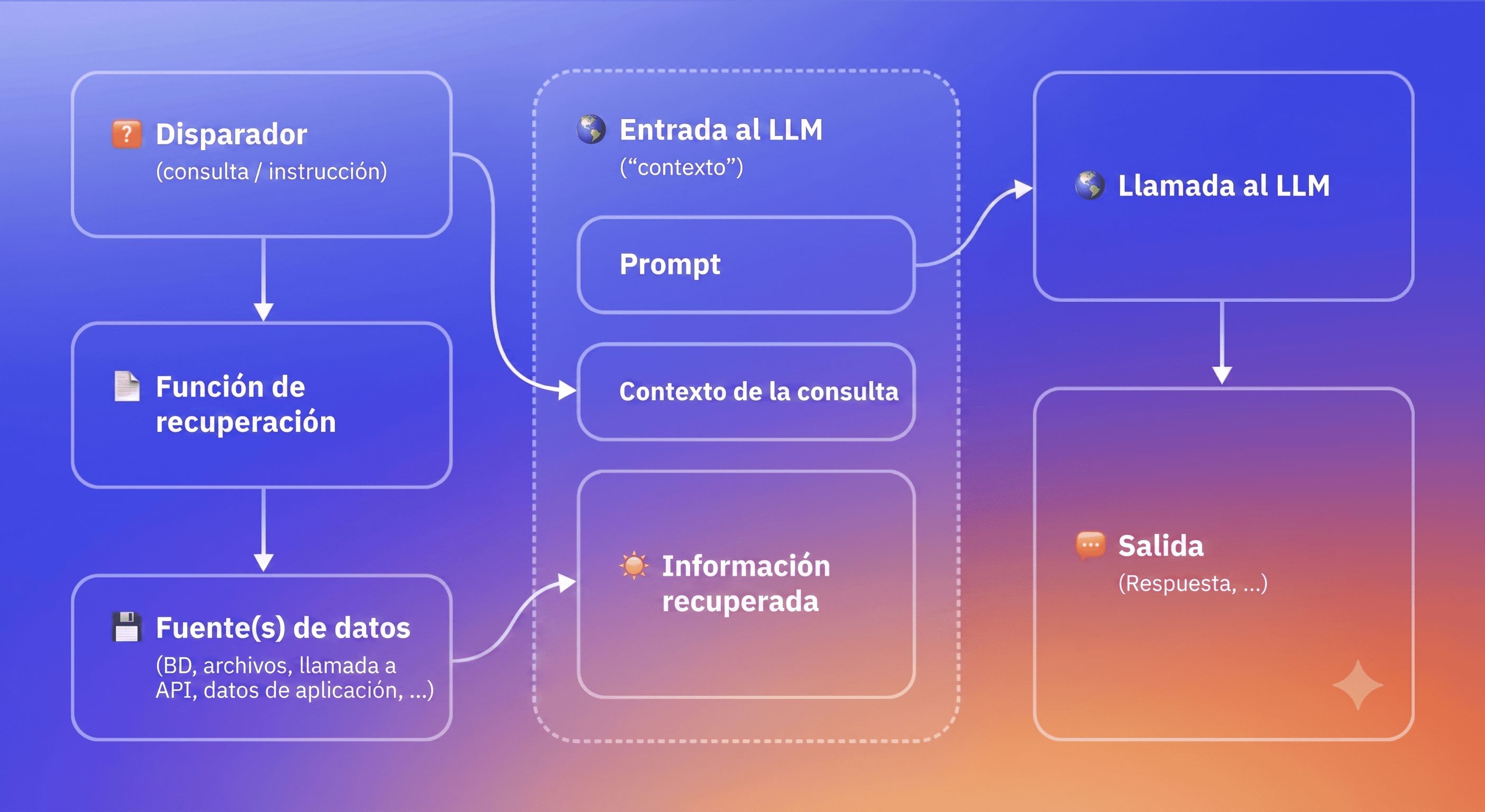
Visualización de la generación aumentada por recuperación.
“Grounding” (fundamentación) es el término más amplio para este anclaje. Cuando una respuesta de IA está fundamentada, está vinculada a fuentes recuperadas específicas, lo que reduce drásticamente el riesgo de alucinación.
Como explica Britney Muller:
El grounding proviene de la verdad fundamental, enraizada en la estadística y originalmente en la cartografía, donde literalmente significaba salir a verificar que tu mapa coincidía con la realidad.

Los motores de búsqueda de IA como ChatGPT y Gemini utilizan índices de búsqueda tradicionales como Google y Bing para este proceso de grounding. Es por eso que un buen SEO, y posicionarse alto en la búsqueda tradicional, también mejorará tu visibilidad en la IA. Cuanto más alto aparezcas en el índice de búsqueda para el término que busca la IA, mayor será tu probabilidad de ser recuperado y citado en la respuesta.
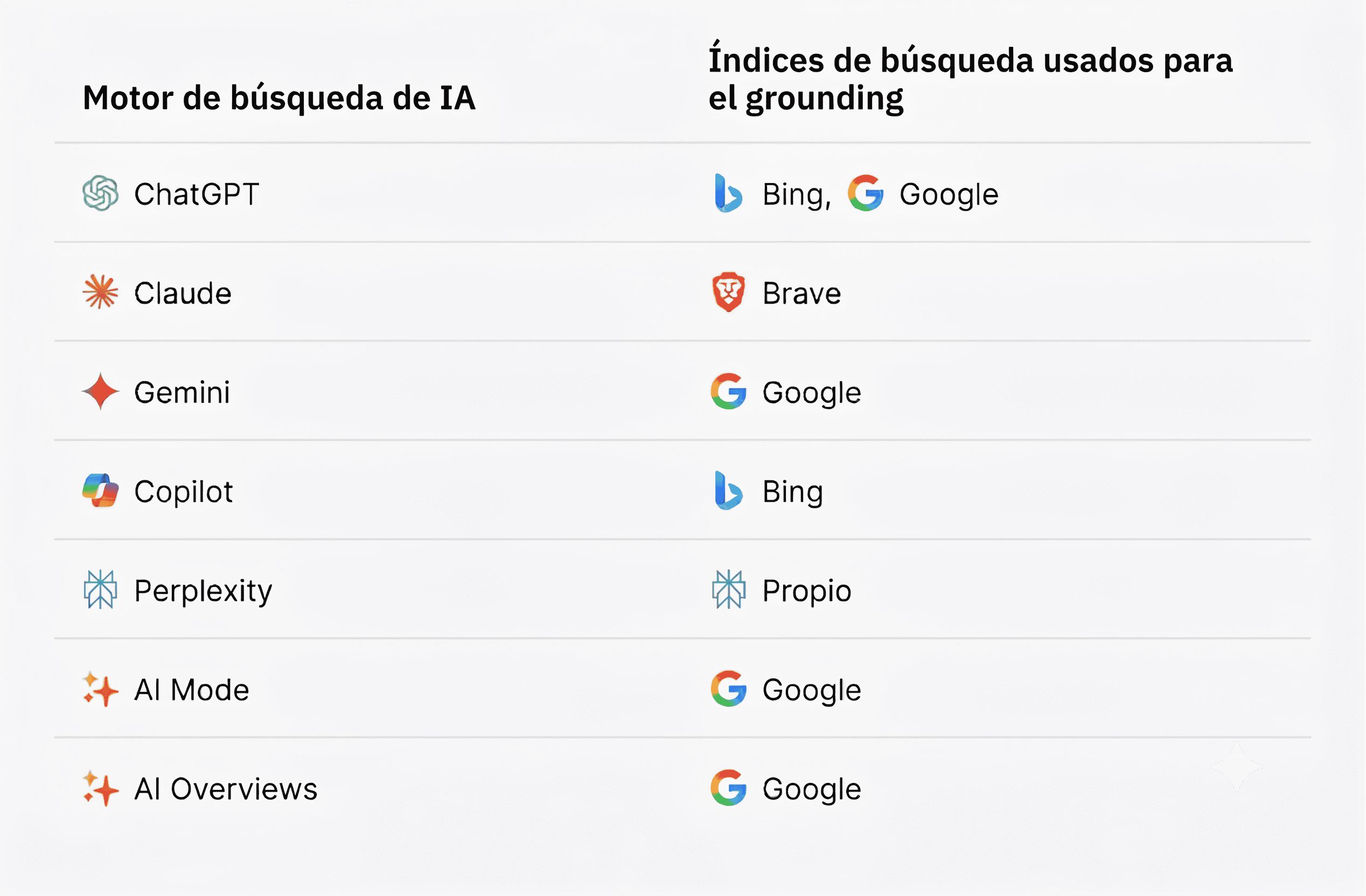
No todos los productos de IA utilizan RAG. Una sesión básica de ChatGPT con la navegación desactivada, por ejemplo, se basa puramente en el entrenamiento: no tiene acceso a información actual y no tiene forma de verificar sus respuestas con fuentes en tiempo real.
La compensación es velocidad y simplicidad. Las respuestas basadas únicamente en el entrenamiento son rápidas, pero están permanentemente desactualizadas. El RAG añade latencia e introduce un nuevo modo de fallo (errores de recuperación: extraer la fuente equivocada o una de mala calidad), pero hace posible la actualidad.
El RAG es una forma de obtener información fresca en una respuesta de IA. Pero los sistemas de IA modernos van cada vez más lejos, dando a los modelos la capacidad de llamar a herramientas externas a mitad de la conversación. Este es el territorio de los agentes de IA.
Un agente de IA no solo recupera documentos; puede consultar API, realizar búsquedas, ejecutar código e interactuar con fuentes de datos en tiempo real como parte del desarrollo de una tarea.
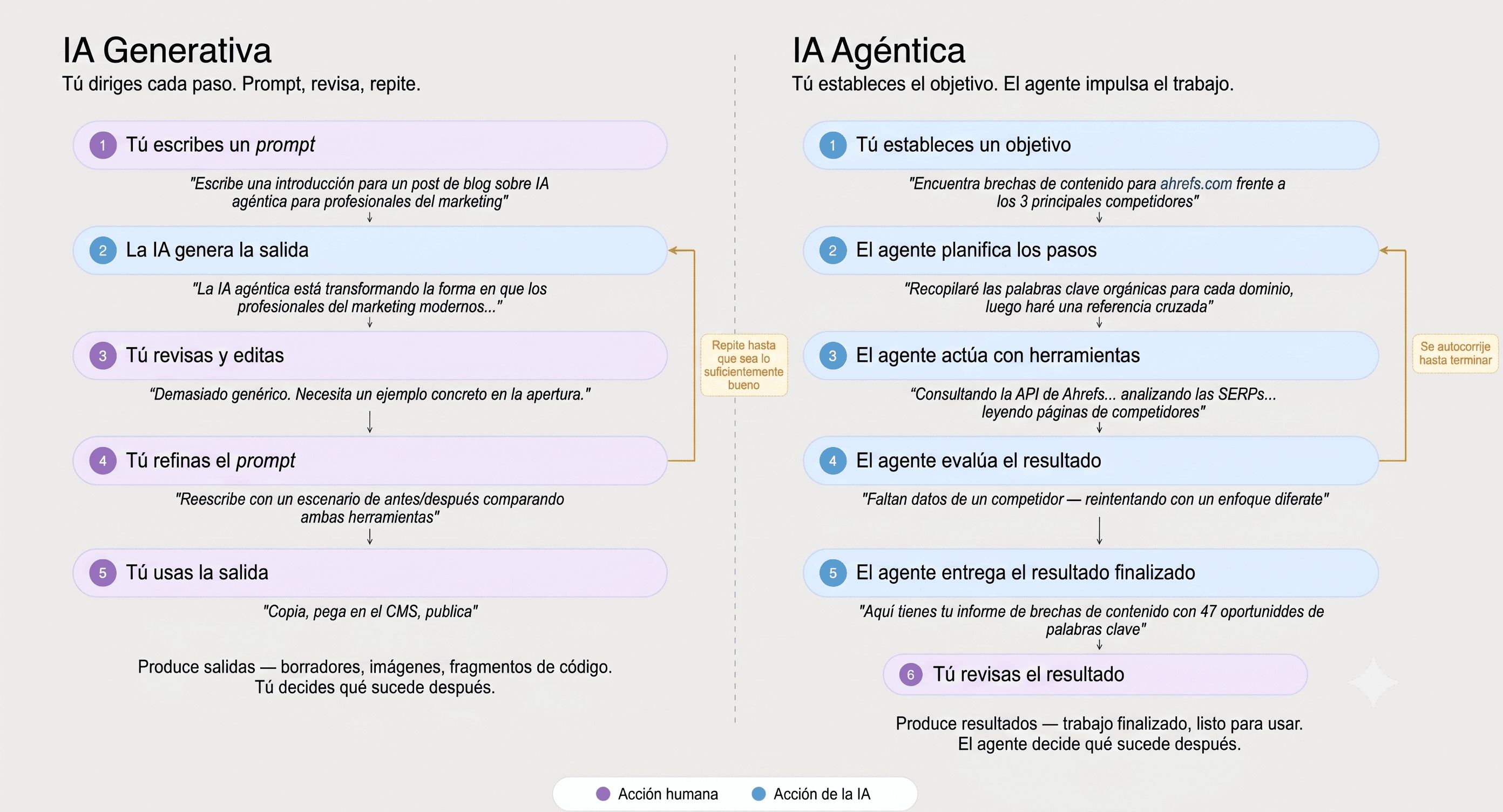
Una comparativa del uso de IA generativa frente a IA agéntica.
La infraestructura emergente para esto se llama Model Context Protocol (MCP), un estándar que permite a los modelos de IA conectarse a fuentes de datos externas de manera estructurada.
Un ejemplo concreto: Ahrefs tiene una integración con el MCP de Ahrefs que permite a los agentes de IA consultar los datos de Ahrefs directamente durante una tarea, extrayendo métricas de palabras clave, datos de enlaces o información competitiva sin que el usuario abandone su flujo de trabajo.
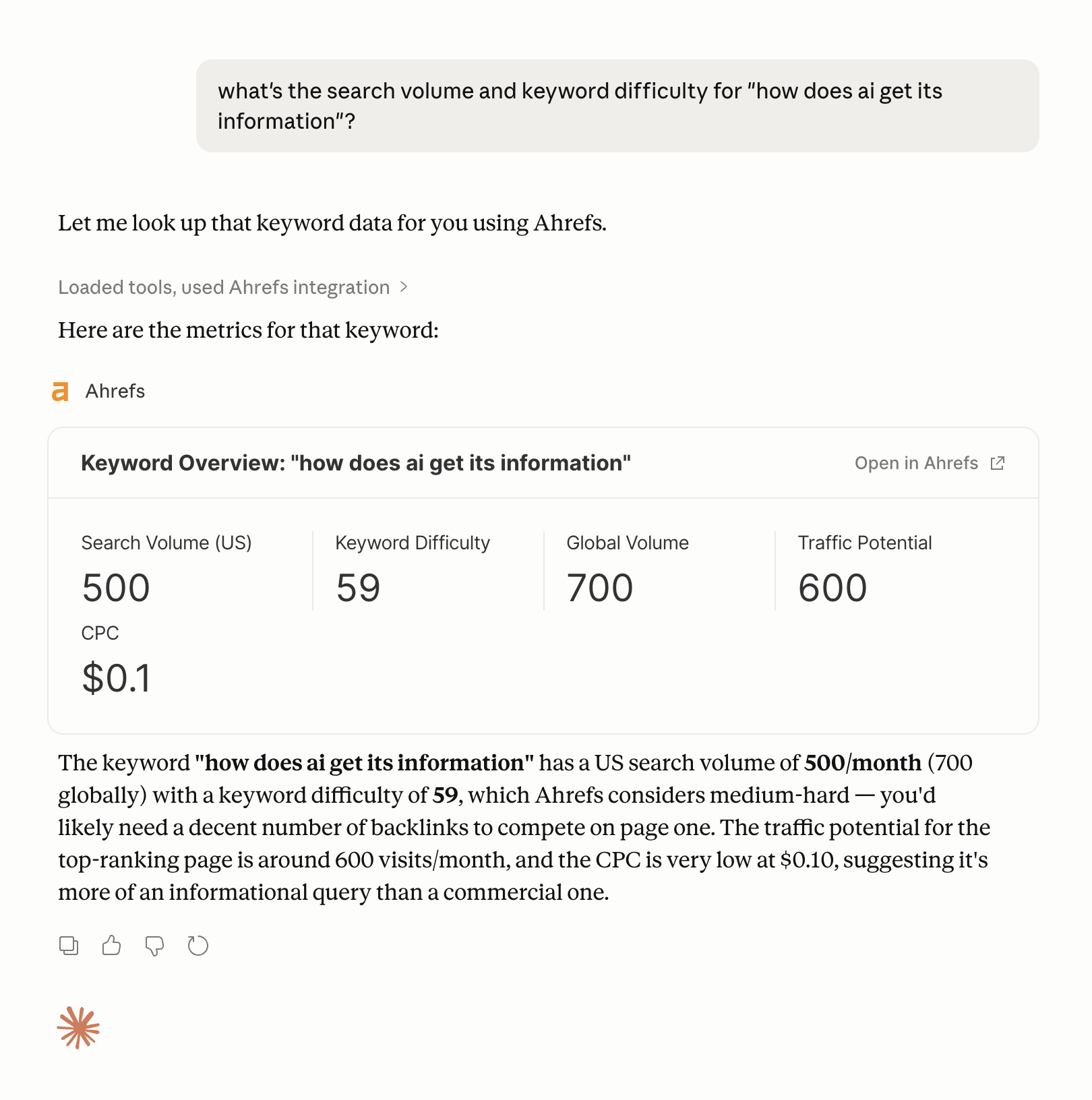
Un ejemplo de obtención de datos de palabras clave usando el MCP de Ahrefs en Claude.
Agent A de Ahrefs lleva esto más allá. Es una IA de marketing con acceso directo e ilimitado a todo el conjunto de datos internos de Ahrefs: datos de palabras clave, métricas del sitio, inteligencia competitiva, todo.
En lugar de una IA que tiene que aproximar los insights de SEO a partir de datos de entrenamiento (que se vuelven obsoletos) o recuperarlos de fuentes públicas (que están incompletas), Agent A trabaja con los datos reales.
Para tareas de marketing y SEO específicamente, esa es una gran diferencia: Agent A puede abordar muchos flujos de trabajo de SEO y marketing, sin necesidad de que le lleves de la mano.
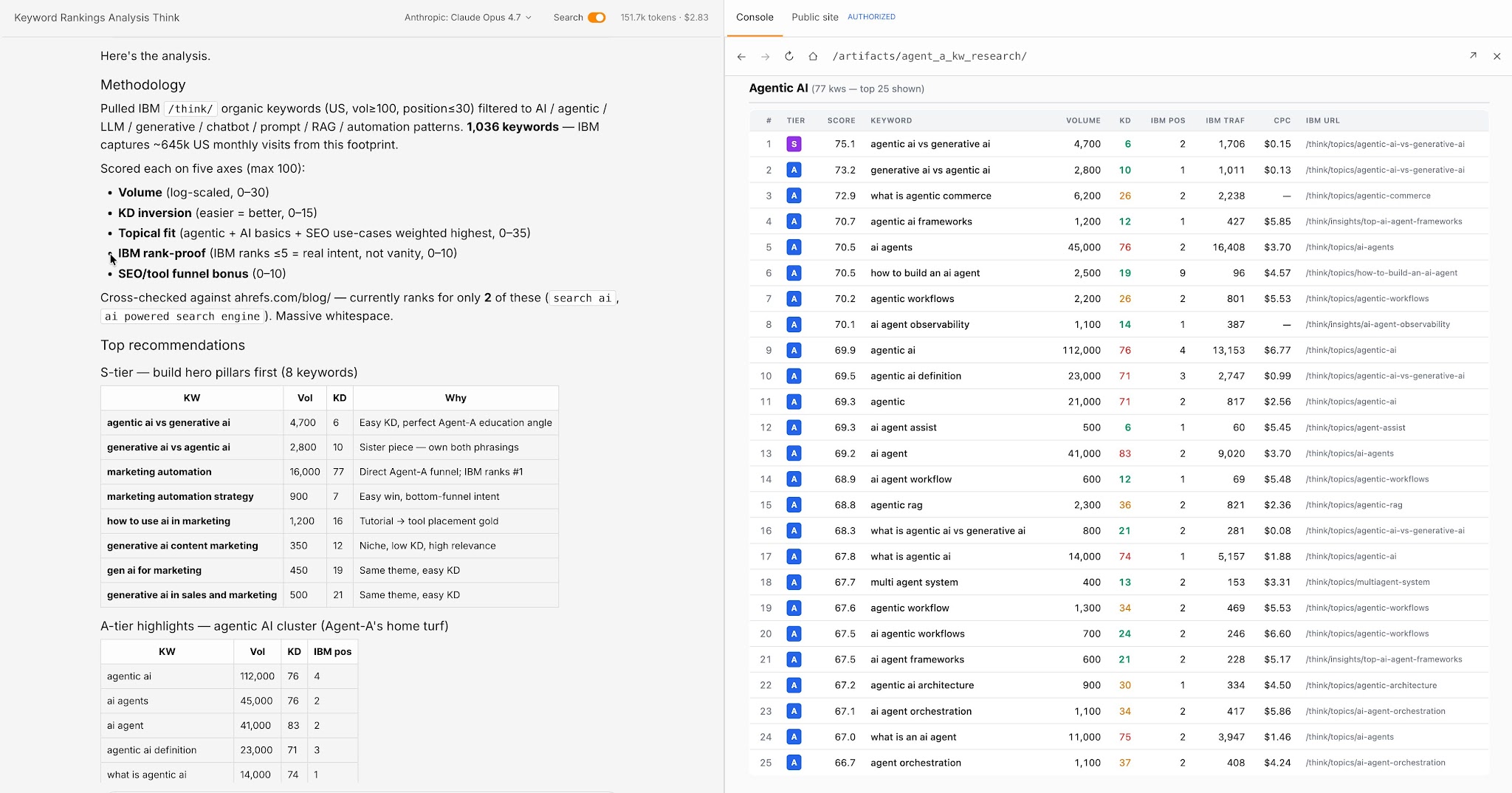
El principio más amplio es que la IA aumentada por herramientas es tan fiable como las herramientas a las que llama. Si la API devuelve datos erróneos, la IA produce una respuesta errónea, con total seguridad. La inteligencia del modelo no te salva de entradas basura. Lo que sí hace es ampliar el alcance del modelo mucho más allá de lo que cualquier conjunto de datos de entrenamiento podría cubrir.
Cuando entiendes de dónde obtiene la IA su información, entiendes dónde necesita aparecer tu marca para tener la mejor oportunidad de ser citada:
- Menciones fuera del sitio. Si quieres que la IA represente tu marca de forma precisa, el punto de partida no es tu sitio web, son las menciones fuera del sitio. Los modelos aprenden sobre las marcas de las fuentes en las que fueron entrenados: cobertura de prensa, reseñas de terceros, discusiones en foros, entradas de Wikipedia y citas en publicaciones autorizadas. Una marca que solo existe en su propio dominio es en gran medida invisible para los datos de entrenamiento del modelo.
- Query fan-out. Más allá del reconocimiento de marca, necesitas pensar en el query fan-out, las preguntas adyacentes que los sistemas de IA generan en torno a un tema central. Una marca que posiciona para “software de gestión de proyectos” también debería apuntar a contenido como “cómo hacer una revisión de sprint” o “metodología ágil frente a cascada”, porque esas son las preguntas que un sistema de IA mostrará cuando un usuario haga un seguimiento de la consulta inicial. Crear contenido que cubra todo el vecindario semántico alrededor de tus temas principales aumenta las posibilidades de que aparezcas en esa expansión.
- Accesibilidad para la IA. La accesibilidad técnica también sigue siendo importante. Un HTML limpio, tiempos de carga rápidos y un archivo robots.txt bien configurado afectan si los rastreadores de IA pueden leer tu contenido o no. llms.txt es un estándar propuesto para ayudar a los LLM a navegar por la estructura de tu sitio, pero a partir de 2026 ningún proveedor importante de LLM ha confirmado que lo respeten (así que no pierdas tu tiempo).
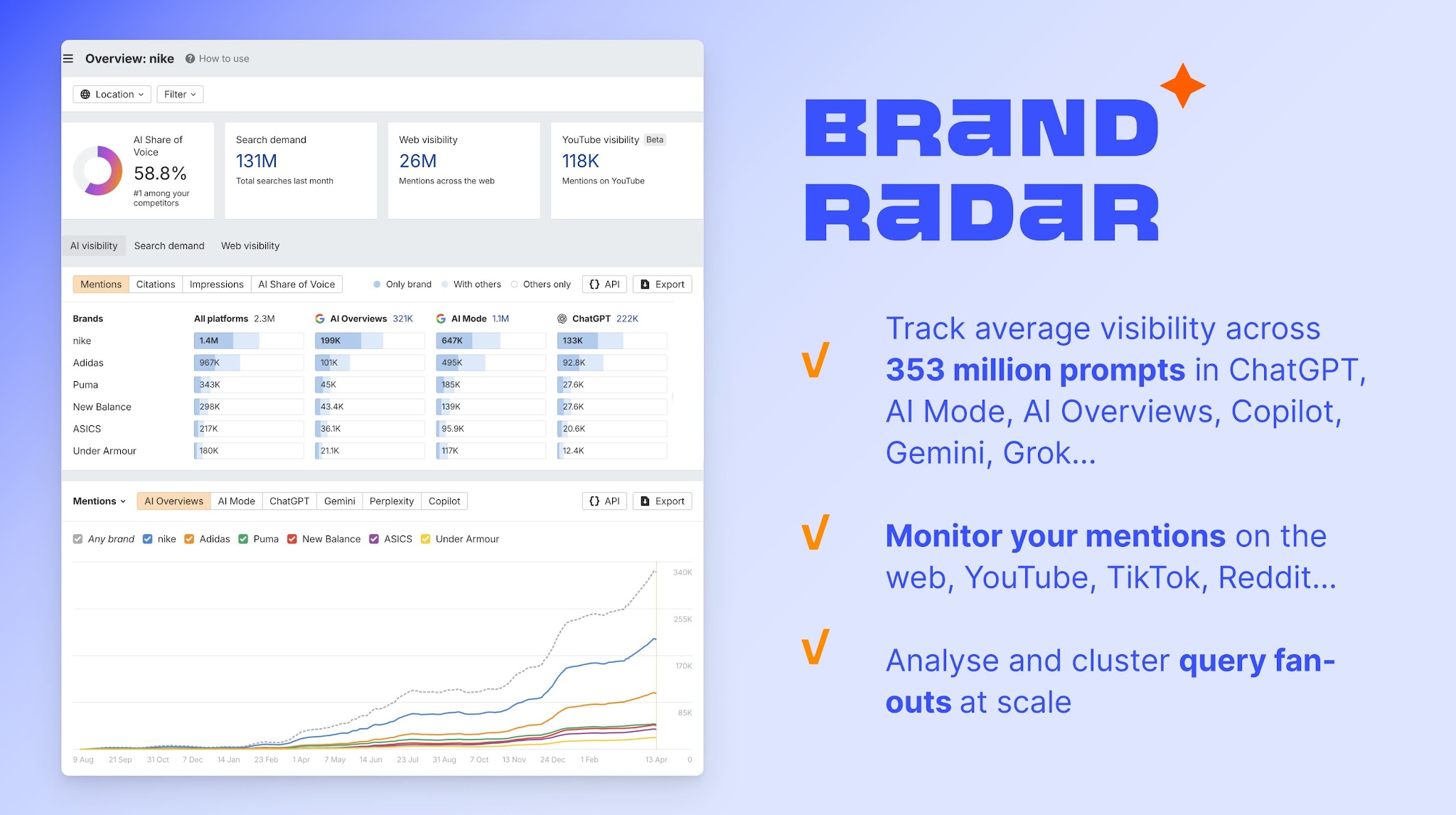
Para medir cómo funciona esto en la práctica, Brand Radar de Ahrefs rastrea la cuota de voz en IA en ChatGPT, Gemini, Perplexity, las AI Overviews, el modelo de IA Grok y muchos más, mostrando con qué frecuencia se menciona tu marca en las respuestas generadas por IA en relación con los competidores. Lee este artículo para aprender cómo funciona.
Reflexiones finales
El conocimiento de la IA proviene de tres capas: datos de entrenamiento congelados, documentos recuperados en tiempo real y herramientas externas conectadas, como las API y los MCP. Cada una tiene un perfil de precisión diferente, una relación distinta con la actualidad y una forma diferente de fallar.
Los datos de entrenamiento son la base (amplia, costosa y estática). El RAG y el grounding añaden actualidad a costa de la fiabilidad en la recuperación. Las integraciones de herramientas como el MCP de Ahrefs y agentes creados con un propósito específico como Agent A lo amplían aún más, dando a la IA acceso a datos autoritativos en tiempo real en el momento en que se necesitan.
Para un vistazo más profundo a cómo los motores de búsqueda de IA unen estas capas para generar respuestas, echa un vistazo a nuestra guía sobre cómo funcionan los motores de búsqueda de IA.
¿Tienes preguntas? Estamos en LinkedIn y en X.


