Por muy especiales y diferentes que consideremos nuestras webs siempre van a cumplir ciertos patrones y eso es bueno, especialmente cuanto más grande es nuestra web. Ya que si sabemos aprovechar estos patrones, podemos conseguir aplicar nuestras mejoras o auditorías de SEO en bloque.
Pero para poder utilizar esto a nuestro favor tenemos que saber cuáles son los lenguajes para búsqueda de patrones o elementos más útiles en cada caso. Entonces podremos sacarle partido a esos patrones de muy distintas formas.
Si bien es cierto que hay diversidad de lenguajes para la búsqueda de patrones nos centraremos en 3, que aunque puedan parecer complejos de aprender, merece la pena hacer el esfuerzo por el ahorro de tiempo que nos puede suponer.
Regex
Conocido como expresiones regulares, es utilizado para buscar patrones en cadenas de texto. Es muy potente y flexible y en caso de querer aprender solo uno, este sería el más polivalente.
Se puede utilizar para: Filtrar en un listado de URLs; encontrar información en una base de datos y encontrar elementos o atributos concretos de un documento HTML.
Tiene mucha aceptación y a día de hoy y se emplea en:
- Google Search Console.
- Cualquier lenguaje de programación.
- Servidores (vamos a ver ejemplos prácticos).
- Herramientas de SEO como Ahrefs.
Los códigos más habituales son los siguientes:

Fuente original: https://coderpad.io/
El uso avanzado de estos operadores nos va a permitir seleccionar exactamente el tipo de URL que nosotros deseamos, de una forma exacta, limitando el error humano y agilizando la tarea.
Aquí podemos ver una configuración para seleccionar las URLs de post ficticios que contienen la palabra “seo” cuando están dentro del subdirectorio /articulo/ o /blog/
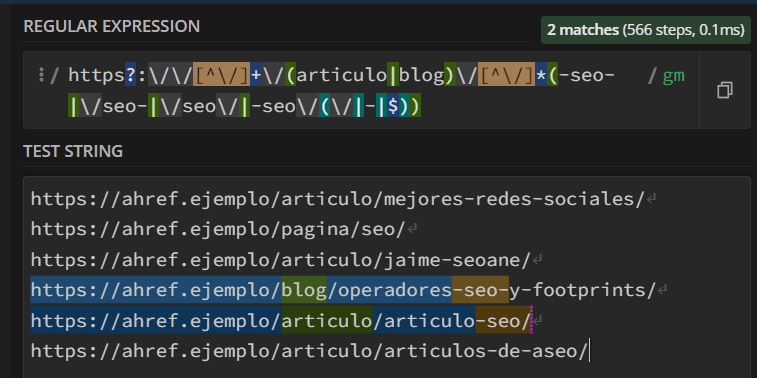
Además, lo que seleccionemos en paréntesis lo podemos “guardar” para sustituirlo en el lenguaje de programación que estemos utilizando.
Por ejemplo, podríamos hacer una redirección en masa para cambiar seo por posicionamiento web, o artículo\blog por “post” cuando estemos editando un servidor
Ejemplo de esto en un .htaccess:
RedirectMatch 301 ^/(articulo|blog)/(.*?)(-seo-|\/seo-|\/seo\/|-seo\/|seo($|\/|-))(.*)$ /post/$2posicionamiento-web$4$5
Por medio de los dólares y su numeración, podemos guardar el regex en el paréntesis.
Si quieres profundizar en regex, puedes ver este artículo que además te explica cómo aplicarlo en Ahrefs.
Selectores
Aunque este es el menos conocido de los 3 diría que es el más útil, pues te va a servir para distintas herramientas cuando navegues por el HTML, pero también para entender, modificar y crear mejor con CSS y JavaScript.
Los selectores, como su propio nombre indica, son para seleccionar elementos atributos o valores de HTML.
Evidentemente para poder entender los selectores tenemos que saber cual es la sintaxis básica de cualquier etiqueta de HTML.
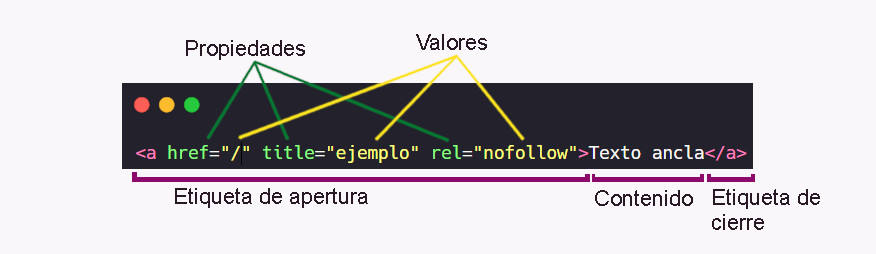
Esto nos va a permitir encontrar cualquier contenido o elemento que esté justo dentro de otra etiqueta, con un valor o una propiedad en específico.
Por ejemplo, si rastreamos todo el HTML de una web nos podría permitir ver todos los enlaces sin http:
a[href^="http:"]
También nos sirve para detectar todo tipo de elementos dentro de cualquier página de HTML. Ya sea por su etiqueta, atributo, valor y/o elementos padre.
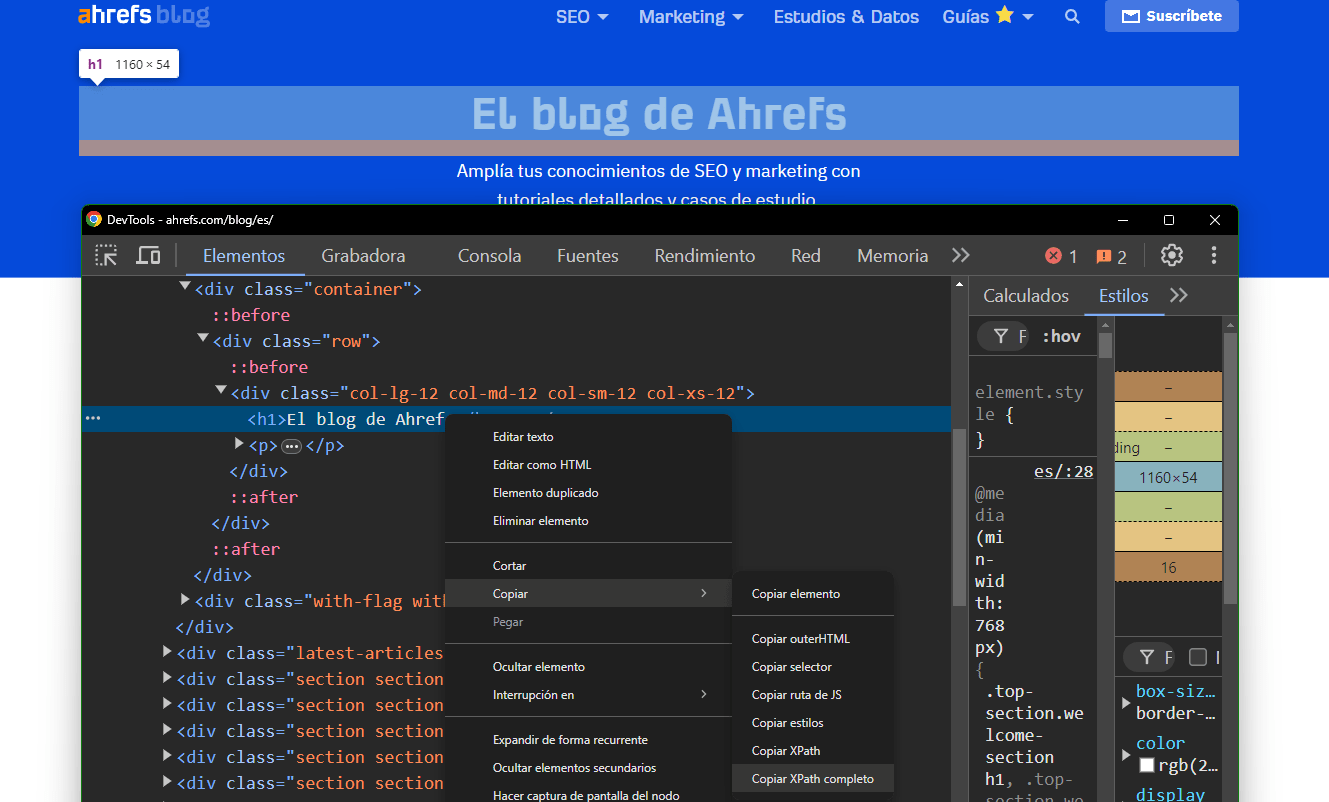
Un truco para coger un selector único y específico de una página de HTML es abrir la Consola de Chrome, inspeccionar elemento hasta encontrar el deseado, darle a la opción de copiar y copiar selector. Tal y como aparece representado en la imagen.
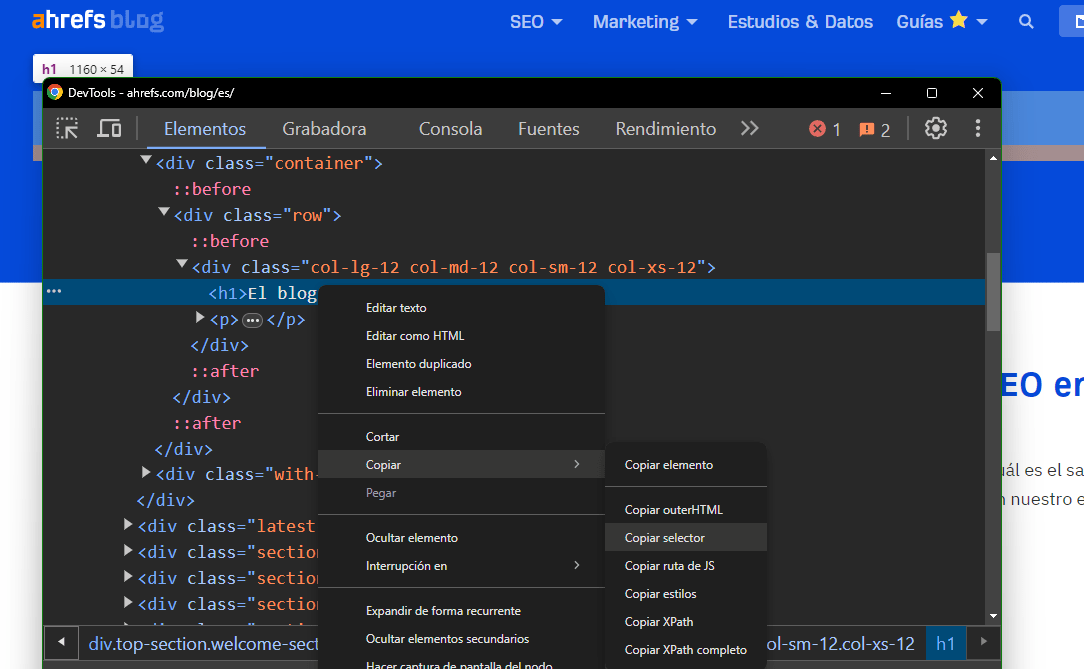
Este sería el selector específico del h1 del blog de ahrefs:
#content > div.top-section.welcome-section > div.container > div > div > h1
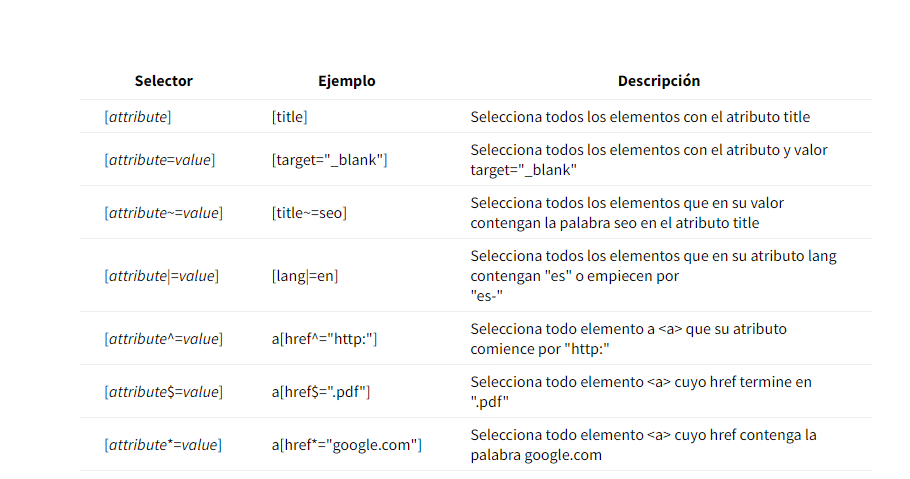
Selectores básicos:
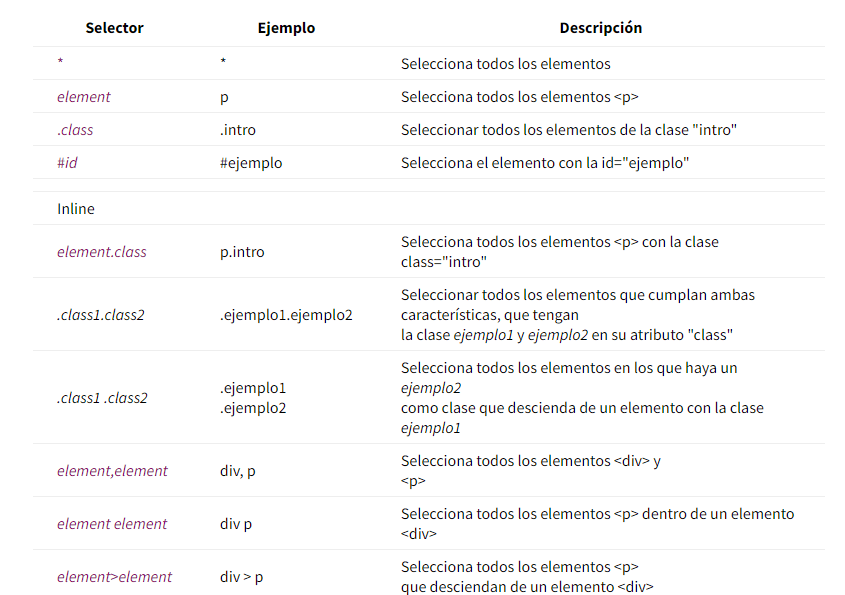
Selectores avanzados:
XPath
Se utiliza para navegar a través de elementos y atributos en HTML y XML. Funciona bastante similar a los selectores. En su origen se pensó para XML, pero es más flexible y un poquito más avanzado, ya que si que te permite navegar en cualquier dirección del documento a diferencia de los selectores (los selectores te permiten solo de arriba hacia abajo).
Además XPath es mucho más sencillo para aprender que los selectores, pero no te servirá para CSS o JavaScript.
Este sería el XPath específico para el h1 del blog de ahrefs:
/html/body/div[2]/div/div[1]/div[1]/div/div/h1
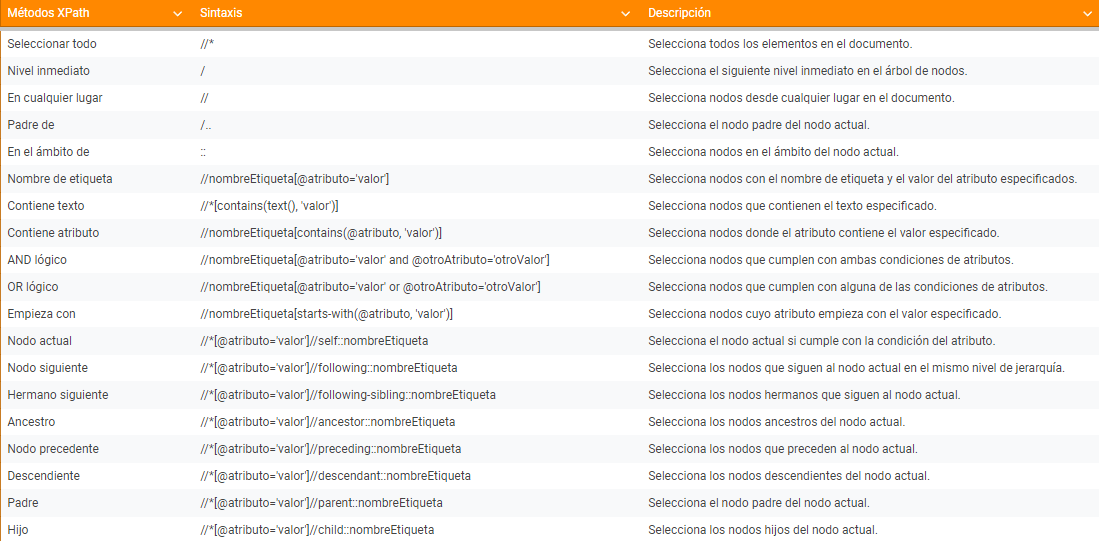
Aunque tiene su complejidad, como se puede observar en este “cheatsheet” que es más sencillo de aprender que los selectores o que regex:
En una web los elementos tienden a repetirse. Cuando se pretende hacer cualquier tipo de implementación técnica es conveniente saber detectar patrones y utilizarlos a nuestro favor. De esta forma haremos nuestro entorno web mucho más sostenible, escalable y personalizable. Así podremos realizar los cambios que necesitamos de un ”solo golpe”.
Veamos unos cuantos ejemplos, pues el límite de lo que se puede hacer está en la imaginación:
Códigos de respuesta en masa
- Podemos hacer redirecciones en masa, cuestión que nos ayudará enormemente en las migraciones.
- Podemos generar un código de respuesta 4XX para URLs específicas. Por ejemplo, podemos hacer que toda URL con caracteres japoneses sea automáticamente un 404 si recibimos un “JAPANESE KEYWORD HACK”, un virus que afecta directamente al SEO
- Podemos forzar con un 503 en todo un subdirectorio. Por ejemplo cuando se está haciendo una migración por partes de una web en distintos idiomas. Para el periodo donde no está disponible pero no queremos que se desindexe.
Evitar la indexación
Podemos evitar la indexación de páginas en masa aún sin tener acceso al código si tenemos acceso al servidor. Por ejemplo, con este código evitaríamos la indexación de todas las páginas tras el directorio /tag/ en un htaccess:
FilesMatch "^tag/.+/"
Header set X-Robots-Tag "noindex"
</FilesMatch>
O en nginx:
location ~ ^/tag/.+/
add_header X-Robots-Tag "noindex";
}
Eliminar h1 en bulk
Puede ocurrirnos que estemos en una web donde no podemos tocar el lenguaje de servidor en el que esté programada la web. Por ejemplo puede ocurrir que tengamos plugins en una web que nos genere encabezados indeseados, ya sea en la navbar o en la política de Cookies.
Esta práctica no es la más adecuada, ya que no ayudará a mejorar la velocidad de una web. pero si que es un parche funcional.
Utilizando selectores, podemos seleccionar ese H1 indeseado que se nos genera y eliminarlo o modificarlo (que no ocultarlo) por JavaScript. De esta forma nos liberaremos de tener nuestros headings mal jerarquizados en el momento de la renderización si nuestra web es lo suficientemente rápida.
Añadir data-nosnippet
El mismo procedimiento nos valdría para elementos repetitivos de nuestra web que no queremos que aparezcan en las descripciones de nuestras SERPs. Si no tenemos acceso al código, pero sí podemos añadir Scripts, como por ejemplo con Google Tag Manager, podemos añadir a esos elementos concretos a lo largo de nuestra web un data-nosnippet para asegurarnos de que ese contenido no aparece como “fruto de nuestras metadescripciones”.
Buscar contenido en un bloque en particular
Es bastante posible que en algún momento necesitemos una información muy concreta de nuestra web. Por ejemplo la descripción o un apartado concreto de nuestra ficha de producto con su URL.
En este caso podremos utilizar nuestra herramienta de Scrapeo favorita, añadir XPath o un Selector para encontrar justo el apartado repetitivo de nuestra web, y sacar un listado con solo el texto que necesitamos.
Analíticas
El Regex puede ser muy utilizado en herramientas de analítica como Google Analytics y su familia, para Google Search Console o con Ahrefs. Esto nos permitirá hacer un análisis más certero sobre las URLs que nos interesan. Aunque para ello también es importante tener una arquitectura jerarquizada y ordenada, un motivo más para hacer buenas prácticas de SEO.
Preguntas que acaban en tu web
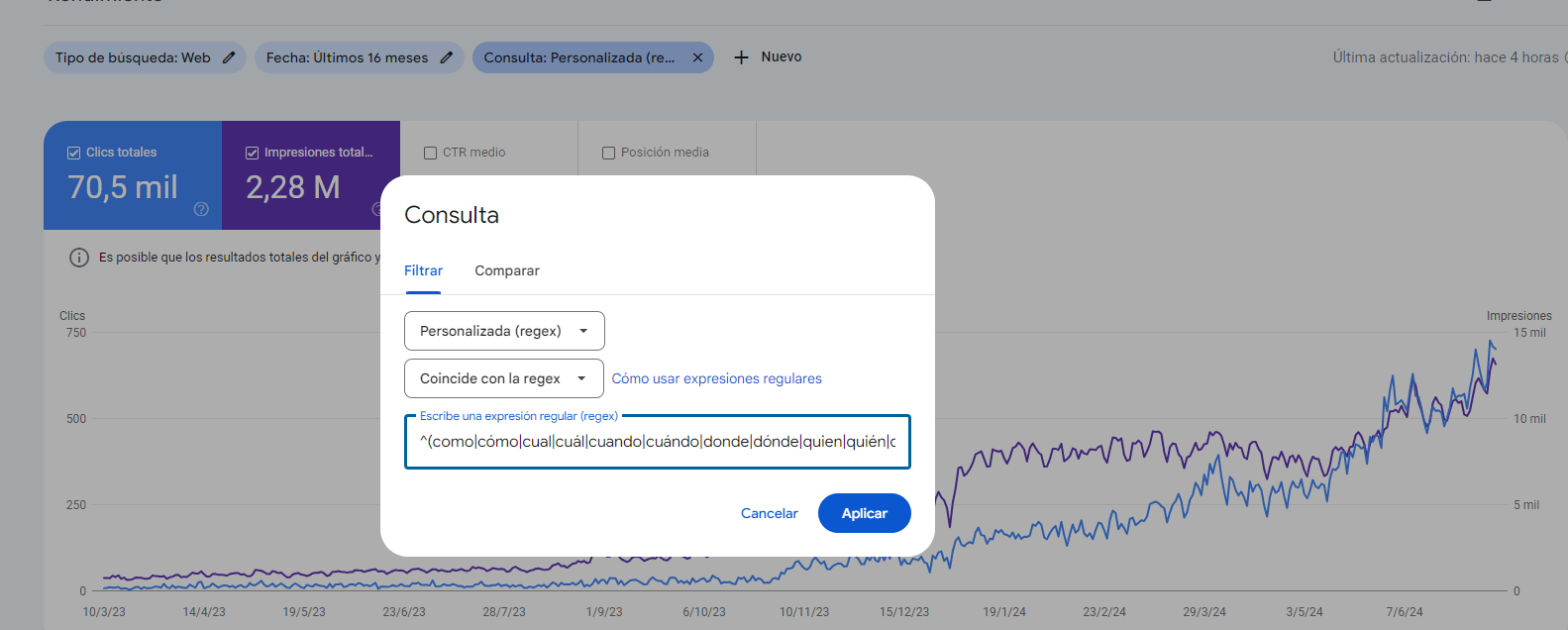
Se puede hacer un truco con Regex en Google Search Console para averiguar los tipos de preguntas que suele hacer un usuario en Google para ver qué páginas satisfacen ciertas intenciones de búsqueda.
Para ello podemos poner las expresiones que indican pregunta en el idioma que estemos analizando. Pongo un ejemplo en español:
^(como|cómo|cual|cuál|cuando|cuándo|donde|dónde|quien|quién|que|qué|por que|por qué|para que|para qué|cuanto|cuánto|cuantos|cuántos|cuantas|cuántas)\b
Auditorías
Repetición de términos en nuestra web
Nos puede servir para auditorías y depuración de contenido. Si queremos saber cuánto se repite un término nuestro en nuestra web podemos ir al Site Audit de Ahrefs, acceder al Page explorer y darle al filtro avanzado. Y configuras lo que quieras buscar a tu gusto, para este caso he aplicado la búsqueda en page text, dónde podré utilizar regex para palabras concretas que se repitan en la web.
Site Audit > Page Explorer > Advanced Filter
La herramienta nos lo pondrá bastante sencillo ya que nos permitirá filtrar y añadir condicionales, por lo que no necesitaremos un regex especialmente avanzado.
Aquí expongo un ejemplo simple de cuantas veces aparece la palabra SEO separada (para evitar seotérminos):
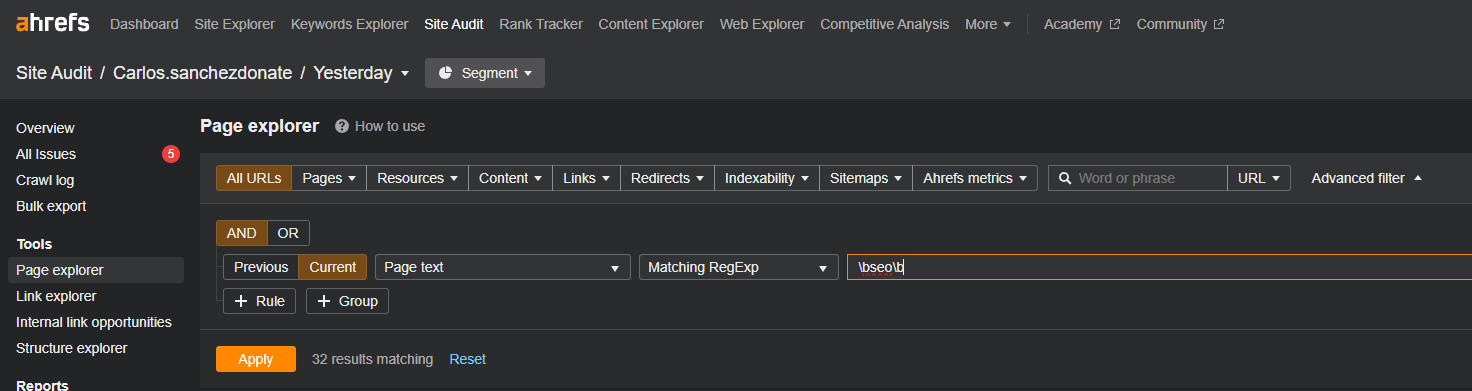
No obstante, esto nos permite buscar de forma rápida multitud de términos y variaciones de una forma sencilla. Sobre todo cuando una palabra tiene diferencias entre plural/singular, masculino/feminino (con otros idiomas como el alemán que dispone del género neutro se hace más útil y divertido).
Esto puede ser útil por ejemplo para detectar palabras y mejorar el enlazado.
Patrones en páginas antiguas
También podemos utilizar regex para detectar alguna práctica que se hiciese en una página del pasado.
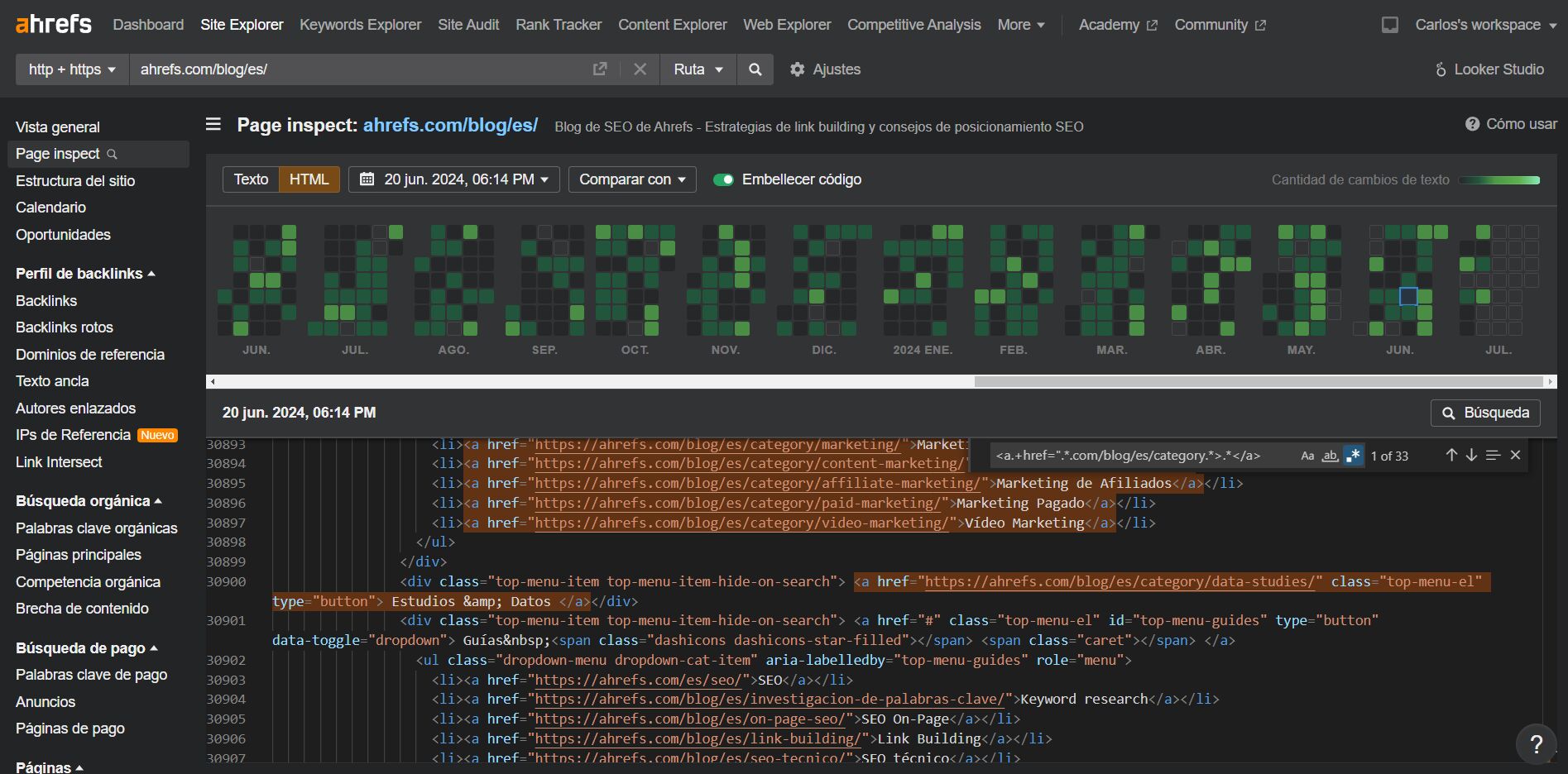
En este ejemplo podemos ver cómo analizar la cantidad de URLs que iban a un tipo de página en concreto al darle en el buscador al “simbolito” que significa búsqueda con regex. ![]()

