llms.txt については様々な議論が交わされていますが、実際のエビデンスとなると、単一サイトのログや小規模な実験しか存在しません。
Ahrefs チームは Ahrefs ウェブアナリティクスとボットアナリティクスを使い、13.7 万のドメインのサーバーログとライブトラフィック、そしてそれらにアクセスするすべてのユーザーエージェントを分析しました。
以下がその調査結果です。
- llms.txtの公開率:対象ドメインのうち、28%が
llms.txtファイルを公開していました。 - トラフィックの現状:そのうち97%のファイルでは、2026年5月のトラフィックがゼロ(一度もアクセス/読み込みがされていない状態)でした。
- アクセスの内訳:
llms.txtファイルに到達したリクエストの96%はボットによるものでした。 - AIツールの動向:読まれた3%のファイルへのアクセスのうち、19.5%は名前のあるAIツール(最多はGPTBot、2位はClaude-Code)からのものであり、これらは、AI検索ボットやアシスタントボットによるアクセスを上回る結果となっています。
- 研究目的のアクセス:アクセスの12%は、業界関係者や研究者が分析を行う目的(GEO/AEOツール、llms.txtチェッカーツール、リサーチャーなど)のものでした。
- AIボットの挙動:存在しない
llms.txtファイルに対するAIボットからのリクエストはゼロでした。AIボットが能動的に探しに行くことはありません。 - その他のアクセス:Chrome Lighthouseの
llms.txt監査によるアクセスは、約1,000件に1件の割合でした。
2026 年 5 月下旬、Google は 1 週間足らずの間に llms.txt をめぐる議論の両サイドに立ちました。
Google が新たに公開した生成 AI 機能向け最適化ガイドでは、「mythbusting」というセクションの中で、生成 AI 検索に表示されるために llms.txt のような機械可読ファイルは不要だとサイトオーナーに伝えています。
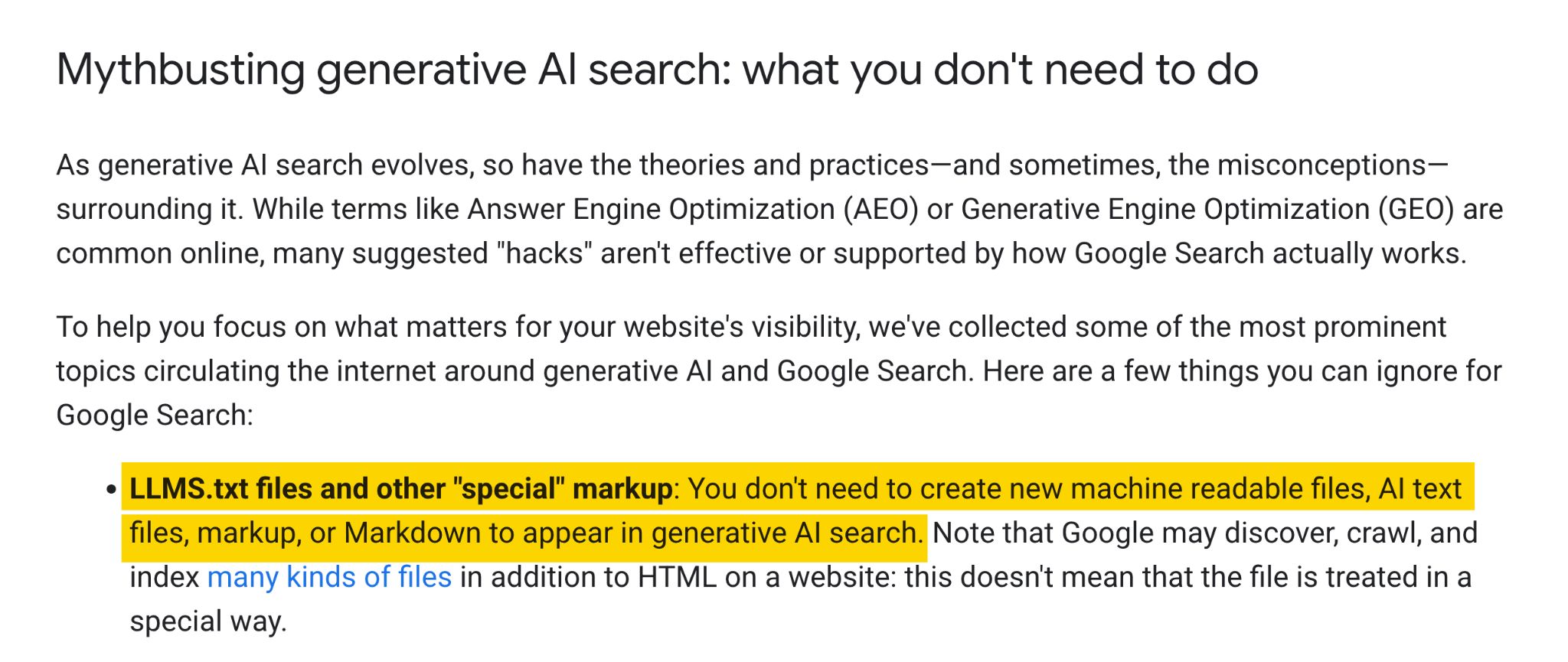
その数日後、Chrome チームは Lighthouse の実験的な Agentic Browsing 監査に llms.txt チェック機能を追加しました。そのドキュメントには、llms.txt ファイルがないとエージェントがサイト構造を理解するためにより多くの時間をクロールに費やす可能性があると説明されています。
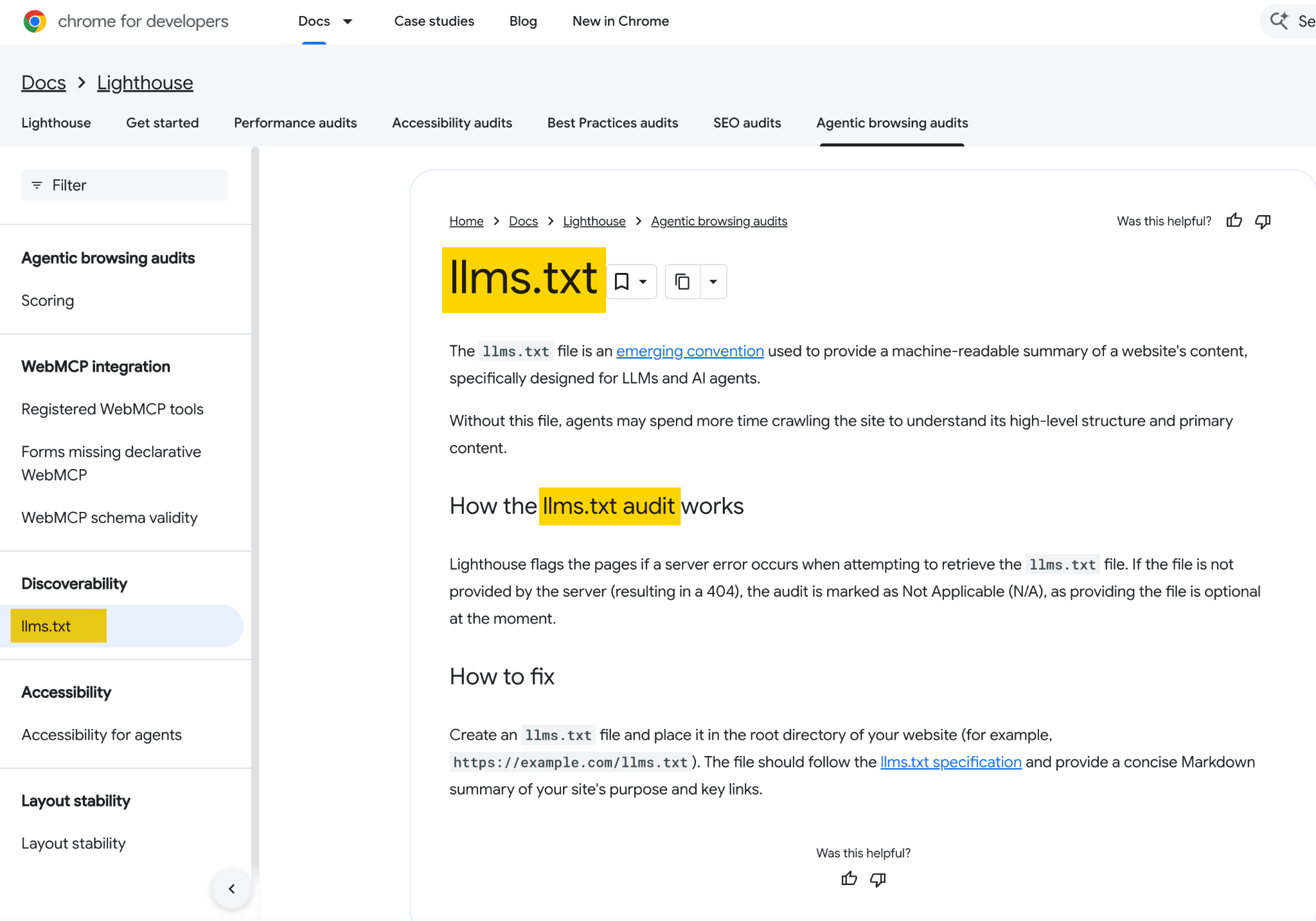
リリー・レイさんが Google のジョン・ミューラーさんにこの矛盾を問いただしたところ、ミューラーさんは llms.txt は「検索のためのものではない」と説明しました。開発者向けドキュメントを解析する AI コーディングツールのための「一時的な補助手段であり、トークンを節約するためのもの」であって、開発者以外のサイトが心配する必要はないとのことです。
また、サーバーログを確認すれば AI エージェントのトラフィックはほとんど見つからないだろうとも述べています。
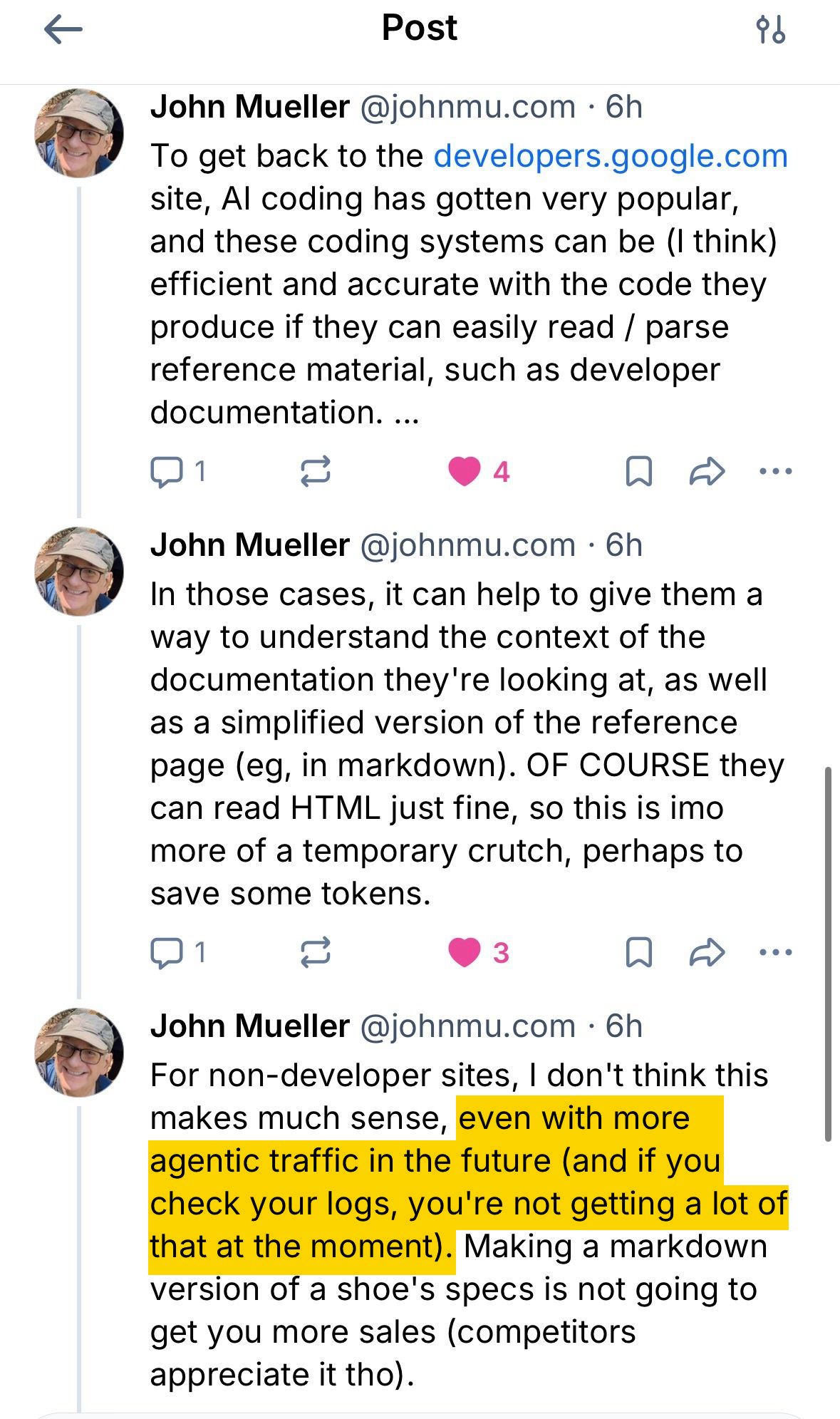
Ahrefs チームは、この主張を検証することにしました。
- llms.txt は、ウェブページの Markdown コピーを公開するプラクティスとは異なります。それは独自の問題を抱えた別の手法です。
- また、ファイル名の印象に反して、robots.txt のようなディレクティブでもありません。何も制御せず、何もブロックしません。
本調査はインデックスファイルのみを測定対象としています。
本調査では、2026 年 5 月にトラフィックのあった Ahrefs ウェブアナリティクス上の全 137,210 ドメインを対象としました。
各ドメインのルートで HTTP 200 を返す llms.txt の有無を確認し、Ahrefs ボットアナリティクスを使って全ドメインの /llms.txt パスへのリクエストを、HTTP レスポンス(200 と 404)で分類し、チャネルおよび個別のユーザーエージェントごとに検証しました。
ソフト 404 やファントムファイルを除外するため、各ファイルが HTML ではなく実際の Markdown であることを確認し、タイトルやコンテンツに「404」や「Page not found」などのエラーシグナルがないかスクリーニングも行いました。
以下の点に留意してください。
- Ahrefs ウェブアナリティクスの利用者は、ウェブ全体の平均よりも技術的・ SEO 的な意識が高い傾向にあります。そのため、28% という採用率は上限値として捉えてください。
- llms.txt の仕様に対してファイルが正しいフォーマットであるかどうかは、今回の調査では明示的に検証していません。
Google 検索のガイダンスでは「不要」とされ、Chrome チームは監査項目に追加し、ミューラーさんは「コーディングツール向けの一時的な措置」と説明しています。
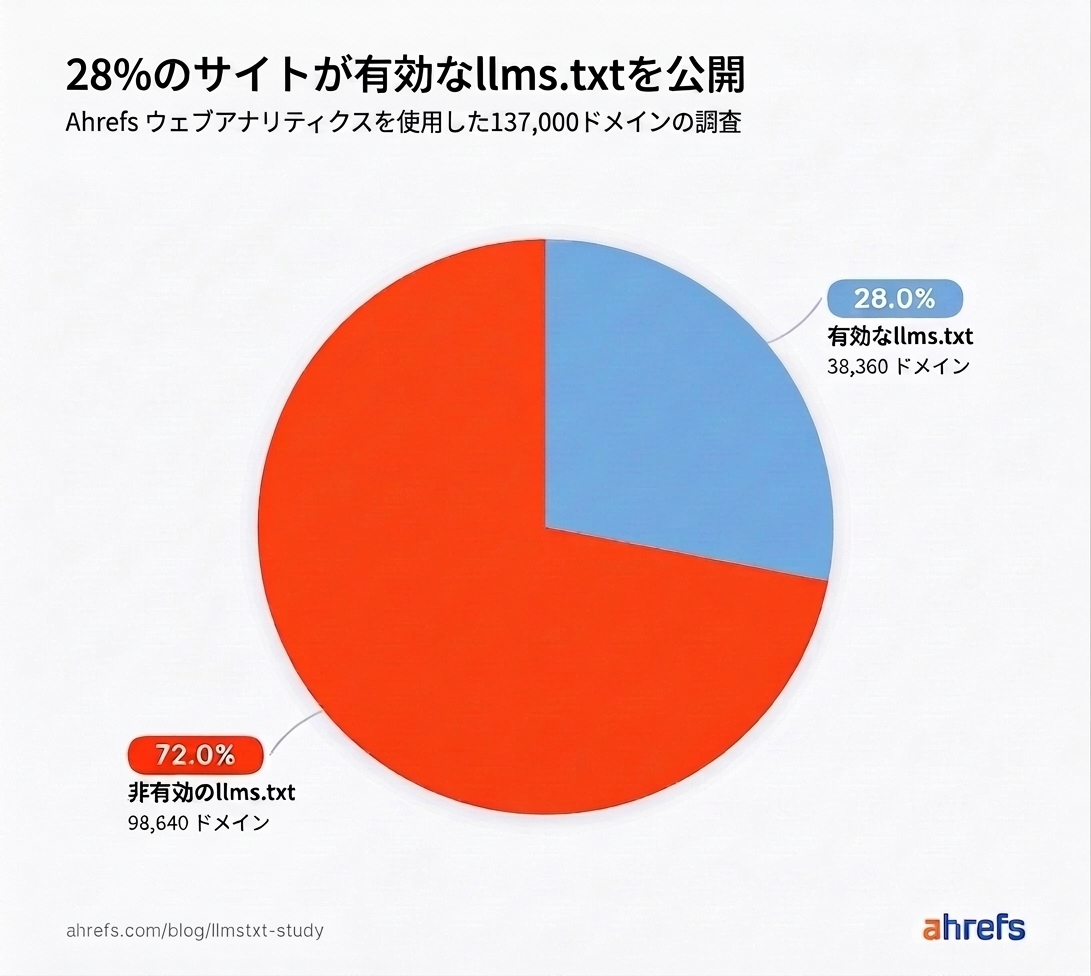
このように相反するメッセージが飛び交う中、llms.txt は実際にどの程度普及しているのでしょうか。今回の調査対象である 13.7 万のドメインのうち、28% がこのファイルを公開していることがわかりました。
調査対象の 4 分の 1 以上にあたる 38,000 ドメインが llms.txt を採用しています。主要な AI プラットフォームがこのファイルを読み込むと公式に表明したことは一度もないにもかかわらずです。
採用を後押ししたのは、AI プラットフォームがこのファイルを利用し始めるかもしれないという推測であり、実際に利用しているという確認ではありません。
調査対象の llms.txt ファイルのほぼすべてが読まれていません。
有効なファイルを持つ約 38,000 ドメインのうち、97% は 5 月中にリクエストが一切ありませんでした。
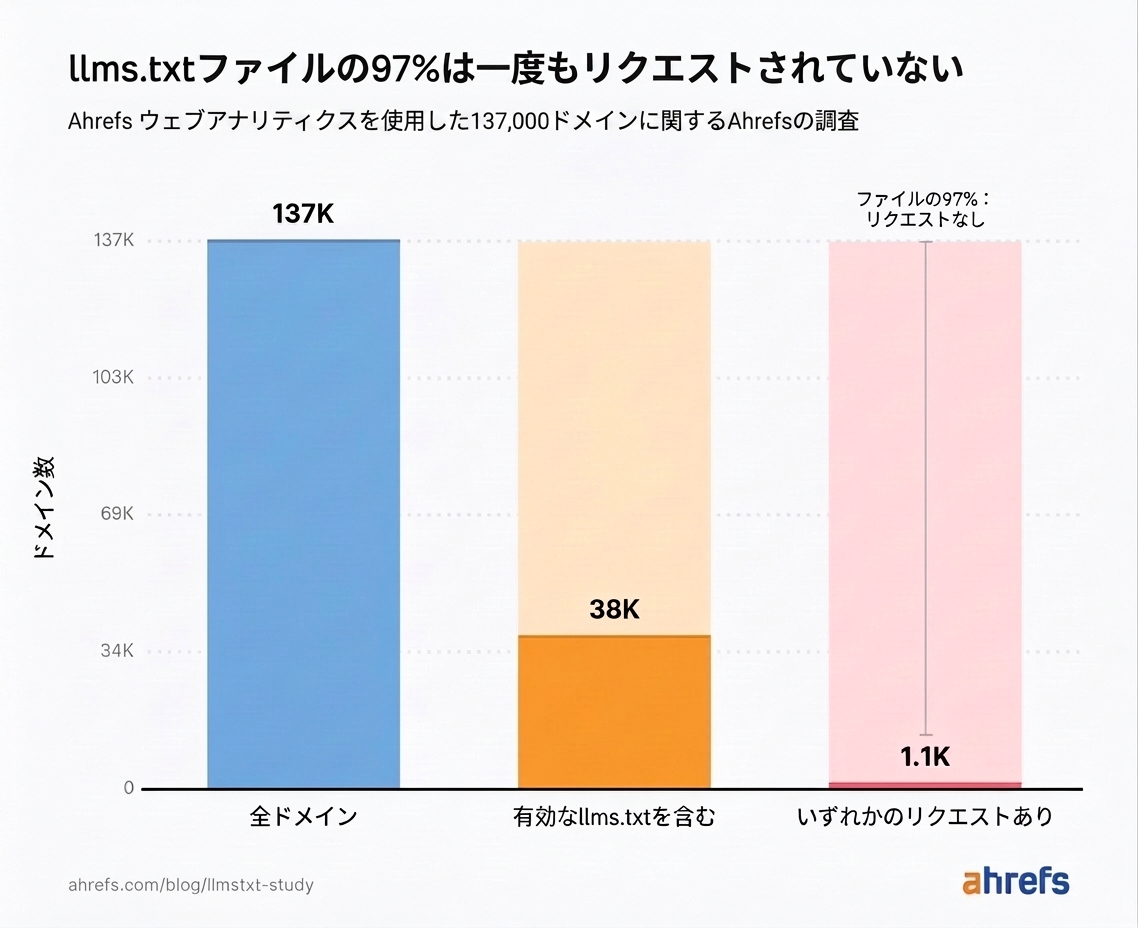
残りの 3%(1,100 ドメイン)が、測定された llms.txt トラフィックのすべてを受け取っていました。
このデータから、ジョン・ミューラーさんの主張は正しいと言えます。このファイルによる AI トラフィックがほとんどないだけでなく、トラフィック自体がほとんどありません。
現時点で llms.txt ファイルを公開しても、圧倒的に高い確率で何もフェッチされないという結果になります。
ただし、読まれている 3% のファイルには興味深い訪問者がアクセスしています。
以降の調査ではこの 3% に焦点を当てます。
llms.txt ファイルは機械向けに書かれたものであり、実際にそれを読んでいるのもほぼ機械だけです。
トラフィックのあったファイル全体で、リクエストの 96% はボットからのものでした。
人間は 4% で、その中にはチャットアプリで llms.txt のリンクを共有する SEO 担当者も含まれており、リンク展開ボットが忠実にフェッチしているケースもあります。
Slackbot は、PerplexityBot よりも高い頻度で llms.txt ファイルをフェッチしていました。
Perplexity は llms.txt の恩恵を受けるはずの AI 検索エンジンの一つです。チャットアプリのリンクプレビューボットのほうがフェッチ数で上回っているという事実は、これらのファイルに対する AI 検索側の実際の関心がどの程度かを如実に物語っています。
多くのサイトが llms.txt を公開する理由は、ChatGPT の回答に表示されたり、Perplexity の引用を獲得したり、AI による概要(AI Overview) に採用されたりする可能性が高まると考えるからです。
しかし、データが示すのは別の実態です。llms.txt をフェッチしているボットの 77% は AI ツールではありません。
llms.txt をリクエストしているボットを把握するため、すべてのユーザーエージェントを 12 のカテゴリに分類しました。
| カテゴリ | 種別 | リクエスト数 | 全体に占める割合 |
|---|---|---|---|
| SEO 監査ツール:従来の SEO ヘルスチェックのためにサイトをクロール。llms.txt に特化した関心はなし(例:SiteAuditBot, WebPageTest) | 監査 | 4,776 | 21.7% |
| その他・不明:匿名の SDK デフォルトおよび目的やオペレーターを特定できなかったボット(例:node, satoric-indexer) | 不明 | 3,278 | 14.9% |
| 一般的なウェブクローラー:検索や商品ディスカバリーのためにウェブをインデックス。AI エージェントの用途は明示されていない(例:Googlebot, Amazonbot) | クロール | 2,871 | 13.1% |
| テクノロジープロファイリングツール:技術スタックの特定やビジネスインテリジェンスデータの収集のためにサイトをクロール(例:BuiltWith, Dataprovider) | プロファイリング | 2,546 | 11.6% |
| AI エージェント・エージェンティックインフラ:ユーザーの代理として動作する AI エージェント、およびそれらを支えるクローラーやツール(例:Claude-Code, IbouBot) | AI | 2,302 | 10.5% |
| GEO/AEO ツール:ウェブサイトをスキャンし、AI 検索やエージェントへの対応状況をスコアリング(例:CairrotReadinessBot, AuditMetricBot) | llms.txt の調査 | 1,278 | 5.8% |
| AI 学習用クローラー:モデル構築のためのデータ収集(例:GPTBot, ClaudeBot) | AI | 1,179 | 5.3% |
| llms.txt ディスカバリーボット:llms.txt ファイルを専門的にスキャン、検証、カタログ化するボット(例:LLMS-Txt-Scanner, txtfeed-bot) | llms.txt の調査 | 793 | 3.6% |
| サービス・ソーシャルボット:メッセージングアプリやソーシャルプラットフォームでリンクプレビューを生成するために URL をフェッチ(例:Slackbot, Skype URI Preview) | ソーシャル | 645 | 2.9% |
| リサーチボット:学術目的や調査目的、セキュリティリサーチを含むクロール(例:prompt-injection-survey, ResearchProject) | llms.txt の調査 | 585 | 2.7% |
| AI アシスタント:単一のクエリに応答し、ユーザーの代わりにウェブを閲覧(例:ChatGPT-User, Claude-User) | AI | 559 | 2.5% |
| AI 検索取得ボット:AI 検索プロダクトでユーザーのリアルタイムクエリに回答するためにページをフェッチ(例:OAI-SearchBot, PerplexityBot) | AI | 233 | 1.1% |
※ SEO 監査ツールには Ahrefs のクローラー(SiteAuditBot、Ahrefs Bot、Ahrefs Site Audit)が含まれ、合計 2,334 リクエスト(全体の 10.6%)を占めています。これを除くと、サードパーティの SEO 監査ツールは 2,442 リクエスト(11.1%)です。ボットカテゴリの合計は全リクエストの 96% で、残りの 4%(930 リクエスト)は人間からのアクセスでした。
個別に見ると、AI ボットのカテゴリは上位 4 つに入っていません。
SEO 監査ツール(21.7%)、その他・不明(14.9%)、一般的なウェブクローラー(13.1%)、テクノロジープロファイリングツール(11.6%)のいずれもが、どの AI ボットカテゴリよりも多くのリクエストを送信しています。
独立した AI カテゴリで最大の「AI エージェント」は、5 位の 10.5% です。
しかし、4 つの AI カテゴリ(学習用クローラー、検索取得ボット、アシスタント、エージェント)を合算すると、AI ボットは 19.5% で最大の単一バケットとなります。
ボットトラフィックは 3 つの構図に分かれます。
- ファイルを利用する AI ボット(19.5%)
- 匿名スクレイパーのロングテール(14.9%)
- ファイルを検査する業界(12.1%)
以下で、いくつかの項目を掘り下げます。
llms.txt ファイルに実際に到達するリクエストのうち、既知の AI ボットが占める割合は 19.5% です。
AI ボットが llms.txt の最大の識別可能な読者層であることは確かですが、AI ボットの「種類別」内訳を見ると、多くの人が想定しているような AI ツールにこのファイルが活用されているわけではないことがわかります。
Ahrefs チームでは、AI ボットを以下の 4 つに分類しています。
- AI エージェント&エージェントインフラ:ユーザーに代わって行動したり、エージェントにデータを提供するためにクロールを行うボット
- AI トレーニングクローラー:モデル構築のためにデータを収集するボット
- AI アシスタント:リアルタイムでユーザーに代わってウェブを閲覧するボット
- AI 検索取得ボット:AI プラットフォーム上のユーザーのクエリに回答するためにページを取得するボット
各カテゴリの割合は以下のとおりです。
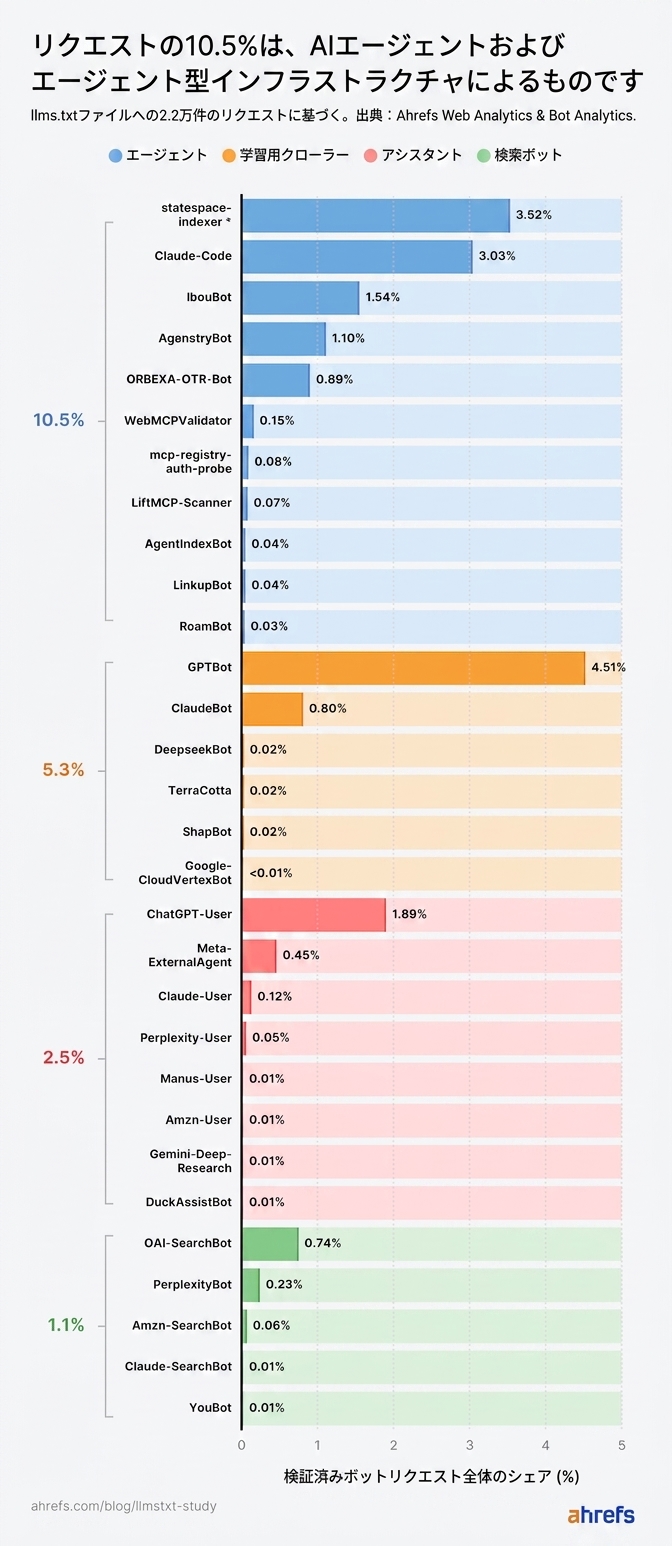
*statespace-indexer:オペレーターは Statespace (エージェントインフラ)と特定されていますが、IP レンジは未確認です。
補足:この分析は、リクエストを 1 件でも受けた 3% のファイルを対象としており、13.7 万のドメイン全体に対するものではありません。対象は約 1,100 ドメイン、合計約 22,000 リクエストに相当するため、依然として非常に小さなサンプルでの調査です。また、「取得された」ことは「読まれた」ことを意味しません。多くのボットが llms.txt ファイルを取得しても、その内容に基づいて何かしらのアクションを取っていない可能性があります。そのため、本調査のすべての数値は llms.txt の実際の消費量の「上限」です。たとえば、AI からのリクエストが 19.5% というのは最も楽観的な解釈であり、実際の AI による消費量はこの数値かそれ以下のどこかに位置します。
エージェントウェブが真の消費者であり、リクエストの 10.5% を送信
AI エージェントとそのインフラは、llms.txt リクエストの 10.5% を占めており、他のどの AI ボットカテゴリよりも多くのリクエストを送信しています。
この結果は、業界の多くの関係者がすでに抱いていた直感と一致するものです。
前述のとおり、ジョン・ミュラーさんは llms.txt が AI コーディングエージェントの参考資料として最も効果を発揮すると述べています。
Nectiv の創設者であるクリス・ロングさんも、llms.txt が Google 検索に直接役立たないとしても、顧客が「Claude Code を使って推薦情報を探している」場合にはこのファイルに有用性があると述べています。
Ahrefs のボットアナリティクスデータは、両者の見解を裏付けています。
llms.txt ファイルは、可視性に関与していると思われる検索エンジンや AI ボットによる取得がはるかに少なく、構造化された情報を求めるエージェントツールやユーザーに代わって行動するエージェントツールによる取得がはるかに多い傾向にあります。
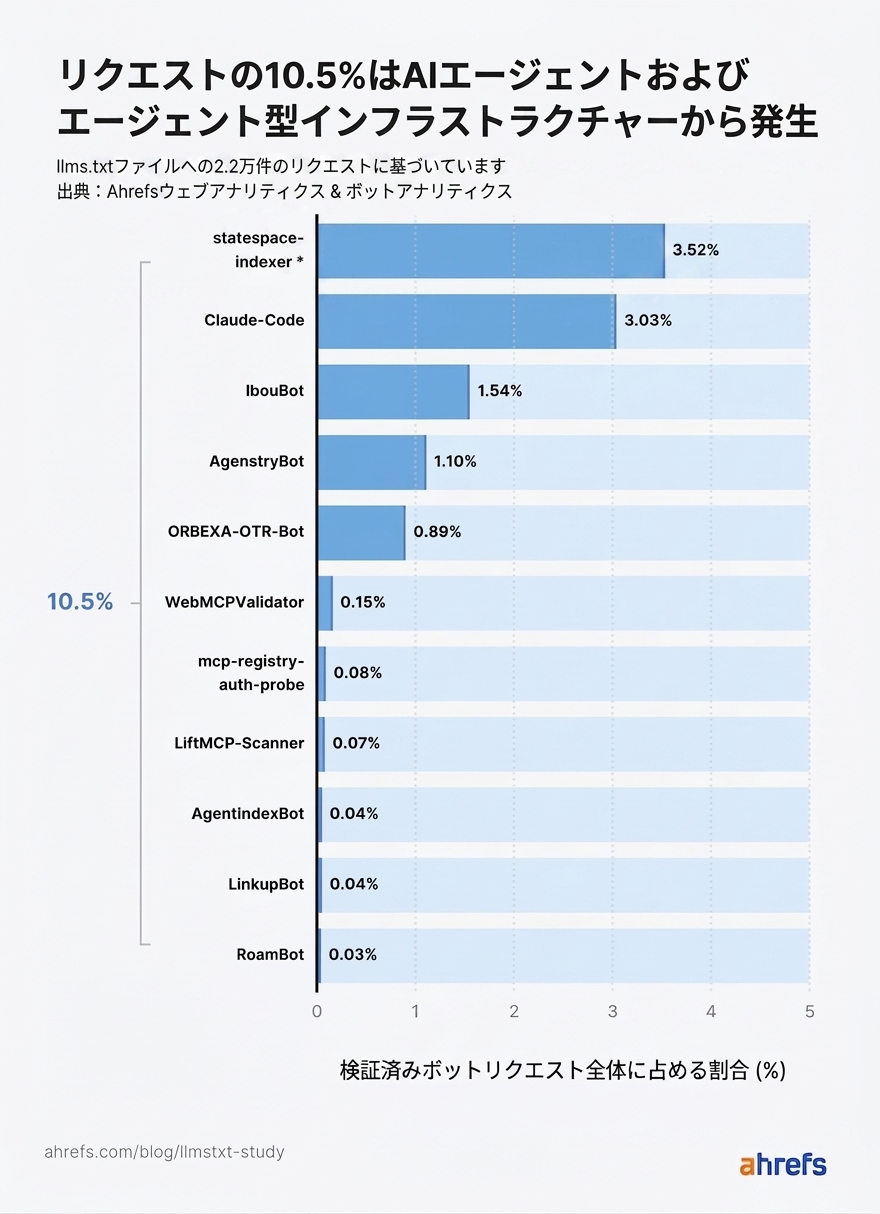
*statespace-indexer:オペレーターは Statespace (エージェントインフラ)と特定されていますが、IP レンジは未確認です。
statespace-indexer と GPTBot を除くと、Claude-Code (Anthropic のコーディングエージェント)が、すべての AI 検索取得ボット、すべての AI アシスタント、すべての AI トレーニングクローラーよりも多くの取得を行っていました。
トレーニングクローラーが AI カテゴリ第 2 位で 5.3%
llms.txt ファイルは、AI 検索の検索取得よりも、トレーニング用コーパスに多くのデータを提供しています。
実際、AI トレーニングクローラーによる llms.txt の取得は、AI 検索取得ボットの約 5 倍にのぼります。
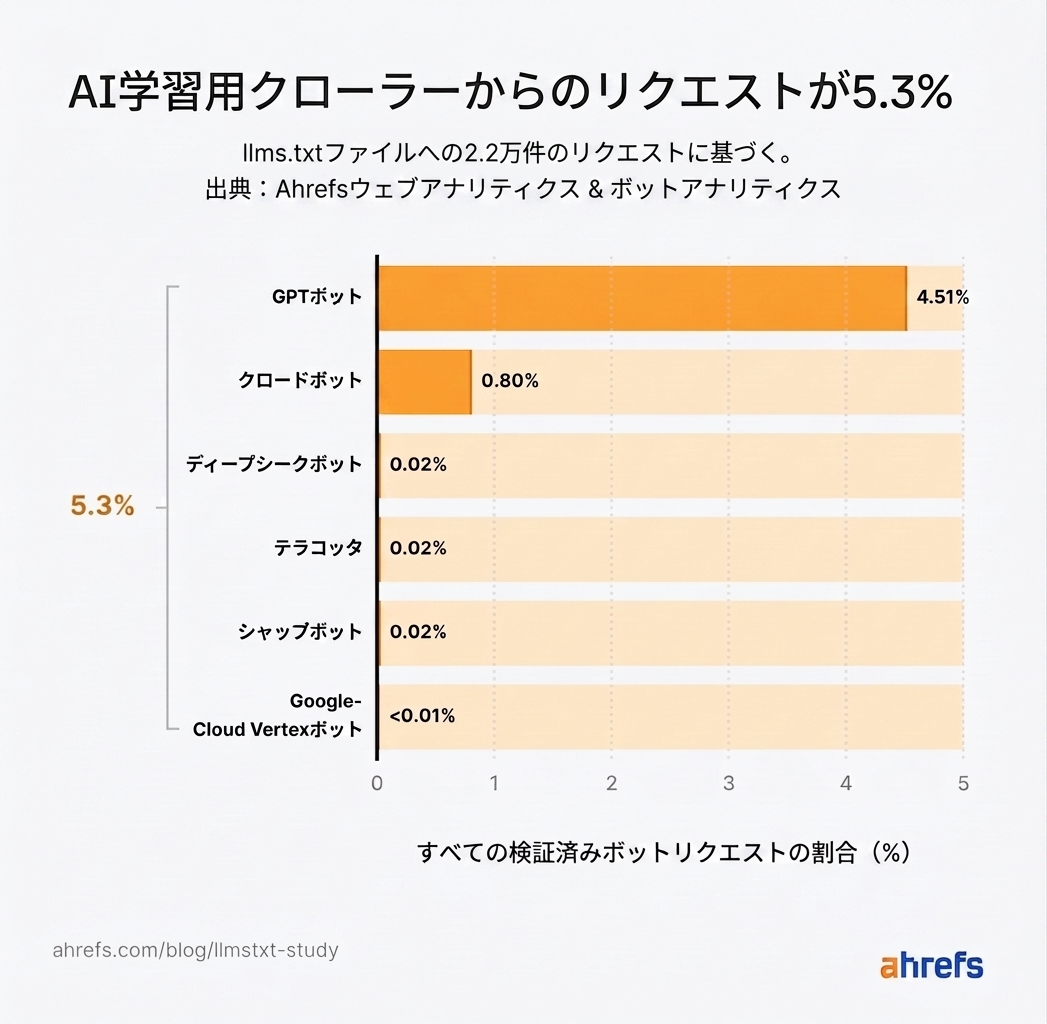
したがって、llms.txt がブランドの AI における可視性に何らかの影響を与えるとすれば、それは検索取得の時点ではなく、上流のトレーニング段階においてです。
全トレーニングクローラーの中で、GPTBot が llms.txt の取得数で圧倒的なトップに立っています。
このリストに Gemini のクローラーは含まれていません。そもそも存在しないからです。
Google は Gemini のトレーニングとグラウンディングに、通常の Googlebot が取得したコンテンツを使用しています。パブリッシャーがオプトアウトに使用する Google-Extended は、独自のユーザーエージェントを持つクローラーではなく、robots.txt のトークンにすぎません。
Googlebot は 5 月に llms.txt ファイルを約 900 回取得しましたが、Googlebot はサイト上で発見した URL を通常の検索インデックス作成の一環として定期的に取得するため、これは llms.txt への特別な関心を示すものではありません。サイトマップや他のページをクロールするのと同じ振る舞いです。
そのコンテンツが最終的に Gemini に供給されているかどうかは、このデータからは判断できません。
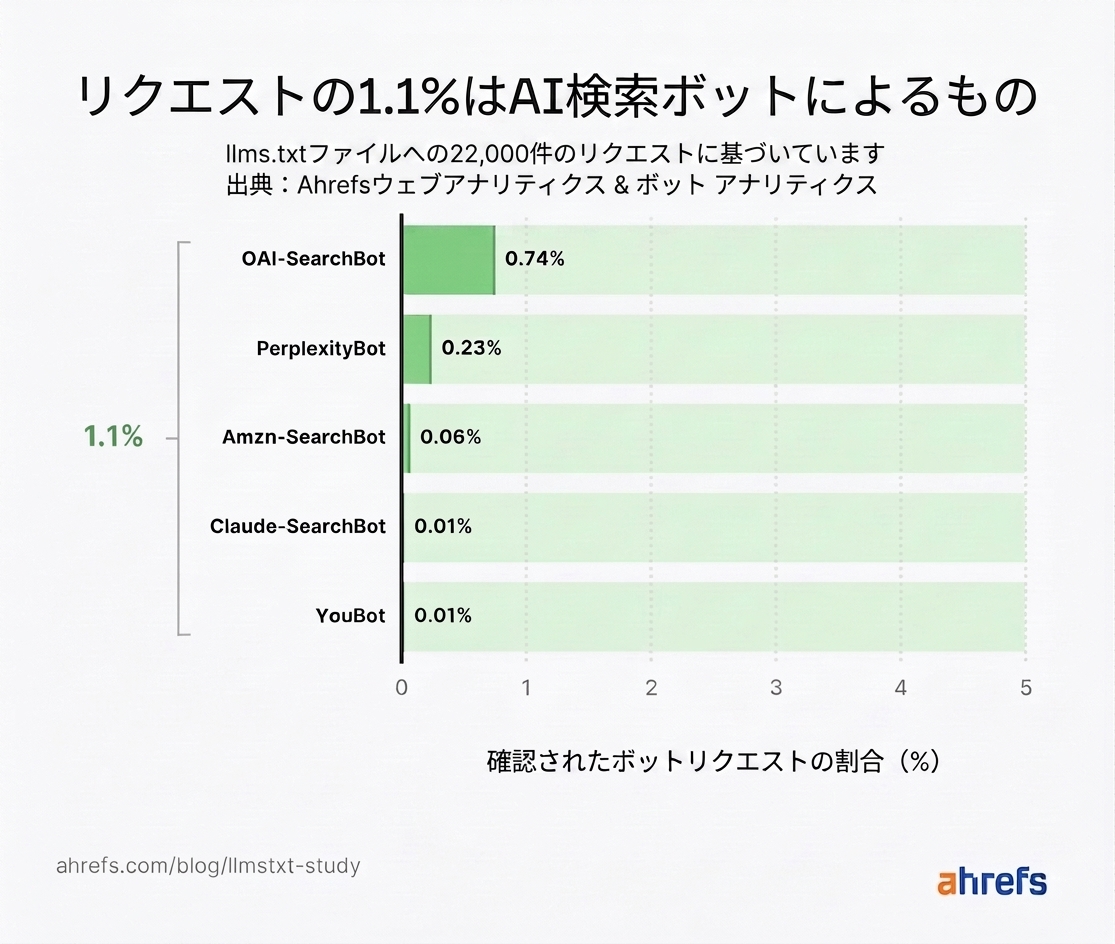
AI 検索取得ボットはわずか 1.1% でほぼ存在感なし
調査データによると、AI 検索取得ボットが AI ボットリクエストに占める割合はわずか 1.1% です。
AI アシスタントおよび AI トレーニングクローラーと合算しても、これらのボットのリクエスト合計は 8.9% にとどまり、AI エージェント単独(10.5%)より 1.6% 少ない結果となりました。
OAI-SearchBot、PerplexityBot、Claude の検索クローラーを合わせても、数千のサイトに対して数百件程度の取得しか行っていませんでした。
AI 引用数を増やす目的で llms.txt を作成しようと考えている場合は、再考が必要かもしれません。
llms.txt の標準規格を監査、スコアリング、検証、研究するためのエコシステムがすでに形成されています。しかし、主要な AI プラットフォームが実際にこのファイルを読んでいるかどうかすら確立されていない段階でのことです。
以下の 3 つのカテゴリが、全リクエストの 12% を占めています。
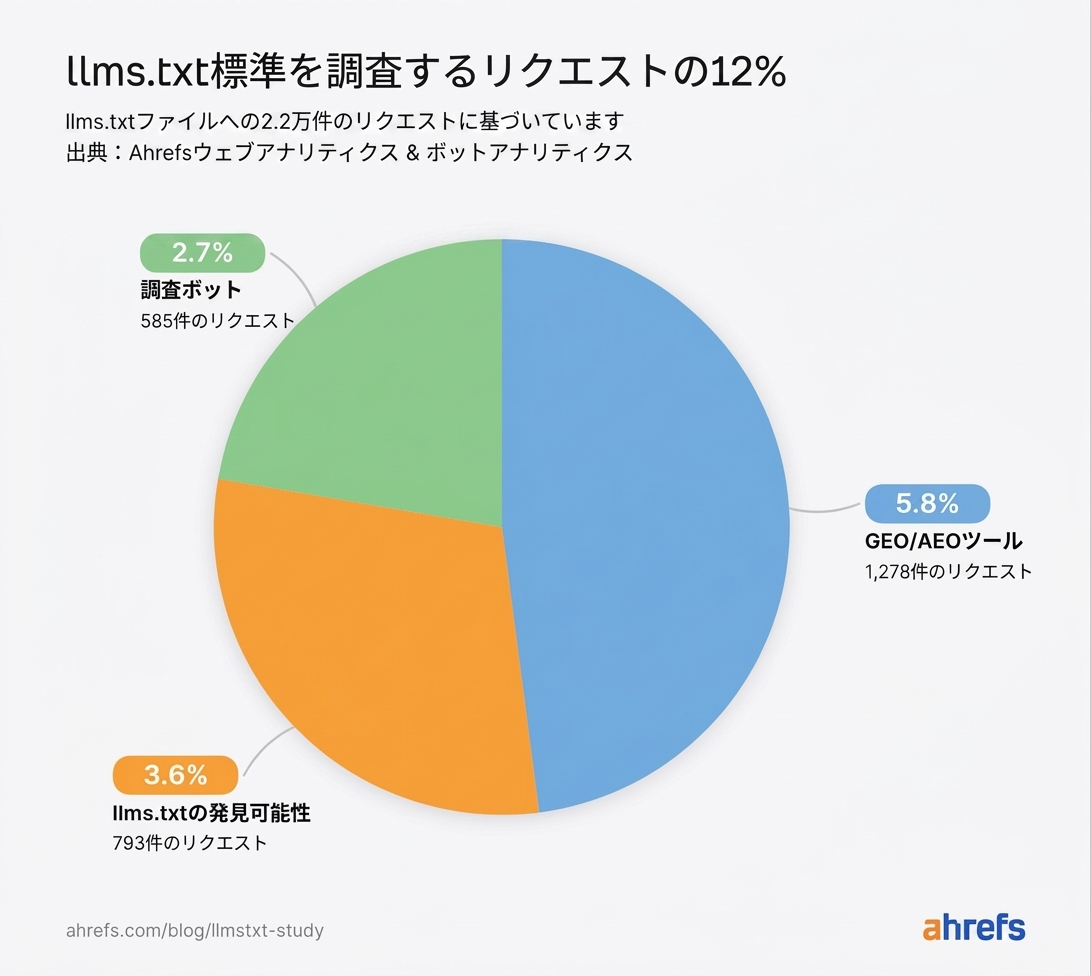
GEO/AEO ツールがリクエストの 5.8% を送信
商用ツールがウェブサイトをスキャンし、AI 検索やエージェントによる発見への対応度をスコアリングしています。llms.txt の有無は、多くのシグナルの 1 つとして使われています。
最もアクティブだったのは CairrotReadinessBot で、これは 2025 年後半にローンチされた WordPress 向け AEO プラットフォーム Cairrot のボットです。
次いで、Framer、Lovable、Wix といった主要なウェブサイトビルダーが、自社製品に AI 対応チェックを組み込んでいます。
llms.txt の導入は、ウェブマスターが判断を下す前に、プラットフォームのデフォルト機能として組み込まれるようになっています。
llms.txt ディスカバラビリティボットがリクエストの 3.6% を占有
ほとんど誰も読まない llms.txt ファイルをカタログ化するツールのエコシステムが存在しています。
llms.txt ファイル専用のスキャナー、バリデーター、ディレクトリが、AI 検索取得ボットや AI アシスタントよりも多くのリクエストを送信しています。
リサーチボットがリクエストの 2.7% を送信
データセット内で最大のリサーチクローラーは、自身を prompt-injection-survey/1.0 と名乗っています。
誰かが llms.txt を、AI エージェントが取り込んで信頼するよう設計されたプロンプトインジェクションの機会として、体系的に調査しているのです。
エージェントが llms.txt ファイルを大規模に信頼することのセキュリティ上の影響はほとんど議論されていませんが、潜在的な悪意ある攻撃者はすでに調査を進めています。
AI ツールは、存在しない llms.txt ファイルを探しに行くことは一切ありません。そのため、llms.txt を公開しても AI のレーダーに捕捉されるわけではないのです。
/llms.txt パスへのリクエストのうち 404 を返したものをすべて分析したところ、ボットデータの中で最も明確な二極化が確認されました。有効なファイルへのトラフィックの 96% がボットである一方、存在しないファイルへのトラフィックの 98% は人間からのもので、404 に対する AI ボットのシェアはゼロでした。
存在しない llms.txt ファイルを探しているのは、ブラウザに URL を直接入力している人間であり、おそらく競合サイトをチェックしている SEO 担当者です。
この結果は、AI システムが llms.txt ファイルを能動的に探しており、ファイルを設置していないサイトはチャンスを逃しているという仮説を否定するものです。
AI ツールが llms.txt を取得するのは、リンク、インデックス、またはユーザーの指示によってファイルの存在が知らされた場合に限られます。
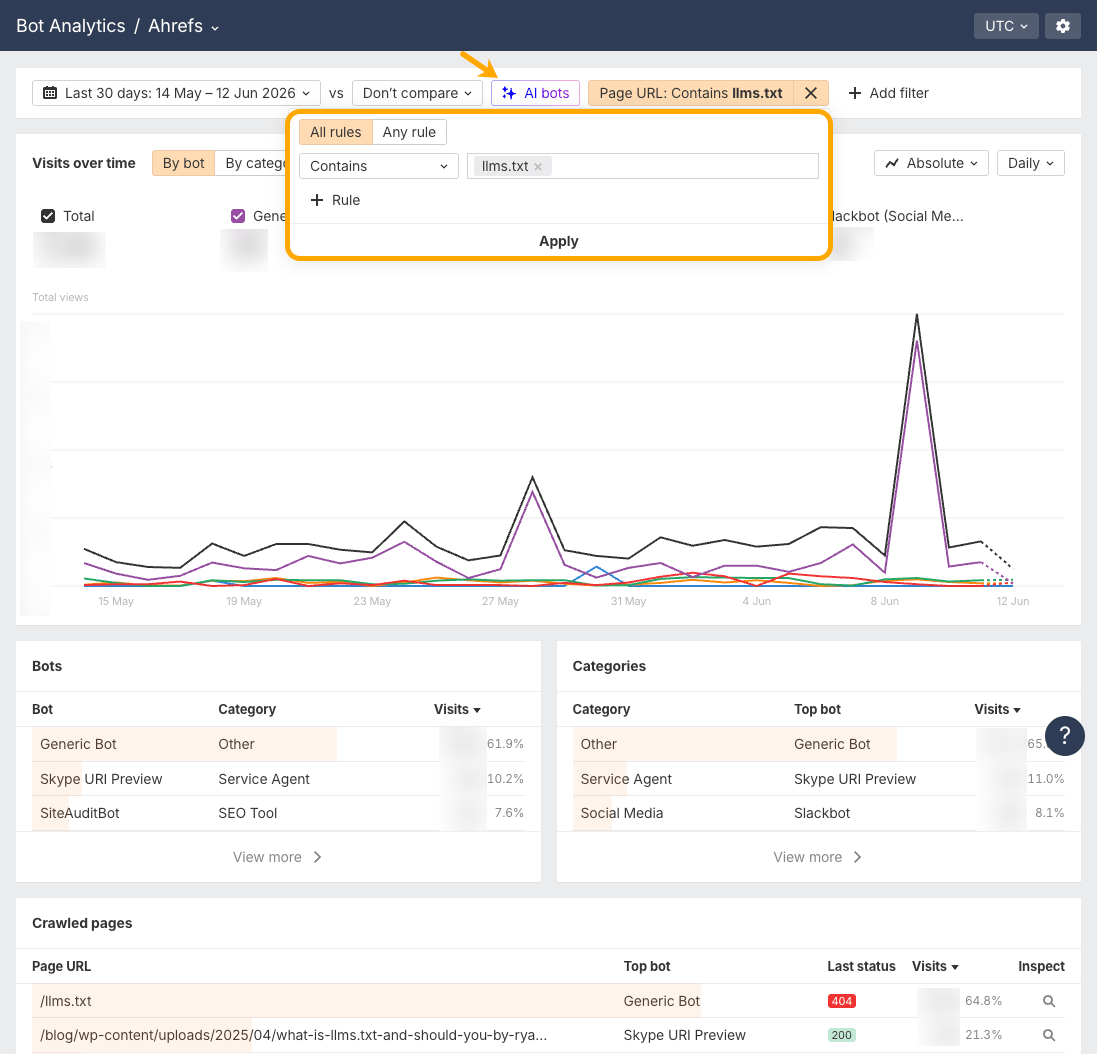
これにより、‘llms.txt‘ ファイル(または URL に「llms.txt」を含むブログ記事など)へのリクエストだけに絞り込めます。
Ahrefs のサイトには llms.txt ファイルを設置していませんが、404 ステータスが示すとおり、一部のボットがそのページにアクセスしていることがわかります。
ここから、以下の項目を確認できます。
- 時系列のアクセス推移:ボット別 と カテゴリ別 を切り替えて、トラフィックが増加傾向か、横ばいか、急増しているかを確認できます。
- ボットテーブル:
llms.txtファイルを取得している具体的なボットを確認できます。 - クロール済みページの最新ステータス:ステータスコードを確認します。
/llms.txtに対する404は、ボットが存在しないファイルを要求していることを意味します。
最後の項目は、実態を把握するうえで有用なチェックポイントです。多くのサイトが、一度も公開していない ‘llms.txt‘ に対してボットリクエストを受けています。トラフィックは実在しますが、ファイルは存在しません。
ページ上部の AI bots フィルターを使えば、他のクローラーを除外して LLM 関連のボットのみを表示することも可能です。
ただし、ボットが llms.txt をリクエストしたからといって、ファイルが「読まれた」または「内容に基づいてアクションが取られた」ことの証拠にはなりません。わかるのは、ファイルが取得されたという事実だけです。
ChatGPT、Perplexity、AI Overview に表示されることが目的であれば、llms.txt ファイルはほぼ飾りにすぎません。
AI 検索ボットが llms.txt を取得することはほとんどなく、どの AI システムも自発的にこのファイルを探しに行くことはありません。そして既存の llms.txt ファイルの 97% は、いかなる種類の読み手も引きつけていません。
さらに、リクエスト数はあくまで寛大な指標であることを忘れてはなりません。ボットが取得した内容を実際に活用しているかどうかは、また別の問題です。
以下に、メリットとデメリットを並べて整理します。
| メリット | デメリット |
|---|---|
| llms.txt の公開はコストがほとんどかからず、Wix のようなプラットフォームが今後ますます自動生成してくれるようになります。 | ベースレートは厳しい現実を示しています。既存の llms.txt ファイルの 97% は、いかなる種類の読み手も引きつけていません。 |
| 今回のデータで想定読者に最も近いのはコーディングエージェントです。顧客がコーディングエージェントを利用している場合や、エージェントがサイト上で動作している場合、このファイルが実際に読まれる可能性は十分にあります。 | 現時点では AI 検索における可視性向上には役立ちません。AI 検索取得ボットがこのファイルを取得することはほとんどなく、未公開の llms.txt をどの AI システムも探しに来ることはありません。 |
| 将来への備えとなる可能性があります。Google は検索の未来がエージェント型であることを明言しています。検索取得ボットがページを直接取得するのではなく、エージェントが AI 検索を仲介するようになれば、llms.txt はエージェント層を通じて AI における可視性に影響を及ぼし始める可能性があります。 | 公開するだけでは不十分です。エージェントは指示を受けたときに llms.txt を取得するのであって、推測的にアクセスするわけではないため、どこからもリンクされていないファイルが読み取られる可能性は低いです。 |
| セキュリティリスクがあります。エージェントはこのファイルを信頼するように設計されており、悪意のある攻撃者がすでにプロンプトインジェクションを狙って llms.txt を探査しています。古くなったファイルや改ざんされたファイルは、読み取るすべてのエージェントを誤誘導します。 |
結論としては、現時点ではデメリットがメリットを上回ります。AI 検索に表示されることが目標なら、このファイルよりも確実に可視性を高める方法が他にあります。AI 検索に関する情報も参考にしてください。
それでも llms.txt の作成を検討しているのであれば、以下のステップを踏むことをお勧めします。
- 追加投資の前に自社のログを確認する。 読者ゼロの確率が 97% というのがベースレートです。
- ウェブサイト構築プラットフォームに自動生成させる。 Wix はすでにこのファイルを自動生成しており、Framer や Lovable もスキャン対象としています。1 年以内に、llms.txt の設置はサイトマップと同様に CMS のデフォルト機能になる可能性があります。効果が不確実であれば、労力を最小限に抑えるのが合理的です。
- エージェントをファイルに誘導する。 HTML からリンクを張る、ドキュメント内で参照する、エージェントがサイトに関する指示を受け取る場所で言及するなどの方法があります。エージェントは指示を受けたときに llms.txt を取得するのであって、推測的にアクセスするわけではありません。
- プロンプトインジェクションのリスクを軽減するために llms.txt をコードと同様に扱う。 バージョン管理を行い、編集権限を制限し、不正な変更に対するアラートを設定し、内容はプレーンなリンクと説明文のみに留め(指示的な文言は避ける)、自身が管理するリソースのみにリンクし、プラットフォームが自動生成した内容は必ずレビューしてください。
本調査は、どれだけのサイトが llms.txt を公開しているか、そして誰がそれを読んでいるかという問いに答えるものです。
ただし、本調査の範囲を超えるものの、さらなる調査に値する問いがいくつかあります。
- エージェントは開発者向けドキュメントをより頻繁に取得するのか? ミューラーさんの見解が示唆するように、Claude-Code の llms.txt への関心は /docs/ や /api/ といったドキュメントパスに集中しているのでしょうか?
- ボットは読み取った内容に基づいて実際に行動するのか? AI エージェントが llms.txt を取得した後、そのファイルがリンクしているリソースも取得するのでしょうか? SEO コンサルタントのデイヴィッド・マクスウィーニーさん(Queryburst 創業者)は、まさにこの点に関する実験を行っています。テストサイトで AI ユーザーエージェントに対して圧縮されたエージェント向けサマリーを配信し、より詳細なコンテンツをリクエストするための指示を含めたうえで、実際にエージェントがそれに従うかどうかを追跡しています。マクスウィーニーさんの結果は注目に値します。
ミューラーさんは llms.txt を一時的な「松葉杖」と呼びました。
しかし、その松葉杖にはすでに独自のサプライチェーンが形成されているようです。llms.txt ファイルを自動生成するプラットフォーム、それを監査する業界、そしてそれを研究するセキュリティ研究者。「読み手」が実際に現れる前から、こうしたエコシステムが構築されています。
本物の標準規格の初期段階を目にしているのか、それとも SEO 業界があらゆるものを製品化できることを証明しているのか。おそらく、その両方でしょう。

Ahrefs をもっと活用 👉
▶︎ Ahrefs 公式ブログ — 本社発信の記事
▶︎ Ahrefs Canny — 開発チームへ意見を送る
▶︎ X 公式アカウント— 最新情報をリアルタイムで
▶︎ YouTube 公式チャンネル— 動画コンテンツをチェック
▶︎ Ahrefs note — 日本チーム発信の記事

