Across LinkedIn threads and AI‑SEO guides, the promise is the same: format your content into perfect “chunks” and you’ll get chosen for Google’s AI Overviews or cited in AI search results.
The problem?
Chunk optimization isn’t actually an SEO tactic. It’s a technical term borrowed from AI engineering—misunderstood, misapplied, and mostly out of your hands.
Before diving into the technical side, here are key takeaways:
- Chunk optimization ≠ rankings hack. Most SEOs using the term are just talking about good content structure: short paragraphs, scannable sections, clear subheadings.
- AI tools don’t see your content the way you think. Large language models (LLMs) don’t “read” your pages; they vectorize your text token by token. Tokens can be whole words or parts of words.
- Chasing “chunk optimization” is a dead end. You can’t control how Google, ChatGPT, or Perplexity chunk your content. Their pipelines change based on cost, model, and context.
- Focus on atomic content instead. Create self‑contained sections that answer a query clearly and can stand on their own. This approach works for humans and LLMs without gimmicks.
This guide explains how chunking actually works for AI search and offers a simple framework for structuring content that serves both humans and LLMs.
But you probably don’t need to change your workflow if you’re already structuring your content well.
Chunking is the process of splitting long content documents into smaller, machine‑readable pieces so large language models can store, retrieve, and use them efficiently.
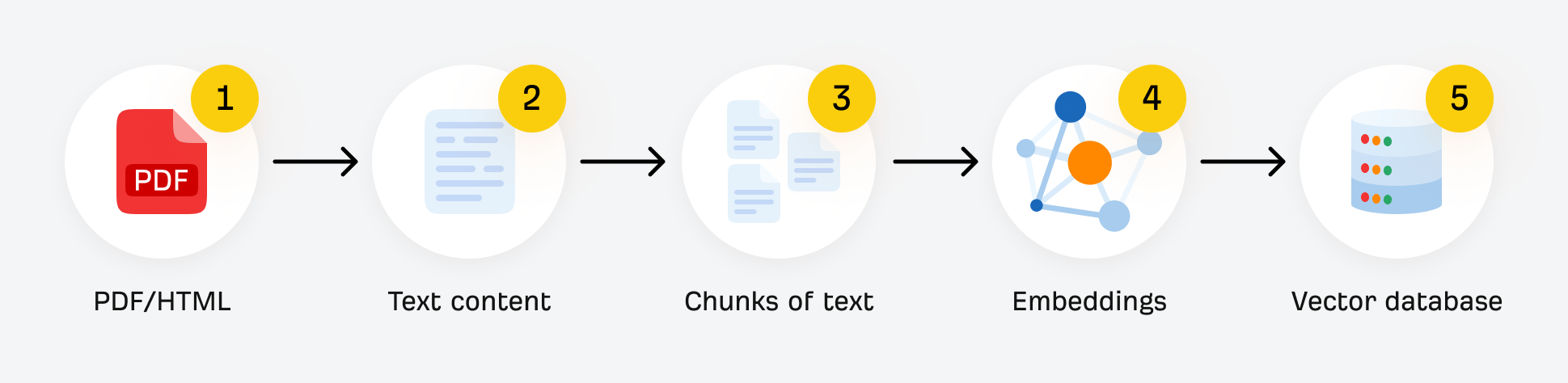
In AI pipelines like Retrieval‑Augmented Generation (RAG), this looks like:
- Breaking a document into chunks (small, self-contained sections of text)
- Embedding them as vectors (numerical representations that capture meaning for semantic search)
- Retrieving the most relevant chunks from the vector database to answer a user’s query
Think of chunks as the units of meaning that AI systems work with.
Only small portions of these chunks (often just a sentence or two) are surfaced to users. Engineers sometimes call these “passages” as they are the specific slices of text that best match the query.
Here’s the key for SEOs: this process is entirely automatic and model‑dependent. Different LLMs use different token limits and chunking strategies, optimized for precision, cost, and efficiency, not for your headings or paragraph length. Tokens are the smallest units of meaning, usually parts of words, used by AI models.
Whether your content uses 50‑word or 150‑word sections makes no difference to how Google or ChatGPT chunks it internally.
Chunking matters for AI search under the hood, but it’s not a lever you can optimize directly, and here’s why.
Even though content chunking is fundamental to how LLMs and AI search work, SEOs cannot meaningfully control it.
Chunking happens inside model pipelines, guided by token limits, retrieval strategies, and cost‑efficiency, none of which respond to your headings or paragraph length.
1. AI Engineers control the process
Chunking is an engineering decision. Models like Gemini, GPT‑4, or Claude handle document splitting and processing automatically. They retrieve, split, embed, and store text in chunks to achieve goals like:
- Reducing hallucination
- Improving answer quality
- Ensuring information accuracy
- Generating well-structured responses
The system, not your formatting choices, decides what counts as a “chunk” and how it’s sliced.
For instance, common chunking methods that AI engineers are experimenting with depend on model size, document type, and efficiency goals.
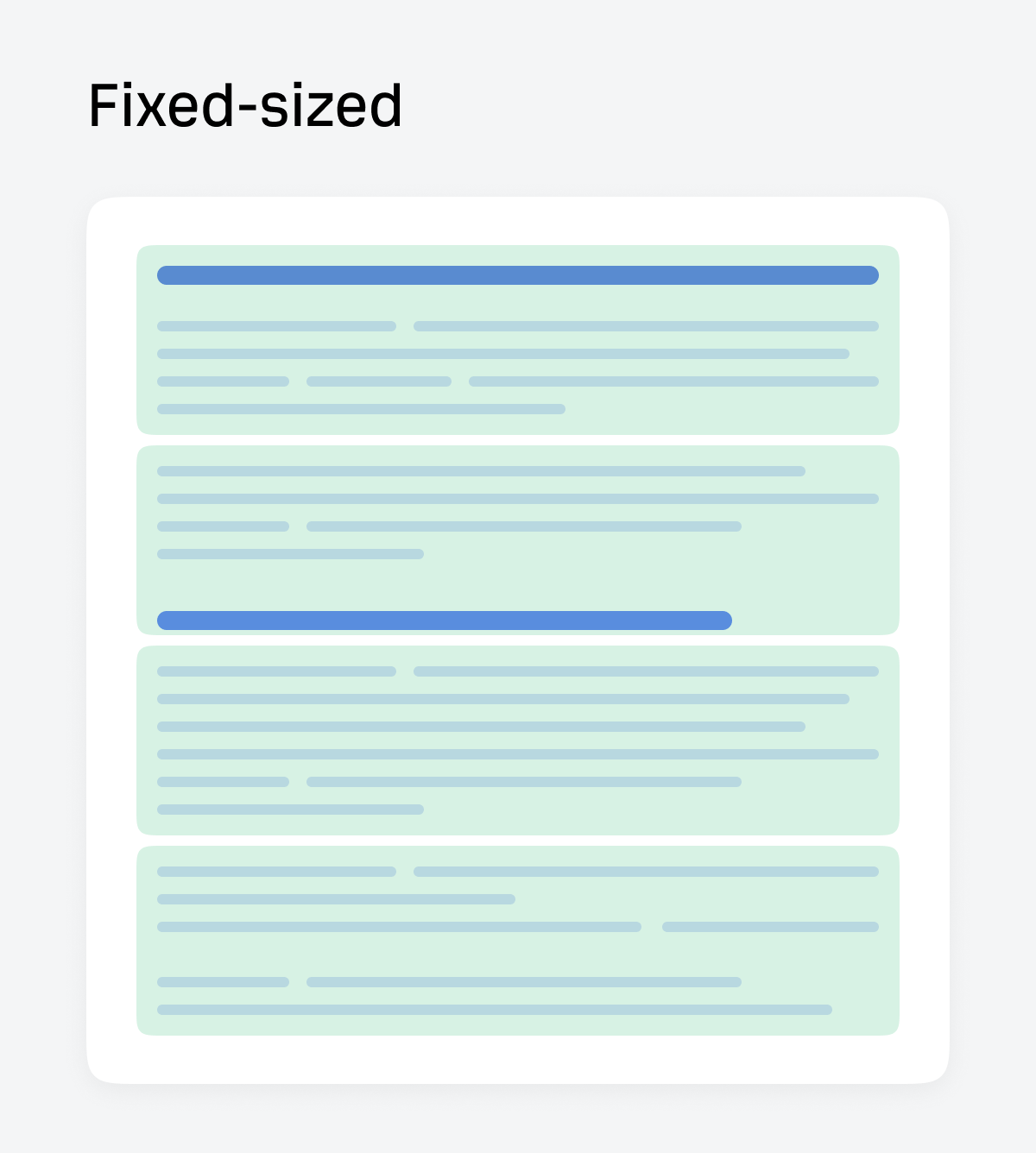
Fixed-size chunking
Fixed-size chunking splits text into equal token blocks (e.g., 500 tokens) with optional overlap, often irrespective of the article’s structure.
Sliding window chunks
The sliding window method of chunking creates overlapping chunks to preserve context between segments.

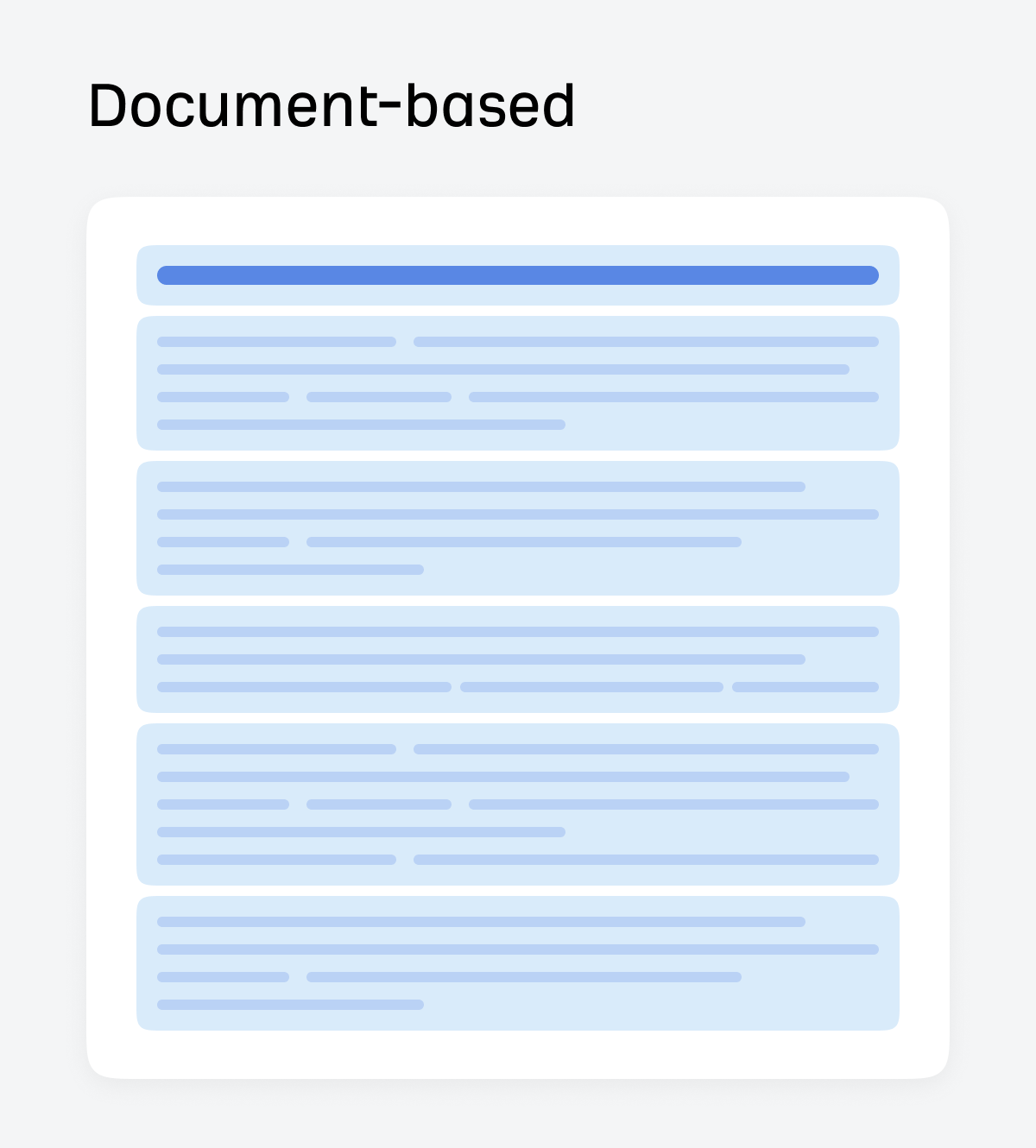
Document-based chunking
Document-based chunking splits along natural document structure like headers, sections, and tables.
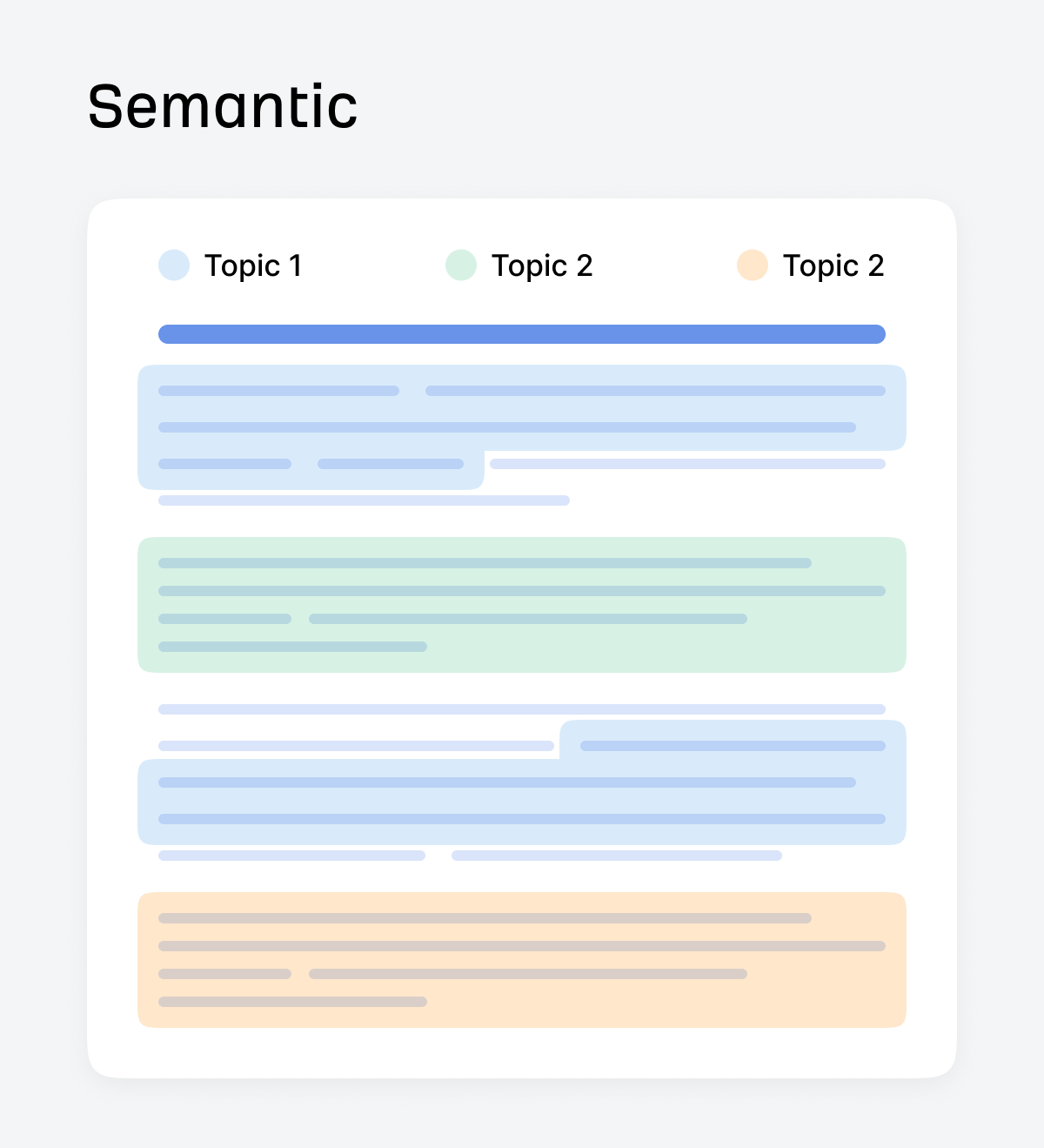
Semantic chunking
The semantic chunking method splits text based on topic shifts, using embeddings to detect boundaries.
Recursive chunking
Recursive chunking breaks content hierarchically (sections → paragraphs → sentences → words) for cleaner natural splits.

HTML-aware chunking
HTML-aware chunking methods use tags like <h2> and <p> to guide content splits.

LLM-guided chunking
LLM‑guided chunking uses a large language model to identify coherent “thought units”. It’s best for complex, unstructured content.

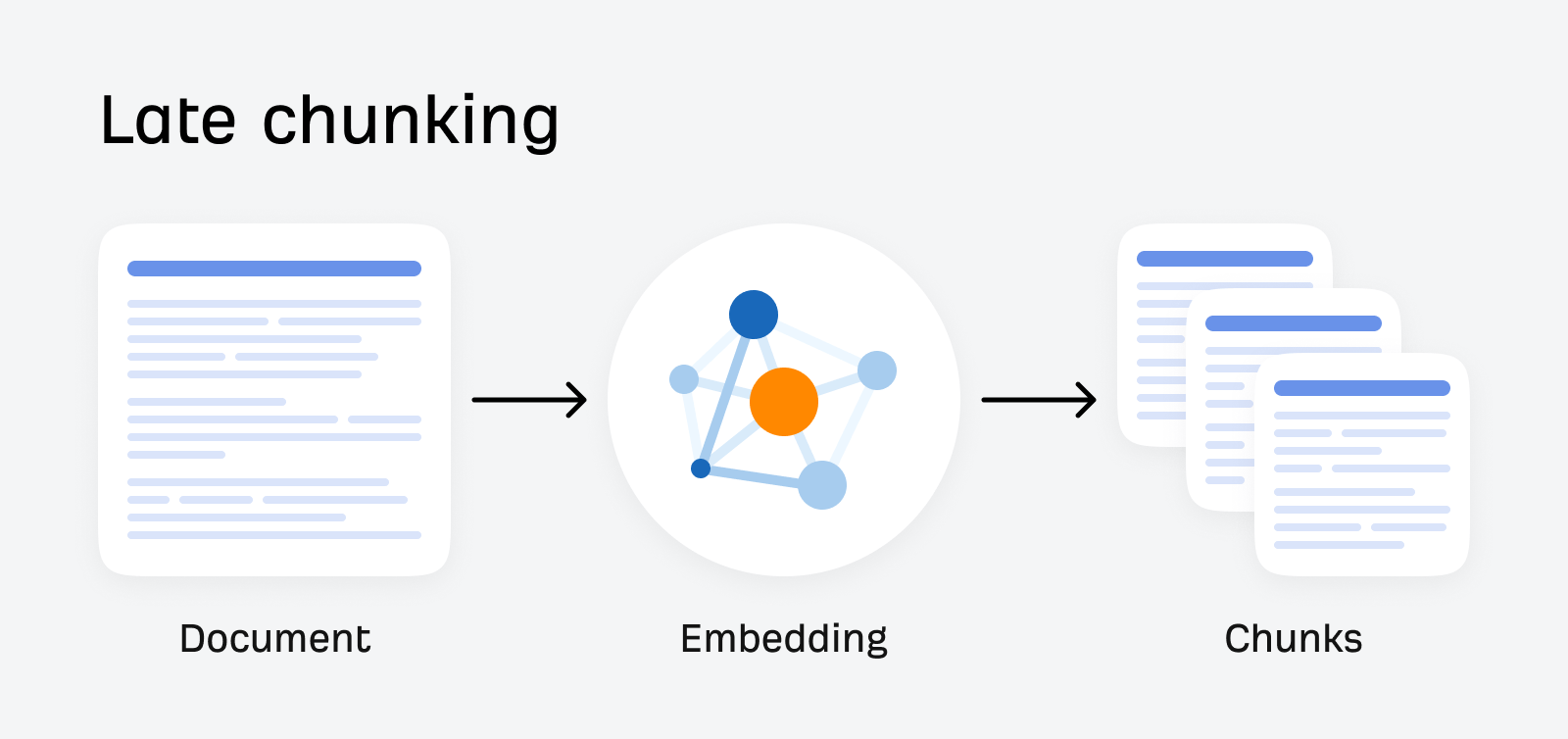
Late chunking
Late chunking is a method that first embeds the whole document and then splits it into chunks, keeping the context intact.
Each method has its own tradeoffs, but none rely on the kind of surface-level formatting tweaks most SEOs are chasing.
These strategies optimize retrieval accuracy and efficiency, but they happen automatically and are invisible to SEOs.
2. Every model uses a different strategy
There is no universal chunking method.
- Smaller models (512‑token limit) may split your content into 200‑300 token chunks.
- Long‑context models (1,000+ tokens) can handle much larger segments.
- Some pipelines use fixed‑size chunks, others use semantic or sliding‑window approaches.
Even if you correctly guessed one model’s preferences, your content is likely processed differently by another. For example, here are Vertex AI’s preferences:

Over time, each model becomes hyper‑personalized to its own performance needs.
AI engineers are incentivized to find even small efficiency gains because every fraction of a cent saved on compute can scale to millions of dollars at the production level.
They routinely test how different chunk sizes, overlaps, and strategies impact retrieval quality, latency, and cost, and make changes whenever the math favors the bottom line.
For example, here’s what such RAG performance experiments look like:
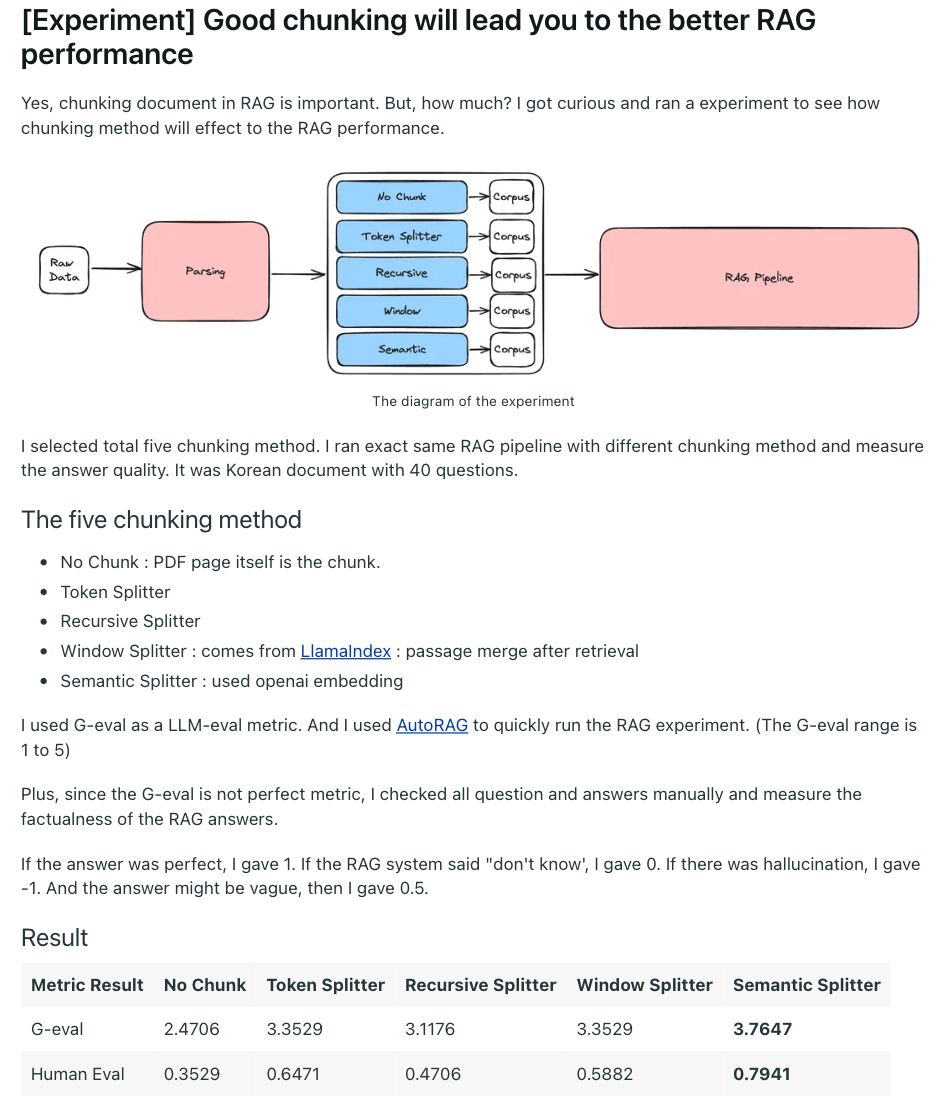
Engineers have run dozens of similar experiments, all testing the best chunking methods for various document types and model preferences.
This means any manual “optimization” you do today can be rendered irrelevant by a model update tomorrow.
3. Manual chunk optimization is a dead end
Ultimately, manual “chunk optimization” is impossible in practice.
Even if you try to write perfect chunks, you have no control over where a model will cut your content.
Chunking is based on tokens, not paragraphs or sentences, and each model decides its own split points dynamically. That means your carefully written intro sentence for a chunk might:
- Land in the middle of a chunk instead of at the start
- Get split in half across two chunks
- Be ignored entirely if the model’s retrieval slices around it
On top of that, Google has already shown what happens to sites that force formatting to game visibility. For example, FAQ‑style content farms once flooded search results with neatly packaged answers to win snippets and visibility.
After recent updates, Google demoted or penalized these sites when recognizing the pattern as manipulative, AI-generated slop, offering low value to readers.
Trying to pre‑structure content for hypothetical AI chunking is the same trap.
You can’t predict how LLMs will tokenize your page today, and any attempt to force it could backfire or become obsolete after the next model update.
Optimizing for AI search doesn’t require chasing “chunk optimization.” Instead, the goal is to create atomic content—self‑contained sections within larger documents that act as indivisible units of knowledge.

Sound familiar? It’s how well-optimized SEO content has been written for many years.
Each atomic unit should be able to stand on its own, delivering a complete answer even if extracted and surfaced by Google, ChatGPT, Perplexity, or other AI search platforms.
Designing your content this way makes it both AI‑ready and user‑friendly, without resorting to gimmicks.
Here’s a simple workflow you can implement.
Step 1: Start with keyword & topic research
Knowing how to structure a page for visibility in search starts with keyword and topic research.
Using Ahrefs’ Keywords Explorer, you can find what questions or topics deserve their own sections within a page you’re writing.
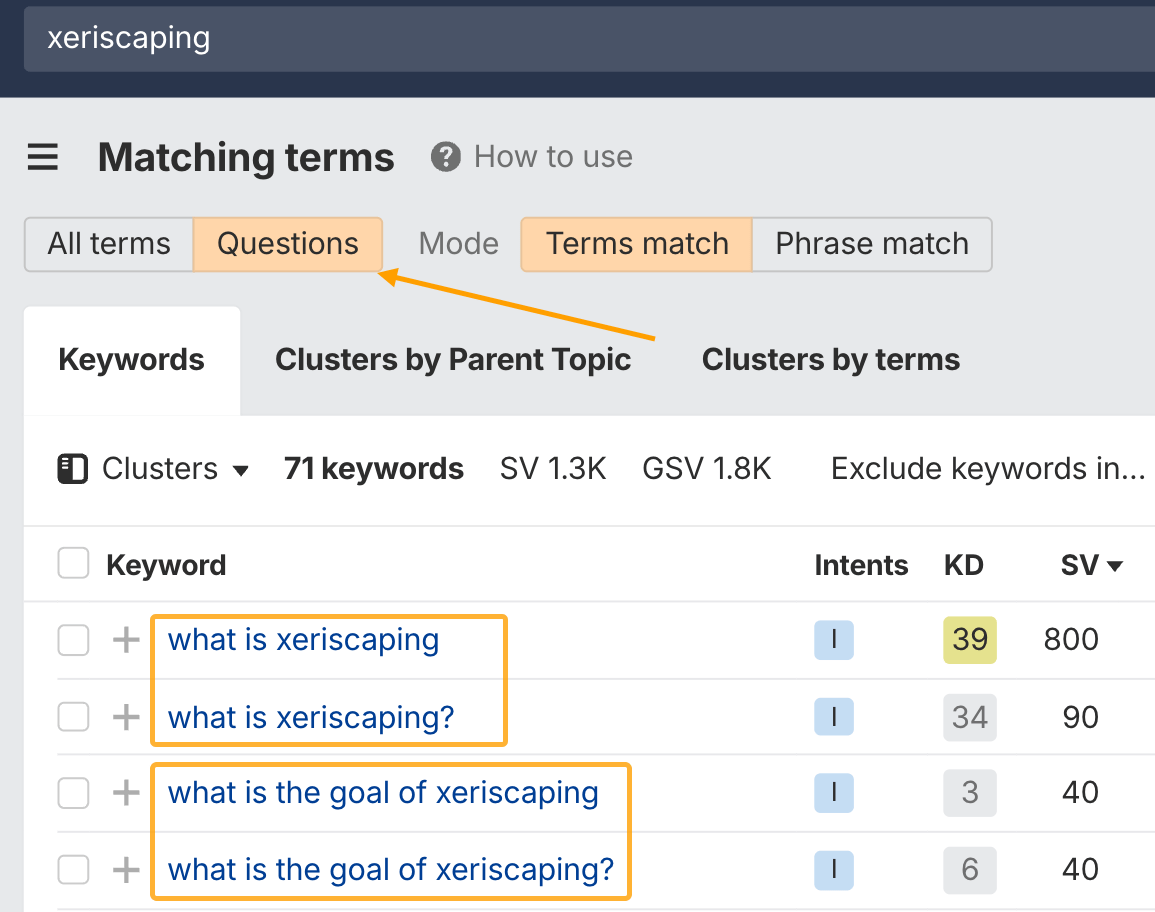
For example, on the topic of xeriscaping (a type of gardening), you can answer questions like:
- What is xeriscaping?
- What’s the goal of xeriscaping?
- How much does xeriscaping cost?
- What plants are good for xeriscaping?
Each topic or cluster represents a potential content atom to add to your website. However, not every atom needs its own page to be answered well.
Some questions and topics make better sense to be answered in an existing article instead.
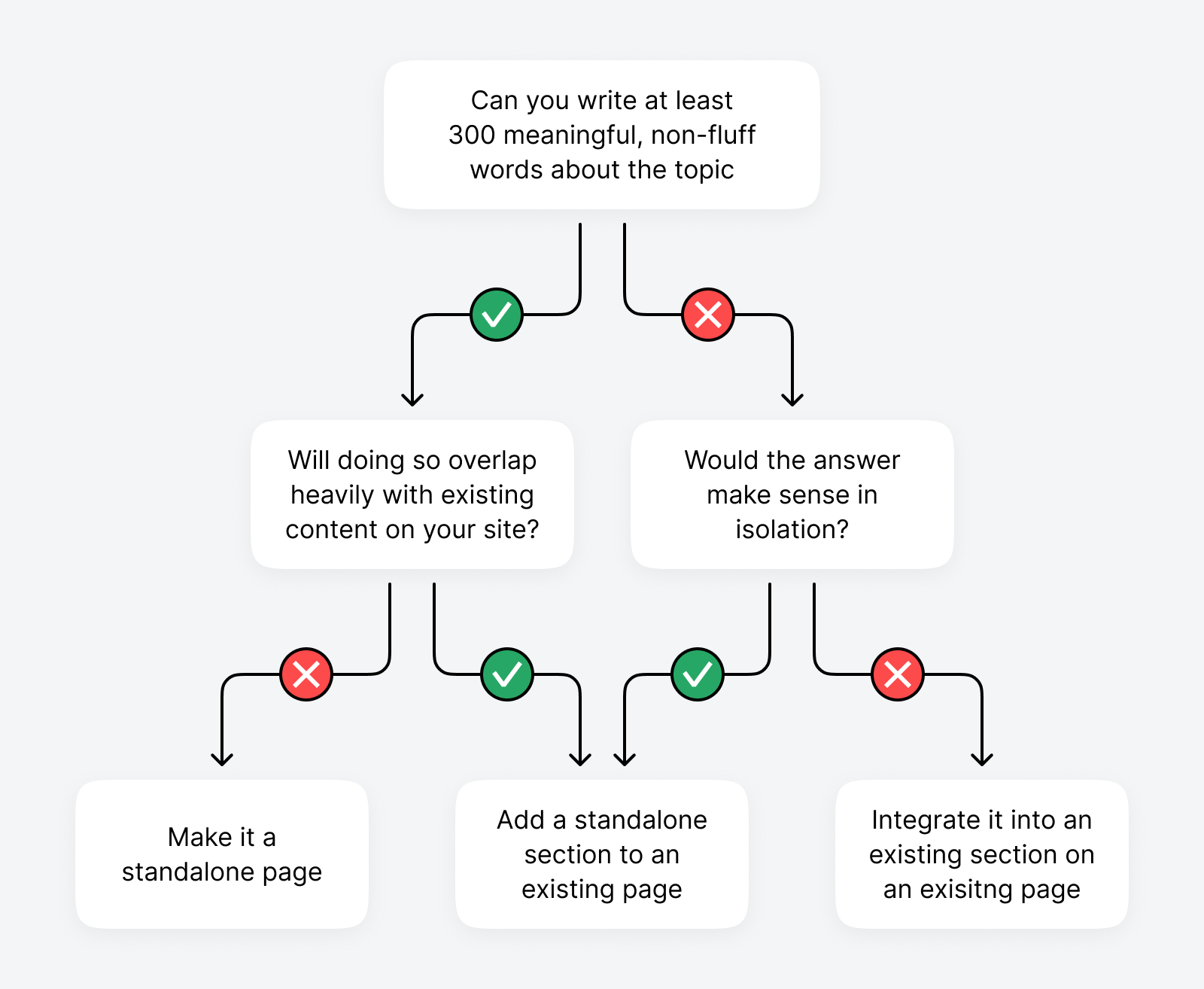
Whether you target keywords as a page or section within a page comes down to what your website’s core topic is about. For example, if you have a specialist site about xeriscaping, it might make sense to target each question in a separate post where you can go deep into the details.
If you have a general gardening site, perhaps you could add each question as an FAQ to an existing post about xeriscaping instead.
This step ensures every piece of content you create starts with search intent alignment and is structured to function as a standalone unit where possible.
Step 2: Apply BLUF (Bottom Line Up Front)
“Bottom Line Up Front” is a framework for communicating the most important information first, then proceeding with an explanation, example, or supporting details.
To implement it in your writing, start each article (and also each section within an article) with a direct answer or clear statement that fully addresses the core topic.
BLUF works because humans scan first, read later.
Decades of Nielsen Norman Group research show readers follow an F‑pattern when reading online: heavy focus on the beginning of sections, a sharp drop‑off in the middle, and some renewed attention at the end.
![]()
![]()
Large language models process text in a surprisingly similar way.
They prioritize the beginning of a document or chunk and show a U‑shaped attention bias by:
- Weighing the early tokens most heavily
- Losing focus in the middle
- Regaining some emphasis toward the end of a sequence
For more insights into how this works, I recommend Dan Petrovic’s in-depth article Human Friendly Content is AI Friendly Content.
By putting the answer first, your content is instantly understandable, retrievable, and citation‑ready, whether for a human skimmer or an AI model embedding your page.
Step 3: Audit for self‑containment
Before publishing, it’s worth scanning your page and asking:
- Is related information grouped logically in your content structure?
- Is each section clear and easy to follow without extra explanation?
- Would a human dropping into this section from a jump link immediately get value?
- Does the section fully answer the intent of its keyword or topic cluster without relying on the rest of the page?
To make this audit faster and more objective, tools like Ahrefs’ AI Content Helper can help visualize your topic coverage.
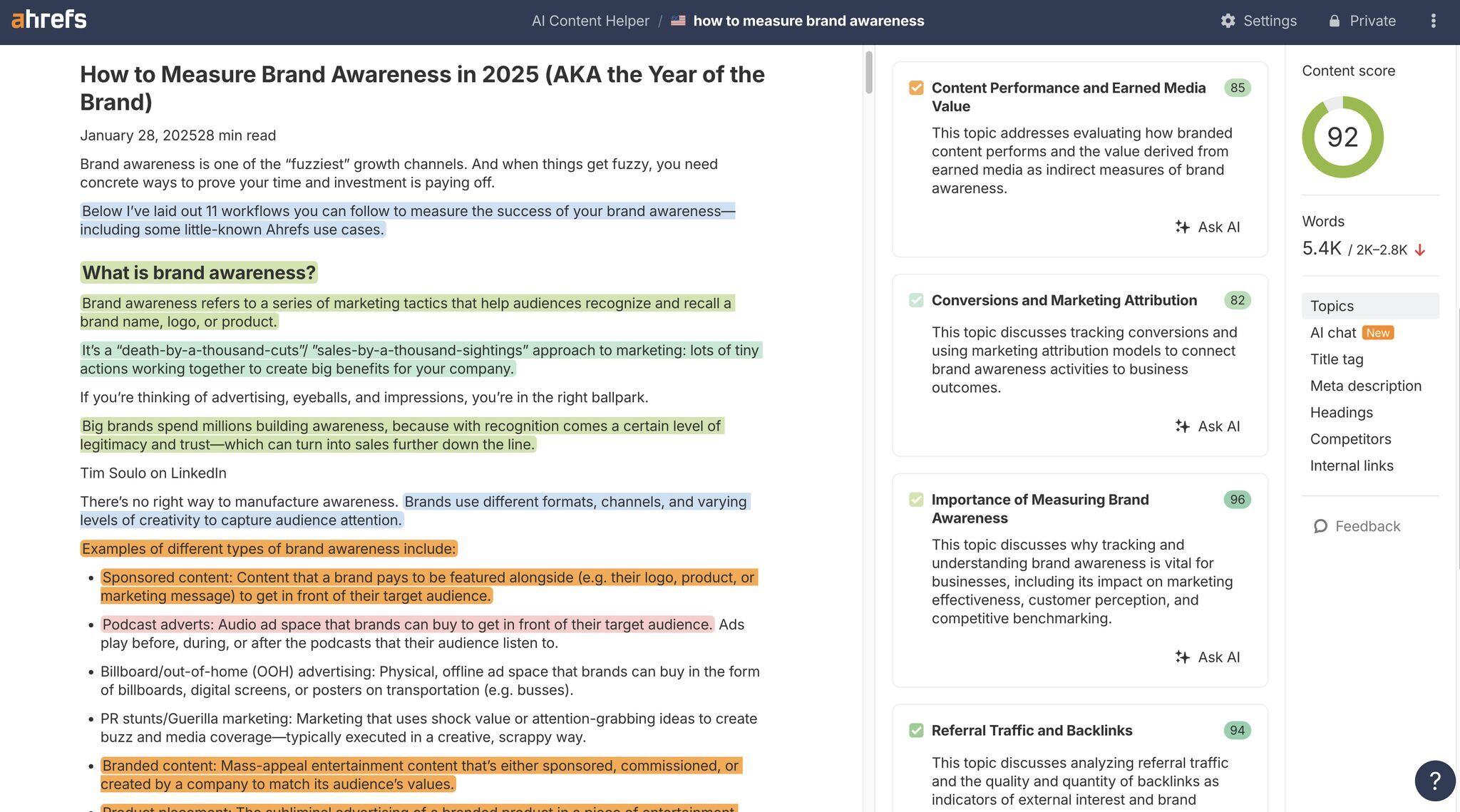
Its topic‑coloring feature highlights distinct topics across your page, making it easy to spot:
- Overlapping or fragmented sections that should be merged
- Sections that don’t cover a topic completely
- Areas that may require re‑labeling or stronger context
If each section is self‑contained and your topic colors show clear, cohesive blocks, you’ve created atomic content that is naturally optimized for human attention and AI retrieval.
Closing takeaway
Chasing “chunk optimization” is a distraction.
AI systems will always split, embed, and retrieve your content in ways you can’t predict or control, and those methods will evolve as engineers optimize for speed and cost.
The winning approach isn’t trying to game the pipeline. It’s creating clear, self‑contained sections that deliver complete answers, so your content is valuable whether it’s read top‑to‑bottom by a human or pulled into an isolated AI summary.



