Y en el SEO uno de los grandes básicos es el enlazado. Aunque tiene muchos ajustes sencillos, es necesario trabajarlo desde el principio hasta lo avanzado para asegurarnos de que tenemos este pilar muy bien consolidado. Puede parecer una tontería, pero tener una web con todos los enlaces correctos es un paso muy importante hacia el éxito.
Los enlaces han sido la forma de navegación tradicional desde que existe internet. La forma más sencilla que ha tenido el usuario para cambiar de página e incluso para cambiar de web.
Tanto es así que Google cómo funciona (además de AI Overviews y los rich snippets) es mostrando un listado de enlaces ante una consulta.
A día de hoy siguen siendo un elemento clave para los motores de búsqueda, tanto a nivel de entender la importancia de una web, como a nivel de rastreo.
Como los enlaces son tan importantes te voy a enseñar distintos trucos para mejorar todo lo relativo al enlazado en tu web.
Cuanto más fácil sea acceder a un contenido, con más frecuencia lo rastreará Google y tendrás más posibilidades de que lo considere un contenido relevante en tu web.
Puedes pensarlo de esta forma, si se dice el dicho “Si quieres esconder un cadáver, ponlo en la segunda página de Google” como de escondido puede estar un contenido tuyo si dicho contenido lo tuvieras solo accesible mediante la paginación.
El crawl depth indica el número mínimo de clics necesarios para que nuestro rastreador acceda a la URL desde la página de inicio (generalmente). Es importante tener en cuenta que las redirecciones también podrían contarse como un enlace intermedio.
Detección de la profundidad de rastreo
Hay varias estrategias que puedes seguir para comprobar la profundidad de rastreo, y no te recomiendo de forma manual porque hay un alto riesgo de error humano
Ahrefs
Se puede ver de una forma fácil con Site Audit de Ahrefs que es una maravilla.
Se puede ver en:
Site Audit > Seleccionas el último rastreo > Page Explorer
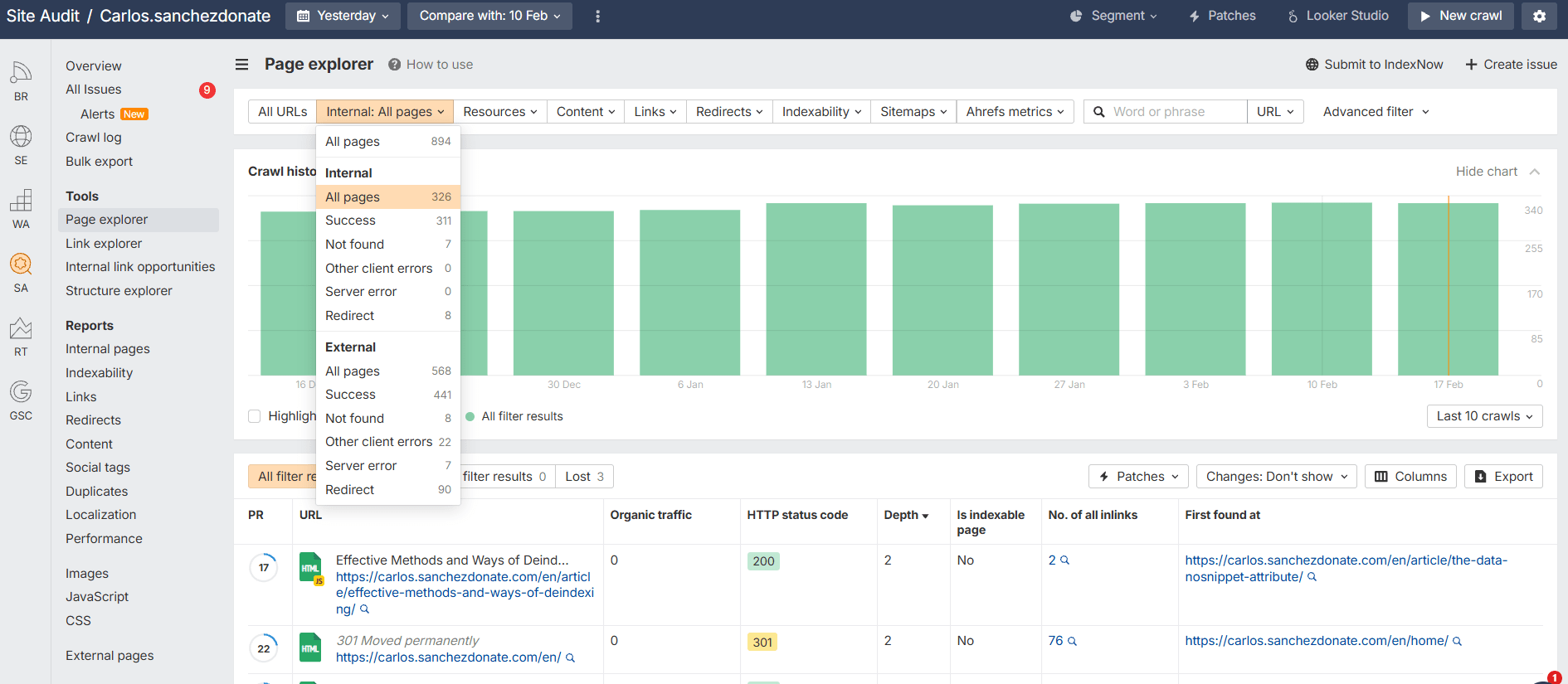
Ahí ya puedes filtrar para seleccionar todas las páginas internas (puedes comprobarlo también con enlaces externos) y filtrar por el crawl depth.
En esta tabla puedes ver el recorrido mínimo de enlaces que puedes hacer para llegar hasta esa página y la cantidad de enlaces internos que tienes hacia la misma.
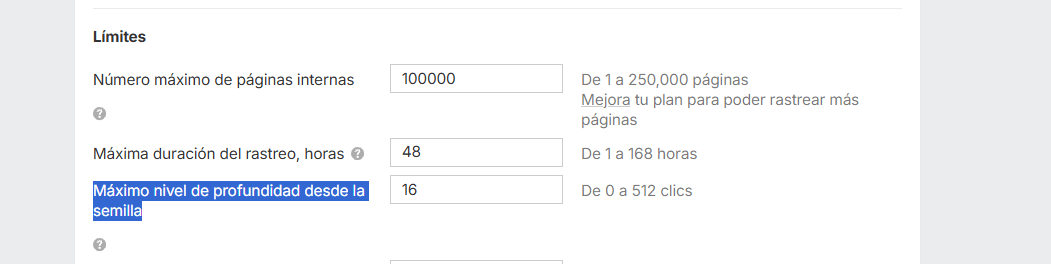
Recuerda que en Site Audit por una cuestión de eficiencia te va a poner como nivel máximo de crawl depth 16 clics, pero que lo puedes modificar por si necesitas auditar páginas con problemas de crawl depth mucho más graves.
Se hace en Site Audit > Configuración > Configuración de rastreo
Screaming Frog
Mi recomendación es que compares con ambos resultados y si puedes conectar la API mejor, pero así tienes dos puntos de vista distintos de como hacer dicho análisis.
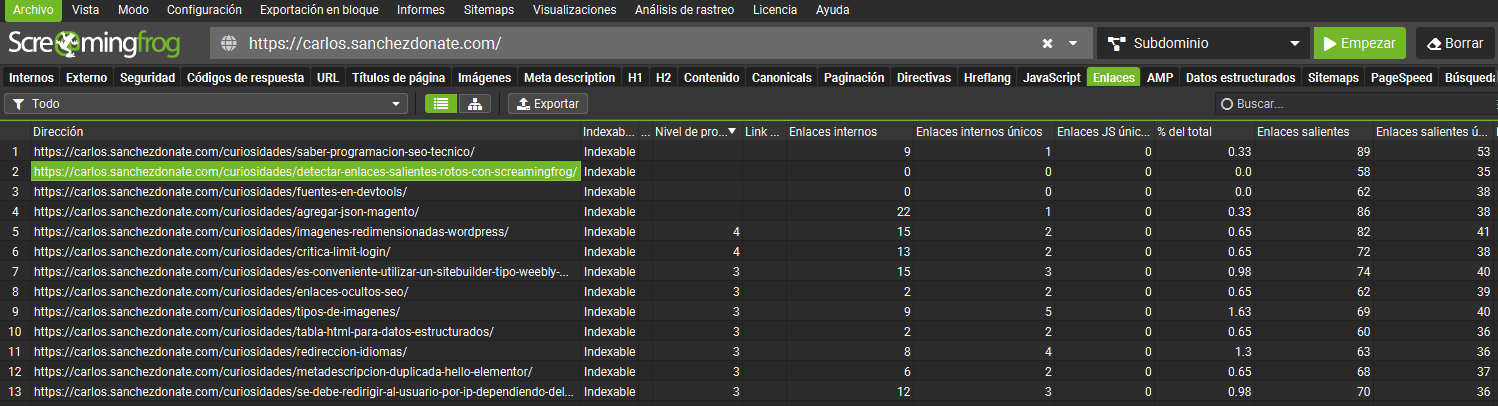
En Screaming Frog tienes que esperar a terminar el rastreo (a menos que lo hayas automatizado) y una vez listo puedes ir a la pestaña de enlaces y hay una columna que indica el nivel de profundidad.
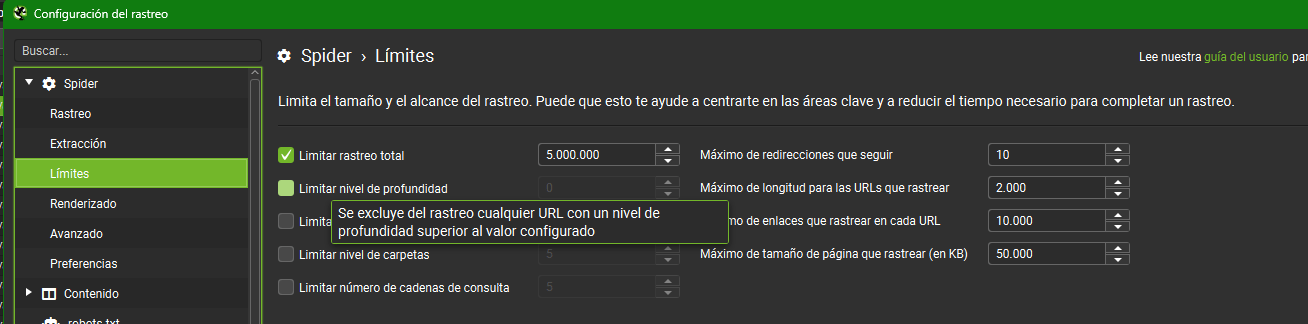
Recuerda que puedes limitar en tu rastreo el nivel de profundidad al que estás dispuesto a llegar desde límites:
Soluciones de un mal crawl depth
Se suele considerar un problema cuando se necesitan más de 3-4 clics para llegar a un contenido. Más aún si dicha URL contiene un contenido relevante.
Para mi la parte creativa es lo más divertido del SEO, y esta es una de ellas. No obstante aquí te voy a comentar algunas potenciales soluciones ante contenido que sea necesario hacer muchos clics para acceder.
- Revisión de la navbar y si sus enlaces son legibles por los crawlers (suele suceder)
- Enlazado en el Footer de contenido importante que no tiene sentido en la navbar
- Buena configuración de Sitemaps.
- Sitemaps HTML creativos. Aquí podemos ver una solución creativa de cómo hacer rápidamente accesibles todas las noticias de la historia de un periódico en activo desde 1851.
- Si una categoría o PLP (Página de Listado de Productos) tiene muchísimos productos y la única forma de acceder a ellos es yendo a la página veintitantos es que no hemos subcategorizado lo suficiente. Deberíamos filtrar mucho más, tanto los motores de búsqueda, los LLMs como los usuarios te lo agradecerán.
- Da igual cuándo y con qué página leas esto, faltan CTAs (Call To Action), siempre hay huecos que se te pueden ocurrir para recordarle a los usuarios que pueden acceder a los contenidos más relevantes de tu web
- Sugerencias de otros artículos/productos/servicios en un artículo/producto/servicio.
- Banner de anuncios propios. Mucha web piensa en poner anuncios para monetizar. En muchas webs puede tener sentido poner anuncios a contenidos propios por medio de banners. Especialmente a las webs corporativas con blogs
- Páginas de autor en los Blogs con sus artículos. Esto además favorece el EEAT.
También puede estar la situación en la que haya enlazado en tu web o hacia tu web y, por el motivo que sea, estén rotos.
Estos enlaces erróneos suelen ir a páginas 4XX o a redirecciones. En el caso de que vayan a contenido existente no deseado hay que hacer un estudio más pormenorizado.
Lo puedes revisar con cualquier herramienta.
En la Search Console de Google puedo ir a páginas y ver las que no se indexan (siempre te puede ayudar ver los motivos de desindexación de una página).
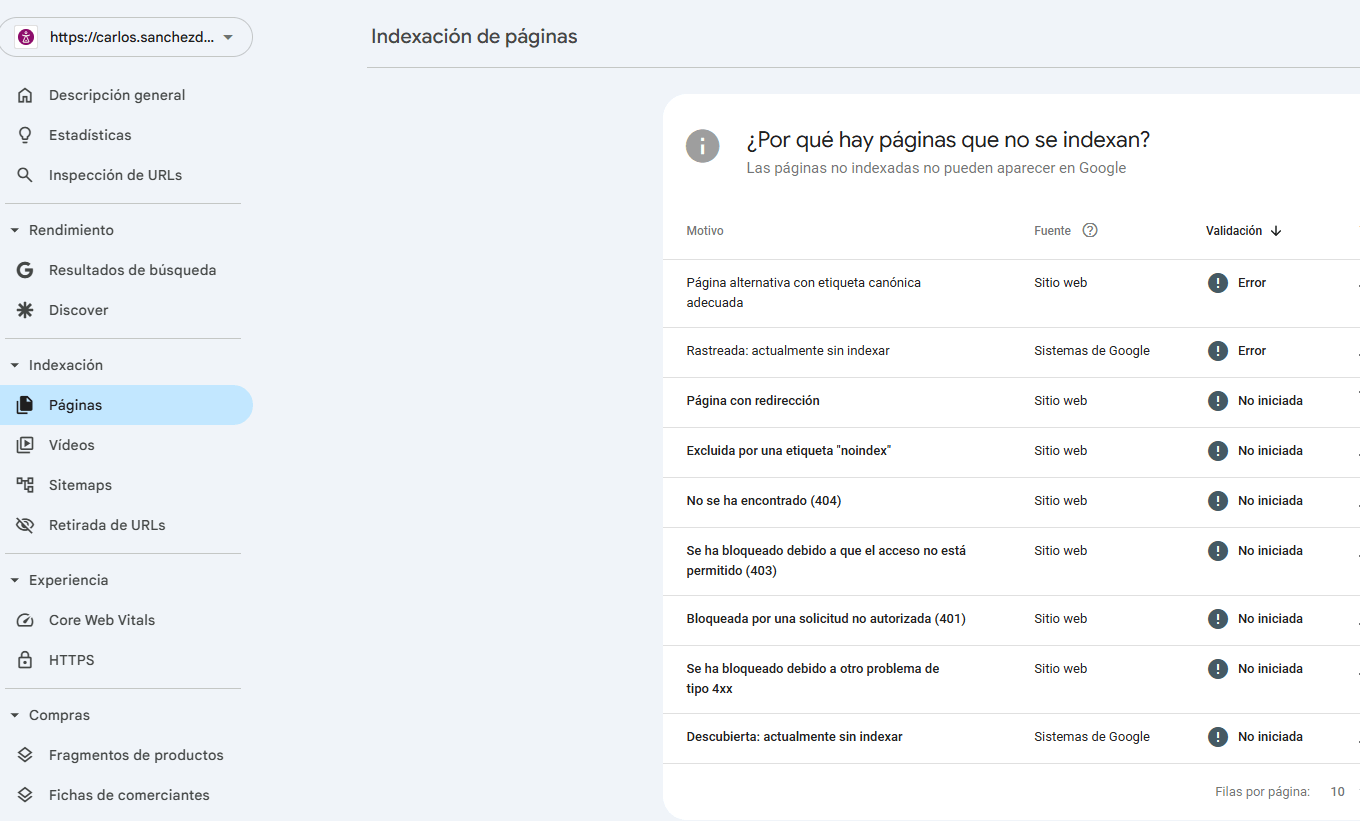
Ahí puedo ver las que tienen errores y de dónde vienen
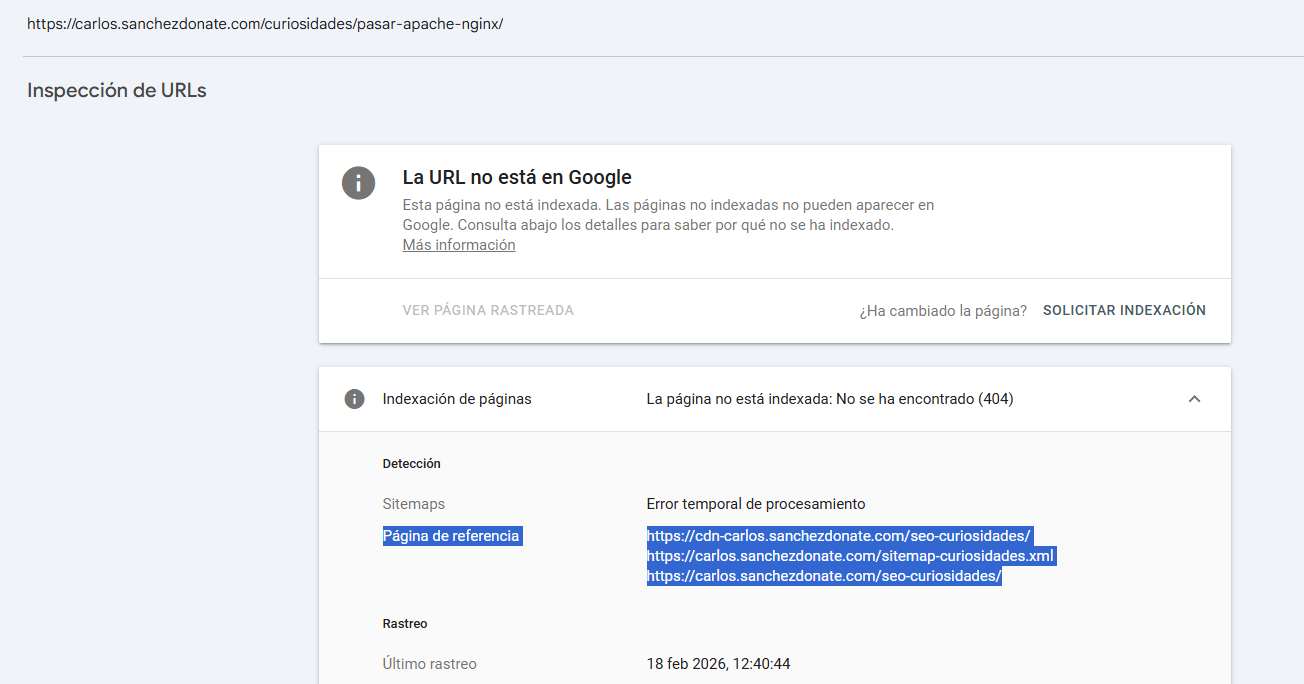
Lo malo de esta herramienta es que pese a ser gratuita no te dice desde todas las páginas en las que se enlaza a esa página para su posterior corrección, solo te indica alguna, por lo que el reporte es incompleto.
En Ahrefs lo puedes hacer de forma bastante intuitiva desde Site Explorer y desde Site Audit.
Desde Site Explorer lo puedes hacer viendo las páginas más enlazadas y luego filtrando más el resultado. También desde Backlinks en enlaces rotos, pero esto solo te ofrecerá la información de enlaces desde otros dominios (lo cual también necesitamos reparar y te enseño cómo, pero me quiero centrar en los internos que tiene más miga).
Pero desde Site Audit se hace bastante cómodo. En la misma sección de Page Explorer donde vemos el crawl depth podemos filtrar por status code:
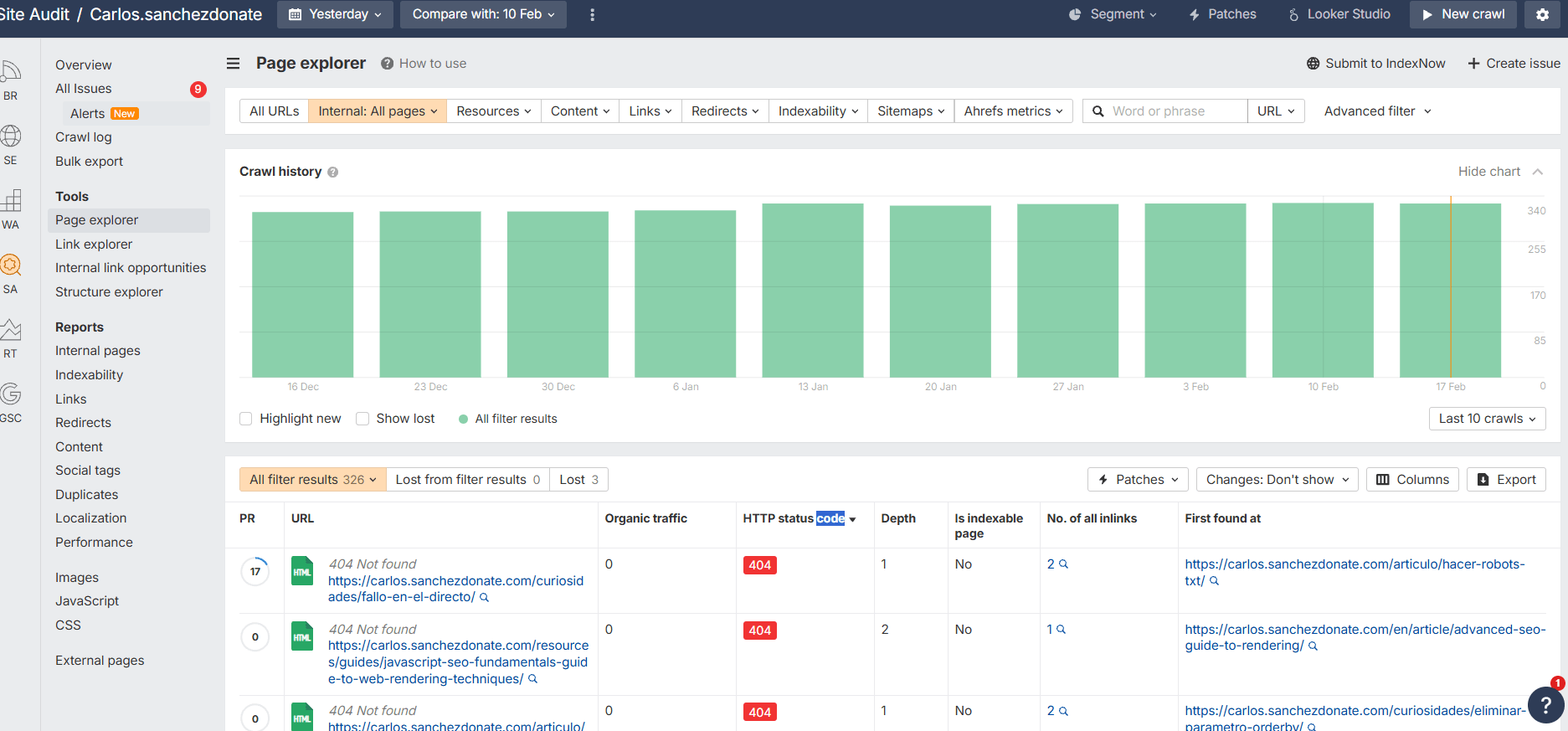
Entonces podemos hacer clic en cada una y ver desde todos los sitios desde los que se enlaza
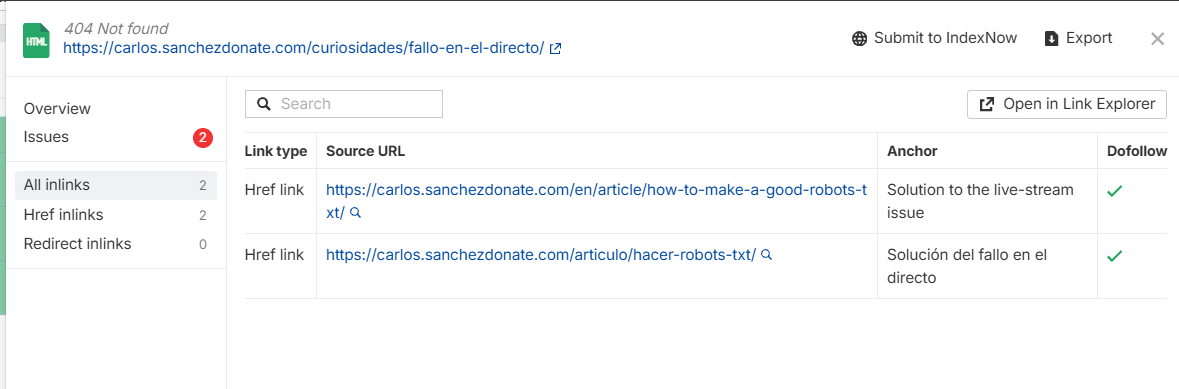
Incluso dándote un enlace al Link Explorer generando ya el filtro avanzado por cada URL (recomendable si es desde demasiados sitios):
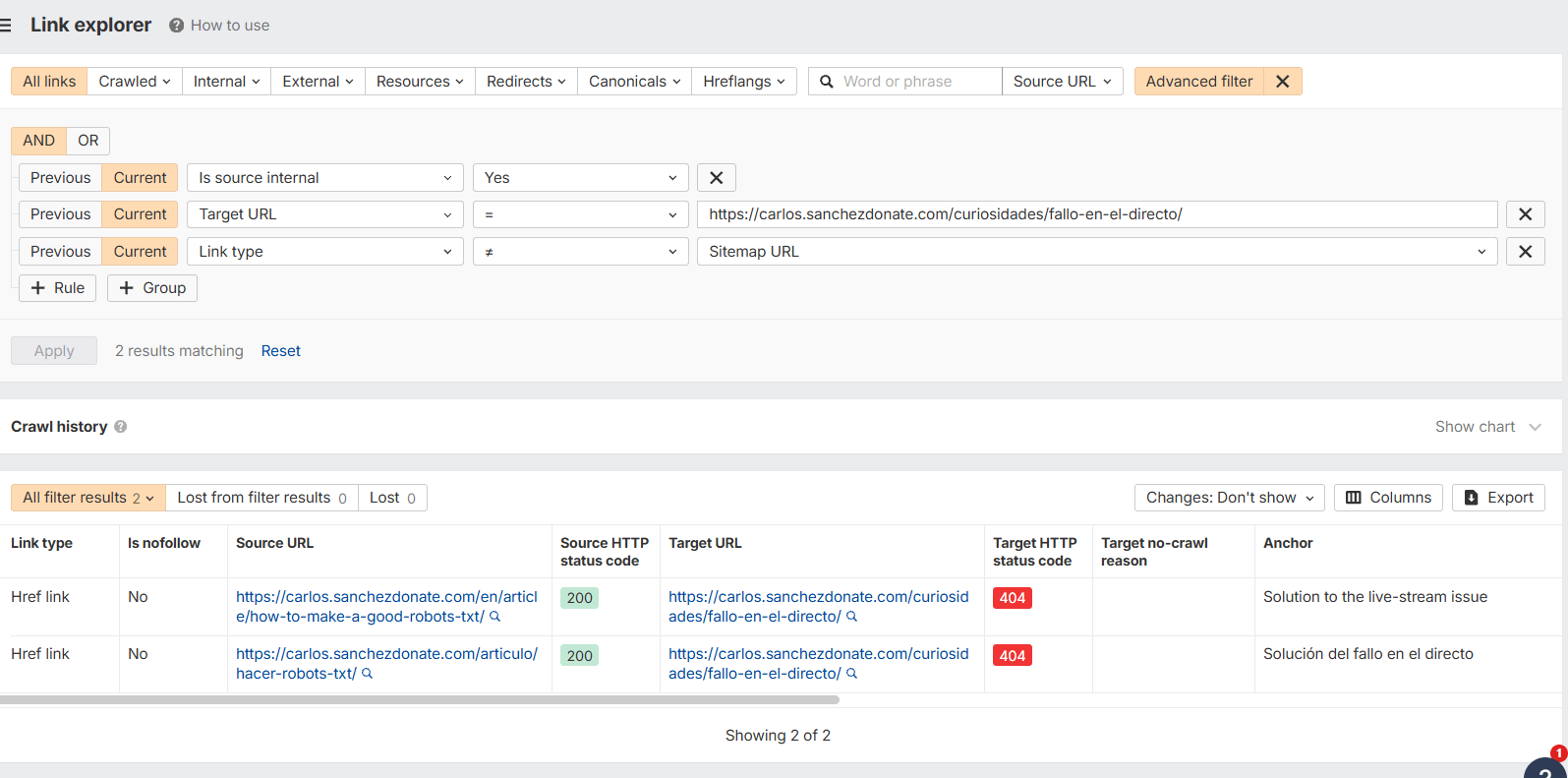
En Screaming Frog en códigos de respuesta puedes ver las URLs erróneas y en el recuadro de abajo puedes ver también todos los enlaces internos.
Solucionar enlaces rotos
Detectarlo aunque es necesario es sencillo ahora vamos a solucionar los problemas detectados. Siempre hay varios caminos y dependiendo del proyecto y la situación te puede convenir más una u otra forma.
Voy a poner de ejemplo un enlace roto imaginario.
Imaginemos que en nuestra web está el enlace:
/seo-tecnicco
y realmente la url es:
/seo-tecnico
veamos los ejemplos con cada uno
Redirecciones
Las redirecciones son la primera solución que te puede venir a la cabeza, y de hecho esta implementación recomiendo no saltartela.
A menos que sea un contenido que ya haya desaparecido por completo, si es un error de escritura o una página que ha cambiado, aunque arreglemos el origen, los crawlers pueden tener ya esta página en su memoria, por lo cual siempre es una buena solución.
De hecho cuando son enlaces externos de otros dominios a nuestra web puede ser nuestra única solución. Ya que contactando a la web de origen corremos el riesgo de que nos ignoren, retiren el enlace o pretendan cobrarnos por ello.
Por esto, salvo excepciones contadas, la redirección es una implementación de solución de enlaces que se debe aplicar siempre. No obstante, si recuerdas lo que he escrito unas líneas más arriba, una redirección puede afectar a nuestro crawl depth.
Además pueden presentarse otros problemas como cadenas de redirecciones o una mala gestión de redirecciones (haberlas realizado desde varios sitios distintos sin un orden claro, embrollo que luego hay que solucionar).
Por lo que en resumen, te recomiendo hacerlo con cuidado y si tienes control sobre la página (por ejemplo es un enlace interno) te recomiendo combinar este cambio con uno de los siguientes.
Ejemplo con Apache / LiteSpeed
Redirect 301 /seo-tecnicco /seo-tecnico
Ejemplo con Nginx
location = /seo-tecnicco {
return 301 /seo-tecnico;
}
Ejemplo con JavaScript
<script>
if (window.location.pathname === '/seo-tecnicco') {
window.location.replace('/seo-tecnico');
}
<script>
Ejemplo con meta refresh
<meta http-equiv="refresh" content="0; url=/seo-tecnico">
Reemplazo manual
Si es la solución de un enlace puntual y tienes acceso a donde se hace, no tiene nada de malo hacer un reemplazo manual puntual, rápido, limpio y eficiente.
Si es una gran cantidad de enlaces, por ejemplo una página importante que se movió y se han quedado enlaces por toda la web, vamos a tener que aplicar otro tipo de estrategias si queremos ser más eficientes en nuestro trabajo.
Buffer
Aunque complejo, si la web está hecha con PHP u otro lenguaje del servidor, siempre podemos hacer un ajuste desde el buffer.
El buffer lo que hace es modificar el HTML resultante en el servidor antes de enviarle el HTML al usuario, por lo cual siempre verá el enlace limpio con las modificaciones realizadas.
Las pegas que pueden tener este tipo de implementación es que no haya un registro ordenado y la complejidad del código, además de que en entornos como Shopify no funciona.
Es verdad que con la IA se ha reducido mucho, especialmente a la hora de hacer los regex. Sin embargo sigue siendo complejo de implementar y si no tienes conocimientos técnicos y un entorno de pruebas, las posibilidades de provocar errores inesperados en tu web son altas. Por lo cual es una implementación en ciertos casos recomendable pero no apta para todos los públicos.
Lo bueno es que funciona muy bien, apenas tiene incidencia en el WPO y no necesitas saber ni cómo se generaron dichas URLs (si está en la DDBB o en el código).
Ejemplo de código
Se debería poner en un php.ini, un config.php, un functions.php, quedaría así:
php
ob_start(function($buffer) {
return str_replace('/seo-tecnicco', '/seo-tecnico', $buffer);
});
Lo he simplificado por no liarnos con los selectores (regex), pero debería especificarse más en la mayoría de los casos.
Cambio con JS
Parecido el buffer, pero el problema de esta solución aunque es menos compleja técnicamente, es que a los crawlers (especialmente los LLMs y Bing que no renderizan JS) les seguirá llegando la URL incorrecta.
Tal vez Google si lo renderice correctamente (para eso lo debes ver en el código que te arroja la URL donde está el enlace rota en el inspector de URLs de Google Search Console).
El coste de WPO no es inexistente, pero es mínimo y de cara al usuario en una web optimizada no debería haber mucho problema. Funciona bien como parche, aunque como he comentado no es lo mejor para los crawlers, y los SEOs si tenemos una cosa es que no discriminamos, queremos hacer la web agradable tanto para humanos como para bots.
Ejemplo de código
La misma lógica que antes, lo he simplificado, pero debería hacerse más específico para cada proyecto, especialmente con los selectores:
document.addEventListener('DOMContentLoaded',function() {
document.body.innerHTML = document.body.innerHTML.replace(/\/seo-tecnicco/g, '/seo-tecnico');
});
Reemplazo en la DDBB
Existe la posibilidad de que los enlaces rotos estén en la DDBB de tu web. Por ejemplo si los enlaces están hechos desde el backend de un WordPress, sin lugar a dudas está en la Base de datos.
En este caso no solo recomiendo, sino por la salud mental de todos, exijo una copia de seguridad antes de realizar cualquier reemplazo en una bases de datos.
En este caso el reemplazo lo podríamos realizar con SQL, descargando el archivo sql y haciendo un replace masivo con notepad y volviendo a subir la ddbb o con algún plugin como Better Search Replace.
Aunque sea arriesgado, lo bueno es que se soluciona el error de base, sin poner ningún parche
Ejemplo código SQL
Cuidado que explico lo mismo que antes: en este caso es peligroso si no sabes lo que haces. Estoy poniendo un ejemplo de replace sin un where para que sea válido para todos los proyectos. Pero debes hacerlo adecuado al tuyo y siempre con Backup:
UPDATE tabla SET columna = REPLACE(columna, '/seo-tecnicco', '/seo-tecnico');
Reemplazo en el código
Otra opción es que ese enlace esté “hardcode” en cuyo caso podríamos hacer un reemplazo simple con nuestro editor de texto favorito seleccionando todos los archivos potencialmente involucrados.
Patches
Patches curiosamente hace efectos muy parecidos a los mencionados previamente.
La versión de JS es la misma que te he explicado pero sin necesidad de saber código.
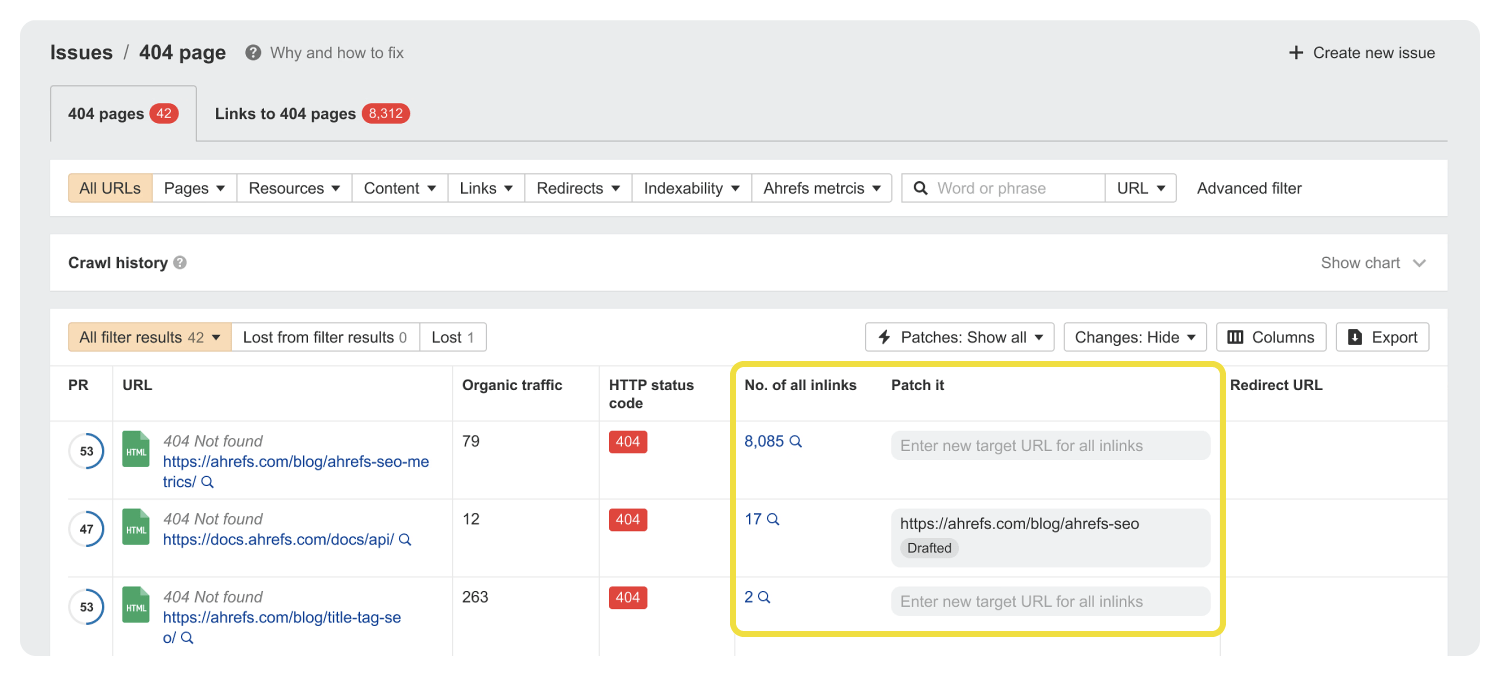
Y la versión de cloudflare workers hace prácticamente el mismo efecto que un reemplazo con el buffer. El resultado para los usuarios y crawlers será el del enlace corregido.
Quedarían así las opciones que tenemos:
| Soluciones para enlaces rotos | Ventajas | Desventajas |
|---|---|---|
| Redirecciones (301/302) | Solución estándar SEO-friendly. Mantiene autoridad del enlace. Útil cuando hay enlaces externos que no puedes cambiar. Compatible con todos los bots y navegadores. Complementaría al resto de implementaciones | Puede aumentar el crawl depth. Riesgo de cadenas o loops de redirecciones. Mala gestión puede afectar WPO y rastreo. No soluciona el origen del problema. |
| Reemplazo manual | Limpio y definitivo. Sin impacto en rendimiento ni rastreo. Ideal para pocos enlaces. No genera parches adicionales. | Poco escalable. Requiere localizar manualmente cada enlace. Fácil que alguno quede sin corregir. |
| Buffer (output buffering en servidor) | Corrige enlaces antes de enviarlos al navegador. Válido para usuarios y crawlers. No requiere saber dónde se generan los enlaces. Impacto WPO bajo si está optimizado. | Implementación técnica compleja. Difícil mantenimiento y auditoría. Riesgo de errores con regex. No compatible con todos los entornos (ej. Shopify). |
| Cambio con JavaScript | Fácil implementación. Buen parche rápido. No requiere acceso a backend o servidor. | Muchos crawlers no renderizan JS. No soluciona la URL de origen. Puede afectar ligeramente WPO. Solución poco robusta para SEO técnico. |
| Reemplazo en base de datos | Solución definitiva si el origen está en CMS o backend. Escalable para grandes volúmenes. No añade parches adicionales. | Riesgo alto sin backup. Puede afectar contenido no previsto. Requiere conocimientos técnicos. |
| Reemplazo en código (hardcoded) | Limpio y permanente. Sin impacto SEO ni rendimiento. Fácil con herramientas de búsqueda global. | Puede ser difícil localizar todas las instancias. Requiere acceso al código y control de despliegues. |
| Patches / Cloudflare Workers | No requiere tocar servidor ni CMS. Puede actuar como buffer externo. Compatible con usuarios y bots si se hace en edge. Muy flexible. | Dependencia de servicios externos. Complejidad técnica media/alta. Posible coste económico. Puede complicar debugging futuro. |
Enlaces dañinos
Si bien las redirecciones pueden solucionar enlaces rotos (con el dominio correcto) desde otras webs, existe la problemática de recibir enlaces desde webs potencialmente dañinas. No es algo tan común como pueda parecer pero puede ocurrir.
Para ello la mejor forma de verlo puede ser:
Como Google ignora bastante bien los enlaces de spam, vamos a ver cuales se han filtrado. En nuestra Search Console vamos a Enlaces.
De ahí vamos a Sitios con Más Enlaces y podremos observar los dominios desde los que tenemos URLs.
Mi recomendación es “ante la duda no hacer nada”, pero si te encuentras una URL de un dominio potencialmente dañino siempre tienes la opción del Disavow (no confundir con Disallow)
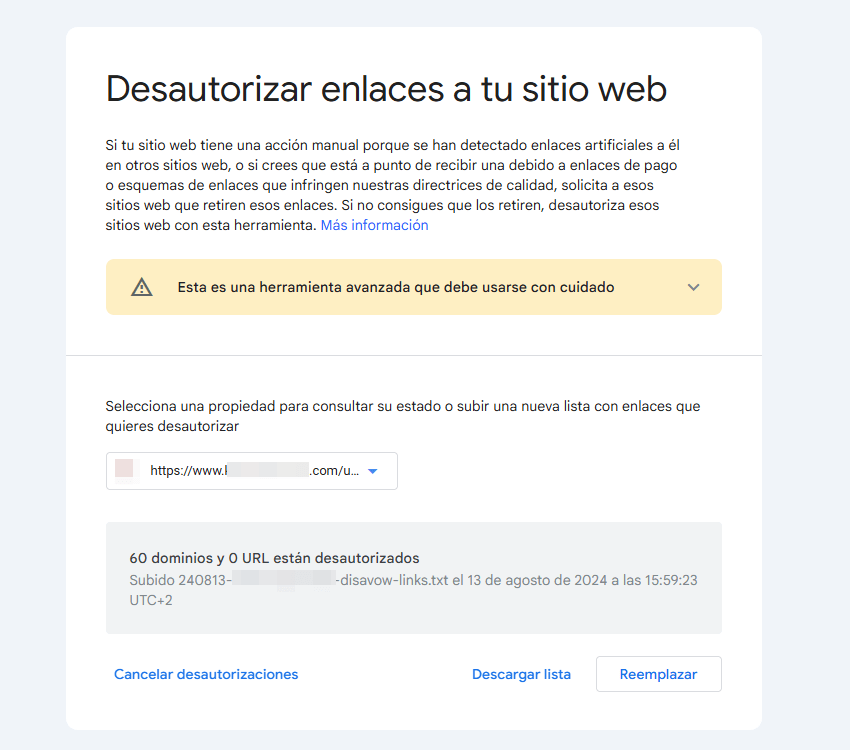
Desde ahí puedes actualizar el listado con los enlaces o dominios que quieres desautorizar desde Google.
Es importante recordar que no puede ser una propiedad de dominio, sino que tiene que estar en la Search Console como una propiedad de prefijo de la URL.
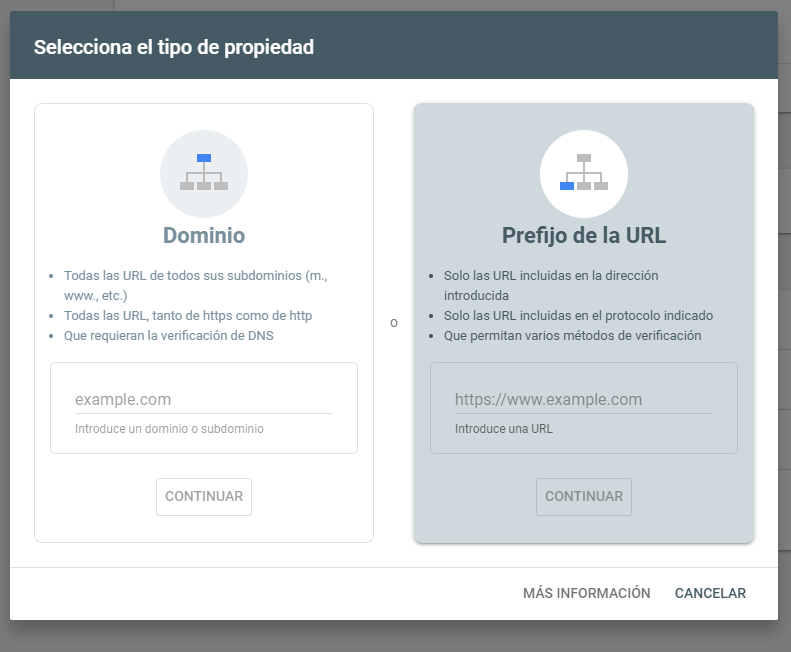
Desde el resto de crawlers no se puede hacer. El Disavow aunque John Mueller lleve “matándolo próximamente” unos cuantos años, sigue funcionando.
No solo el href es importante en un enlace. El anchor text, al igual que el alt text en las imágenes, es importante para que los crawlers entiendan más sobre la página a la que se van a dirigir.
Para que un anchor text (texto de anclaje) sea eficaz según las prácticas de Google, debe cumplir con estas cuatro características principales:
- Descriptivo y específico: Debe explicar claramente de qué trata la página de destino. Evita términos genéricos como “haz clic aquí” o “leer más”.
- Conciso: Usa frases breves y naturales. No vincules párrafos enteros ni oraciones excesivamente largas.
- Relevante: Debe tener coherencia tanto con el contenido de la página donde se encuentra como con el contenido al que dirige.
- Natural: Evita el “keyword stuffing” (acumulación excesiva de palabras clave). El texto debe fluir dentro de la redacción y aportar contexto al lector.
Si lees el anchor text de forma aislada (sin el resto del párrafo) y aún así entiendes a dónde te va a llevar, es un buen enlace.
Como hemos mencionado la web tiene que estar adaptada a todos, por lo que vamos a hacer la experiencia de los enlaces lo mejor posible para el usuario.
Voy a dar unos cuantos trucos para mejorar los enlaces en UI/UX tanto para usuarios como para Bots. Para esto es esencial conocer unos mínimos de HTML.
Enlazar una caja
Puede ocurrirte que quieras que toda una caja sea clicable para que el usuario pueda acceder fácilmente, pero que el anchor text quieras que sea un simple título de dentro. Sin necesidad de englobar otras imágenes o texto.
No necesitas JavaScript ni configuraciones que pueden salir muy mal. En un post anterior incluí un tutorial de cómo poner un enlace en una caja sin sacrificar el anchor text.
Enlaces con atributos
Te puedes valer de atributos en enlaces para evitar que los crawlers los sigan pero sigan siendo un enlace para el usuario.
También tienes la opción de añadir un noreferrer para que la página de destino no sepa de dónde viene el usuario.
Atributo Title
En el caso de que falle el anchor text y no haya contenido en el <a>, Google utiliza el title como anchor text. Dicho en la propia documentación de Google.
Target Blank
El target Blank es de sobra conocido por ser el enlace que te abre el contenido en una página nueva. Esto es especialmente recomendable cuando el enlace es hacia un dominio externo.
Gracias a los selectores y CSS podemos hacer trucos muy chulos como añadir logotipos automáticamente cuando enlazamos a sitios externos.
Como hay muchas combinaciones y dependen de tu imaginación, voy a enseñarte un truco que te va ayudar a entender cómo mejora tu UX y que además verás cómo Google aplica en proyectos propios.
Generar un símbolo de enlace externo:
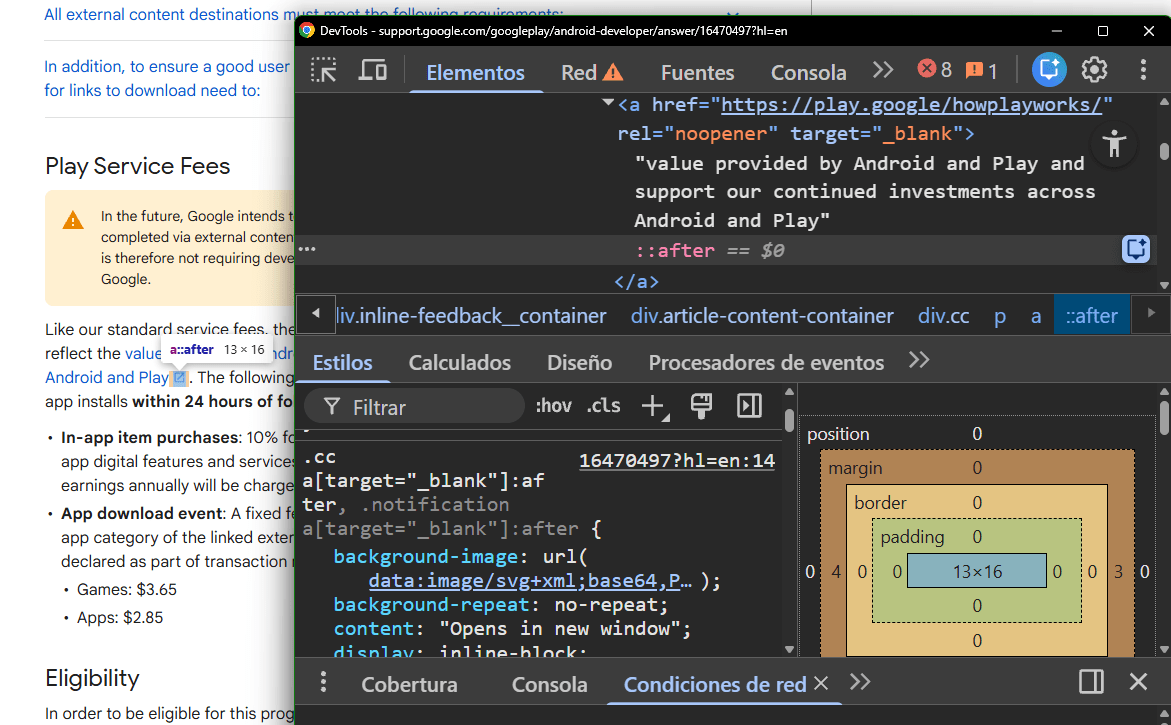
Si te das cuenta, con este código de CSS:
.cc a[target="_blank"]:after, .notification a[target="_blank"]:after {
background-image: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAyNCAyNCIgd2lkdGg9IjEzIiBoZWlnaHQ9IjEzIiBmaWxsPSIjMWE3M2U4Ij48cGF0aCBkPSJNMTkgMTlINVY1aDdWM0g1YTIgMiAwIDAgMC0yIDJ2MTRhMiAyIDAgMCAwIDIgMmgxNGMxLjEgMCAyLS45IDItMnYtN2gtMnY3ek0xNCAzdjJoMy41OWwtOS44MyA5LjgzIDEuNDEgMS40MUwxOSA2LjQxVjEwaDJWM2gtN3oiLz48cGF0aCBmaWxsPSJub25lIiBkPSJNMCAwaDI0djI0SDBWMHoiLz48L3N2Zz4=);
background-repeat: no-repeat;
content: "Opens in new window";
display: inline-block;
height: 1rem;
margin: 0 .1875rem 0 .25rem;
position: relative;
text-indent: -500vw;
width: .8125rem;
vertical-align: middle;
}Google hace que de forma automática aparezca un símbolo de enlace externo de forma visual. Así el usuario sabe que si le da clic, acabará saliendo de la página.
En mi web por ejemplo lo aplico con excepciones por medio del selector :not, de esta forma me ahorro la flechita en botones o CTAs necesarios, pero me sale el símbolo con cada URL que tiene un Target Blank:
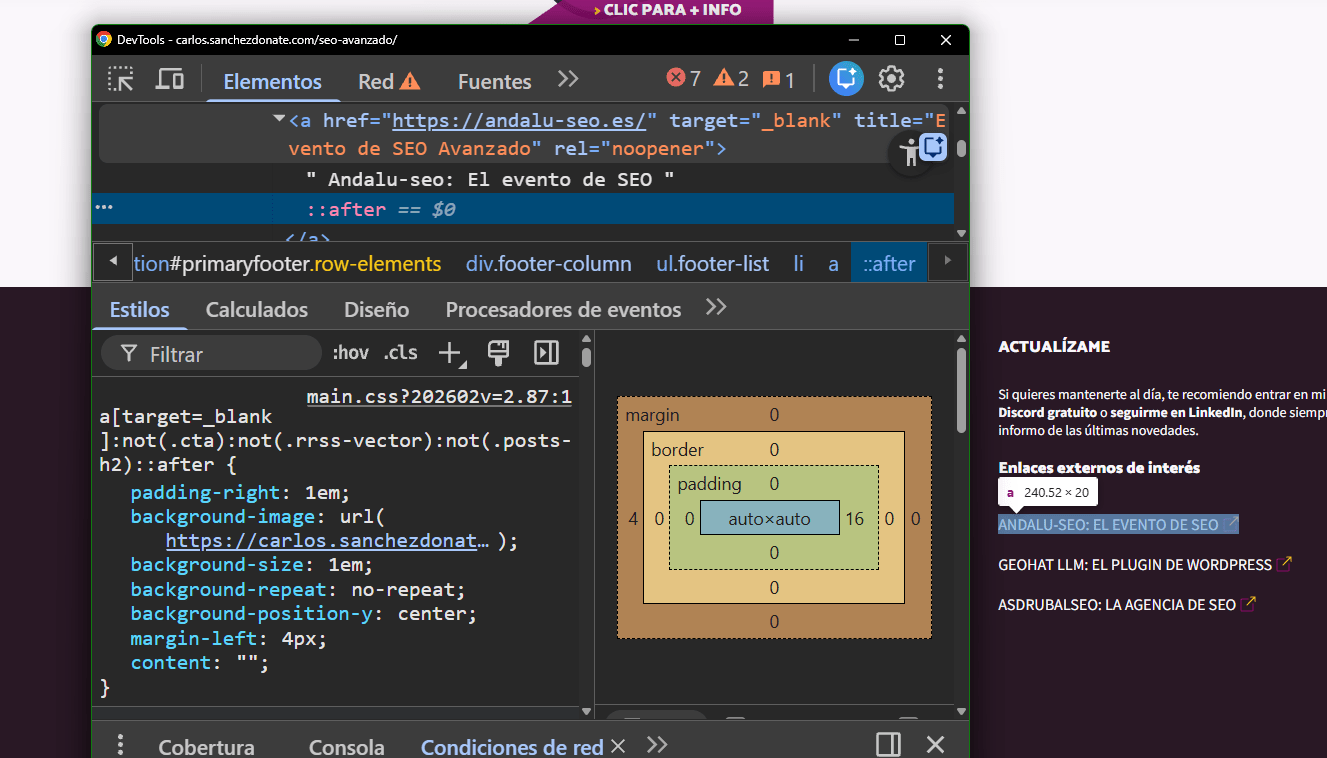
Aquí el límite puede ser tu imaginación, pero con un pequeño gesto puedes ayudar mucho al usuario a entender cómo va a navegar a tu web.
Por ejemplo podríamos hacer que aparezca un símbolo de PDF cada vez que tengamos un enlace a un PDF con el atributo download (que también ayuda al usuario, pues descarga el elemento directamente):
a[download][href$=".pdf"]::after {
content: "";
display: inline-block;
width: 1em;
height: 1em;
margin-left: 0.3em;
background-image: url("ruta/al/logo-pdf.svg");
background-size: contain;
background-repeat: no-repeat;
vertical-align: middle;
}
Este código hace que cada vez que alguien en un blog por ejemplo ponga un PDF descargable, tenga el logo de PDF, para que el usuario sepa donde va a ir con el enlace.
Cuando tenemos enlaces entrantes a nuestra web que son erróneos siempre podremos redirigir, ya hemos visto esas estrategias, pero siempre podremos jugar con esto.
Por ejemplo gracias al referrer podremos poner mensajes personalizados si los usuarios vienen de una web concreta.
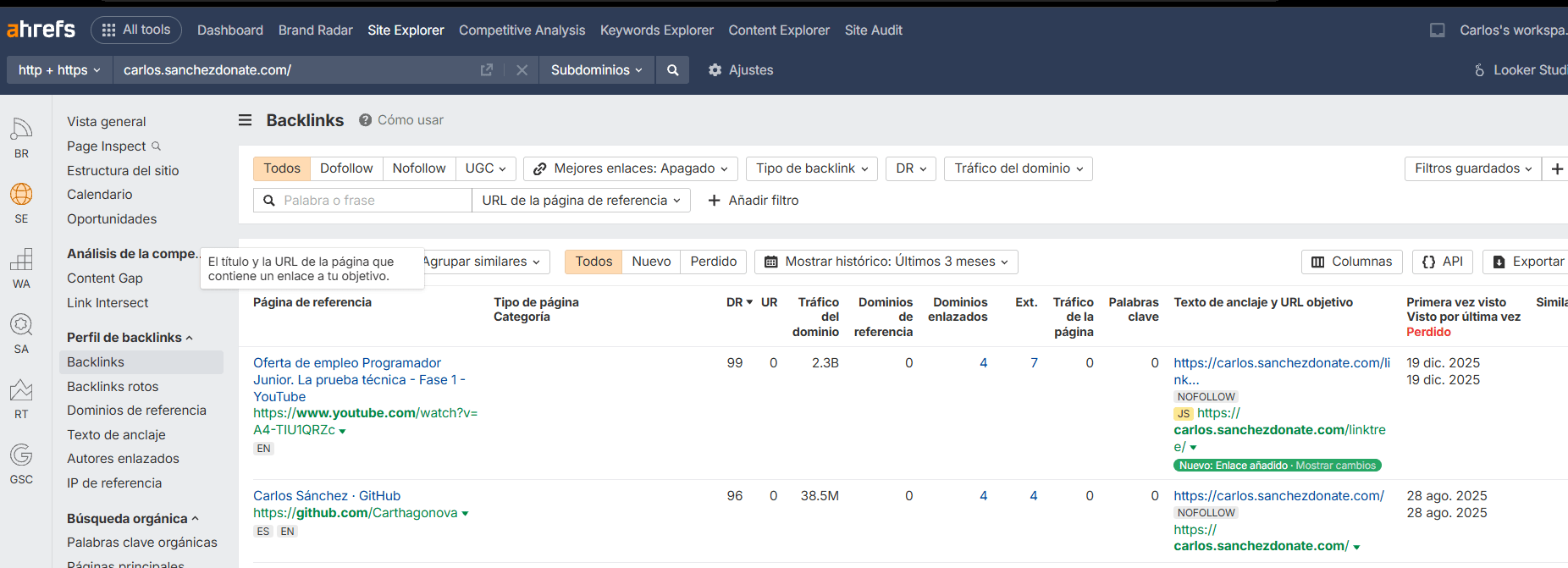
Podemos comprobar que hemos podido hacer bien para conseguir enlaces de otros usuarios con el perfil de backlinks de Ahrefs y ver su historial, si lo vamos ganando o los vamos perdiendo:
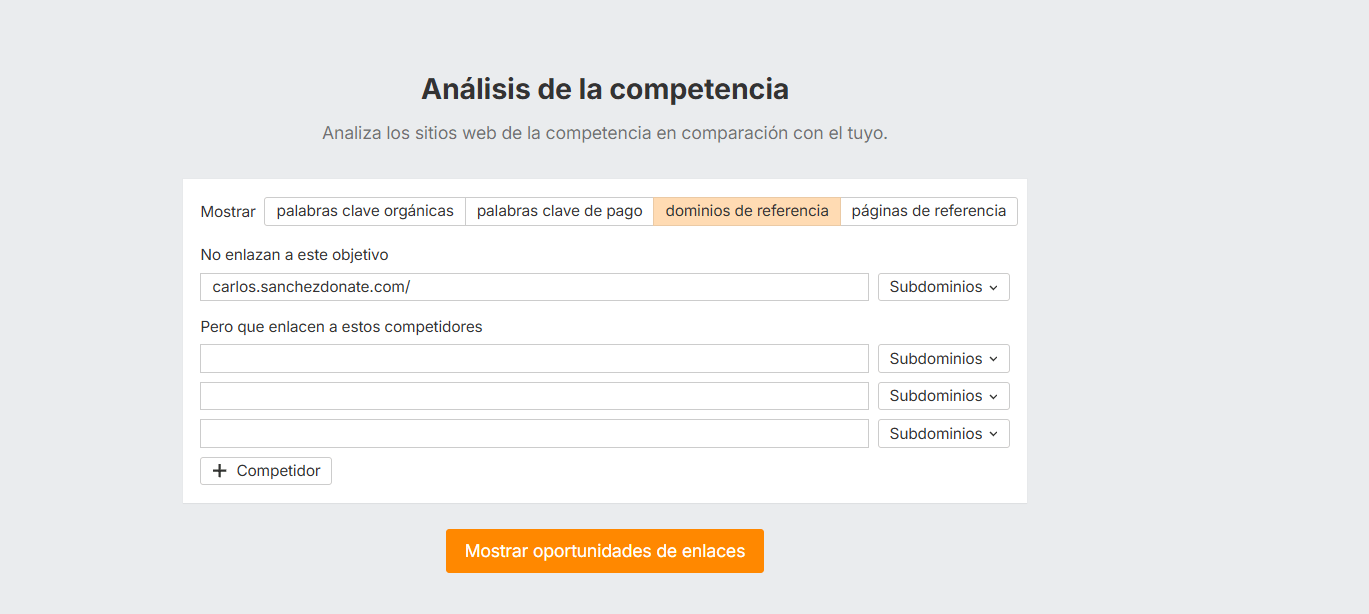
Pero hay un aspecto genial de todo esto, que es la herramienta de Análisis de la competencia.
Con esta herramienta podemos ver de forma instantánea los enlaces que “nos faltan”, juntamos a varios de la competencia y a nuestra web, y podremos observar fácilmente que enlaces tienen ellos que a nosotros se nos han escapado.
No obstante esto ya sería meterme en el extensísimo mundo del link building.
Reflexiones finales
Un enlace es una conexión, la esencia de internet
Los enlaces pese a todo lo que está avanzado internet siguen siendo una parte esencial de las tareas que podemos realizar para SEO (y también favoreciendo el ahora conocido GEO).
Como has podido ver mejorar el enlazado no es pagar por Link Building, tienes muchas opciones que puedes hacer onsite tanto para enlaces internos como externos.
Si aplicas todas las formas explicadas de detectar problemas y las implementaciones necesarias para solucionarlos, tienes mucho ganado ya que hace que tu web sea más navegable.
Para los desarrolladores, diseñadores y otro tipo de webmaster: Estos son los motivos por los que los SEOs podemos pedir breadcrumbs y otros elementos que os pueden traer de cabeza sin que entendáis por qué.
Para los SEOs, sean entrantes o salientes: ¡Larga vida a los enlaces!

