Chaque couche de données a ses avantages et ses inconvénients. Si vous vous êtes déjà demandé pourquoi une IA vous affirmait quelque chose d’incorrect avec une totale assurance, pourquoi un outil semble au courant de l’actualité de la semaine dernière alors qu’un autre est complètement à la traîne, ou pourquoi le produit de votre concurrent est cité partout tandis que le vôtre reste dans l’ombre : la réponse se trouve presque toujours dans la couche qui a traité votre question.
Je vous explique simplement d’où vient réellement la connaissance d’une IA, et pourquoi ça change tout à la confiance que vous pouvez accorder à une réponse.
Avant qu’un modèle d’IA réponde à la moindre question, il passe par une phase appelée l’entraînement.
Durant cette phase, le modèle ingère des milliards d’exemples de textes, d’images et de code : crawls du web public, livres, Wikipédia, dépôts de code, bases de données sous licence… et apprend à prédire des schémas logiques à travers toutes ces infos.
À la fin de l’entraînement, le modèle a mémorisé une sorte de photographie statistique de la connaissance humaine jusqu’à ce moment.
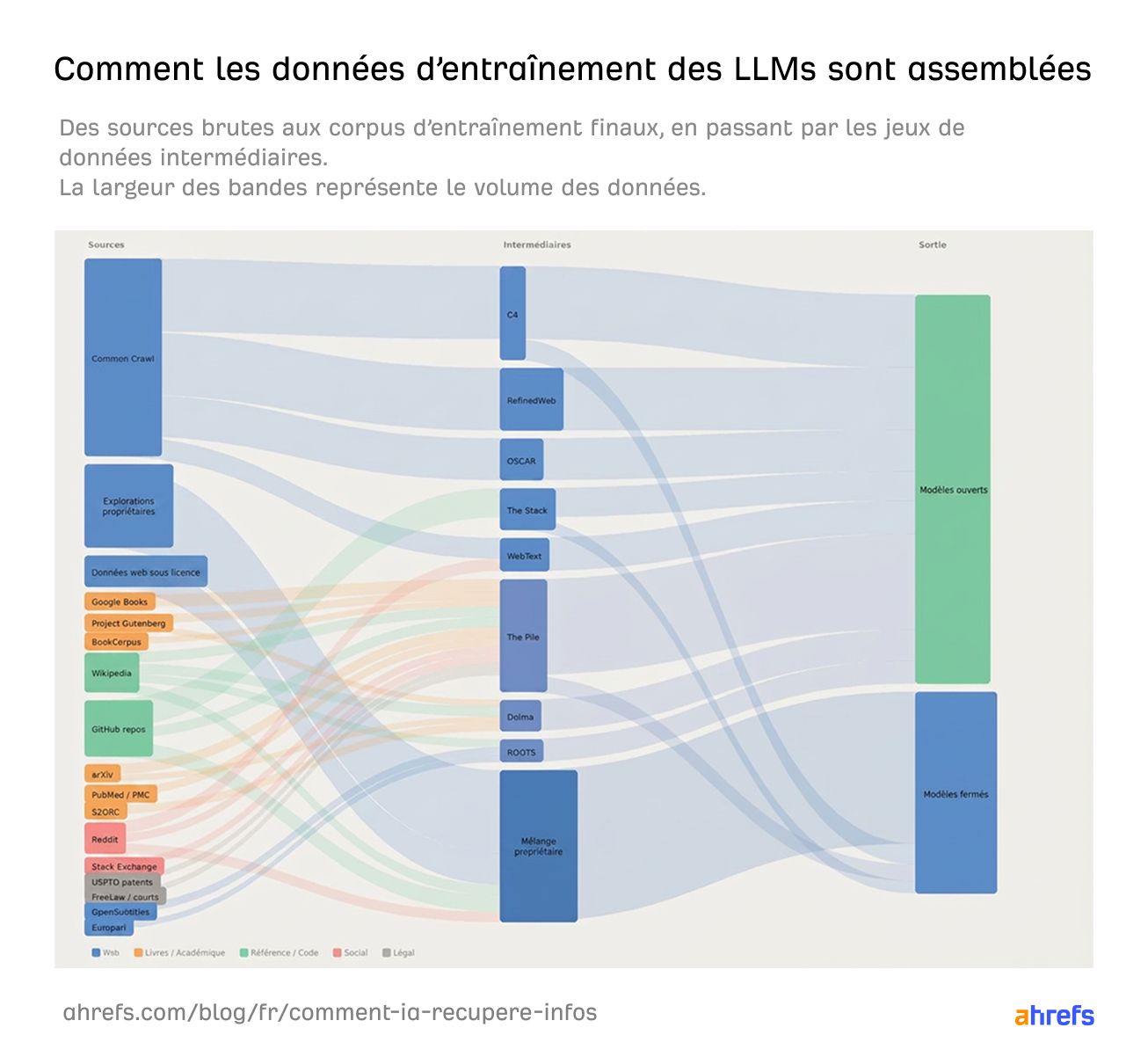
Infographie expliquant le fonctionnement des données d’entraînement des LLMs et la manière dont les modèles d’IA assemblent les informations issues du web et de la recherche en temps réel
C’est ainsi que les modèles d’IA développent leur « compréhension » du monde. La fréquence d’apparition d’entités dans les données d’entraînement (comme le nom de votre marque ou vos produits : pensez à « Decathlon » ou « Quechua »), ainsi que les mots qui leur sont souvent associés (comme « Accessible » ou « rapport qualité-prix »), façonnent la représentation que le modèle a de votre marque.
Comme l’explique Gianluca Fiorelli :
« Les LLM apprennent les relations entre votre marque et des concepts comme “sport” ou “réduction du bruit”. Ces associations sémantiques influencent directement si vous êtes mentionné et comment. »
Gianluca Fiorelli
L’échelle impliquée dans l’entraînement est presque difficile à imaginer. Les données d’entraînement des grands modèles se mesurent en milliers de milliards de tokens (grossièrement, des fragments de mots). Les coûts donnent une idée de ce que ça représente : l’entraînement de GPT-4 a coûté environ 78 millions de dollars et celui de Gemini Ultra de Google, environ 191 millions de dollars.
Le marché mondial des jeux de données d’entraînement pour l’IA pesait 3,2 milliards de dollars en 2025, et devrait atteindre 16,3 milliards d’ici 2033, soit un taux de croissance annuel de 22,6 %, ce qui reflète à quel point la donnée est devenue centrale dans toute cette industrie.
Voilà ce qu’il faut absolument comprendre : une fois l’entraînement terminé, la connaissance du modèle est gelée. Il ne peut pas apprendre de nouveaux événements. Il ne sait pas ce qui s’est passé hier, le mois dernier, ni après la date à laquelle ses données d’entraînement ont été arrêtées.
Certains fournisseurs affinent périodiquement leurs modèles sur des données plus récentes, mais c’est quand même un processus discret, plus proche d’une mise à jour logicielle que d’une lecture continue de l’actualité.
L’autre grand mode d’échec, c’est l’hallucination. Quand un modèle ne dispose pas de données d’entraînement fiables sur un sujet, il comble le vide avec quelque chose qui sonne plausible : une citation fabriquée, une statistique inventée, une réponse confiante mais fausse (comme cet AI Overview de Google qui citait un article satirique du 1er avril comme source factuelle).
Le modèle n’avait aucun moyen de savoir que l’article était une blague. Il avait juste l’air suffisamment sérieux pour correspondre au pattern.
La génération augmentée par récupération (Retrieval-Augmented Generation, RAG) est la principale technique utilisée pour contourner le problème de la date limite de connaissance.
Au lieu de s’appuyer uniquement sur ce que le modèle a appris pendant l’entraînement, le RAG lui permet de récupérer des documents pertinents au moment où une question est posée, puis d’utiliser ces documents comme contexte lors de la génération d’une réponse.
Imaginez la différence entre un examen à livre fermé et un examen à livre ouvert. Un modèle uniquement basé sur l’entraînement doit répondre de mémoire. Un modèle avec RAG peut d’abord chercher, puis répondre. Le résultat est plus actuel et, en principe, plus vérifiable, car la réponse s’appuie sur du contenu réellement récupéré plutôt que sur des correspondances statistiques de patterns.
On parle alors d’ancrage en français et de grounding en anglais.
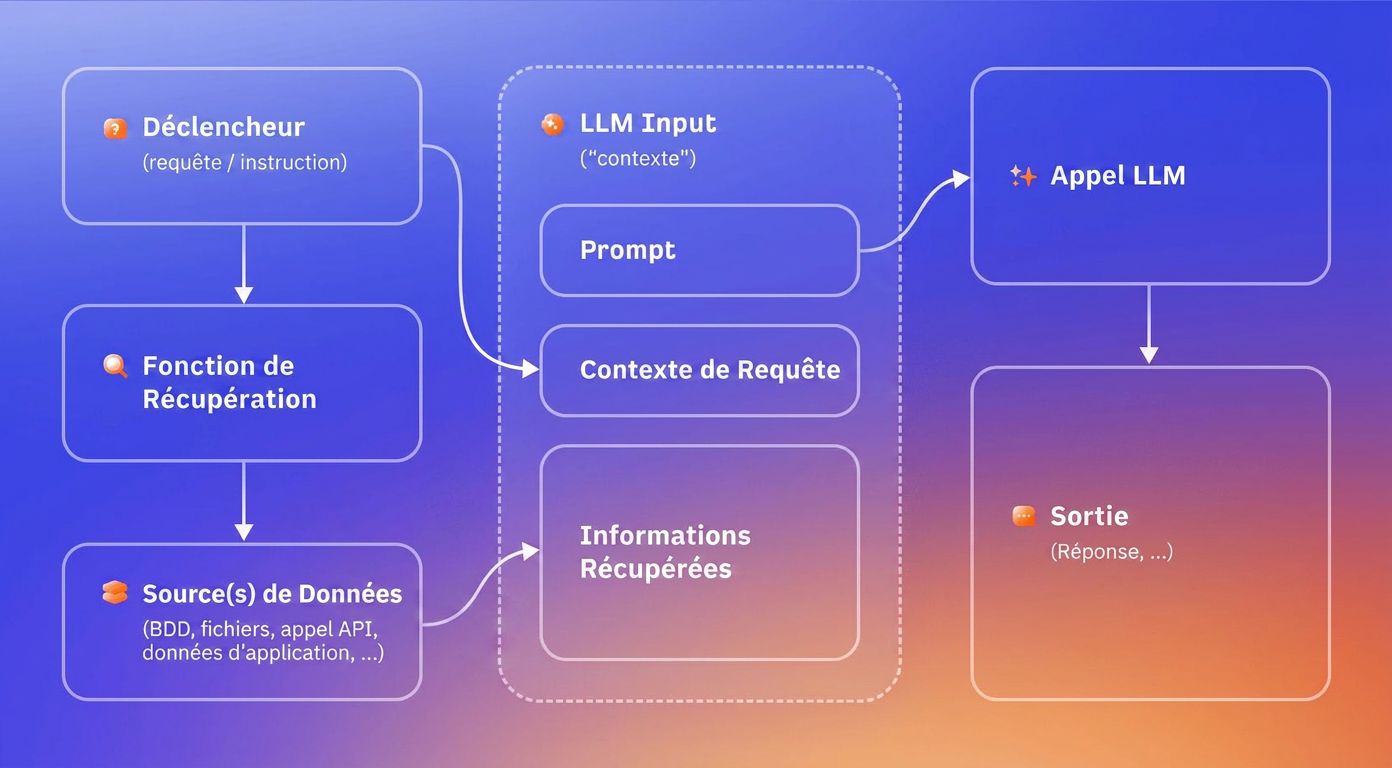
Schéma illustrant le fonctionnement du Retrieval-Augmented Generation (RAG) pour récupérer des données en temps réel et enrichir les réponses des assistants IA génératifs
« L’ancrage » (grounding) est le terme générique pour désigner ce rattachement. Quand une réponse d’IA est ancrée, elle est liée à des sources récupérées spécifiques, ce qui réduit considérablement le risque d’hallucination.
Comme l’explique Britney Muller :
« L’ancrage vient de “vérité terrain” (ground truth), ancré dans les statistiques et originellement dans la cartographie, où cela signifiait littéralement sortir sur le terrain pour vérifier que votre carte correspondait à la réalité. »
Britney Muller SEO +ML Consultant
Les moteurs de recherche IA comme ChatGPT et Gemini utilisent des index de recherche traditionnels comme Google et Bing pour ce processus d’ancrage.
C’est pourquoi un bon SEO, et un bon classement dans la recherche traditionnelle, améliorent également votre visibilité IA. Plus vous apparaissez haut dans l’index de recherche pour le terme recherché par l’IA, plus vous avez de chances d’être récupéré et cité dans la réponse.
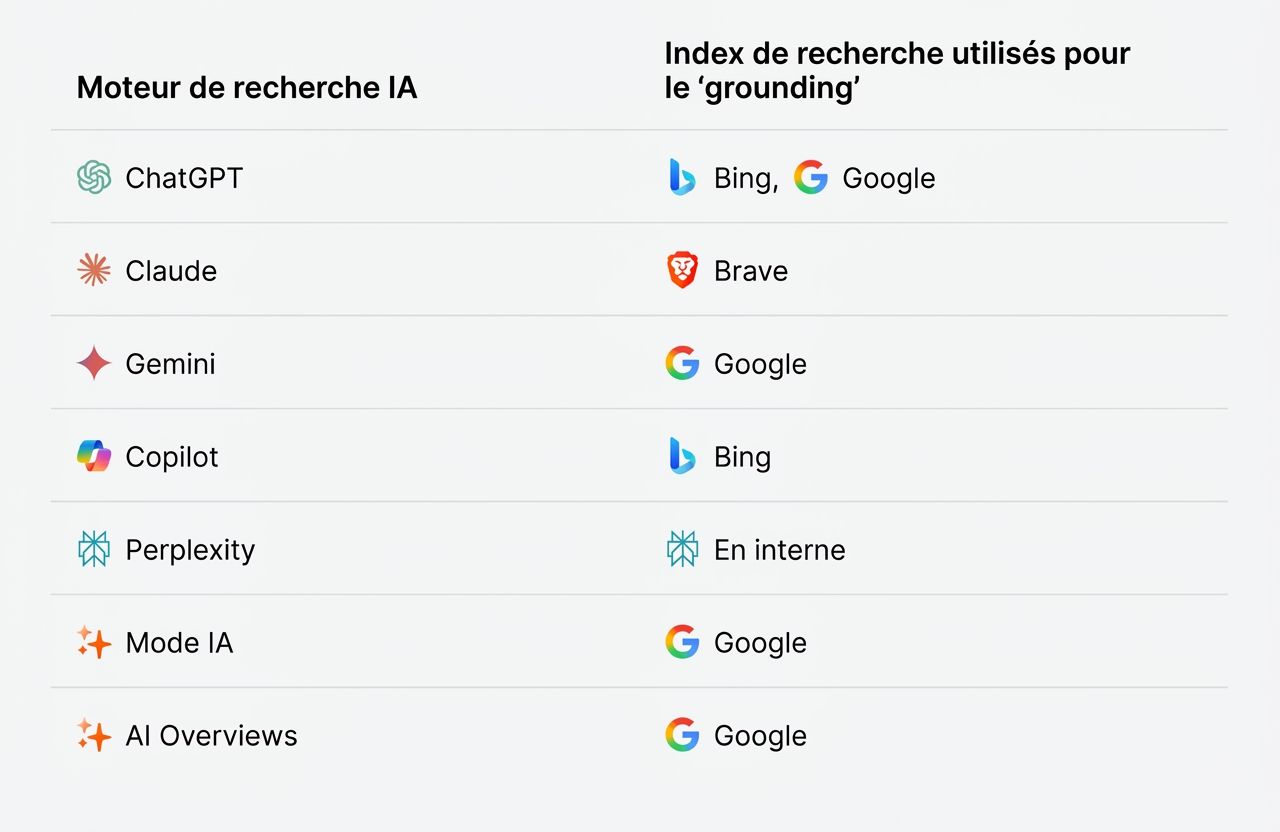
Tous les produits IA n’utilisent pas le RAG. Une session ChatGPT de base avec la navigation désactivée, par exemple, repose uniquement sur l’entraînement : elle n’a pas accès aux informations actuelles et ne peut pas vérifier ses réponses contre des sources en direct.
Le compromis, c’est la vitesse et la simplicité. Les réponses basées uniquement sur l’entraînement sont rapides, mais clairement datées. Le RAG ajoute de la latence et introduit un nouveau mode d’échec (les erreurs de récupération : récupérer la mauvaise source, ou une source de mauvaise qualité), mais il rend la fraîcheur possible.
Le RAG est une façon d’introduire des informations fraîches dans une réponse IA. Mais les systèmes IA modernes vont de plus en plus loin, en donnant aux modèles la capacité d’appeler des outils externes en pleine conversation. C’est le territoire des agents IA.
Un agent IA ne se contente pas de récupérer des documents : il peut interroger des API, lancer des recherches, exécuter du code et interagir avec des sources de données en direct dans le cadre d’une tâche.
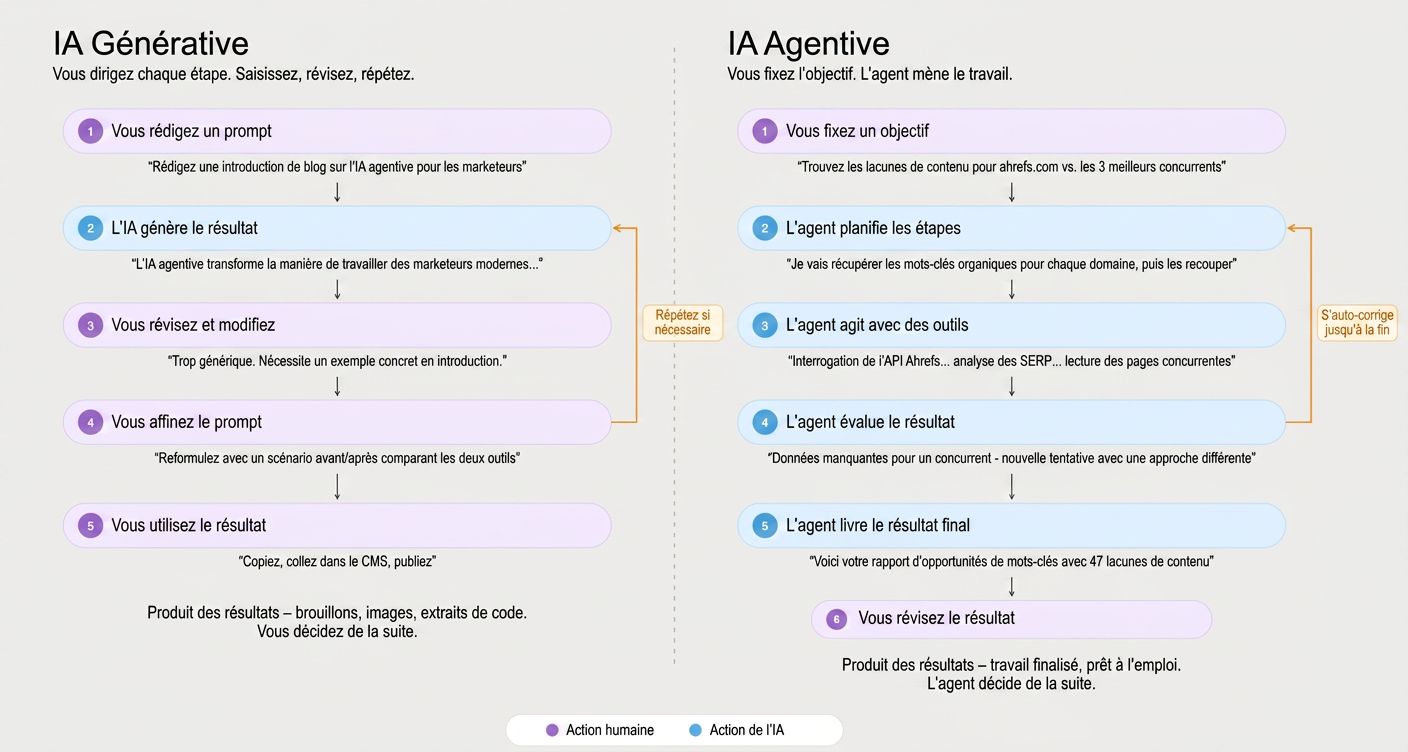
L’infrastructure émergente pour cela s’appelle le Model Context Protocol (MCP), un standard qui permet aux modèles IA de se connecter à des sources de données externes de façon structurée.
Un exemple concret : Ahrefs propose une intégration MCP qui permet aux agents IA d’interroger les données Ahrefs directement pendant une tâche, en récupérant des métriques de mots-clés, des données de backlinks ou des informations concurrentielles sans que l’utilisateur quitte son flux de travail.
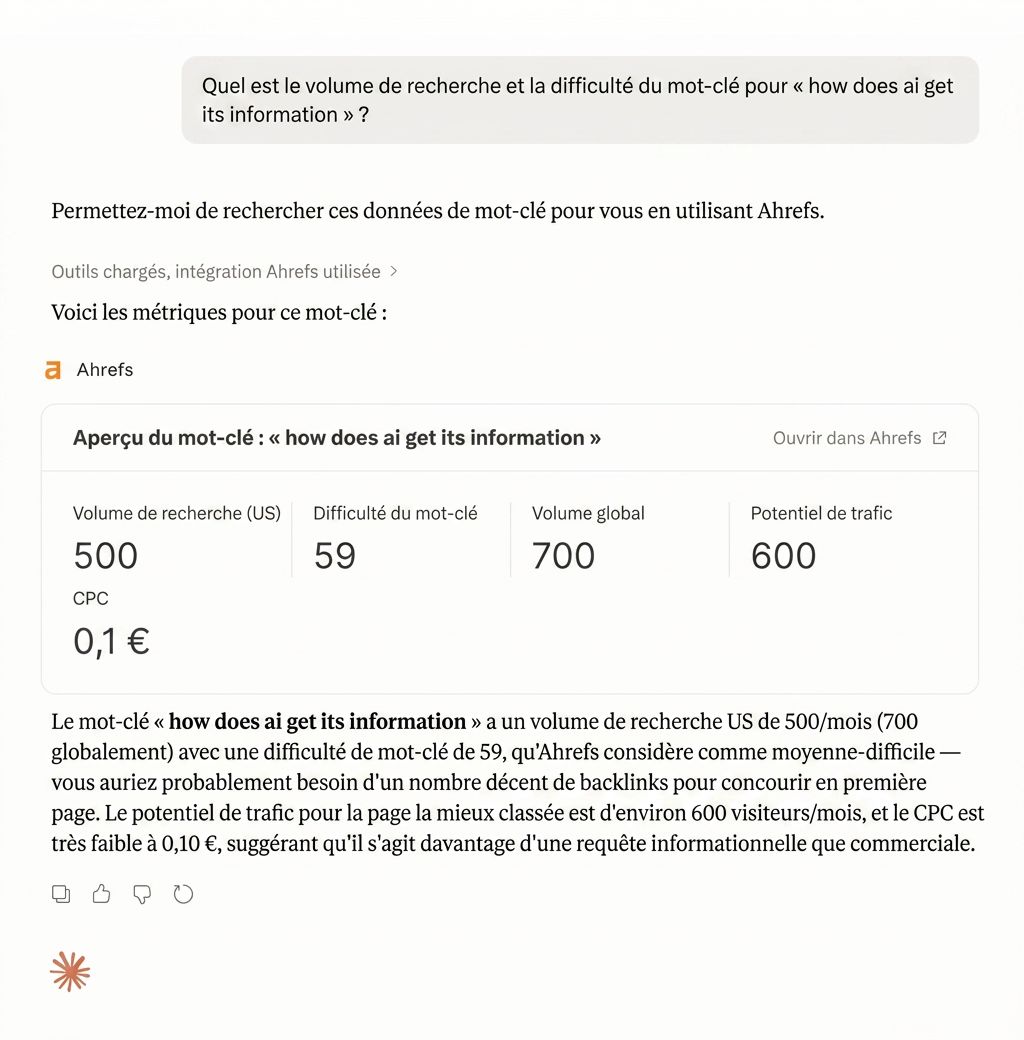
Exemple d’utilisation de Claude avec le serveur MCP d’Ahrefs pour récupérer et analyser des données SEO directement depuis un assistant IA génératif
Juliette vous partageait 15 utilisations du serveur MCP d’Ahrefs ici.
Agent A d’Ahrefs va encore plus loin. C’est un outil IA marketing avec un accès direct et illimité à l’ensemble des données d’Ahrefs : données de mots-clés, KPI SEO et GEO, intelligence concurrentielle, tout y est.
Plutôt qu’une IA qui estiment des insights SEO à partir de données d’entraînement (qui deviennent obsolètes) ou les récupérer depuis des sources publiques (qui sont incomplètes), Agent A travaille directement avec les données réelles.
Pour les tâches marketing et SEO en particulier, c’est une différence considérable : Agent A peut prendre en charge de nombreux workflows SEO et marketing, sans avoir besoin d’être guidé pas à pas.
Juliette vous partage une application créée avec Agent A sans compétence techniques :
Le principe général : une IA augmentée par des outils n’est fiable qu’à la hauteur des outils qu’elle appelle. Si l’API renvoie de mauvaises données, l’IA produit une mauvaise réponse, avec assurance. L’intelligence du modèle ne vous protège pas d’entrées médiocres. Ce qu’elle fait, en revanche, c’est étendre la portée du modèle bien au-delà de ce que n’importe quel jeu de données d’entraînement pourrait couvrir.
Quand vous comprenez comment l’IA récupère des infos, vous comprenez où votre marque doit être présente pour maximiser ses chances d’être citée.
Les mentions hors site. Si vous voulez que l’IA représente votre marque avec précision, le point de départ n’est pas votre site web, ce sont les mentions hors site.
Les modèles apprennent à connaître les marques à partir des sources sur lesquelles ils ont été entraînés : couverture presse, avis tiers, discussions sur les forums, entrées Wikipédia et citations dans des publications faisant autorité. Une marque qui n’existe que sur son propre domaine est largement invisible pour les données d’entraînement du modèle.
L’expansion de requêtes. Au-delà de la notoriété de marque, vous devez réfléchir à l’expansion de requêtes (requêtes fan-out), c’est-à-dire les questions adjacentes que les systèmes IA génèrent autour d’un sujet principal.
Une marque classée pour « logiciel de gestion de projet » devrait aussi cibler du contenu comme « comment animer une rétrospective de sprint » ou « agile vs. cascade », car ce sont les questions qu’un système IA va faire remonter quand un utilisateur approfondit la requête initiale. Créer du contenu qui couvre l’ensemble du voisinage sémantique de vos sujets principaux augmente vos chances d’apparaître dans cette expansion.
L’accessibilité pour les IA. L’accessibilité technique reste importante, elle aussi. Un HTML propre, des temps de chargement rapides et un fichier robots.txt bien configuré influencent la capacité des crawlers IA à lire votre contenu. Le llms.txt est un standard proposé pour aider les LLM à naviguer dans la structure de votre site, mais en 2026, aucun grand fournisseur de LLM n’a confirmé le respecter (inutile d’y passer du temps pour l’instant).
Pour mesurer concrètement comment tout ça fonctionne, Brand Radar d’Ahrefs suit la part de voix IA (AI Share of Voice) sur ChatGPT, Gemini, Perplexity, AI Overviews, Grok et bien d’autres, en montrant à quelle fréquence votre marque est mentionnée dans les réponses générées par l’IA par rapport à vos concurrents. Lisez cet article pour comprendre comment ça fonctionne.
Retenez bien que la connaissance d’une IA provient de trois couches : des données d’entraînement gelées, des documents récupérés en temps réel, et des outils externes connectés comme les API et les MCP. Chacune a un profil de précision différent, un rapport différent à la fraîcheur, et une façon différente d’échouer.
Les données d’entraînement constituent la fondation : vastes, coûteuses et statiques. Le RAG et l’ancrage ajoutent de la fraîcheur au prix de la fiabilité de la récupération. Les intégrations d’outils comme le MCP d’Ahrefs et les agents dédiés comme Agent A vont encore plus loin, en donnant à l’IA un accès à des données fiables et actualisées au moment précis où elle en a besoin.
Pour aller plus loin sur la façon dont les moteurs de recherche IA assemblent ces couches pour générer des réponses, consultez notre guide sur le fonctionnement des moteurs de recherche IA.

