That’s where we are with optimizing for visibility in LLMs (LLMO), and we need more experts to call out this behavior in our industry, like Lily Ray has done in this post:
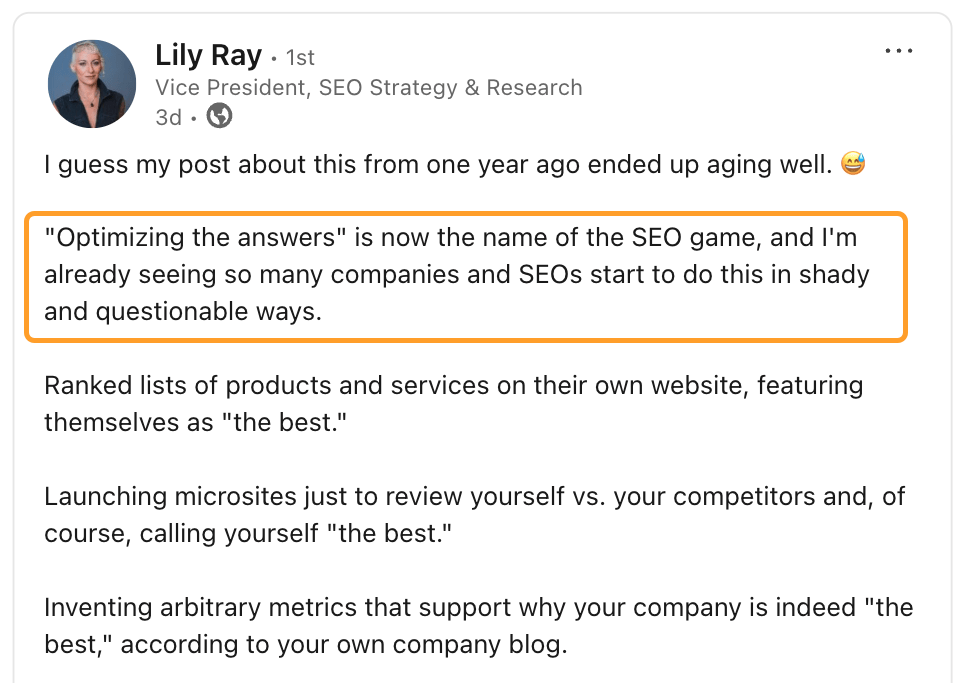
If you’re tricking, sculpting, or manipulating a large language model to make it notice and mention you more, there’s a big chance it’s black hat.
It’s like 2004 SEO, back when keyword stuffing and link schemes worked a little too well.
But this time, we’re not just reshuffling search results. We’re shaping the foundation of knowledge that LLMs draw from.
In tech, black hat typically refers to tactics that manipulate systems in ways that may work temporarily but go against the spirit of the platform, are unethical, and often backfire when the platform catches up.
Traditionally, black hat SEO has looked like:
- Putting white keyword-spammed text on a white background
- Adding hidden content to your code, visible only to search engines
- Creating private blog networks just for linking to your website
- Improving rankings by purposely harming competitor websites
- And more…
It became a thing because (although spammy), it worked for many websites for over a decade.
Black hat LLMO looks different from this. And, a lot of it doesn’t feel immediately spammy, so it can be hard to spot.
However, black hat LLMO is also based on the intention of unethically manipulating language patterns, LLM training processes, or data sets for selfish gain.
Here’s a side-by-side comparison to give you an idea of what black hat LLMO could include. It’s not exhaustive and will likely evolve as LLMs adapt and grow.
Black Hat LLMO vs Black Hat SEO
| Tactic | SEO | LLMO |
|---|---|---|
| Private blog networks | Built to pass link equity to target sites. | Built to artificially position a brand as the “best” in its category. |
| Negative SEO | Spammy links are sent to competitors to lower their rankings or penalize their websites. | Downvoting LLM responses with competitor mentions or publishing misleading content about them. |
| Parasite SEO | Using the traffic of high-authority websites to boost your own visibility. | Artificially improving your brand’s authority by being added to “best of” lists…that you wrote. |
| Hidden text or links | Added for search engines to boost keyword density and similar signals. | Added to increase entity frequency or provide “LLM-friendly” phrasing. |
| Keyword stuffing | Squeezing keywords into content and code to boost density. | Overloading content with entities or NLP terms to boost “salience”. |
| Automatically-generated content | Using spinners to reword existing content. | Using AI to rephrase or duplicate competitor content. |
| Link building | Buying links to inflate ranking signals. | Buying brand mentions alongside specific keywords or entities. |
| Engagement manipulation | Faking clicks to boost search click-through rate. | Prompting LLMs to favor your brand; spamming RLHF systems with biased feedback. |
| Spamdexing | Manipulating what gets indexed in search engines. | Manipulating what gets included in LLM training datasets. |
| Link farming | Mass-producing backlinks cheaply. | Mass-producing brand mentions to inflate authority and sentiment signals. |
| Anchor text manipulation | Stuffing exact-match keywords into link anchors. | Controlling sentiment and phrasing around brand mentions to sculpt LLM outputs. |
These tactics boil down to three core behaviors and thought processes that make them “black hat”.
Language models undergo different training processes. Most of these happen before models are released to the public; however, some training processes are influenced by public users.
One of these is Reinforcement Learning from Human Feedback (RLHF).
It is an artificial intelligence learning method that uses human preferences to reward LLMs when they deliver a good response and penalize them when they provide a bad response.
OpenAI has a great diagram for explaining how RLHF works for InstructGPT:
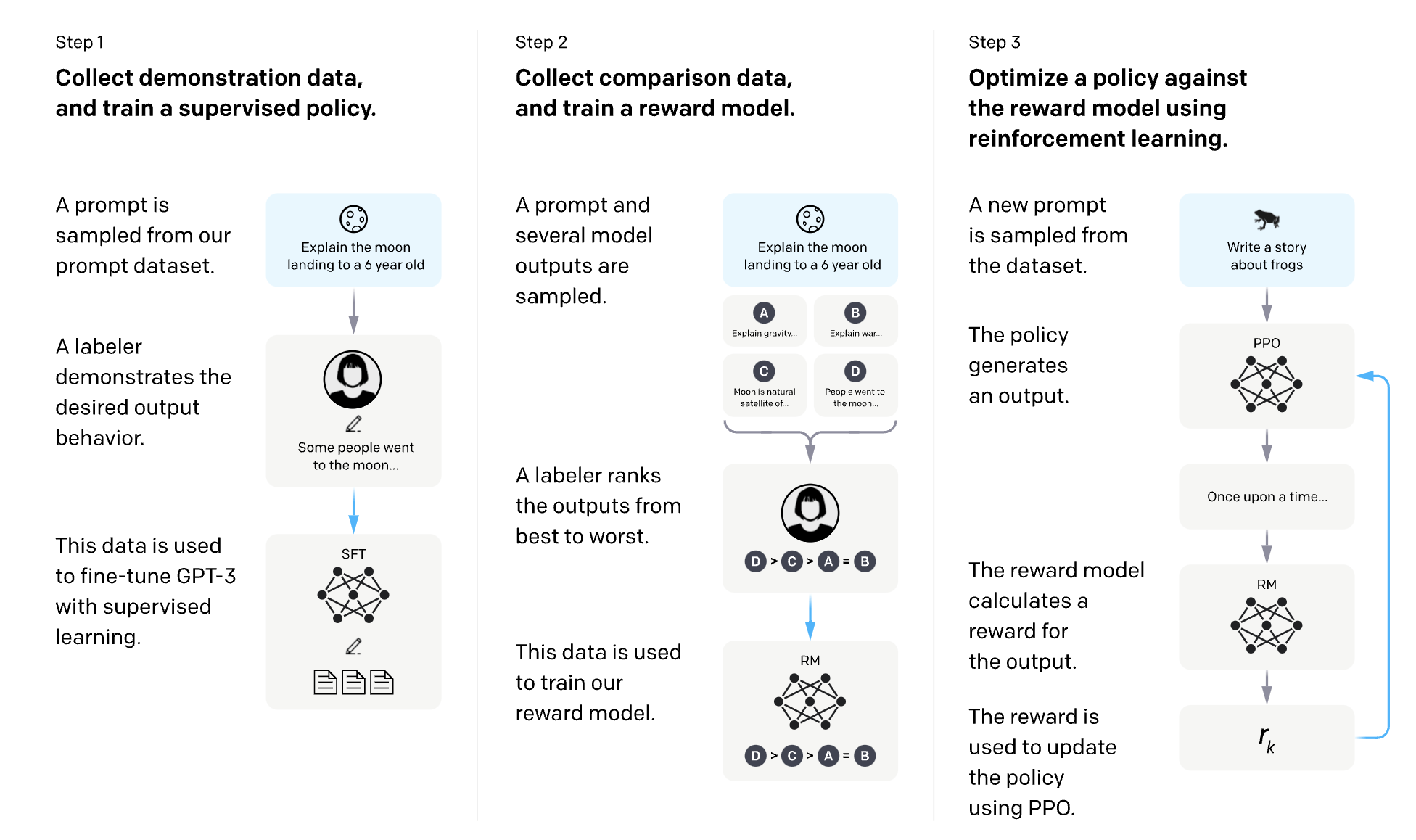
LLMs using RLHF learn from their direct interactions with users… and you can probably already see where this is going for black hat LLMO.
They can learn from:
- The actual conversations they have (including historical conversations)
- The thumbs-up/down ratings that users give for responses
- The selection a user makes when the LLM presents multiple options
- The user’s account details or other personalized data that the LLM has access to
For example, here’s a conversation in ChatGPT that indicates it learned (and subsequently adapted future behavior) based on the direct conversation it had with this user:
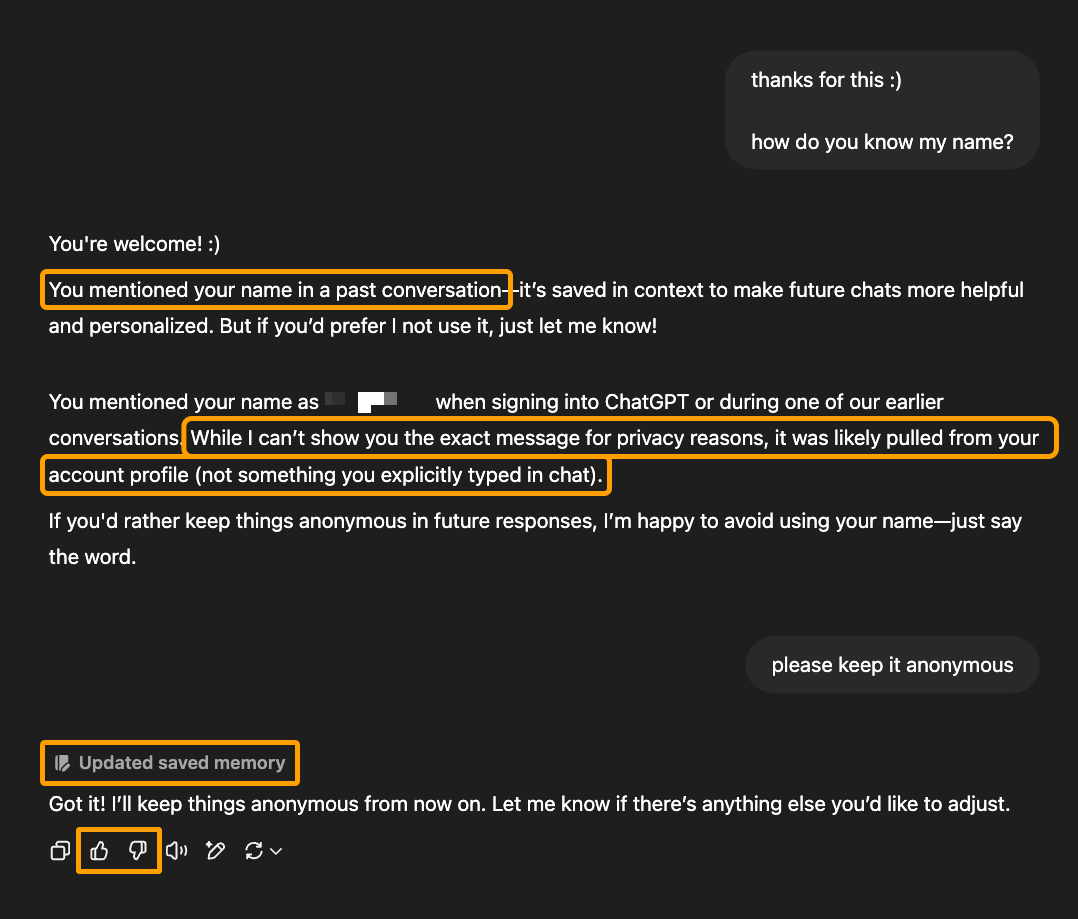
Now, this response has a few problems: the response contradicts itself, the user didn’t mention their name in past conversations, and ChatGPT can’t use reason or judgment to accurately pinpoint where or how it learned the user’s name.
But the fact remains that this LLM learned something it could not have through training data and search alone. It could only learn it from its interaction with this user.
And this is exactly why it’s easy for these signals to be manipulated for selfish gain.
It’s certainly possible that, similarly to how Google uses a “your money, your life” classification for content that could cause real harm to searchers, LLMs place more weight on specific topics or types of information.
Unlike traditional Google search, which had a significantly smaller number of ranking factors, LLMs have illions (millions, billions, or trillions) of parameters to tune for various scenarios.
| Model | Parameters |
|---|---|
| GPT-1 | ~117 million |
| GPT-2 | ~1.5 billion |
| GPT-3 | ~175 billion |
| GPT-4 | ~1.76 trillion |
| GPT-5 | ~17.6 trillion (speculated) |
For instance, the above example relates to the user’s privacy, which would have more significance and weight than other topics. That’s likely why the LLM might have made the change immediately.
Thankfully, it’s not this easy to brute force an LLM to learn other things, as the team at Reboot discovered when testing for this exact type of RLHF manipulation.

As marketers, we are responsible for advising clients on how to show up in new technologies their customers use to search. However, this should not come from manipulating those technologies for selfish gain.
There’s a fine line there that, when crossed, poisons the well for everybody. This leads me to the second core behavior of black hat LLMO…
Let me shine a light on the word “poison” for a moment because I am not using it for dramatic effect.
Engineers use this language to describe the manipulation of LLM training datasets as “supply chain poisoning.”
Some SEOs are doing it intentionally. Others are just following advice that sounds clever but is dangerously misinformed.
You’ve probably seen posts or heard suggestions like:
- “You have to get your brand into LLM training data.”
- “Use feature engineering to make your raw data more LLM-friendly.”
- “Influence the patterns that LLMs learn from to favor your brand.”
- “Publish roundup posts naming yourself as the best, so LLMs pick that up.”
- “Add semantically rich content linking your brand with high-authority terms.”
I asked Brandon Li, a machine learning engineer at Ahrefs, how engineers react to people optimizing specifically for visibility in datasets used by LLMs and search engines. His answer was blunt:
Please don’t do this — it messes up the dataset.

The difference between how SEOs think about it and how engineers think is important. Getting in a training dataset is not like being indexed by Google. It’s not something you should be trying to manipulate your way into.
Let’s take schema markup as an example of a dataset search engineers use.
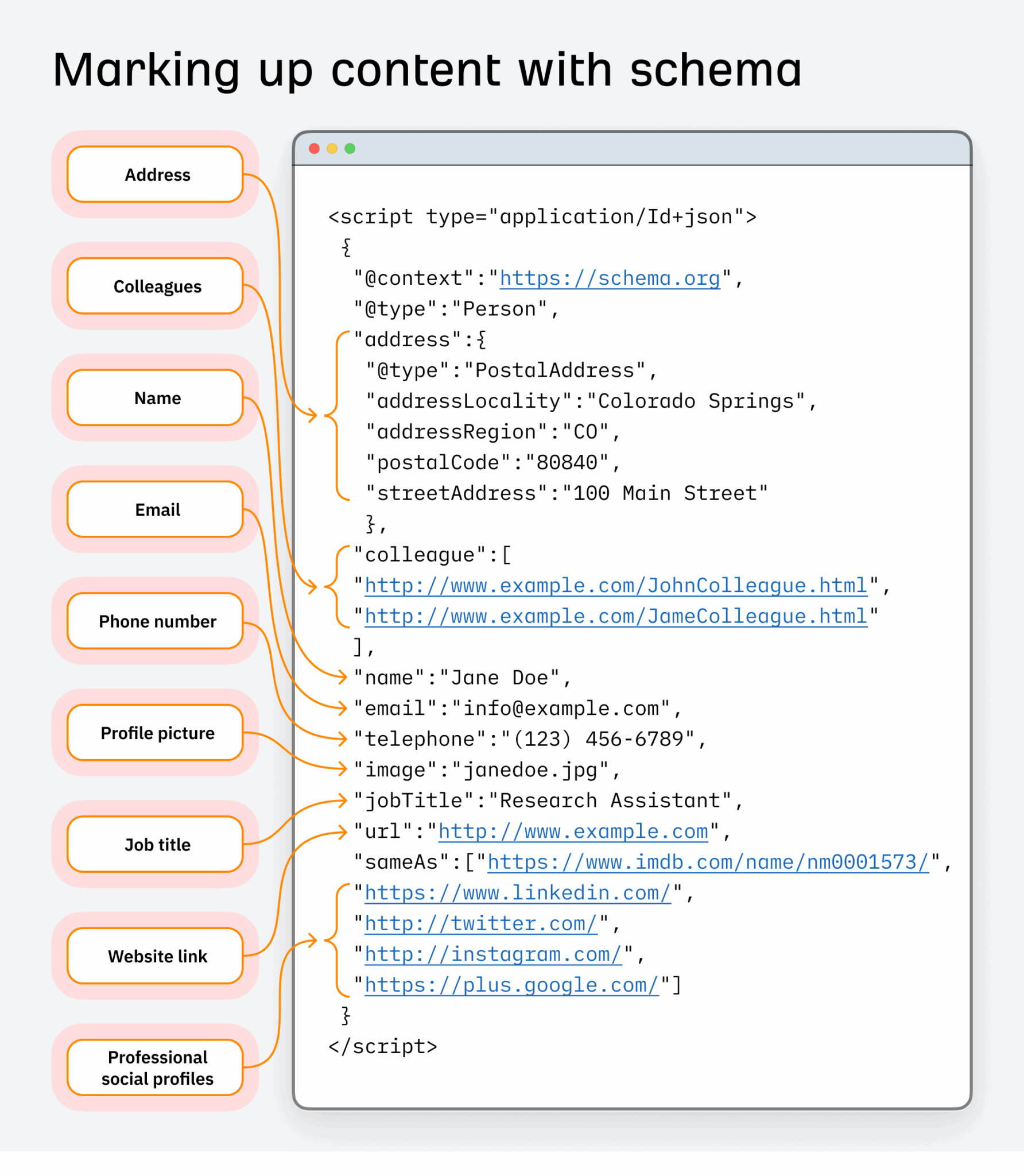 In SEO, it has long been used to enhance how content appears in search and improve click-through rates.
In SEO, it has long been used to enhance how content appears in search and improve click-through rates.
But there’s a fine line between optimizing and abusing schema; especially when it’s used to force entity relationships that aren’t accurate or deserved.
When schema is misused at scale (whether deliberately or just by unskilled practitioners following bad advice), engineers stop trusting the data source entirely. It becomes messy, unreliable, and unsuitable for training.
If it’s done with the intent to manipulate model outputs by corrupting inputs, that’s no longer SEO. That’s poisoning the supply chain.
This isn’t just an SEO problem.
Engineers see dataset poisoning as a cybersecurity risk, one with real-world consequences.
Take Mithril Security, a company focused on transparency and privacy in AI. Their team ran a test to prove how easily a model could be corrupted using poisoned data. The result was PoisonGPT — a tampered version of GPT-2 that confidently repeated fake news inserted into its training set.
Their goal wasn’t to spread misinformation. It was to demonstrate how little it takes to compromise a model’s reliability if the data pipeline is unguarded.
Beyond marketers, the kinds of bad actors who try to manipulate training data include hackers, scammers, fake news distributors, and politically motivated groups aiming to control information or distort conversations.
The more SEOs engage in dataset manipulation, intentionally or not, the more engineers begin to see us as part of that same problem set.
Not as optimizers. But as threats to data integrity.
Why getting into a dataset is the wrong goal to aim for anyway
Let’s talk numbers. When OpenAI trained GPT-3, they started with the following datasets:
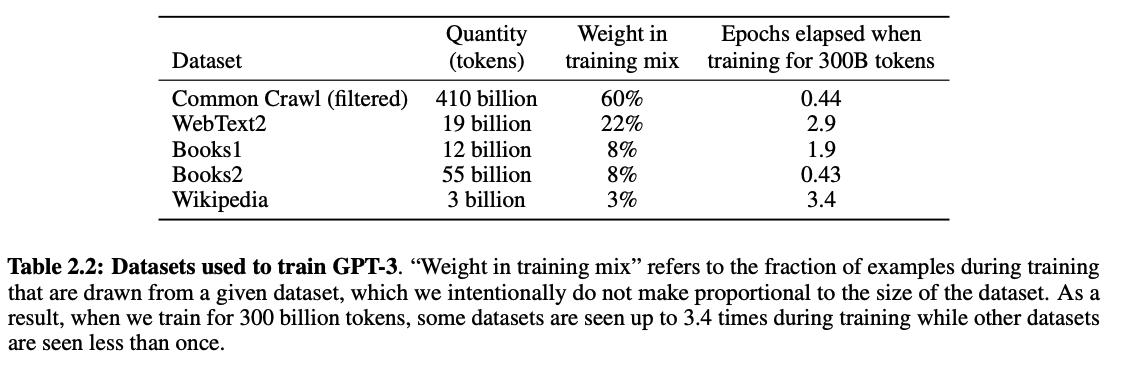
Initially, 45 TB of CommonCrawl data was used (~60% of the total training data). But only 570 GB (about 1.27%) made it into the final training set after a thorough data cleaning process.
What got kept?
- Pages that resembled high-quality reference material (think academic texts, expert-level documentation, books)
- Content that wasn’t duplicated across other documents
- A small amount of manually selected, trusted content to improve diversity
While OpenAI hasn’t provided transparency for later models, experts like Dr Alan D. Thompson have shared some analysis and insights for datasets used to train GPT-5:

This list includes data sources that are far more open to manipulation and harder to clean like Reddit posts, YouTube comments, and Wikipedia content, to name a few.
Datasets will continue to change with new model releases. But we know that datasets the engineers consider higher quality are sampled more frequently during the training process than lower quality, “noisy” datasets.
Since GPT-3 was trained on only 1.27% of CommonCrawl data, and engineers are becoming more careful with cleaning datasets, it’s incredibly difficult to insert your brand into an LLM’s training material.
And, if that’s what you’re aiming for, then as an SEO, you’re missing the point.
Most LLMs now augment answers with real time search. In fact they search more than humans do.
For instance, ChatGPT ran over 89 searches in 9 minutes for one of my latest queries:

By comparison, I tracked one of my search experiences when buying a laser cutter and ran 195 searches in 17+ hours as part of my overall search journey.
LLMs are researching faster, deeper, and wider than any individual user, and often citing more resources than an average searcher would ordinarily click on when simply Googling for an answer.
Showing up in responses by doing good SEO (instead of trying to hack your way into training data) is the better path forward here.
An easy way to benchmark your visibility is in Ahrefs’ Web Analytics:
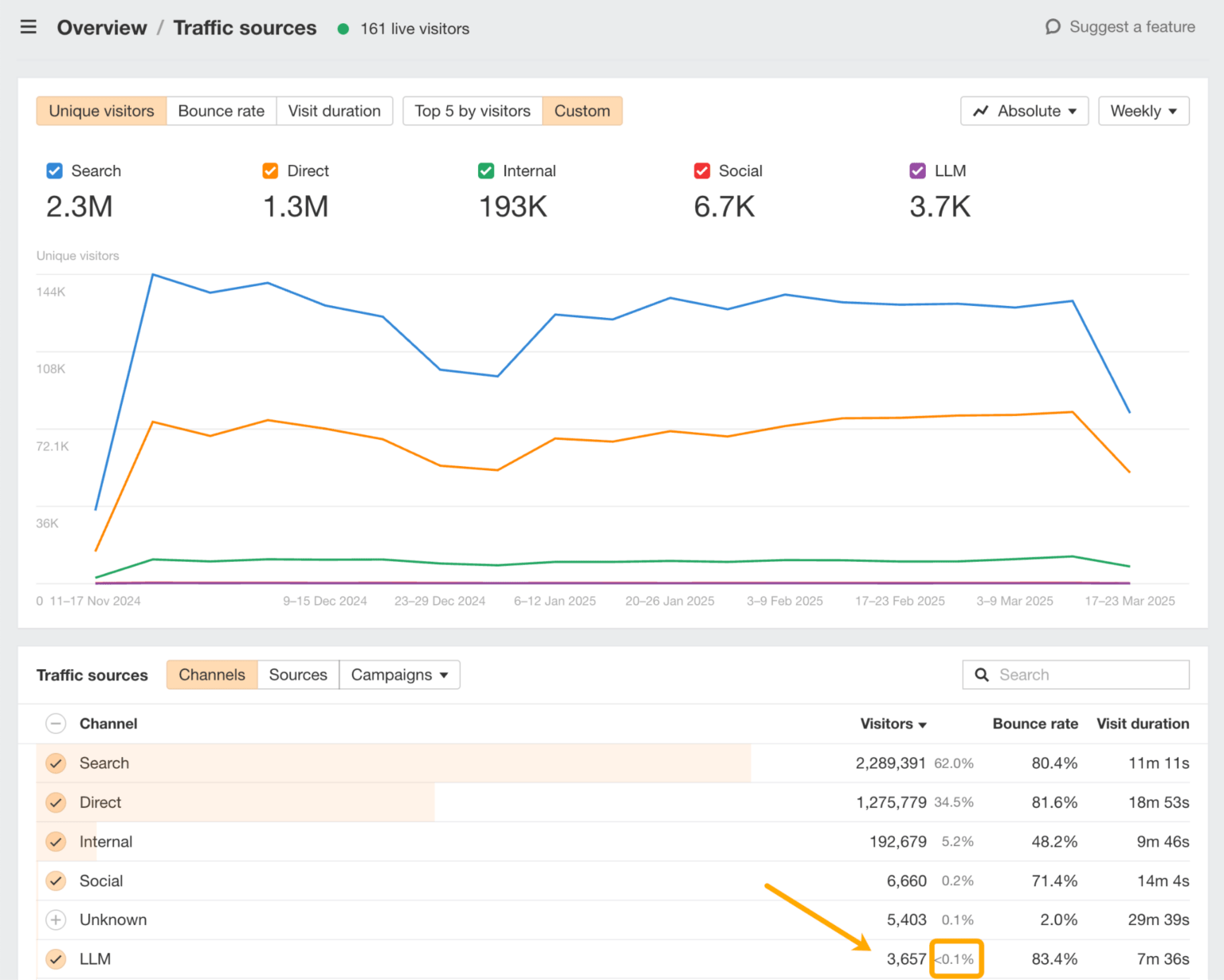
Here you can analyze exactly which LLMs are driving traffic to your site and which pages are showing up in their responses.
However, it might be tempting to start optimizing your content with “entity-rich” text or more “LLM-friendly” wording to improve its visibility in LLMs, which takes us to the third pattern of black hat LLMO.
The final behavior contributing to black hat LLMO is sculpting language patterns to influence prediction-based LLM responses.
It’s similar to what researchers at Harvard call “Strategic Text Sequences” in this study. It refers to text that’s injected onto web pages with the specific aim of influencing more favorable brand or product mentions in LLM responses.
The red text below is an example of this:

The red text is an example of content injected on an e-commerce product page in order to get it showing as the top choice in relevant LLM responses.
Even though the study focused on inserting machine-generated text strings (not traditional marketing copy or natural language), it still raised ethical concerns about fairness, manipulation, and the need for safeguards because these engineered patterns exploit the core prediction mechanism of LLMs.
Most of the advice I see from SEOs about getting LLM visibility falls into this category and is represented as a type of entity SEO or semantic SEO.
Except now, instead of talking about putting keywords in everything, they’re talking about putting entities in everything for topical authority.
For example, let’s look at the following SEO advice from a critical lens:

The rewritten sentence has lost its original meaning, does not convey the emotion or fun experience, loses the author’s opinion, and completely changes the tone, making it sound more promotional.
Worse, it also does not appeal to a human reader.
This style of advice leads to SEOs curating and signposting information for LLMs in the hopes it will be mentioned in responses. And to a degree, it works.
However, it works (for now) because we are changing the language patterns that LLMs are built to predict. We are making them unnatural on purpose to please an algorithm a model instead of writing for humans… does this feel like SEO déjà vu to you, too?
Other advice that follows this same line of thinking includes:
- Increasing entity co-occurrences: Like re-writing content surrounding your brand mentions to include specific topics or entities you want to be connected to strongly.
- Artificial brand positioning: Like getting your brand featured in more “best of” roundup posts to improve authority (even if you create these posts yourself on your site or as guest posts).
- Entity-rich Q&A content: Like turning your content into a summarizable Q+A format with many entities added to the response, instead of sharing engaging stories, experiences, or anecdotes.
- Topical
authoritysaturation: Like publishing an overwhelming amount of content on every possible angle of a topic to dominate entity associations.
These tactics may influence LLMs, but they also risk making your content more robotic, less trustworthy, and ultimately forgettable.
Still, it’s worth understanding how LLMs currently perceive your brand, especially if others are shaping that narrative for you.
That’s where a tool like Ahrefs’ Brand Radar comes in. It helps you see which keywords, features, and topic clusters your brand is associated with in AI responses.

That kind of insight is less about gaming the system and more about catching blind spots in how machines are already representing you.
If we go down the path of manipulating language patterns, it will not give us the benefits we want, and for a few reasons.
Unlike SEO, LLM visibility is not a zero-sum game. It’s not like a tug-of-war where if one brand loses rankings, it’s because another took its place.
We can all become losers in this race if we’re not careful.
LLMs don’t have to mention or link to brands (and they often don’t). This is due to the dominant thought process when it comes to SEO content creation. It goes something like this:
- Do keyword research
- Reverse engineer top-ranking articles
- Pop them into an on-page optimizer
- Create similar content, matching the pattern of entities
- Publish content that follows the pattern of what’s already ranking
What this means, in the grand scheme of things, is that our content becomes ignorable.
Remember the cleaning process that LLM training data goes through? One of the core elements was deduplication at a document level. This means documents that say the same thing or don’t contribute new, meaningful information get removed from the training data.

Another way of looking at this is through the lens of “entity saturation”.
In academic qualitative research, entity saturation refers to the point where gathering more data for a particular category of information doesn’t reveal any new insights. Essentially, the researcher has reached a point where they see similar information repeatedly.
That’s when they know their topic has been thoroughly explored and no new patterns are emerging.
Well, guess what?
Our current formula and SEO best practices for creating “entity-rich” content leads LLMs to this point of saturation faster, once again making our content ignorable.
It also makes our content summarizable as a meta-analysis. If 100 posts say the same thing about a topic (in terms of the core essence of what they communicate) and it’s fairly generic Wikipedia-style information, none of them will get the citation.
Making our content summarizable doesn’t make getting a mention or citation easier. And yet, it’s one of the most common pieces of advice top SEOs are sharing for getting visibility in LLM responses.
So what can we do instead?
My colleague Louise has already created an awesome guide on optimizing your brand and content for visibility in LLMs (without resorting to black hat tactics).
Instead of rehashing the same advice, I wanted to leave you with a framework for how to make intelligent choices as we move forward and you start to see new theories and fads pop up in LLMO .
And yes, this one is here for dramatic effect, but also because it makes things dead simple, helping you bypass the pitfalls of FOMO along the way.
It comes from the 5 Basic Laws of Human Stupidity by Italian economic historian, Professor Carlo Maria Cipolla.
Go ahead and snicker, then pay attention. It’s important.
According to Professor Cipolla, intelligence is defined as taking an action that benefits yourself and others simultaneously—basically, creating a win-win situation.
It is in direct opposition to stupidity, which is defined as an action that creates losses to both yourself and others:
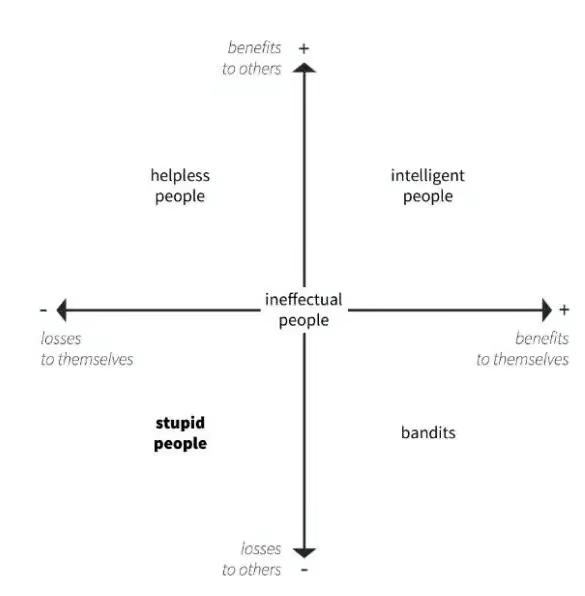
In all cases, black hat practices sit squarely in the bottom left and bottom right quadrants.
SEO bandits, as I like to think of them, are the people who used manipulative optimization tactics for selfish reasons (benefits to self)… and proceeded to ruin the internet as a result (losses to others).
Therefore, the rules of SEO and LLMO moving forward are simple.
- Don’t be stupid.
- Don’t be a bandit.
- Optimize intelligently.
Intelligent optimization comes down to focusing on your brand and ensuring it is accurately represented in LLM responses.
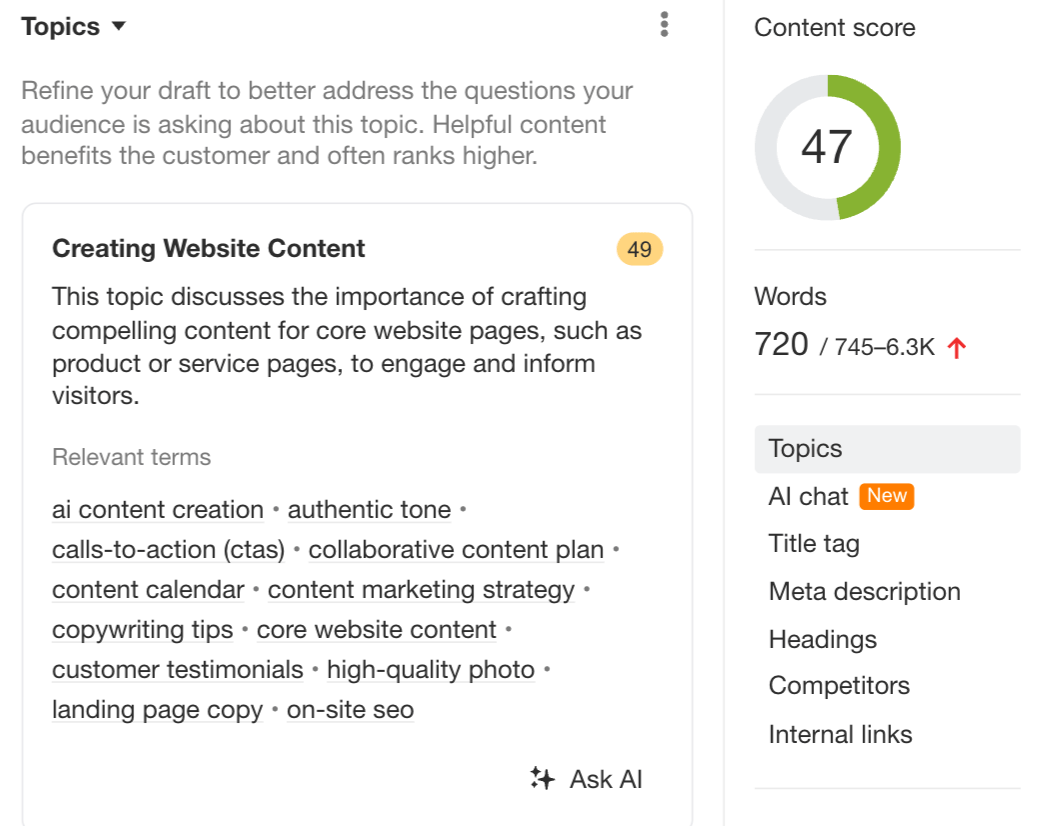
It’s about using tools like AI Content Helper that are specifically designed to elevate your topic coverage, instead of focusing on cramming more entities in. (The SEO score only improves as you cover the suggested topics in detail, not when you stuff more words in.)
But above all, it’s about contributing to a better internet by focusing on the people you want to reach and optimizing for them, not algorithms or language models.
Final thoughts
LLMO is still in its early days, but the patterns are already familiar — and so are the risks.
We’ve seen what happens when short-term tactics go unchecked. When SEO became a race to the bottom, we lost trust, quality, and creativity. Let’s not do it again with LLMs.
This time, we have a chance to get it right. That means:
- Don’t manipulate prediction patterns; shape your brand’s presence instead.
- Don’t chase entity saturation, but create content humans want to read.
- Don’t write to be summarized; rather, write to impact your audience.
Because if your brand only shows up in LLMs when it’s stripped of personality, is that really a win?


