
Nella maggior parte dei casi, questo succede quando hai bloccato la scansione dal tuo robots.txt. Esistono però una serie di motivazioni aggiuntive che possono far scattare il problema, e questo processo può aiutarti a diagnosticare e sistemare la causa nella maniera più efficiente possibile:
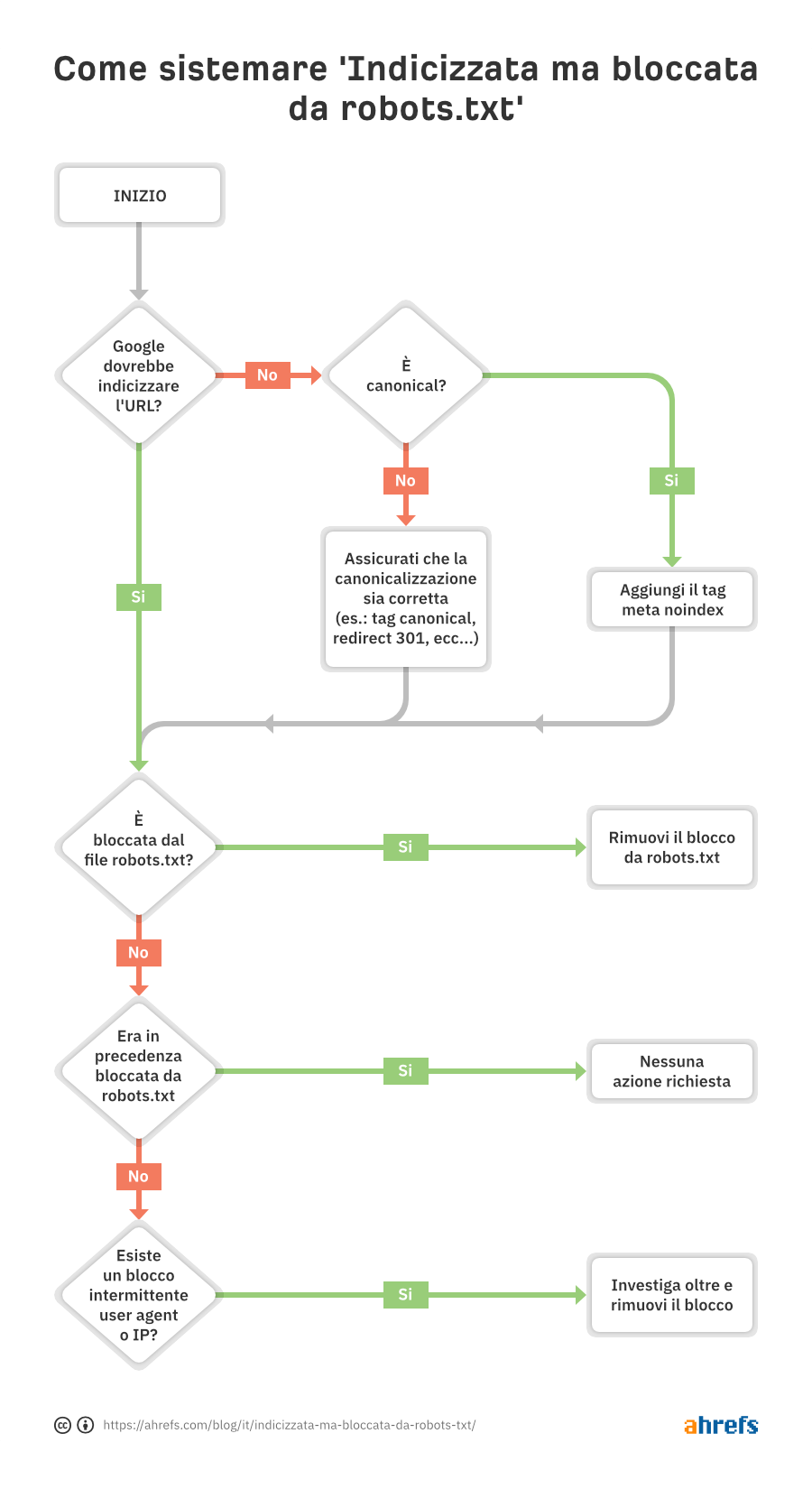
Come puoi notare, il primo step consiste nel verificare se Google debba o meno indicizzare quella URL.
Se vuoi che l’URL non venga indicizzata…
Aggiungi un meta tag robots noindex e assicurati di consentire la scansione—dando per scontato che la pagina sia la giusta versione canonica.
Se blocchi la scansione per una pagina, Google potrebbe comunque indicizzarla, in quanto indicizzazione e scansione sono due cose ben diverse. A meno che Google non possa scansionare una pagina infatti, non può vedere la presenza del meta tag noindex su di essa, e potrebbe decidere di indicizzarla comunque perchè riceve dei link.
Se la URL ha un canonical che punta verso un’altra pagina, non aggiungere il meta tag noindex. Assicurati però che tutti i segnali di canonicalizzazione siano corretti, incluso il tag canonical sulla pagina canonica, e assicurati che la scansione sia consentita, in modo che i vari segnali possano essere consolidati correttamente.
Se vuoi che l’URL venga indicizzata…
Devi capire perchè Google non riesce a scansione la URL e rimuovere il blocco.
La causa più probabile è un blocco all’interno del file robots.txt. Esistono però altri scenari che potrebbero portare alla comparsa di un messaggio che sostiene che la scansione sia bloccata. Vediamoli nell’ordine in cui dovresti controllarli in base alla probabilità che questi accadano:
- Verifica la presenza di un blocco nel file robots.txt
- Verifica la presenza di blocchi intermittenti
- Verifica la presenza di blocchi a livello di user-agent
- Verifica la presenza di blocchi a livello di IP
Verifica la presenza di un blocco nel file robots.txt
Il modo più semplice per verificare la presenza di questo problema, è quello di utilizzare il robots.txt tester presente all’interno di GSC, che evidenzia la presenza di un’eventuale regola.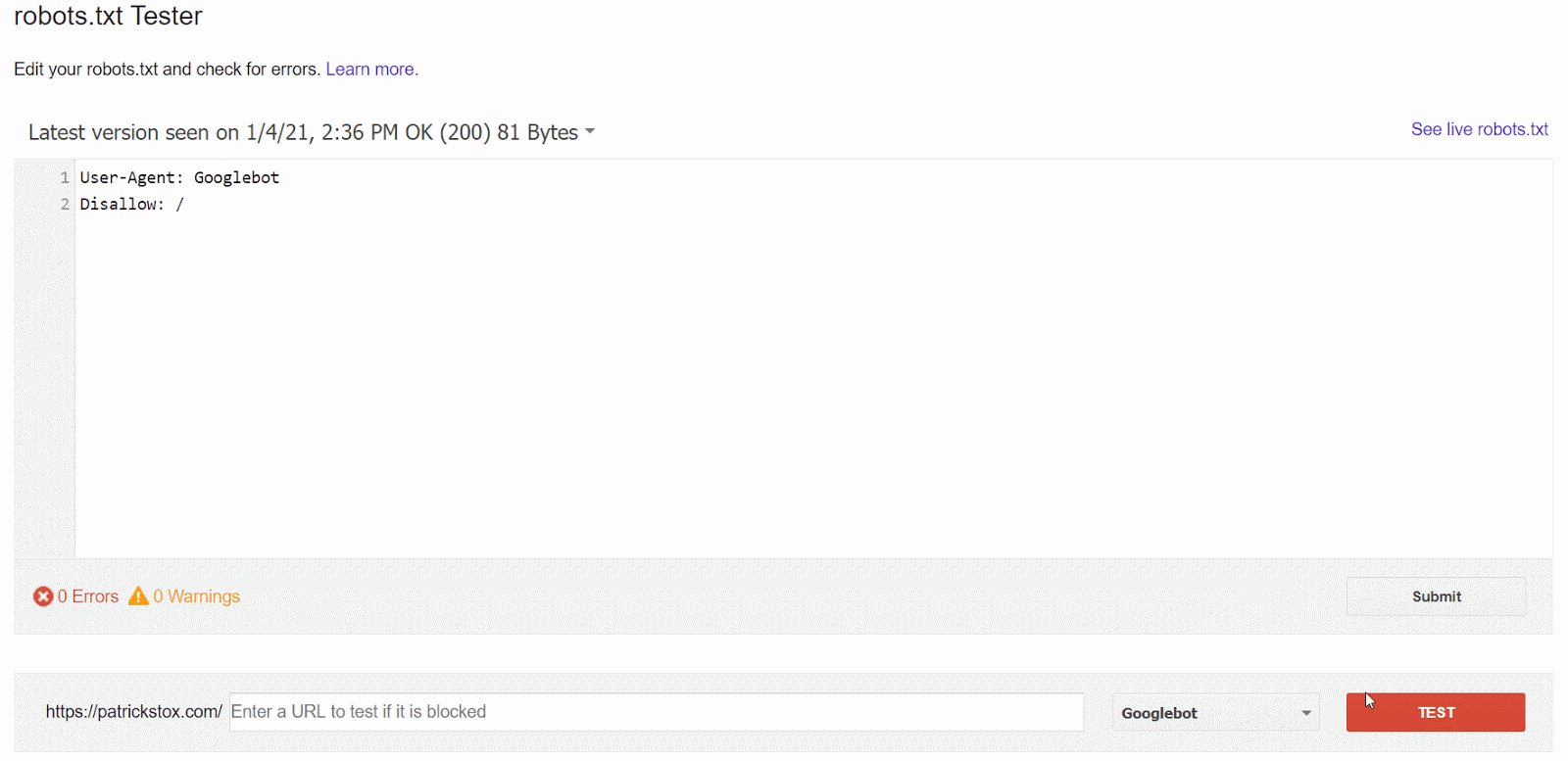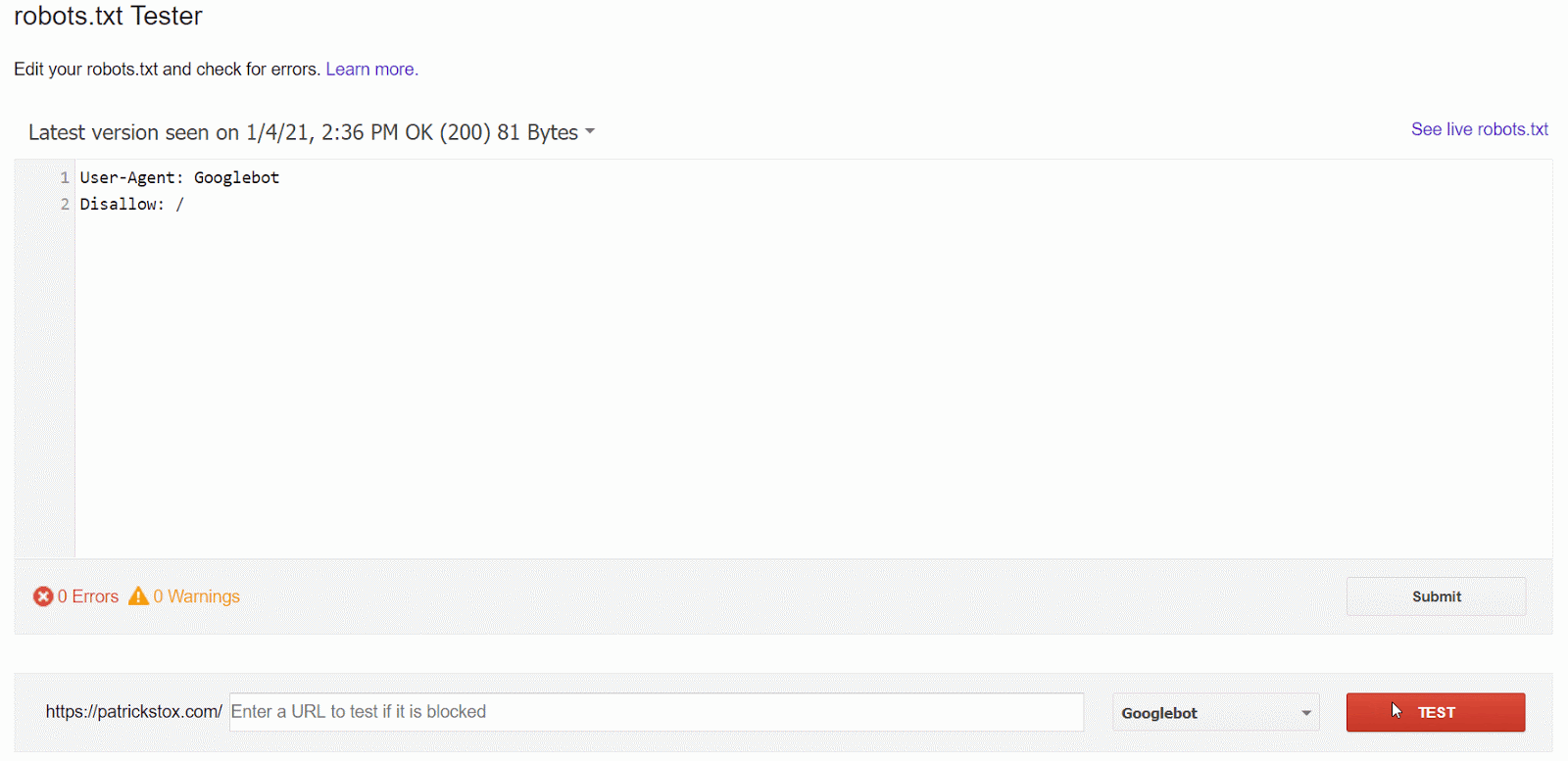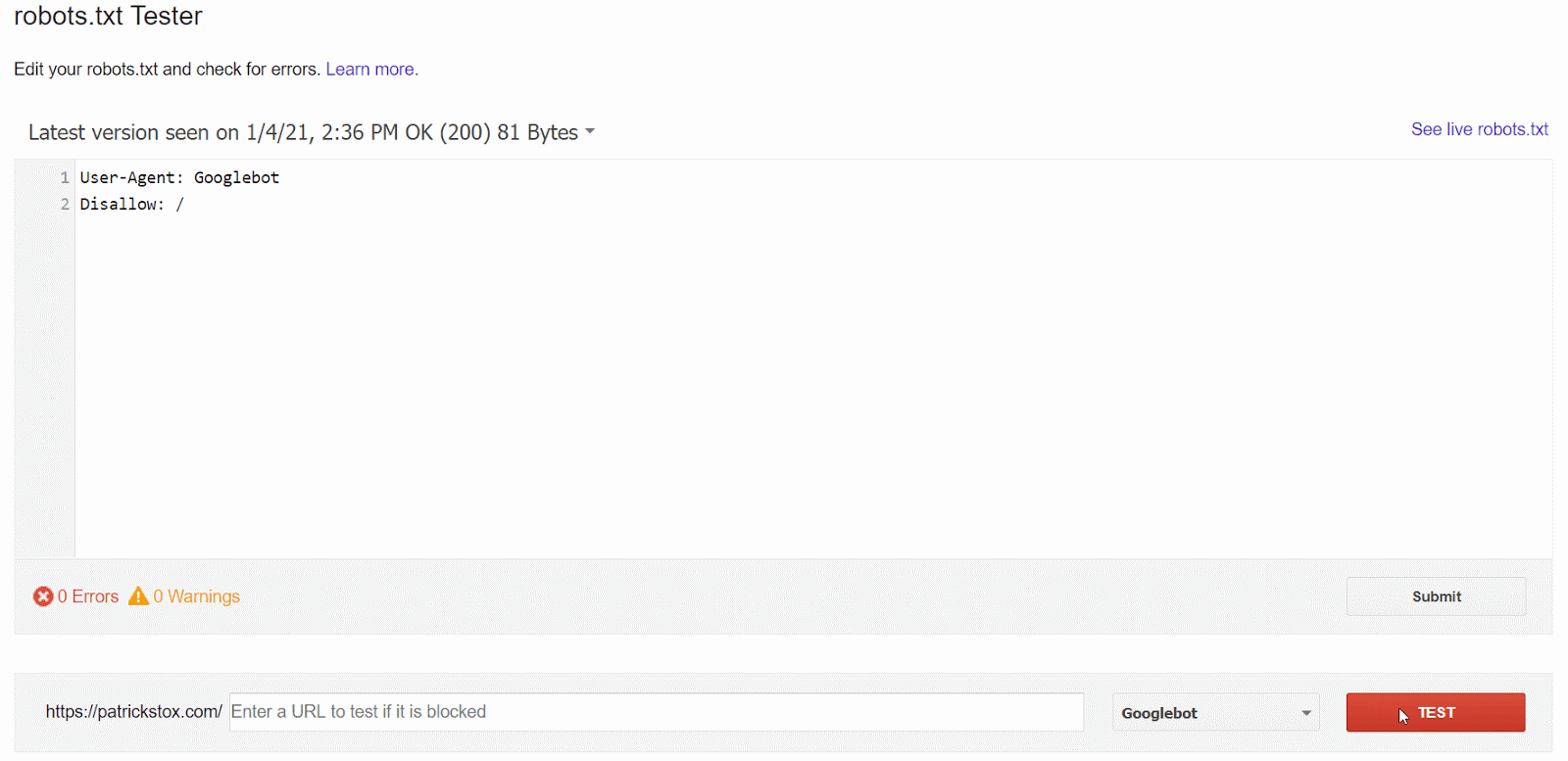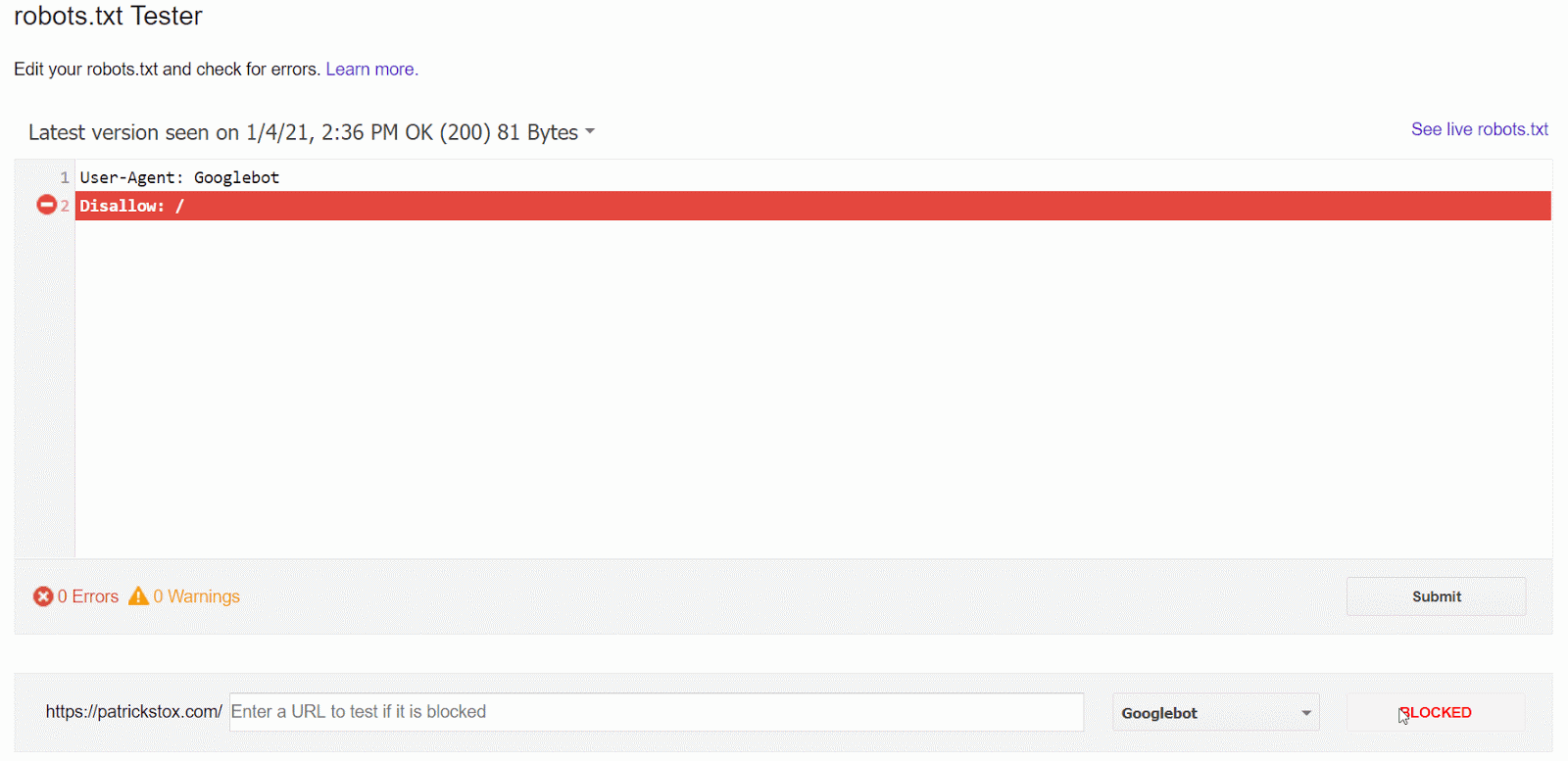
Se non sei certo di come fare, o non hai accesso a GSC, puoi andare su tuodominio.com/robots.txt per visualizzare il file. Abbiamo un intero articolo dedicato al file robots.txt, ma quello che dovresti controllare è l’eventuale presenza di regole di disallow simili alla seguente:
Disallow: /
Potrebbe esserci uno specifico user-agent menzionato, o potrebbero semplicemente essere tutti bloccati. Se il tuo sito è nuovo o è appena stato lanciato, verifica che non sia presente la seguente stringa:
User-agent: *
Disallow: /
È possibile che qualcuno abbia identificato il blocco all’interno del file robots.txt ed abbia già risolto il problema. Questo è chiaramente lo scenario più favorevole. Ad ogni modo, se il problema sembra risolto ma riappare dopo poco tempo, potresti avere un blocco intermittente.
Come si sistema
Devi rimuovere la regola che causa il blocco. Il modo in cui farlo dipende dalla tecnologia che utilizzi.
WordPress
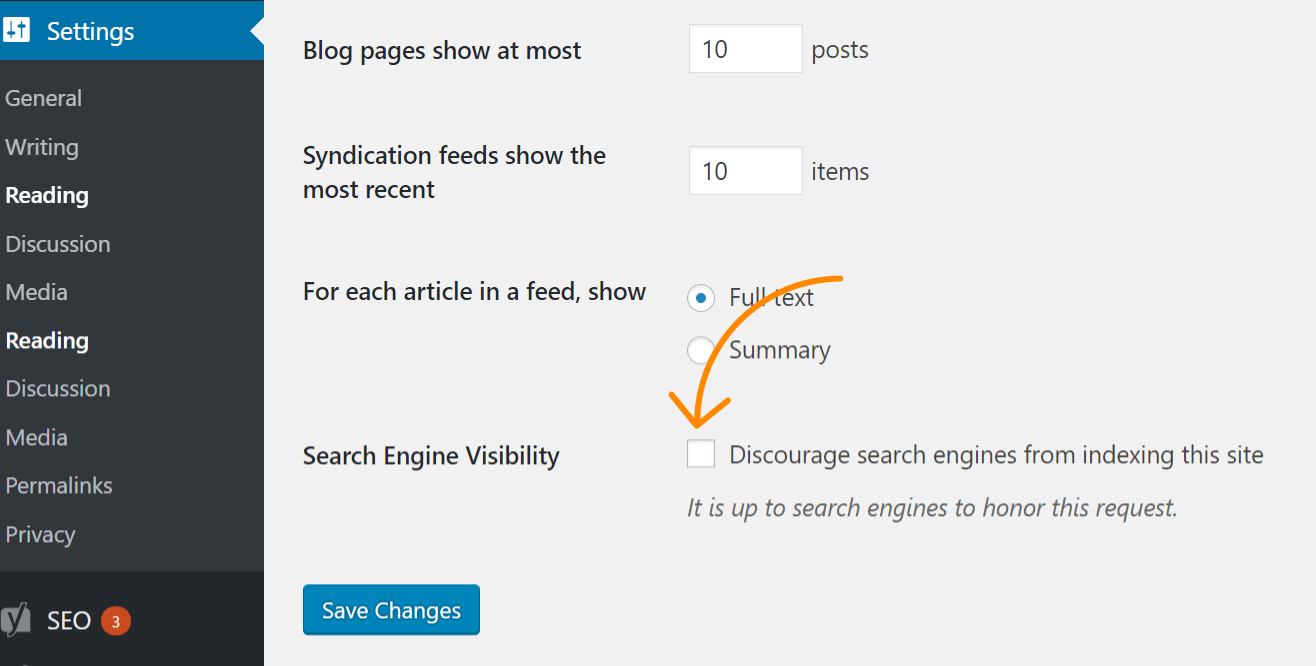
Se il problema si rispecchia sull’intero sito, la causa più probabile è che tu possa accidentalmente aver attivato l’impostazione di WordPress per disabilitare le scansioni su tutto il sito. Questo è un errore comune sui nuovi siti o a seguito di una migrazione. Segui queste istruzioni per effettuare un controllo:
- Fai click su ‘Impostazioni’
- Fai click su ‘Lettura’
- Assicurati che l’impostazione ”Scoraggia i motori di ricerca ad effettuare l’indicizzazione su questo sito” non sia spuntata
WordPress con Yoast
Se utilizzi il plugin Yoast SEO, puoi editare direttamente il file robots.txt per rimuovere la regola di blocco.
- Fai click su ‘Yoast SEO’
- Fai click su ‘Strumenti’
- Fai click su ‘Modifica file’
WordPress con Rank Math
Come Yoast, anche Rank Math ti permette di modificare direttamente il file robots.txt.
- Fai click su ‘Rank Math’
- Fai click su ‘General Settings’
- Fai click su ‘Edit robots.txt’
FTP o hosting
Sei hai l’accesso FTP al sito, puoi modificare direttamente il file robots.txt e rimuovere il problema relativo al disallow. Il tuo provider di hosting potrebbe anche fornire l’accesso ad un file manager che ti permette di editare il file robots.txt direttamente dal loro pannello di controllo.
Verifica la presenza di blocchi intermittenti
I problemi intermittenti possono essere i più complicati da identificare, in quanto la condizione che li causa potrebbe non sempre essere attiva.
Quello che ti consiglio di fare, è verificare la cronologia del tuo file robots.txt. Puoi farlo utilizzando ad esempio il robots.txt tester all’interno di GSC. Cliccando sul menù a discesa potrai infatti vedere le versioni precedenti del file insieme a quello che era il loro contenuto.

Anche The Wayback Machine su archive.org conserva un cronologia dei file robots.txt per i siti che scansiona. Puoi cliccare su ogni data disponibile per vedere cosa conteneva il file quello specifico giorno. 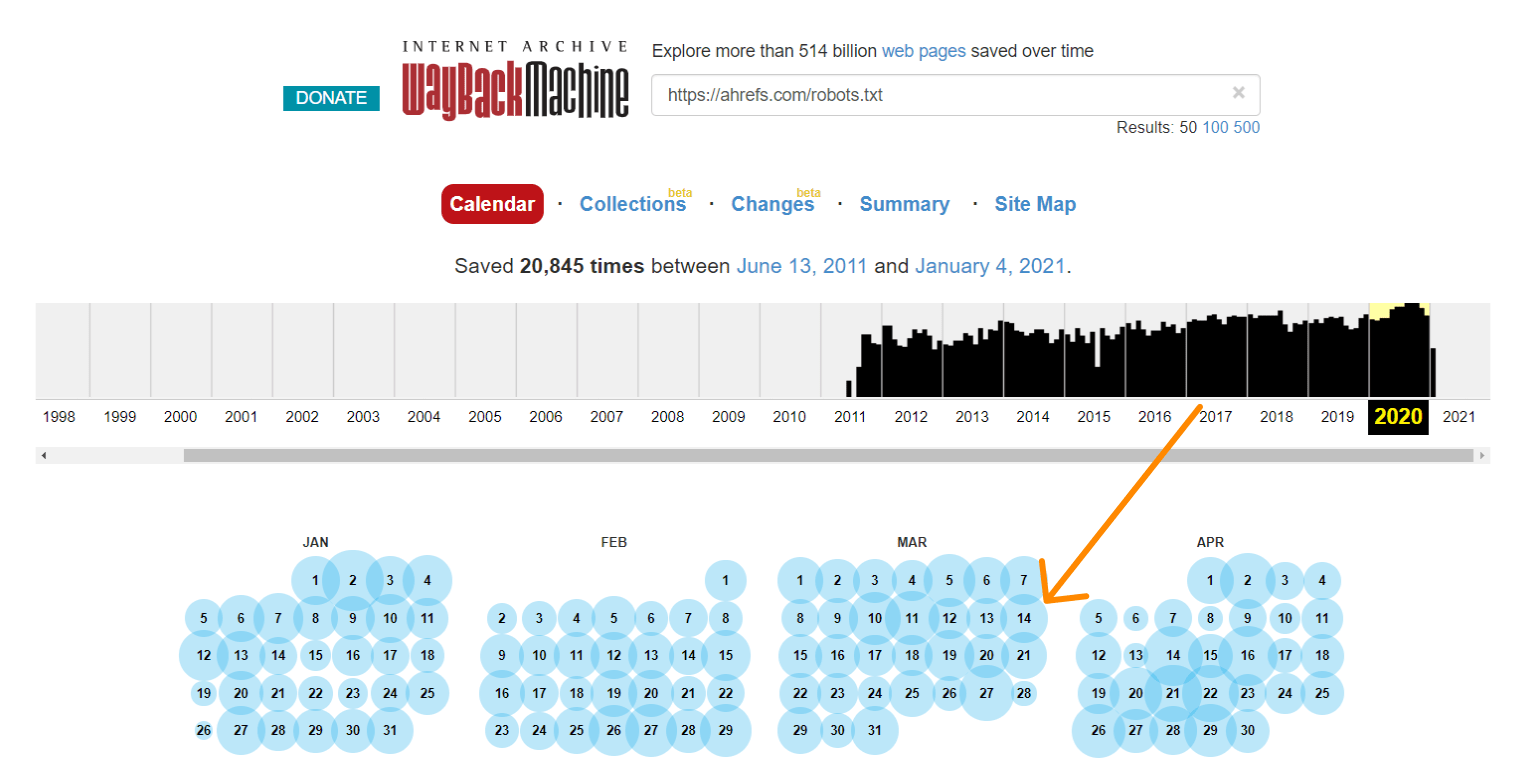
Oppure, puoi utilizzare la versione beta del report Changes, che consente di visualizzare in modo immediato le differenze fra due versioni.
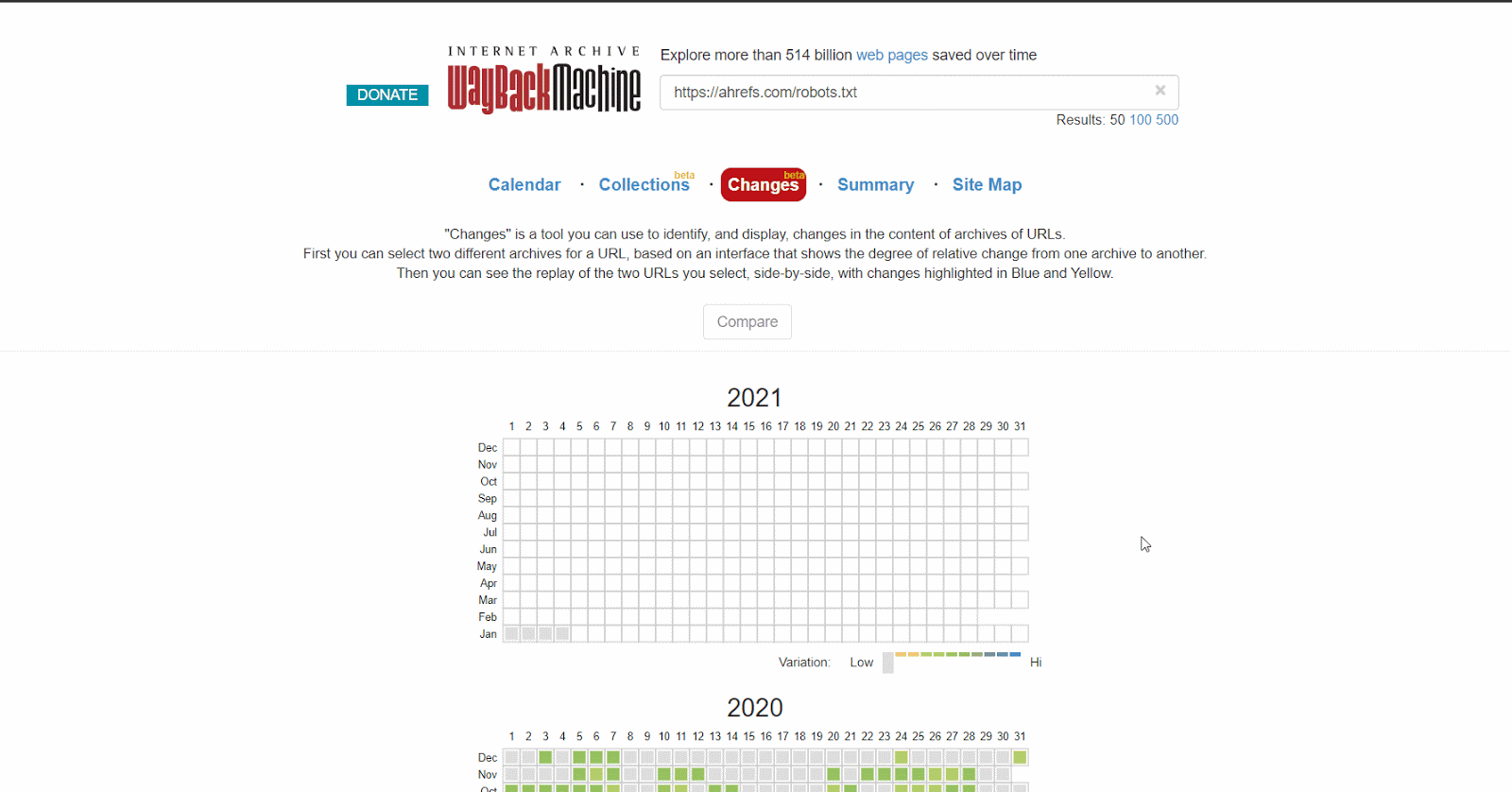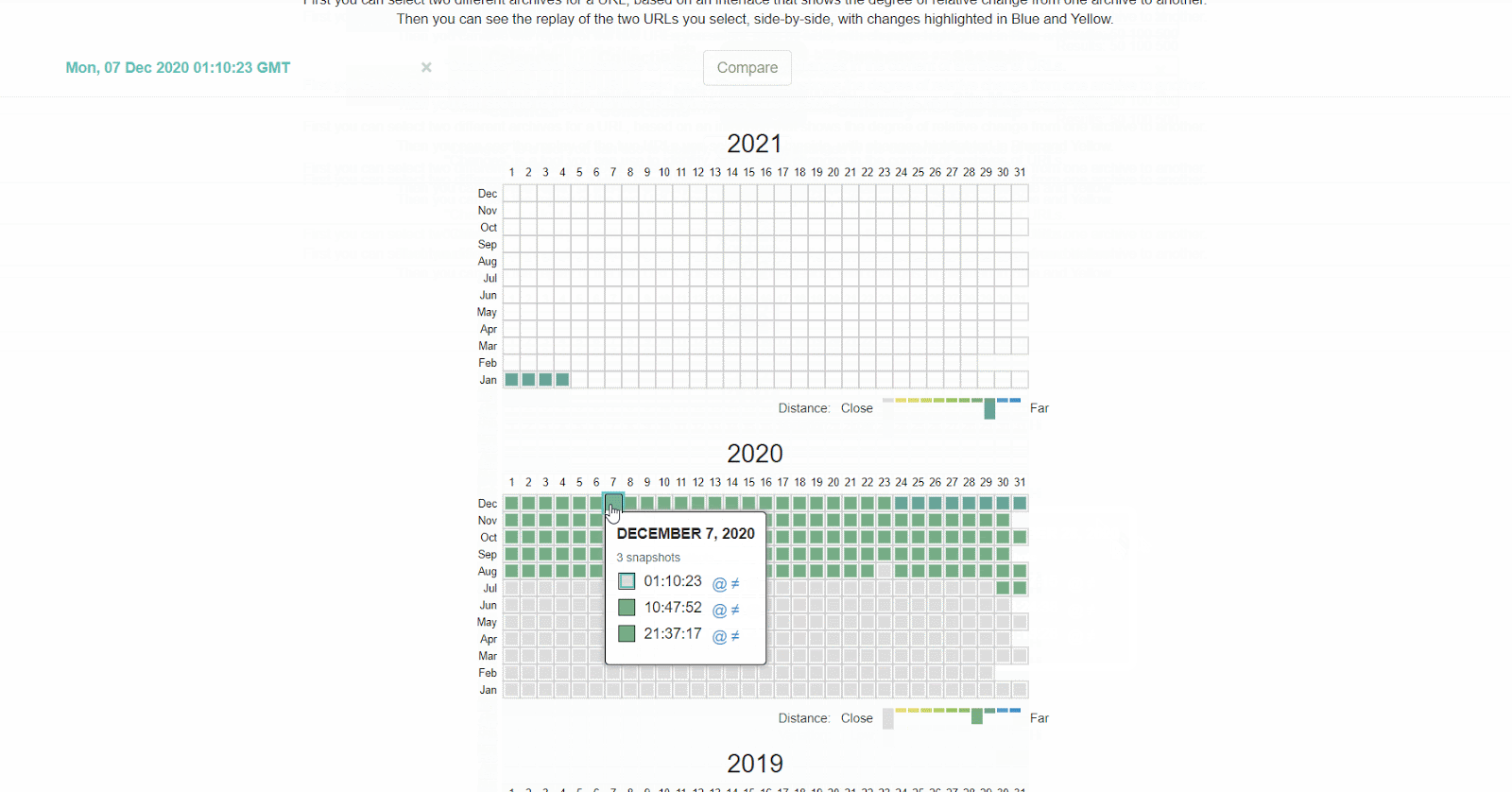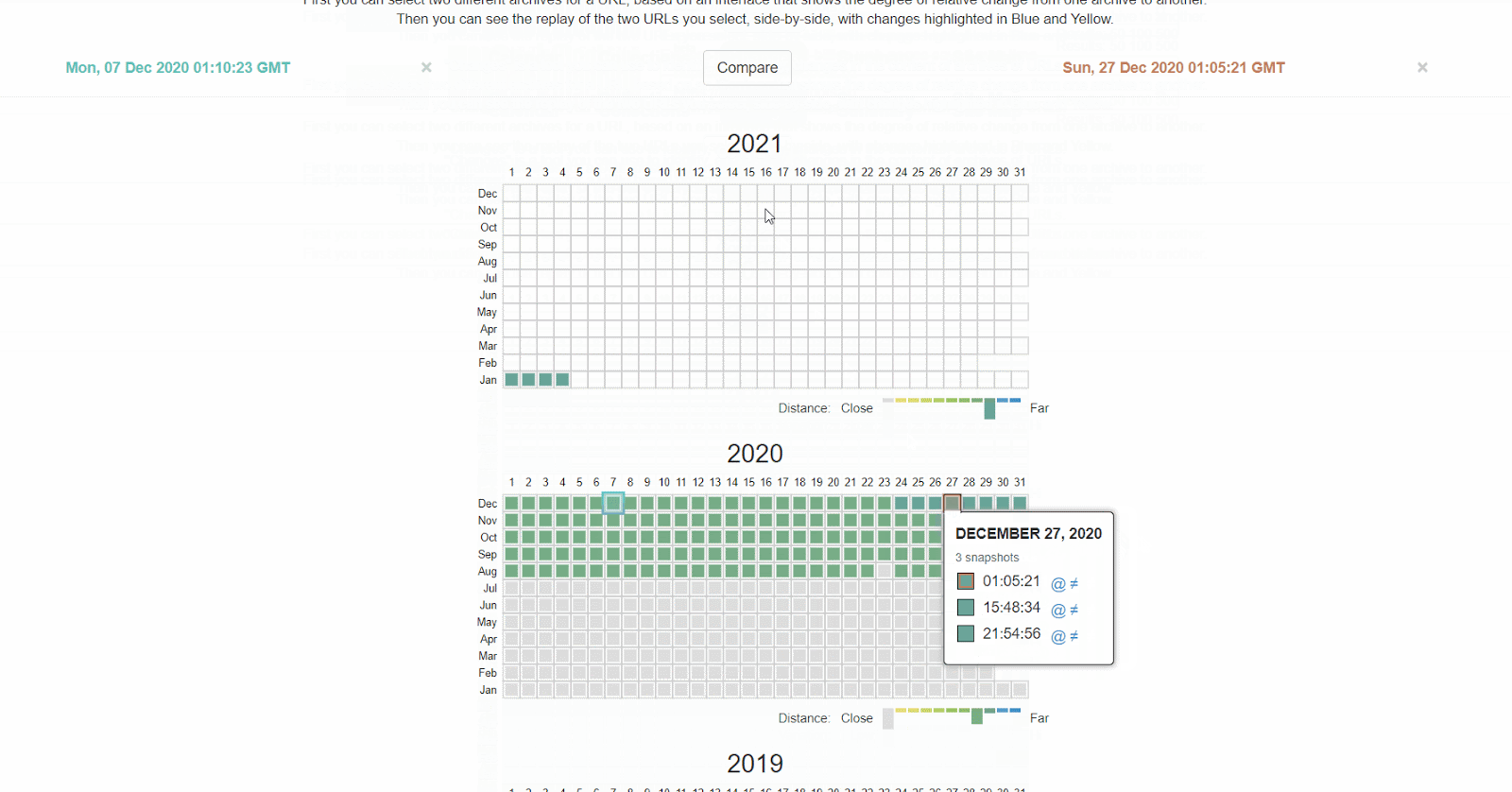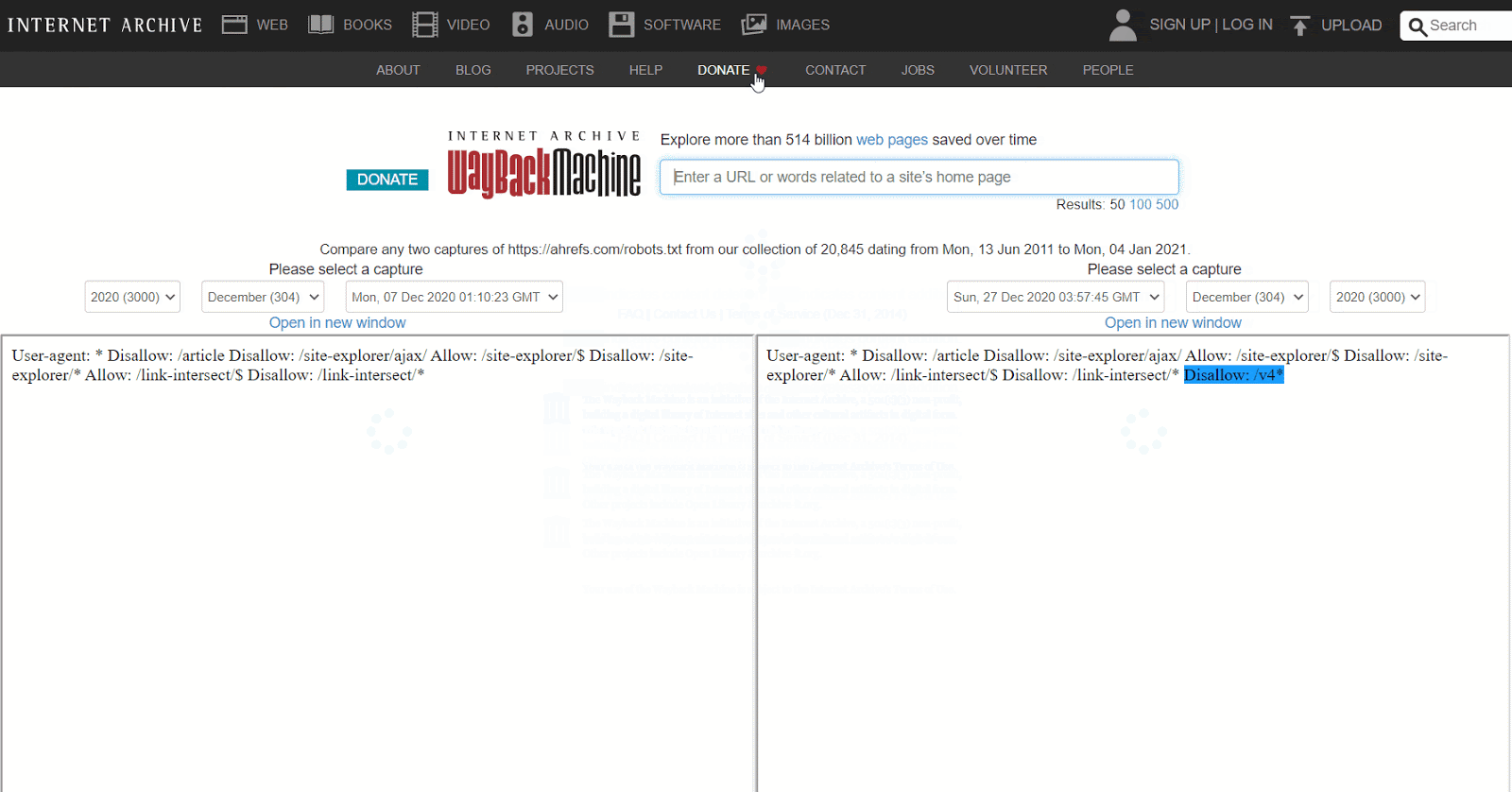
Come si sistema
Il processo di risoluzione per i blocchi intermittenti dipende dalla loro causa. Ad esempio, una possibile origine potrebbe essere una cache condivisa fra un ambiente di test ed uno live. Quando la cache dell’ambiente test è attiva, il file robots.txt potrebbe contenere delle regole di blocco. Quando invece la cache del sito live è attiva, il sito potrebbe essere accessibile dal crawler. In questo caso dovresti dividere la cache, o escludere i file con estensione .txt dal caching dell’ambiente di test.
Verifica la presenza di blocchi a livello di user-agent
I blocchi a livello di user-agent avvengono quando uno specifico di questi viene bloccato, come ad esempio Googlebot o AhrefsBot. In altre parole, il sito rileva lo specifico bot che sta tentando di eseguire la scansione, e blocca lo user-agent corrispondente.
Se riesci a vedere correttamente una pagina all’interno del tuo browser, ma vieni bloccato dopo aver cambiato il tuo user-agent, significa che quello specifico user-agent è, per l’appunto, bloccato.
Puoi specificare un preciso user agent da utilizzare attraverso i devtools di Chrome. Un’altra opzione è quella di utilizzare un’estensione che consenta di fare la stessa cosa, come questa qui.
In alternativa, puoi verificare la presenza di blocchi a livello di user-agent con il comando cURL. Ecco come farlo su Windows:
- Premi Windows+R per lanciare la box “Esegui”
- Scrivi “cmd” e premi “Invio”
- Inserisci un comando cURL come il seguente:
curl -A “user-agent-che-vuoi-utilizzare” -Lv [URL]
curl -A “Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)” -Lv https://ahrefs.com
Come si sistema
Sfortunatamente, questa è un’altra di quelle situazioni dove la soluzione dipende da cosa origina il blocco. Esistono infatti diversi sistemi che possono bloccare un bot, incluso il file .htaccess, le configurazioni del server, i firewall, le CDN o anche qualche parametro controllato dal tuo provider di hosting che non riesci a vedere. Potresti provare a contattare il provider del tuo hosting o della tua CDN chiedendo di indagare il blocco per te.
Ad esempio, ecco due diversi modi per bloccare uno user agent dal file .htaccess che potresti voler verificare:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Googlebot [NC]
RewriteRule .* - [F,L]
Oppure…
BrowserMatchNoCase "Googlebot" bots
Order Allow,Deny
Allow from ALL
Deny from env=bots
Verifica la presenza di blocchi a livello di IP
Se hai verificato ed escluso la presenza di blocchi nel file robots.txt o a livello di user agent, allora si tratta probabilmente di un blocco a livello di indirizzo IP.
Come si sistema
I blocchi a livello di IP sono ardui da identificare. Come per i blocchi a livello di user agent, puoi contattare il provider del tuo hosting o della tua CDN e chiedergli come poter risolvere il problema.
Ecco un esempio di blocco IP che potrebbe essere impostato all’interno del file .htaccess che potresti voler indagare:
deny from 123.123.123.123
Conclusioni
La maggior parte delle volte, il messaggio “indicizzata ma bloccata da robots.txt” salta fuori a seguito di un problema sul file robots.txt. Spero questa guida ti abbia aiutato a identificare e risolvere il problema se questo non fosse stato il caso.
Domande? Fammelo sapere su Twitter.
Tradotto da Matteo Ginnetti, Consulente Digital Marketing.


