What “Crawled - Currently Not Indexed” Means In Google Search Console
The status “Crawled - currently not indexed” in Google Search Console means that Google has successfully visited your page but has chosen not to include it in its search index. This differs from “Discovered - currently not indexed,” which indicates that Google is aware of the URL but hasn’t yet crawled it. Essentially, Google knows the page exists, but doesn’t consider it valuable enough to appear in search results.
A page can also be moved to this status after previously being indexed. This is one of several indexing statuses Google puts pages in within the GSC reports.
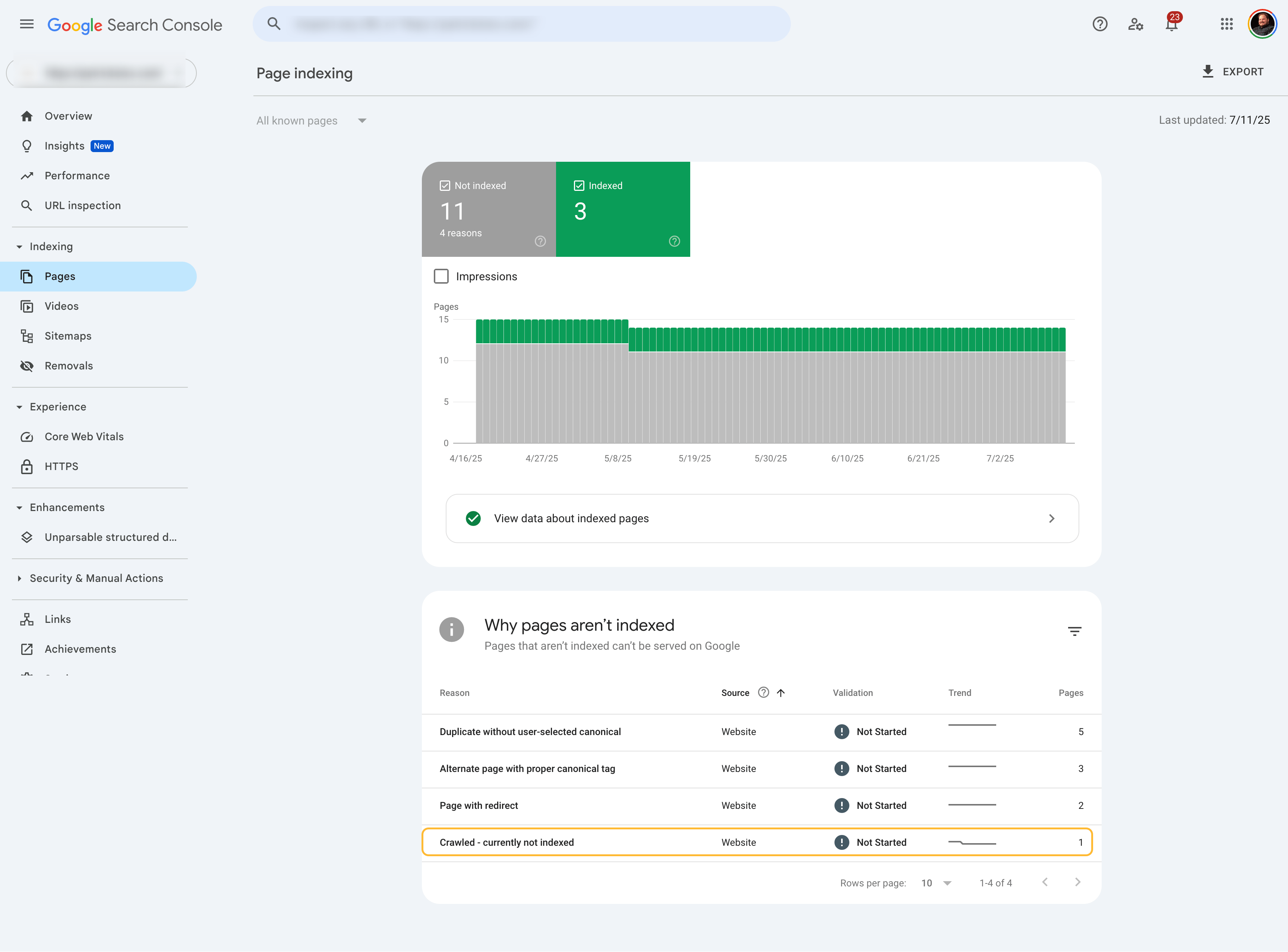
Reasons for this status
There are several reasons why a page might be crawled but not indexed:
- Content Quality Issues:
- Thin or low-quality content: Pages with minimal or unhelpful information are less likely to be indexed.
- Duplicate content: Having similar or identical content across multiple pages can confuse Google and result in de-prioritization.
- Lack of relevance: Content that doesn’t adequately address user intent or is irrelevant to the target audience may be overlooked.
Ahrefs AI Content Helper can help with this.
- Technical Issues:
- Noindex tags: The page might be explicitly excluded from indexing using a “noindex” meta tag.
- Robots.txt blocks: The robots.txt file might inadvertently block Google’s crawlers from accessing the page.
- Canonicalization issues: Incorrectly implemented canonical tags can mislead Google about the preferred version of the page.
- Server errors: Issues like 404 or 500 errors can hinder Google’s ability to crawl and index the page.
Ahrefs Site Audit will check for all of these technical issues and show you how to fix them.
- Other Factors:
- Crawl budget limitations: Large websites might face issues with Google’s crawl budget, meaning not all pages can be crawled and indexed.
- Low domain authority: For new or less authoritative websites, Google might be more selective about the content it indexes.
- Slow page load speed: Slower loading times can negatively impact user experience and signal lower quality to Google, potentially affecting indexing.
- Website architecture and internal linking: A poorly structured website or lack of internal links can make it harder for Google to discover and understand the importance of your pages.
How to address the “Crawled - currently not indexed” status
Here’s what you need to fix to get your page indexed:
- Improve content quality: Focus on creating unique, valuable, and in-depth content that addresses user needs and avoids duplication.
- Ensure proper technical setup:
- Check for and remove any misplaced “noindex” tags from the page.
- Verify your robots.txt file isn’t blocking the page from crawling.
- Use canonical tags correctly to specify the preferred version of a page.
- Resolve any server errors or page loading issues promptly.
- Optimize website architecture and internal linking:
- Structure your website logically with clear navigation and categories.
- Build a strong internal linking structure, linking to important pages from other relevant content.
- Request re-indexing:
- Use the URL Inspection Tool in Google Search Console to request a re-crawl of the page after making improvements.
- Be patient and monitor:
- Understand that indexing can take time, especially for new pages or websites.
- Regularly check Google Search Console for indexing issues and track the status of your pages.
Final Thoughts
Crawled currently not indexed typically points to some kind of quality issue. Fix that, and the pages marked with this issue will likely be indexed.

