
Read almost any article about LSI keywords, and you’ll be told two things:
- Google uses a technology called LSI to index web pages.
- Using LSI keywords in your content helps you rank higher on Google.
Both of these claims are technically false.
In this guide, you’ll learn why that is and what to do about it.
But first, the basics…

LSI keywords are words and phrases that Google sees as semantically-related to a topic—at least according to many in the SEO community. If you’re talking about cars, then LSI keywords might be automobile, engine, road, tires, vehicle, and automatic transmission.
But, according to Google’s John Mueller, LSI keywords don’t exist:
There’s no such thing as LSI keywords -- anyone who’s telling you otherwise is mistaken, sorry.— John (@JohnMu) July 30, 2019
So what’s the deal here?
Before we answer that question, we first need to understand a bit more about LSI itself.
Latent Semantic Indexing (LSI), or Latent Semantic Analysis (LSA), is a natural-language processing technique developed in the 1980s.
Unfortunately, unless you’re familiar with mathematical concepts like eigenvalues, vectors, and single value decomposition, the technology itself isn’t that easy to understand.
For that reason, we won’t be tackling how LSI works.
Instead, we’ll focus on the problem it was created to solve.
Here’s how the creators of LSI define this problem:
The words a searcher uses are often not the same as those by which the information sought has been indexed.
But what does this actually mean?
Say that you want to know when summer ends and fall begins. Your WiFi is down, so you go old school and grab an encyclopedia. Instead of randomly flicking through thousands of pages, you lookup “fall” in the index and flick to the right page.
Here’s what you see:

Clearly, that’s not the type of fall you wanted to learn about.
Not one to be defeated that easily, you flick back and realize that what you’re looking for is indexed under “autumn”—another name for fall.

The problem here is that “fall” is a synonym and polysemic word.
What are synonyms?
Synonyms are words or phrases that mean the same or nearly the same thing as another word or phrase.
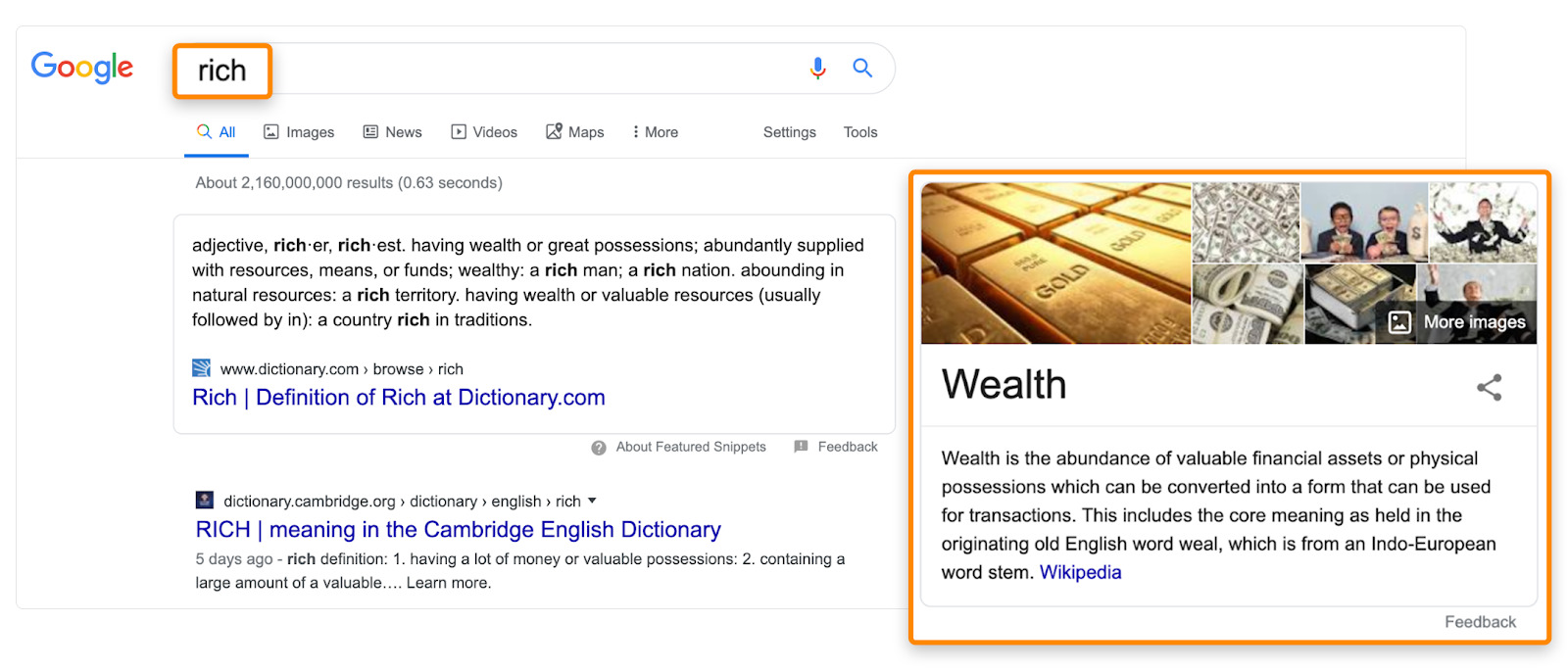
Examples include rich and wealthy, fall and autumn, and cars and automobiles.
Here’s why synonyms are problematic, according to the LSI patent:
[…] there is a tremendous diversity in the words people use to describe the same object or concept; this is called synonymy. Users in different contexts, or with different needs, knowledge or linguistic habits will describe the same information using different terms. For example, it has been demonstrated that any two people choose the same main keyword for a single, well-known object less than 20% of the time on average.
But how does this relate to search engines?
Imagine that we have two web pages about cars. Both are identical, but one substitutes all instances of the word cars for automobiles.
If we were to use a primitive search engine that only indexes the words and phrases on the page, it would only return one of these pages for the query “cars.”
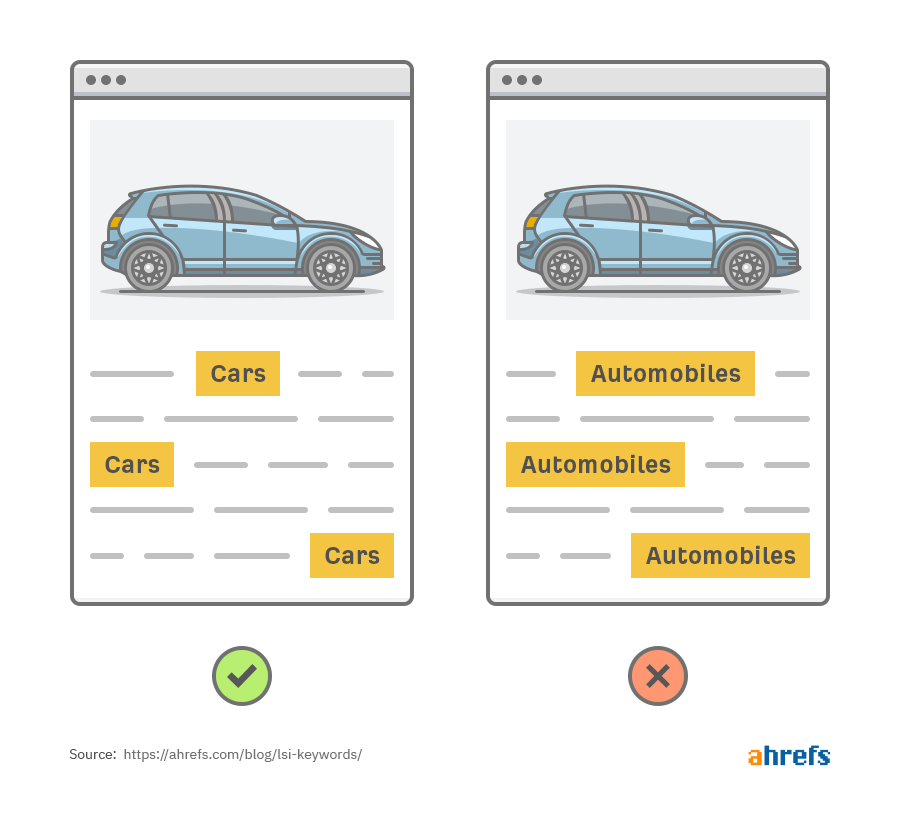
This is bad because both results are relevant; it’s just that one describes what we’re looking for in a different way. The page that uses the word automobile instead of cars might even be the better result.
Bottom line: search engines need to understand synonyms to return the best results.
What are polysemic words?
Polysemic words and phrases are those with multiple different meanings.
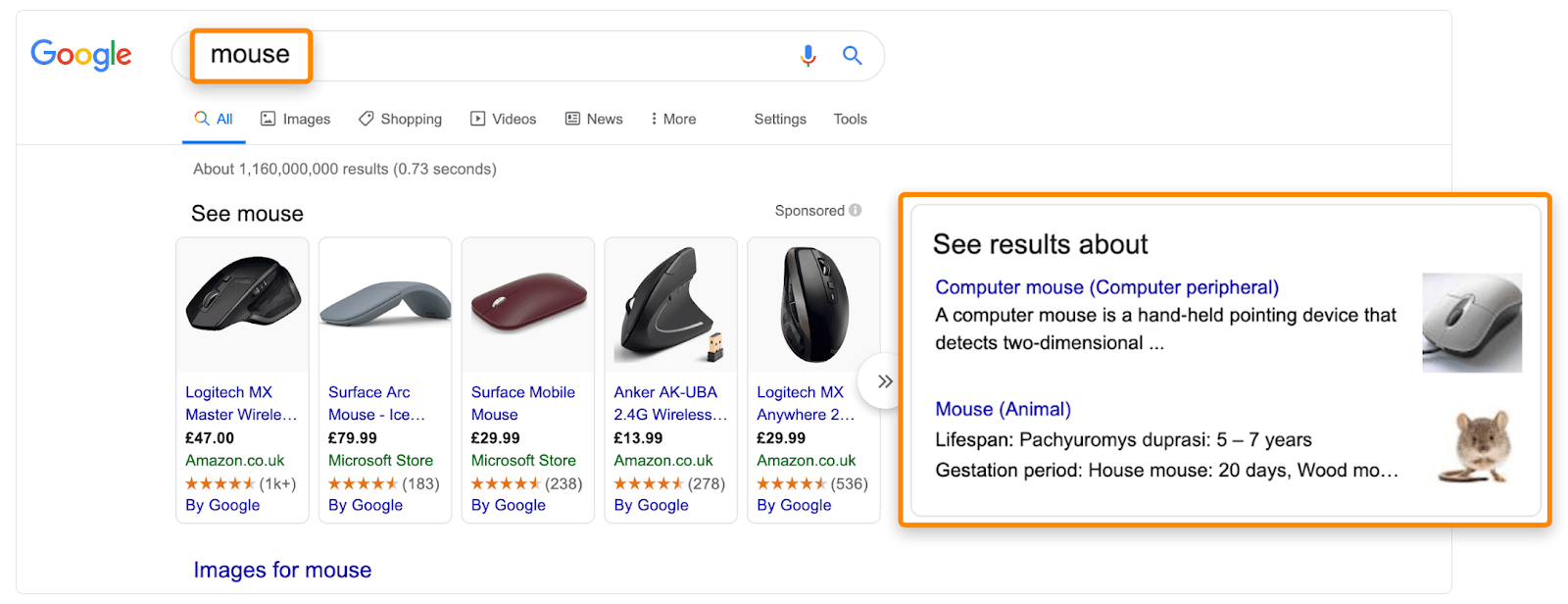
Examples include mouse (rodent / computer), bank (financial institute / riverbank), and bright (light / intelligent).
Here’s why these cause problems, according to the creators of LSI:
In different contexts or when used by different people the same word takes on varying referential significance (e.g., “bank” in river bank versus “bank” in a savings bank). Thus the use of a term in a search query does not necessarily mean that a text object containing or labeled by the same term is of interest.
These words present search engines with a similar problem to synonyms.
For example, say that we search for “apple computer.” Our primitive search engine might return both of these pages, even though one is clearly not what we’re looking for:
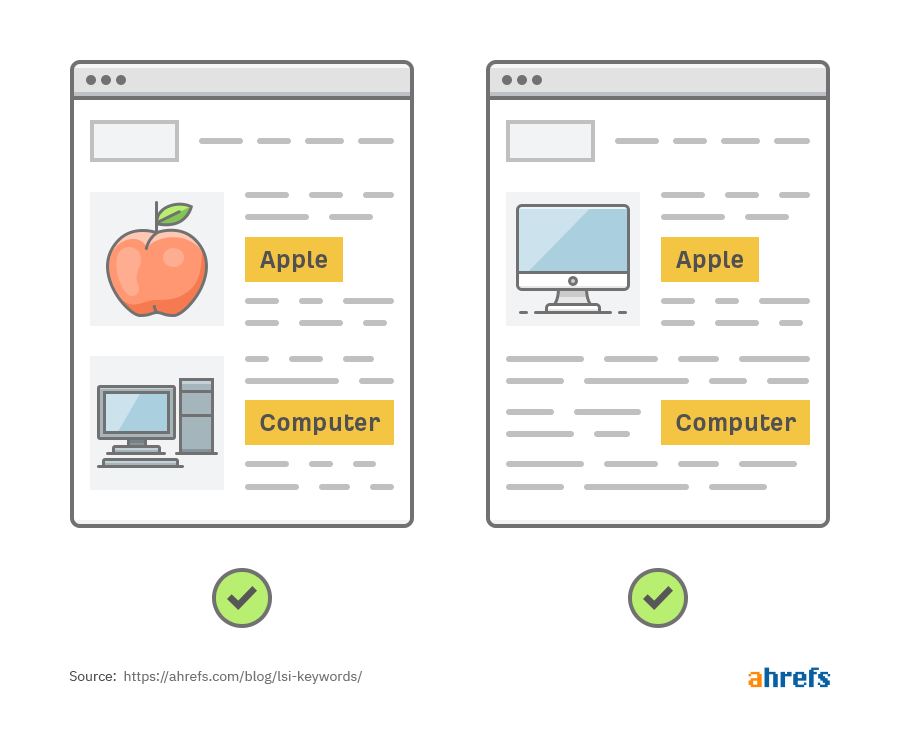
Bottom line: search engines that don’t understand the different meanings of polysemic words are likely to return irrelevant results.
Computers are dumb.
They don’t have the inherent understanding of word relationships that we humans do.
For example, everyone knows that big and large mean the same thing. And everyone knows that John Lennon was in The Beatles.
But a computer doesn’t have this knowledge without being told.
The problem is that there’s no way to tell a computer everything. It would just take too much time and effort.
LSI solves this problem by using complex mathematical formulas to derive the relationships between words and phrases from a set of documents.
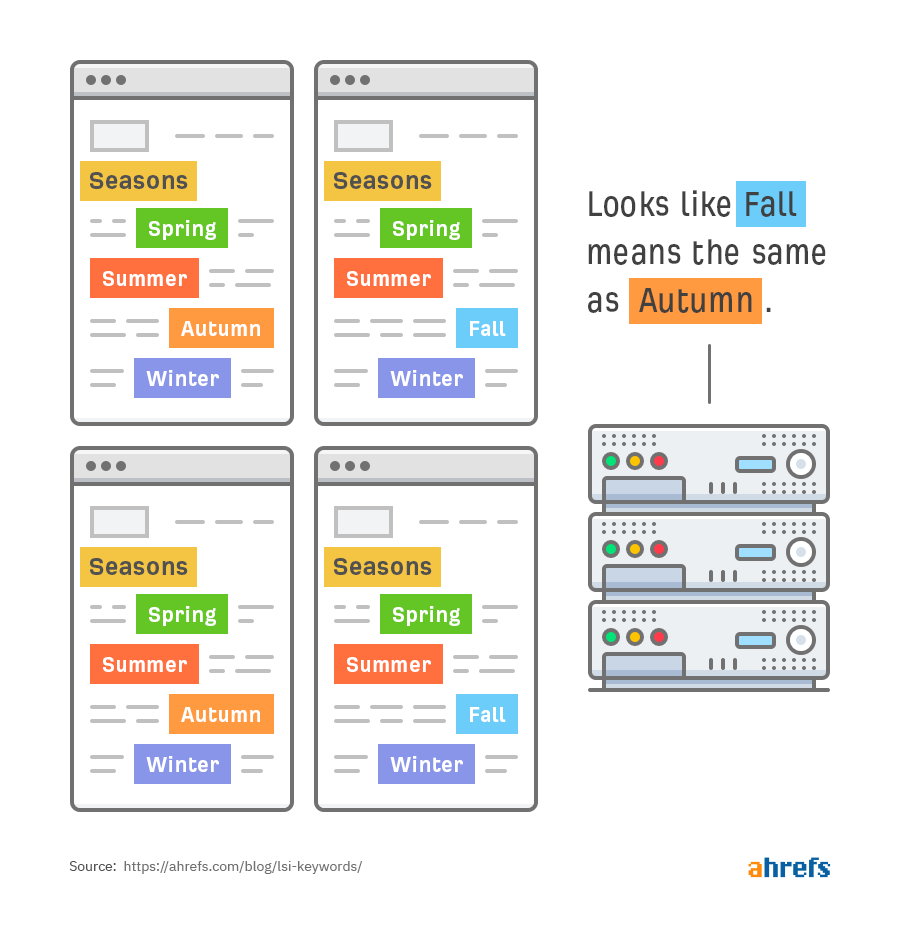
In simple terms, if we run LSA on a set of documents about seasons, the computer can likely figure out a few things:
First, the word fall is synonymous with autumn:
Second, words like season, summer, winter, fall, and spring are all semantically related:
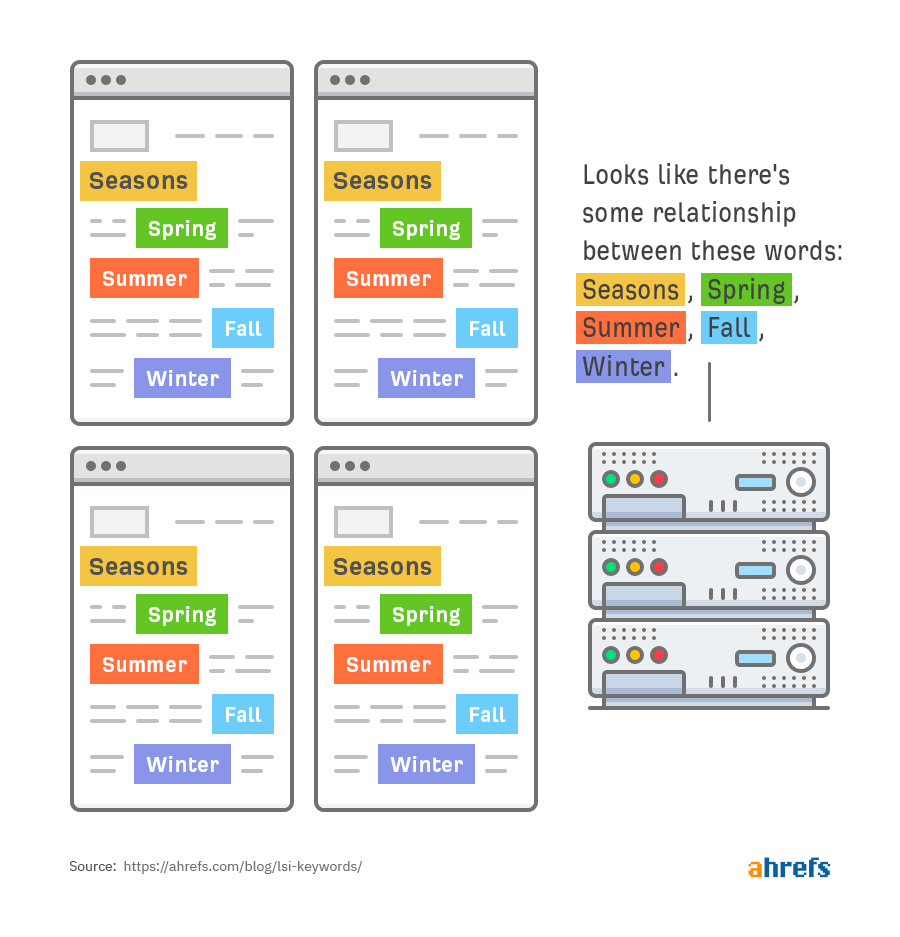
Third, fall is semantically-related to two different sets of words:
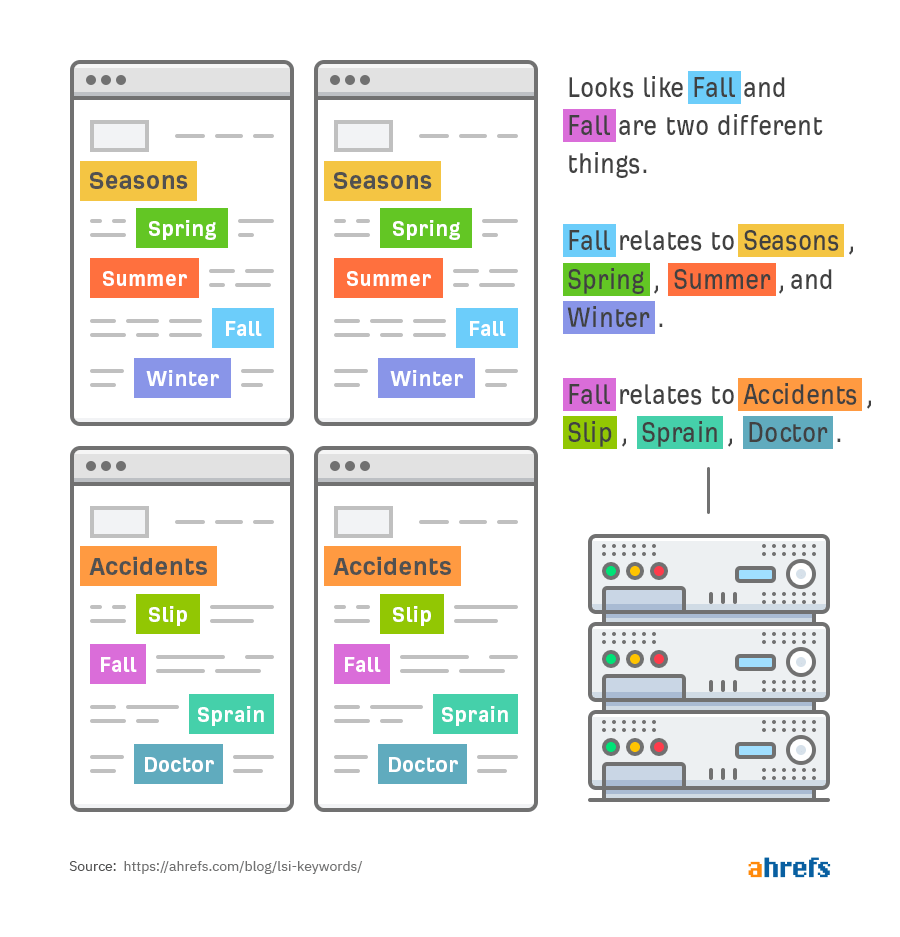
Search engines can then use this information to go beyond exact-query matching and deliver more relevant search results.
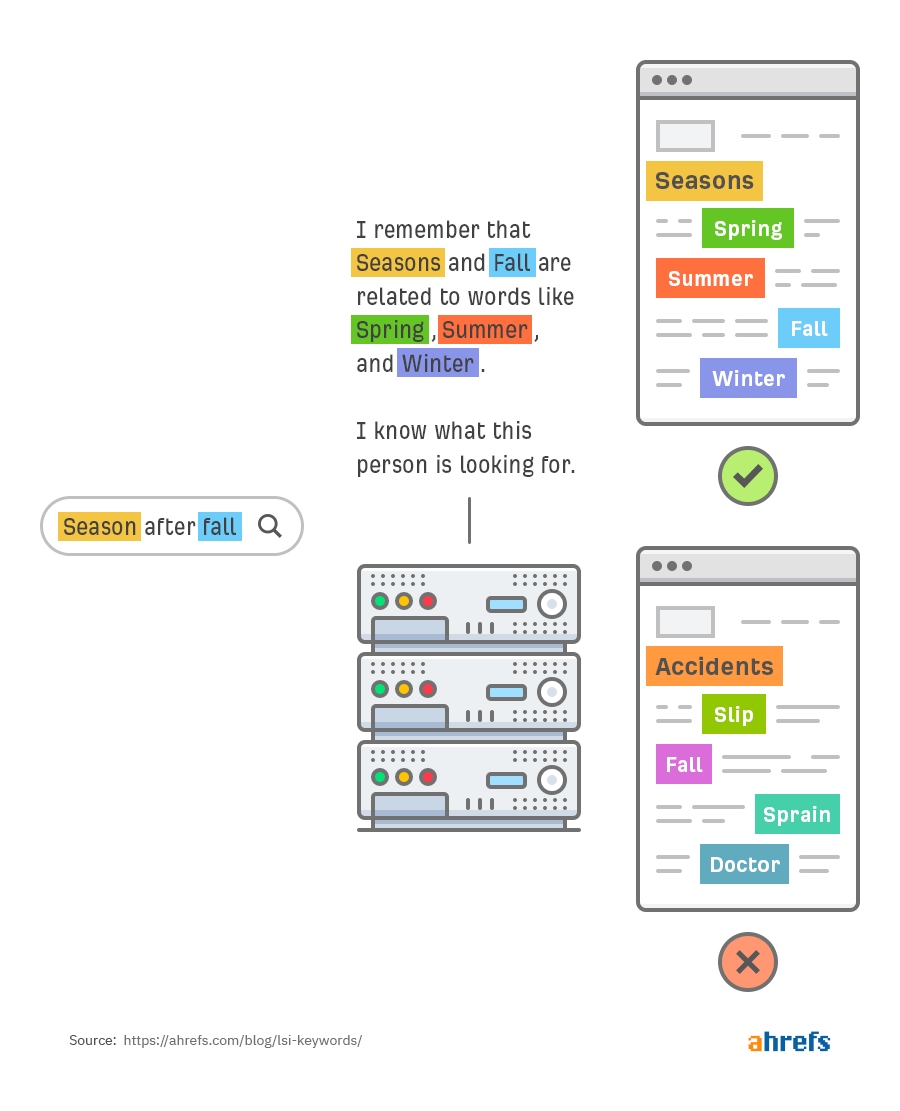
Given the problems LSI solves, it’s easy to see why people assume Google uses LSI technology. After all, it’s clear that matching exact queries is an unreliable way for search engines to return relevant documents.
Plus, we see evidence every day that Google understands synonymy:
And polysemy:
But despite this, Google almost certainly doesn’t use LSI technology.
How do we know? Google representatives say so.
Don’t believe them?
Here are three more pieces of evidence to back up this fact:
1. LSI is old technology
LSI was invented in the 1980s before the creation of the World Wide Web. As such, it was never intended to be applied to such a large set of documents.
That’s why Google has since developed better, more scalable technology to solve the same problems.
Bill Slawski puts it best:
LSI technology wasn’t created for anything the size of the Web […] Google has developed a word vector approach (used for Rankbrain) which is much more modern, scales much better, and works on the Web. Using LSI when you have Word2vec available would be like racing a Ferrari with a go-cart.
2. LSI was created to index known document collections
The World Wide Web is not only large but also dynamic.
This means that the billions of pages in Google’s index change regularly.
That’s a problem because the LSI patent tells us that the analysis needs to run “each time there is a significant update in the storage files.”
That would take a lot of processing power.
3. LSI is a patented technology
The Latent Semantic Indexing (LSI) patent was granted to Bell Communications Research, Inc. in 1989. Susan Dumais, one of the co-inventors who worked on the technology, later joined Microsoft in 1997, where she worked on search-related innovations.
That said, US patents expire after 20 years, which means that the LSI patent expired in 2008.
Given that Google was pretty good at understanding language and returning relevant results much earlier than 2008, this is yet another piece of evidence to suggest that Google doesn’t use LSI.
Once again, Bill Slawski puts it best:
Google does attempt to index synonyms and other meanings for words. But it isn’t using LSI technology to do that. Calling it LSI is misleading people. Google has been offering synonym substitutions and query refinements based upon synonyms since at least 2003, but that doesn’t mean that they are using LSI. It would be like saying that you are using a smart telegraph device to connect to the mobile web.
Most SEOs see “LSI keywords” as nothing more than related words, phrases, and entities.
If we roll with that definition—despite it being technically inaccurate—then yes, using some related words and phrases in your content can almost certainly help improve SEO.
How do we know? Google indirectly tells us so here:
Just think: when you search for ‘dogs’, you probably don’t want a page with the word ‘dogs’ on it hundreds of times. With that in mind, algorithms assess if a page contains other relevant content beyond the keyword ‘dogs’ – such as pictures of dogs, videos or even a list of breeds.
On a page about dogs, Google sees names of individual breeds as semantically related.
But why do these help pages to rank for relevant terms?
Simple: Because they help Google understand the overall topic of the page.
For example, here are two pages that each mention the word “dogs” the same number of times:
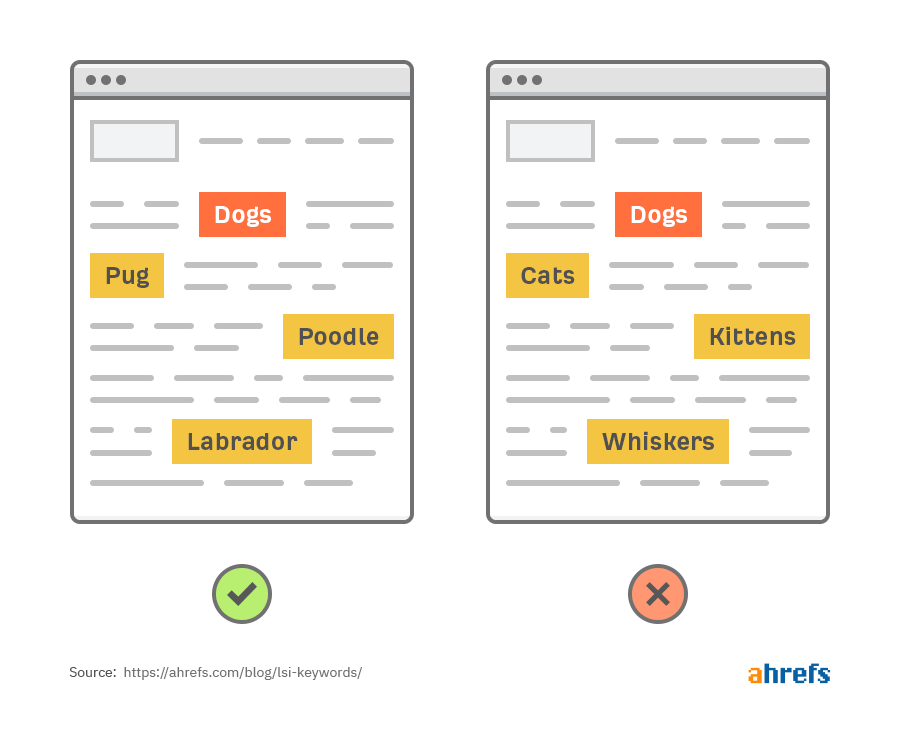
Looking at other important words and phrases on each page tells us that only the first is about dogs. The second is mostly about cats.
Google uses this information to rank relevant pages for relevant queries.
If you’re knowledgeable about a topic, you’ll naturally include related words and phrases in your content.
For example, it would be difficult to write about the best video games without mentioning words and phrases like “PS4 games,” “Call of Duty,” and “Fallout.”
But it’s easy to miss important ones—especially with more complex topics.
For instance, our guide to nofollow links fails to mention anything about the sponsored and UGC link attributes:
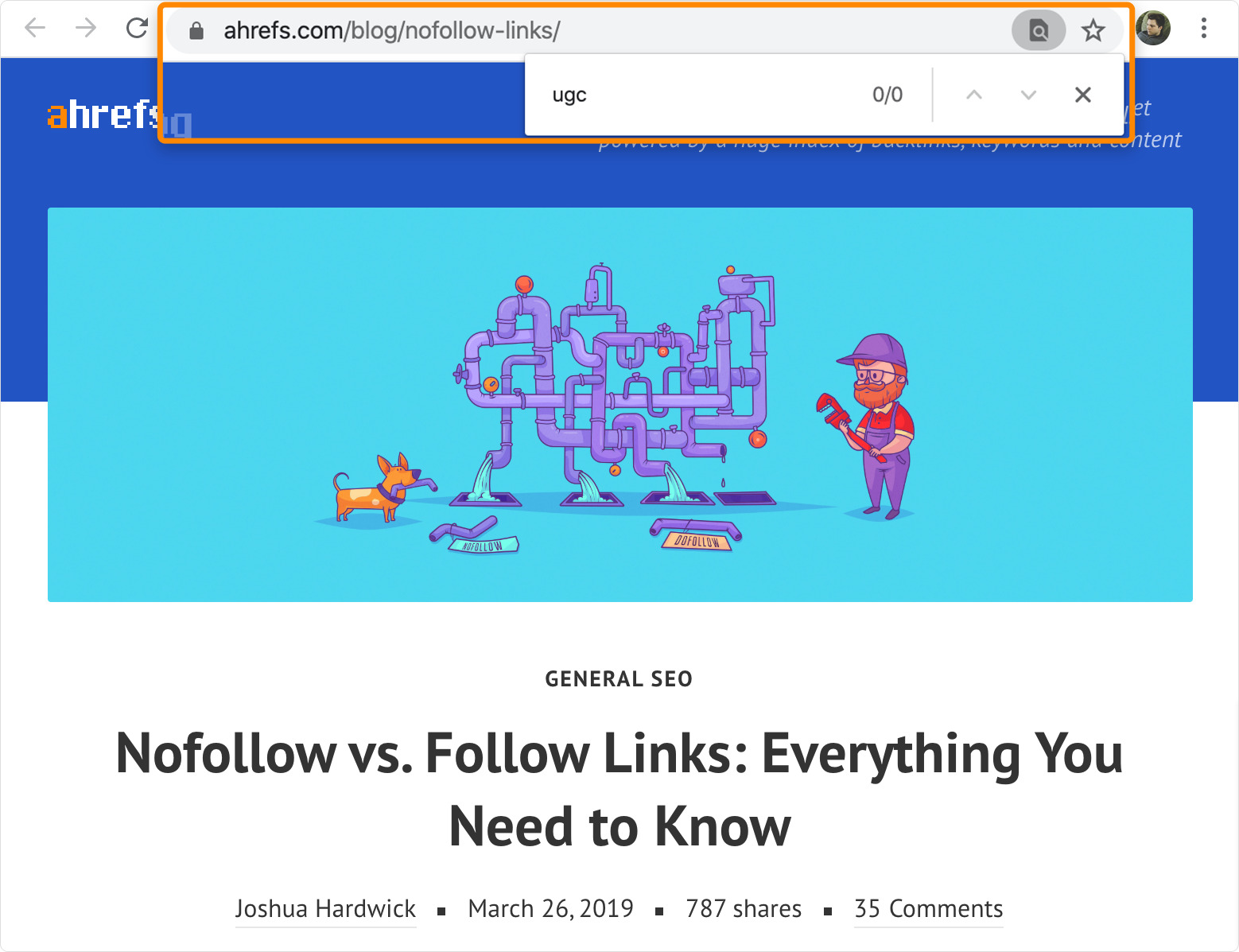
Google likely sees these as important, semantically-related terms that any good article about the topic should mention.
That may be part of the reason why articles that talk about these things outrank us.
With this in mind, here are nine ways to find potentially related words, phrases, and entities:
1. Use common sense
Check your pages to see if you’ve missed any obvious points.
For example, if the page is a biographical article about Donald Trump and doesn’t mention his impeachment, it’s probably worth adding a section about that.
In doing so, you’ll naturally mention related words, phrases, and entities like “Mueller Report,” “Nancy Pelosi,” and “whistleblower.”
2. Look at autocomplete results
Autocomplete results don’t always show important related keywords, but they can give clues about ones that might be worth mentioning.
For example, we see “donald trump spouse,” “donald trump age,” and “donald trump twitter” as autocomplete results for “donald trump.”
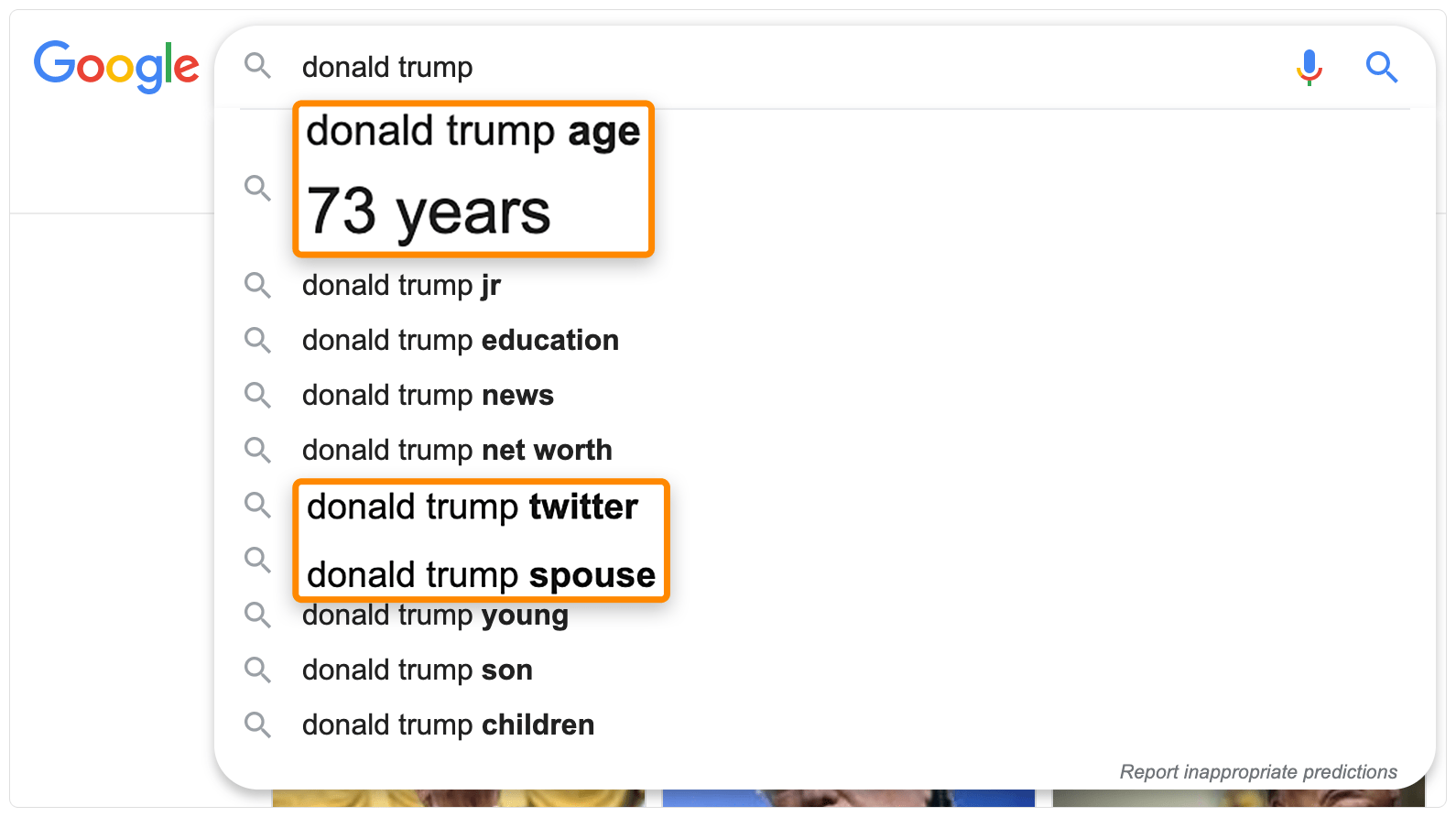
These aren’t related keywords in themselves, but the people and things they’re referring to might be. In this case, those are Melania Trump, 73 years old, and @realDonaldTrump.
Probably all things that should be mentioned in a biographical article, right?
3. Look at related searches
Related searches appear at the bottom of the search results.
Like autocomplete results, they can give clues about potentially related words, phrases, and entities worth mentioning.
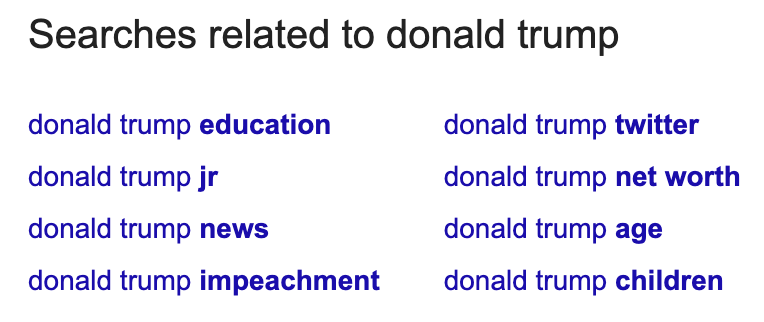
Here, “donald trump education” is referring to The Wharton School of the University of Pennsylvania that he attended.
4. Use an “LSI keyword” tool
Popular “LSI keyword” generators have nothing to do with LSI. However, they do occasionally kick back some useful ideas.
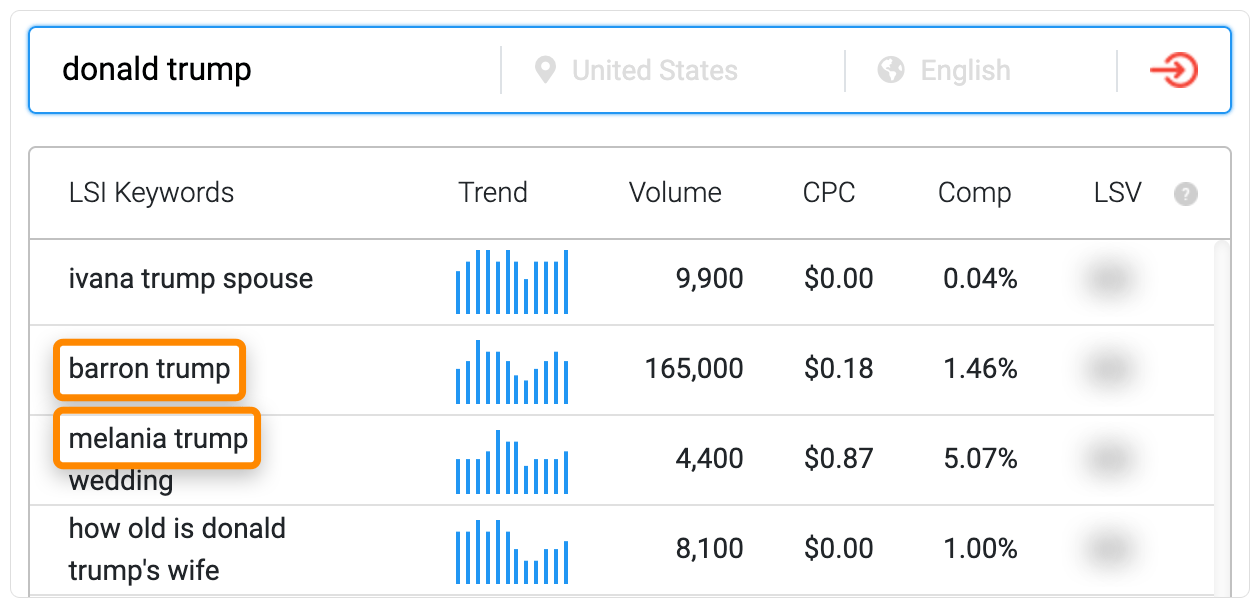
For example, if we plug “donald trump” into a popular tool, it pulls related people (entities) like his spouse, Melania Trump, and son, Barron Trump.
5. Look at other keywords the top pages rank for
Use the “Also rank for” keyword ideas report in Ahrefs’ Keywords Explorer to find potentially related words, phrases, and entities.
![]()
![]()
If there are too many to handle, try running a Content Gap analysis using three of the top-ranking pages, then set the number of intersections to “3.”
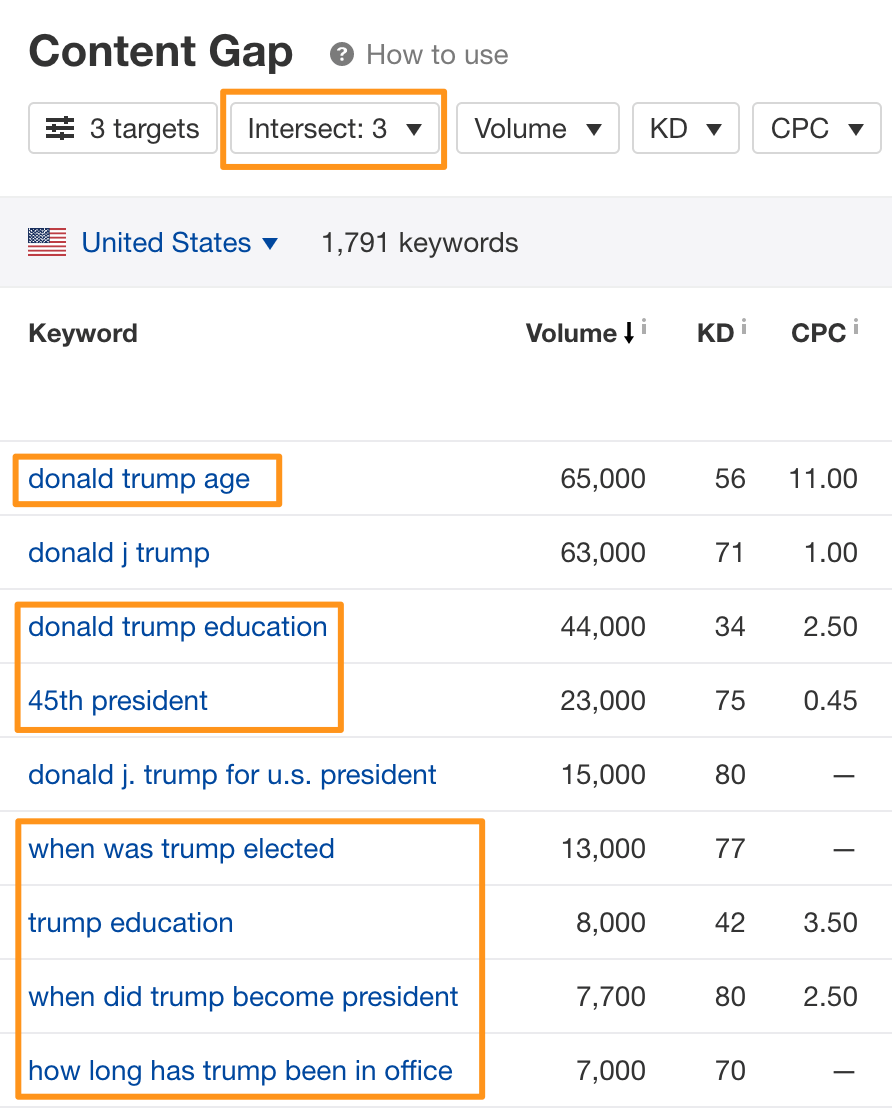
This shows keywords that all of the pages rank for, which often gives you a more refined list of related words and phrases.
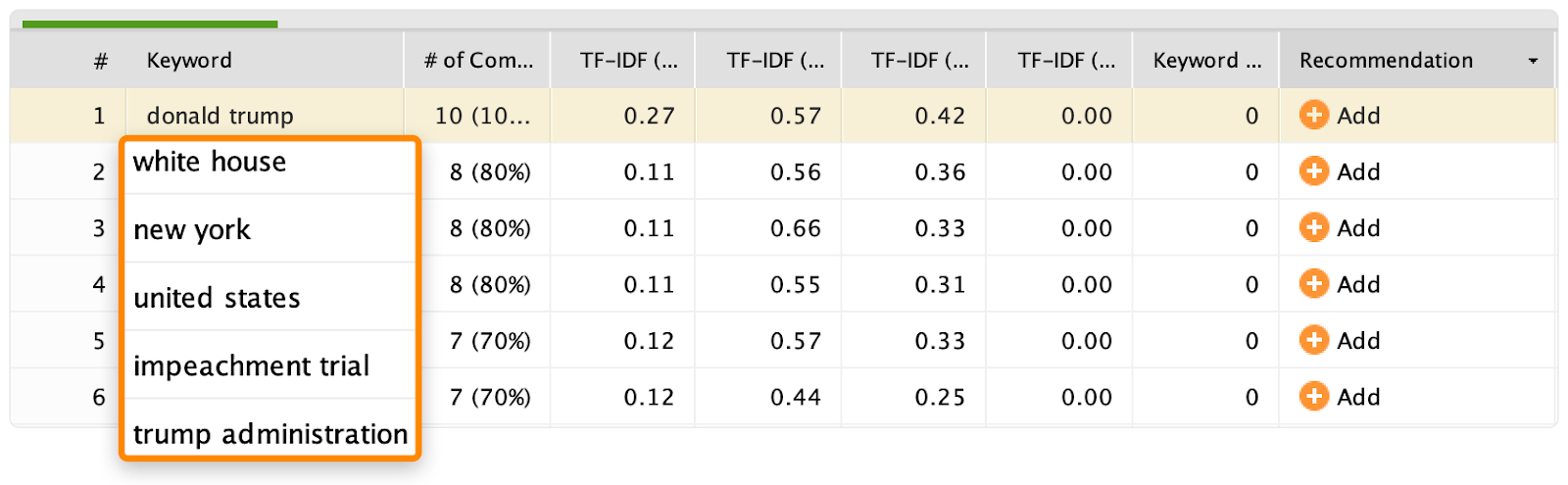
6. Run a TF*IDF analysis
TF-IDF has nothing to do with latent-semantic indexing (LSI) or latent-semantic analysis (LSA), but it can occasionally help uncover “missing” words, phrases, and entities.
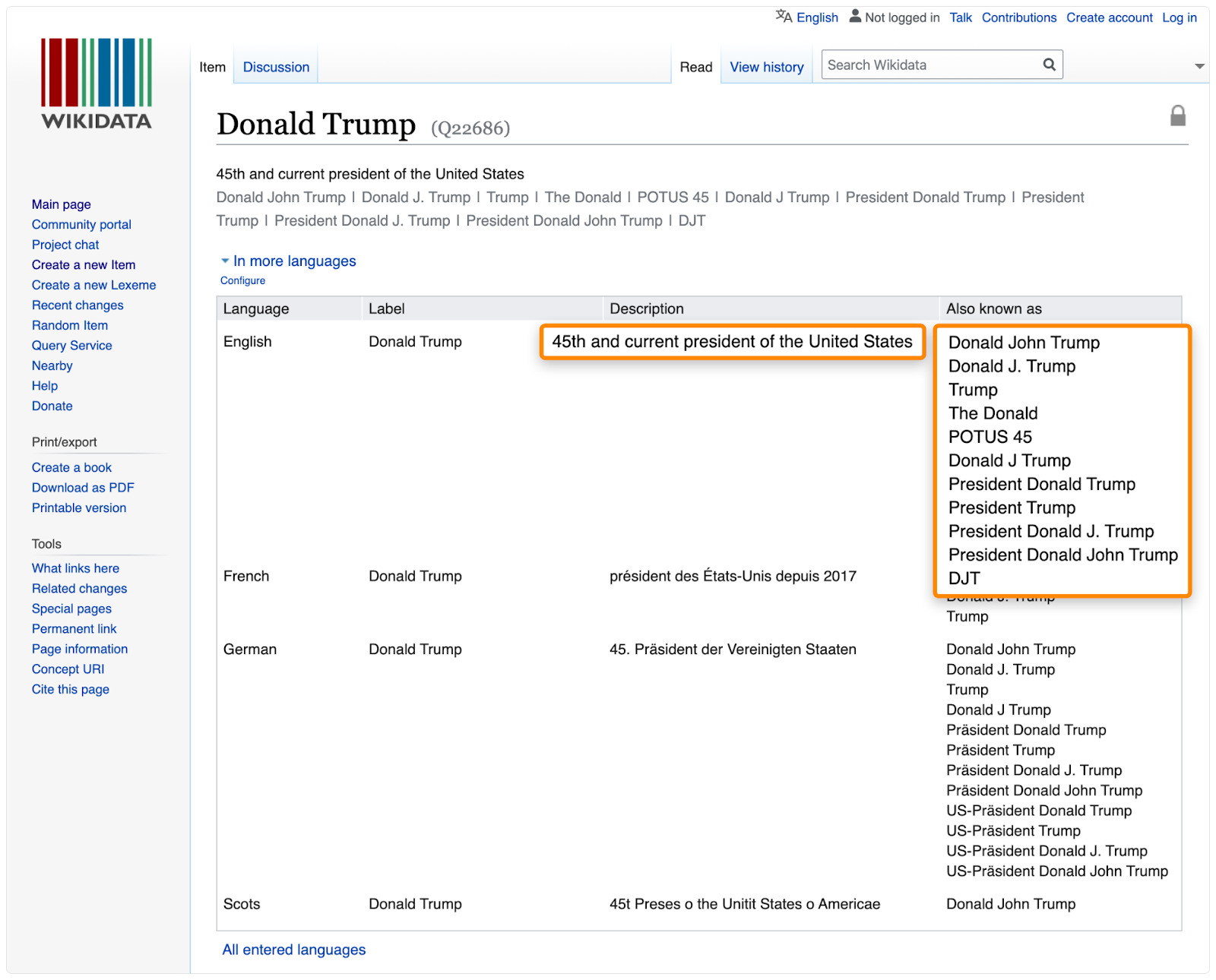
7. Look at knowledge bases
Knowledge bases like Wikidata.org and Wikipedia are fantastic sources of related terms.
Google also pulls knowledge graph data from these two knowledge bases.
8. Reverse-engineer the knowledge graph
Google stores the relationships between lots of people, things and concepts in something called a knowledge graph. Results from the knowledge graph often show up in Google search results.
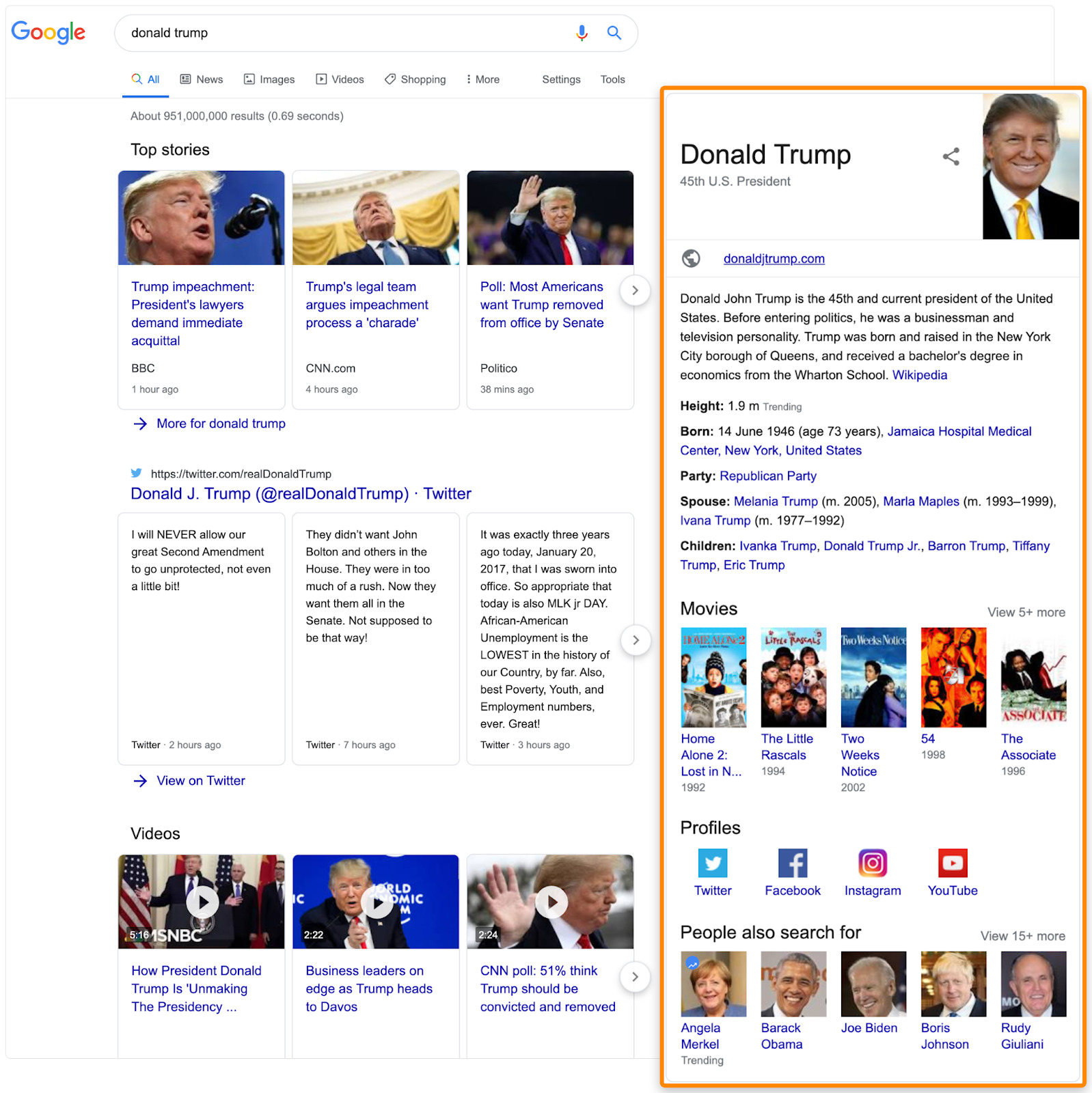
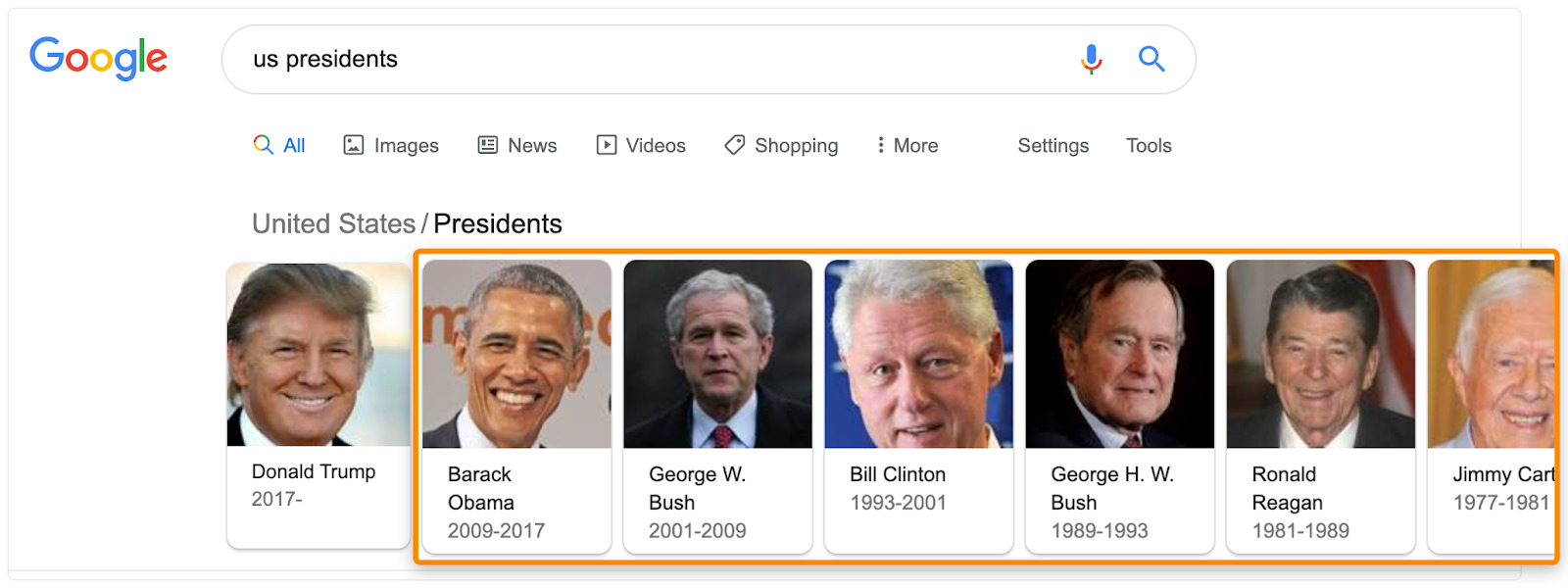
Try searching for your keyword and see if any data from the knowledge graph shows up.
Because these are entities and data points that Google associates with the topic, it’s definitely worth talking about relevant ones where it makes sense.
9. Use Google’s Natural Language API to find entities
Paste the text from a top-ranking page into Google’s Natural Language API demo. Look for relevant and potentially important entities that you might have missed.
Final thoughts
LSI keywords don’t exist, but semantically-related words, phrases, and entities do, and they have the power to boost rankings.
Just make sure to use them where it makes sense, and not to haphazardly sprinkle them whenever and wherever.
In some cases, this may mean adding new sections to your page.
For instance, if you want to add words and entities like “impeachment” and “House Intelligence Committee” to an article about Donald Trump, that’s probably going to require a couple of new paragraphs under a new subheading.
Do you have any other questions about LSI keywords?
Leave a comment or ping me on Twitter.



