
La recherche à facettes est une méthode d’UX largement utilisée pour aider les utilisateurs à trouver rapidement ce qu’ils cherchent. Le côté négatif est que cela implique beaucoup de complications SEO potentielles qu’il va falloir gérer.
Vous allez apprendre dans ce guide :
- Qu’est-ce que la recherche à facettes ?
- Comment fonctionne la recherche à facettes ?
- Problèmes SEO causés par la recherche à facettes
- Comment détecter les problèmes liés à la recherche à facettes
- Comment corriger les problèmes de recherche à facette
- Comment éviter dès le début les erreurs de recherche à facettes
- Comment utiliser la recherche à facette pour attirer plus de trafic
La recherche à facettes (ou navigation à facette) est un type de navigation souvent trouvé dans les pages d’archives ou de catégories avec de nombreux éléments. Son objectif est d’aider les utilisateurs à trouver rapidement ce qu’ils recherchent grâce à plusieurs filtres selon les attributs des éléments.
La plupart des gens parlent de recherche à facettes tout simplement avec le terme “filtres”.
Vous trouverez le plus souvent ce type de navigation sur des pages catégorie de :
- Sites e-commerce comme AO.com.
- Sites d’annonce d’emploi comme Indeed.
- Sites de voyage/réservation comme Google Flights ou Airbnb.
Mais on peut aussi en trouver sur d’autres sites de grande ampleur.
La recherche à facettes fonctionne via le filtre des éléments d’une page de catégorie selon les attributs, comme dit plus haut, ce seront souvent des listes de :
- Produits
- Hotels/vols
- Emplois
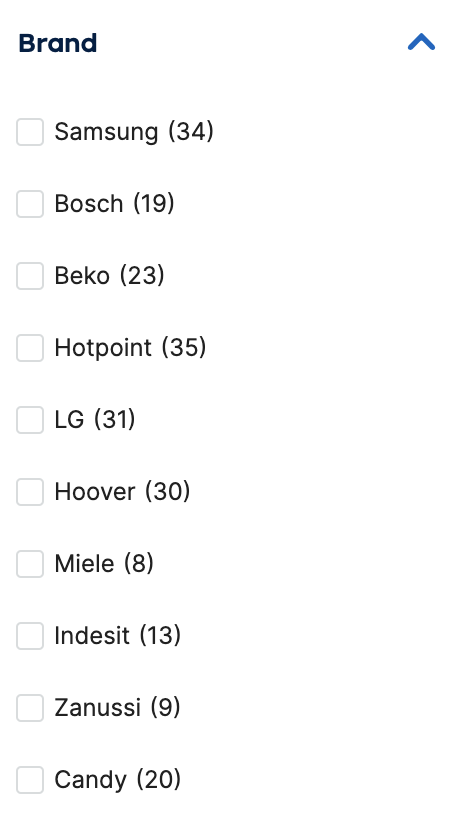
Les attributs peuvent varier de site en site, mais les plus fréquents sont :
- Prix
- Couleur
- Marque
- Poids
- Temps de trajet
- Salaire
- Quantité
- Temps de livraison
Une fois que les administrateurs du site ont donné les attributs adéquats aux éléments, le site va les proposer aux utilisateurs dans une liste :
Ce qui arrive lorsqu’un utilisateur sélectionne un filtre va varier, mais en règle générale ce sera l’une de ces quatre choses :
- La liste va se mettre à jour instantanément selon la sélection sans recharger la page (via du JavaScript)
- La page recharge est la liste se met à jour (pas besoin de JavaScript)
- Lorsque l’utilisateur clique, rien ne se passe tant qu’il ne cliquent pas aussi sur “Appliquer”, ce qui va mettre à jour la liste (encore une fois, avec du JavaScript).
- Lorsque l’utilisateur clique sur appliquer les filtres, une nouvelle page se charge.
Les deux premières options ont une UX similaire, mais différente de la troisième.
L’UX choisie va dépendre de si votre utilisateur va avoir tendance à sélectionner plus d’un filtre. S’il a plutôt tendance à appliquer plusieurs filtres, il est logique de ne les appliquer que lorsqu’il a fini de les sélectionner et a cliqué sur le bouton pour valider.
Une fois que les filtres sont appliqués, l’URL peut éventuellement se mettre à jour pour refléter la sélection. Ce qui arrive à l’URL à cette étape peut varier :
- Ça ne change rien. La liste est mise à jour sans changement d’URL.
- Le site ajoute un paramètre à l’URL comme “?colour=blue&brand=samsung”.
- Le site ajoute un hash à l’URL pour identifier la sélection, par exemple #colour=blue
- Une nouvelle URL statique est créée comme /jeans/bleu/ (l’utilisateur a ici choisi l’attribut “bleu”)
Les types de problèmes qu’il va falloir prévoir ou corriger avec la mise en place d’une recherche à facette impliquent :
- La duplication de contenu
- Le gonflement de l’index (index bloat)
- Exploration (crawling)
Malheureusement, la recherche à facettes peut potentiellement créer un nombre presque infini de combinaisons et d’URL indexables. Si vous avez un problème comme celui-ci, l’impact SEO risque d’être très important.
Voici quelques exemples de la manière dont ces problèmes arrivent et leur impact sur le SEO de votre site :
Contenu dupliqué
On parle de contenu dupliqué lorsque du contenu similaire est accessible via plusieurs URL. Les filtres sont connus pour créer des masses de contenu dupliqué. Ceci est principalement dû aux pages filtrées qui sont des copies très proches de la page originale.
Si le contenu dupliqué n’est pas nécessairement un mauvais signal de ranking, cela peut causer quelques problèmes :
- Cannibalisation de mot-clé
- Dilution des signaux de ranking dans plusieurs URL (plutôt que de tout consolider dans une seule URL forte)
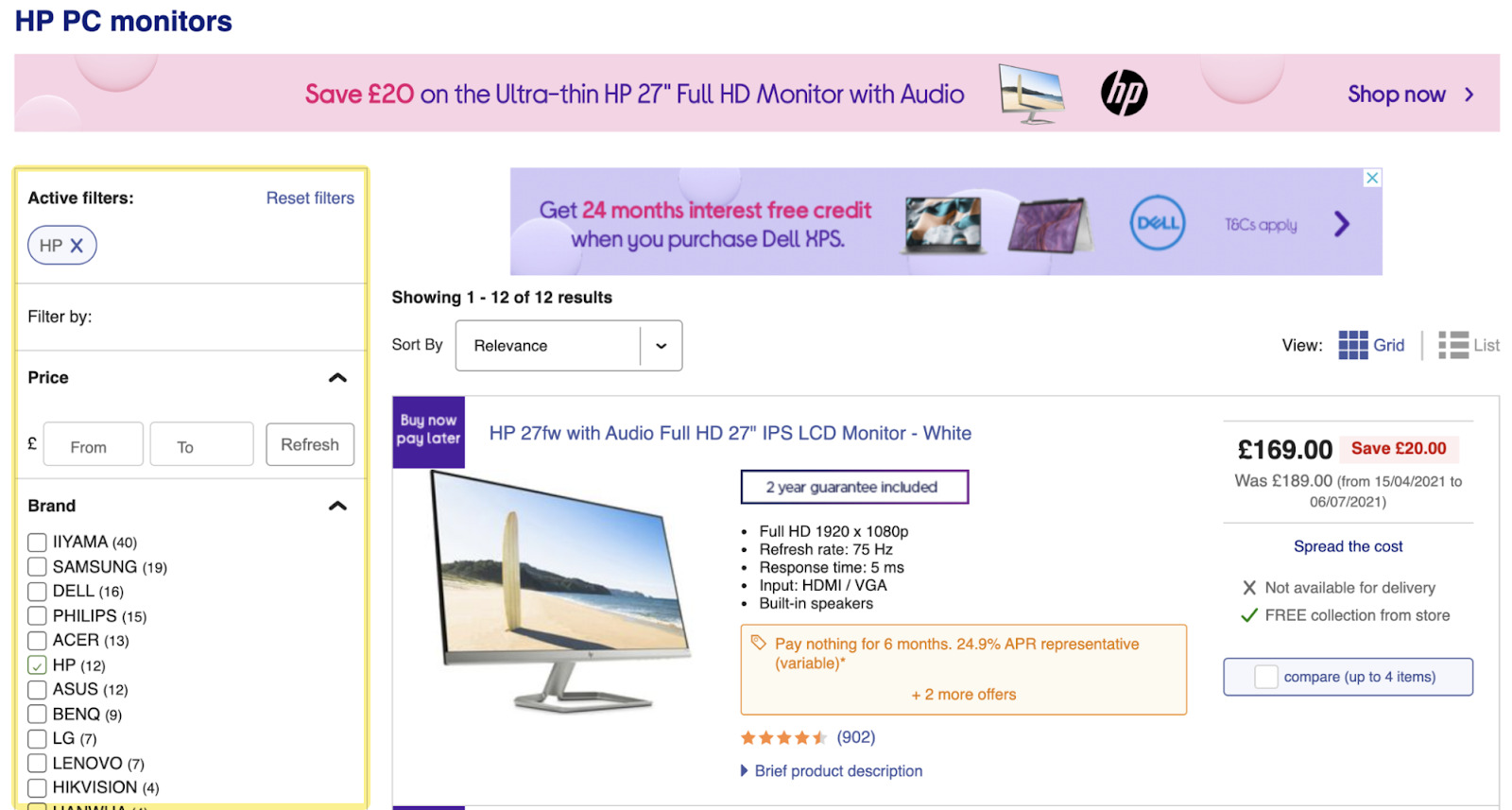
Voici par exemple le site de e-commerce currys.co.uk. Nous commençons par leur page écran PC HP. C’est une maquette de e-commerce relativement standard, avec un header, une liste et une recherche à facettes :
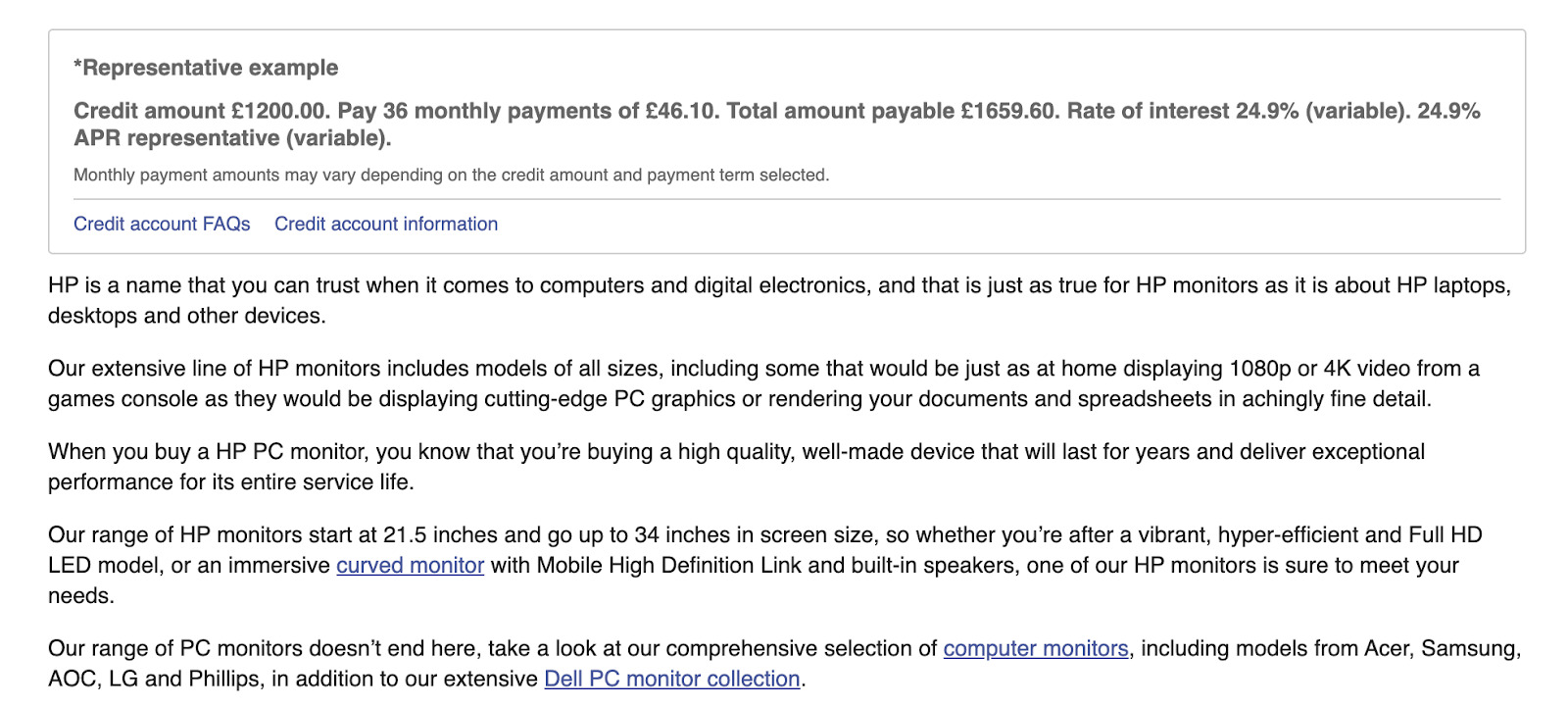
Et, sous la liste de produit, du contenu au sujet des écrans HP :
Maintenant, appliquons le filtre “écran 4k”.
Vous verrez que la liste de produit se met à jour, le H1 change et l’URL passe de :
/hp-computing/pc-monitors/pc-monitors/354_3057_30059_16_xx/xx-criteria.html
À :
/hp-4k-monitors/pc-monitors/pc-monitors/354_3057_30059_16_ba00012894-bv00311096/xx-criteria.html
Mais si vous scrollez jusqu’en bas de la page, le même bloc de contenu est toujours là, sous la liste de produits.
Ce n’est qu’un exemple de duplication sur le site. Mettez ça à l’échelle de tous les filtres disponibles, et vous allez rapidement avoir des millions de pages dupliquées que Google doit essayer de rassembler en une seule page canonique.
Gonflement d’index (Index bloat)
Le gonflement d’index est lorsque les moteurs de recherche indexent des pages de votre site qui n’ont aucune valeur de recherche.
Ne permettre à Google d’indexer que des pages de qualité est très important, des pages indexées de basse qualité vont avoir un impact négatif global sur votre site, comme John Mueller l’explique dans cette vidéo :
La recherche à facettes peut potentiellement créer des millions d’URL indexables qui ne contiennent aucun contenu unique. Cela peut aussi créer des variantes de pages qui n’apportent aucune valeur ajoutée aux utilisateurs ou aux moteurs de recherche.
Voici un exemple :
AO.com a une page de catégorie dédiée aux lave-linges non-encastrables
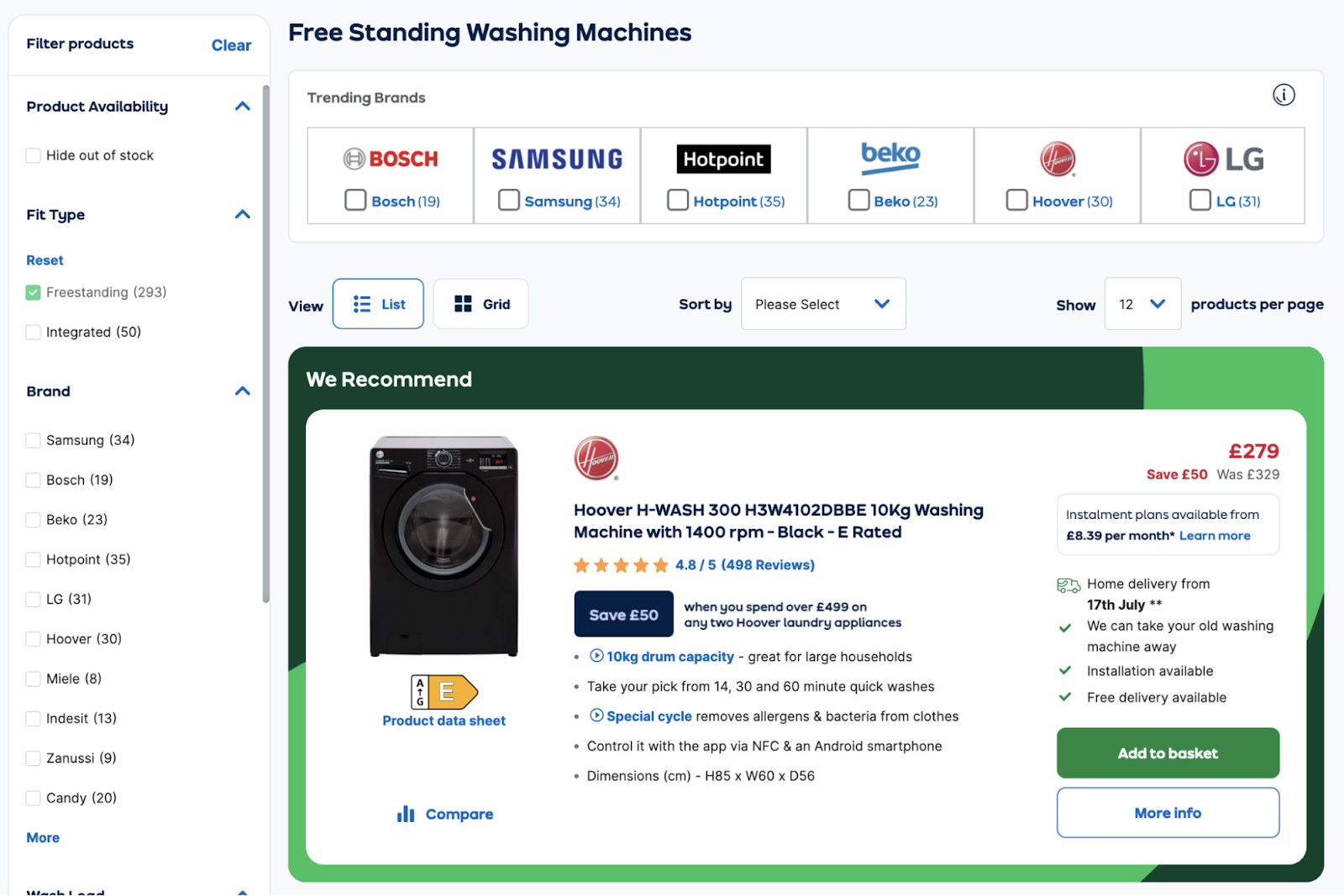
Un utilisateur peut visiter cette page et décider s’il veut filtrer par :
- Marque : Samsung
- Capacité : Grande
- Couleur : métallique
- Fonctionnalités : lavage rapide
- Classe énergie : A
Grâce aux filtres, le site montre les machines qui répondent précisément aux besoins de l’utilisateur.

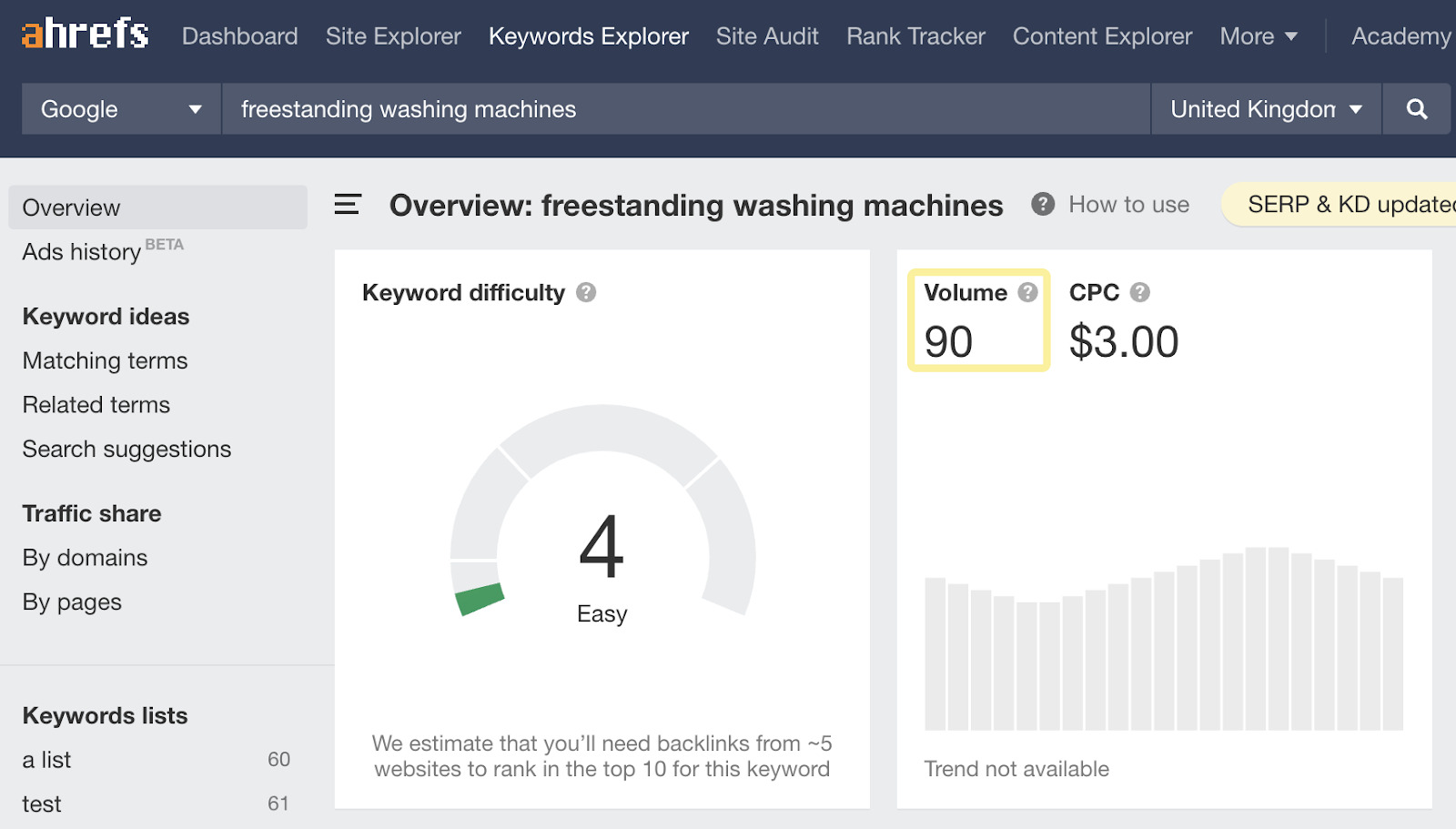
Mais est-ce qu’un utilisateur va un jour faire une recherche aussi précise sur Google ?
Bien évidemment que non.
Nous le savons parce que nous avons une estimation de recherche mensuelle estimée de seulement 90 pour “lave-linge non encastrable” au Royaume-Uni, il y a donc très peu (aucune ?) chances que quelqu’un fasse une recherche plus spécifique comme “grand lave-linge samsung non encastrable avec fonction lavage rapide et classe énergie A”
Avoir des pages indexées qui ne correspondent pas à une demande et recherche et qui sont de basse qualité peut potentiellement pousser un algorithme à avoir un impact négatif sur votre site
Gâchis de budget de crawl
Google ne peut dédier qu’un montant fini de ressources pour explorer les pages de votre site. C’est ce qu’on appelle le budget de crawl.
Gérer son budget de crawl n’est pas quelque chose que Google va considérer comme prioritaire à moins que vous ayez un énorme site (+1M pages uniques) ou grand (10k+ pages uniques) avec du contenu qui change rapidement.

Au vu de ce conseil, si vous n’avez que quelques milliers de catégories et produits, vous pourriez vous dire que vous n’avez pas besoin de vous inquiéter de votre budget de crawl.
Ce serait une grave erreur.
Certaines recherches à facettes vont créer des liens explorables pour chaque combinaison possible.
Sans parler des éventuels problèmes de gonflement de l’index, cela veut dire que vous allez potentiellement générer des millions d’URL à crawler par Google, vous allez vite devoir vous intéresser au budget de crawl.
Vous pouvez trouver un exemple sur le site de next.co.uk :
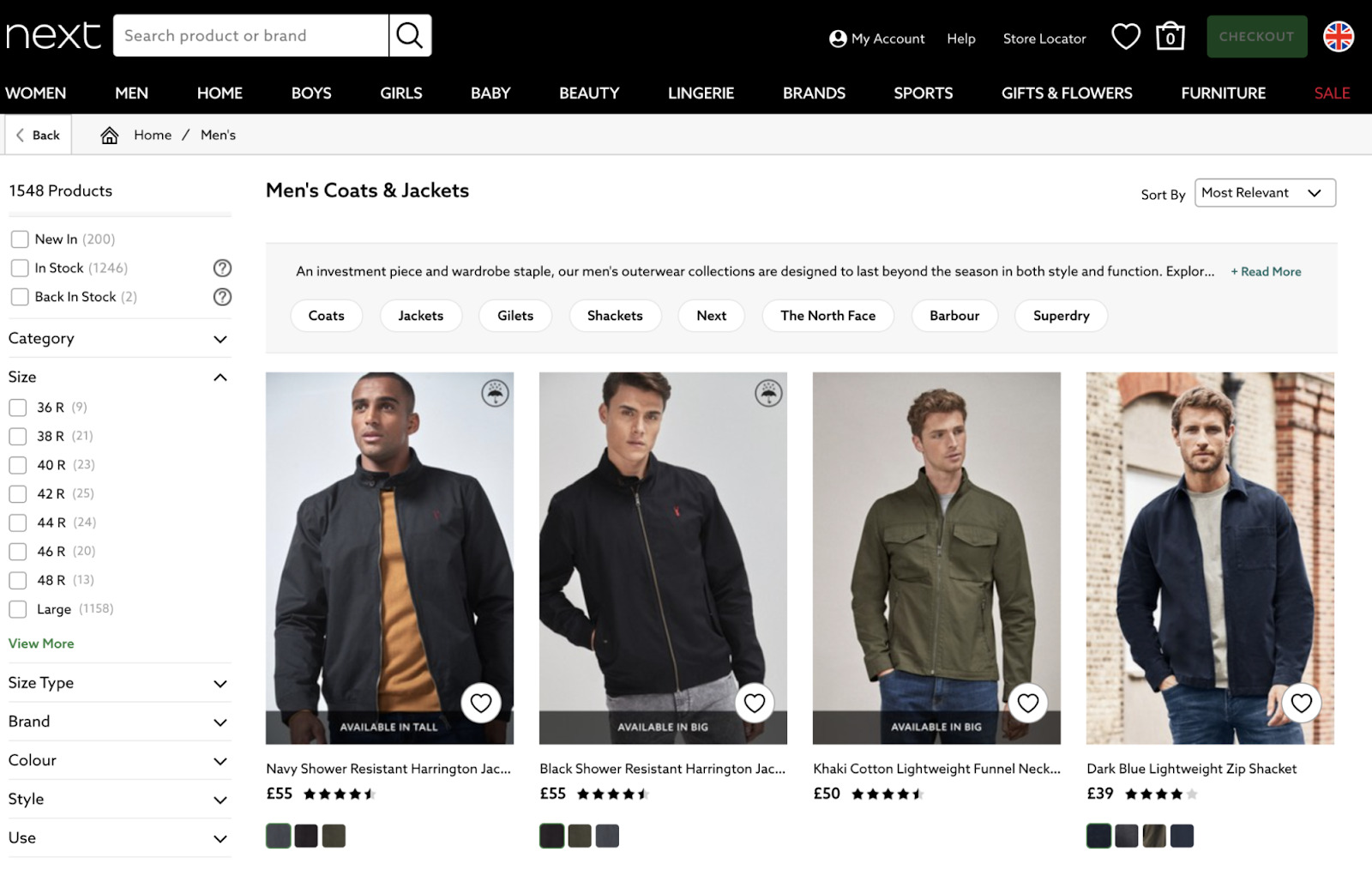
En inspectant le code HTML de la recherche à facette, vous verrez un lien :

Une fois que vous aurez suivi ce lien, vous pouvez vérifier le code HTML d’un autre résultat comme le bleu :

Vous voyez que la combinaison de ces facettes crée une nouvelle URL à crawler.
Prenez maintenant en compte les potentielles combinaisons de tous les filtres disponibles. Vous allez vite voir pourquoi une navigation à facettes peut poser des problèmes à un moteur de recherche.
Dilution du PageRank
La recherche à facettes peut aussi diluer le PageRank qui passe sur votre site.
C’est parce que le PageRank est divisé par le nombre total de liens sur la page. Le problème inhérent avec la recherche à facette est que cela crée un grand nombre de liens internes.
Donc au lieu de passer le PageRank vers vos produits ou catégories importantes, cela va l’envoyer vers des liens au sein de vos filtres, ce qui dans la plupart des cas ne va pas vous aider à améliorer le trafic organique.
Lecture recommandée : Google PageRank is NOT Dead: Why It Still Matters
Il y a toujours des signes évidents de problèmes liés à la recherche à facettes, voici quelques étapes à suivre pour voir si vos filtres font du mal à votre SEO.
1. Commencez par une recherche site :
Une excellente tactique pour vérifier le gonflement d’index rapidement est d’utiliser l’opérateur de recherche site :. Si ce n’est pas forcément très précis, c’est rapide et facile à faire.
C’est très simple : ajouter “site :” devant votre nom de domaine, comme ci-dessous.

Notez le nombre de résultats que remonte Google. Est-ce que cela vous semble plus élevé que le nombre d’URL que vous savez disponibles sur votre site ?
Si c’est le cas, c’est le premier signe d’un problème de gonflement de l’index.
2. Confirmez avec le rapport de couverture de la Google Search Console (GSC)
Le rapport de couverture de la GSC est un excellent moyen de repérer les problèmes de crawl et d’indexation rapidement.
Rendez-vous simplement dans le rapport “Couverture”dans GSC et sélectionnez “valides” sur le graphique pour avoir un nombre précis des pages indexées par Google :

Si cela vous semble élevé, ou que vous avez récemment mis en place une recherche à facette et que ça a crevé le plafond, cela tend vers un problème de gonflement d’index comme dit au-dessus.
Mais comment savoir si c’est à cause des filtres ?
Un bon sitemap va vous aider à diagnostiquer le problème. Si vous l’avez chargée dans la GSC, le tableau sous le graphique va diviser les URL en :
- Indexée, non soumise dans le sitemap
- Soumise et indexée
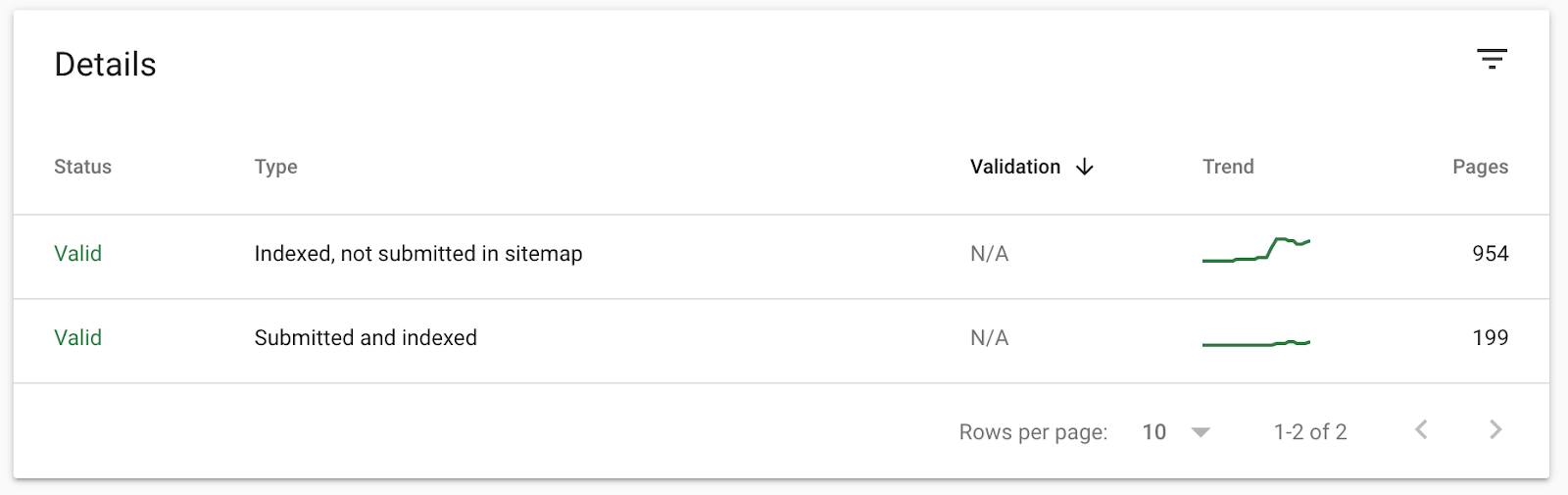
Cela veut dire que nous pouvons regarder les pages “Indexées, non soumises dans le sitemap” pour voir quelles sont les pages indexées par Google que vous ne voulons pas :

Cet exemple est un site de paris qui vous permet de filtrer par lieux et tournois. Nous voyons que Google indexe des URL non souhaitées.
Une autre méthode pour découvrir des problèmes potentiels est de filtrer par URL “Exclues” :

Analyser les URL “Explorées, actuellement non indexées” peut vous donner des informations sur les pages que Google a découvertes, mais a décidé de ne pas les indexer.
Google ne va pas indexer tout ce qu’il explore. Si les pages ne sont pas de bonne qualité comme la plupart des pages de facettes, il peut décider de ne pas les indexer.
Dans cet exemple, nous savons qu’il y a plus de 1000 pages que Google a découvertes qu’il pourrait indexer dans le futur. Nous voyons aussi les URL issues de Facettes en cliquant sur le rapport.

Ce qu’il y a au-dessus est un exemple relativement standard de problèmes issus de la recherche à facette mis en avant par la GSC. Au fil du temps, ces problèmes peuvent devenir des centaines de milliers d’URL découvertes, mais non indexées (ce qui va montrer les potentiels problèmes de crawl) :

Ou encore des centaines de milliers d’URL indexées alors qu’elles ne devraient pas l’être :

3. Obtenir plus de données avec un audit de site
Utiliser la recherche et la GSC est un très bon moyen pour obtenir des données rapides sur un problème, mais aucun ne vous montrera toutes les URL indexables/indexées, ce qui va rendre difficile de voir les corrélations et l’échelle du problème.
Un outil d’audit de site comme celui de Ahrefs peut vous aider à remédier à ce problème en vous donnant des informations détaillées sur les URL découvertes en explorant le site.
L’exemple ci-dessous est celui d’un site avec des problèmes de recherche à facette qui provoquent un gâchis de budget de crawl, vous pouvez les repérer en quelques clics.
Pour commencer, rendez-vous dans le rapport indexabilité dans la barre de gauche.

Ensuite, jetez un œil à la “distribution d’indexabilité” pour voir si quelque chose vous semble étrange.
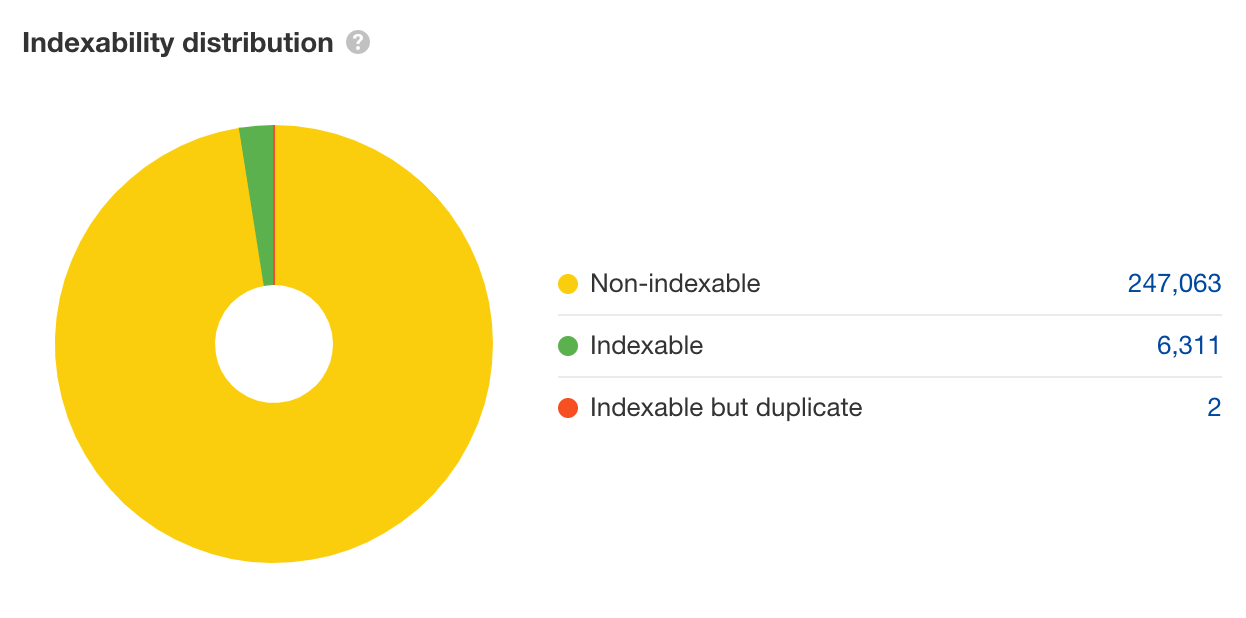
À partir d’un crawl partiel, l’Audit de site a trouvé 39 URL non indexable pour chaque URL indexable. Comme ce n’est qu’un crawl partiel, on peut s’attendre à ce que ce ratio entre indexable et non indexable va sans doute s’aggraver.
Ce que l’on voit au-dessus est un terrible gâchis de budget de crawl, c’est aussi un excellent exemple de piège à crawler : où des problèmes techniques vont créer un nombre quasi infini d’URL inutiles que les bots vont explorer.
Si votre recherche à facette provoque un gonflement de l’index (index bloat), le graphique que vous allez voir sera différent. Plutôt qu’un grand nombre d’URL non-indexable, vous verrez un grand nombre d’URL indexables comme sur ce que vous voyez en dessous.

Pour confirmer que c’est un problème lié à la recherche à facettes, sélectionnez la portion non indexable du graphique et analysez la liste. Vous verrez un tableau de toutes les pages non indexables explorées.
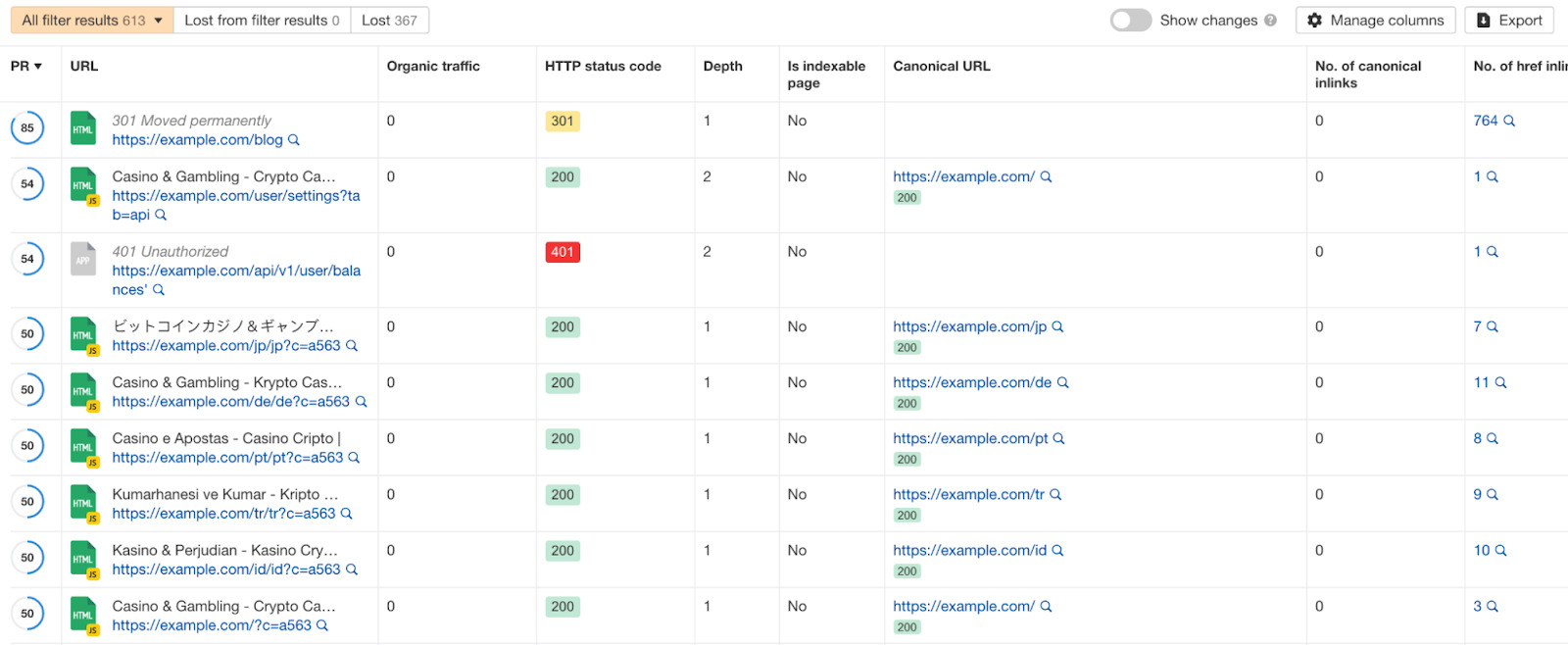
C’est ici que vous allez devoir trouver les points communs.
Qu’est-ce qui fait que les crawlers considèrent que ces pages ne sont pas indexables ?
Si la grande majorité des URL qui remontent dans le tableau sont issues des filtres, vous faites face à un problème de recherche à facette.
Maintenant que vous savez comment trouver les problèmes de recherche à facettes, voici comment les régler.
1. Corrigez l’indexation avec une balise canonique
Si vous rencontrez des problèmes d’indexation, mais pas de grave problème de budget de crawl (et n’avez pas un site immense), la meilleure solution est sans doute d’utiliser la balise canonique. Cela renforce les signaux de lien pour les pages similaires/dupliquées vers l’URL que vous définissez comme canonique.
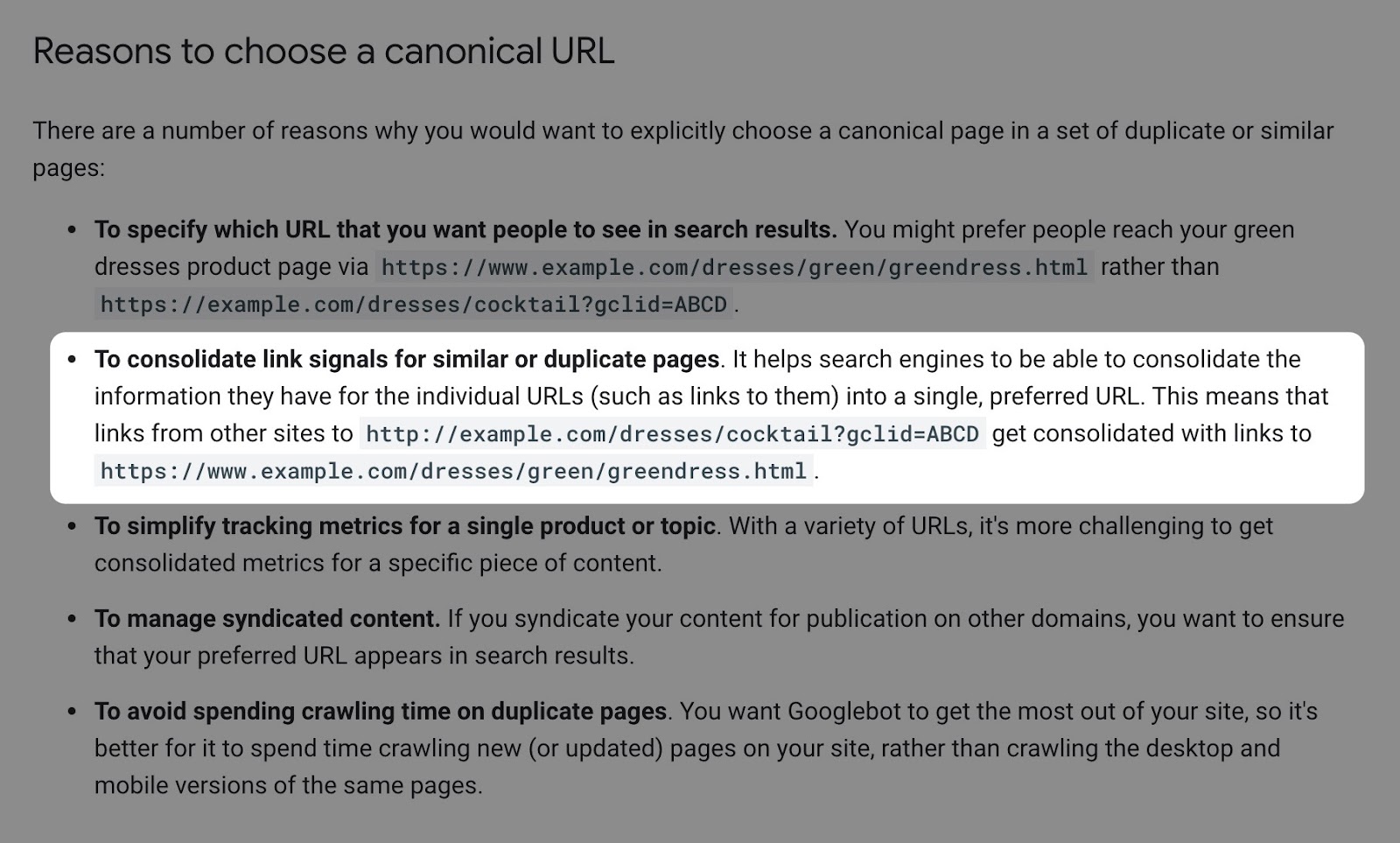
L’intérêt ?
Si vous avez des liens vers une page à facette, qui sont canonisées vers la page sans facette, les signaux de ces liens ne sont pas perdus. Les moteurs de recherche vont les renvoyer vers la page de catégorie, ce qui va les aider à bien se positionner.
Voici un exemple de comment faire…
Imaginons que ce soit l’URL de votre page de catégorie :
https://exemple.com/lave-linge/samsung/
Votre URL à facette fonctionne avec des paramètres, donc lorsque quelqu’un applique des filtres, l’URL ressemble à ceci :
https://exemple.com/lave-linge/samsung/?drumsize=16kg&color=silver&energyrating=A
Sur l’URL à facette au-dessus, vous pouvez simplement ajouter une balise canonique pour pointer vers la page catégorie, elle ressemblerait à ça :
<link rel="canonical" href="https://exemple.com/lave-linge/samsung/" />
Ou de cette manière dans vos headers HTTP :
Link : <https://exemple.com/lave-linge/samsung/>; rel="canonical"
Si cela semble simple et facile à faire pour un si gros problème SEO, comme toujours, il y a des problèmes potentiels. Le principal : que Google ignore votre balise canonique.
Tout simplement parce que les balises canoniques ne sont que des suggestions pour moteurs de recherche, pas des ordres. Si Google, pour une raison ou pour une autre, vient à penser que vous avez fait une erreur avec cette balise, il pourrait décider de l’ignorer.
Les raisons les plus fréquentes pour lesquelles Google peut décider d’ignorer votre balise canonique sont :
- Les pages ne sont pas dupliquées. Si vos pages à facettes changent de manière significative lorsque vous appliquez un filtre, Google va certainement penser que ce n’est pas du contenu dupliqué. Par exemple, si votre contenu, titres et header change, Google peut s’y perdre.
- Vous faites des liens internes vers les pages à facettes. Si vous avez beaucoup de liens internes qui pointent vers une page à facette qui a une page canonique,Google peut ignorer votre balise.
Si vous ne voyez pas le nombre d’URL valides dans votre rapport de couverture après avoir mis en place des balises canoniques, passez à l’étape 2.
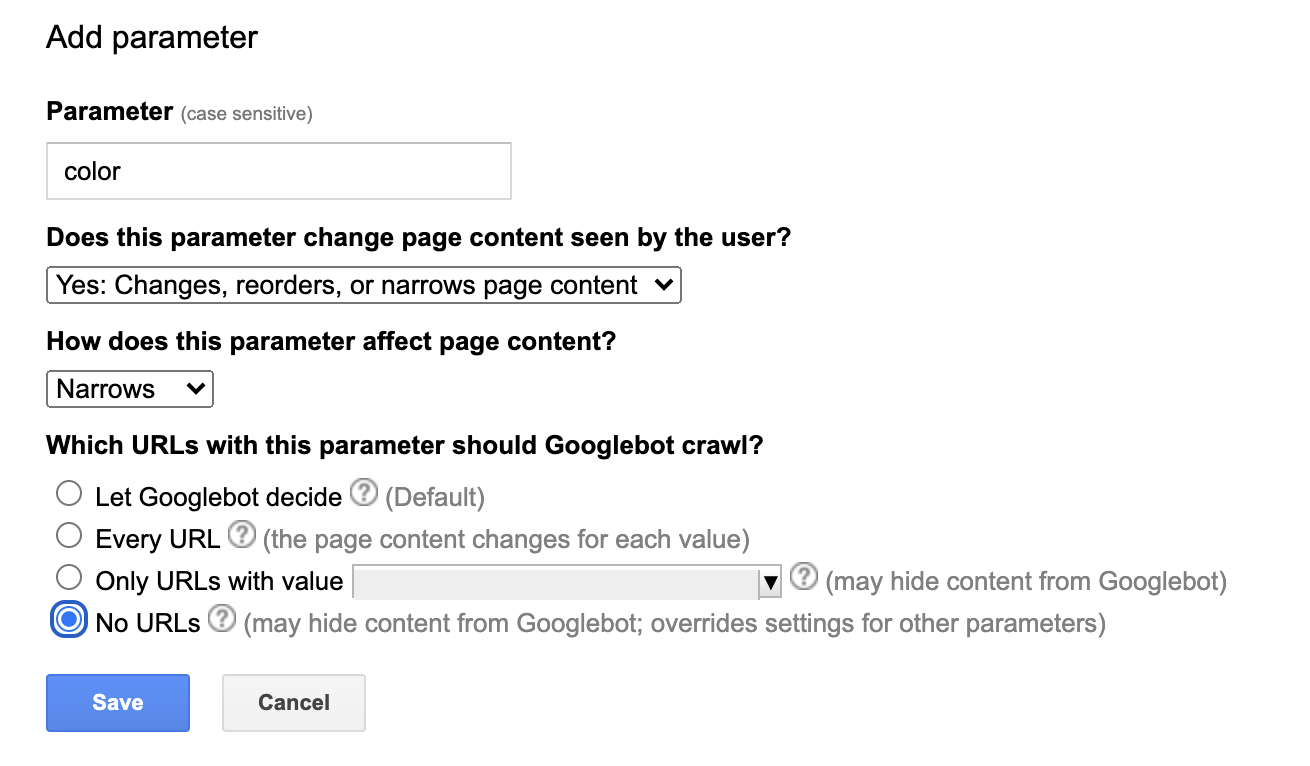
2. Utilisez le rapport de paramètre URL de la Search Console
Si la canonisation ne règle pas les problèmes d’indexation, le rapport de paramètres d’URL dans la GSC est sans doute votre meilleure chance d’optimiser le crawl. Cela vous permet de dire à Google comment gérer les paramètres d’URL pour une meilleure exploration.
Le point négatif de cette méthode est qu’elle ne fonctionne que si votre recherche à facettes utilise des paramètres d’URL (si ce n’est pas le cas, passez à l’étape 3).
L’utilisation du rapport de paramètre d’URL est relativement simple : ajoutez les paramètres, dites à Google comment cela affecte le contenu de la page et s’il existe des exceptions à la règle de ce qu’il devrait explorer.
3. Fix crawling with robots.txt
Si vous faites face à un problème de budget de crawl et que vous n’avez pas besoin de consolider les signaux, vous allez devoir utiliser robots.txt pour empêcher Google d’explorer les URL à facette.
Pour bloquer le crawl d’URL avec robots.txt, ajouter une règle disallow comme ci-dessous :
User-agent : *
Disallow: *size=*
Dans l’exemple ci-dessus, nous avons utilisé deux joker (*) autour des paramètres. Si votre navigation à facettes ne fonctionne pas en ajoutant des directories, votre règle devrait ressembler à ça :
User-agent : *
Disallow: */size/*
Il y a deux cas où le robots.txt ne va pas bien fonctionner :
- Vous n’avez pas de règle discernable dans le changement d’URL pour les disallow. Peut-être que chaque pas va avoir des paramètres uniques.
- Vous voulez autoriser certains patterns d’URL à être indexés et en bloquer d’autres. Par exemple, vous voulez peut-être que le répertoire /couleur/ puisse être crawlée pour la catégorie T-shirt (ça a un intérêt dans la recherche), mais voulez le désactiver pour la catégorie sous-vêtements. Si vous pourriez contourner cela en mélangeant des règles “Allow” et “Disallow” dans le robots.txt, cela peut vite devenir compliqué à gérer sur des sites à grande échelle.
Vous devez aussi savoir que bloquer le crawl ne va pas nécessairement empêcher Google d’indexer les URL bloquées. En règle générale, Google va retirer les URL bloquées de l’index, mais seulement si elles n’ont pas de backlinks et/ou beaucoup de liens internes qui y pointent. En d’autres termes, tant que rien d’autre ne signale à Google que ces URL ont de la valeur.
4. Retirez les liens internes vers les URL à facettes ou les passer en Nofollow
Si bloquer le crawling n’élimine pas complètement les problèmes d’indexation issus de la recherche à facettes, mettre les liens internes vers ces URL en nofollow pourrait régler le problème.
Il y a généralement deux sources à ces liens :
- Les liens de recherche à facettes. Par exemple, les liens au sein de votre navigation à facettes.
- D’autres liens sur votre site. Par exemple des articles de blog.
Pour les liens de recherche à facettes, appliquer un blanket nofollow est relativement simple quand on connaît les bases du code. Mais ce n’est peut-être pas la meilleure idée si vous avez des balises canonical sur les URL à facette et/ou des URL à facettes que vous voulez indexer. Si Google finit par ne pas explorer ces liens parce qu’ils sont en nofollow, cela peut provoquer des problèmes d’indexation.
L’alternative est de choisir une à une les facettes à mettre en nofollow. C’est un peu plus difficile à mettre en place d’un point de vue technique, mais peut valoir la peine si vous cherchez à viser des requêtes longue-traîne via la recherche à facettes (je vais développer plus bas).
Le principal problème de cette approche est qu’elle est moins utile depuis que Google a commencé à considérer le rel=’nofollow’ comme une indication, ce n’est pas une directive comme robots.txt.
Cela dit, Google va se servir du nofollow interne pour déterminer que l’URL avec l’attribut href en question n’est pas très importante et qu’elle n’est donc pas prioritaire.
John Mueller l’a confirmé :
[…] Nous allons continuer à nous servir de ces liens nofollow comme un signal pour nous dire que :
- Ces pages ne sont pas si intéressantes
- Google n’a pas besoin de les explorer
- Elles n’ont pas besoin d’être utilisées pour le positionnement ou l’indexation

Pour les liens qui se trouvent ailleurs sur votre site, votre meilleure chance reste de les retirer.
Vous pouvez trouver les liens internes qui pointent vers des URLS issus de facettes en utilisant l’Explorateur de site de Ahrefs :
- Entrez l’URL en question
- Rendez-vous dans le rapport Backlinks internes
- Filtrez les liens dofollow

Vous pouvez ensuite simplement chercher les liens internes “follow” sur votre site pour les retirer.
5. Corrigez définitivement l’indexation avec la balise noindex
Si vous avez toujours des problèmes d’indexation après avoir suivi les étapes ci-dessus, votre dernière chance est la balise noindex.
L’intérêt de la balise noindex est que c’est une manière sûre d’empêcher l’indexation des pages issues des facettes. Le problème est que cela ne va pas renforcer les signaux de ranking et, au fil du temps, Google pourrait arrêter d’explorer les liens internes sur une page noindex, ce qui veut dire ne pas faire passer de signal de ranking.
Mais cela reste une bonne méthode pour retirer les URL de facettes de l’index de Google si rien d’autre ne fonctionne.
Pour mettre cela en place, ajoutez simplement soit une balise de meta robots dans le <head> d’une URL Facette :
<meta name="robots" content="noindex">
Our le X-Robots header dans le header HTTP de votre URL facette :
X-Robots-Tag: noindex
Ensuite, vous devez retirer/ajuster tous les blocages de crawl pour l’URL dans le robots.txt ou l’outil de paramètres d’URL. SI vous ne le faites pas, Google ne verra jamais la directive noindex, donc la page restera indexée.
Lecture recommandée : Robots Meta Tag & X‑Robots-Tag: Everything You Need to Know
À la lecture des parties précédentes, vous avez dû vous rendre compte que corriger tous les problèmes potentiels liés à la recherche à facette n’est pas facile.
Toute approche pour corriger l’indexation ou l’exploration peut présenter de mauvais côtés ou des complications.
Mais il existe une meilleure méthode.
Imaginons que vous mettiez en place une nouvelle recherche à facettes ou que vous en créez une pour la première fois. Dans ce cas-là, pour pouvez circonvenir à tous les problèmes cités plus haut tout en soignant votre UX.
Voici comment y parvenir.
1. Utilisez AJAX et évitez les liens internes
Tout d’abord, construisez votre recherche à facettes avec AJAX et n’ajoutez pas de liens internes <a href=…>.
En faisant cela, vous allez améliorer l’expérience utilisateur car la page ne va pas se recharger à chaque nouveau filtre et Google ne verra pas de lien interne vers des pages à facette, ce qui veut dire :
- Qu’il ne va pas les explorer
- Elles ne seront donc pas indexées
- Ce qui évite la potentielle dilution de PageRank
Voici un exemple.
Nous avons intégré une recherche à facette dans le plugin WordPress WP Grid Builder sur une ressource que j’ai créée appelée la SEO Toolbelt.
Ça ressemble à ça :
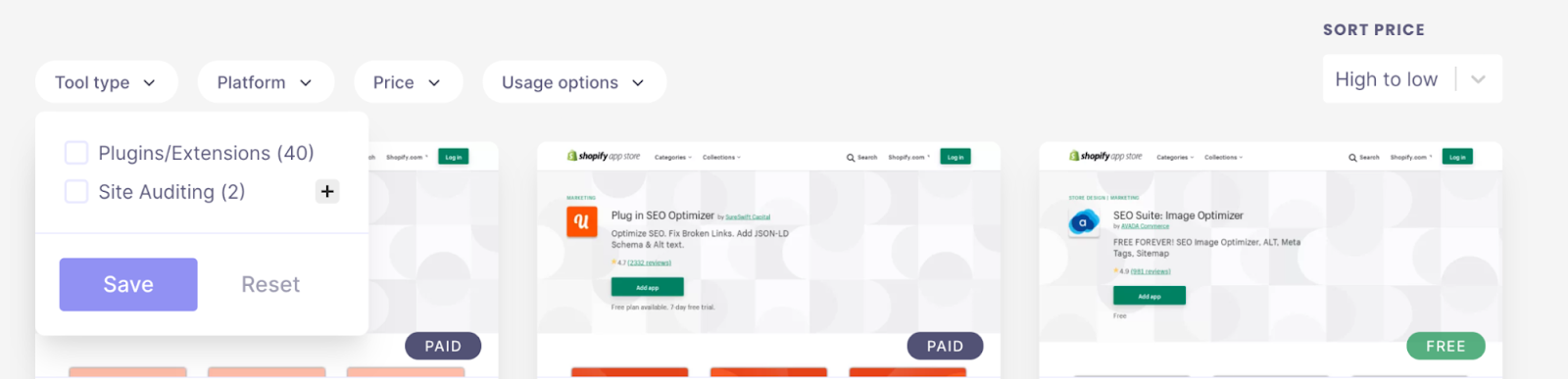
Lorsque vous faites clic droit et inspecter sur n’importe laquelle des cases pour appliquer un filtre, vous verrez qu’elles ne contiennent pas de lien<a href=…>, ce qui va empêcher Google d’explorer des URL supplémentaires.
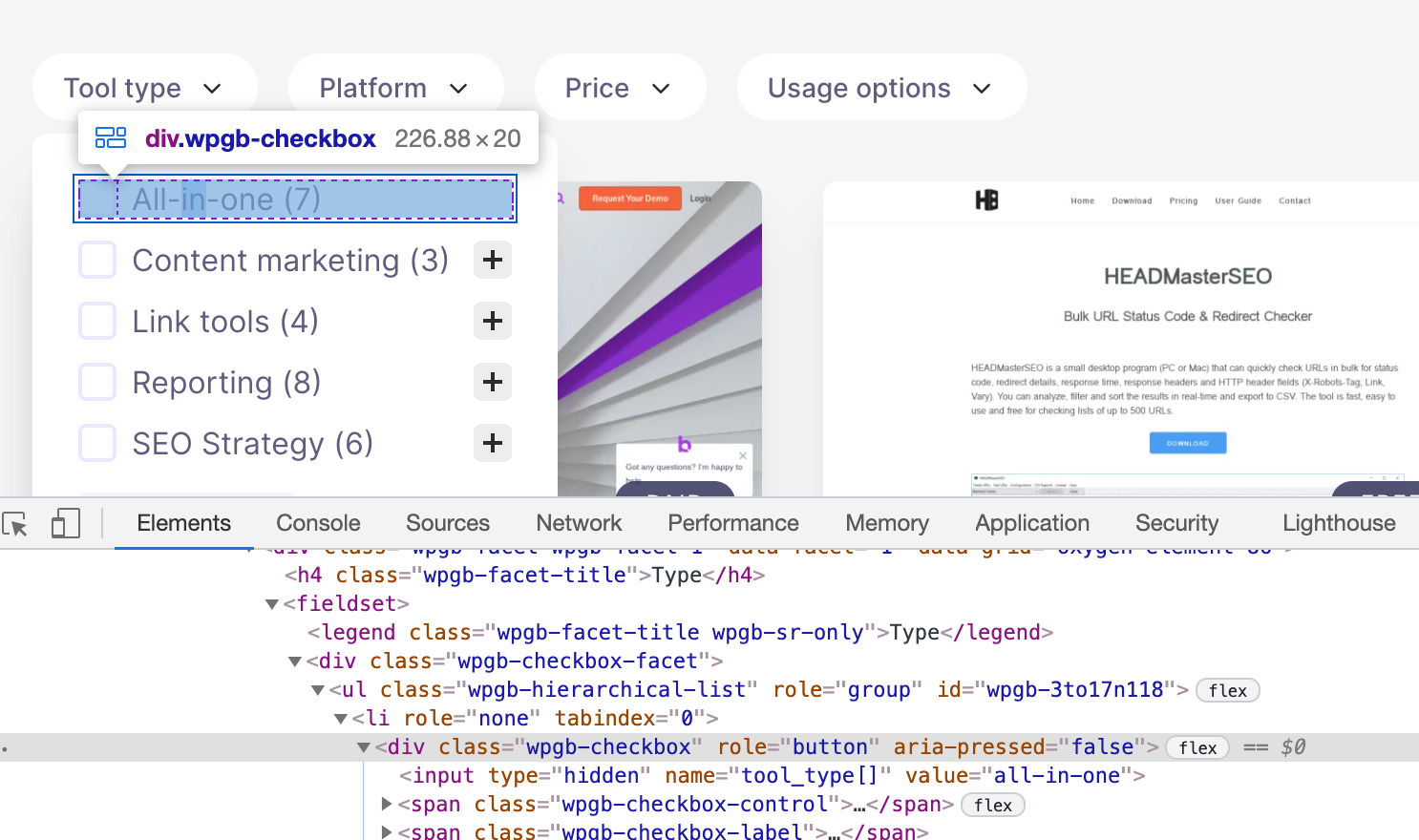
Ainsi, j’ai évité d’avoir à ne serait-ce que penser à la perte de budget de crawl à cause de la navigation à facettes.
2. Assurez-vous que les URL puissent être partagées
Ensuite, il faut s’assurer que lorsqu’un utilisateur clique sur un filtre, l’URL change.
Je recommande cette méthode car nous avons concrètement changé le contenu de la page et, dans l’idéal, si un utilisateur la met en favori, fait un lien vers la page ou partage l’URL avec un ami, cela va sélectionner les filtres et les appliquer directement lorsque le lien/favori/partage sera cliqué.
Il y a deux méthodes pour le faire :
- Paramètre d’URL (?)
- Hashes d’URL (#)
La meilleure solution est le hashes d’URL, Google a tendance à ignorer tout ce qui se trouve derrière le hash dans une URL.
WP Grid Builder utilise des paramètres, donc après avoir appliqué les filtres, l’URL change ainsi :
https://seotoolbelt.co/tools/auditing/?_tool_type=browser-extension
Si vous accédez à cette URL, vous verrez des grilles d’outils filtrés qui correspondent aux cases cochées.
Dans cet exemple, comme j’utilise des paramètres d’URL, je dois aussi ajouter une balise canonique à la version de l’URL sans les paramètres, celle-ci :
https://seotoolbelt.co/tools/auditing/
Comme ces versions paramétrées des URL ne reçoivent pas de lien interne et qu’il y a peu de chance qu’elles reçoivent des backlinks (ce qui serait le seul moyen pour Google de les trouver), nous avons peu de chance qu’elles posent problème.
3. Produisez des crawl path alternatifs pour les pages importantes
Dans certains cas, une version filtrée d’une page peut être intéressante pour la recherche organique.
Par exemple, il y a des filtres pour “Firefox” et “Chrome” sur ma page pour l’extension de navigateur SEO, ces deux pages ont du potentiel de recherche.
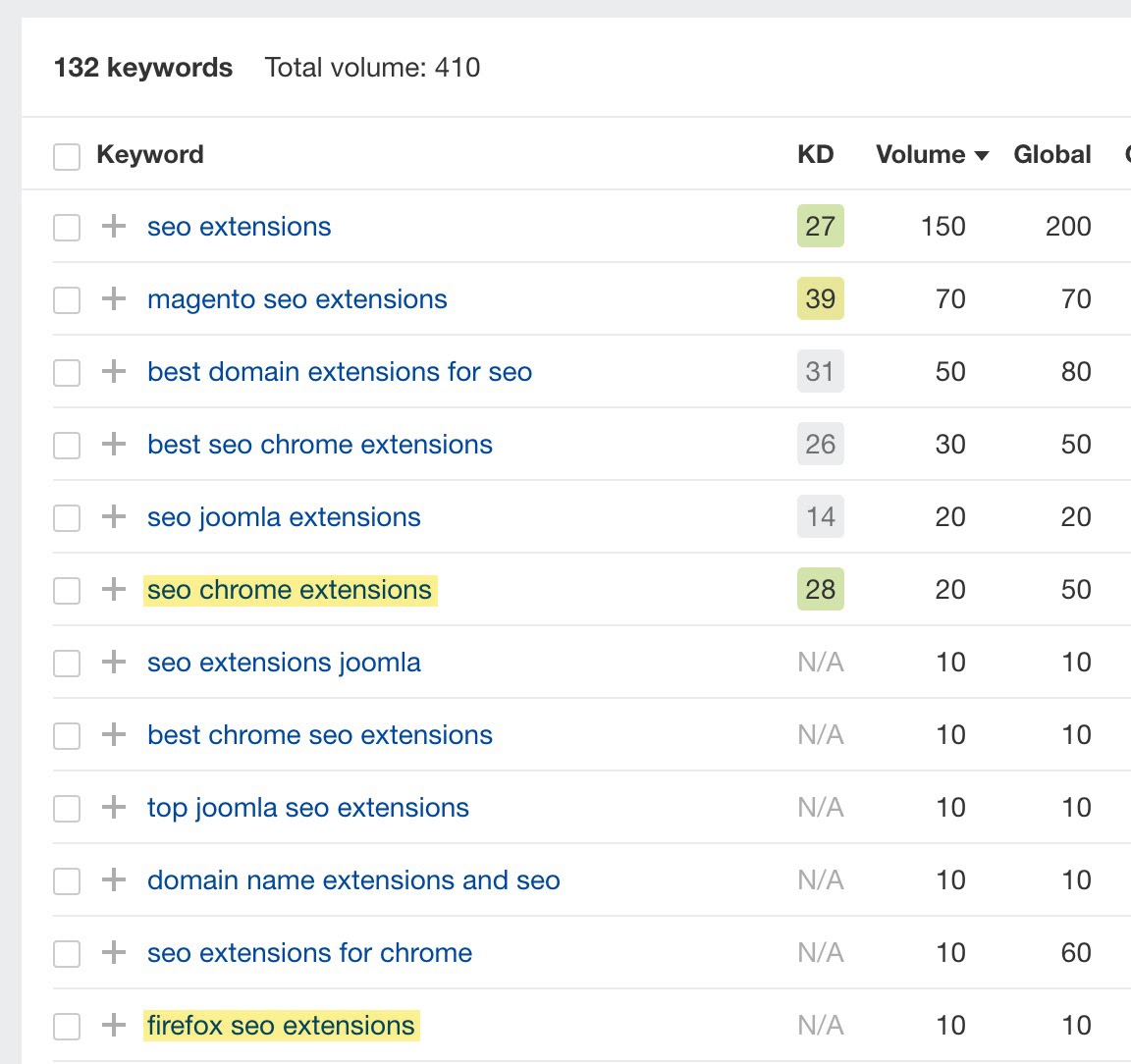
Il faut donc s’assurer que les URL créées soient indexables. Le meilleur moyen d’y parvenir est de mettre en place des chemins d’exploration (crawl paths) vers ces pages. J’ai fait cela en ajoutant des liens de sous-navigation à des versions indexables de ces pages filtrées en haut de page.

Ces “sous-filtrages” sont générés en se basant sur les mêmes attributs que la version à facette, mais je dois les générer consciemment.
Cela a permis plusieurs choses :
- J’ai empêché le gâchis de budget de crawl, puisque je ne fais pas de lien interne vers les pages filtrées
- Les pages filtrées restent partageables, ce qui est une bonne chose en UX
- Si une page filtrée a du potentiel de recherche, je peux manuellement permettre à la page d’être indexée.
Comme vous pouvez le voir, cela va grandement vous simplifier la vie en termes de SEO et n’a pas de désavantages.
Jusqu’ici, je n’ai fait que présenter la recherche à facettes que comme quelque chose qui implique des complications SEO. Mais elle peut aussi être utilisée pour attirer plus de trafic via une stratégie de mots-clés longue traîne.
Je ne peux qu’insister sur les incroyables bénéfices que cela peut attirer. Les données Ahrefs montrent que 99,84 % des mots-clés reçoivent moins de 1000 recherches par mois, et représentent 29,33% de la totalité de requêtes :

Les URL facettes sont idéales pour attirer du trafic longue traîne, car elles proposent des versions plus spécifiques des pages qui visent des requêtes plus larges.
Commençons par les étapes qui vont vous permettre de repérer les opportunités d’attirer plus de trafic longue-traîne. Ensuite, nous verrons comment implémenter des actions concrètes.
1. Identifier les variations longue-traîne de mots-clés
Pour commencer, vous allez devoir identifier les opportunités de mots-clés grâce à l’Explorateur de mots-clés Ahrefs. C’est extrêmement simple.
Entrez le nom d’une catégorie que vous avez déjà sur votre titre comme “jeans taille haute”
Allez dans le rapport “Matching Terms” (termes correspondants)
Utilisez la sidebar et changez l’onglet sur “Parent Topic” (sujet parent)
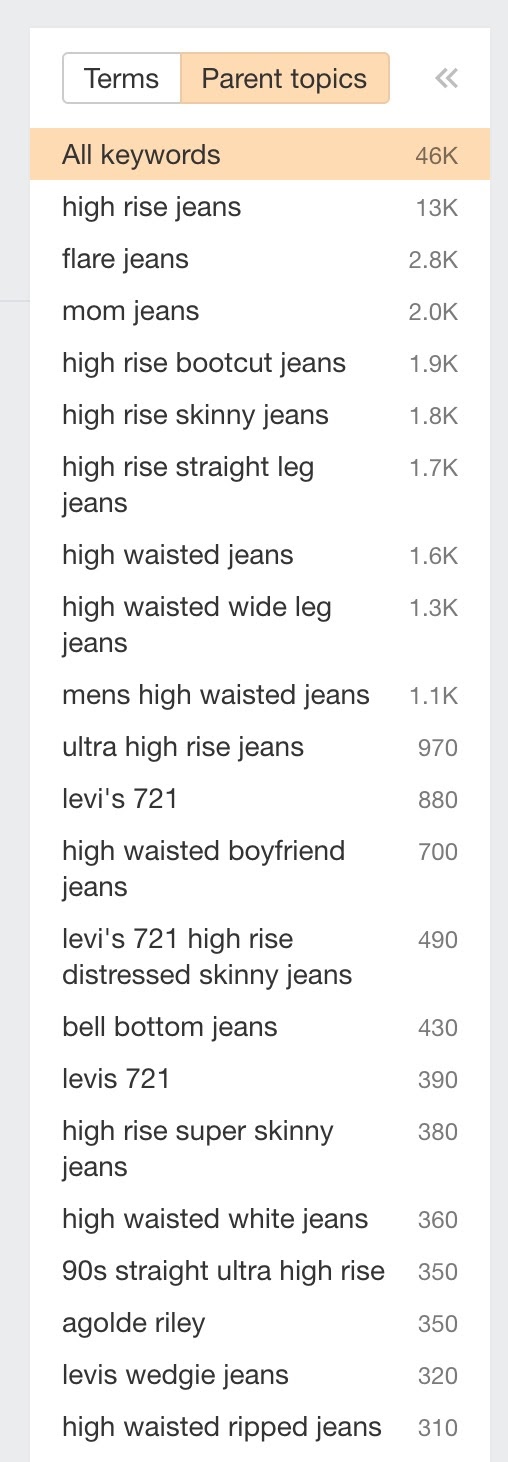
En faisant cela, l’outil va regrouper tous les mots-clés avec un SERP similaire ensemble. Vous pouvez ensuite analyser la liste pour choisir les pages facettées potentielles qu’il vaudrait le coup de faire indexer. En voici quelques-unes que j’ai repérées depuis la capture d’écran ci-dessus :
- high rise bootcut jeans (1 900 recherches)
- high rise skinny jeans (1 800 recherches)
- high rise wide leg jeans (1 300 recherches)
- ultra high rise jeans (970 recherches)
- high waisted boyfriend jeans (700 recherches)
- high rise super skinny jeans (380 recherches)
- high waisted white jeans (360 recherches)
2. Rendez ces pages indexables
Vous devez ensuite rendre les pages qui correspondent à ces filtres à la fois explorables et indexables par Google.
Ma méthode va dépendre de votre type de recherche à facette.
Recherche à facettes avec liens internes
Si vous avez intégré une recherche à facettes qui n’est pas configurée comme il le faudrait et qui a des liens internes vers chaque facette, vous avez besoin de vous assurer que pour chaque URL :
- La balise canonique est en self-reference
- La balise noindex est retirée (si applicable)
- Toutes les règles disallow applicables ont été retirées du robots.txt (ou que vous avez mis des règles allow)
- Tous les attributs nofollow ont été retirés des liens internes (si applicable)
Ce qu’il faut précisément faire dépend de la manière dont l’ensemble est configuré, mais ce qui est important est que les moteurs de recherche puissent explorer et indexer ces pages.
Recherche à facettes AJAX avec des liens internes
Vous allez avoir à créer des pages de sous-catégorie pour avoir une navigation à facette idéale comme mentionné dans la partie précédente.
C’est nécessaire parce que la recherche à facettes ne génère pas de liens internes, vous ne pouvez donc pas l’utiliser pour créer ces pages à votre place.
La plupart des plateformes de e-commerce rendent possible la création de sous-catégories, mais dans l’idéal il vous faut d’autres fonctionnalités sur lesquelles baser les sous-catégories de produit selon les filtres de la catégorie parente. C’est principalement pour éviter d’avoir à optimiser chaque sous-catégorie manuellement. Ainsi, vous aurez l’avantage de générer rapidement des pages, à la manière d’une recherche à facettes, tout en évitant les complications SEO.
Par exemple, si vous créez une catégorie “jeans taille haute slim”, nous allons vouloir hériter du listing de produits de “jeans taille haute”, mais qui ne montreront que les produits qui ont aussi l’attribut “slim” d’appliqué.
3. Optimisez les URL pour les recherches
C’est relativement évident, mais il faut passer par les fondamentaux de l’optimisation SEO, comme :
- Avoir des URL simples et lisible, dans l’idéal, votre URL serait :
/jeans/taille-haute/slim/, et non/jeans/taille-haute/?fit_variant=slim - Des balises title, meta description et de header optimisées
- Du contenu rédactionnel unique
- L’ajout des URL aux sitemaps XML
Les principales complications sont dans les configurations où vous retirez une page facettée hors des contrôles d’indexation et d’exploration par défaut.
C’est tout simplement parce que, techniquement, les pages facettées sont dynamiques par essence et donc différentes de la création d’une nouvelle sous-catégorie.
Des fonctionnalités personnalisées sont nécessaires pour paramétrer correctement ces optimisations on-page de première importance.
Conclusion
J’espère que vous avez bien compris les risques que peuvent représenter la recherche à facettes pour le SEO, mais aussi les belles opportunités qu’elle peut représenter pour les requêtes longue-traîne.
Vous avez des questions sur la recherche à facette ? Je suis sur Twitter.

