


Cara Kerja Mesin Pencari AI

Berdasarkan Ryan Law
Direktur Pemasaran Konten, Ahrefs
Saat Anda meminta ChatGPT untuk merekomendasikan headphone over-ear terbaik untuk olahraga, apa yang terjadi?
Bagaimana mesin pencari AI menghasilkan jawaban dan memilih rekomendasi produk? Apa bedanya dengan mesin pencari konvensional seperti Google (dan apa kesamaannya)?
Hal paling penting adalah bagaimana membuat situs web, merek, dan produk Anda muncul dalam hasil pencarian?
Terima kasih kepada Gianluca Fiorelli dan Mark Williams-Cook atas ulasan dan kontribusinya pada bab ini.
Apa itu mesin pencari AI?
Mesin pencari AI adalah sistem tanya-jawab yang menggunakan model bahasa besar (LLM) untuk menemukan informasi dan menghasilkan jawaban.
Terdapat beberapa perbedaan utama antara mesin pencari konvensional dan mesin pencari AI (meskipun perbedaan ini semakin kecil seiring diadopsinya lebih banyak fitur AI oleh mesin pencari konvensional):
- Selain memasukkan pertanyaan intan, pengguna dapat mengajukan pertanyaan lanjutan dan terus melanjutkan percakapan.
- Alih-alih menampilkan daftar tautan berperingkat, mesin pencari AI memberikan jawaban dan rekomendasi langsung (dan jawaban tersebut bisa berubah secara berkala).
- Alih-alih mengarahkan pencari untuk mengunjungi situs web Anda, kueri pengguna mendapatkan jawaban langsung di antarmuka obrolan (sehingga menghasilkan sedikit klik ke situs web Anda).
Berikut tampilan antarmuka pencarian AI yang umum, mirip dengan tampilan yang biasa Anda lihat di ChatGPT, Claude, atau AI Mode:

- Prompt percakapan: Pertanyaan pengguna.
- Pesan grounding: Pesan yang menunjukkan bahwa LLM telah memutuskan untuk mencari informasi tambahan untuk digunakan dalam jawabannya.
- Respons: Jawaban buatan AI untuk prompt pengguna.
- Penyebutan: Suatu entitas (seperti merek atau produk Anda) yang disebutkan langsung dalam teks jawaban.
- Kutipan: URL sumber yang digunakan dalam pembuatan jawaban, biasanya dicantumkan di bagian akhir.
Agar merek Anda muncul dalam jawaban seperti ini, Anda perlu memahami terlebih dahulu proses inti dari cara kerja mesin pencari AI.
Cara kerja pelatihan
LLM dilatih menggunakan konten dalam jumlah yang sangat besar. Model ini secara efektif telah "membaca" seluruh isi Wikipedia, seluruh Dataset Common Crawl, semua buku di Google Books, serta jutaan halaman konten web lainnya.
Data pelatihan ini membantu memberikan “pemahaman” tentang dunia pada LLM. Jika perusahaan headphone Anda sering muncul dalam data pelatihannya, dalam konteks yang relevan dan disertai deskripsi positif ("nilai terbaik", "cocok untuk gym", dan sebagainya), maka perusahaan Anda akan berpeluang besar disebutkan dalam jawaban LLM terhadap prompt terkait headphone.
Tahukah Anda?
Proses pelatihan ini lebih kompleks daripada yang dijelaskan di sini. Ada tahap pra-pelatihan untuk membersihkan HTML, menghapus informasi pribadi, mengecualikan kata-kata dalam daftar blokir, dan memfilter data untuk bahasa tertentu. Ada juga tahap pasca-pelatihan untuk melatih model bahasa agar berperilaku lebih seperti asisten obrolan yang membantu (bukan sekadar memprediksi token berikutnya). Untuk mempelajari lebih lanjut, tonton video Andrej Karpathy, Deep Dive into LLMs like ChatGPT.


Inilah alasan mengapa SEO berbasis entitas sangat penting. Jika merek Anda secara konsisten muncul di Knowledge Graphs, terstruktur dengan benar menggunakan schema markup, dan sering muncul bersama entitas yang relevan dalam konten berkualitas tinggi di seluruh web, maka Anda sedang membangun "sinyal entitas" yang lebih kuat dalam data pelatihan.

Gianluca Fiorelli, Konsultan SEO Strategis dan Internasional/Pencarian AI
Penting diketahui bahwa LLM memiliki banyak karakteristik unik:
- Bersifat probabilistik: Anda dapat menggunakan prompt yang sama dan mendapatkan jawaban yang berbeda setiap kali. Sifat probabilistik ini berarti Anda tidak bisa “mengoptimalkan sebuah prompt” seperti mengoptimalkan sebuah kata kunci. Sebaiknya, gunakan pola pikir distribusi: seberapa besar probabilitas merek Anda muncul di 100 prompt yang serupa? Inilah sebabnya melacak visibilitas rata-rata di banyak prompt lebih baik daripada berfokus pada sedikit prompt.
- Pengetahuan LLM memiliki cut-off: secara default, pengetahuan LLM terbatas pada dataset saat model dilatih. Setiap model dilatih satu kali pada snapshot data hingga tanggal tertentu. Model baru dengan cut-off pengetahuan yang lebih baru dirilis secara berkala (secara historis kira-kira setiap enam bulan sekali).
- LLM berhalusinasi: LLM bisa sangat meyakinkan dalam menyatakan sesuatu yang tidak benar. LLM menghasilkan teks dengan memprediksi kata apa yang kemungkinan muncul berikutnya, bukan dengan memverifikasi fakta. Walaupun LLM dilatih untuk membantu dan akurat, tetapi tidak memiliki mekanisme pemeriksaan fakta bawaan, itulah sebabnya grounding melalui pencarian web menjadi sangat penting.
Sering kali orang salah paham dengan mengira bahwa LLM mendapatkan "pembaruan pengetahuan" seperti patch perangkat lunak. Padahal, setiap model dilatih satu kali pada dataset yang tetap. Jika ada rilis model baru dengan batas pengetahuan yang lebih baru, itu adalah model yang benar-benar baru yang dilatih dari nol, bukan pembaruan dari model yang sudah ada.
Gianluca Fiorelli, Konsultan SEO Strategis dan Internasional/Pencarian AI
Mesin pencari yang berhalusinasi dan membagikan informasi lama itu tidak berguna. Karena itu, LLM mengatasi sebagian keterbatasan ini melalui proses yang dikenal sebagai grounding.
Cara kerja grounding dan RAG
LLM dapat memverifikasi dan meningkatkan jawaban dengan dua cara: menggunakan alat (seperti kalkulator atau API data lainnya), atau mengambil informasi tambahan dari sumber eksternal. Proses yang kedua ini secara teknis dikenal sebagai Retrieval-Augmented Generation (RAG).
Saat pengguna memasukkan pertanyaan, LLM bertanya pada dirinya sendiri: "Apakah aku sudah tahu jawabannya, atau perlu mengambil informasi tambahan?" Jika LLM dapat memprediksi token berikutnya dengan tingkat kepastian yang tinggi (misalnya, pertanyaan yang tidak banyak berubah, seperti "apa fungsi sel darah merah?"), besar kemungkinan ia akan menjawab berdasarkan pengetahuan dasarnya. Dengan tingkat kepastian yang rendah (untuk pertanyaan yang rentan berubah, seperti "apa penggiling kopi budget terbaik?"), maka ia dapat menggunakan alat pencariannya untuk menemukan informasi relevan dari sumber lain di internet.
LLM telah diselaraskan untuk mengenali jenis kueri yang mungkin memerlukan informasi tambahan, seperti:
- Topik di luar ruang lingkup pelatihan model: “Apa faktor peringkat internal yang digunakan oleh Ahrefs’ Keywords Explorer?”
- Topik yang membutuhkan informasi terbaru atau peka waktu: “Apa pembaruan inti terbaru Google dan kapan diluncurkan?”
- Topik yang secara jelas meminta pencarian web: "Cari di internet taktik link-building yang populer pada tahun 2026."
- Prompt yang meminta sumber dan bukti: “Berikan sumber yang mengonfirmasi bahwa Google menggunakan sinyal keterlibatan pengguna dalam algoritmanya."
Beberapa model LLM juga sangat cenderung memicu pencarian tambahan (misalnya, model "riset mendalam" yang secara khusus dikonfigurasi untuk memicu beberapa pencarian RAG).
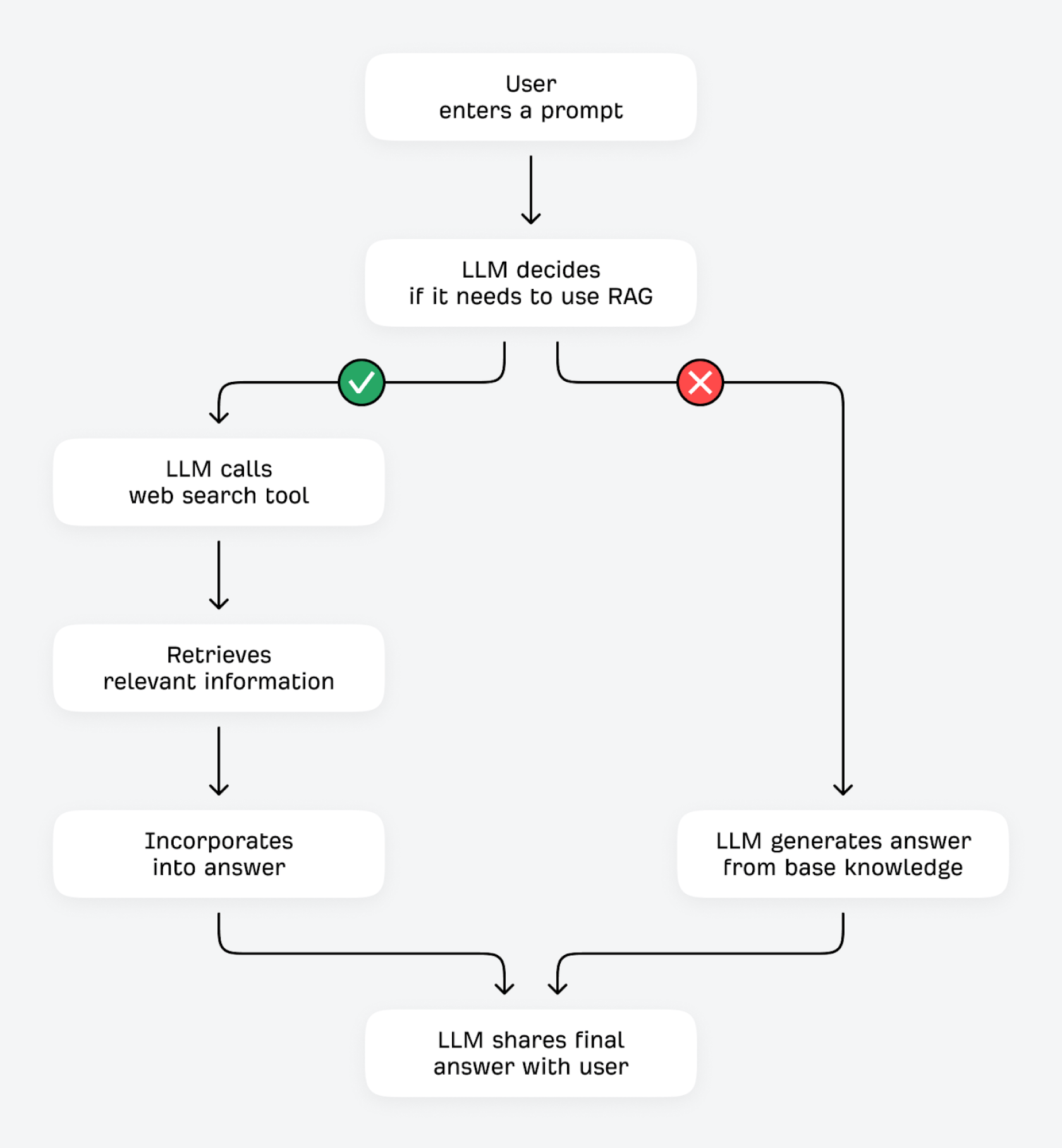
Proses verifikasi fakta melalui RAG (yang kerap dikenal dengan istilah “grounding”) memberikan berbagai keuntungan. LLM mampu meningkatkan ketepatan fakta dan meminimalkan halusinasi dengan melakukan pengecekan silang antara jawabannya dan sumber pihak ketiga. Sistem ini dapat mengambil serta menyajikan informasi terbaru, meski data pelatihannya sudah cukup lama. Selain itu, LLM dapat memberikan jawaban yang lebih detail dan menyeluruh, serta menawarkan transparansi dan rujukan sumber yang lebih jelas.
Mesin pencari AI melakukan grounding dengan menggunakan proses yang dikenal sebagai kueri fan-out.
Cara kerja kueri fan-out
Intinya, kueri fan-out menjelaskan mengapa SEO konvensional sangat penting untuk visibilitas AI.
Asisten AI seperti ChatGPT, Gemini, dan Perplexity menggunakan indeks pencarian seperti Google, Bing, dan Brave untuk mendapatkan informasi terbaru.
Pilihan penyedia pencarian itu penting karena setiap platform memiliki algoritma peringkat, indeks, dan jangkauan yang berbeda. Memastikan merek Anda muncul di Google Search dapat meningkatkan visibilitas di AI Mode secara lebih efektif dibandingkan di ChatGPT, yang sangat bergantung pada Bing.
| mesin pencari AI | Indeks pencarian yang digunakan untuk grounding |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Saat pencarian web dipicu, LLM meminta hasil yang relevan dari indeks pencariannya. Indeks pencarian memberikan daftar hasil, dan LLM memilih halaman yang paling relevan untuk di-crawl dengan mengevaluasi informasi seperti judul halaman, konten snippet halaman yang dihasilkan, dan kemutakhirannya (seberapa baru halaman dipublikasikan).
Mengapa SEO sangat penting untuk Pencarian AI
Poin ini patut ditegaskan kembali: mesin pencari konvensional seperti Google dan Bing berperan sangat penting dalam membantu mesin pencari AI memutuskan konten apa yang disebutkan dan dkutip dalam jawabannya.
Dengan kata lain, peringkat tinggi di pencarian konvensional akan meningkatkan visibilitas Anda di pencarian AI.
Apa sebenarnya yang dicari oleh LLM?
LLM menggunakan proses yang disebut kueri fan-out. Banyak prompt yang dimasukkan ke ChatGPT dan mesin pencari AI lainnya sangat panjang, bersifat percakapan, dan sering kali sangat unik. Mencari dengan prompt seperti itu di Google tidak selalu menghasilkan konten yang berguna.
Jadi, alih-alih menjalankan pencarian web dengan kueri yang sama persis seperti yang digunakan pengguna…
"Saya sedang menyusun strategi konten 6 bulan untuk perusahaan SaaS B2B berukuran menengah yang menjual produk analitik kepada merek ecommerce. Perusahaan tersebut…"

…LLM menggunakan prompt awal tersebut untuk menghasilkan serangkaian kueri terkait yang lebih singkat guna mengambil informasi yang relevan.
Kueri fan-out ini juga dibuat oleh model bahasa besar sehingga bersifat non-deterministik: kueri ini dapat berubah secara berkala, bahkan untuk pencarian yang sama.

Mark Williams-Cook, Founder, AlsoAsked
Proses ini seharusnya terasa akrab bagi praktisi SEO: kueri terkait ini sangat mirip dengan kata kunci panjang, sub-maksud, dan pertanyaan Orang Juga Bertanya:
- Kerangka kerja strategi konten SaaS B2B umum
- Contoh konten TOFU vs BOFU untuk SaaS
- Praktik terbaik untuk pembaruan konten dan penautan internal
- Metrik untuk pertumbuhan demo berbasis konten
Faktanya, hanya 12% tautan yang dikutip oleh ChatGPT, Gemini, dan Copilot yang muncul di hasil 10 teratas Google untuk prompt pengguna asli. Namun, bukan berarti peringkat konvensional menjadi tidak relevan. Mesin pencari AI mengambil konten dengan membuat beberapa kueri pencarian dan kueri fan-out sering kali berupa pencarian yang lebih konvensional dan berfokus pada kata kunci, sehingga peran strategi SEO Anda tetap sangat besar.

Kueri fan-out memberikan keleluasaan: Anda tidak perlu menebak perintah percakapan apa yang akan digunakan orang. Sebaliknya, lakukan optimasi pada kueri yang telah terurai, atau komponen semantik yang secara alami dihasilkan oleh LLM. Hal ini sangat mirip dengan riset kata kunci konvensional: [topik] + [kualifikasi], kueri perbandingan, kueri definisi, dan konten "praktik terbaik". Riset SEO Anda saat ini kemungkinan besar sudah mencakup ruang fan-out tersebut.
Gianluca Fiorelli, Konsultan SEO Strategis dan Internasional/Pencarian AI
Cara kerja retrieval, chunking, dan sintesis jawaban
Setelah LLM mendapatkan halaman yang relevan dari indeks pencarian, ia tidak membaca semuanya. Halaman tersebut dipecah menjadi beberapa potongan teks singkat, lalu model akan memprioritaskan (dan terkadang memperluas) bagian teks yang paling relevan dengan kueri.
Tiap potongan teks ini biasanya berisi beberapa ratus sampai beberapa ribu kata, yang merupakan sebagian kecil dari kebanyakan halaman web. LLM juga dibatasi jendela konteks yang ketat: ada batas jumlah teks yang bisa diolah sekaligus, mulai dari pertanyaan pengguna, potongan teks yang diambil, hingga jawaban yang dihasilkan. Akibatnya, LLM harus benar-benar memilih konten mana yang paling penting untuk diambil dan disertakan.
Berikut contohnya:
| Konten halaman penuh | “Grounding adalah alur kerja ketika model mengambil sumber eksternal, mengekstraksi fakta yang relevan, dan menggunakan ekstraksi tersebut untuk mengurangi halusinasi serta meningkatkan kemutakhiran.… Kemudian, model memindai berbagai sumber, membandingkan informasi, dan menyintesis jawaban alih-alih menyalin teks apa adanya. Tahap sintesis ini membantu menghindari ketergantungan berlebihan pada satu sumber saja.” |
| Snippet | "Menjelaskan bagaimana asisten menggunakan pencarian web untuk mengambil sumber eksternal dan mengurangi halusinasi dengan mendasarkan jawaban pada fakta yang diperoleh." |
| Perluasan (baris 1–2) | “Grounding adalah alur kerja ketika model mengambil sumber eksternal, mengekstraksi fakta yang relevan, dan menggunakan ekstraksi tersebut untuk mengurangi halusinasi serta meningkatkan kemutakhiran. Model mengevaluasi apakah sebuah kueri memerlukan informasi terbaru atau dapat diverifikasi sebelum memulai pencarian web.” |
| Perluasan (baris 33–34) | “Kemudian, model memindai berbagai sumber, membandingkan informasi, dan menyintesis jawaban alih-alih menyalin teks apa adanya. Tahap sintesis ini membantu menghindari ketergantungan berlebihan pada satu sumber saja.” |
Permudah LLM memahami konten Anda
Ini penting: saat mesin pencari AI mengambil konten Anda dari internet, yang terbaca hanyalah cuplikan sebagian, bukan halaman utuh. Agar halaman Anda berpeluang besar dikutip dalam jawaban LLM, pastikan relevansi dan manfaat halaman tersebut mudah dipahami oleh LLM, sekalipun tanpa akses ke seluruh halaman.
Mesin pencari AI kemudian mengintegrasikan teks tersebut dalam proses pembuatan jawabannya.
Konten web mentah menjadi landasan dari jawaban model: snippet teks atau data yang diekstraksi pada langkah sebelumnya ditambahkan ke konteks model, yang pada dasarnya memberikan instruksi, “Berikut adalah beberapa konteks dari web yang mungkin berguna, sekarang jawablah pertanyaan pengguna menggunakan informasi ini.”
Cara pemilihan kutipan
Selanjutnya, model akan membuat jawaban dengan menggabungkan pengetahuan bawaannya dengan konten yang didapatkan, lalu membagikannya kepada pengguna. Jawaban biasanya akan menyertakan kutipan: URL yang dapat diklik dan tertaut ke sumber yang digunakan selama proses grounding.
Tidak setiap halaman yang diambil oleh mesin pencari AI akan mendapatkan kutipan dalam jawaban akhir. Model akan memilih sumber yang dikutip berdasarkan beberapa faktor:
- Relevansi: Seberapa langsung konten yang diambil berkontribusi terhadap klaim tertentu dalam jawaban.
- Kemutakhiran: Seberapa baru sumber terlihat.
- Keberagaman: Seberapa beragam sumber kutipan (mesin pencari AI sering kali lebih memilih mengutip berbagai sumber yang berbeda, alih-alih berulang kali mengutip sumber yang sama).
Artinya bahwa meskipun konten Anda diambil dan dibaca, tetapi tidak menjamin kutipan yang terlihat; konten tersebut harus dianggap relevan secara langsung dengan klaim tertentu dalam jawaban.
Cara kerja personalisasi
Inilah inti cara kerja mesin pencari AI, tetapi ada satu tingkat kompleksitas tambahan, yaitu personalisasi.
ChatGPT dan mesin pencari AI lainnya dapat mempersonalisasi hasil pencarian bagi setiap pengguna, artinya prompt yang sama bisa menghasilkan jawaban yang berbeda bagi orang yang berbeda. Personalisasi ini dapat dipengaruhi oleh beberapa hal, yaitu:
- Konteks percakapan terkini: Pesan sebelumnya dalam obrolan yang sama akan memengaruhi jawaban terhadap prompt terkini. Ketika Anda menyebutkan bahwa Anda mengutamakan “daya tahan” pada perlengkapan hiking, maka ChatGPT akan memasukkan kriteria tersebut dalam pencariannya ketika Anda kemudian meminta “rekomendasi ransel” di obrolan yang sama.
- Memori: Banyak LLM memiliki fitur memori yang memungkinkan sistem menyimpan fakta atau preferensi tertentu di berbagai obrolan. Misalnya, dengan mengaktifkan memori, ChatGPT akan menyimpulkan dan mengingat detail yang telah Anda bagikan (seperti nama atau minat Anda) dan menyertakannya dalam percakapan berikutnya untuk mempersonalisasi jawabannya.
- Lokasi, waktu, tanggal: Banyak mesin pencari AI dapat menyimpulkan informasi tentang Anda dan menyesuaikan jawabannya berdasarkan informasi itu, mulai dari menggunakan alamat IP Anda untuk memperkirakan lokasi (untuk kueri seperti “restoran di sekitar saya”), hingga tanggal dan waktu (“daftar perlengkapan camping” mungkin akan menyarankan tenda 4 musim di musim dingin dan tenda 3 musim di musim panas).
- Prompt sistem: Setiap preferensi khusus yang dibagikan dalam pesan sistem akan memengaruhi percakapan Anda (menambahkan "ingat saya seorang vegan" pada perintah sistem akan memengaruhi jawaban untuk prompt seperti "ide sarapan sehat").
Berikut adalah analogi untuk memahami prompt sistem. Jika Anda bermain sepak bola, "data pelatihan" adalah semua latihan yang Anda jalani selama bertahun-tahun, ini adalah memori jangka panjang dari otot Anda. Sementara itu, prompt sistem adalah instruksi yang diberikan pelatih tepat sebelum Anda masuk ke lapangan. Ini adalah memori jangka pendek yang kuat dan lebih cenderung memengaruhi hasil permainan Anda.
Mark Williams-Cook, Founder, AlsoAsked

Maka dari itu, sebaiknya lacak rata-rata visibilitas merek dan situs web Anda dari waktu ke waktu untuk berbagai prompt, alih-alih terpaku pada jawaban satu prompt saja.
Pemikiran akhir
Setiap mesin pencari AI (mulai dari ChatGPT, Perplexity, hingga Google AI Mode) sedikit berbeda satu sama lain, namun proses intinya tetap sama. Hal penting bagi praktisi SEO dan pemasar adalah mesin pencari konvensional seperti Google dan Bing menyediakan banyak infrastruktur yang dibutuhkan agar mesin pencari AI dapat berfungsi. Optimalisasi pencarian AI sangat bergantung pada praktik terbaik SEO konvensional.
Bacaan lebih lanjut
Ryan Law adalah Direktur Pemasaran Konten di Ahrefs. Ryan memiliki 13 tahun pengalaman sebagai penulis, ahli strategi konten, pemimpin tim, direktur pemasaran, VP, CMO, dan pendiri agensi. Dia telah membantu puluhan perusahaan meningkatkan pemasaran konten dan SEO mereka, termasuk Google, Zapier, GoDaddy, Clearbit, dan Algolia. Dia juga seorang novelis dan pembuat dua kursus pemasaran konten.
Kuasai SEO Langkah demi Langkah
Cara Kerja Mesin Pencari
Sebelum Anda mulai belajar SEO, Anda perlu memahami cara kerja mesin pencari.
Dasar-Dasar SEO
Pelajari cara menyiapkan situs web Anda untuk kesuksesan SEO dan pahami keempat aspek utama SEO.
Riset Kata Kunci
Titik awal dalam SEO adalah memahami apa yang dicari oleh pelanggan target Anda.
Konten SEO
Pelajari cara membuat konten yang mendapat peringkat di mesin pencari.
SEO On-Page
Ini adalah tempat Anda mengoptimalkan halaman Anda untuk membantu mesin pencari memahaminya.
Bangunan Tautan
Pelajari cara membuat konten yang mendapat peringkat di mesin pencari.
SEO Teknis
Hentikan masalah teknis yang mencegah Google mengakses dan memahami situs web Anda.
SEO Lokal
Pelajari cara meningkatkan visibilitas Anda di hasil penelusuran lokal dan mendapatkan lebih banyak pelanggan dari area Anda.
Peran AI dalam SEO
Mustahil membahas SEO saat ini tanpa menyinggung AI generatif.
Cara Kerja Mesin Pencari AI
Pelajari secara tepat bagaimana mesin pencari AI seperti ChatGPT membuat jawaban serta menentukan merek dan produk yang disebutkan.