
Googlebot est le crawler web utilisé par Google pour collecter les informations nécessaires à la construction d’un index de recherche. Googlebot dispose de crawlers mobile et desktop, ainsi que de crawlers spécialisés pour les actualités, les images, les vidéos, et bien plus encore.
Il existe d’autres crawlers que Google utilise pour des tâches spécifiques, et chaque crawler s’identifie avec une chaîne de texte différente appelée « user agent ». Googlebot est dit « evergreen », ce qui signifie qu’il voit les sites web comme le ferait un utilisateur avec la dernière version du navigateur Chrome.
134
Dans les chaînes user-agent, Chrome/W.X.Y.Z est un espace réservé qui correspond à la dernière version de Chrome utilisée par Googlebot.
Googlebot tourne sur des milliers de machines, qui déterminent la vitesse et le contenu à crawler sur les sites web. Il ralentit toutefois son activité pour ne pas surcharger les serveurs.
Googlebot est le crawler le plus rapide du web selon Cloudflare Radar, Ahrefsbot arrivant en deuxième position.
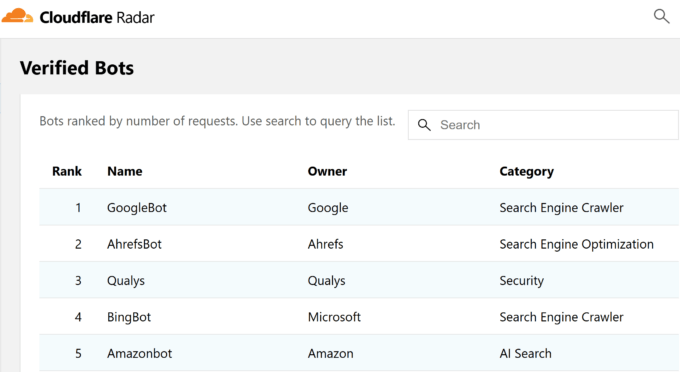
Si l’on regarde le pourcentage de requêtes HTTP, Googlebot représente 23,7 % de l’ensemble des requêtes provenant de bons bots. Ahrefsbot en représente 14,27 %, et pour comparaison, Bingbot atteint 4,57 % et Semrushbot 0,6 %.
Voyons maintenant comment Googlebot construit un index du web.
Google a partagé plusieurs versions de son pipeline par le passé. Voici la plus récente.

Google part d’une liste d’URL collectées depuis diverses sources : pages web, sitemaps, flux RSS, et URL soumises via Google Search Console ou l’Indexing API. Il priorise ce qu’il souhaite crawler, récupère les pages et en stocke des copies.
Ces pages sont ensuite traitées pour y trouver de nouveaux liens, notamment vers des requêtes API, du JavaScript et des fichiers CSS dont Google a besoin pour restituer la page. Toutes ces ressources supplémentaires sont crawlées et mises en cache. Google utilise un service de rendu qui s’appuie sur ces ressources mises en cache pour voir les pages comme le ferait un utilisateur.
Le contenu est traité une nouvelle fois pour détecter d’éventuels changements ou de nouveaux liens. C’est le contenu de la version mobile des pages rendues qui est stocké et consultable dans l’index de Google. Tout nouveau lien trouvé rejoint le réservoir d’URL à crawler.
Pour en savoir plus sur ce processus, consultez notre article sur le fonctionnement des moteurs de recherche. Si vous vous intéressez aux aspects liés au rendu, lisez notre article sur le JavaScript SEO.
Google vous propose plusieurs façons de contrôler ce qui est crawlé et indexé.
Comment contrôler le crawl
- Robots.txt : ce fichier présent sur votre site vous permet de contrôler ce qui est crawlé.
- Nofollow : nofollow est un attribut de lien ou une balise meta robots qui suggère à Google de ne pas suivre un lien. Il s’agit simplement d’une indication, qui peut donc être ignorée.
- Modifier la vitesse de crawl (obsolète) : cet outil dans Google Search Console permettait de ralentir le crawl de Google, mais il a été abandonné.
Comment contrôler l’indexation
- Supprimer votre contenu : si vous supprimez une page, il n’y a plus rien à indexer. L’inconvénient, c’est que personne d’autre ne peut non plus y accéder.
- Restreindre l’accès au contenu : Google ne se connecte pas aux sites web, donc toute protection par mot de passe ou authentification l’empêchera d’accéder au contenu.
- Noindex : un noindex dans la balise meta robots indique aux moteurs de recherche de ne pas indexer votre page.
- Outil de suppression d’URL : le nom de cet outil Google est légèrement trompeur, car son fonctionnement consiste à masquer temporairement le contenu. Google continuera à voir et à crawler ces pages, mais elles n’apparaîtront pas dans les résultats de recherche.
- Robots.txt (images uniquement) : bloquer Googlebot Image du crawl signifie que vos images ne seront pas indexées.
Si vous ne savez pas quel dispositif de contrôle de l’indexation utiliser, consultez notre organigramme dans notre article sur la suppression d’URL des résultats Google.
Pour plus de détails sur la façon dont Googlebot détermine ce qu’il crawle et à quelle vitesse, consultez notre article sur le crawl budget.
Voici quelques informations techniques sur Googlebot qui peuvent vous aider à résoudre divers problèmes.
Localisation
Googlebot crawle principalement depuis Mountain View, en Californie, sur la côte Pacifique des États-Unis. Google dispose néanmoins d’options de crawl spécifiques à certaines zones géographiques, qui peuvent être utilisées dans des situations particulières, par exemple lorsque des sites web bloquent le crawl depuis les États-Unis.
Taille maximale des fichiers
Pour la plupart des types de fichiers, Google récupère les 15 premiers Mo de chaque fichier. Pour les fichiers robots.txt, la taille maximale est de 500 kibioctets (Kio).
Protocoles de transfert supportés
Googlebot prend en charge HTTP/1.1 et HTTP/2, et choisit celui qui offre les meilleures performances de crawl pour votre site. Il peut également crawler via FTP et FTPS, mais c’est rare.
Encodage du contenu (compression)
Googlebot prend en charge gzip, deflate et Brotli (br).
Mise en cache HTTP
Google prend en charge les standards de mise en cache tels que les réponses ETag et Last-Modified, ainsi que les en-têtes de requête If-None-Match et If-Modified-Since.
De nombreux outils SEO et certains bots malveillants se font passer pour Googlebot. Cela peut leur permettre d’accéder à des sites web qui tentent de les bloquer.
Par le passé, il fallait effectuer une recherche DNS pour vérifier Googlebot. Récemment, Google a simplifié la démarche en fournissant une liste d’adresses IP publiques permettant de vérifier que les requêtes proviennent bien de Google. Vous pouvez comparer ces données avec celles de vos logs serveur.
Vous avez également accès au rapport « Statistiques de crawl » dans Google Search Console. En allant dans Paramètres > Statistiques de crawl, vous trouverez de nombreuses informations sur la façon dont Google crawle votre site. Vous pouvez voir quel Googlebot crawle quels fichiers et à quel moment.
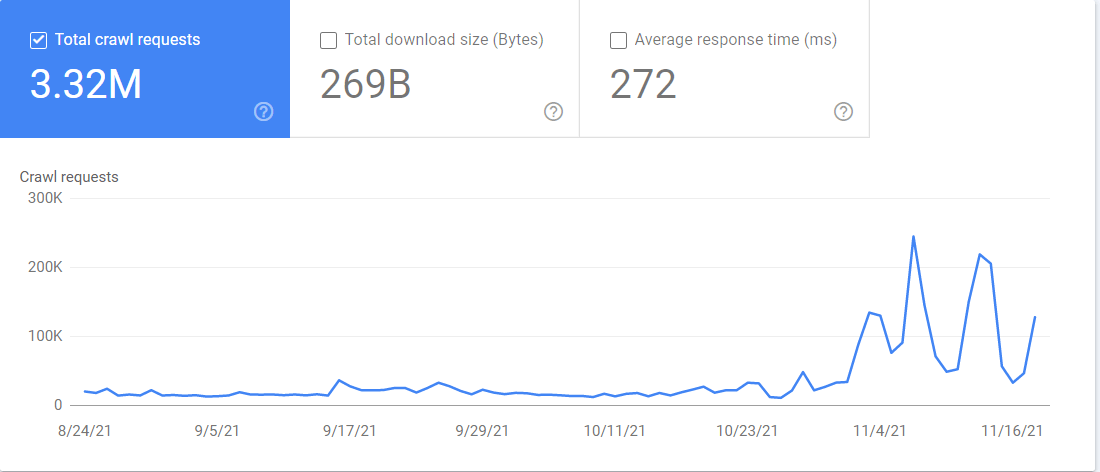 Statistiques de crawl dans Google Search Console
Statistiques de crawl dans Google Search ConsoleLe web est un endroit vaste et complexe. Googlebot doit naviguer parmi toutes sortes de configurations, de pannes et de restrictions pour collecter les données dont Google a besoin pour faire fonctionner son moteur de recherche.
Pour finir sur une note légère : Googlebot est généralement représenté sous la forme d’un robot et porte logiquement le nom de « Googlebot ». Il existe aussi une mascotte araignée appelée « Crawley ». D’après Lizzi Harvey de Google, cette araignée a également un nom non officiel : « Dex », diminutif d’Index.
Des questions ? N’hésitez pas à les poser sur Twitter.


