Comme l’a dit Bernard Huang, pendant sa prise de parole lors de l’Ahrefs Evolve, “LLMs are the first realistic search alternative to Google.” :
« Les LLMs sont la première alternative crédible à Google pour la recherche. »
Les projections de marché vont dans le même sens :
- Le marché mondial des LLM devrait augmenter de 36 % entre 2024 et 2030
- La croissance des chatbots devrait atteindre 23 % d’ici 2030
- Gartner prévoit que 50 % du trafic des moteurs de recherche aura disparu d’ici 2028
Vous pouvez vous plaindre que les chatbots IA réduisent votre part de trafic ou s’approprient votre propriété intellectuelle. Ce ne serait pas faux.
Mais dans tous les cas, très bientôt, vous ne pourrez plus les ignorer.
Comme aux débuts du SEO, je pense qu’on s’apprête à entrer dans une sorte de Far West, où les marques vont tout faire pour s’imposer dans les LLM, par tous les moyens.
Et pour équilibrer, je m’attends aussi à voir certains acteurs légitimes, arrivés tôt, rafler la mise.
Apprenez à intégrer les conversations IA juste à temps pour la ruée vers l’or du LLMO grâce à ce guide SEO x IA.
Comprendre rapidement le LLMO
L’optimisation pour les LLM (ChatGPT, Perplexity, Claude, Mistral AI…) consiste à préparer l’« univers » de votre marque (votre positionnement, vos produits, vos équipes et les informations qui l’entourent) pour obtenir des mentions dans un LLM.
Je parle de mentions textuelles, de liens, et même de l’intégration native de votre contenu de marque (par exemple des citations, des statistiques, des vidéos ou des visuels).
Petit lexique du LLMO
LLMO (Large Language Model Optimization)
Ensemble des pratiques visant à influencer la visibilité, les mentions et les recommandations d’une marque dans les réponses des LLM.
LLM (Large Language Model)
Modèle d’IA entraîné sur de vastes volumes de données textuelles pour comprendre le langage et générer des réponses (ex. ChatGPT, Gemini).
GEO / AEO / AISO (termes proches, souvent interchangeables)
Optimisation des contenus pour apparaître dans les réponses générées par l’IA, plutôt que dans une liste classique de résultats.
- GEO (Generative Engine Optimization) : focalisé sur les moteurs génératifs.
- AEO (Answer Engine Optimization) : centré sur les réponses directes aux questions.
- AISO (AI Search Optimization) : terme générique englobant les deux.
Mentions
Références à une marque, un produit ou une entité dans une réponse générée par un LLM, avec ou sans lien.
Citations
Mentions accompagnées d’une source identifiable (site, marque, URL), utilisées par le LLM pour appuyer ou justifier une réponse.
Part de voix IA (AI Share of Voice)
Part relative de visibilité d’une marque dans les réponses des LLM, comparée à celle de ses concurrents sur un ensemble de requêtes.
Exemple pour comprendre le LLMO
On va voir un exemple concret.
Quand j’ai demandé à Perplexity « Qu’est ce qu’un assistant de rédaction IA », la réponse du chatbot sourcait explicitement Ahrefs avec 4 liens au-dessus de la ligne de flottaison.
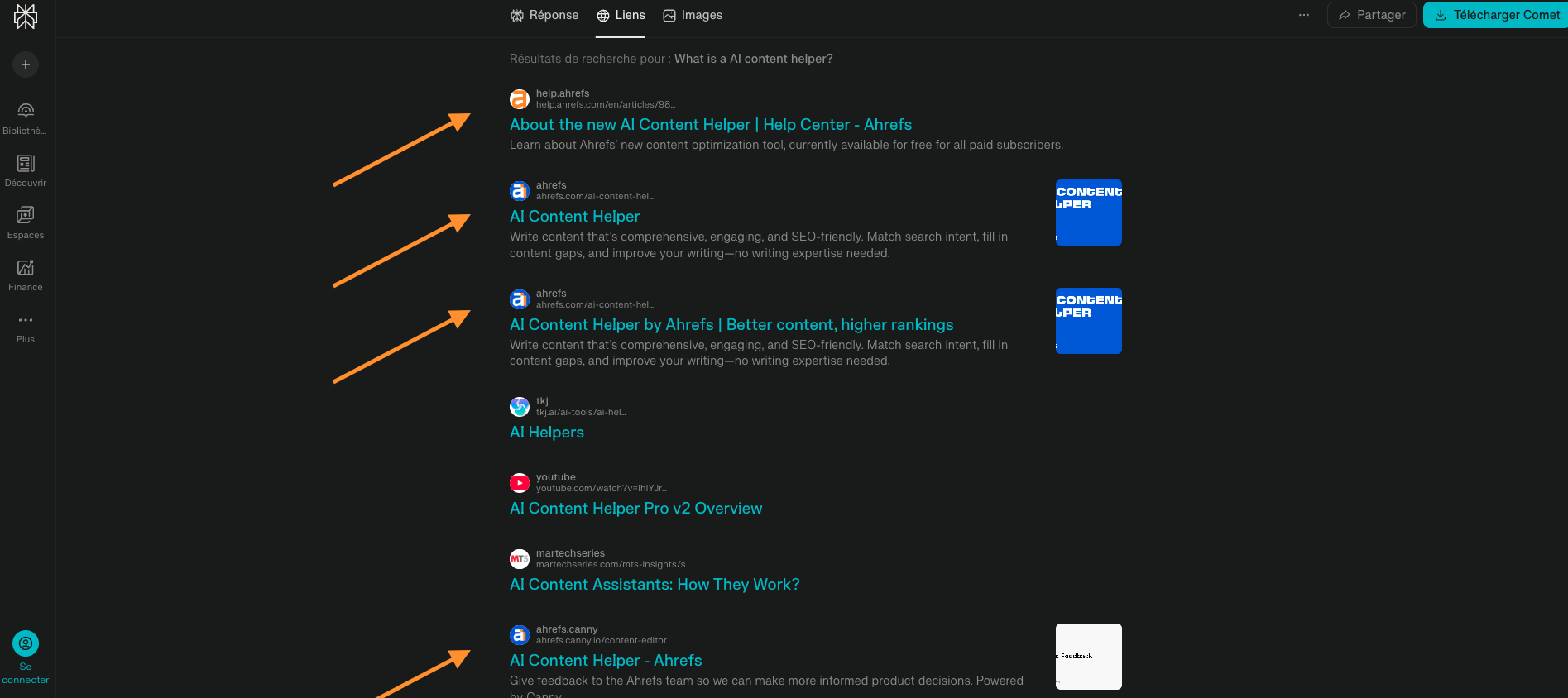
Attention à ne pas confondre LLM et AI Overviews, même si c’est effectivement lié.
Voyez le LLMO comme un nouveau type de SEO. Les marques cherchent activement à optimiser leur visibilité dans les LLM, comme elles le font déjà dans les moteurs de recherche.
En réalité, le marketing LLM pourrait devenir une discipline à part entière. Harvard Business Review va même jusqu’à dire que les SEOs seront bientôt appelés des LLMOs.
Les LLM comme ChatGPT ne se contentent pas de fournir des informations sur les marques, ils les recommandent.
Comme un conseiller de vente ou un personal shopper, ils influencent même les utilisateurs à sortir leur carte bancaire.
Si les gens utilisent les chatbot IA pour obtenir des réponses et acheter, votre marque doit apparaître.
Mais c’est loin d’être la seule raison pour laquelle vous devez suivre cette tendance.
Voici les avantages clés à investir dans le LLMO :
- Vous pérennisez la visibilité de votre marque.
Les LLM ne vont pas disparaître. Ils deviennent un nouveau canal majeur pour développer la notoriété. - Vous bénéficiez d’un avantage de premier entrant (si vous agissez vite).
- Vous occupez davantage d’espace en liens et en citations, ce qui laisse moins de place à vos concurrents.
- Vous vous intégrez à des conversations clients pertinentes et personnalisées.
- Vous augmentez vos chances que votre marque soit recommandée dans des conversations à forte intention d’achat.
- Vous générez du trafic de recommandation depuis les chatbots vers votre site.
- Vous améliorez votre visibilité dans la recherche par ricochet.
- Le trafic venant des LLM ont un meilleur taux de conversion que les moteurs de recherche.
Le LLMO et le SEO sont étroitement liés
Les LLM RAG : c’est quoi?
La plupart des chatbots qui s’appuient sur des LLM sont des LLM RAG, pour « retrieval augmented generation », qui récupèrent des informations en direct sur internet en temps réel (par exemple Gemini).
Les LLM qui récupèrent des informations en direct peuvent citer leurs sources avec des liens et envoyer du trafic de recommandation vers votre site, ce qui améliore votre visibilité organique.
Des rapports récents montrent que Perplexity envoie même du trafic vers des publications qui essaient de le bloquer.
Comment suivre le trafic provenant des chatbots IA facilement ?
Trouver la part de votre trafic qui provient des LLM comme ChatGPT est simple et gratuit :
- Utiliser Ahrefs Webanalytics, l’alternative gratuite à Google Analytics
- Dans la vue d’ensemble, scrollez jusqu’aux sources de trafic
- Cliquez sur “Recherches basées sur l’IA”
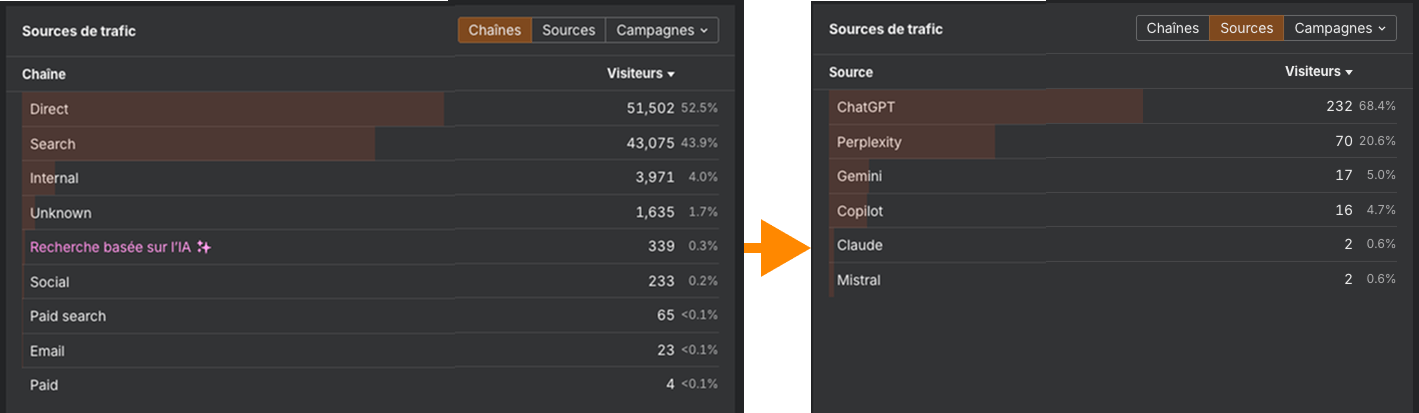
Pas besoin de regex, juste de 2 clics.
[ahrefs-web-analytics-alternative-google-analytics-geo]Les LLM peuvent améliorer votre trafic et votre SEO.
Mais, inversement, votre SEO a aussi le potentiel d’améliorer la visibilité de votre marque dans les LLM.
La mise en avant d’un contenu dans l’entraînement des LLM est influencée par sa pertinence et sa découvrabilité.
LLMO vs SEO : tableau comparatif
Le SEO vous place dans une liste. Le LLMO vous place dans une conversation.
Deux jeux de règles, deux façons de gagner et une belle zone en commun au milieu.
réussir une double strat’
| Dimension | SEO (recherche “classique”) | LLMO (LLMs / moteurs génératifs) |
|---|---|---|
| Objectif | Être classé et obtenir des clics depuis la SERP. | Être mentionné / cité / recommandé dans une réponse IA, avec ou sans clic. |
| Surface de visibilité | Résultats organiques, featured snippets, PAA, images, etc. | Réponses générées (ChatGPT, Perplexity, Gemini…), AI Overviews, citations intégrées. |
| Unité de “ranking” | Une page se positionne sur une requête. | Une entité (marque/personne/produit) s’impose dans un contexte. |
| Ce qui “compte” le plus | Pertinence requête ↔ contenu, qualité on-page, autorité, signaux techniques. | Crédibilité (sources, stats, preuves) Représentation (exactitude de la marque) Disponibilité (être trouvable/citable quand l’IA cherche) |
| Formats qui performent | Pages optimisées (guides, catégories, landing pages, FAQ). | Contenus “citables” : définitions nettes, données propriétaires, comparatifs, FAQs, prises de position sourcées. |
| Off-page | Backlinks, ancres, mentions, PR, E-E-A-T indirect. | Mentions + co-citations + PR + UGC (forums) : tout ce qui renforce l’association marque ↔ sujet. |
| Technique | Crawl, indexation, perf, structure interne, canonical, etc. | HTML accessible, pages stables, info facile à extraire ; “aidons l’IA à lire vite et bien”. |
| Mesure (KPI) |
|
|
| Volatilité | Élevée, mais avec des patterns connus (updates, concurrence, intent). | Très élevée : réponses non déterministes + sources variables + prompts infinis. |
| Horizon d’impact | Souvent progressif, cumulatif (mois). | Mix : quick wins possibles, mais le vrai gain vient d’un travail “marque + sources + cohérence”. |
| Conclusion pratique | Le meilleur move : garder votre SEO solide et ajouter une couche LLMO. On ne remplace pas, on empile. | |
L’optimisation LLM est un domaine très récent et nos recherches sont encore en cours.
Cela dit, j’ai identifié plusieurs stratégies et de techniques qui, selon les études disponibles, ont le potentiel d’augmenter la visibilité de votre marque dans les LLM.
Les voici, sans ordre particulier :
Les LLM interprètent le sens en analysant la proximité entre les mots et les expressions.
J’ai vulgarisé le process d’interprétation des LLM :
- Les LLM prennent les mots présents dans les données d’entraînement et les transforment en tokens. Ces tokens peuvent représenter des mots, mais aussi des fragments de mots, des espaces ou de la ponctuation.
- Ils traduisent ensuite ces tokens en embeddings, c’est-à-dire des représentations numériques.
- Puis, ils positionnent ces embeddings dans un « espace » sémantique.
- Enfin, ils calculent l’angle de « similarité cosinus » entre les embeddings dans cet espace afin d’évaluer leur proximité ou leur distance sémantique, et ainsi comprendre leur relation.
Je vous ai perdu ?
Attendez, ne partez pas encore, je vous explique avec un exemple et des images :
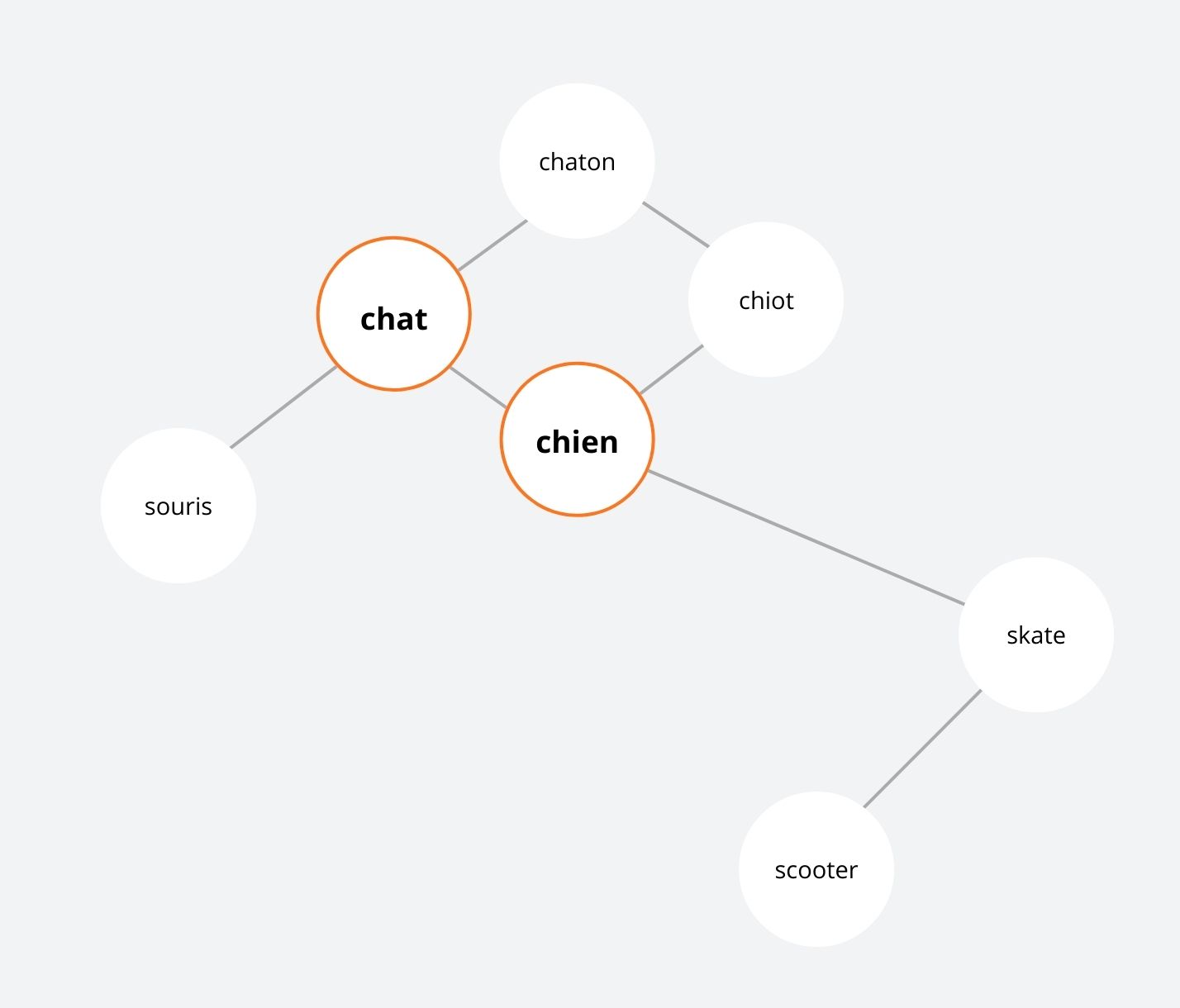
LLMO et clusters thématiques : l’exemple des animaux
Imaginez le fonctionnement interne d’un LLM comme une carte de clusters / cocons. Les sujets thématiquement proches, comme « chien » et « chat », sont regroupés, tandis que ceux qui ne le sont pas, comme « chien » et « skateboard », sont plus éloignés.
LLMO et relations presses : l’exemple des chaises ergonomiques
Lorsque vous demandez à Claude quelles chaises sont adaptées pour améliorer la posture, il recommande les marques Herman Miller, Steelcase Gesture et Humanscale.
C’est parce que ces entités de marque présentent la proximité mesurable la plus forte avec le sujet « amélioration de la posture ».

Pour être mentionné dans des recommandations de produits LLM similaires, à forte valeur commerciale, vous devez créer des associations solides entre votre marque et les sujets associés.
> Investir dans les relations presses peut vous y aider.
Rien que l’année dernière, Herman Miller a obtenu 273 pages de mentions presse liées au terme « ergonomique » dans des médias comme Yahoo, CBS, CNET, The Independent et Tech Radar.
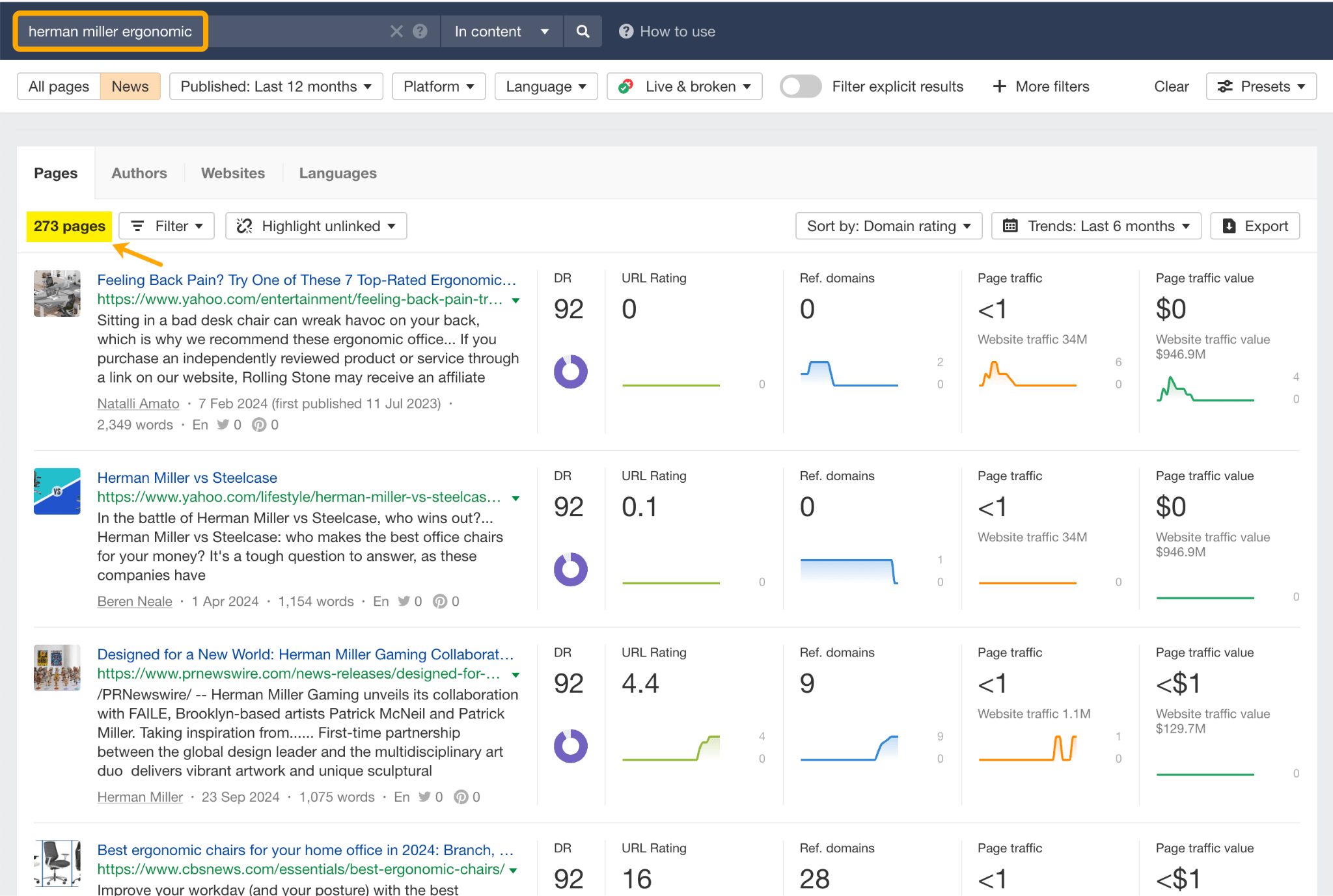
Une partie de cette notoriété thématique a été générée de manière organique, par exemple via des avis :
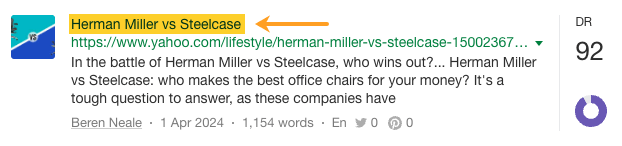
Une autre provient des initiatives PR propres à Herman Miller, comme des communiqués de presse…
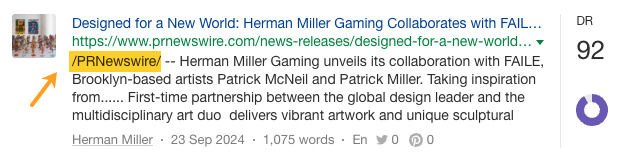
… ainsi que de campagnes de PR orientées produit…
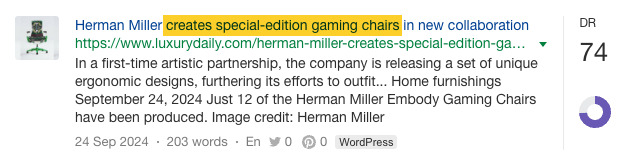
Certaines mentions sont issues de programmes d’affiliation payants…

Et d’autres de partenariats sponsorisés…
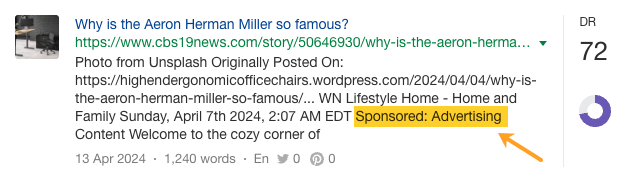
On récapitule les 7 leviers de la stratégie LLMO de Herman Miller pour être cité en premier par Claude :
- Générer beaucoup retombées dans des grands médias
- Inciter les utilisateurs à laisser des avis
- Écrire des communiqués de presse régulièrement
- Communiquer sur les nouveautés produit via des contenus pour les médias
- Lancer des campagnes d’affiliation
- Mener des partenariats rémunérés dans leur secteur
Toutes ces approches sont des stratégies légitimes pour renforcer la pertinence thématique et améliorer vos chances de visibilité dans les LLM.
Si vous investissez dans une campagne RP pilotée par sujets, assurez-vous de suivre votre part de voix, vos mentions web et vos liens pour les thématiques clés qui vous importent, par exemple « ergonomie ».
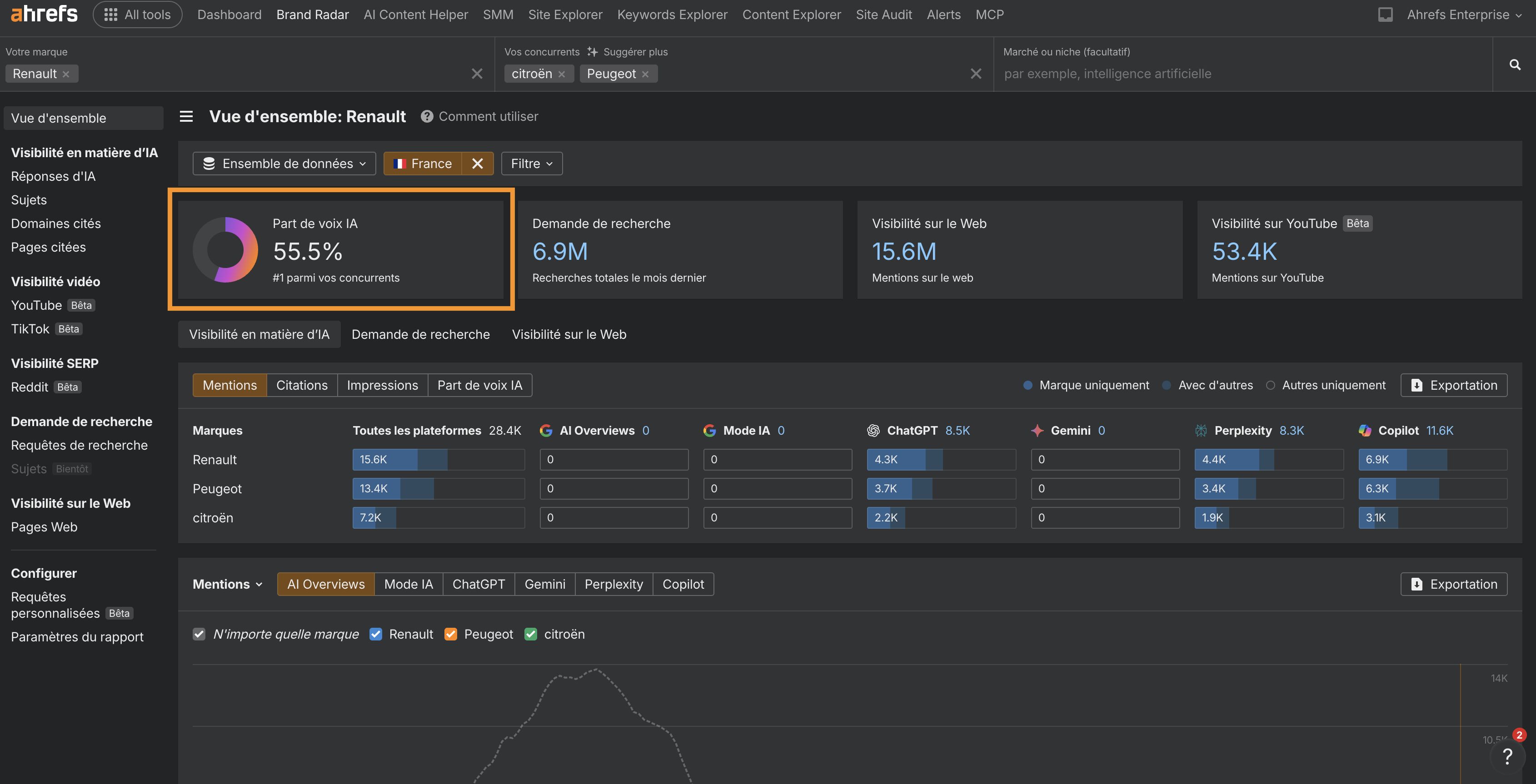
Cela vous aidera à identifier précisément les actions RP les plus efficaces pour augmenter la visibilité de votre marque.
Vous pouvez suivre la progression de vos indicateurs liés aux IA grâce à Brand Radar :
- mentions web
- trafic issu des mentions
- votre part de marché
- Si vous apparaissez dans les AI overviews
On va y revenir un peu plus bas.
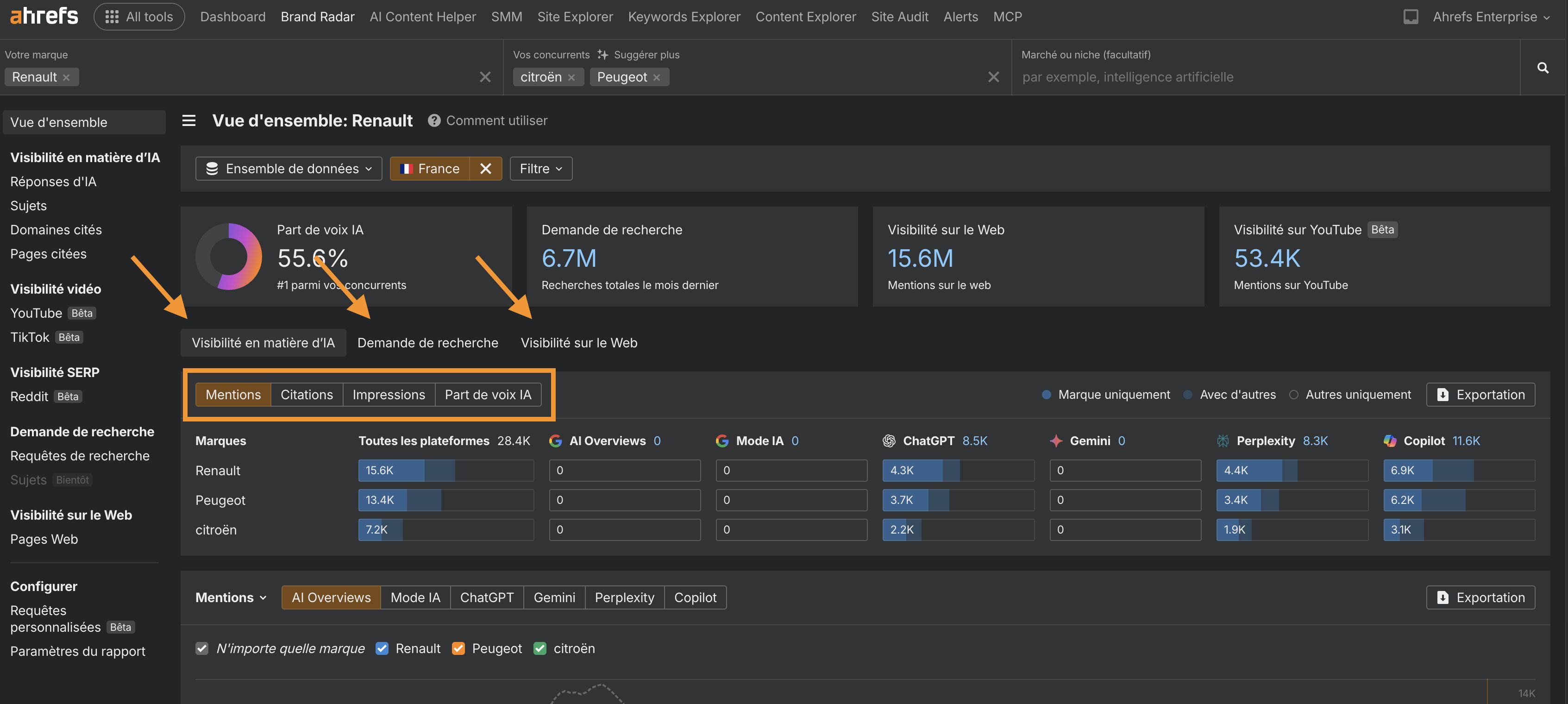
En parallèle, continuez à tester les LLM avec des questions liées à vos thématiques prioritaires et notez toute nouvelle association de sujets.
Si vos concurrents sont déjà cités par l’IA sur des requêtes pertinentes où vous n’apparaissez pas, vous devrez analyser leurs mentions et réaliser une analyse concurrentielle des écarts.
Vous pourrez ainsi comprendre leur visibilité, définir des KPI concrets à atteindre (par exemple le nombre de mentions pour le sujet X) et comparer vos performances aux leurs.
Je vous explique comment trouver ses écarts de contenu dans les IA ici.
J’en ai parlé plus tôt, certains chatbots peuvent se connecter aux résultats web et les citer. Ce processus est appelé RAG, pour « retrieval augmented generation ».
Récemment, un groupe de chercheurs en IA a mené une étude portant sur 10 000 requêtes réelles issues des moteurs de recherche (sur Bing et Google), afin d’identifier les techniques les plus susceptibles d’augmenter la visibilité dans des chatbots RAG comme Perplexity ou BingChat.
Pour chaque requête, ils ont sélectionné aléatoirement un site web à optimiser, puis testé :
- différents types de contenus :
- citations,
- termes techniques
- statistiques…
- différentes caractéristiques :
- fluidité,
- compréhension
- ton d’autorité…
Voici leurs résultats :
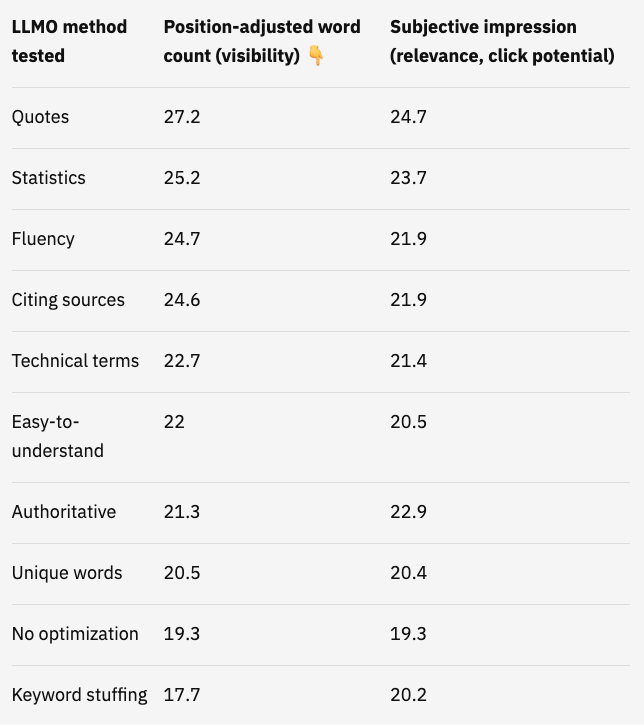
Les sites qui incluent des citations, des statistiques et des sources étaient les plus fréquemment référencés par ChatGPT et les autres LLMs enrichis par la recherche. Ils ont enregistré une augmentation de 30 à 40 % du « Position adjusted word count », autrement dit de la visibilité, dans les réponses des LLM.
Ces trois éléments ont un point commun essentiel. Ils renforcent l’autorité et la crédibilité d’une marque. Ce sont aussi des types de contenus qui ont tendance à générer des backlinks.
Les LLM apprennent à partir d’un large éventail de sources en ligne. Si une citation ou une statistique est régulièrement mentionnée, un LLM va très probablement la partager plus souvent dans ses réponses.
Alors, si vous voulez que le contenu de votre marque apparaisse dans les LLM, complétez le avec avec
- des citations pertinentes
- des statistiques propriétaires
- des sources fiables

Et gardez ce contenu court et synthétique. J’ai constaté que la plupart des LLM ne fournissent généralement qu’une ou deux phrases de citations ou de statistiques.
Avant d’aller plus loin, il faut absolument que je salue 2 professionnels du SEO exceptionnels rencontrés lors de notre événement Ahrefs Evolve, qui ont inspiré cette recommandation : Bernard Huang et Aleyda Solis.
On a déjà compris que les LLM se concentrent sur les relations entre les mots et les expressions pour prédire leurs réponses.
Pour s’aligner avec cette logique, vous devez dépasser la simple approche par mots-clés isolés et analyser votre marque à travers le prisme de ses entités.
Analyser comment les LLM perçoivent votre marque
Vous pouvez auditer les entités (personnes, marques, concepts, produits…) associées à votre marque afin de mieux comprendre comment les LLM la perçoivent.
Pendant Ahrefs Evolve, Bernard Huang, fondateur de Clearscope, a présenté une méthode efficace pour analyser vos entités sur les GSE (chatGPT, Mistral AI…).
Il a essentiellement reproduit le processus qu’utilise le LLM de Google pour comprendre et classer les contenus.
Pour commencer, il a établi que Google s’appuie sur « les 3 piliers du ranking » pour prioriser les contenus : le texte principal (body), le texte d’ancrage et les données d’interaction utilisateur.

Ensuite, à partir des données issues du Google Leak, il a émis l’hypothèse que Google identifie les entités de la manière suivante :
- Analyse on-page : durant le processus de classement, Google utilise le traitement du langage naturel (NLP) pour identifier les thématiques, ou « page embeddings », présentes dans le contenu d’une page. Bernard estime que ces embeddings aident Google à mieux comprendre les entités.
- Analyse au niveau du site : au cours de ce même processus, Google collecte des données sur le site. Là encore, Bernard pense que ces données alimentent la compréhension des entités par Google. Ces données incluent :
- Les embeddings de site : les thématiques reconnues à l’échelle de l’ensemble du site.
- Le score de focus du site : un indicateur du niveau de concentration du site sur un sujet spécifique.
- Le rayon du site : une mesure de l’écart entre les thématiques des pages individuelles et les thématiques globales du site.
Pour reproduire le mode d’analyse de Google, Bernard a utilisé l’API Natural Language de Google afin d’identifier les page embeddings, ou potentielles « entités au niveau de la page », présentes dans un article d’iPullRank.
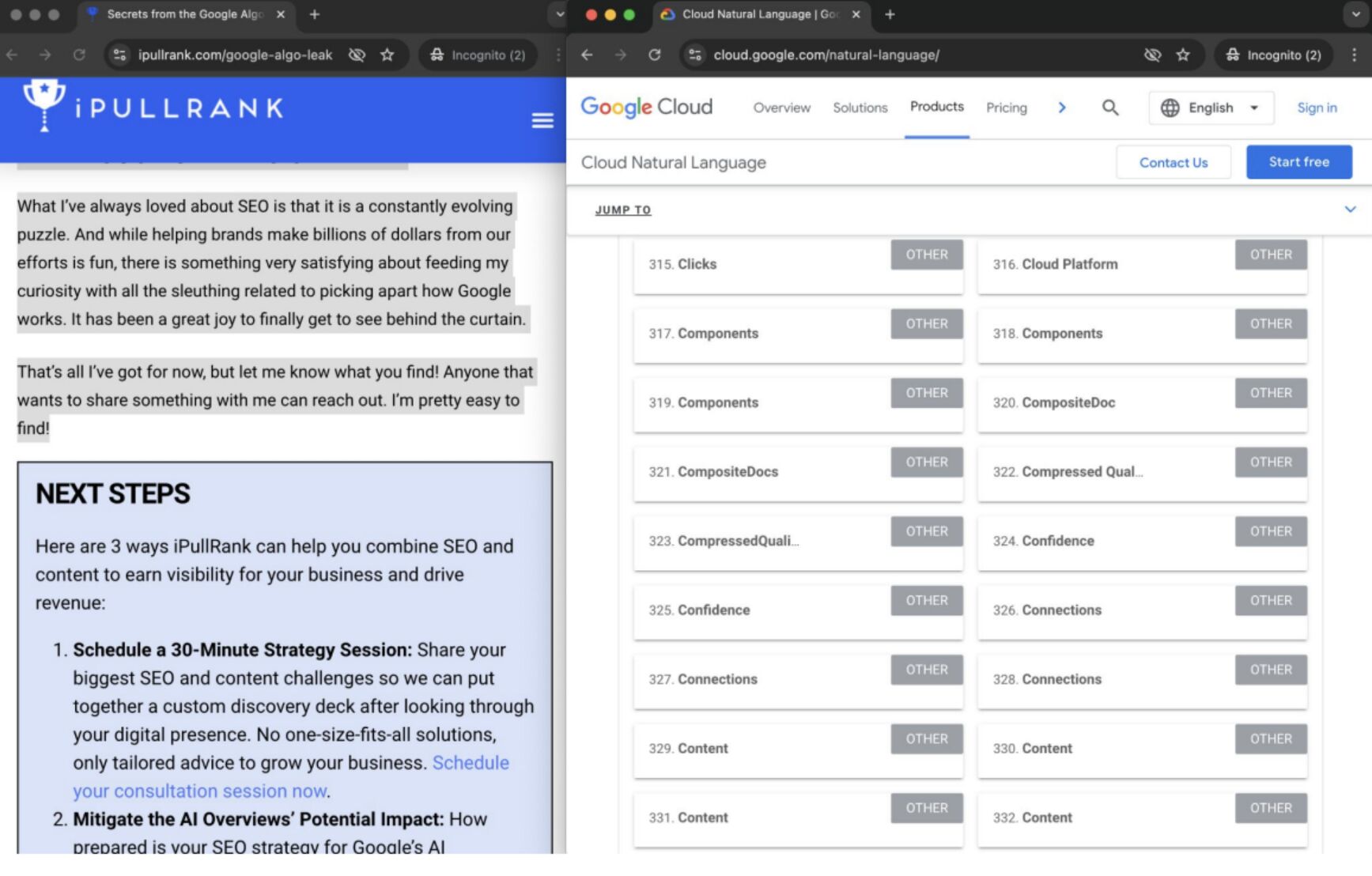
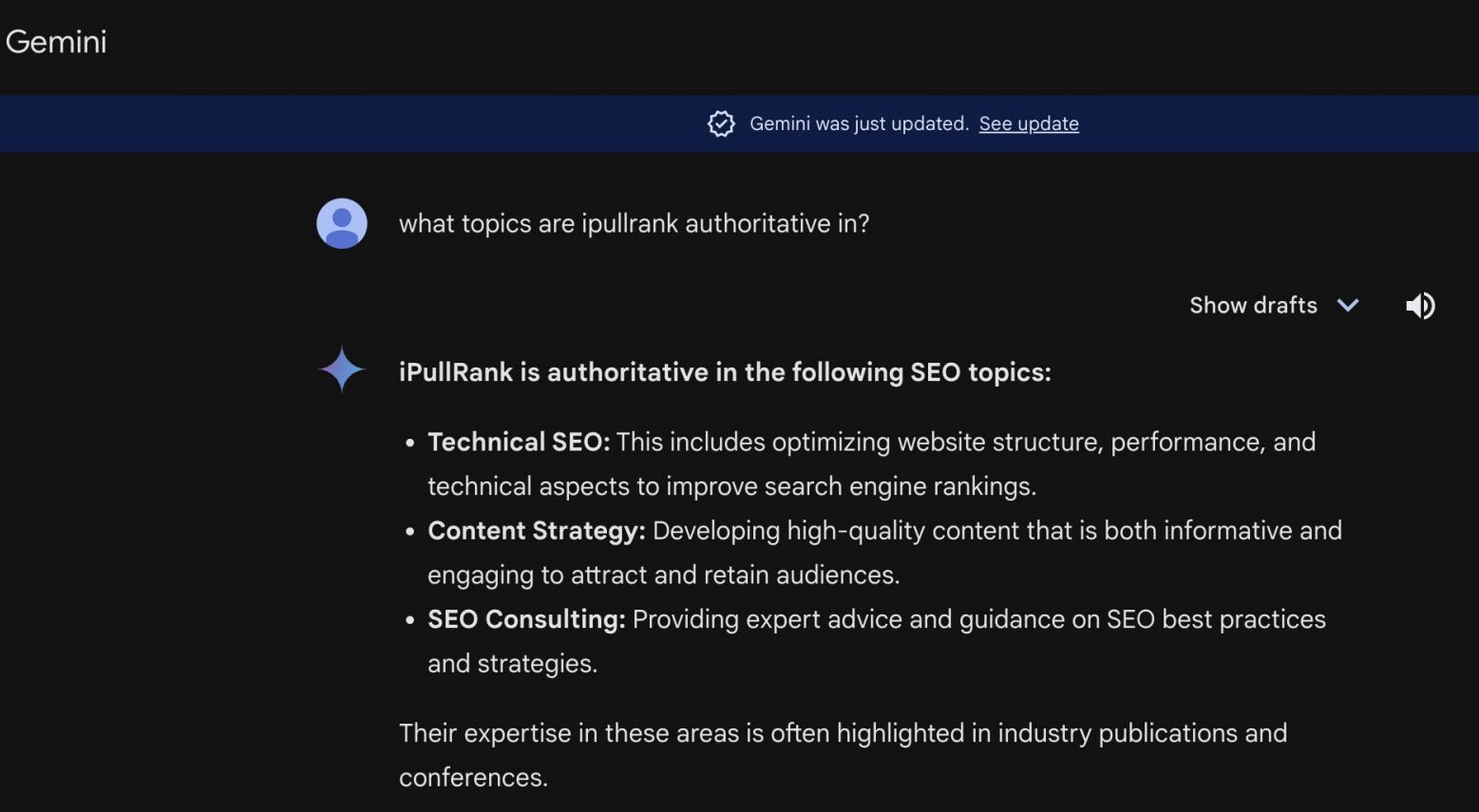
Il s’est ensuite tourné vers Gemini et a posé la question : « Sur quels sujets iPullRank est-il perçu comme faisant autorité ? », afin de mieux comprendre le focus d’entités au niveau du site et d’évaluer le degré d’alignement entre la marque et son contenu.
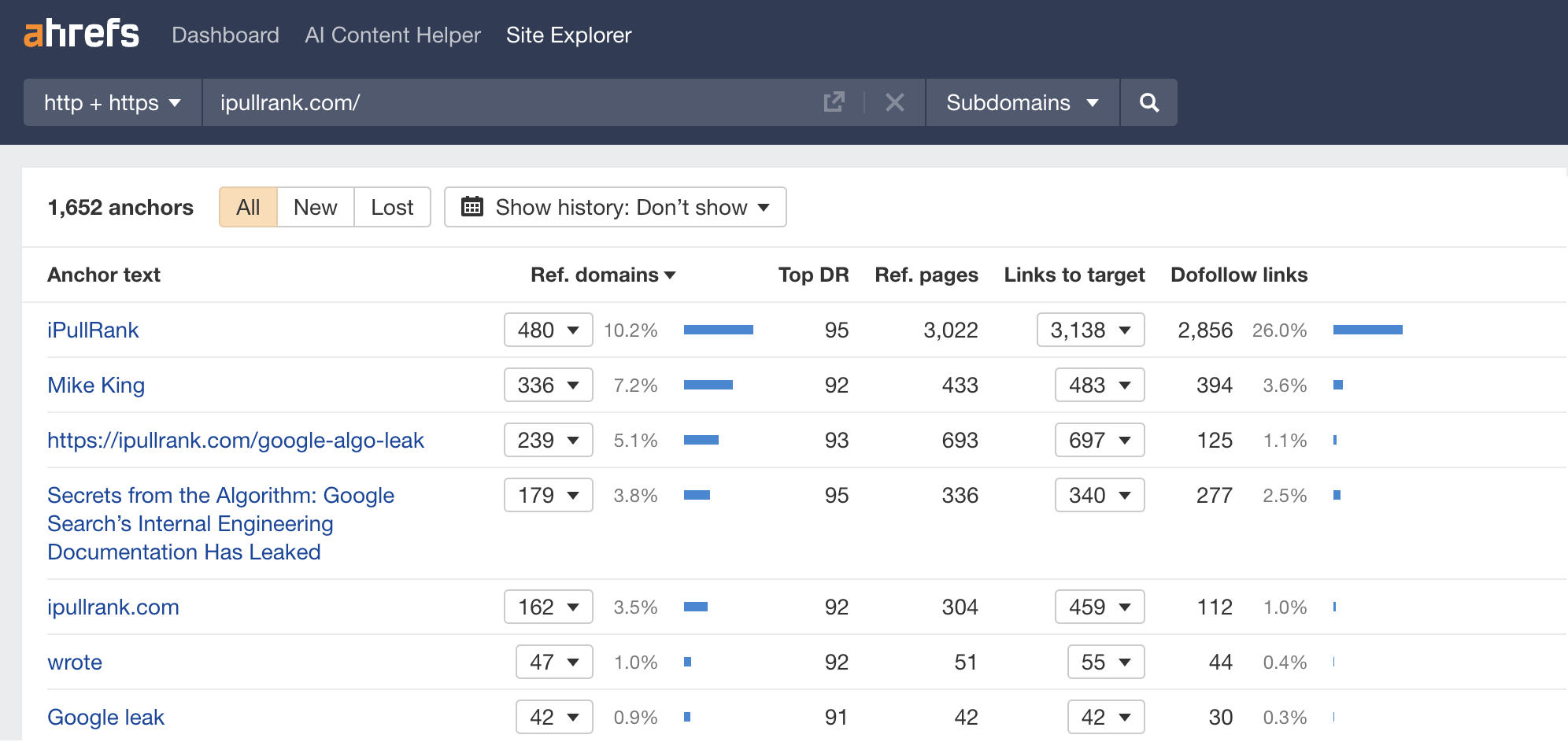
Enfin, il a analysé le texte d’ancrage pointant vers le site d’iPullRank, puisque les ancres indiquent la pertinence thématique et constituent l’un des trois piliers du ranking.
Si vous souhaitez que votre marque apparaisse naturellement dans des conversations clients pilotées par l’IA, c’est exactement cette méthode que vous devez appliquer pour auditer et comprendre vos propres entités de marque.
Évaluer votre situation actuelle et définir votre objectif
Une fois que vous connaissez vos entités de marque existantes, vous pouvez identifier les écarts entre les sujets pour lesquels les LLM vous considèrent comme légitime et ceux sur lesquels vous souhaitez apparaître.
Il ne vous reste alors qu’à créer de nouveaux contenus de marque pour renforcer ces associations.
Utiliser des outils de recherche d’entités de marque
Voici 3 outils que vous pouvez utiliser pour auditer vos entités de marque et améliorer vos chances d’apparaître dans des conversations LLM pertinentes pour votre marque :
1. Google’s Natural Language API
L’API Natural Language de Google est un outil payant qui vous montre les entités présentes dans le contenu de votre marque.
D’autres chatbots LLM utilisent des jeux de données d’entraînement différents de ceux de Google, mais il est raisonnable de supposer qu’ils identifient des entités similaires, puisqu’ils reposent eux aussi sur le traitement du langage naturel.
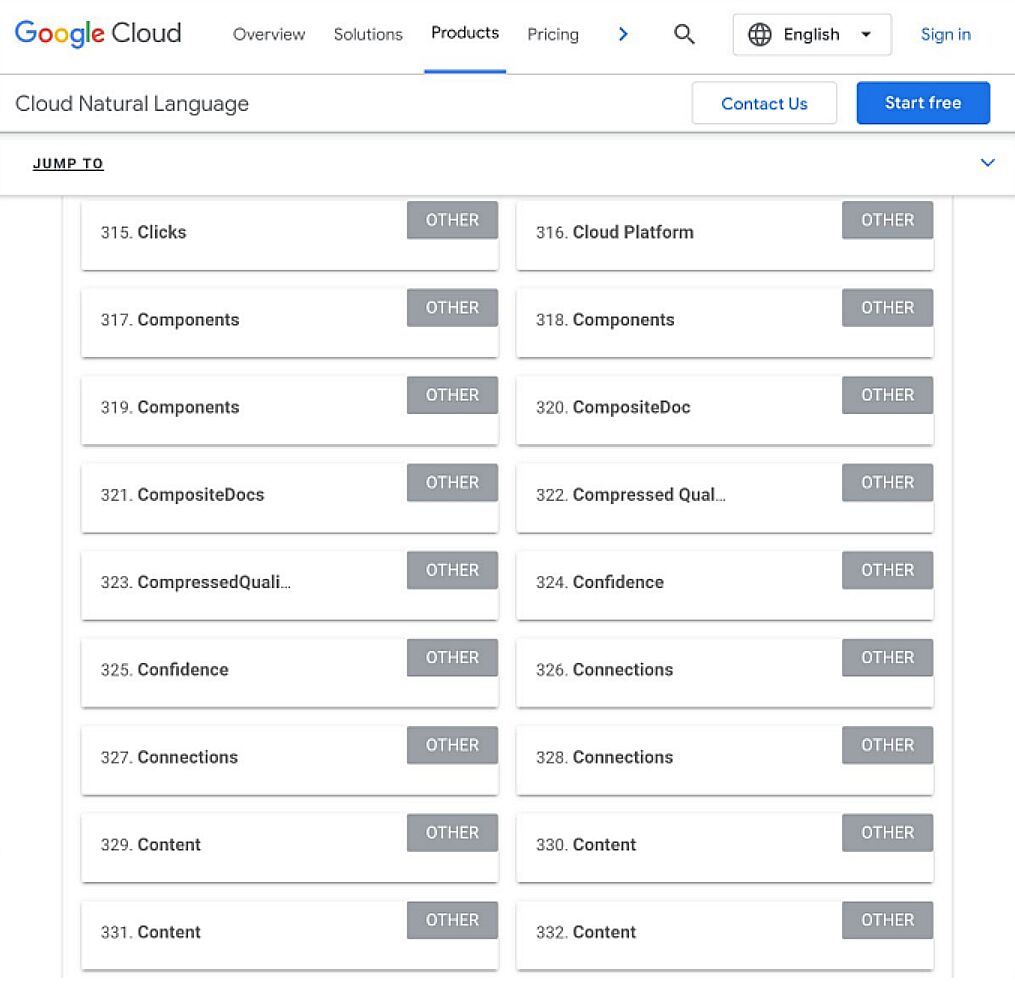
L’Entity Analyzer d’Inlinks utilise également l’API de Google et vous offre quelques analyses gratuites pour comprendre votre optimisation des entités au niveau du site.
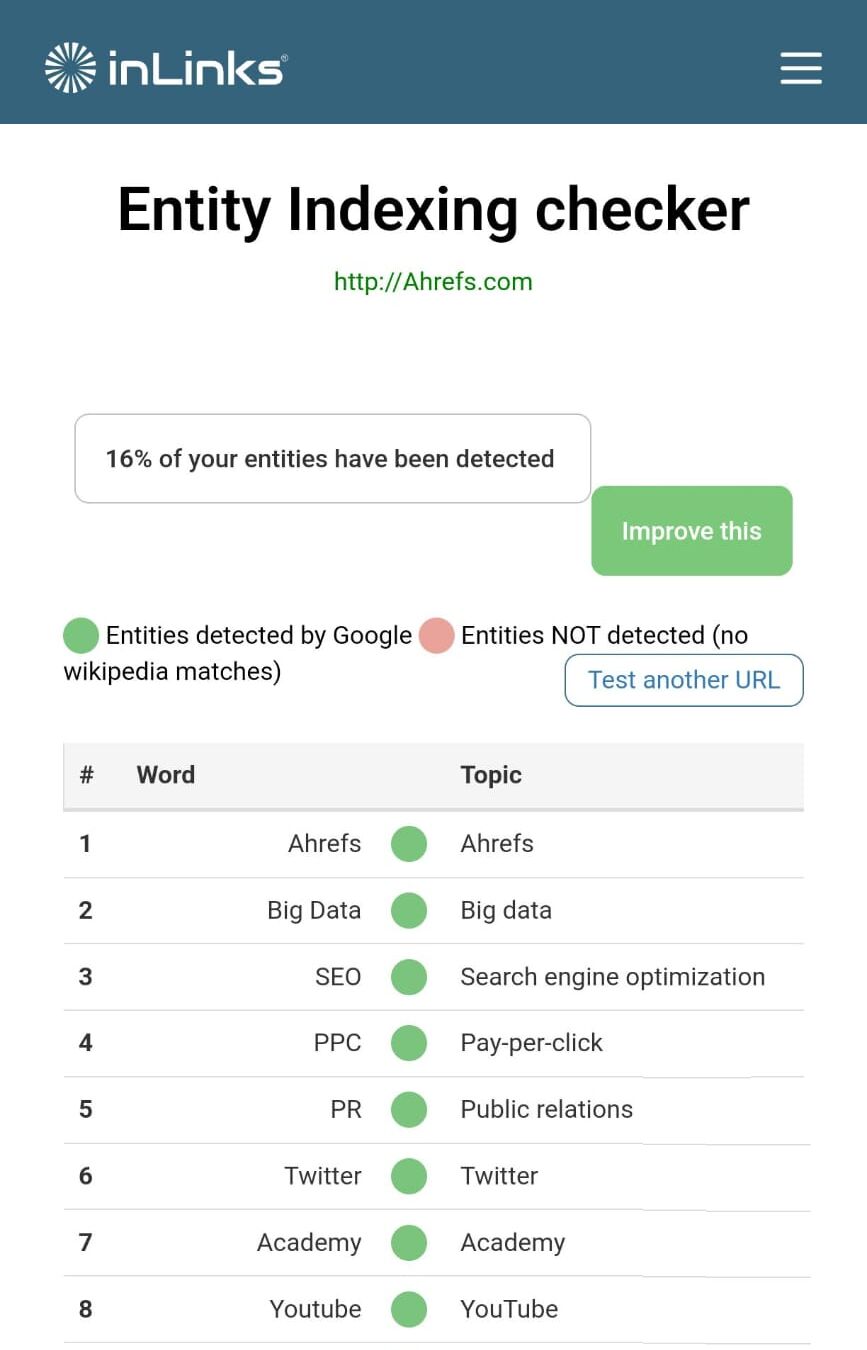
Notre outil AI Content Helper vous indique les entités que vous ne couvrez pas encore au niveau d’une page et vous conseille sur les actions à mener pour améliorer votre autorité thématique.
Selon une étude de Seer Interactive, avoir un bon classement dans les moteurs de recherche augmente la probabilité qu’une marque soit citée dans des réponses générées par l’IA (on parle de cette étude à la section n°9.)
C’est exactement ce que fait Brand Radar, entre autres (tellement plus de possibilités!)
Imaginez si vous pouviez…
- rechercher une thématique de marque importante et à forte valeur
- découvrir combien de fois votre marque est mentionnée en lien avec cette thématique dans les IA
- comparer les mentions de votre marque et votre Part de Voix IA à celles de vos concurrents
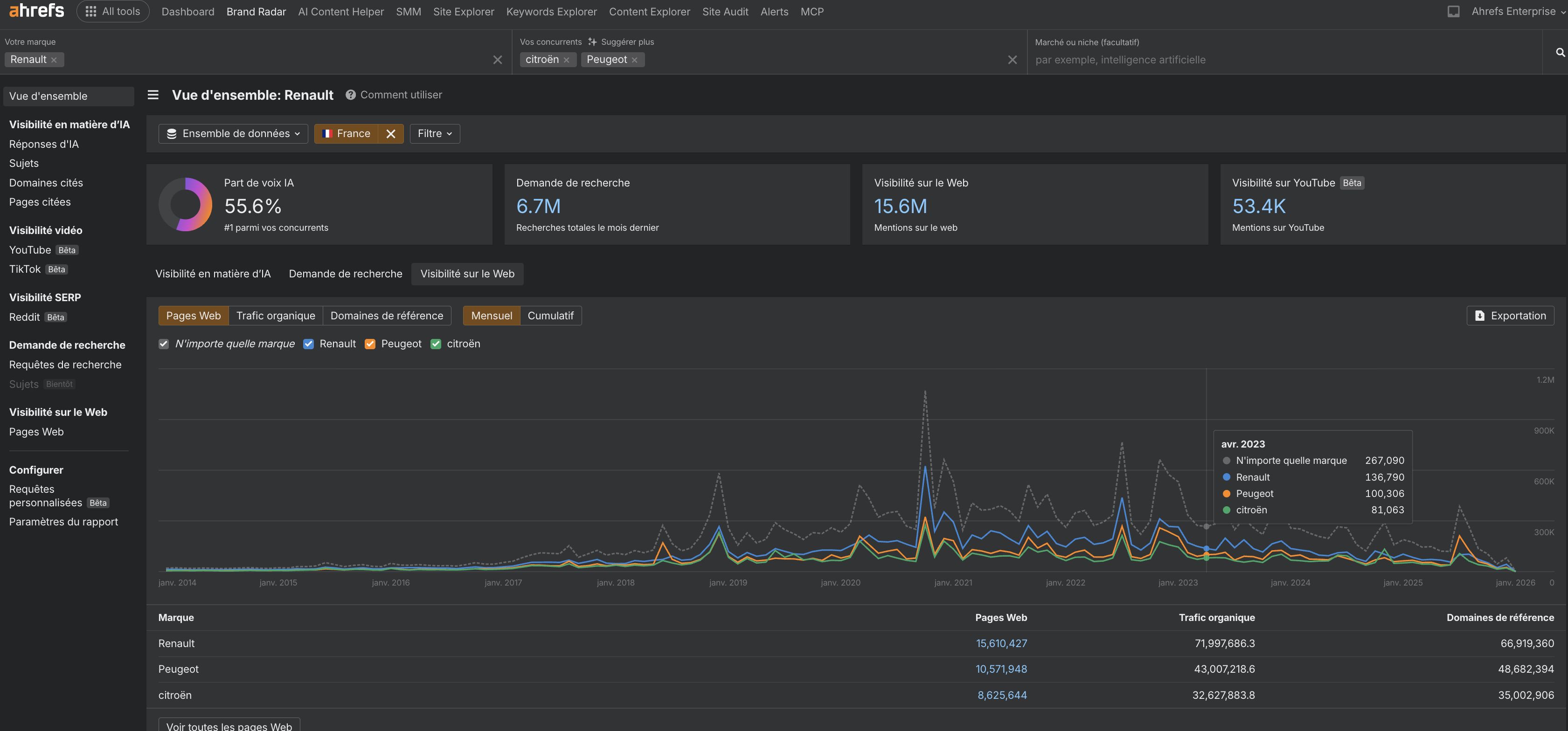
Brand Radar rend ce workflow concret.
En quelques secondes, une simple recherche vous permet d’obtenir un rapport complet sur la visibilité de votre marque afin de comparer vos performances dans les LLM.
Vous pouvez ensuite vous intégrer aux conversations IA en :
- Analysant et recyclant les stratégies des concurrents ayant la plus forte visibilité dans les IA
- Testant l’impact de vos actions marketing et PR sur la visibilité dans les IA
- Renforçant les stratégies les plus efficaces identifiées
- Identifiant des sites tiers bénéficiant d’une forte visibilité dans les Chatbots IA et AI Overviews
- Nouant les meilleurs partenariats identifiés pour obtenir davantage de co-citations
Nous avons vu comment vous entourer des bonnes entités et comment rechercher les entités pertinentes. Il est maintenant temps de parler du fait de devenir une entité de marque à part entière.
Au moment de la rédaction de cet article, les mentions et recommandations de marque dans les LLM dépendent fortement de votre présence sur Wikipedia, car Wikipedia représente une part significative des données d’entraînement des LLM.
À ce jour, tous les LLM sont entraînés à partir du contenu de Wikipedia, qui constitue presque toujours la plus grande source de données dans leurs jeux d’entraînement.
Vous pouvez revendiquer la page Wikipedia de votre marque en respectant ces quatre principes clés :
- Notoriété : votre marque doit être reconnue comme une entité à part entière. Développer des mentions dans des articles de presse, des livres, des publications académiques et des interviews peut vous y aider.
- Vérifiabilité : vos affirmations doivent être étayées par des sources tierces fiables.
- Neutralité de point de vue : les pages de votre marque doivent être rédigées dans un ton neutre et non biaisé.
- Absence de conflit d’intérêts : assurez-vous que la personne qui rédige le contenu soit impartiale vis-à-vis de la marque, par exemple ni propriétaire ni marketeur, et qu’elle privilégie des informations factuelles plutôt que promotionnelles.
Une fois votre marque listée, il s’agit ensuite de protéger cette page contre les modifications biaisées ou inexactes qui, si elles ne sont pas surveillées, pourraient se retrouver dans les LLM et dans les conversations clients.
Un effet secondaire positif du fait d’avoir des pages Wikipedia bien structurées est que vous avez davantage de chances d’apparaître indirectement dans le Knowledge Graph de Google.
Les Knowledge Graphs structurent les données d’une manière plus facile à traiter pour les LLM. Wikipedia est donc un levier durable en matière d’optimisation LLM.
Si vous cherchez à améliorer activement la présence de votre marque dans le Knowledge Graph, utilisez l’outil Google Knowledge Graph Search de Carl Hendy pour analyser votre visibilité actuelle et son évolution. Il affiche des résultats pour des personnes, des entreprises, des produits, des lieux et d’autres types d’entités.
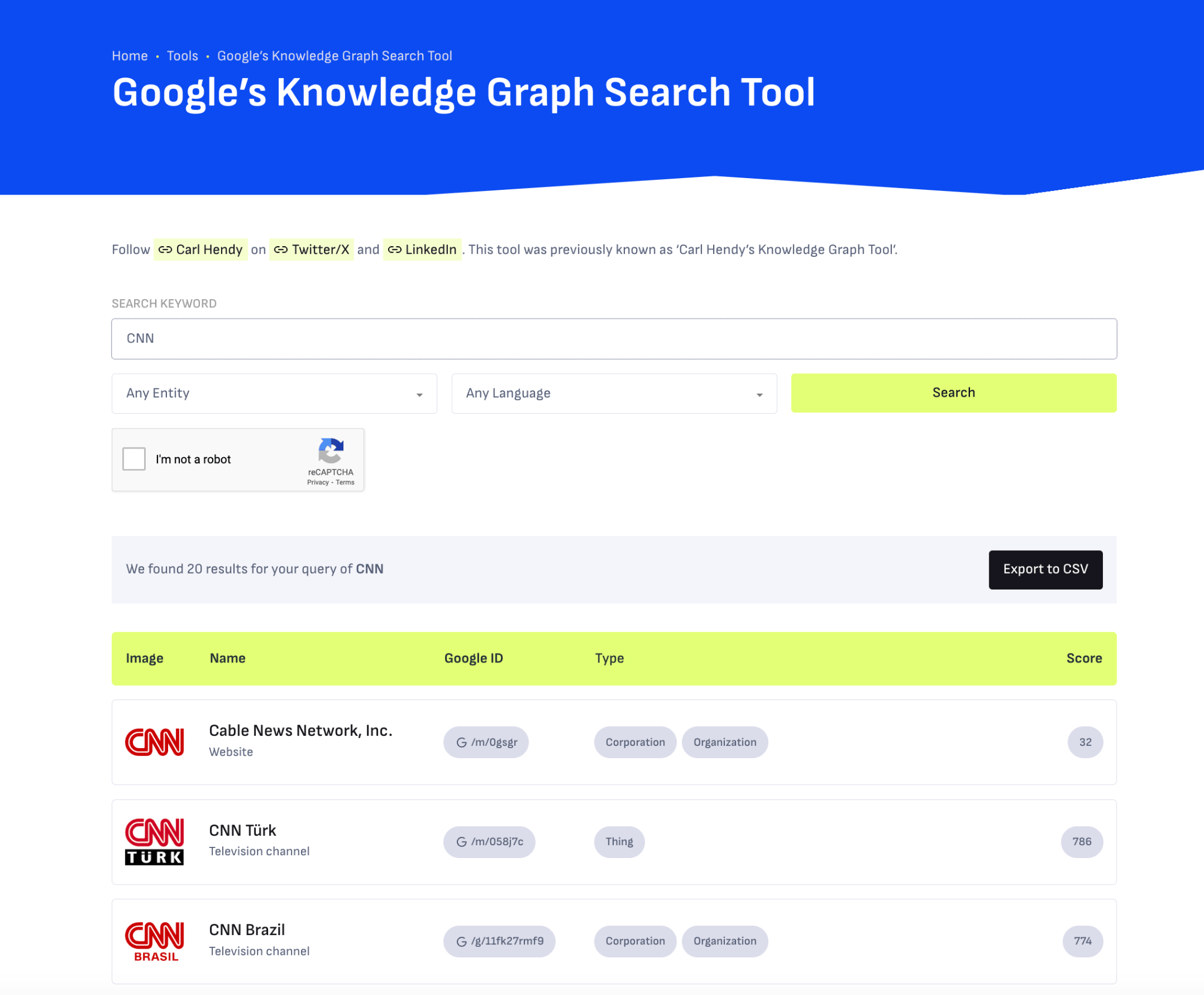
Les volumes de recherche ne correspondent pas forcément à la quantité de prompts, mais vous pouvez tout de même exploiter les données de volume pour identifier des questions de marque importantes susceptibles d’apparaître dans les conversations LLM.
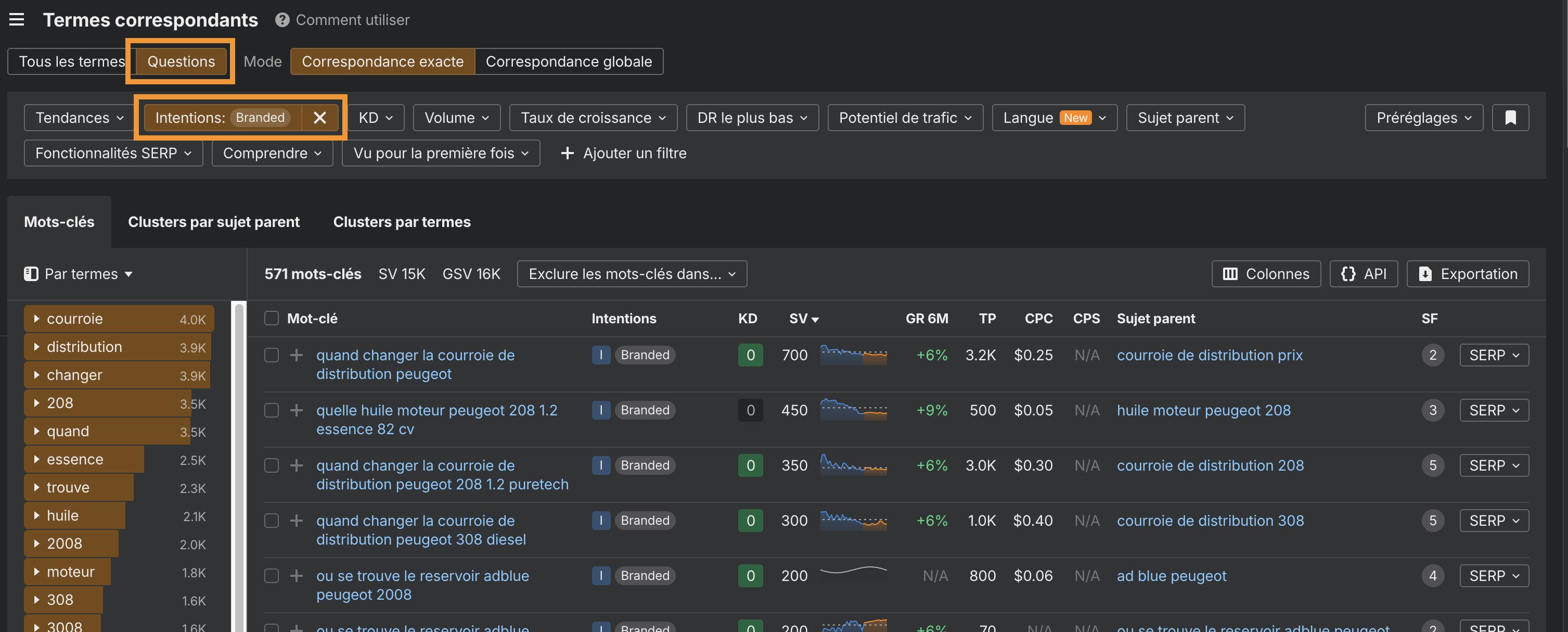
Comment trouver les questions de marque sur Ahrefs ?
Vous pouvez trouver les questions de marque en longue traîne dans l’outil Keywords Explorer, dans le rapport Termes Correspondants.
- Rechercher une thématique pertinente
- Ouvrir l’onglet « Questions »,
- Activer le filtre « Marque »
Vous obtenez une liste de requêtes auxquelles répondre dans votre contenu.
Surveillez les suggestions des LLM et des moteurs de recherche
Si votre marque est déjà bien établie, vous pouvez même mener une recherche de questions directement dans un chatbot IA.
Certains LLM intègrent une fonctionnalité de saisie semi-automatique dans leur barre de recherche. En tapant un prompt comme « Est ce que [nom de marque]… », vous pouvez déclencher cette fonctionnalité voire même en commençant avec le nom de votre marque pour voir les sujets actuellement.
Ces suggestions sont indépendantes de l’autocomplétion Google ou des questions People Also Ask.
Ce type de recherche reste évidemment limité, mais il peut vous fournir des idées supplémentaires sur les thématiques que vous devez couvrir pour renforcer la visibilité de votre marque dans les LLM.
Mais il ne suffit pas de coller une grande quantité de documentation de marque dans Copilot en espérant être mentionné et cité indéfiniment.
Le fine-tuning n’améliore pas la visibilité de marque dans les LLM publics comme ChatGPT ou Gemini. Il ne fonctionne que dans des environnements fermés et personnalisés, comme les CustomGPTs.
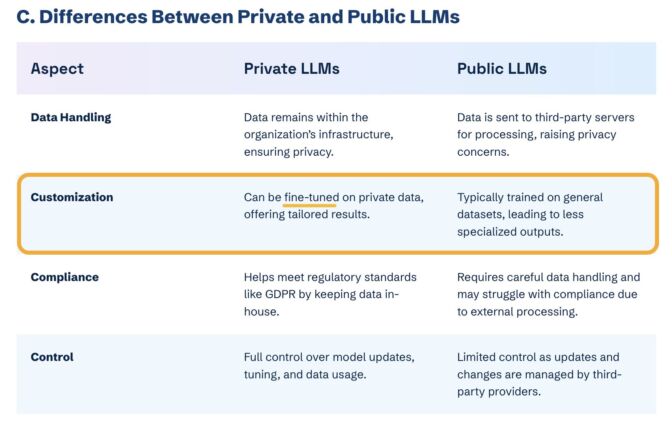
Tableau comparatif des LLM publics et privés par Kanerika
Cela permet d’éviter que des réponses biaisées soient diffusées publiquement.
Le fine-tuning peut être utile en interne, mais pour améliorer la visibilité de votre marque, vous devez surtout vous concentrer sur l’intégration de votre marque dans les données d’entraînement des LLM publics.
Les entreprises IA restent très discrètes sur les données d’entraînement qu’elles utilisent pour affiner les réponses des LLM.
Les mécanismes internes des grands modèles de langage au cœur des chatbots restent une véritable boîte noire.
Voici quelques-unes des sources qui alimentent les LLM. Il a fallu creuser en profondeur pour les identifier, et je pense n’avoir fait qu’effleurer le sujet.

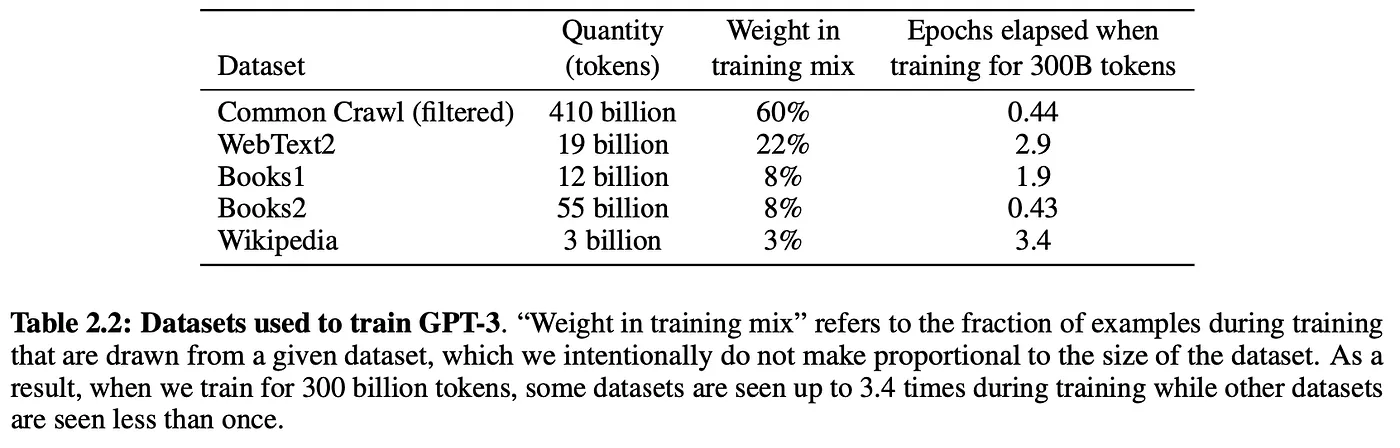
Les LLM sont essentiellement entraînés sur un corpus massif de textes issus du web.
Par exemple, ChatGPT est entraîné sur 19 milliards de tokens de contenus web et sur 410 milliards de tokens provenant des pages du Common Crawl.
Étude de recherche OpenAI Language Models are Few-Shot LearnersUne autre source clé des données d’entraînement des LLM est le contenu généré par les utilisateurs, et plus précisément Reddit.
« Notre contenu est particulièrement important pour l’intelligence artificielle. Il constitue un socle fondamental de l’entraînement de nombreux grands modèles de langage (LLM). »
Pour renforcer la visibilité et la crédibilité de votre marque, il est pertinent de lancer et affiner une bonne stratégie Reddit.
Si vous souhaitez augmenter les mentions de marque issues de contenus générés par les utilisateurs, tout en évitant les pénalités liées au parasite SEO, concentrez-vous sur :
- La création de communautés sans spam de liens
- L’organisation de sessions Ask me Anything (AMA)
- Le développement de partenariats avec des influenceurs
- L’encouragement de contenus générés par les utilisateurs autour de votre marque
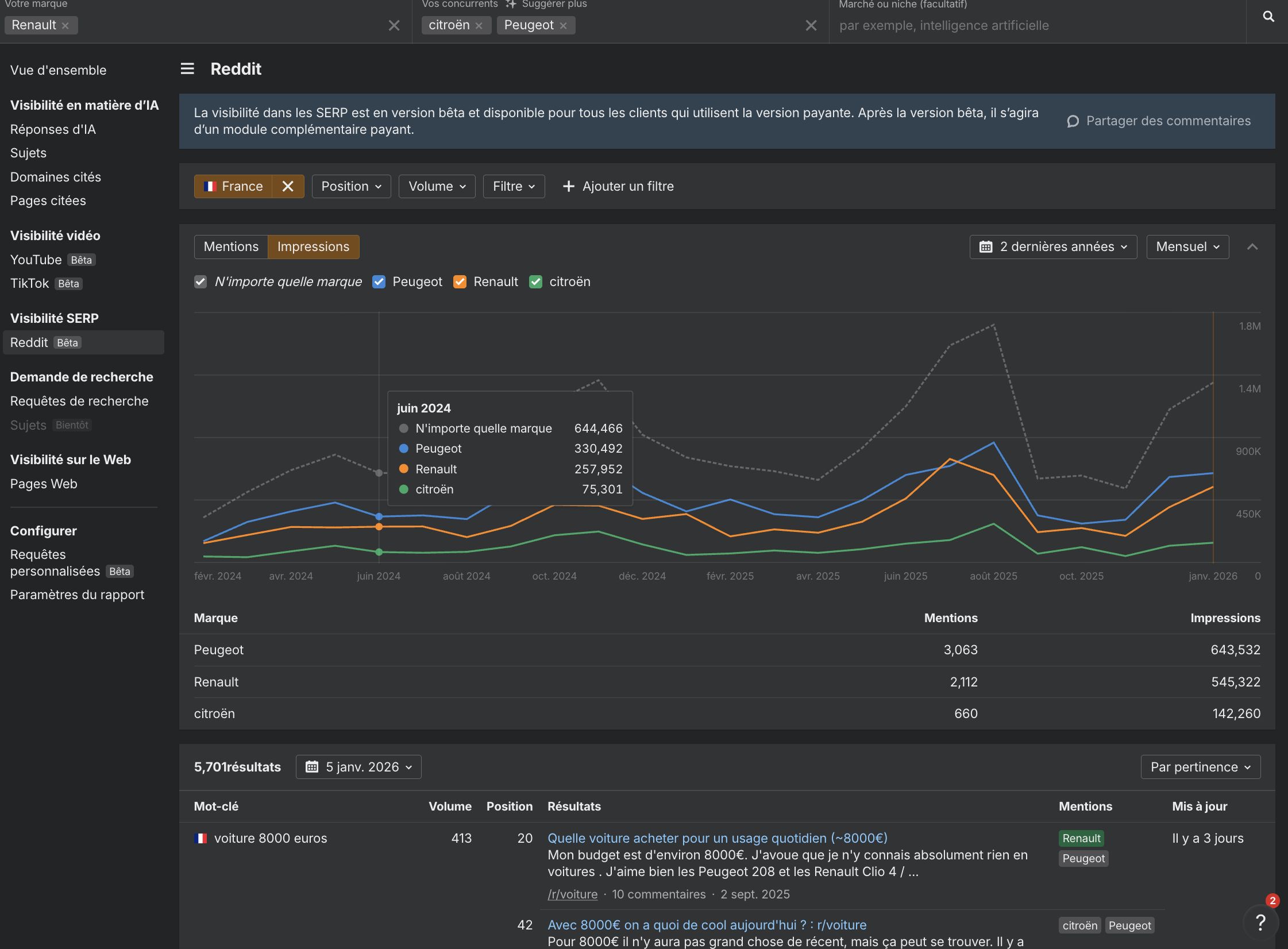
Ensuite, une fois ces actions mises en place, vous devez suivre votre progression sur Reddit.
Vous pouvez le faire avec Ahrefs via Brand Radar dans l’onglet Reddit tout en comparant votre progression sur Reddit avec vos concurrents :
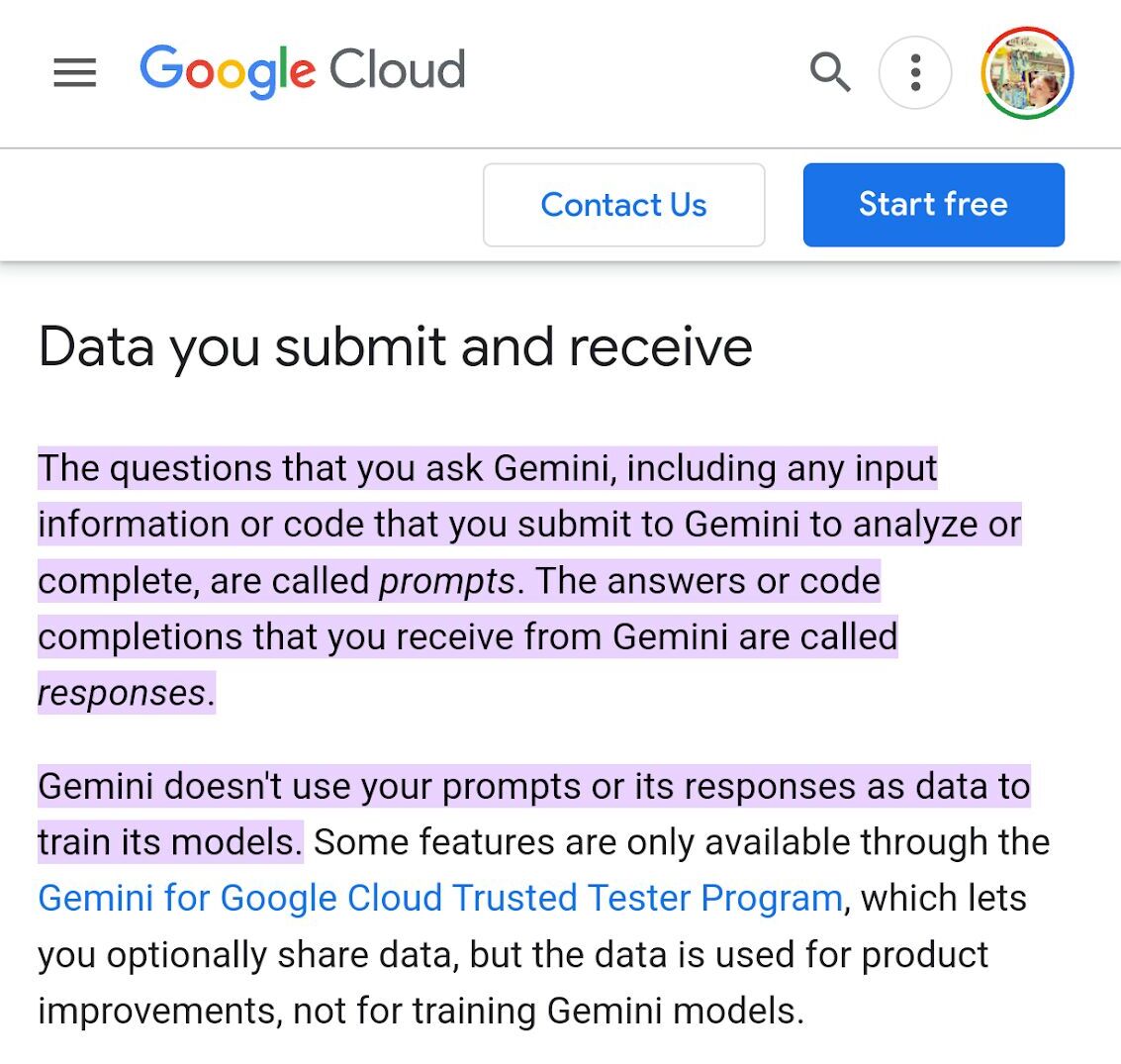
Gemini n’entraînerait théoriquement pas ses modèles à partir des prompts ou des réponses des utilisateurs…
Cependant, le fait de fournir un retour sur ses réponses semble l’aider à mieux comprendre les marques.
Lors de son excellente conférence à BrightonSEO, Crystal Carter a présenté l’exemple d’un site, Site of Sites, qui a fini par être reconnu comme une marque par Gemini grâce à des actions telles que la notation des réponses et l’envoi de feedback.
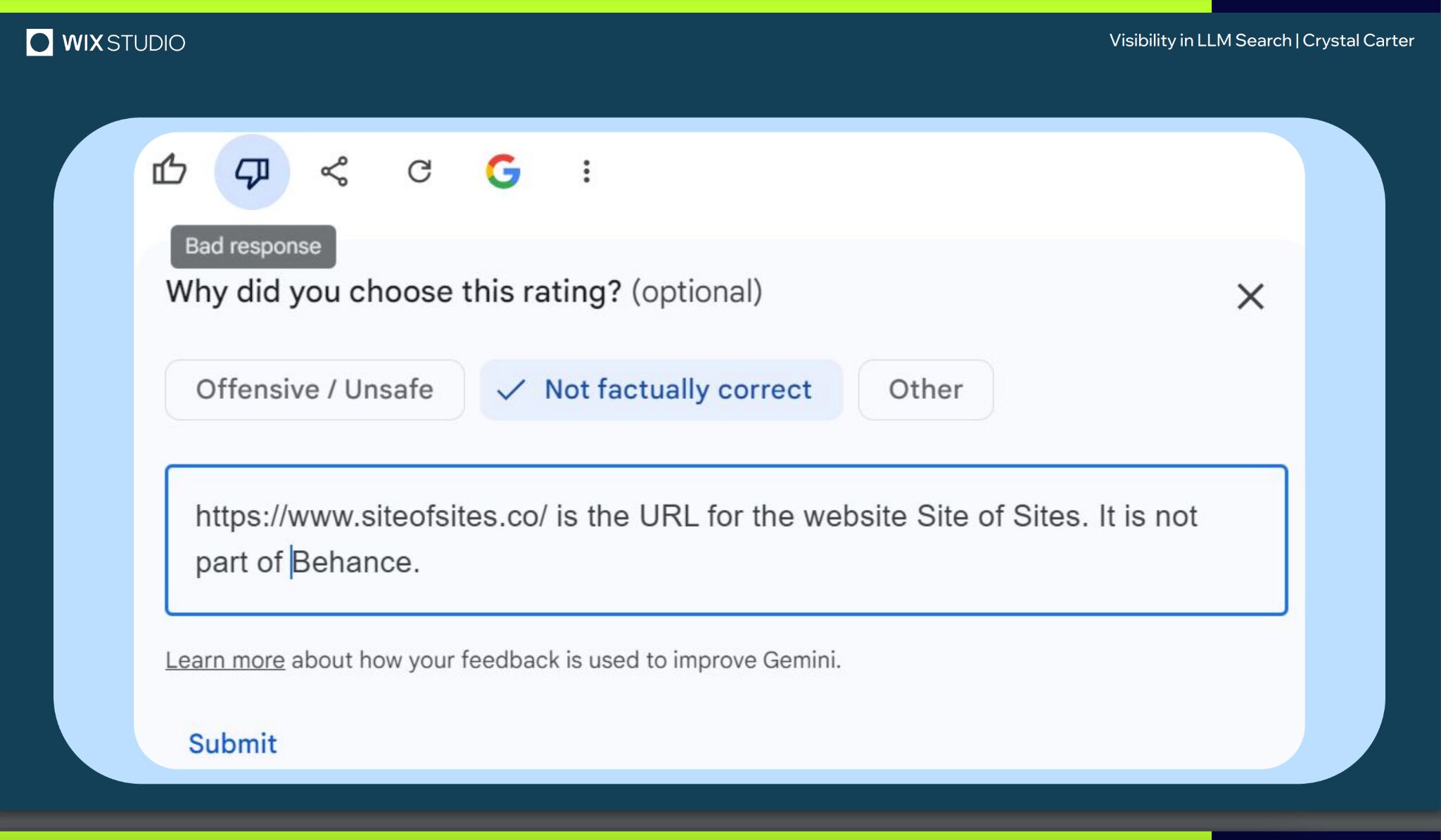
Essayez vous aussi de fournir des retours sur les réponses générées. C’est particulièrement pertinent pour les LLM basés sur la récupération d’informations en temps réel comme Gemini, Perplexity et Copilot.
Cela pourrait bien être votre porte d’entrée vers une meilleure visibilité de marque dans les LLM.
À l’origine, cette section portait sur l’utilisation du balisage schema pour structurer votre contenu de manière à ce qu’un LLM puisse mieux l’analyser et le comprendre. Cette approche s’appuyait sur les recherches que j’avais lues sur le sujet.
Depuis, j’ai découvert que ce n’était pas tout à fait exact. Les crawlers IA ne peuvent pas accéder aux données schema ni, plus largement, aux données rendues côté client. À l’heure actuelle, ils ne peuvent crawler que le HTML.
Je reconnais m’être trompée et je m’excuse de vous avoir induit en erreur.
Voici un excellent post d’Elie Berreby si vous souhaitez une analyse plus technique sur la manière dont les LLM explorent les données sur le web ouvert.

Mais voici pourquoi vous devez absolument continuer à travailler votre SEO lorsque vous cherchez à capter ces précieuses mentions dans les LLM.
En se concentrant sur les secteurs de la finance et du SaaS, Seer Interactive a soumis 10 000 requêtes à fort volume de recherche et à forte intention d’achat à l’API GPT-4o d’OpenAI. Ils ont ensuite mesuré la fréquence d’apparition des noms de marque dans les réponses.
Ils ont complété cette analyse avec des données de SERP issues de Google et Bing.
De fortes corrélations, autour de 0,65, indiquent que les positions organiques influencent bien les mentions dans les LLM. À l’inverse, l’impact des backlinks s’avère étonnamment neutre.
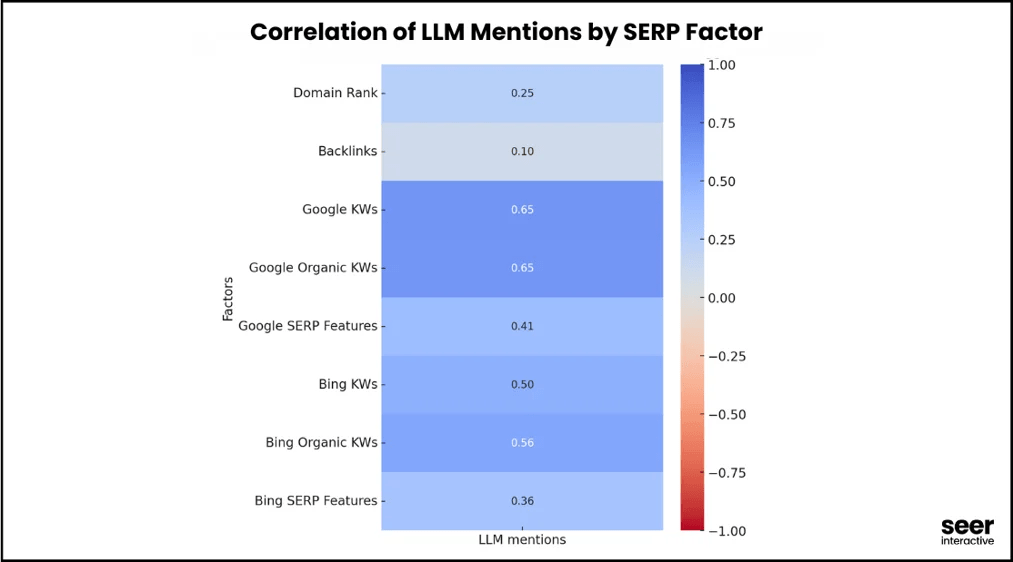
Les corrélations liées aux mots-clés organiques deviennent encore plus fortes lorsque l’équipe de Seer Interactive exclut les forums, les réseaux sociaux et les agrégateurs, afin de se concentrer sur des sites orientés solution, plus susceptibles d’apparaître dans les réponses des LLM.
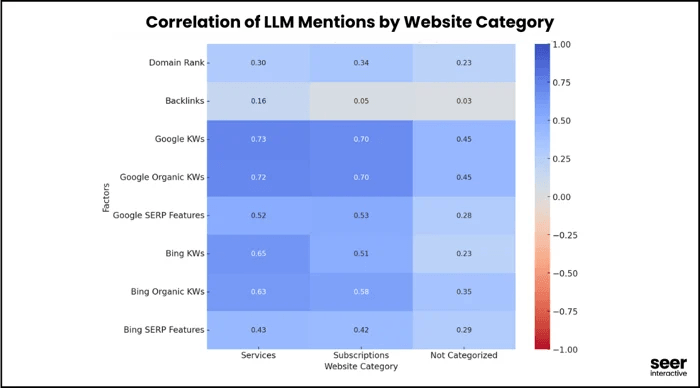
La morale est simple : ne sacrifiez pas vos positions organiques au profit de la visibilité dans les LLM.
Vos efforts SEO quotidiens jouent un rôle majeur dans le développement de la notoriété de votre marque auprès des IA.
Dans une étude récente intitulée Manipulating Large Language Models to Increase Product Visibility, des chercheurs de Harvard ont montré qu’il est techniquement possible d’utiliser le « strategic text sequencing » (STS) pour gagner en visibilité dans les LLM.
Initialement conçu pour contourner les garde-fous de sécurité des modèles, ce procédé repose sur une optimisation par essais et erreurs, visant à déclencher certains schémas appris par le LLM afin d’influencer ses réponses.
Les résultats sont parlants : dans environ 40 % des cas testés, l’ajout de séquences optimisées améliore le classement du produit ciblé. D’autres travaux démontrent également que des contenus soigneusement conçus, incluant des injections de prompt ou des biais subtils, peuvent manipuler les recommandations de marques, allant jusqu’à faire dépasser des produits factices à des acteurs établis.
Ces pratiques LLMO black hat ne sont plus théoriques. Des cas réels de dénigrement et de sabotage de marque via l’IA commencent à émerger, exposant de nouvelles failles dans les systèmes de recommandation des LLM.
Si l’optimisation pour les LLM est devenue incontournable, une réalité s’impose : à l’image des débuts du SEO, des acteurs opportunistes chercheront des raccourcis pour capter la visibilité IA. Il devient donc tout aussi crucial de penser stratégie défensive et protection de marque que performance.
- Croire que le LLMO remplace le SEO
Mauvais pari. Le SEO vous rend découvrable. Le LLMO vous rend citable. Si vous sacrifiez vos positions organiques, vous coupez une partie de l’alimentation. - Confondre LLM, AI Overviews et “recherche IA”
Même écosystème, pas les mêmes règles. Optimiser “comme pour Google” sans comprendre le format (conversation, sources, RAG) = beaucoup d’efforts pour peu de mentions. - Raisonner “mots-clés” au lieu de raisonner “entités”
Les LLM ne “rangent” pas votre marque dans un dossier “keyword”. Ils la situent dans une carte de concepts. Sans associations claires (marque ↔ sujet ↔ preuves), vous restez hors champ. - Faire du contenu flou, long et sans preuves
Les réponses IA adorent ce qui se cite facilement : définitions nettes, points clés, stats, sources. Un pavé marketing sans faits = zéro citation, voire pire, une reformulation tiède. - Se noyer dans les features au lieu d’être ultra clair
Trop de paillettes = pas de positionnement. Si vous ne savez pas résumer votre valeur en 1–2 phrases vérifiables, l’IA ne saura pas non plus. - Miser sur le “fine-tuning” pour percer dans les LLM publics
Coller votre doc dans un Copilot et espérer dominer ChatGPT n’est pas une stratégie. Le fine-tuning aide en environnement fermé, pas pour la visibilité “grand public”. - Penser que le schema “suffit”
Les crawlers IA ne lisent pas toujours ce que vous pensez (et pas forcément ce qui est rendu côté client). Priorité : un HTML lisible, stable, et des infos faciles à extraire. - Faire du black hat (STS, prompt injections, manipulations)
Oui, certains “cheat codes” existent. Non, ce n’est pas durable. Et surtout : vous vous exposez à un retour de flamme (réputation, confiance, plateformes). - Spammer Reddit / forums façon “parasite”
L’UGC peut aider… mais pas le bruit. Si vous laissez une trace de spam, vous gagnez peut-être une mention aujourd’hui et vous perdez votre crédibilité demain. - Ne pas mesurer la visibilité IA (et piloter au feeling)
Sans KPI (mentions, citations, part de voix IA, trafic de recommandation), vous ne saurez jamais ce qui marche. Le LLMO est un terrain de test permanent. - Oublier la défense de marque
Désinformation, sabotage, pages tiers biaisées : ça arrive déjà. Wikipédia, pages de référence, cohérence des infos, monitoring… c’est du LLMO aussi. - Ignorer l’expérience on-site après la mention
Les mentions finissent par envoyer du trafic. Si vos pages citées ne guident pas vers vos pages clés (maillage, preuve, conversion), vous laissez l’or dans la rivière.
Tester, tester, tester
Avec le LLMO, rien n’est garanti. Les LLM restent en grande partie une boîte noire.
Nous ne savons pas précisément quelles données ni quelles stratégies sont utilisées pour entraîner les modèles ou déterminer l’inclusion des marques. Mais nous sommes habitués, nous les professionnels du SEO.
Nous testerons, rétroconcevrons et enquêterons jusqu’à comprendre.
Le parcours d’achat a toujours été complexe et difficile à mesurer. Les interactions avec les LLM le rendent dix fois plus compliqué.
Elles sont multimodales, riches en intentions, interactives et non déterministes. Elles vont générer encore davantage de recherches non linéaires.
Selon Amanda King, il faut déjà environ 30 points de contact sur différents canaux avant qu’une marque soit reconnue comme une entité. Avec la recherche IA, ce chiffre ne fera qu’augmenter.
Aujourd’hui, ce qui se rapproche le plus du LLMO est l’optimisation de l’expérience de recherche, ou SXO.
Réfléchir à l’expérience que vivront vos clients sous tous les angles de votre marque est désormais crucial, d’autant plus que vous avez de moins en moins de contrôle sur la manière dont ils vous découvrent.
Lorsque, enfin, ces mentions et citations de marque durement acquises commenceront à affluer, vous devrez alors vous pencher sur l’expérience on-site. Cela inclut par exemple le fait de lier stratégiquement les pages fréquemment citées par les LLM vers des pages clés afin de redistribuer cette valeur sur votre site.
En clair, le LLMO repose sur une construction de marque réfléchie et cohérente dans le temps. Ce n’est pas un chantier simple, mais il en vaut clairement la peine si ces prévisions se confirment et si les LLM finissent par dépasser la recherche traditionnelle dans les années à venir.
Et si vous débutez en stratégie LLMO, je ne peux que vous conseillez de vous appuyer sur le serveur Ahrefs MCP (une sorte de chatbot Ahrefs, vous verrez) pour avoir des stratégies GEO qui s’appuient sur de vraies données :

