しかし、llms.txt とは何で、誰が使うもの?そもそも何の役割があるのでしょうか。
llms.txt とは、LLM がウェブサイトの構造化されたコンテンツにアクセスし、解釈しやすくするための標準仕様として提案されているテキストファイルです。詳しい提案内容は llmstext.org をご覧ください。
簡単に言うと、llms.txt は LLM に有益な情報(API ドキュメント、返品ポリシー、商品の分類、その他の文脈に富んだリソース)がどこにあるのかを伝えるために設計されたファイルです。これにより、言語モデルが価値の高いコンテンツを確実に見つけられるようになり、曖昧さを排除することができます。LLM はこうして、対象となる情報の重要性を推測する手間を省けるようになるのです。
理論的には、これは良いアイデアのように思えます。すでに robots.txt や sitemap.xml のようなファイルを使って、検索エンジンにサイトの内容や構造を伝えているのですから、同じ仕組みを LLM にも応用できるのでは?
しかし重要なのは、現時点では OpenAI や Anthropic、Google などの主要な LLM プロバイダーは llms.txt をサポートしていないということです。
冒頭でも述べたように、llms.txt はあくまで「提案中の標準仕様」です。
やろうと思えば筆者が標準(たとえば、please-send-me-traffic-robot-overlords.txt などを作成)を提案することもできますが、主要 LLM プロバイダーが使用に同意しない限り、ほとんど意味がありません。
これが、llms.txt の現状です。公式には採用されていない、仮説的なアイデアなのです。
llms.txt は、オンラインでの可視性に影響を与えないかもしれませんが、robots.txt は確実に影響を与えます。
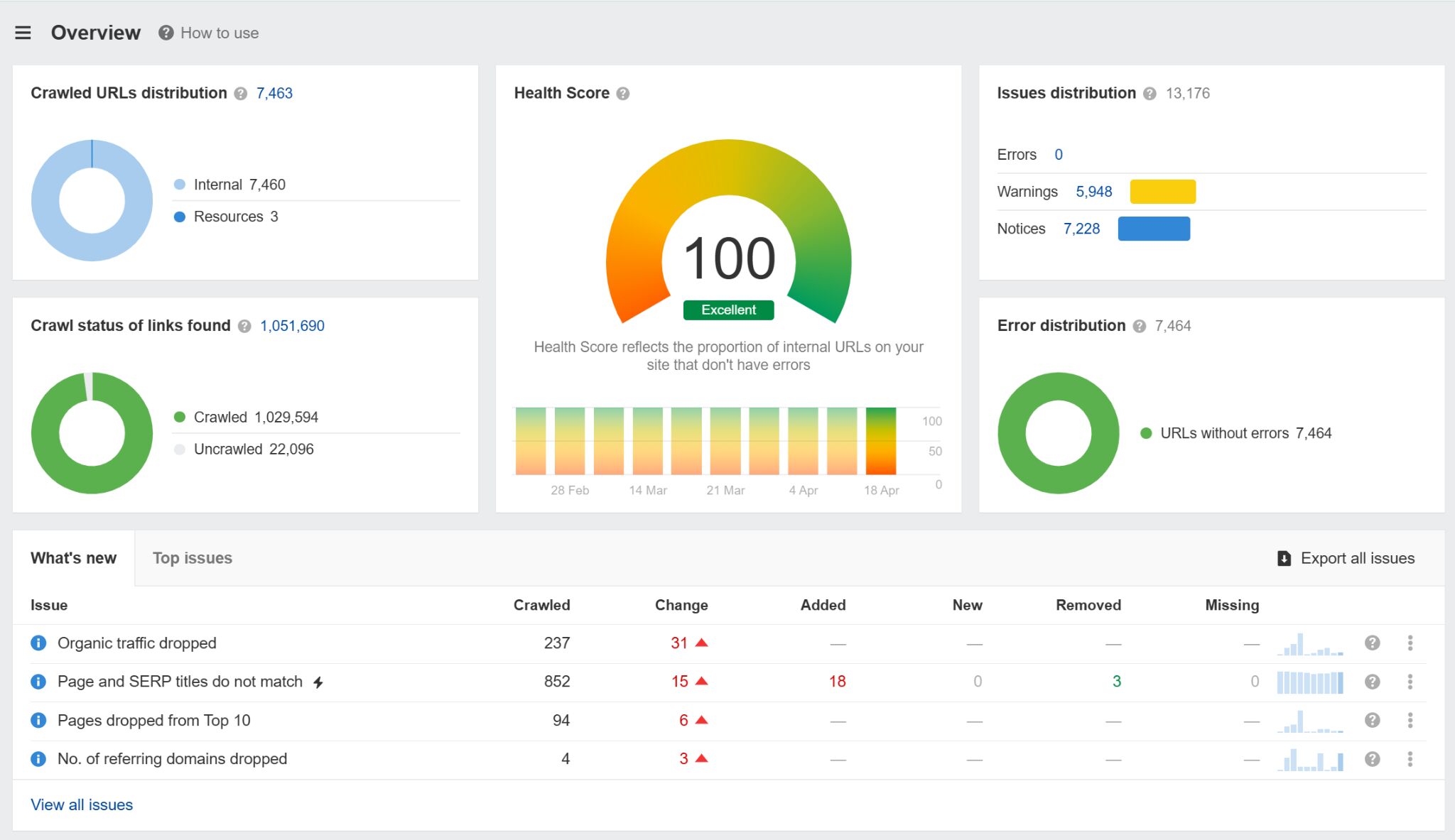
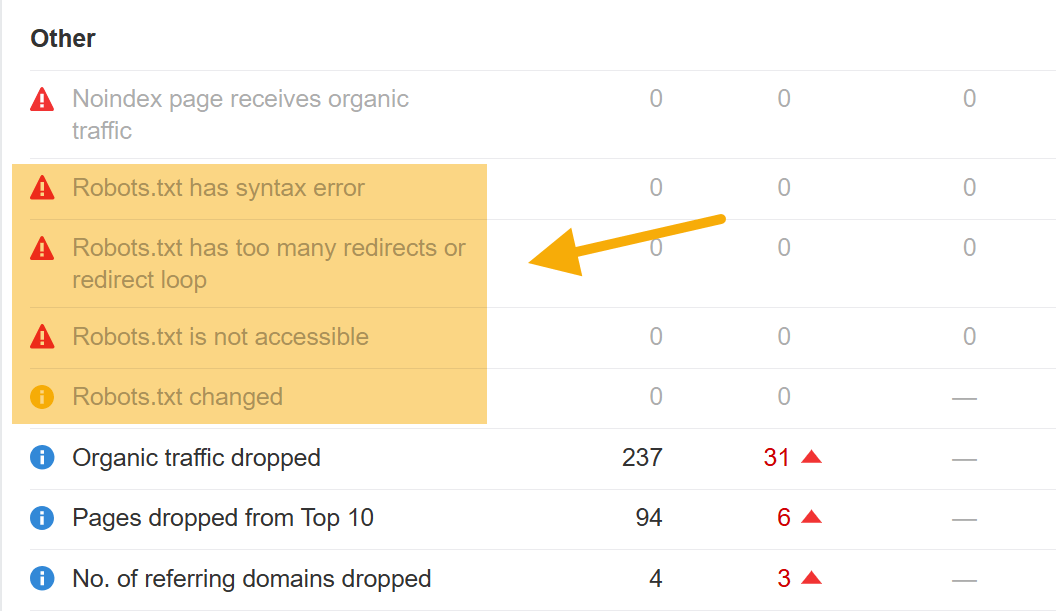
Ahrefs のサイト監査を使えば、robots.txt の設定ミスを含む数百にも及ぶ技術的な SEO の問題を自動で監視できます。 robots.txt にエラーがあると、可視性に深刻な影響が生じます。最悪の場合はサイトがクロールされなくなるかもしれません。
では、llms.txt ファイルの実例を見てみましょう。Anthropic 社が作成した、実際の llms.txt ファイルのスクリーンショットをご覧ください。
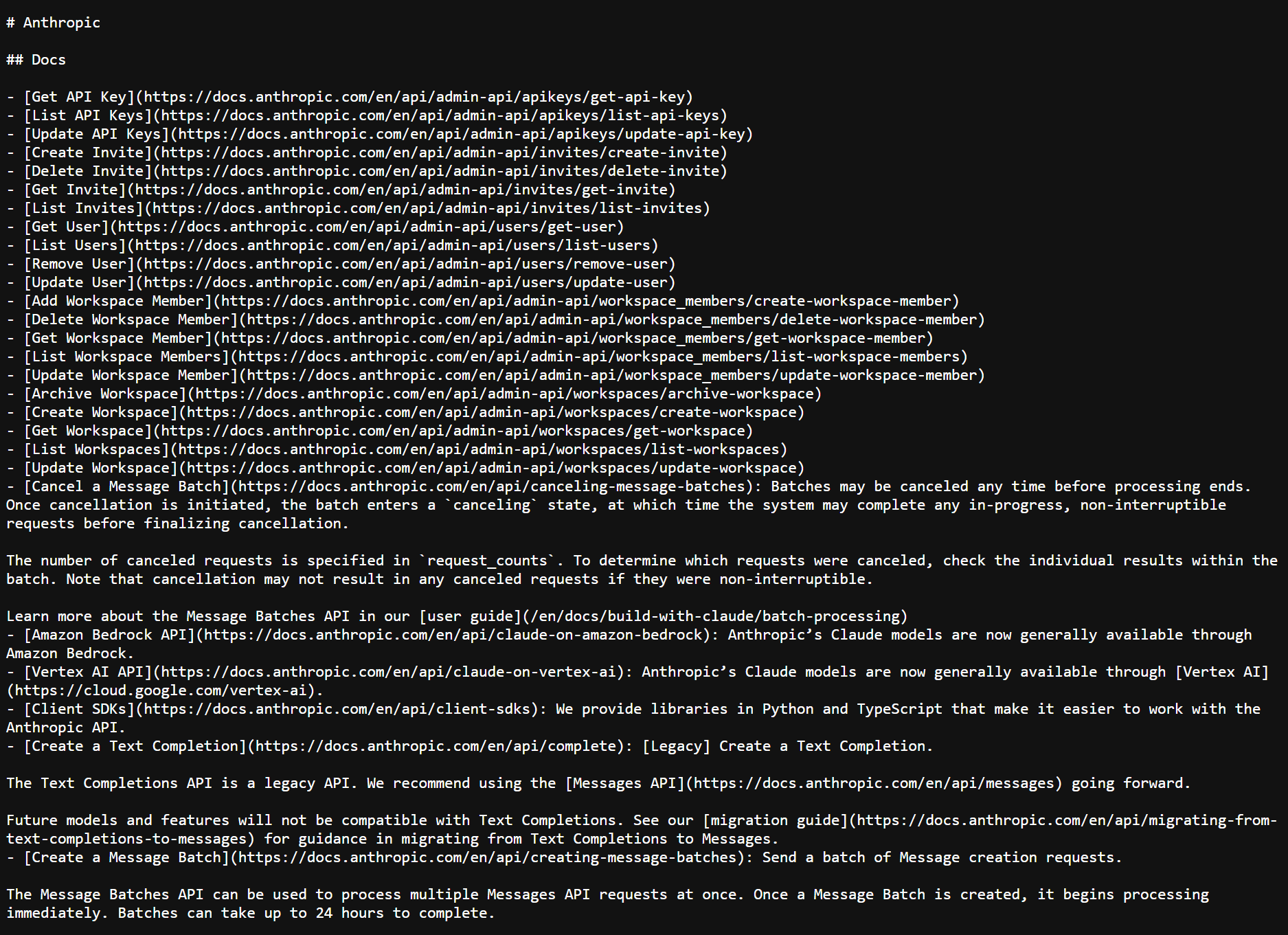
Llms.txt は、本質的には Markdown ドキュメント(特別な形式のテキストファイル)で、重要なリソースへのリンクは H2 見出し(##)でカテゴライズされ、見やすくなっています。
# llms.txt
## Docs
- /api.md
API メソッド、認証、レート制限、リクエスト例の概要。
- /quickstart.md
開発者がプラットフォームをすぐに使い始めるのに役立つセットアップガイド。
## Policies
- /terms.md
サービスの利用方法を概説した法的条件。
- /returns.md
返品条件に該当するかの判断基準と処理に関する情報。
## Products
- /catalog.md
製品カテゴリー、SKU、メタデータなどの構造指数。
- /sizing-guide.md
カテゴリー全体にわたるプロダクトサイジングに関するリファレンスガイド。上記を踏まえれば、簡単に独自の llms.txt を作成できます。その手順を見ていきましょう。
- まず、基本的な Markdown ファイルからとりかかります。
- H2 を使ってリソースをタイプ別にグループ化します。
- Markdown 対応の構造化されたコンテンツにリンクします。
- これを常に最新の状態に保ちます。
- ルートドメイン https://yourdomain.com/llms.txt でホストします。
こういった llms.txtは自分で作成することも、こちらの無料 llms.txt ジェネレーターを使って生成することもできます。
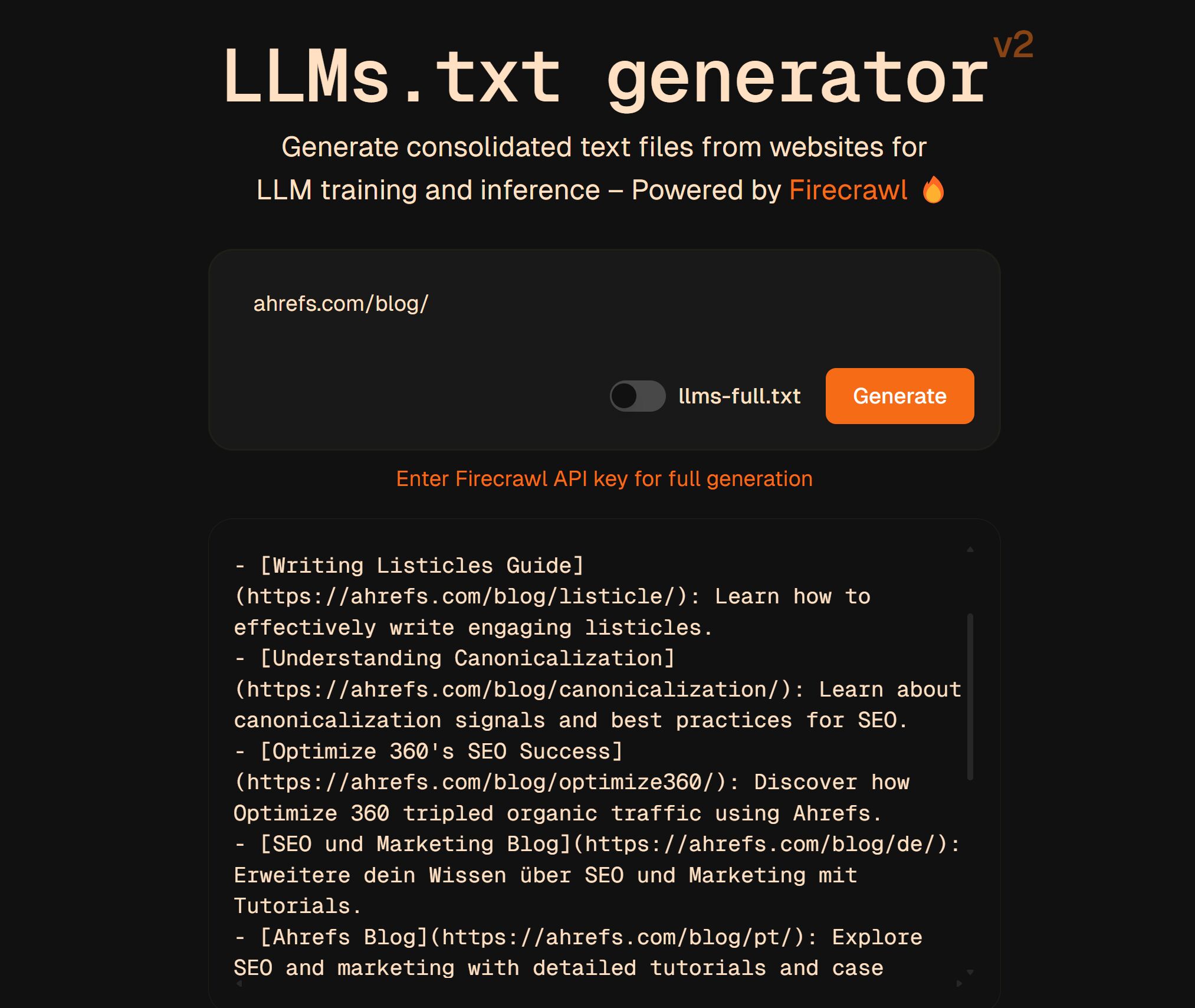
一部の開発者は、llms.txt ファイルにトークンの使用上限や優先するファイル形式などの LLM 向けの独自メタデータを実験的に追加している、ということをどこかで読んだこともありますが、クローラーや LLM モデルがこれを実際に参照しているかどうかは定かではありません。
llms.txt を使用している企業のリストは、コミュニティが運営している公開済み llms.txt ファイルのインデックス directory.llmstxt.cloud から閲覧できます。
以下が使用している企業の一部です。
- Mintlify:開発者向けドキュメントプラットフォーム
- Tinybird:リアルタイムデータ API
- Cloudflare:パフォーマンスとセキュリティに関するドキュメントリスト
- Anthropic:API ドキュメントの完全な Markdown マップ公開
では、大手企業はどうでしょうか?
今のところ、主要な LLM プロバイダーの中で、llms.txt をクローラープロトコルの一部として正式に採用している企業はありません。現状は次の通りです。
- OpenAI (GPTBot):robots.txt への評価は高いものの、公式には llms.txt を使用していない。
- Anthropic (Claude): 独自の llms.txt を公開しているが、自社のクローラーが標準規格を使用しているとは明言していない。
- Google (Gemini/Bard): AI のクロール動作を管理するために robots.txt(Google-Extended ユーザーエージェント経由)を使用しているが、llms.txt のサポートについては言及していない。
- Meta (LLaMA): 公開されたクローラーやガイダンスはなく、llms.txt の使用についても言及されていない。
これは重要なポイントを浮き彫りにしています。llms.txt を作成することと、それをクローラーの動作に反映させることは同じではないということです。つまり現時点では、ほとんどの LLM ベンダーは llms.txt をおもしろいアイデアであると認識しているものの、優先して採用し対応すべきものとは考えていないのです。
現時点では実際に llms.txt が役に立つとは言えない、というのが筆者の見解です。
llms.txt が AI 検索を向上させたり、トラフィックを増加させたり、モデルの精度を高めたりするという確証はなく、llms.txt のパースを約束しているプロバイダーもありません。
とはいえ、設定が非常に簡単なことは否めません。製品ページや開発者向けドキュメントなどの構造化されたコンテンツが既にある場合は、それをもとに Markdown ファイルとして作成し、自社ウェブサイトでホストするだけです。設定しても目に見えるメリットはないかもしれませんが、リスクもありません。ただ、LLM が最終的にこれを標準として採用すれば、早期導入することで多少のメリットが得られるかもしれません。
現時点で llms.txt が注目を集めているのは、誰もが LLM の可視性を高めたいと願っているものの、それを実現する手段がないため、コントロールできそうな気がするアイデアに飛びついているだけだと思います。
さらに、llms.txt は、あるかないかわからない問題に対処するために無理やり作り出された解決策であると筆者は考えています。検索エンジンは既に robots.txt や sitemap.xml といった既存の標準を使用してコンテンツをクロールし、理解しています。 LLM もほぼ同じインフラを使用して事足りているのです。
Google 社のジョン・ミューラー氏は、最近の Reddit 投稿で次のように述べています。
私の知る限り、どの AI サービスも LLMs.TXT を使用しているとは言っていないし、サーバーログを見ればチェックすらしていないことがわかります。私にとっては、LLMs.TXT はキーワードメタタグと同じように、サイトオーナーが「自分のサイトはこうだ」と主張しているだけのものに過ぎない…(実際にそのサイトがそうなのかは、直接チェックすれば分かることでは?)

これについてご自身の意見をお持ちの方、あるいは反対の事例をご存知の方は、ぜひ X までメッセージをお寄せください。

