These instances of anonymous queries account for 46.08% of all clicks in our study. The study includes one month of data across 146,741 websites and nearly 9 billion total clicks.
Let’s dive in.
First, I want to give a big thanks to Mauricio Fernandez from our backend team for helping me pull this data. Missing is calculated as follows:
(total clicks - sum of clicks to all keywords) / total clicks
This is a scatter plot where each dot represents one of the 146,741 websites. It shows the percentage of clicks that is missing and the overall site traffic.
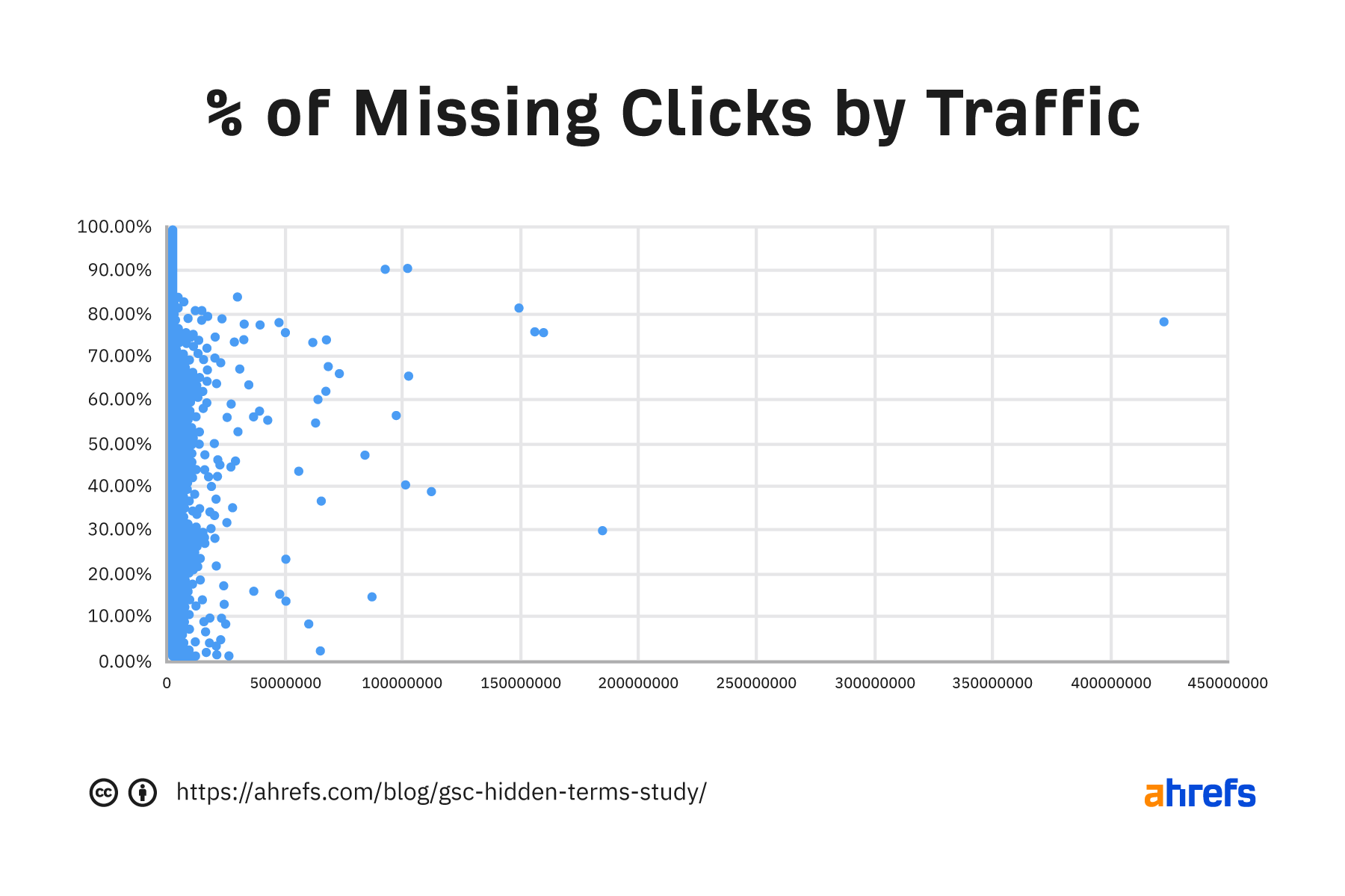
As you can see, some sites have no terms with clicks associated and others have all of their data. Every site is different, and the amount of missing data varies across the dataset.
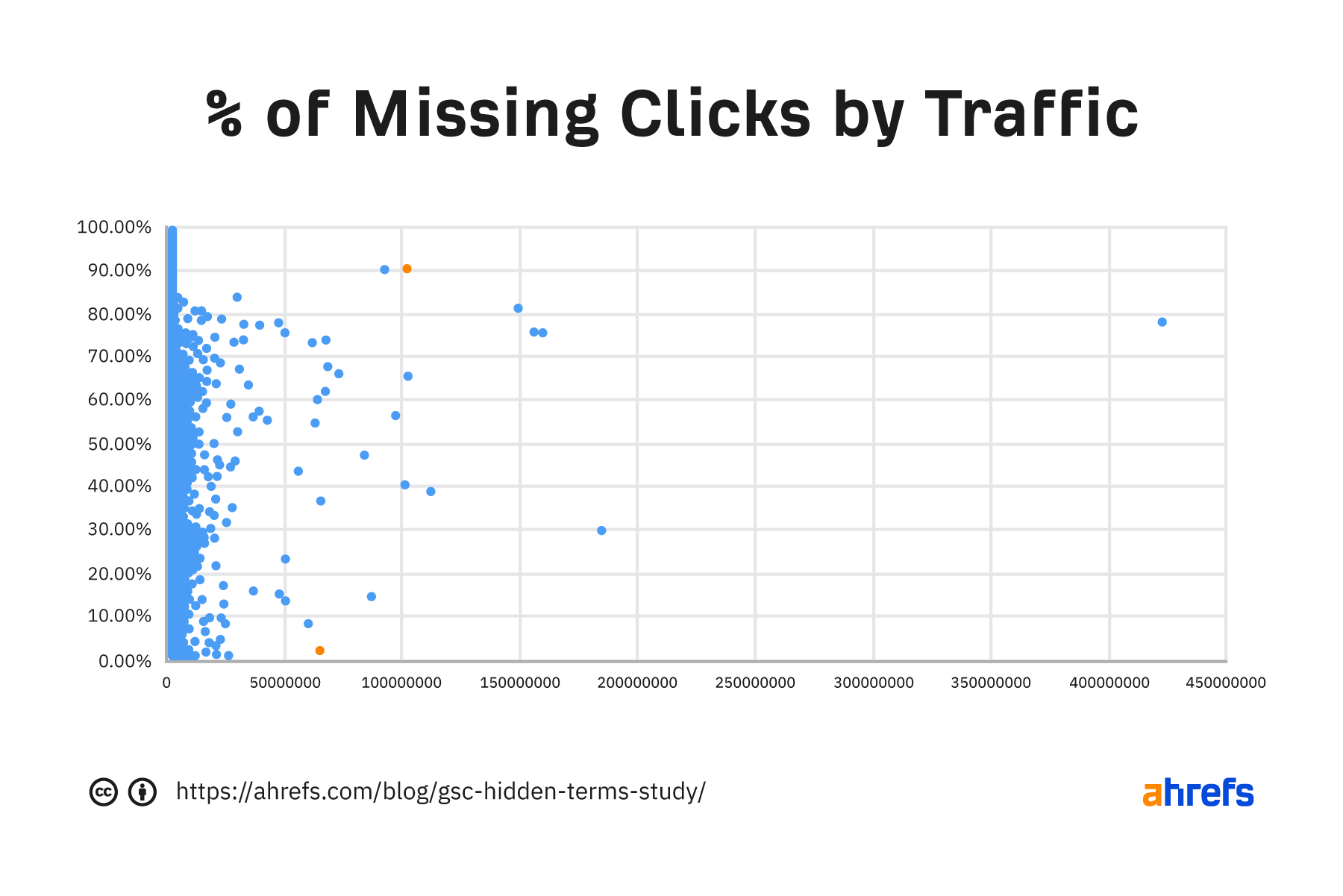
There are a couple of points here I want to talk about because of their significance. There’s a site (1) with 100 million clicks where 90.3% of the data is missing. There’s another site (2) with 63 million clicks that are missing terms for only 2.27% of their clicks. As you can see, the data varies a lot!
Another way to show how much the missing click data varies is to look at the distribution of how much data is missing across the dataset. There are lots of sites in every single bucket. You’ll have a tough time guessing how much data is missing from any one site.
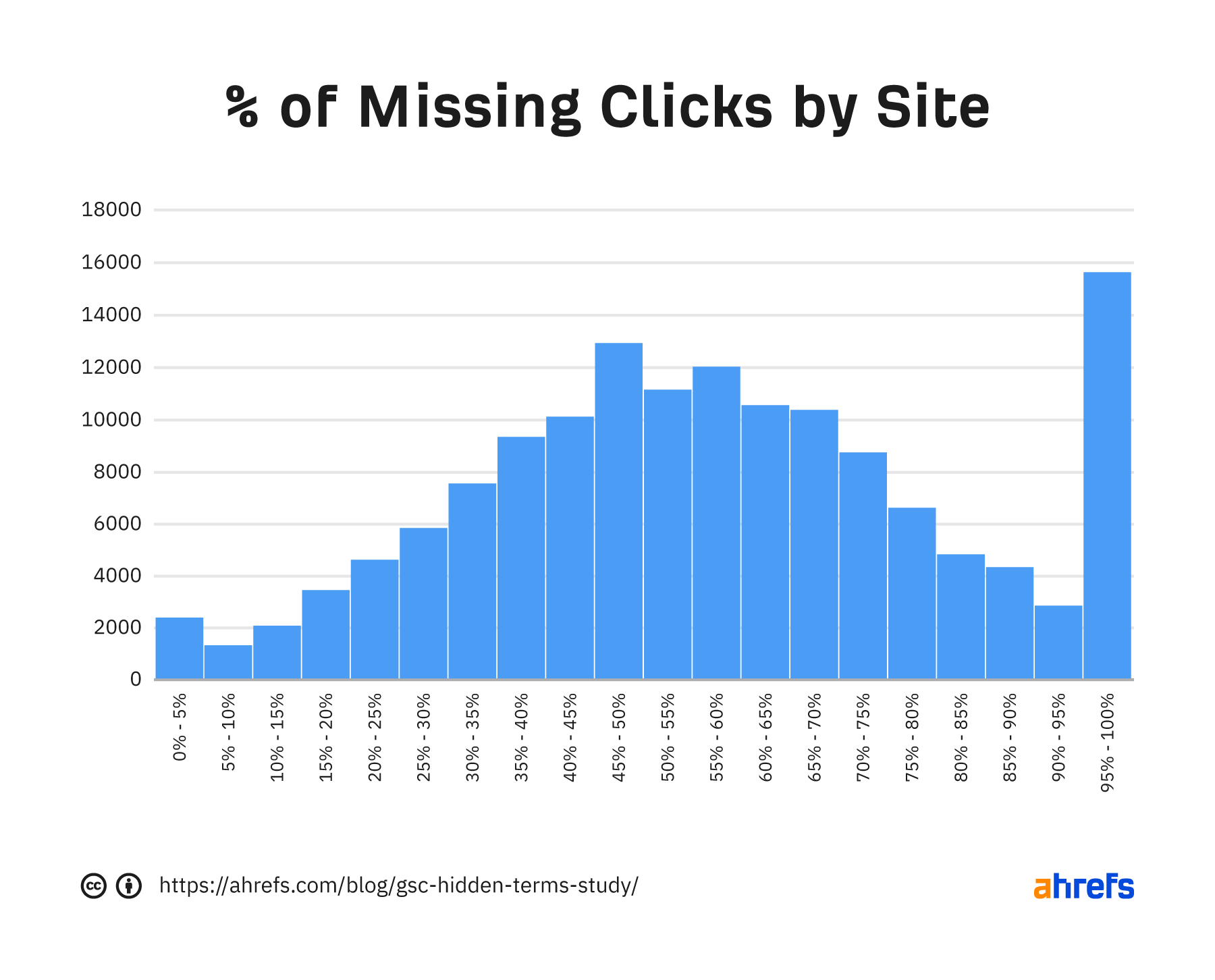
You see lots of sites around the middle and a large spike at 95%-100% missing clicks. So many of the sites are missing about half their data, but a large number of sites are missing most of the data.
What I think may be interesting is to bucket the sites by the traffic they receive. In the box plot below, you’ll see that both low-traffic and high-traffic sites tend to be missing more of the data. Sites in the middle buckets tend to have less missing data.
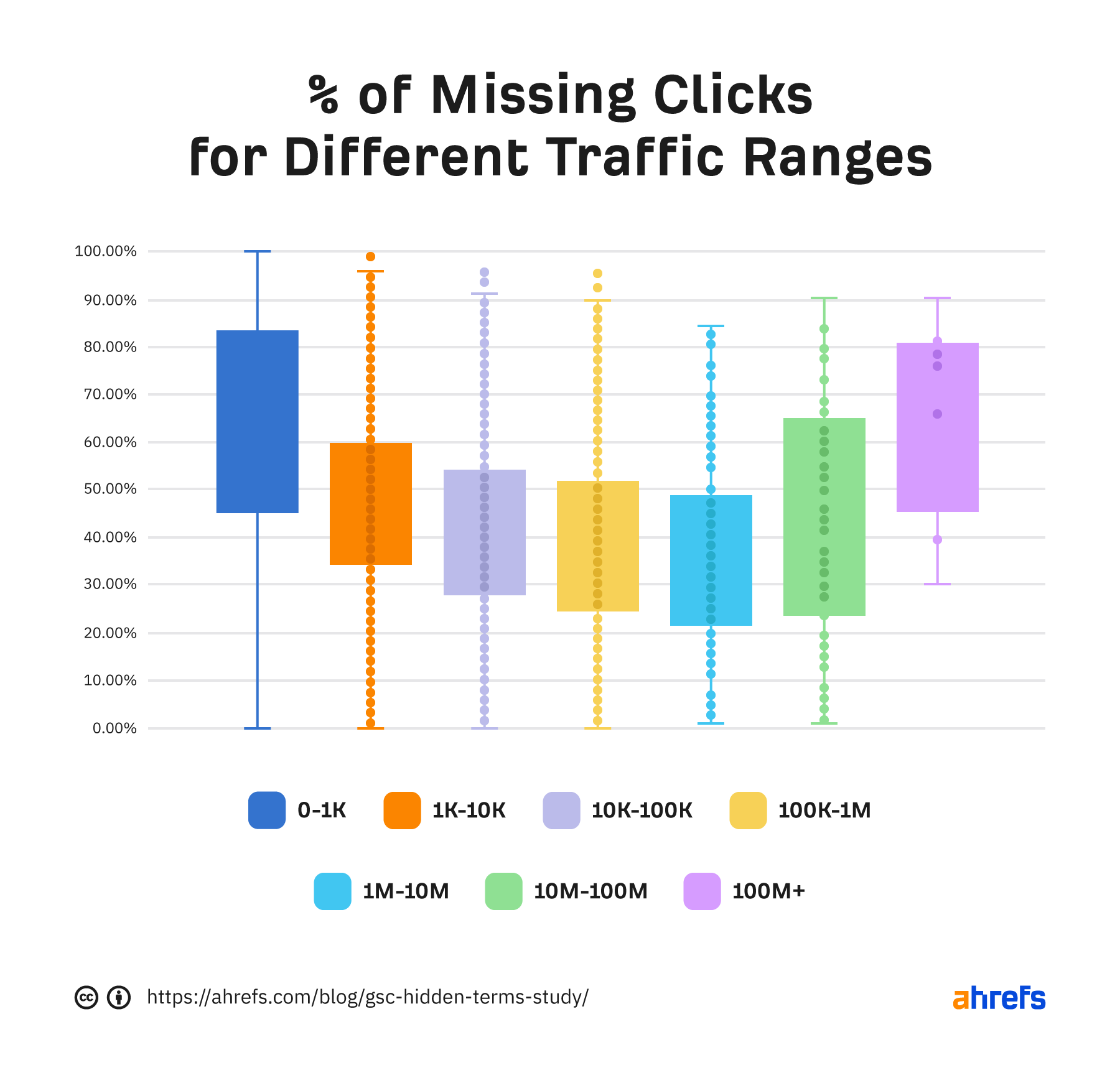
The data generally gets better with more traffic. But after 10 million or so clicks, the data starts to get considerably worse.
In case you’re seeing box plots for the first time, here’s how you should read them:
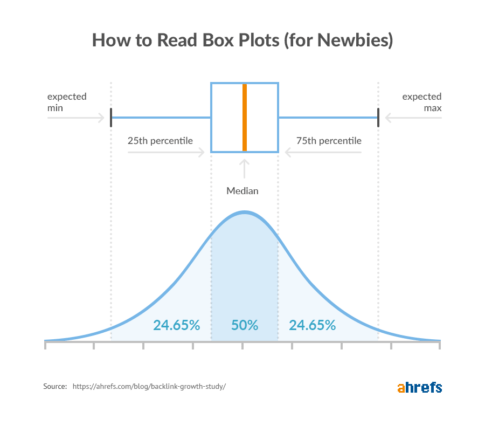
The small lines on the edges represent the minimum and maximum values. And 50% of all values fall in the highlighted areas. The line in that area is the median value.
At this point, you may think we’ve made a mistake with the data. That we totaled up only the 1,000 rows shown in the GSC interface that are exportable to get the data, and that’s why so much is missing.
But that’s not the case. We pulled this data via the API, which allows us to get all of the data—and there’s still a lot missing!
I know everyone’s main concern is going to be how much data is missing from their own site, so I want to provide you with a way to check this. The easiest way to see how many clicks go to terms Google doesn’t show you is to use the GSC connector in Google Data Studio.
I made a Data Studio report that you can copy to check the missing data for your own website. This uses data for the last 12 months. About half the data is missing for my personal site at the time of writing.

Make your own copy of the report and add your GSC data as a source. Here’s how:
- In the top right, click the three dots and then click “Make a copy.”
- In the dropdown for “New Data Source,” select the GSC data source for the site you’re interested in.
- If the site isn’t available, select “Create data source.” Search for “Search Console” and click it.
- Click the GSC property you want to use > click “Site Impression” > click “Web.” Then in the upper-right corner, click “Connect.”
- In the upper-right corner, click “Add To Report.”
- Click “Copy Report.”
I’d love some self-reported user data for this. If you want to share, tweet your “Grand total” numbers from #1 and #2 to @patrickstox and @ahrefs. Or just PM me on Twitter, and I’ll aggregate the self-reported data to share here at a later date. I suspect most of the user-reported data corroborates with the data from the study that shows the amount missing varies across sites.
Google gives a few reasons for this discrepancy:
To protect user privacy, the Performance report doesn’t show all data. For example, we might not track some queries that are made a very small number of times or those that contain personal or sensitive information.
I don’t believe for a second that nearly half of the searches to all of these sites were private. That leaves the reason that some of the queries are being made a small number of times—often called long-tail keywords. Google may have understated that just a bit. At any rate, 46.08% missing is way higher than I expected.
We know that 15% of all Google searches have never been seen before. I’m sure Google stores these queries. Otherwise, it won’t be able to come up with that statistic.
However, I’d speculate that the team behind GSC has limited resources, and it doesn’t bother to store or expose all of the data. It’s just the extent of the data that’s missing is surprising to me and may come as a shock to you.
Final thoughts
You can figure out the kinds of terms that drive traffic to a page by using the Performance report in GSC or by checking the Organic keywords report in Ahrefs’ Site Explorer. The anonymous queries in GSC likely includes terms that are similar to the terms listed here.
For example, Google is missing data on 35% of the clicks for our post on keyword research. In the U.S., there are 327 terms listed in GSC and 426 in Ahrefs.
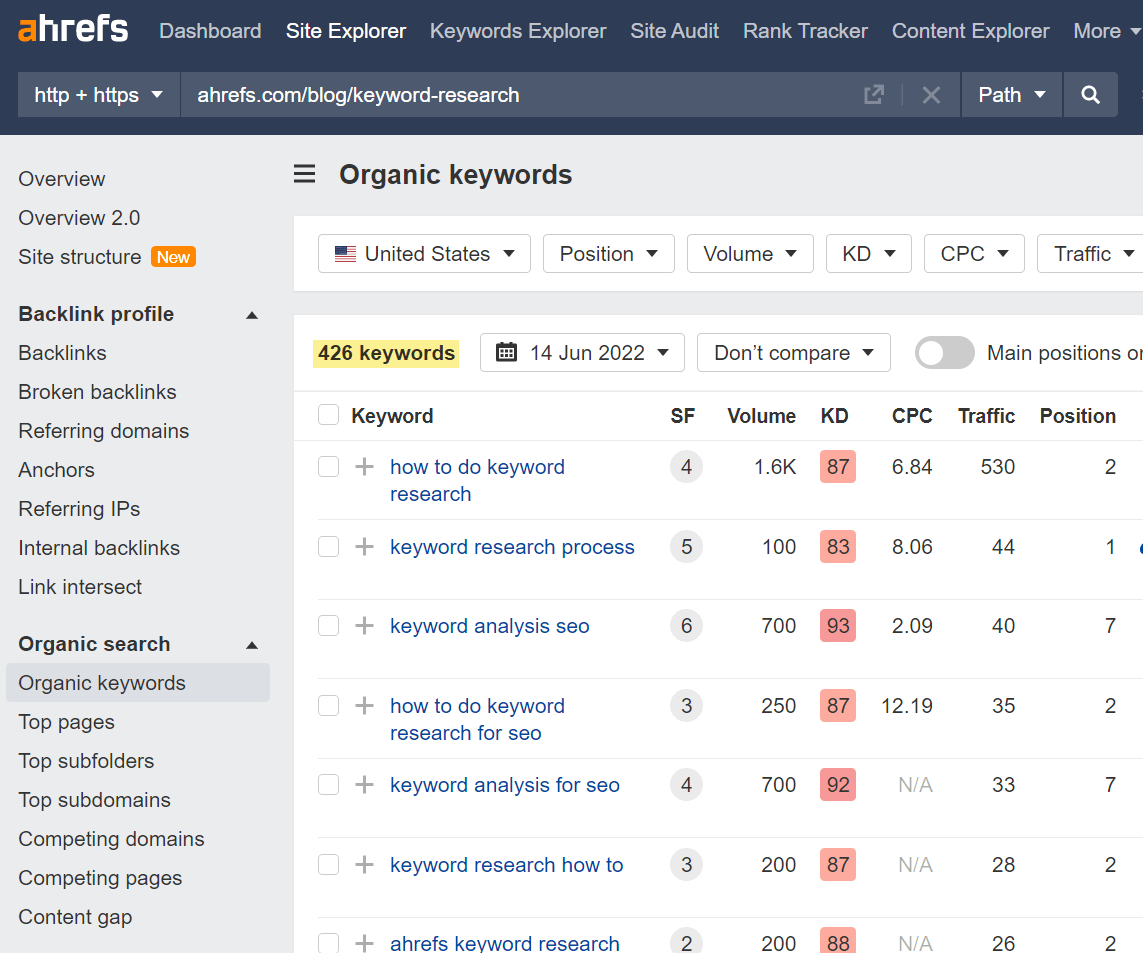
In all, 178 of these are duplicated in the datasets, but that leaves a number of unique terms in each dataset. While we can’t say for sure what the missing terms are, they’re likely similar to the terms included in these reports.
Message me on Twitter if you have any questions.