There’s a cost to bots crawling your websites and there’s a social contract between search engines and website owners, where search engines add value by sending referral traffic to websites. This is what keeps most websites from blocking search engines like Google, even as Google seems intent on taking more of that traffic for themselves. This social contract extends to generative engines.
When we looked at the traffic makeup of ~35K websites in Ahrefs Analytics, we found that AI sends just 0.1% of total referral traffic—far behind that of search.
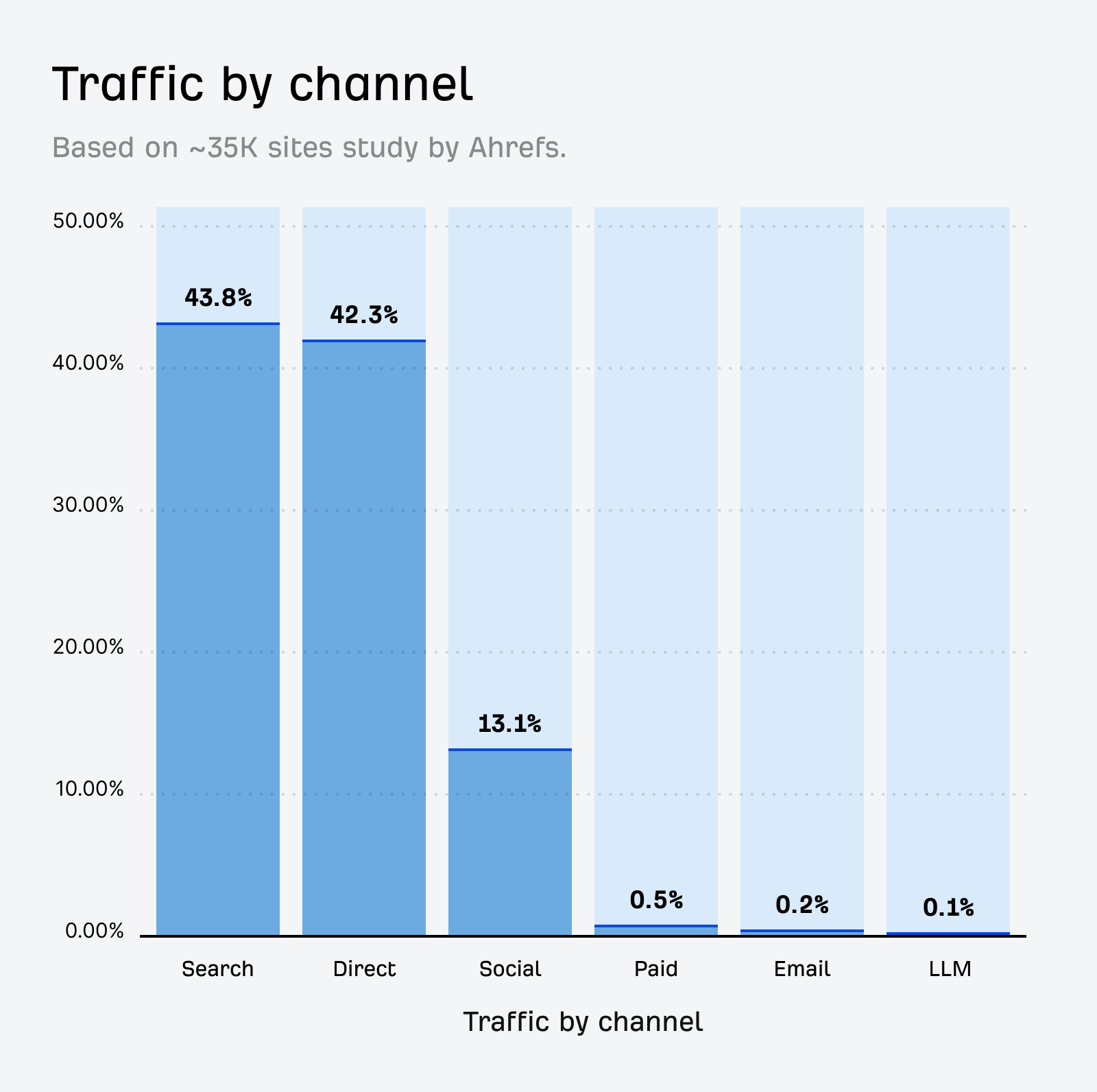
I think many site owners want to let these bots learn about their brand, their business, and their products and offerings. But while many people are betting that these systems are the future, they currently run the risk of not adding enough value for website owners.
The first LLM to add more value to users by showing impressions and clicks to website owners will likely have a big advantage. Companies will report on the metrics from that LLM, which will likely increase adoption and prevent more websites from blocking their bot.
The bots are using resources, using the data to train their AIs, and creating potential privacy issues. As a result, many websites are choosing to block AI bots.
We looked at ~140 million websites and our data shows that block rates for AI bots have increased significantly over the past year. I want to give a huge thanks to our data scientist Xibeijia Guan for pulling this data.
- The number of AI bots has doubled since August 2023, with 21 major AI bots now active on the web.
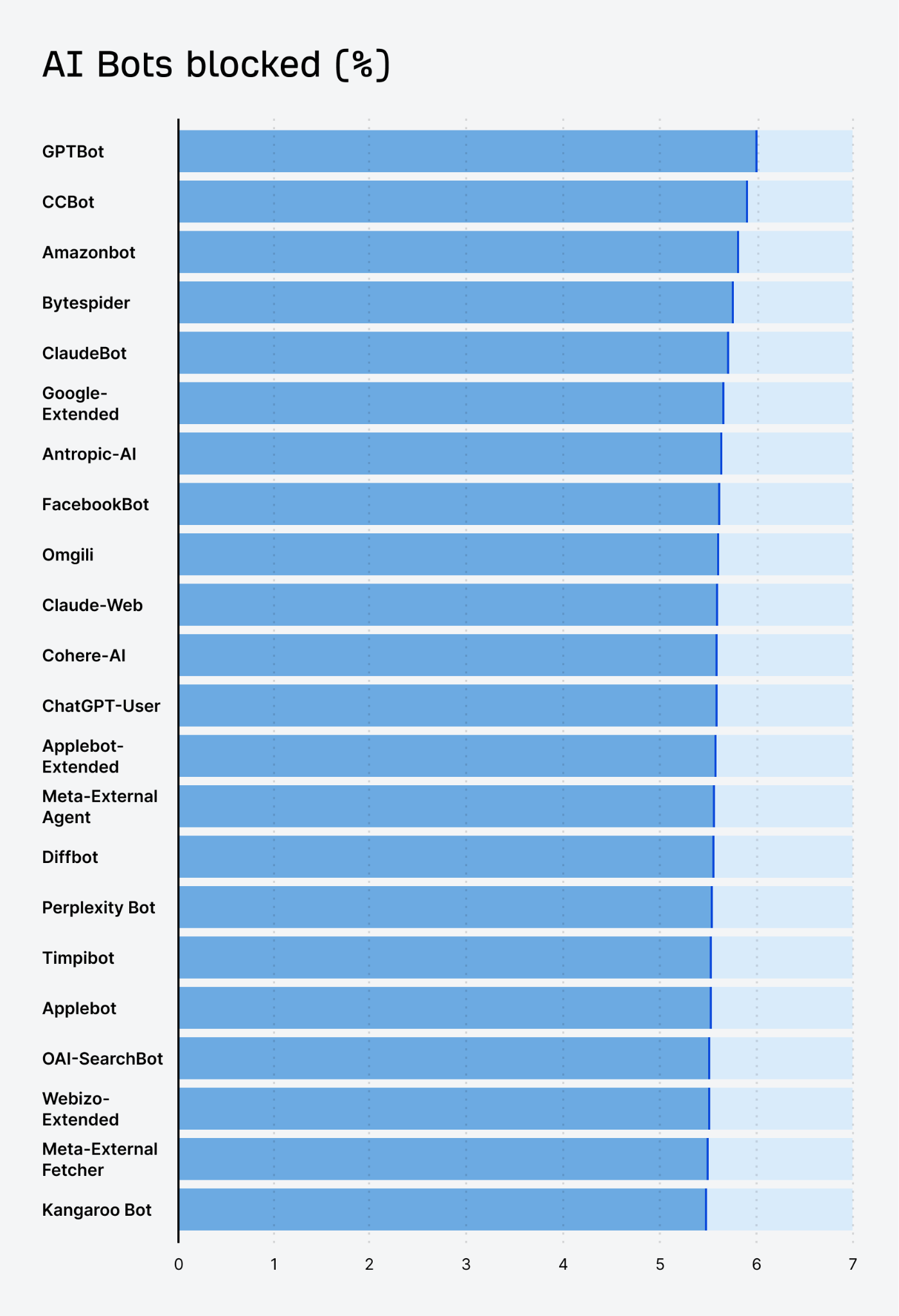
- GPTBot (OpenAI) is the most blocked AI bot, with 5.89% of all websites blocking them.
- ClaudeBot (Anthropic) saw the highest growth in block rates, increasing by 32.67% over the past year.
- The most blocked bots are also the most active ones.
We looked at the total number of websites blocking the bots. There are many ways to block bots with robots.txt, and this accounts for all of them including:
- Explicit blocks, where the bot is mentioned and disallowed
- General blocks, where all bots may be blocked
- Any instances where a directive allowed the bot, after blocking all bots
Caveats: this doesn’t include any other block types such as firewalls or IP blocks.
As I mentioned earlier, the most blocked bot is GPTBot. It’s the most active AI bot according to Cloudflare Radar.

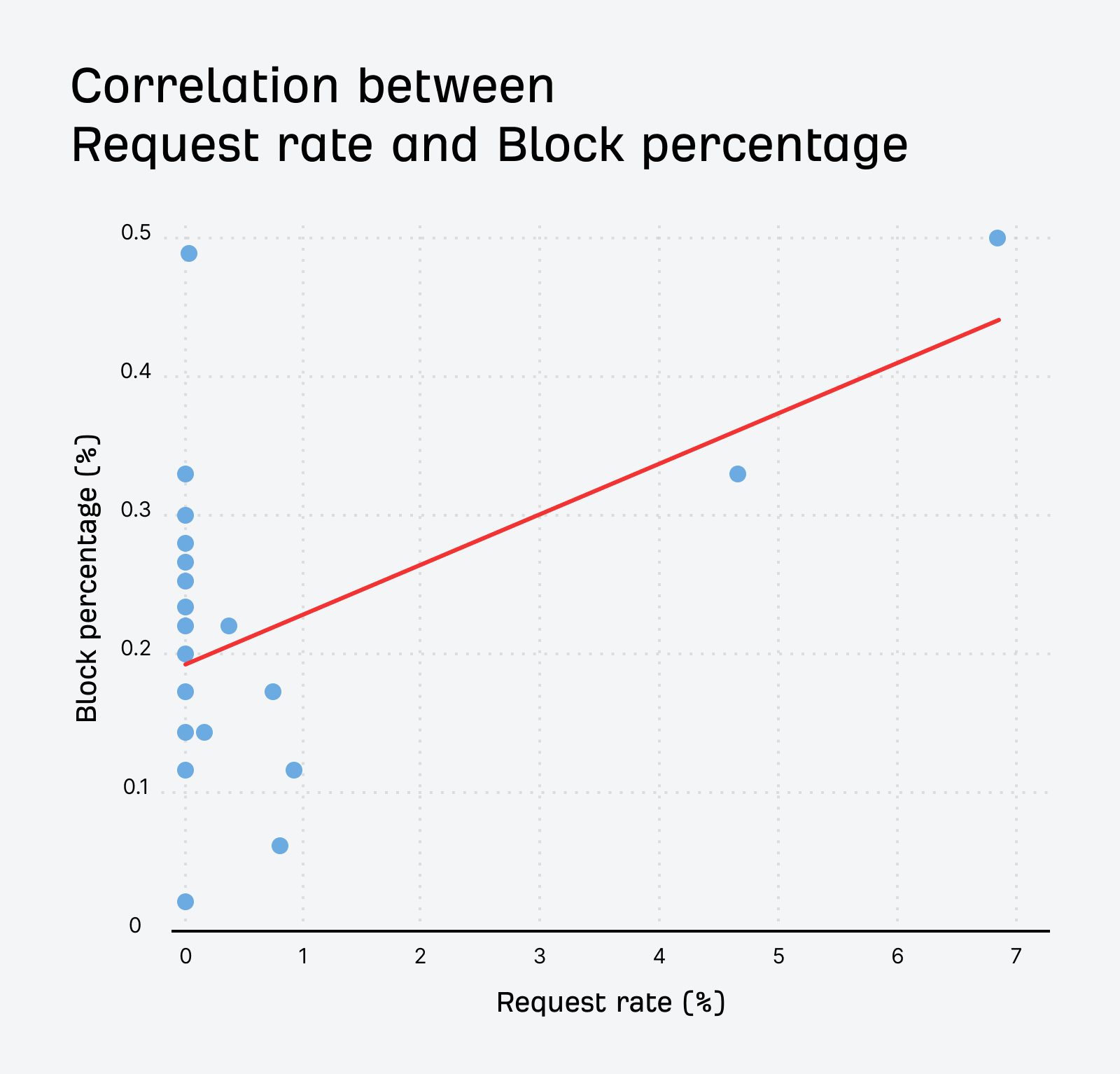
There is a moderate positive correlation between the request rate and the block rate for these bots. Bots that make more requests tend to be blocked more often. The nerdy numbers are 0.512 Pearson correlation coefficient, p-value of 0.0149, and this is statistically significant at the 5% level.
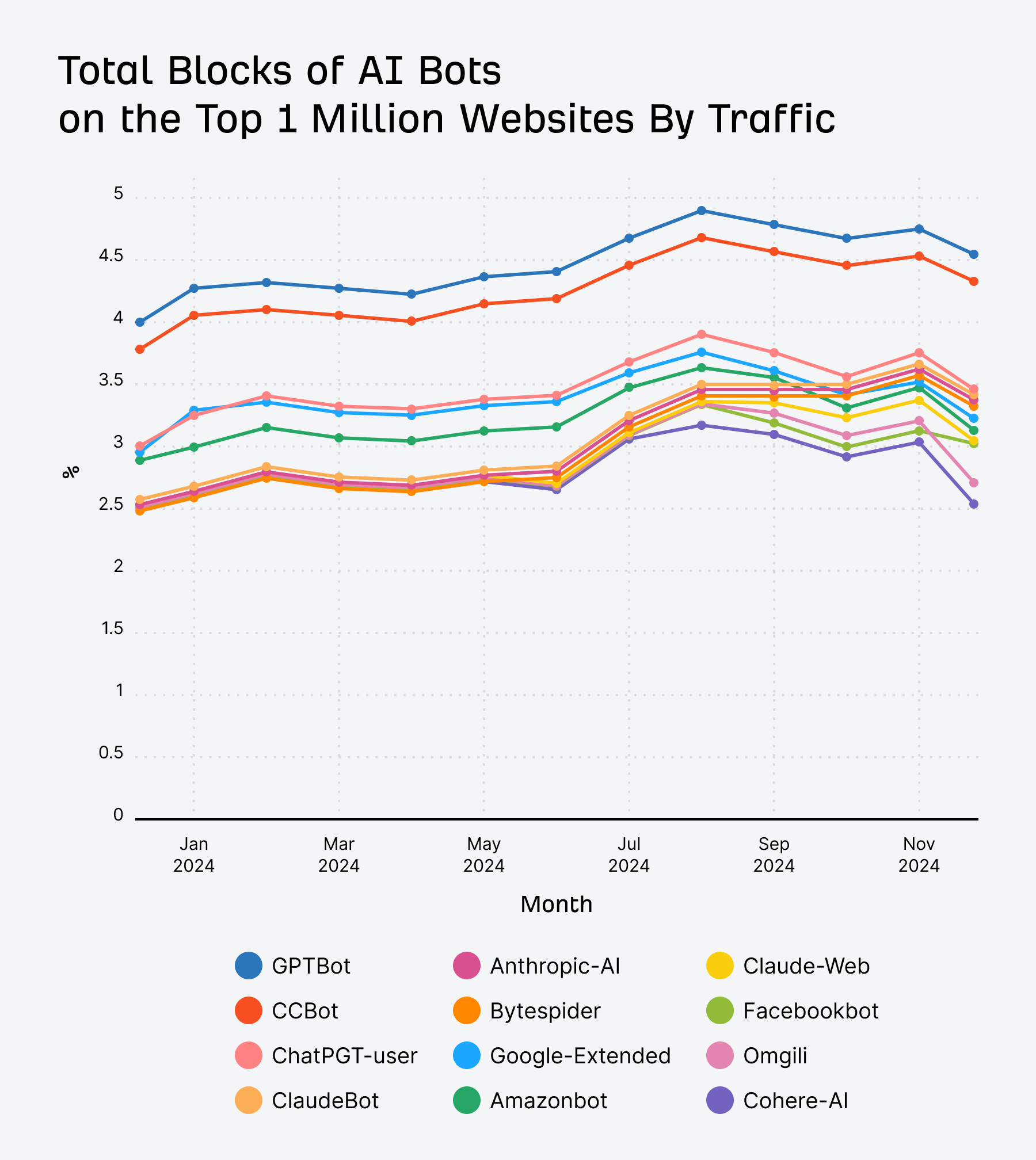
Here’s the data for the overall blocks:
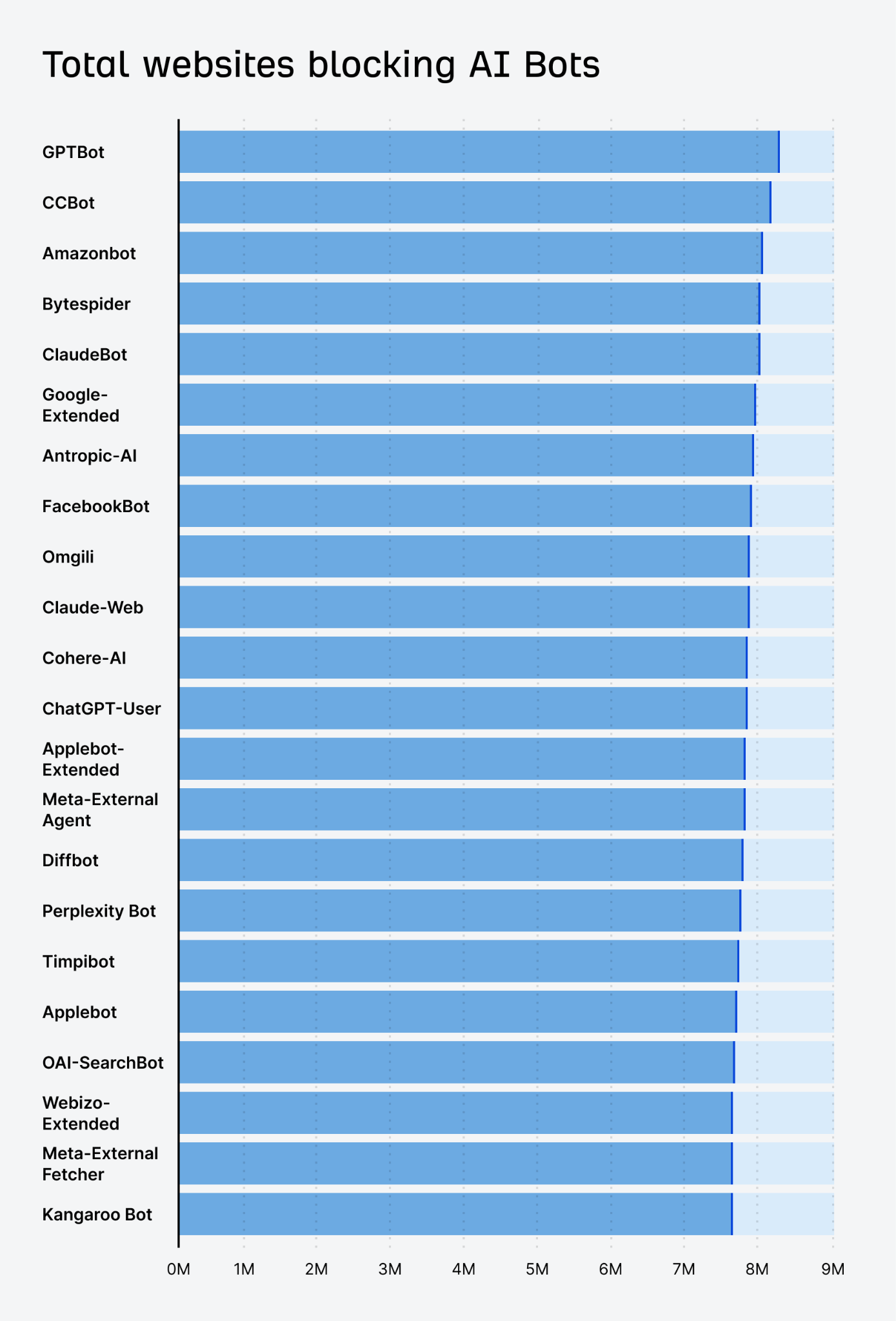
Here is the total number of websites blocking AI bots:
Here’s the data:
| Bot Name | Count | Percentage % | Bot Operator |
|---|---|---|---|
| GPTBot | 8245987 | 5.89 | OpenAI |
| CCBot | 8188656 | 5.85 | Common Crawl |
| Amazonbot | 8082636 | 5.78 | Amazon |
| Bytespider | 8024980 | 5.74 | ByteDance |
| ClaudeBot | 8023055 | 5.74 | Anthropic |
| Google-Extended | 7989344 | 5.71 | |
| anthropic-ai | 7963740 | 5.69 | Anthropic |
| FacebookBot | 7931812 | 5.67 | Meta |
| omgili | 7911471 | 5.66 | Webz.io |
| Claude-Web | 7909953 | 5.65 | Anthropic |
| cohere-ai | 7894417 | 5.64 | Cohere |
| ChatGPT-User | 7890973 | 5.64 | OpenAI |
| Applebot-Extended | 7888105 | 5.64 | Apple |
| Meta-ExternalAgent | 7886636 | 5.64 | Meta |
| Diffbot | 7855329 | 5.62 | Diffbot |
| PerplexityBot | 7844977 | 5.61 | Perplexity |
| Timpibot | 7818696 | 5.59 | Timpi |
| Applebot | 7768055 | 5.55 | Apple |
| OAI-SearchBot | 7753426 | 5.54 | OpenAI |
| Webzio-Extended | 7745014 | 5.54 | Webz.io |
| Meta-ExternalFetcher | 7744251 | 5.54 | Meta |
| Kangaroo Bot | 7739707 | 5.53 | Kangaroo LLM |
It gets a little more complicated. For the above, we looked at the main robots.txt file for a website, but every subdomain can have its own set of instructions. If we look at the ~461M robots.txt in total, then the total block % for GPTBot goes up to 7.3%.
AI bot blocks over time
More top-trafficked sites began blocking AI bots in 2024, but the trend is decreasing towards the end of the year. It looks like the decrease mostly comes from generic blocks. The trend for AI bots themselves is increasing and I’ll show you that in a minute.
Do certain types of sites block AI bots more?
Here’s how it breaks down for each individual bot in different categories of websites. I was actually expecting news to be more blocked than other categories because there were a lot of stories about news sites blocking these bots, but arts & entertainment (45% blocked) and law & government (42% blocked) sites blocked them more.
The decision to block AI bots varies by industry. There can be a number of unique reasons for this. These are somewhat speculative:
- Arts and Entertainment: ethical aversions, reluctance to become training data.
- Books and Literature: copyright.
- Law and Government: legal worries, compliance.
- News and Media: prevent their articles from being used to train AI models that could compete with their journalism and take away from their revenue.
- Shopping: prevent price scraping or inventory monitoring by competitors.
- Sports: similar to news and media on the revenue fears.
For this measure, we’re looking only at cases where a particular bot is disallowed. It does not include any overall disallow statements or cases where only certain bots may be allowed. In these cases, website owners went out of their way to specifically block certain bots.
Again, GPTBot is the most targeted, followed closely by Common Crawl’s bot. Common Crawl data is likely used as a data source for most LLMs.
Here are the most blocked AI bots with websites specifically targeting them:
Here’s the data for the number of websites blocking them:
Here’s the data:
| Bot Name | Count | Percentage % | Bot Operator |
|---|---|---|---|
| GPTBot | 693639 | 0.5 | OpenAI |
| CCBot | 682861 | 0.49 | Common Crawl |
| Amazonbot | 469086 | 0.34 | Amazon |
| Bytespider | 461706 | 0.33 | ByteDance |
| Google-Extended | 415821 | 0.3 | |
| ClaudeBot | 393511 | 0.28 | Anthropic |
| anthropic-ai | 383176 | 0.27 | Anthropic |
| FacebookBot | 361803 | 0.26 | Meta |
| omgili | 322502 | 0.23 | Webz.io |
| ChatGPT-User | 310430 | 0.22 | OpenAI |
| cohere-ai | 306385 | 0.22 | Cohere |
| Claude-Web | 276411 | 0.2 | Anthropic |
| Applebot-Extended | 258451 | 0.18 | Apple |
| Meta-ExternalAgent | 245176 | 0.18 | Meta |
| PerplexityBot | 214488 | 0.15 | Perplexity |
| Diffbot | 213828 | 0.15 | Diffbot |
| Timpibot | 174434 | 0.12 | Timpi |
| Applebot | 163148 | 0.12 | Apple |
| OAI-SearchBot | 110376 | 0.08 | OpenAI |
| Webzio-Extended | 100572 | 0.07 | Webz.io |
| Meta-ExternalFetcher | 99993 | 0.07 | Meta |
| Kangaroo Bot | 95056 | 0.07 | Kangaroo LLM |
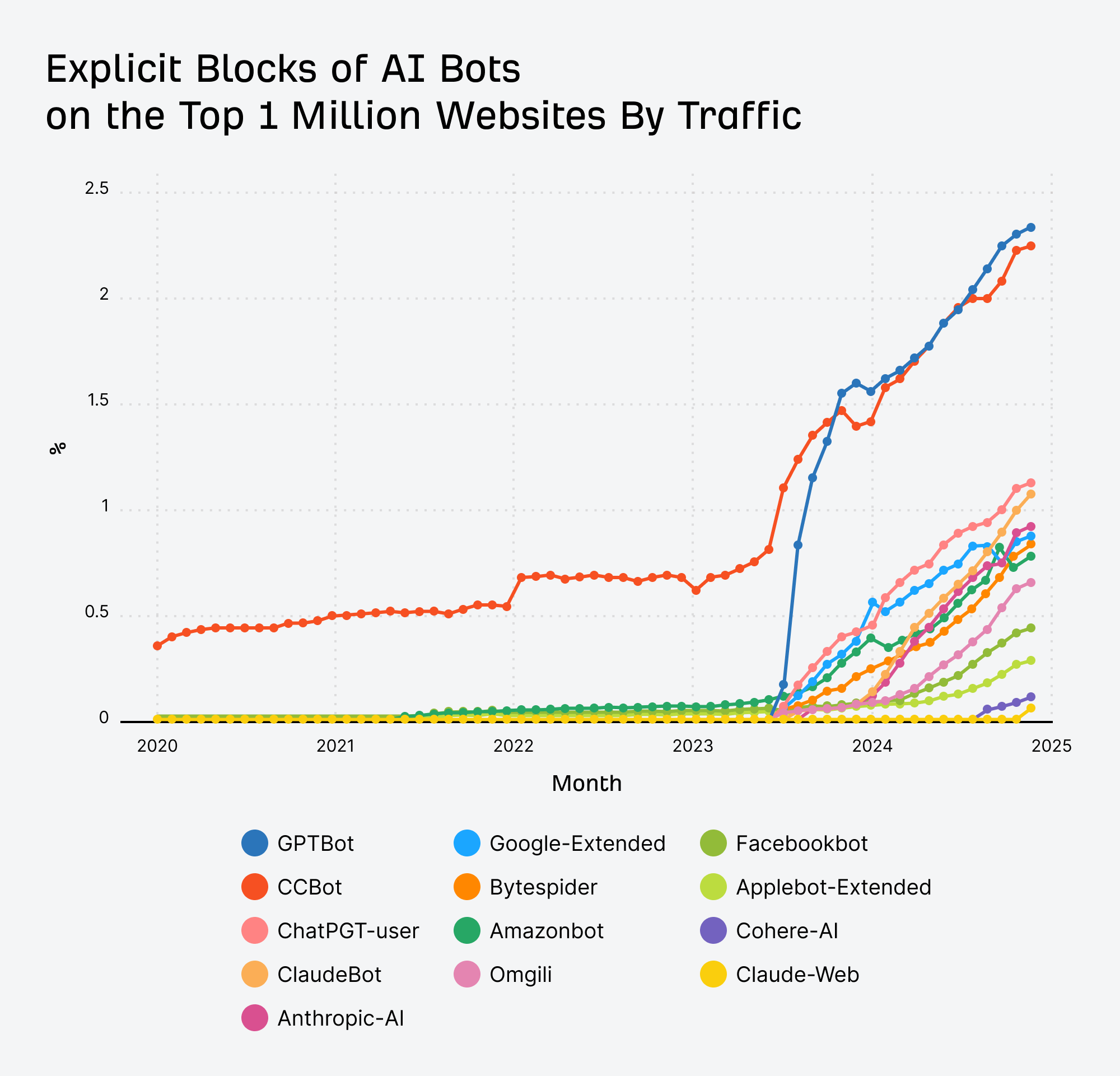
Explicit blocks of AI bots over time
As you can see, AI bots are starting to be blocked by a lot more of the most trafficked websites.
The number of AI bots more than doubled in just over a year, from 10 in August 2023 to 21 in December 2024. More new entrants into the market mean more bots all using resources to crawl websites.
Claudebot had the fastest growth of any crawler in the last year.
Here’s the data:
| Bot name | Growth % | Absolute growth |
|---|---|---|
| claudebot | 32.67% | 0.85 |
| anthropic-ai | 25.14% | 0.67 |
| claude-web | 20.66% | 0.54 |
| bytespider | 19.57% | 0.54 |
| chatgpt-user | 15.52% | 0.47 |
| perplexitybot | 15.37% | 0.4 |
| gptbot | 13.38% | 0.53 |
| cohere-ai | 12.45% | 0.32 |
| facebookbot | 11.71% | 0.32 |
| ccbot | 11.41% | 0.44 |
| amazonbot | 10.22% | 0.3 |
| google-extended | 10.07% | 0.3 |
| diffbot | 8.98% | 0.23 |
| omgili | 8.96% | 0.25 |
| applebot-extended | 7.11% | 0.18 |
| meta-externalagent | 5.90% | 0.15 |
| oai-searchbot | 2.17% | 0.06 |
| timpibot | 0.01% | 0 |
| webzio-extended | -1.69% | -0.04 |
| applebot | -3.32% | -0.09 |
| meta-externalfetcher | -4.32% | -0.11 |
| Kangaroo bot | -5.89% | -0.15 |
Final thoughts
It will be interesting to see how the block rate evolves as more and more of these crawlers start to use an ever-increasing amount of resources. Will they be able to fulfill that social contract with website owners and send them more traffic, or will they choose to keep that traffic for themselves?
I think if they go for the walled garden approach, more sites will end up blocking the bots and these systems will have to pay websites for access to their data, or the bots may end up breaking web standards and ignoring robots.txt blocks. There have been a few reports of some AI bots ignoring robots.txt blocks already, which sets a dangerous precedent.
What’s your take? Are you blocking them on your site, or do you see value in allowing them access? Let me know on X or LinkedIn.


