Here’s how they work and when to use them.
A canonical tag (rel=“canonical”) is a snippet of HTML code that tells search engines which page version is the main one when there are similar or duplicate URLs. This helps ensure only the main version is indexed.
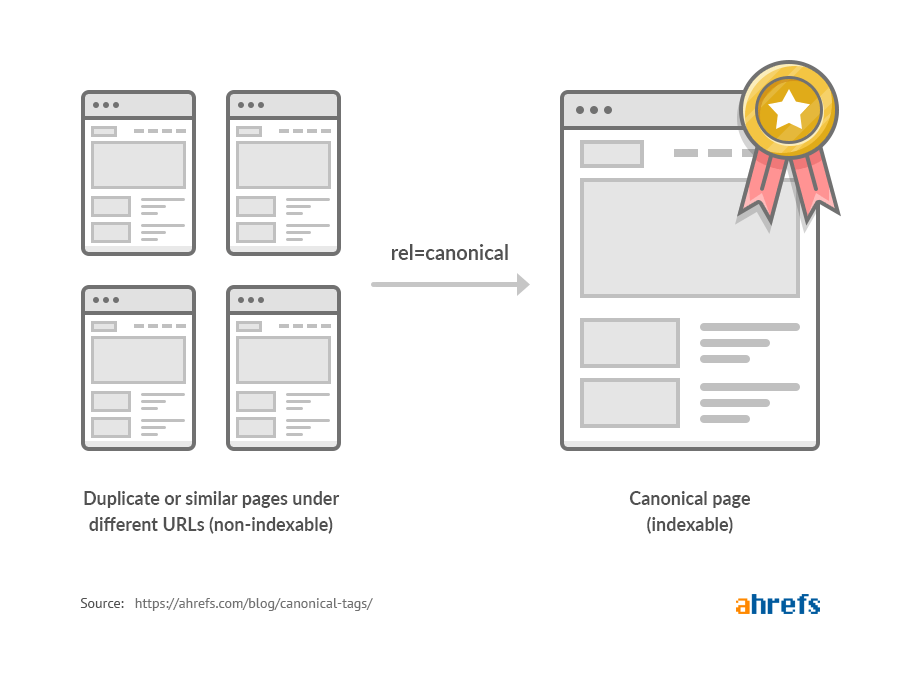
Here’s an example canonical tag:
<link rel="canonical" href="https://example.com/" />The URL you specify is the master version of the page that you want indexed.
You should use canonical tags whenever you have the same or similar content available at multiple URLs.
Here are just a few of many reasons why this can happen:
- You have duplicate content at URLs with and without trailing slashes (e.g. example.com/ and example.com)
- You have duplicate content at desktop and mobile versions of pages (e.g., example.com and m.example.com)
- You have duplicate content at parameterized versions of URLs (e.g., example.com and example?tracking-code)
For example, say you have an ecommerce store selling widgets. You might have a category page listing all your blue widgets at this URL: example.com/widgets/blue/. But the exact same content might be accessible at an ugly URL like this when visitors apply product filters: example.com/widgets?color=blue
Unless you specify the canonical, the “wrong” version of the URL might get indexed and appear in search results.
Canonical tags also help ensure that ranking signals like links consolidate to one page. This is important because links are a confirmed Google ranking factor, and there’s a strong correlation between links and traffic.
Too much duplicate content can also burn “crawl budget,” which is where Google wastes its resources crawling duplicate versions of content instead of new pages you actually want indexed. Sure, it will probably figure out eventually that it shouldn’t crawl pages regularly, but it has to crawl them initially to before it can do that—which is what wastes crawl budget.
You can do this manually by adding <link rel="canonical" href="https://example.com"/> to the <head> section of your page’s code, but hardly anyone does that because it’s too much hassle. It’s usually way easier to do it through your website platform.
However you choose to do it, make sure to follow these golden rules:
- Use absolute URLs. Google says not to use relative URLs (e.g.,
/sample-page/), even though they’re supported. This means you should specify full absolute URLs in canonical tags (e.g.,https://example.com/sample-page/). - Use the correct domain. If you switched over to SSL (you should have by now!), make sure that you don’t declare any non-SSL (i.e., HTTP) URLs in your canonical tags. Doing so can lead to confusion on Google’s part and unexpected results.
- Specify only one canonical per page. Google will ignore all declared canonicals if you declare more than one.
Let’s take a look at the process for a few popular platforms.
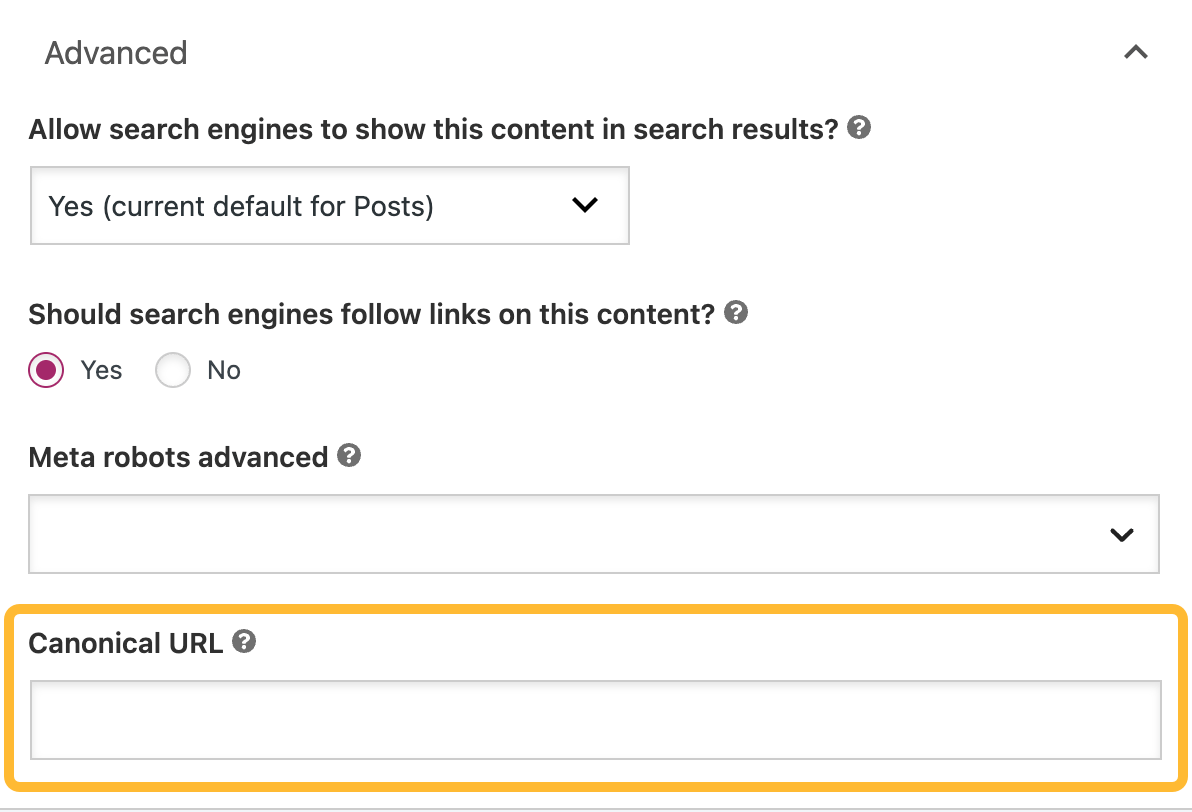
Setting canonical tags in WordPress
Install Yoast SEO, then scroll to the “Advanced” section on a page or post where you’ll see an option to specify a canonical.
Setting canonical tags in Wix
Follow their step-by-step guide. It’s a bit convoluted compared to WordPress, but it’s still possible.
Setting canonical tags in Shopify
Shopify handles canonicalization fairly well out of the box. Does that mean it’s always perfect? No. But most small and medium sized stores probably won’t need to add canonical tags manually. I’d recommend getting a developer’s help if you need to, as you’ll need to edit your theme’s code (.liquid files) directly.
Setting canonical tags in Squarespace
Go to the advanced settings of your page and you can inject canonical tags into the header.

Canonical tags are not the only way to declare a page’s canonical. You can use three other methods:
- Redirect
- rel=“canonical” in HTTP header
- Sitemap
Redirects
Google says to use this only when deprecating a duplicate page because it redirects Googlebot (and visitors) to a different URL. This is a particularly useful option for duplicate content caused by both HTTP and HTTPS pages being accessible.
rel=“canonical” in HTTP header
For documents like PDFs, there’s no way to place canonical tags in the page header because there is no page <head> section. In such cases, you’ll need to use HTTP headers to set canonicals.
Here’s what that might look like for a PDF version of this blog post:
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <https://ahrefs.com/blog/canonical-tags/>; rel="canonical"
You can also use a canonical in HTTP headers on standard webpages.
Sitemap
Only canonical URLs should be listed in your sitemap, although Google says that doing so is a weak canonicalization signal.
Canonicalization can be complex. Because of this, there are a lot of misunderstandings and misconceptions about how to canonicalize properly.
Mistake #1: Blocking the canonicalized URL via robots.txt
Blocking a URL in robots.txt prevents Google from crawling it, meaning that it’s unable to see any canonical tags on that page. That, in turn, prevents it from transferring any “link equity” from the non-canonical to the canonical.
Mistake #2: Setting the canonicalized URL to noindex
Never mix noindex and rel=canonical. They’re contradictory instructions.
John Mueller said on Reddit that Google will generally prioritize the canonical tag over the noindex tag, but it’s not a guarantee. Google’s official documentation says that noindex will completely remove the page from search. That may be the desired end result, but other canonicalization methods should have the same effect without the potential downsides (e.g., Google not being able to consolidate “link equity”).
Mistake #3: Setting a 4XX HTTP status code for the canonicalized URL
Setting a 4XX HTTP status code for a canonicalized URL has the same effect as using the noindex tag: Google will be unable to see the canonical tag and, therefore, can’t transfer “link equity” to the canonical version.
Mistake #4: Canonicalizing all paginated pages to the root page
Google says not to canonicalize paginated pages to the first in the series.
Mistake #5: Not using canonical tags with hreflang
Hreflang tags are used to specify the language and geographical targeting of a webpage.
Google states that when using hreflang, you should “specify a canonical page in the same language, or the best possible substitute language if a canonical doesn’t exist for the same language.”
Mistake #6: Having multiple rel=canonical tags
Having multiple rel=canonical tags will cause them to likely be ignored by Google. In many cases this happens because tags are inserted into a system at different points such as by the CMS, the theme, and plugin(s). This is why many plugins have an overwrite option meant to make sure that they are the only source for canonical tags.
Another area where this might be a problem is with canonicals added with JavaScript. If you have no canonical URL specified in the HTML response and then add a rel=canonical tag with JavaScript then it should be respected when Google renders the page. However, if you have a canonical specified in HTML and swap the preferred version with JavaScript, you are sending mixed signals to Google.
Mistake #7: Rel=canonical in the <body>
Rel=canonical should only appear in the <head> of a document. A canonical tag in the <body> section of a page will be ignored.
Where this can become a problem is with the parsing of a document. While the source code of a page may have the rel=canonical tag in the correct location, when the page is actually constructed in a browser or rendered by a search engine, many different things such as unclosed tags, JavaScript injected, or <iframes> in the <head> section can cause the <head> to end prematurely while rendering. In these cases a canonical tag may be accidentally thrown into the <body> of a rendered page where it will not be respected.
It’s easy to make mistakes with canonicalization, so it pays to regularly audit your website for issues related to canonical tags and fix them ASAP.
You can do this with Ahrefs’ Site Audit, which you can use for free with verified websites with an Ahrefs Webmaster Tools (AWT) account. It crawls your website for over 170 SEO issues, including those related to canonical tags.
Here are the 14 canonical issues Site Audit may find, and how to fix them:
1. Canonical points to 4XX
One or more pages are canonicalized to a dead (4XX) URL.
Why it’s an issue
Search engines don’t index 4XX pages because they don’t work. As a result, they’ll ignore any canonical tags pointing to such pages and often end up indexing the wrong (non-canonical) version of the page.
How to fix
Review the affected pages and replace the dead (4XX) canonical links with links to working (200) pages that you want indexed.
2. Canonical points to 5XX
One or more pages is canonicalized to a 5XX URL.
Why it’s an issue
5XX HTTP status codes indicate server issues, which result in an inaccessible canonical page. Google is unlikely to index inaccessible pages, so may ignore the canonical.
How to fix
Replace any erroneous canonical URLs with valid URLs. Check for server misconfigurations if the specified canonical seems correct. Note that this may be a temporary issue if the crawl occurred when your site was down for maintenance or your site’s server overloaded.
3. Canonical points to redirect
One or more pages is canonicalized to a redirected URL.
Why it’s an issue
Canonicals should always point to the most authoritative version of a page. This is not the case with redirecting URLs. As a result, search engines may misinterpret or ignore the canonical.
How to fix
Replace the canonical links with direct links to the most authoritative version of the page (i.e., one that returns a 200 HTTP status code and doesn’t redirect).
4. Canonical URL has no incoming internal links
One or more specified canonical URLs have no internal incoming links.
Why it’s an issue
Canonical URLs without internal links are inaccessible to website visitors. Somewhere on the site, they’re being directed to a non-canonical version of the page instead.
How to fix
Replace any internal links to canonicalized pages with direct links to the canonical.
5. Canonical URL has no incoming internal links
There are no internal links pointing to one or more declared canonical URLs.
Why it’s an issue
Because there’s no way for people browsing your website to reach the canonical URL. Internal links are also a canonicalization signal for Google.
How to fix
Check your website navigation and link architecture to make sure all canonical pages are easily accessible. You should always internally link directly to the canonical URL where possible.
6. Duplicate pages without canonical
One or more duplicate or very similar pages exist that don’t specify a canonical version.
Why it’s an issue
Because no canonical is specified, Google will attempt to identify the most appropriate version to show in search results themselves. This may not be the version you want indexed.
How to fix
Review the groups of duplicates. Pick one canonical version that should be indexed in the search results. Specify this as the canonical version across all duplicates (and add a self-referencing canonical tag to the canonical version).
7. Hreflang to non-canonical
One or more pages specify a non-canonical URL in their hreflang annotations.
Why it’s an issue
Links in hreflang tags should always point to the canonical pages. Linking to a non-canonical version of a page from hreflang annotations can confuse and mislead search engines.
How to fix
Replace links in the hreflang annotations of affected pages with their canonical.
8. Non-canonical page in sitemap
One or more non-canonical pages are listed in the sitemap.
Why it’s an issue
Google states that you shouldn’t include non-canonical URLs in your sitemap. Reason being, they see pages in sitemaps as suggested canonicals. You should only list pages that you want indexed in sitemaps.
How to fix
Remove non-canonical URLs from your sitemap.
9. Non-canonical page specified as canonical one
One or more pages specify a canonical URL which is also canonicalized to a different page. This creates a “canonical chain” where page A is canonicalized to page B, which is then canonicalized to page C.

Why it might be an issue
Canonical chains may confuse and mislead search engines. As a result, they may misinterpret or ignore the specified canonical.
How to fix
Replace non-canonical links in the canonical tags of affected pages with direct links to the canonical. For example, if page A is canonicalized to page B, which is then canonicalized to page C, replace the canonical link on page A with a link to page C.
10. Open Graph URL not matching canonical
The URL specified in og:url Open Graph tag and in rel=canonical tag is mismatched.
Why it might be an issue
It’s not an issue for Google SEO, but a non-canonical version of a page will be shared on social networks.
How to fix
Make sure the URL specified in og:url matches the URL of the canonical page.
11. Canonical from HTTPS to HTTP
One or more secure (HTTPS) pages specify a non-secure (HTTP) version as the canonical.
Why it might be worth fixing
HTTPS is a ranking factor, so it makes sense to specify secure versions of pages as canonical where possible.
How to fix
Redirect the HTTP page to the HTTPS equivalent. If that’s not possible, add a rel=“canonical” link from the HTTP version of the page to the HTTPS one.
12. Canonical from HTTP to HTTPS
One or more non-secure (HTTP) pages specify a secure (HTTPS) version as the canonical.
Why it might be worth fixing
HTTPS is preferred over HTTP. Having an HTTP version of a page then specifying the HTTPS version as canonical is illogical. This likely won’t cause a huge issue, but it’s still worth fixing if possible.
How to fix
Implement a 301 redirect from HTTP to HTTPS. You should also replace any internal links to the HTTP version of the page with links directly to the HTTPS version.
13. Canonical URL changed
The declared canonical on one or more URLs changed since the last crawl.
Why it might be worth fixing
It could point to a mistake or issue since the last crawl. Remember that the declared canonical should be the version of the page you want Google to index and rank.
How to fix
Review affected pages and ensure that the changes are intentional.
14. Non-canonical page receives organic traffic
One or more non-canonical pages show up in search results and get organic search traffic (which shouldn’t happen).
Why it might be worth fixing
Either your canonical tags are set up incorrectly or Google has chosen to ignore the specified canonical.
How to fix
Check that the rel=canonical tags are set up correctly on all reported pages. If that’s not the issue, use the URL Inspection tool in Google Search Console to see whether they consider the specified canonical URL as canonical. If there’s a mismatch, investigate why this may be the case.
Learn more about canonicalization
Read my colleague Patrick’s canonicalization guide. He goes into more detail about canonicalization signals and how to check how Google views a URL’s canonical using the URL Inspection tool in Google Search Console.
Got questions? Ping me on LinkedIn.



