We know that AI assistants like ChatGPT access search indices, like Google and Bing, to retrieve URLs for their response. But how, exactly?
To find out, we’ve run a series of experiments looking at the relationship between the URLs cited by AI assistants, and the results found in Google when searching for the same topics.
So far, we’ve tested long-tail prompts (very long, very specific queries just like those you’d enter into ChatGPT); fan-out queries (mid-length prompts that relate to the original long-tail prompt); and today we’re testing short-tail keywords—ultra-short, ultra-specific “head” terms.
Short-tail keywords offer the clearest illustration of how AI citations track with Google results.
Based on three separate studies, our conclusion is that ChatGPT (and similar systems) don’t just lift URLs directly from Google, Bing, or other indexes. Instead, they apply additional processing steps before citing sources.
Even when we examined fan-out queries—the actual search prompts these systems send to search engines—the overlap between AI and search engine citations was surprisingly low.
In other words, while ChatGPT may pull from Google’s search index, it still appears to apply its own selection layer that filters and reshuffles which links appear.
It’s therefore not enough to identify fan-out queries and rank well for them—there are additional factors influencing which URLs get surfaced, that are outside of a publisher’s control.
Different query types tell us different things about how AI assistants handle information.
In our earlier research, Ahrefs’ data scientist Xibeijia Guan analyzed citation overlap between AI and search results for informational long-tail and fan-out prompts, using Ahrefs Brand Radar.
This time, she has taken a sample of 3,311 classic SEO-style head terms, covering informational, commercial, transactional, and navigational intent.
| Example query | Informational | Commercial | Transactional | Navigational |
|---|---|---|---|---|
| 1 | cincinnati bearcats basketball | best credit card rewards | pools for sale | onedrive sign in |
| 2 | protein in shrimp | soundbar for tv | shop girls dress | verizon customer support |
| 3 | what is cybersecurity | at home sauna | buy a domain | costco toilet paper |
Each keyword has been run through ChatGPT, Perplexity, and Google’s top 100 SERPs to analyze citation overlap between AI and search.
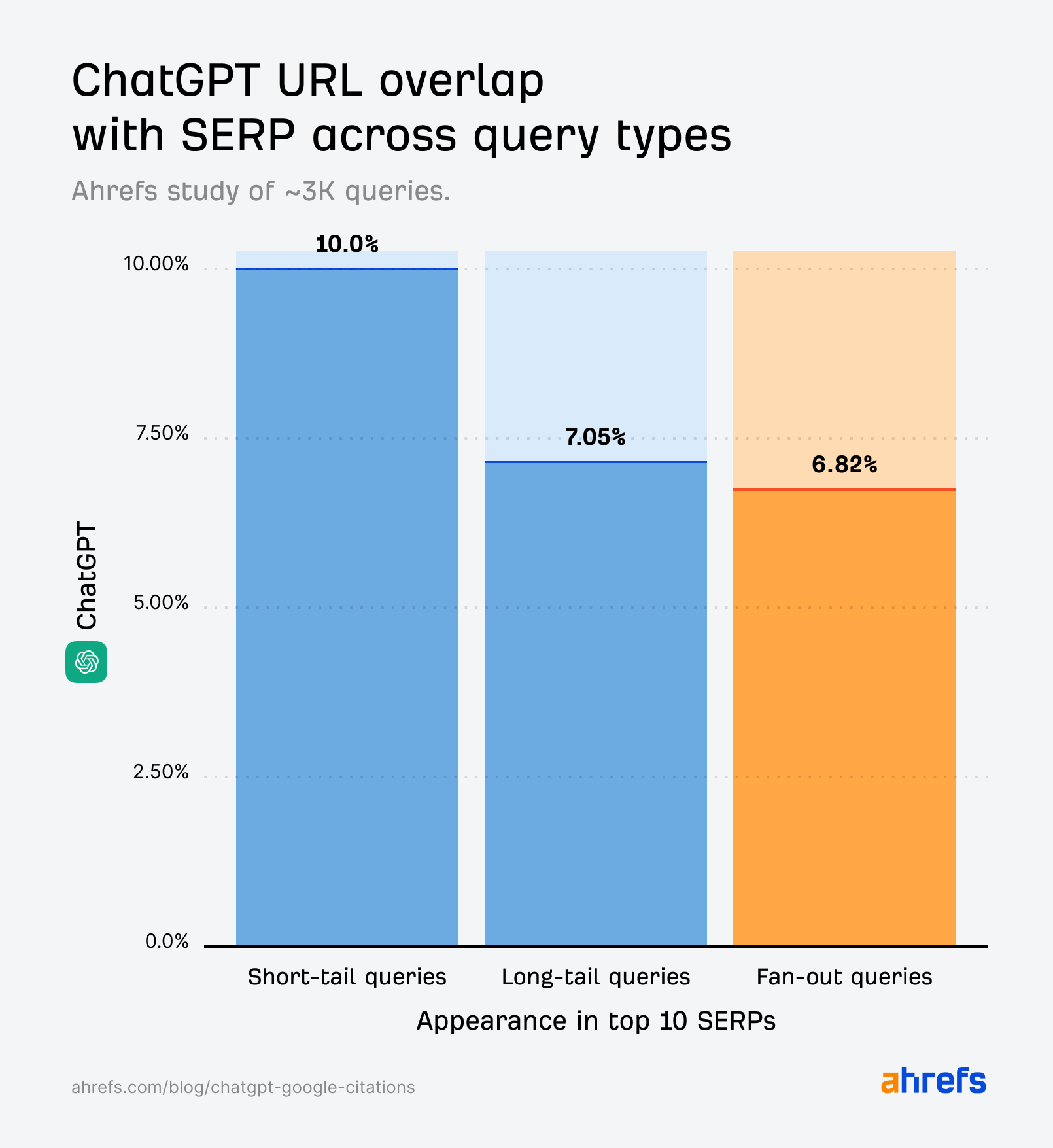
If anything were to align closely with Google’s results, you’d expect it to be short-tail queries—since that’s the classic way we search.
But that’s not quite the case.
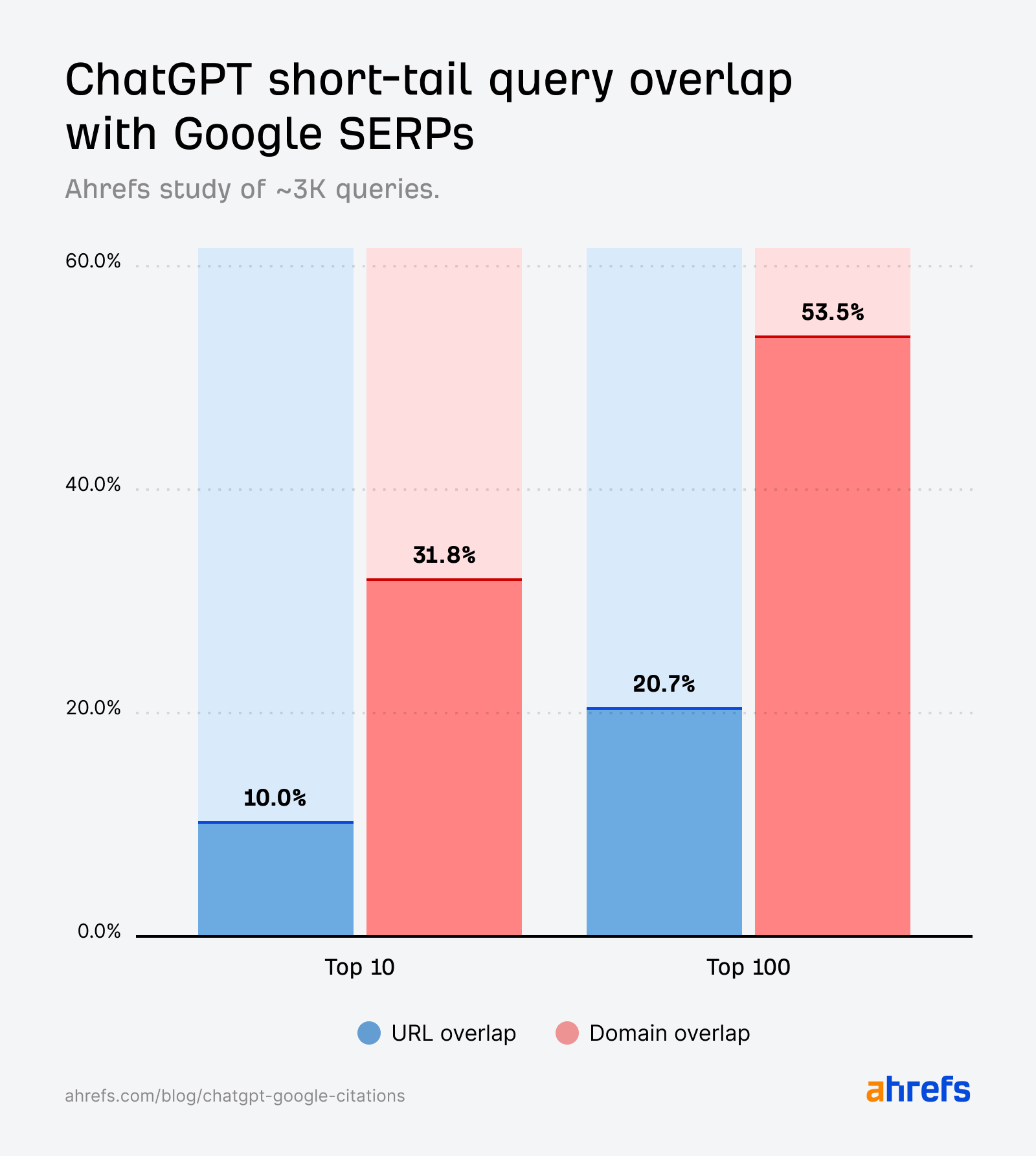
While the citation overlap for short-tail queries (10%) is slightly stronger than for fan-out queries (6.82%), it’s still much weaker than we’d expect if it were directly echoing the SERPs.
This is even more surprising, now we have confirmation that OpenAI and Perplexity have been scraping Google results via a third-party provider.
It’s possible we’d see more overlap if our study focused only on ‘real-time’ queries (e.g., news, sports, finance), since those are reportedly the kinds ChatGPT scrapes Google for.
Perplexity citations align closely with Google’s search results across short-tail queries.
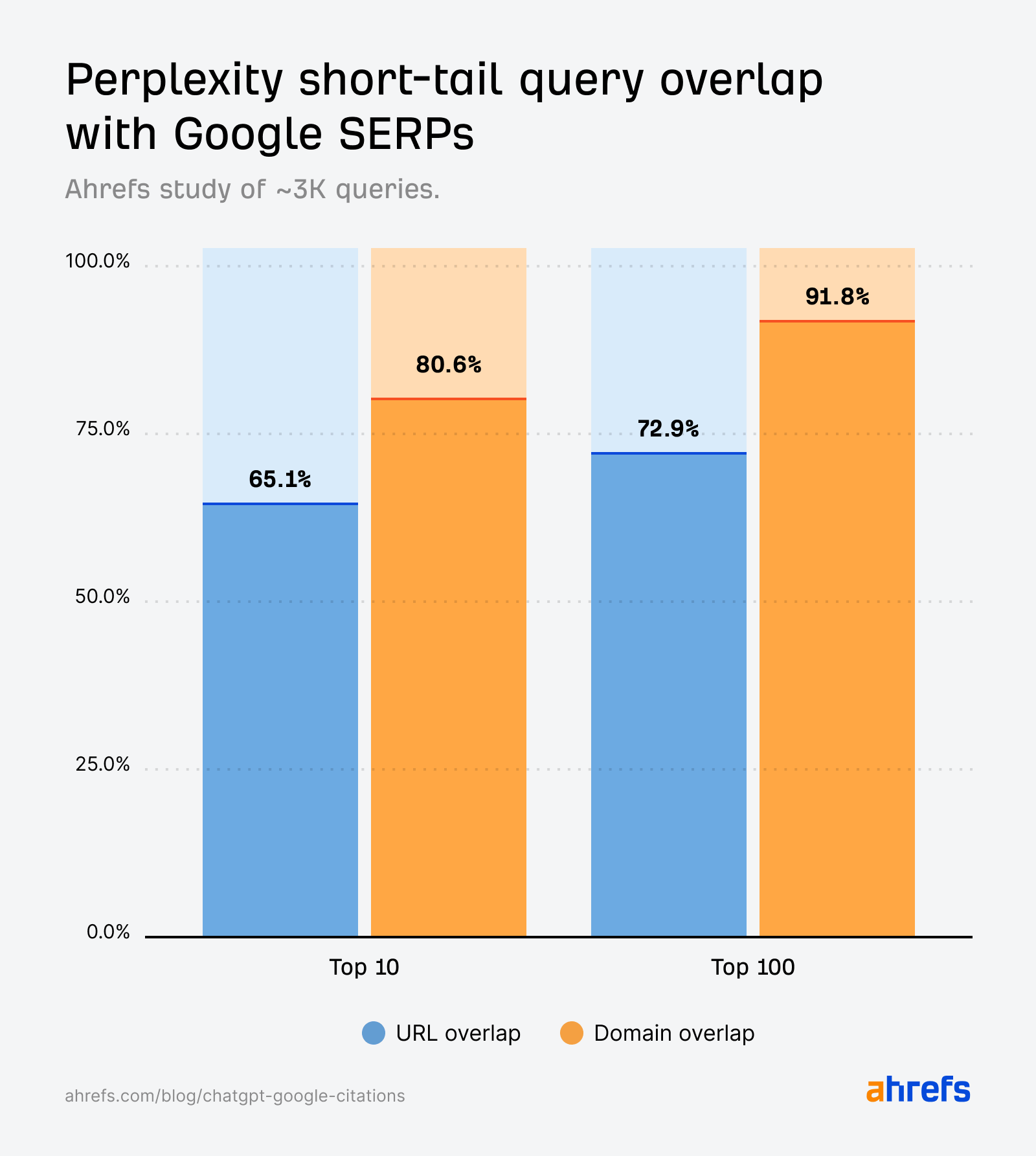
Unlike ChatGPT, overlap isn’t just visible at the domain level—most of Perplexity’s cited pages are also the exact URLs ranking in Google’s top 10.
This mirrors the findings in our long-tail query study, where Perplexity responses most resembled Google’s results, reinforcing its design as a “citation-first” engine.
Domain overlap is consistently higher than URL overlap, suggesting that ChatGPT and Perplexity cite the same websites as Google—but not the exact same pages.
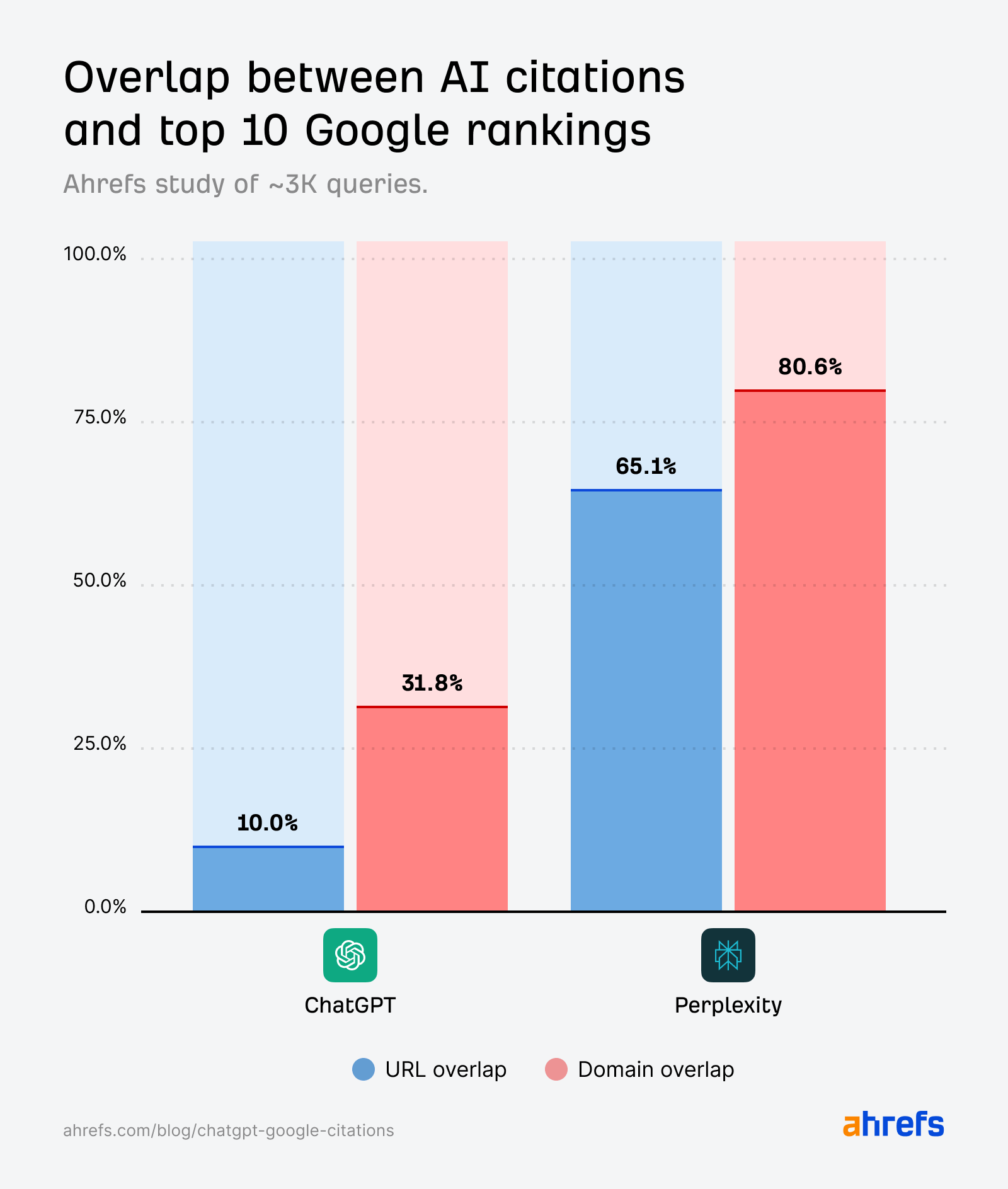
In ChatGPT, the domain-URL gap is especially wide—31.8% vs. 10%.
In other words, ChatGPT cites ranking domains ~3X more than ranking pages.
On the one hand, this could mean ChatGPT selects different pages from the same domains as Google.
For example, Google cites one page from ahrefs.com/writing-tools/, while ChatGPT finds a better “fit” on ahrefs.com/blog/ and cites another.
If true, this reinforces the value of creating cluster content—optimizing multiple pages for different topic intents, to have the best chance of being found.
Another possibility is that both lean on the same pool of authoritative domains, but disagree on arbitrary pages.
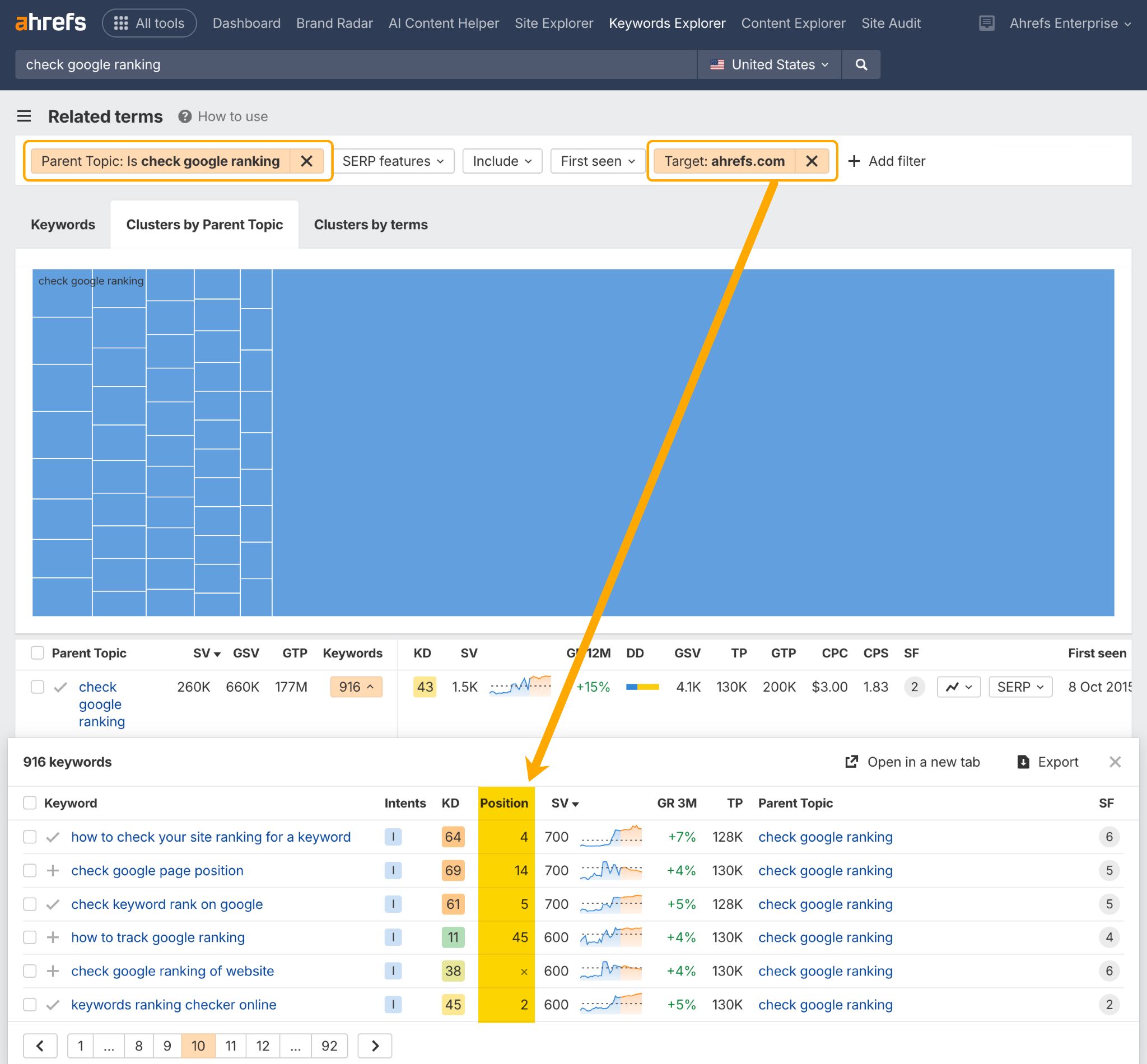
You can check the SEO performance of your cluster content in the Related Terms report in Ahrefs Keywords Explorer.
This will show you if and where you rank across an entire cluster of related keywords.
Just add a Parent Topic filter, and a Target filter containing your domain.
Once you’ve done that, head to Ahrefs Brand Radar to check on the AI performance of your cluster content.
Run individual URLs through the Cited Pages report in Ahrefs Brand Radar to see if your cluster content is being cited by AI assistants like ChatGPT, Perplexity, Gemini, and Copilot.
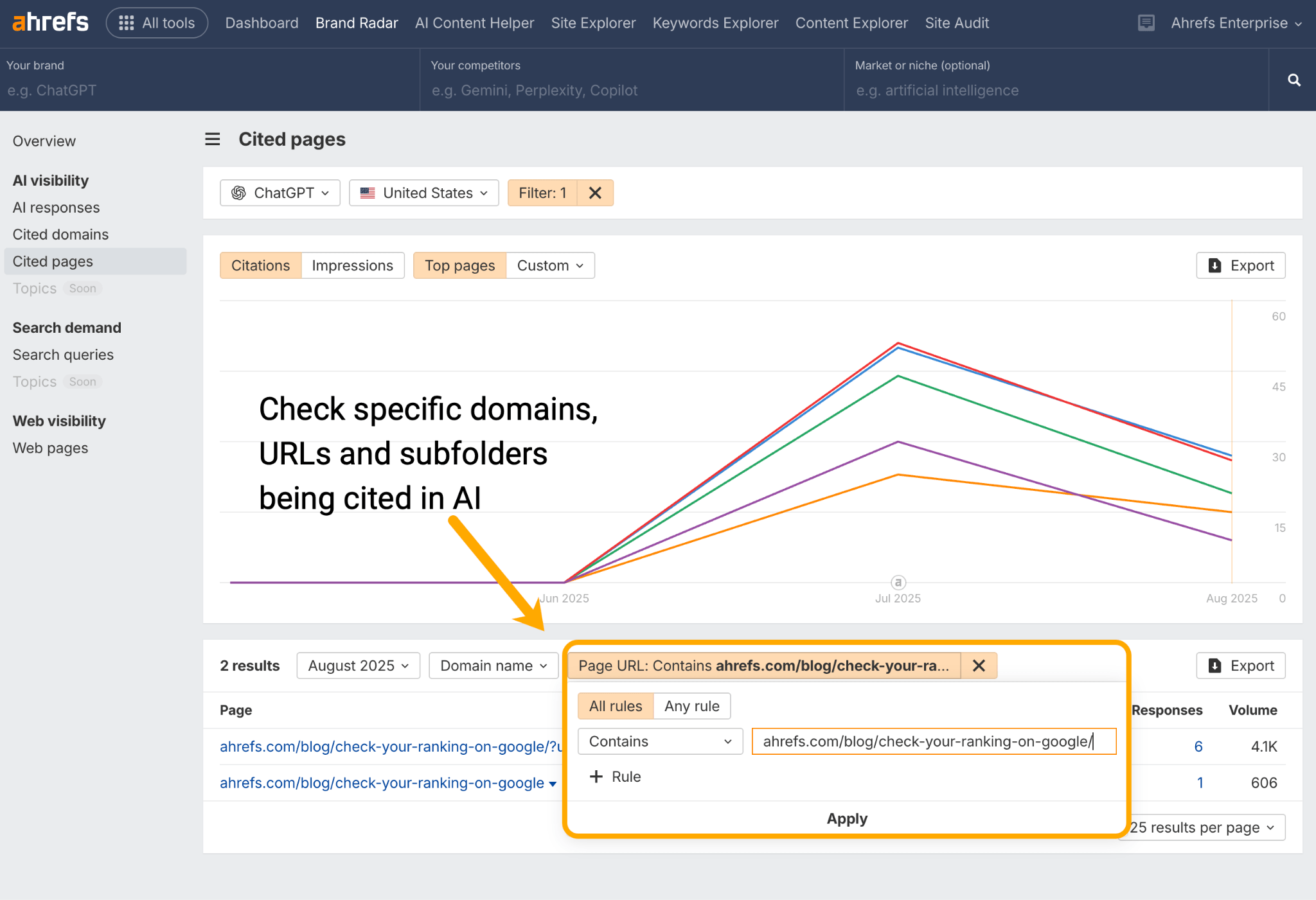
Work out if any content is missing from either surface, then optimize until you’ve filled those gaps and enriched the overall cluster.
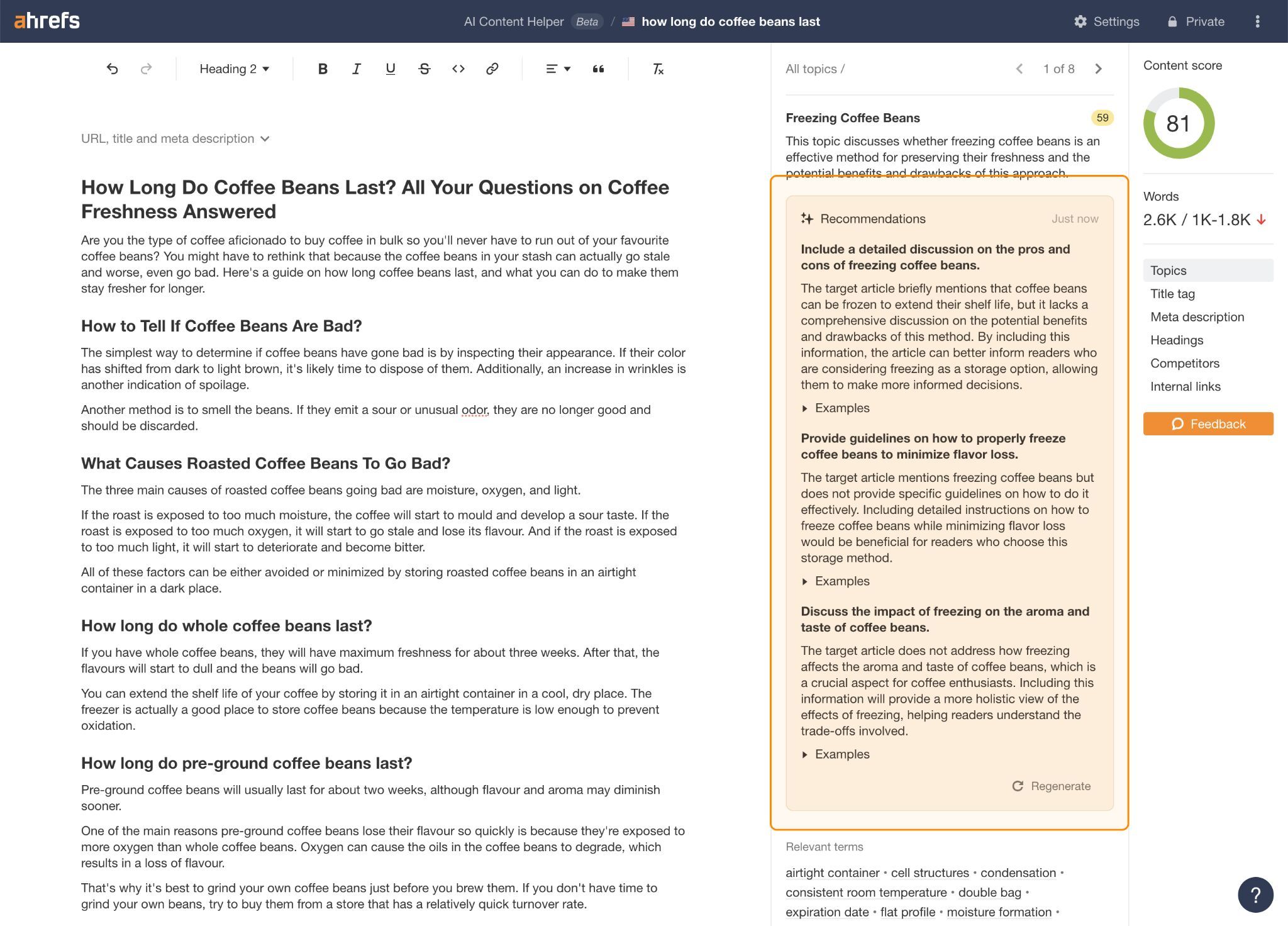
You can use topic gap recommendations in Ahrefs’ AI Content Helper to help with this.
Short-tail queries show closer SERP-AI alignment than natural language prompts—especially when it comes to Perplexity.
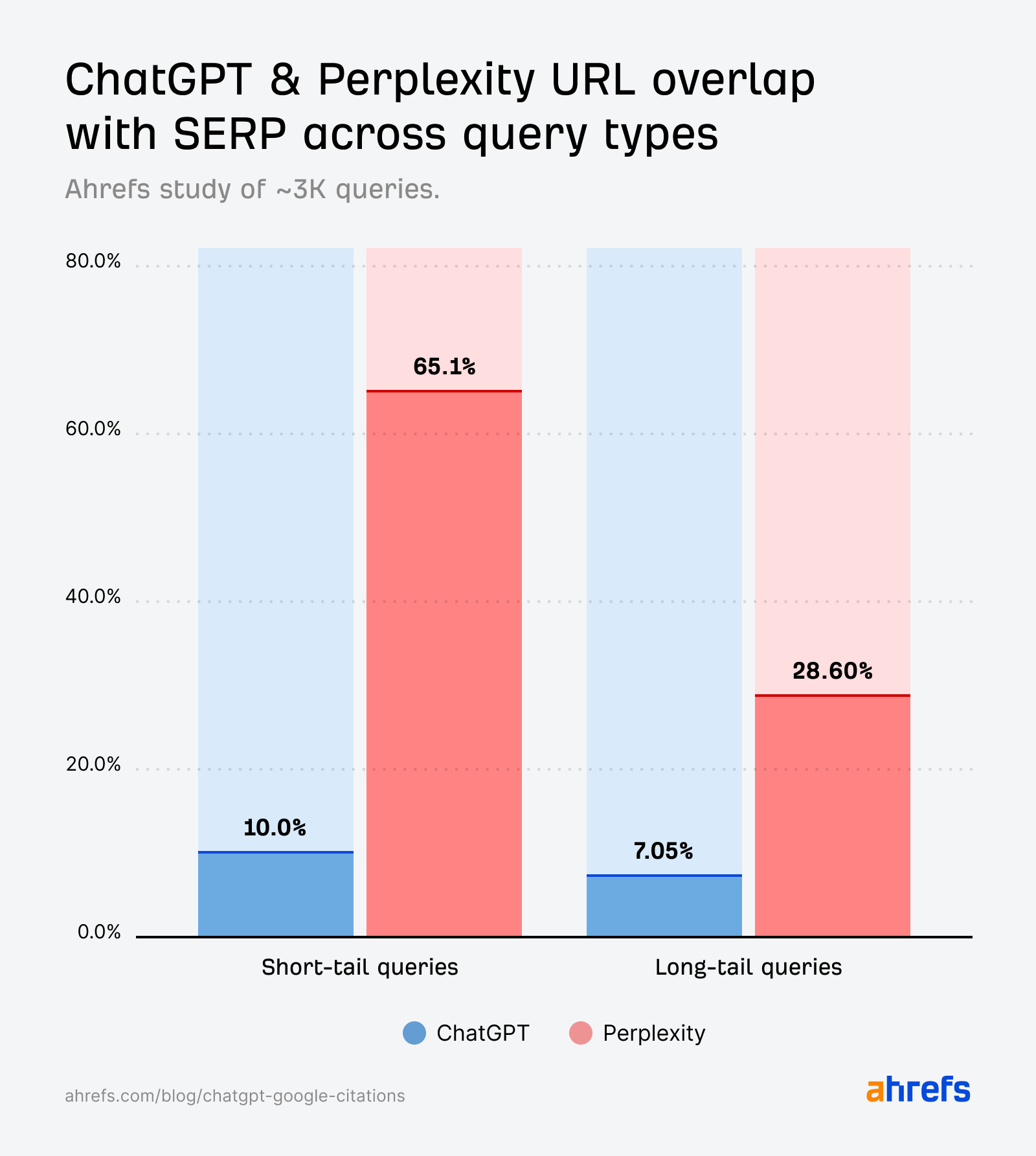
But the ChatGPT citations generated by fan-out queries (first studied by SQ and Xibeijia) show the least overlap. They match only 6.82% of Google’s top 10 results.
We’re not comparing apples-with-apples here. These percentages represent different studies, and different sized datasets.
But each study produces similar findings: the pages that ChatGPT cites don’t overlap significantly with the pages that Google ranks. And it’s largely the opposite for Perplexity.
One other thing we haven’t mentioned is intent. The greater citation overlap we see across short-tail queries could partly be explained by the relative stability of navigational, commercial, and transactional queries—which we didn’t assess in our previous studies.
Navigational, commercial, and transactional head terms have SERPs that don’t tend to change too often, because the set of relevant products, brands, or destinations is finite.
This stability means AI assistants and Google are more likely to converge on the same sources, meaning overlap is higher than it is for informational queries (where the pool of possible pages is far larger and more volatile).
Final thoughts
Across all three studies, the story is consistent: ChatGPT doesn’t follow Google’s sources, Perplexity does.
What’s surprising is that ChatGPT differs so much from Google, when we now know that OpenAI does scrape Google’s results.
My hunch is that ChatGPT does more than Perplexity to differentiate its results set from Google.
This theory from SQ seems the most probable one to me:
“ChatGPT likely uses a hybrid approach where they retrieve search results from various sources, e.g. Google SERPs, Bing SERPs, their own index, and third-party search APIs, and then combine all the URLs and apply their own re-ranking algorithm.”
Whatever the case, search and AI are shaping discovery side-by-side, and the best strategy is to build content that gives you a chance to appear on both surfaces.



