
Il y a encore plus de crawlers que Google utilise pour des tâches spécifiques, chacun va s’identifier avec un texte différent appelé “user agent”. Google bot est “evergreen”, c’est-à-dire qu’il voit les sites comme un utilisateur avec la dernière version de Chrome.
Googlebot tourne sur des milliers de machines. Elles déterminent à quelle vitesse et quoi explorer sur les sites. Mais les bots vont ralentir si leur exploration risque de submerger un site.
Voyons de plus près le processus pour la création d’un index du web.
Comment Google explore et indexe le web
Google a partagé quelques versions de son processus par le passé. Celui-ci est le dernier en date.

Il analyse cela de nouveau et regarde s’il voit des changements dans la page ou de nouveaux liens. Le contenu des pages rendues est stocké dans l’index de Google, dans lequel on fait des recherches. Tout nouveau lien trouvé va être renvoyé dans la liste d’URL à explorer.
Nous donnons plus de détails sur ce processus dans notre article sur comment fonctionnent les moteurs de recherche.
Comment contrôler Googlebot
Google vous donne quelques moyens pour contrôler ce qui va être exploré et indexé.
Moyens de contrôler l’exploration
- Robots.txt – Ce fichier sur votre site va vous permettre de contrôler ce qui est exploré.
- Nofollow – NoFollow est un attribut de lien ou meta robots tag qui suggère si un lien doit être suivi ou non. C’est considéré comme une recommandation qui peut être ignorée.
- Changer la fréquence de crawl – Cet outil dans la Google Search Console vous permet de ralentir le crawl de Google.
Moyens de contrôler l’indexation
- Effacer votre contenu – Si vous effacez une page, il n’y a plus rien à indexer. Le problème est que personne n’y a accès non plus.
- Restreindre l’accès au contenu – Google ne se logue pas aux sites, donc toute forme de protection par mot de passe ou authentification va l’empêcher de voir le contenu.
- Noindex – une balise meta robot noindex indique aux moteurs de recherche de ne pas indexer la page.
- Outil de retrait d’URL – le nom de cet outil de Google peut prêter à confusion, il fonctionne en cachant temporairement le contenu. Google va toujours le voir et l’explorer, mais les pages n’apparaîtront plus dans les résultats de recherche.
- Robots.txt (images uniquement) – Empêcher Googlebot Image d’explorer va empêcher l’indexation de vos images.
Si vous n’êtes pas sûr de quel outil de contrôle d’indexation utiliser, vous pouvez regarder notre tableau explicatif sur retirer des URL de la recherche Google.
Est-ce que c’est vraiment Googlebot ?
Beaucoup d’outils SEO et certains bots malveillants vont prétendre être Googlebot. Cela peut leur permettre d’accéder à des sites qui voudraient les bloquer.
Auparavant, vous auriez eu besoin de lancer un DNS lookup pour vérifier Googlebot. Mais, récemment, Google a simplifié tout cela en fournissant une liste d’IP publiques que vous pouvez utiliser pour vérifier que les requêtes viennent bien de Google. Vous pouvez comparer ces données à celles de vos logs serveur.
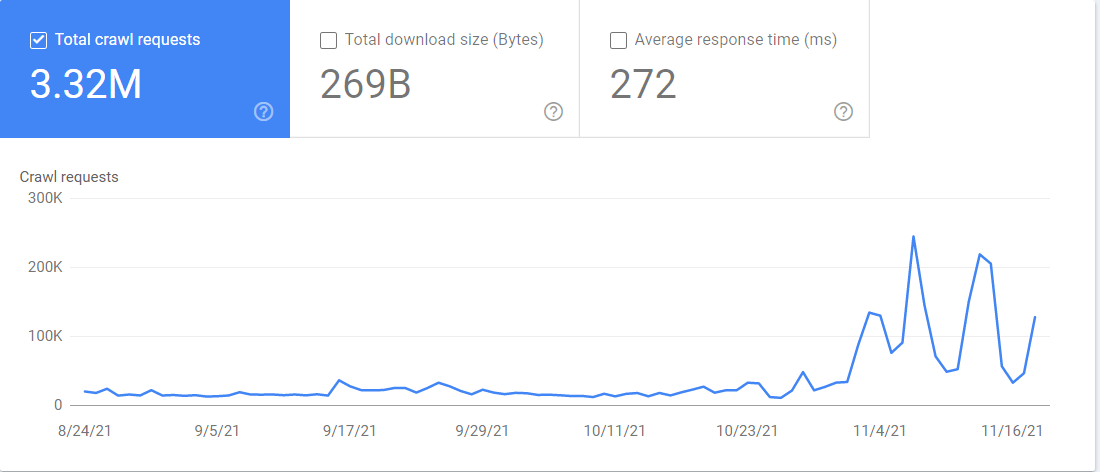
Vous pouvez aussi accéder au rapport “crawl stats” (statistiques d’exploration) dans la Google Search Console. Si vous allez dans Settings > Crawl stats, le rapport contient beaucoup d’informations sur comment Google explore votre site. Vous pouvez vérifier quel Googlebot crawle quels fichiers et quand il y a accédé.
Conclusion
Le web est un endroit immense et chaotique. Googlebot a besoin de naviguer à travers différentes configurations, avec des restrictions et des pannes de serveurs pour rassembler les données dont son moteur de recherche a besoin.
Pour l’anecdote amusante, Googlebot est généralement représenté par un robot logiquement appelé “Googlebot”. Il y a aussi une mascotte qui ressemble à une araignée et qui s’appelle “Crawley”.
Vous avez encore des questions ? Je suis sur Twitter.


