
根据谷歌网站管理员趋势分析师 Gary Illyes 的说法,互联网上约有60%的内容是重复的。
Google’s crawling process is highly focused on removing duplication because 60% of the internet is duplicate 🤯 @methode #seodaydk pic.twitter.com/OJ9OkP74DU
— Lily Ray 😏 (@lilyraynyc) March 30, 2022
规范化经常容易被误解。我不认为大多数的重复是可以而为,很多是技术问题导致的。我们稍后会更多地讨论这个。先来谈一谈规范化的过程是如何进行的:
有很多不同的信号会进入规范化过程。这些信号包括
- 重复
- 规范化链接元素
- 网站地图中的 URL
- 内部链接
- 外部链接
- 跳转
- Hrelang
谷歌查看所有不同的信号,并对它们进行权衡,以确定什么是规范版本。也就是索引的页面的版本,也是它通常显示给用户的版本。
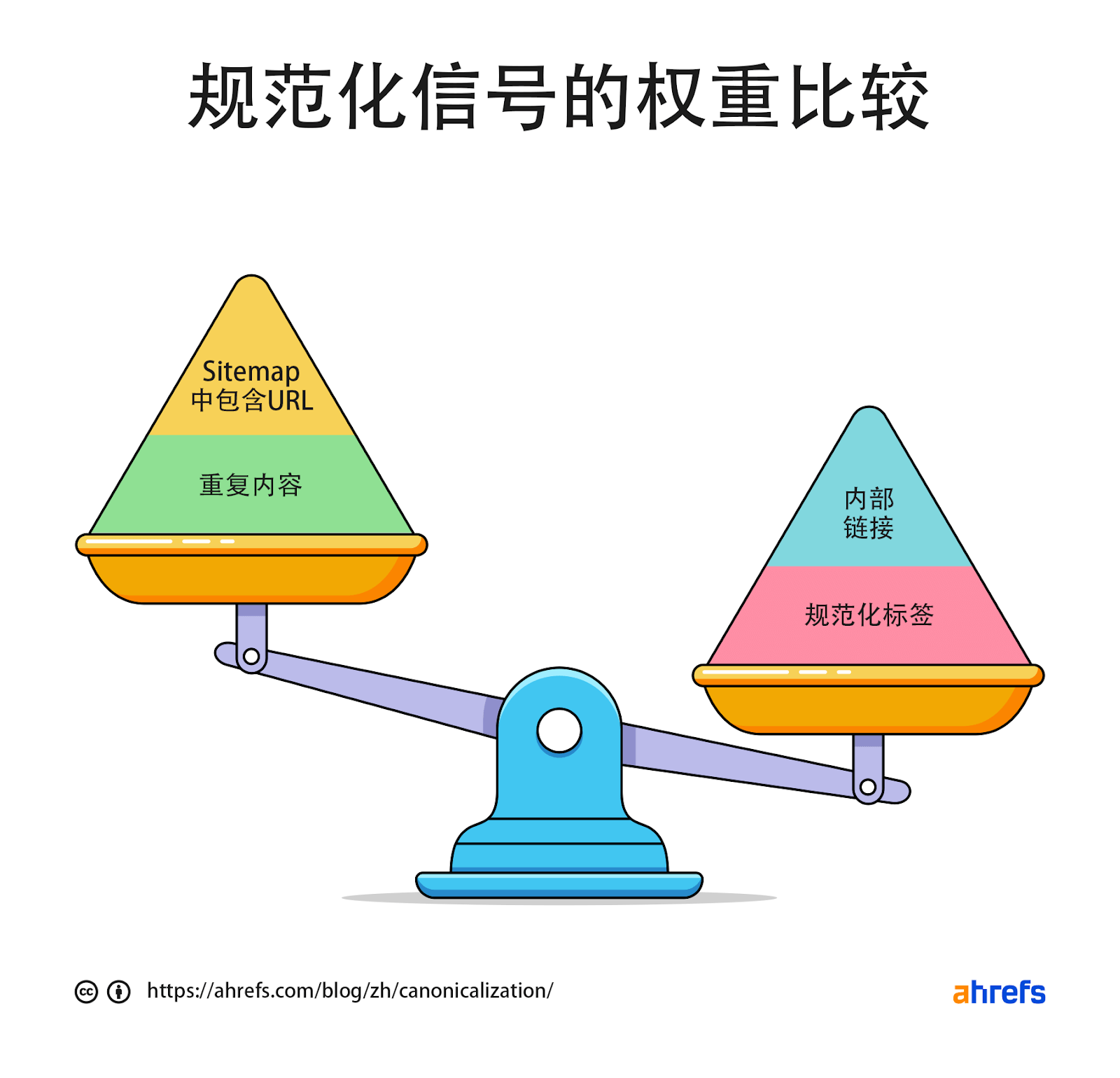
当谷歌根据网站内部确定规范页面时,一个潜在的信号强度比较。
重复内容
对于重复的内容,谷歌将挑选一个规范的版本进行索引。所有符合条件的页面形成一个页面集群,进入该集群中的页面的信号将合并到所选择的规范版本。该规范化指定的页面可能随着时间的推移而改变。
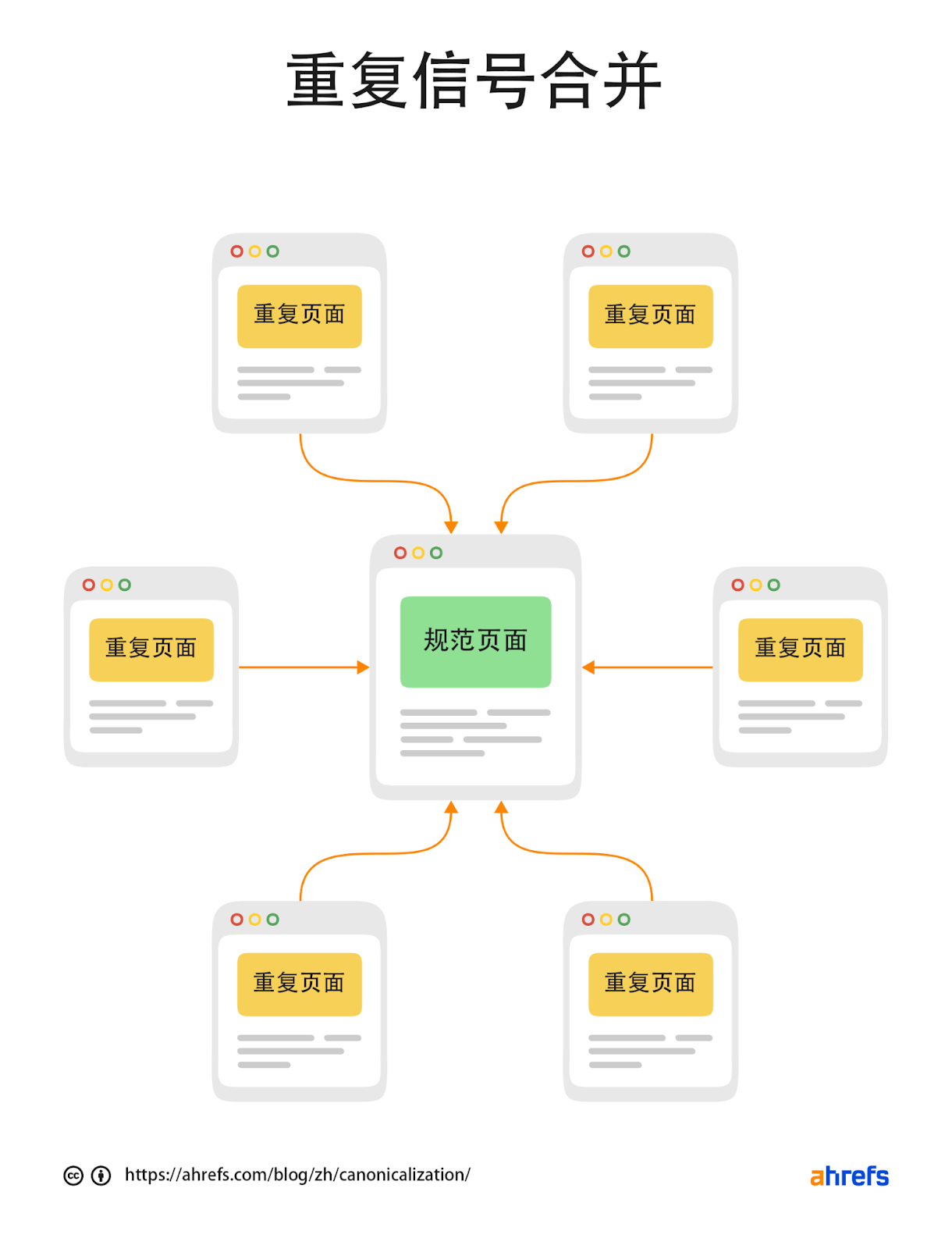
一些 SEO 认为存在重复内容的惩罚,但这并不正确。一般来说,你将会有另一个版本页面被索引。但它可能不是你希望被索引的版本。甚至有时候,与同一页面的任何其他版本的排名一样好。
下面是一些可能导致重复页面的例子,有时还可能导致规范化问题:
- HTTP 和 HTTPS – 例子: http://www.example.com 和 https://www.example.com.
- 非 www 和www – 例子: http://example.com 和 http://www.example.com.
- 有尾部斜线和无尾部斜线的 URL – 例子: https://example.com/page/ 和 https://example.com/page.
- 有大写字母和无大写字母的 URL – 例子: https://example.com/page/ 和 https://example.com/Page/.
- 页面的默认版本,如 index 页 – 例子: https://www.example.com/, https://www.example.com/index.htm, https://www.example.com/index.html, https://www.example.com/index.php, https://www.example.com/default.htm, 等.
- 网页的替代版本 – 这个可能会包含移动版本的页面 (例如 example.com 和 m.example.com), AMP 版本 (例如 example.com/page 和 amp.example.com/page), 打印版本 (例如 example.com/page 和 example.com/page/print), 为其他国家准备的、包含相同内容的替代版本 (例如 example.com/en-us/, example.com/en-gb/, example.com/en-au/), 或开发中、以及暂存中的版本 (例如 dev.example.com).
- URL 参数 – 例如: example.com?parameter=whatever. 这些可能是因为跟踪代码、分面导航、排序内容、会话ID等而存在。有一些情况下,参数可能会改变页面的内容,以便它不会被判断为是重复的。
- 其他页面显示了完整的内容 – 当另一个页面完整显示内容时,谷歌可能会选择错误的规划化页面。这可能包括主博客页面、分页、标签页面、分类页面或 feed 页面。
- 采集或变体的内容 – 内容变体通常建议有一个回到原始内容的规范标签,或至少有一个指向原始内容的链接。这是因为所选择的规范化页面可能来自完全不同的域名。他们试图选择原始来源作为规范页面,但在某些情况下,可能会选择错误的页面。
大多数这些通常都不是问题。正如我提到的,谷歌通常会选择一个或另一个版本作为规范。当然也会有一些例外:
- 有时,在内容变体中,来源内容没有被选为规范。如果别人开始对你写的文章进行排名,你会有什么感觉?
- Hreflang 并不能完美解决国际网站的重复问题。谷歌一般会尝试做替换以显示正确的版本。但这并不能保证绝对正确,而且这种设置经常会更新。当这种情况发生时,用户会看到来自错误国家的页面。对于国际网站来说,最好是避免在多个页面上出现相同的内容。
- 对于一些 JavaScript 网站(通常是应用程序 Shell 类型),页面的初始代码可能看起来像其他页面,甚至是其他网站的代码。有时这些页面会被规范化到同一甚至不同网站上的其他页面上面去。
我相信 hreflang 和 JavaScript 内容的部分问题是,谷歌可能通过抓取算法来运行重复检测,这些算法在仅仅看到代码后检测重复模式,而在不是再渲染页面后检测。
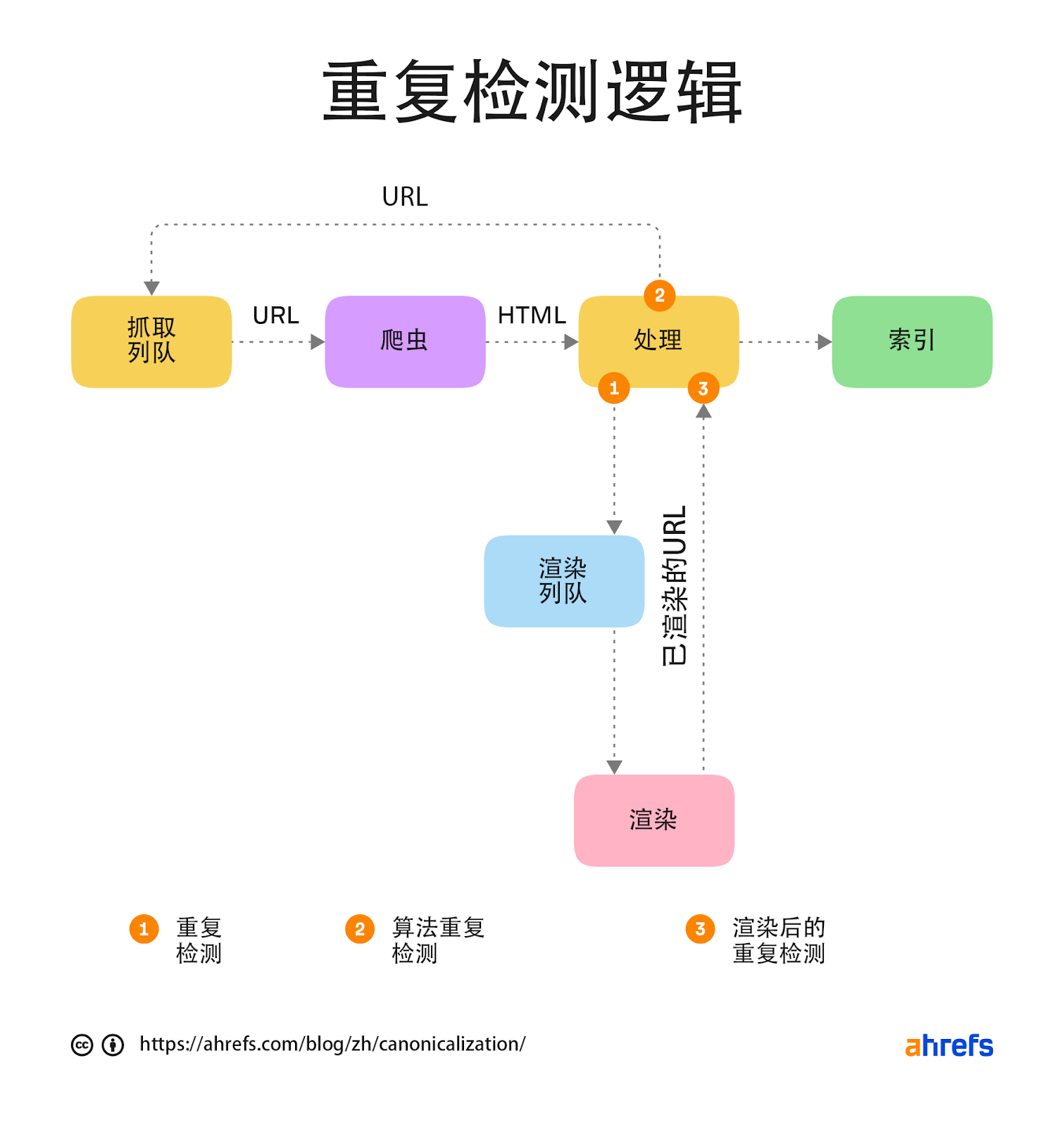
谷歌的渲染路径标出了我认为重复检测系统的运行地点。
对于使用 hreflang 的页面,如果谷歌在没有抓取的情况下判断这些页面是重复的,可能无法正确地辨别它们。
在一个页面被渲染之前,根据 HTM L内容,它可能 “看起来” 像另一个页面。谷歌可能会根据这个初始版本选择规范化版本,并且可能不会优先渲染它,因为它已经被认为是一个重复的页面。这通常会在渲染后自行解决,但它可能需要一些时间来识别。
当涉及到重复内容的规范化时,谷歌有几条它通常遵循的规则:
1. 更喜欢 HTTPS 网页而不是 HTTP 网页
谷歌通常会对HTTPS版本进行索引,但有一些问题或冲突的信号可能会导致它选择 HTTP 版本,例如:
- 拥有一个无效的安全证书。
- HTTPS 页面链接到页面上的 HTTP 资源(不包括图像)。
- HTTPS 重定向到 HTTP。
- HTTPS 页面有一个 rel=“canonical” 链接元素,指向 HTTP 页面。
2. 更喜欢较短的 URL,而不是较长的 URL。
多年来,这句话被 SEO 们误解为说你所有的 URL 都应该更短。但这并不是最初的意思。谷歌说的是,如果你有一个干净的短版本的 URL 和一个附有参数的长版本的 URL,它通常会选择没有参数的短版本的 URL 作为规范化版本。
规范化链接元素
这通常也被称为规范化标签(Canonical 标签)。它看起来像下面这样:
<link rel=”canonical” https://www.example.com />
规范化标签有时被称为 hint(提示),因为它只是一个规范化的信号。如果其他信号更强,谷歌会忽略它。
如果谷歌遵循 canonical 标签,所有的信号、如链接权重都会自然传递。然而,如果规范标签被忽视,就不会有任何权重被传递。当然权重并不会丢失;它将保留在原始页面上,或转到谷歌选择的任意规范化页面上。
一个规范标签可以通过两种不同的方式实现。它可以在页面的 <head> 部分或 HTTP 头中。
一个有趣的轶事。谷歌的 SEO 入门指南曾经是一个 PDF 文件。它没有在 HTTP 头中设置一个规范标签,很多人曾经用他们自己的重复版本 “偷” 了这个清单内容。
有时,页面的 <head> 部分会在它应该结束之前结束。这通常是由于 <head> 中的一个标签没有正确关闭造成的。当这种情况发生时,一个规范标签可能被放入 <body> 部分。如果发生这种情况,你的规范标签就不会生效。

位于 <body> 部分的 canonical 标签是无效的。
网站地图中的 URL
你在网站地图中包含的 URL 也是一个规范化的信号。大多数情况下,你只想包括你想被索引的网页的 URL。
这也有一些例外,因为网站地图的 URL 也有助于抓取。在网站迁移后,你应该创建一个网站地图,仍然列出旧的页面,即使它们不是规范化页面 URL。这将有助于谷歌更快地处理重定向。在大部分的重定向被接受和处理后,你就可以删除这个网站地图。
内部链接
链接到页面得方式很重要。内部链接就是另一个规范化的信号。
一般来说,你应该链接到规范的页面的版本,并更新那些需要更新的 URL 链接。但是也有例外,例如分面导航(多选导航)。在这样的一些情况下,对用户友好得做法,并不一定最符合 SEO。你可能需要做取舍。
外部链接
别人页面是怎么链接到你的页面的这也很重要。如果你能让外部链接同步更新,并指向你当前指定的页面,这便于让谷歌知道你希望该网页的最新版本被搜索引擎索引。
跳转
有几种不同类型的重定向,它们都是规范化的信号。它们会传递 PageRank,并帮助决定哪个 URL 可以被显示在谷歌的索引中。
301 跳转和 308 跳转会将信号向前发送至新的 URL。302 跳转和一些 307 跳转则发送信号到重定向前的 URL。如果一个 302 跳转被留在原地足够长的时间,或者它被重定向到的 URL 已经存在,它可能被视为一个 301 跳转,并向新的 URL 发送信号。这需要足够的信号来翻转我们之前看到的规范化信号的尺度。随着链接的建立,内部链接的改变,网站地图 URL 的更新等等,更多的信号会指向新的 UR L而不是旧的 URL。
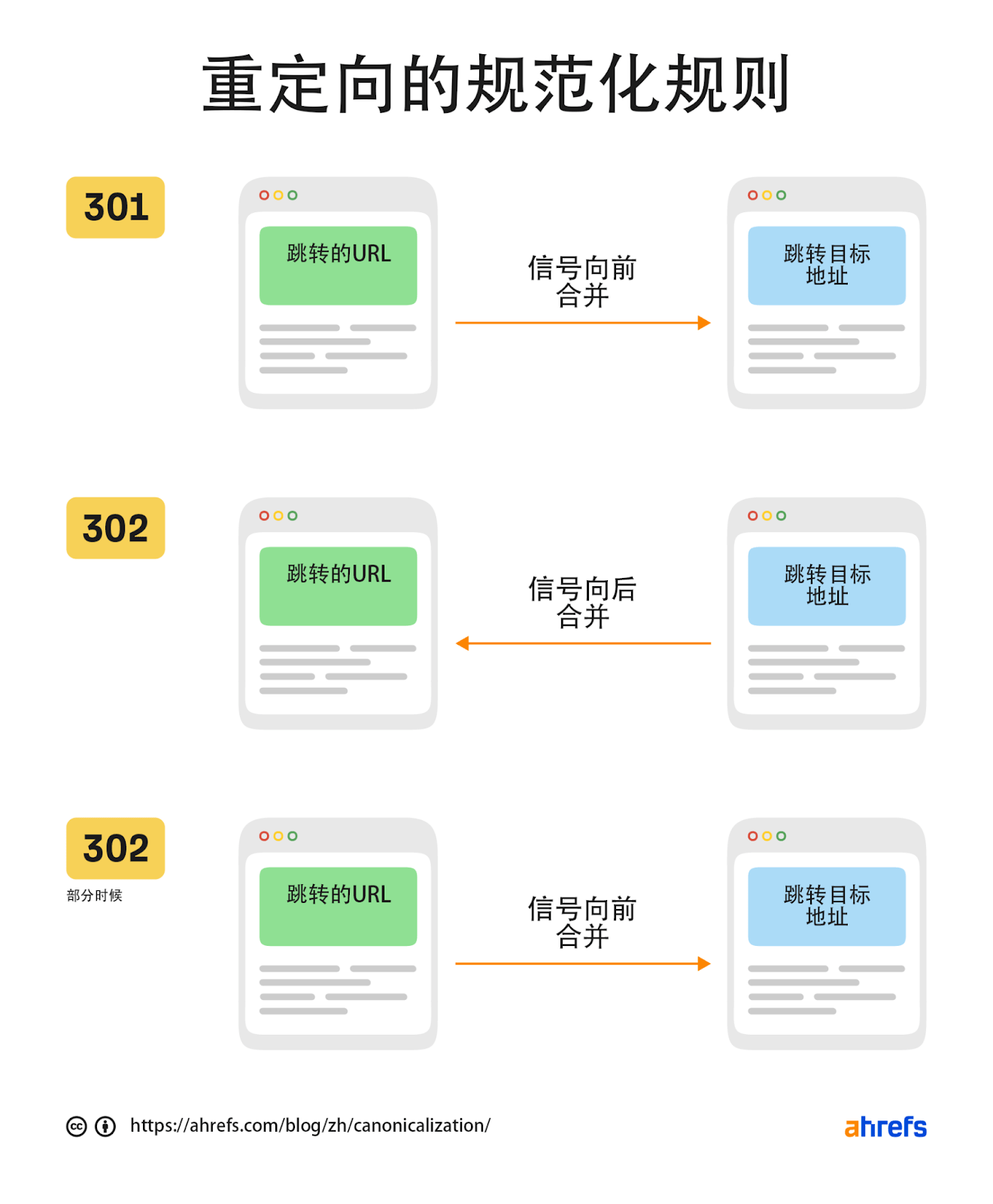
在某些时候,302 跳转的情况会有变化。
一个 307 跳转有两种不同的情况。在它是一个临时重定向的情况下,它将被视为与 302 跳转相同,并尝试合并到旧的 URL 上。当网络服务器要求客户只使用 HTTPS 连接时(HSTS 规则),谷歌不会看到 307 跳转,因为它在浏览器中被缓存了。最初的点击(没有缓存)将有一个服务器响应代码,可能是 301 跳转或 302 跳转。但你的浏览器会在随后的请求中显示为 307 跳转。
永久重定向的类型
- HTTP 301
- HTTP 308
- Meta 刷新 0
- HTTP 刷新 0
- JavaScript 定向
- Crypto 重定向
临时重定向的类型
- HTTP 302
- HTTP 303
- HTTP 307 (服务器端,而不是浏览器缓存)
- Meta 刷新 >0
- HTTP 刷新 >0
关于信号整合
这些信号通常在 1 年后被永久合并。如果重定向在这段时间后被删除,信号将留在被重定向的页面上。如果原来的页面被恢复,任何新的信号将会被转移到恢复的页面,但旧的信号仍将合并到被重定向的页面。
Hreflang
Hreflang 是另一个规范化的信号。这一部分很复杂,我建议阅读 Hreflang:初学者的简易指南 来了解更多信息。
你对谷歌选择什么作为规范的主要信息来源是 Google Search Console 的 URL 检查工具。输入URL,它将显示声明的规范 URL 是什么,以及谷歌选择什么作为规范化页面。
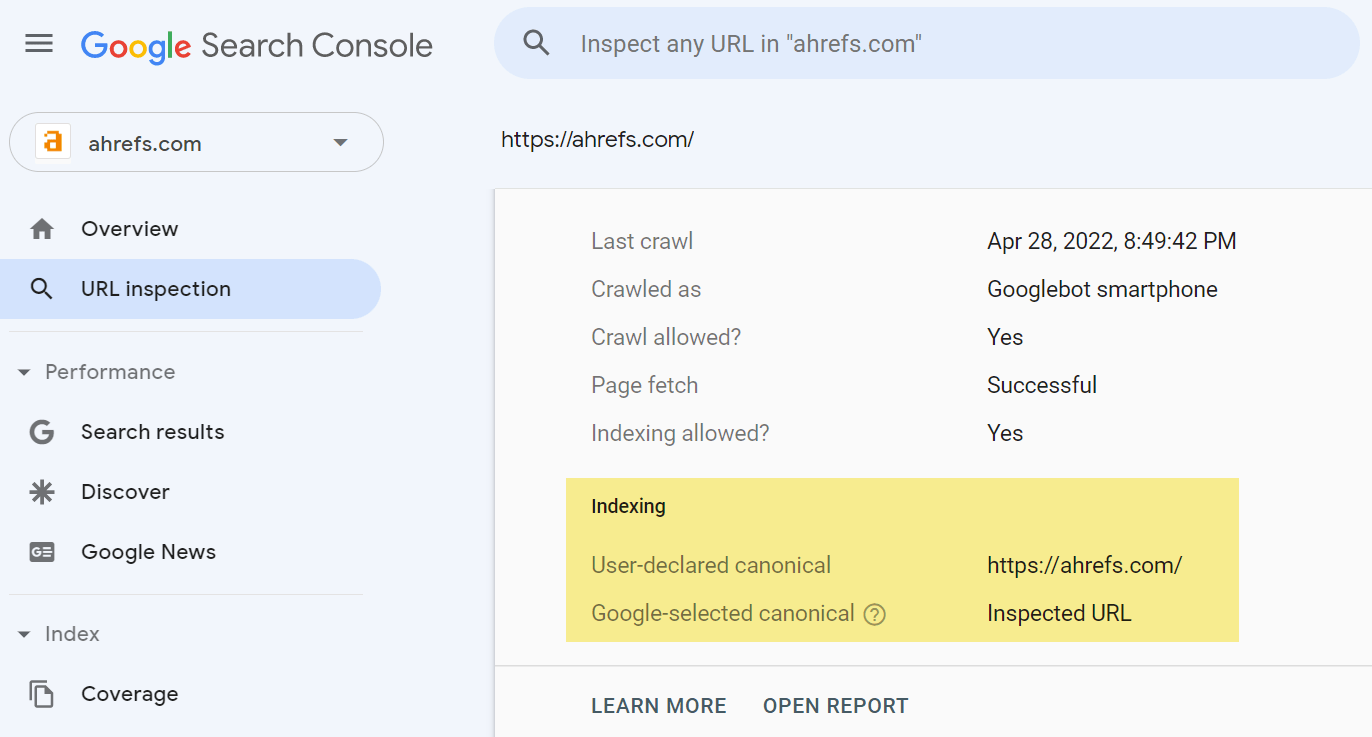
如果你不能访问 Google Search Console,检查谷歌索引的页面版本的推荐方法是将 URL 粘贴到谷歌。最考前的结果通常是规范版本。
同样,如果你在谷歌检查一个页面的缓存版本,而显示的是一个不同的页面,那么基本可以判断为谷歌选择了该页面的不同版本作为规范页面。
注意: 不要使用 site: 搜索来检查规范页面。它显示的是谷歌知道的内容,而不一定是被索引的内容、或选定的规范化页面。
在 Ahrefs Site Audit(网站诊断)的网站审计中,我们显示了许多与规范化有关的问题。请记住,在大多数情况下,我们标记的是最佳做法。因为 canonical 标签只是一个提示,谷歌和其他搜索引擎将不得不选择一个页面的某个版本来索引。
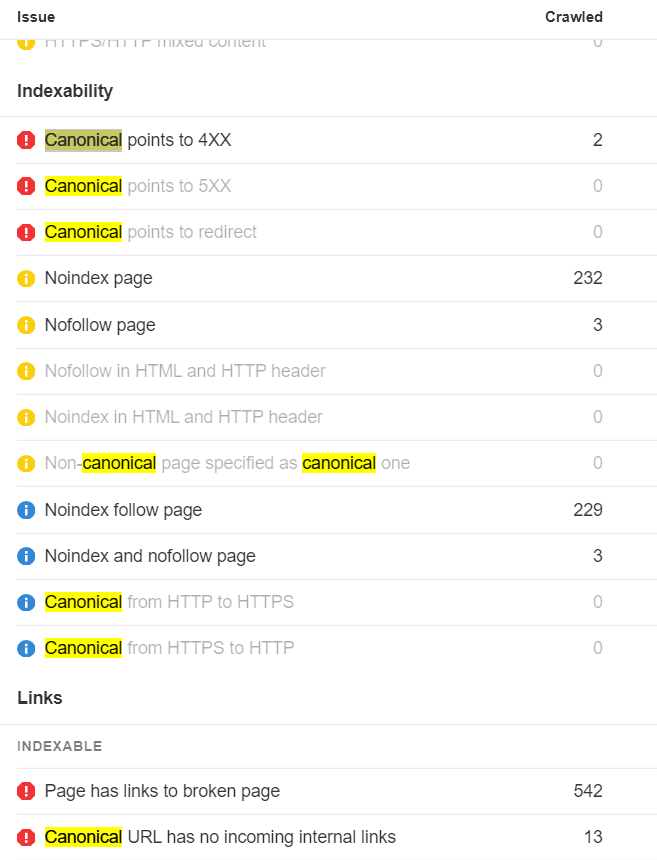
即使你的网站有很多与规范化有关的问题,搜索引擎可能会弄清楚什么版本应该被索引,以及他们应该在哪里整合信号。这可能不会成为特别大的问题。
有趣的事实。在进行网站诊断时,我们只计算页面的规范版本。其他一些工具则将一个页面的每个版本都计入计算中,这可能会产生不少偏差。
规范化有很多可能出错的地方。让我们看一下一些常见的错误。
错误#1、通过 robots.txt 屏蔽规范化的 URL
在 robots.txt 中屏蔽一个URL,可以阻止谷歌抓取它,这意味着谷歌无法看到该页面上的任何规范标签。这反过来又阻止了它将任何 “链接权重” 从非规范页面转移到规范页面。
除非你有抓取预算问题,否则让所有的信号或权重合并起来可能更好。即使你打算屏蔽或不索引一些版本,你最好还是检查一下所有链接的版本。然而,随着时间的推移,谷歌倾向于减少对非规范页面的抓取。
错误#2、将规范化的 URL 设置为 “不索引(noindex)”
不要把 noindex 和 rel=canonical 混在一起。它们是相互矛盾的指令。
正如 John Mueller 所说,谷歌通常会优先考虑 canonical 标签,而不是 “noindex” 标签。
错误#3、为规范化的 URL 设置一个 4XX 的 HTTP 状态代码
为规范化的 URL 设置 4XX 的 HTTP 状态代码,与使用 “noindex” 标签的效果相同。谷歌将无法看到规范化标签,并无法将 “链接权重” 转移到规范化版本上。
错误#4、将所有分页的页面规范化到根页面上
分页的页面不应该被规范化到该系列中第一个分页的页面上。相反,应在所有分页的页面上使用自身 URL 作为规范化 URL。
为什么?正如 John 在 Reddit 上所说,这是对 rel=canonical 的不恰当使用。
既然这个内容是关于规范化的,那么要避免的主要事情就是在第2页上使用指向第1页的 rel=canonical。第2页并不等同于第1页,所以这样的 rel=canonical是不正确的。

如果你有兴趣,我们有一份关于分页的SEO最佳实践的指南。
错误#5、在Google Search Console中使用 URL 删除工具进行规范化处理
这可能会删除一个 URL 的所有版本,会将你的有效页面从搜索中删除。
错误#6、没有保持规范化信号的一致性
正如我们前面谈到的,有许多不同的规范化信号
不同的信号表明不同的规范 URL 意味着你将依赖谷歌为你选择一个规范。你向谷歌展示的你的首选版本的信号越一致,该版本就越有可能成为选定的规范 URL。
错误#7、不使用带有 hreflang 的 canonical 标签
Hreflang 标签指定了一个网页的语言和地理定位。
谷歌指出,在使用 hreflang 时,你应该 “指定一个相同语言的规范页面,或者在相同语言不存在规范页面的情况下,指定一个可能的最佳替代语言”。
错误#8、拥有多个 rel=canonical 标签
拥有多个 rel=canonical 标签通常会导致谷歌忽略它们。在许多情况下,发生这种情况是因为标签是通过不同的功能插入页面的,例如由CMS、主题、以及插件。这就是为什么许多插件有一个覆盖选项,以确保它们是唯一的规范标签来源。
另外一个可能是通过 JavaScript 添加的规范。如果你在HTML响应中没有指定规范的URL,然后用 JavaScript 添加一个 rel=canonical 标签,那么当 Google 渲染页面时,它会得到判断。然而,如果你在 HTML 中指定了一个规范,然后用 JavaScript 交换了首选版本,你就会向谷歌发出混合的(混乱的)信号。
错误#9、<body> 中的 rel=canonical
Rel=canonical 应该只出现在页面的 <head> 中。在一个页面的 <body> 部分的 canonical 标签将被忽略。
这可能成为一个问题的地方是对页面的解析。即使页面的源代码中的 rel=canonical 标签在正确的位置,许多不同的事情,如未关闭的标签、注入的 JavaScript 或 <head> 部分的 <iframe>,都会导致 <head> 在被渲染时过早结束。在这些情况下,规范标签可能会被意外地扔到已渲染页面的<body> 中,在那里它将不会生效。
最后
SEO处理规范化的许多工具已经被拿走了,例如 Google Search Console 中的 URL Parameters Tool 和 Preferred Domain 设置。然而,仍然有很多其他信号可以帮助谷歌选择规范化页面。
有问题吗?在 Twitter 上找我吧。
译者,Park Cheng,歪猫出海创始人。


