Régulièrement, on voit des débats (y compris en France) sur le fichier llms.txt, mais les preuves concrètes se limitent aux logs d’un seul site ou à quelques expériences à petite échelle.
En utilisant Ahrefs Web Analytics et Bot Analytics, on a analysé les logs serveur et le trafic en temps réel de 137 000 domaines, ainsi que les user agents qui les visitent.
Voici ce qu’on a trouvé.
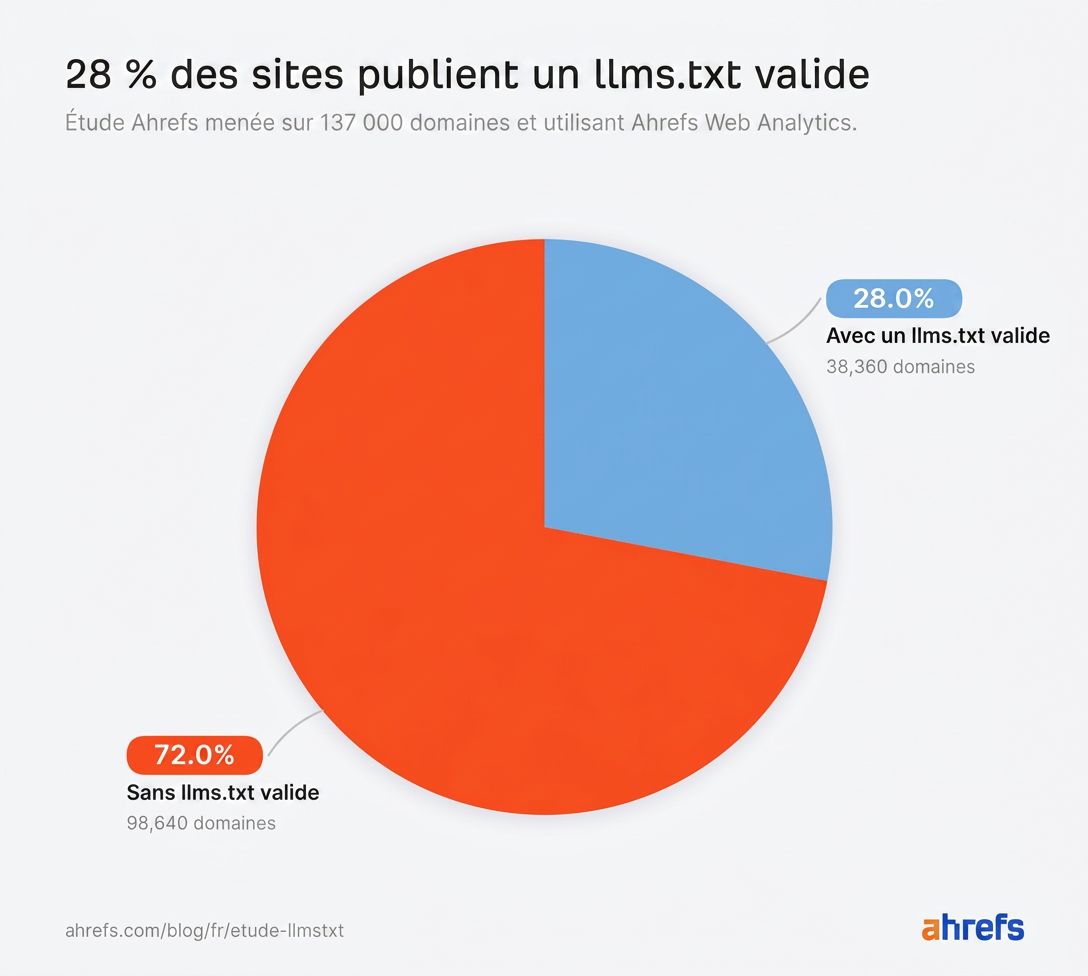
- 28 % des 137 000 domaines utilisant Ahrefs Web Analytics publient un fichier llms.txt.
- 97 % de ces fichiers n’ont reçu aucun trafic en mai 2026. Personne ne les a consultés.
- 96 % des requêtes qui ont bien atteint les fichiers llms.txt provenaient de bots.
- 19,5 % des requêtes provenaient d’outils IA identifiés (parmi les 3 % de fichiers qui n’ont pas été ignorés). GPTBot arrive en tête, suivi de Claude-Code, devant tous les bots de recherche IA et d’assistants IA.
- 12 % des requêtes proviennent du secteur qui s’étudie lui-même : outils GEO/AEO, outils de vérification llms.txt et chercheurs.
- Zéro requête de bots IA pour des fichiers llms.txt qui n’existent pas. Ils ne cherchent jamais.
- L’audit llms.txt de Chrome Lighthouse représente environ 1 requête sur 1 000.
Fin mai 2026, Google a pris les deux positions dans le débat sur llms.txt en moins d’une semaine.
Son nouveau guide d’optimisation pour les fonctionnalités IA génératives expliquait aux propriétaires de sites, dans une section intitulée « démystification », que les fichiers lisibles par les machines comme llms.txt ne sont pas nécessaires pour apparaître dans la recherche IA générative.

Quelques jours plus tard, l’équipe Chrome a intégré une vérification llms.txt dans les audits expérimentaux de navigation agentique de Lighthouse, avec une documentation expliquant que sans ce fichier, les agents pourraient passer plus de temps à crawler un site pour en comprendre la structure.
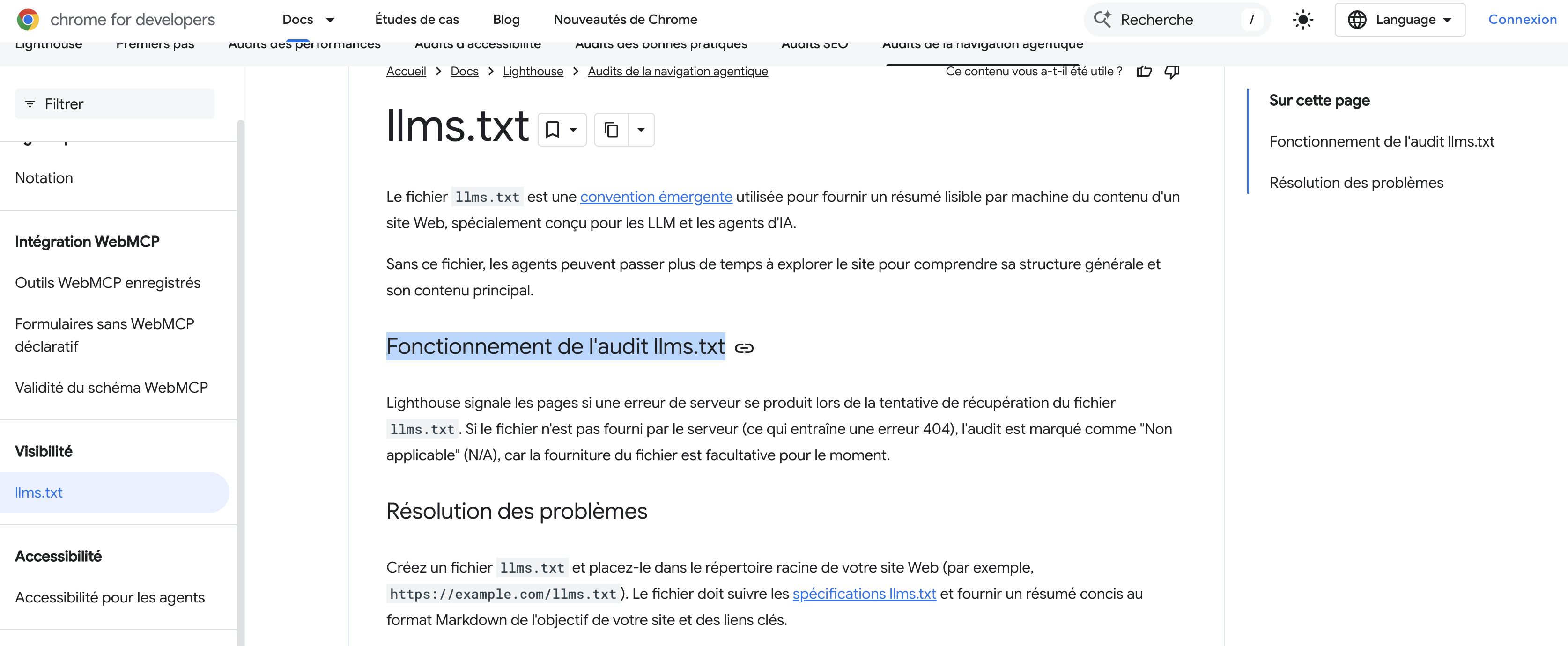
Quand Lily Ray a interrogé John Mueller de Google sur cette contradiction, il a expliqué que llms.txt n’est « pas fait pour la recherche ». C’est une « béquille temporaire, peut-être pour économiser quelques tokens » pour les outils de code IA qui analysent la documentation développeur, pas quelque chose dont les sites non-développeurs ont besoin de s’inquiéter.
Il a également précisé que les propriétaires de sites qui consultent leurs logs trouveront très peu de trafic provenant d’agents IA.
C’est exactement ce qu’on a décidé de vérifier.
Avant d’aller plus loin, précisons ce qu’est réellement llms.txt. C’est un fichier index unique, écrit en markdown, placé à la racine d’un site. Proposé par Jeremy Howard, co-fondateur d’Answer.AI et fast.ai, en 2024, il résume ce qu’est un site et renvoie vers son contenu le plus important.
L’idée : les LLM et les agents peuvent utiliser cette information pour s’orienter sans tout crawler. Le cadrage « visibilité IA » autour de llms.txt est arrivé plus tard, apposé par le secteur SEO au fil de l’adoption, sur la spéculation que les plateformes IA récompenseraient le fichier.
Deux choses avec lesquelles il est souvent confondu, mais qu’il n’est pas :
- Ce n’est pas la pratique de publier des copies markdown de vos pages web, une tactique distincte avec ses propres problèmes.
- Et malgré son nom, ce n’est pas une directive de type robots.txt : il ne contrôle rien et ne bloque rien.
Cette étude mesure le fichier index, et uniquement le fichier index.
Notre étude porte sur 137 210 domaines dans Ahrefs Web Analytics qui ont reçu du trafic en mai 2026.
On a vérifié la présence d’un fichier llms.txt renvoyant un HTTP 200 à la racine de chaque domaine, puis on a utilisé Ahrefs Bot Analytics pour examiner chaque requête vers les chemins /llms.txt sur l’ensemble de la population, classées par réponse HTTP (200 vs 404) et par canal et user agent individuel.
Pour exclure les soft 404s et les fichiers fantômes, on a également confirmé que chaque fichier était bien du Markdown plutôt que du HTML, et filtré les titres et contenus contenant des signaux d’erreur comme « 404 » ou « Page not found ».
Points importants :
- Les clients d’Ahrefs Web Analytics sont plus techniques et sensibles au SEO que la moyenne du web, donc traitez le chiffre d’adoption de 28 % comme une limite haute.
- On n’a pas explicitement étudié si un fichier était bien formé selon la spécification llms.txt.
Le guide de Google Search dit qu’on peut s’en passer, l’équipe Chrome l’audite, et Mueller le qualifie de mesure transitoire (il utilise “stopgap” à l’origine) pour les outils de code.
Face à tous ces messages contradictoires, quelle est la véritable adoption de llms.txt ? Parmi les 137 000 domaines de notre étude, 28 % publient ces fichiers.
Plus d’un domaine sur quatre (38 000) dans notre population a adopté llms.txt, alors qu’aucune grande plateforme IA ne s’est jamais engagée à le lire.
L’adoption a été alimentée par la spéculation que les plateformes IA pourraient commencer à consommer le fichier, plutôt que par une confirmation qu’elles le font vraiment.
Presque tous les fichiers llms.txt de notre étude ne sont jamais lus.
Parmi les ~38 000 domaines disposant d’un fichier valide, 97 % n’ont enregistré aucune requête en mai.
Aucun bot. Aucun humain. Rien.
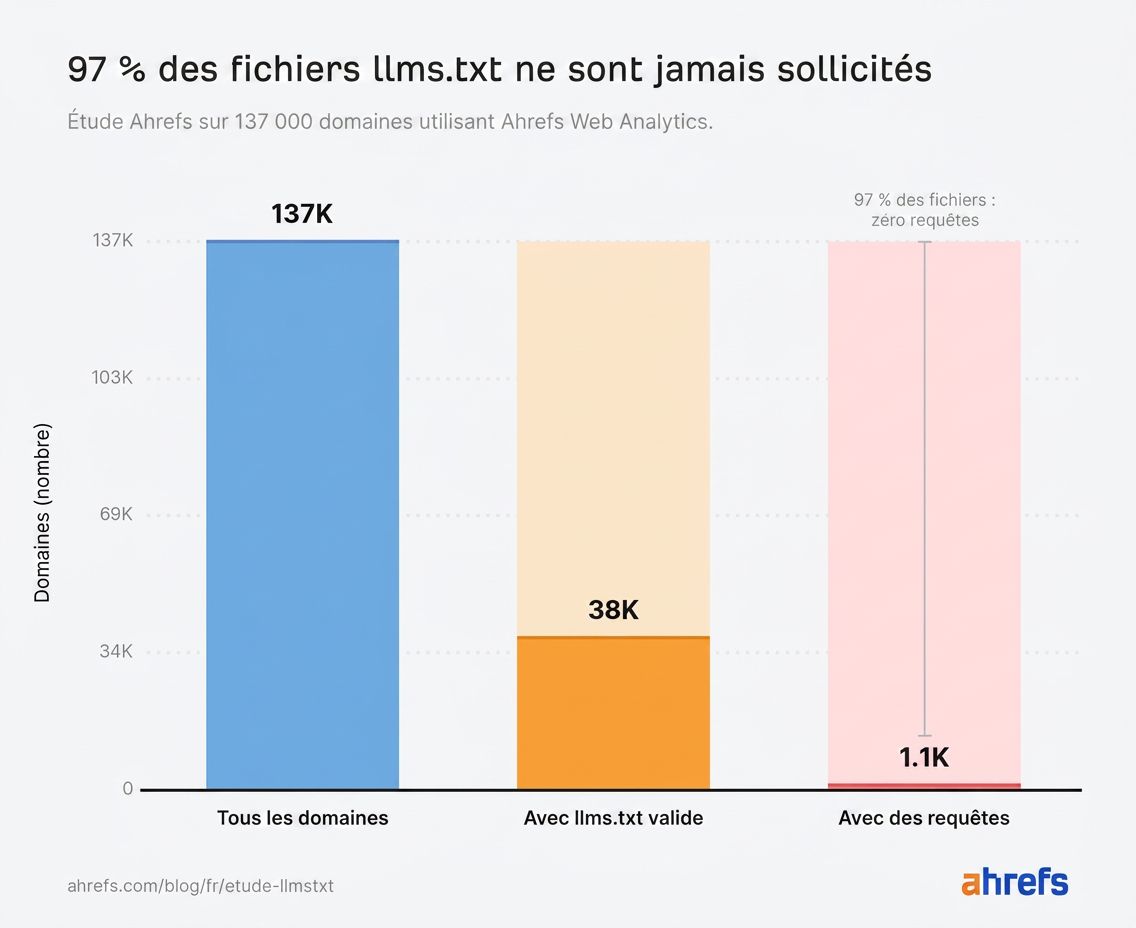
Les 3 % restants (1 100 domaines) ont reçu l’intégralité du trafic llms.txt qu’on a mesuré.
Nos données confirment que John Mueller a raison. Non seulement vous trouverez très peu de trafic IA grâce à ce fichier, mais vous trouverez très peu de trafic en général.
Si vous publiez un fichier llms.txt aujourd’hui, le résultat le plus probable est qu’il ne sera jamais consulté par personne ni aucun bot.
Les 3 % de fichiers qui sont lus, en revanche, le sont par des visiteurs intéressants. On se concentre sur eux pour le reste de l’étude.
Les fichiers llms.txt sont écrits pour les machines, et les machines sont presque les seules à les lire.
Parmi les fichiers qui ont reçu du trafic, 96 % des requêtes provenaient de bots.
Les humains représentaient 4 %, et une bonne partie d’entre eux semblent être des SEO partageant des liens llms.txt dans des applications de messagerie, où les bots de dépliage de liens les récupèrent rapidement.
Slackbot a récupéré des fichiers llms.txt plus souvent que PerplexityBot.
Perplexity est l’un des moteurs de recherche IA que llms.txt était censé aider. Constater que le bot d’aperçu de lien d’une application de messagerie le surpasse en nombre de requêtes en dit long sur l’intérêt réel que ces fichiers génèrent côté recherche IA.
Beaucoup de sites publient llms.txt précisément parce qu’ils pensent que ça améliorera leurs chances d’apparaître dans les réponses de ChatGPT, d’obtenir des citations Perplexity ou de décrocher un AI Overview.
Mais nos données contredisent cet espoir : 77 % des bots qui récupèrent llms.txt ne sont pas des outils IA.
Pour comprendre quels bots demandaient effectivement llms.txt, on a classé chaque user agent en 12 catégories.
| CATÉGORIE | TYPE | REQUÊTES | % DU TOTAL |
|---|---|---|---|
| Outils d’audit SEO | Audit | 4 776 | 21,7% |
| Autres et non identifiés | Inconnu | 3 278 | 14,9% |
| Crawlers web généralistes | Crawling | 2 871 | 13,1% |
| Outils de profilage technologique | Profilage | 2 546 | 11,6% |
| Agents IA et infrastructure agentique | IA | 2 302 | 10,5% |
| Outils GEO/AEO | Étude llms.txt | 1 278 | 5,8% |
| Crawlers d’entraînement IA | IA | 1 179 | 5,3% |
| Bots de découverte llms.txt | Étude llms.txt | 793 | 3,6% |
| Bots de services et réseaux sociaux | Social | 645 | 2,9% |
| Bots de recherche | Étude llms.txt | 585 | 2,7% |
| Assistants IA | IA | 559 | 2,5% |
| Bots de récupération IA | IA | 233 | 1,1% |
* Les outils d’audit SEO incluent les propres crawlers d’Ahrefs (SiteAuditBot, Ahrefs Bot et Ahrefs Site Audit), qui représentent ensemble 2 334 requêtes (10,6 % du total). En les excluant, les outils d’audit SEO tiers représentent 2 442 requêtes (11,1 %). Les catégories de bots totalisent 96 % de l’ensemble des requêtes ; les 4 % restants (930 requêtes) provenaient d’humains.
Individuellement, aucune catégorie de bots IA ne figure dans le top quatre.
Les outils d’audit SEO (21,7 %), les bots autres et non identifiés (14,9 %), les crawlers web généraux (13,1 %) et les outils de profilage technologique (11,6 %) envoient tous plus de requêtes qu’un seul bot IA.
La plus grande catégorie IA isolée, les agents IA, arrive en cinquième position avec 10,5 %.
Mais quand on combine les quatre catégories IA (crawlers d’entraînement, bots de récupération, assistants et agents), les bots IA forment le plus grand groupe unique avec 19,5 %.
Le trafic de bots se divise en trois histoires :
- Les bots IA qui consomment le fichier (19,5 %)
- Une longue traîne de scrapers anonymes (14,9 %)
- Un secteur qui l’audite (12,1 %)
On explore quelques-uns de ces points ci-dessous.
Parmi les requêtes qui atteignent effectivement les fichiers llms.txt, les bots IA identifiés représentent 19,5 %.
Même si les bots IA constituent l’audience identifiable la plus importante de llms.txt, la ventilation par type de bot IA montre que le fichier ne sert pas vraiment les outils IA que la plupart des gens ont en tête.
On les regroupe en quatre catégories :
- Les agents IA et l’infrastructure agentique qui agissent pour le compte d’un utilisateur, ou crawlent pour servir les agents qui le font.
- Les crawlers d’entraînement IA qui collectent des données pour la construction de modèles.
- Les assistants IA qui naviguent sur le web pour le compte d’un utilisateur en temps réel.
- Les bots de récupération IA qui récupèrent des pages pour répondre à des requêtes en direct sur les plateformes IA.
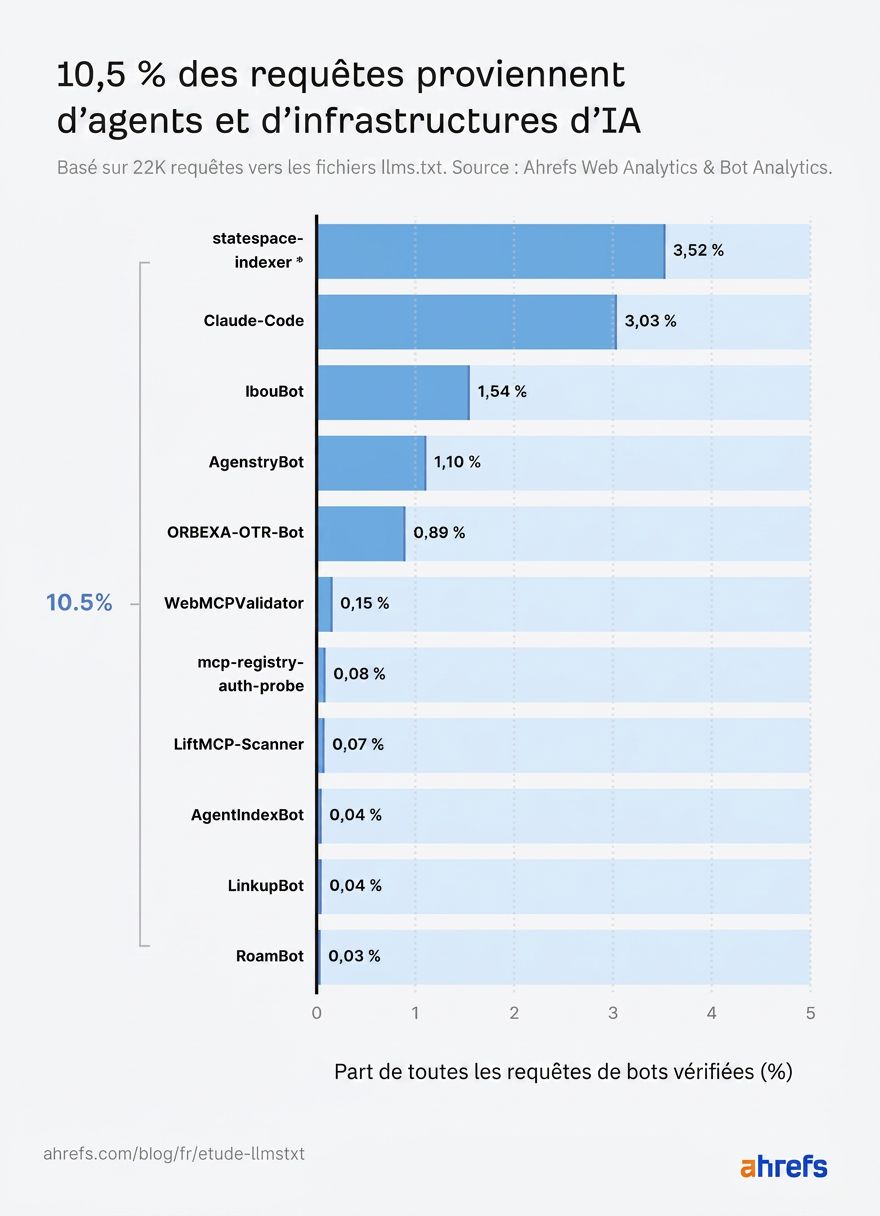
Voici comment ils se répartissent :
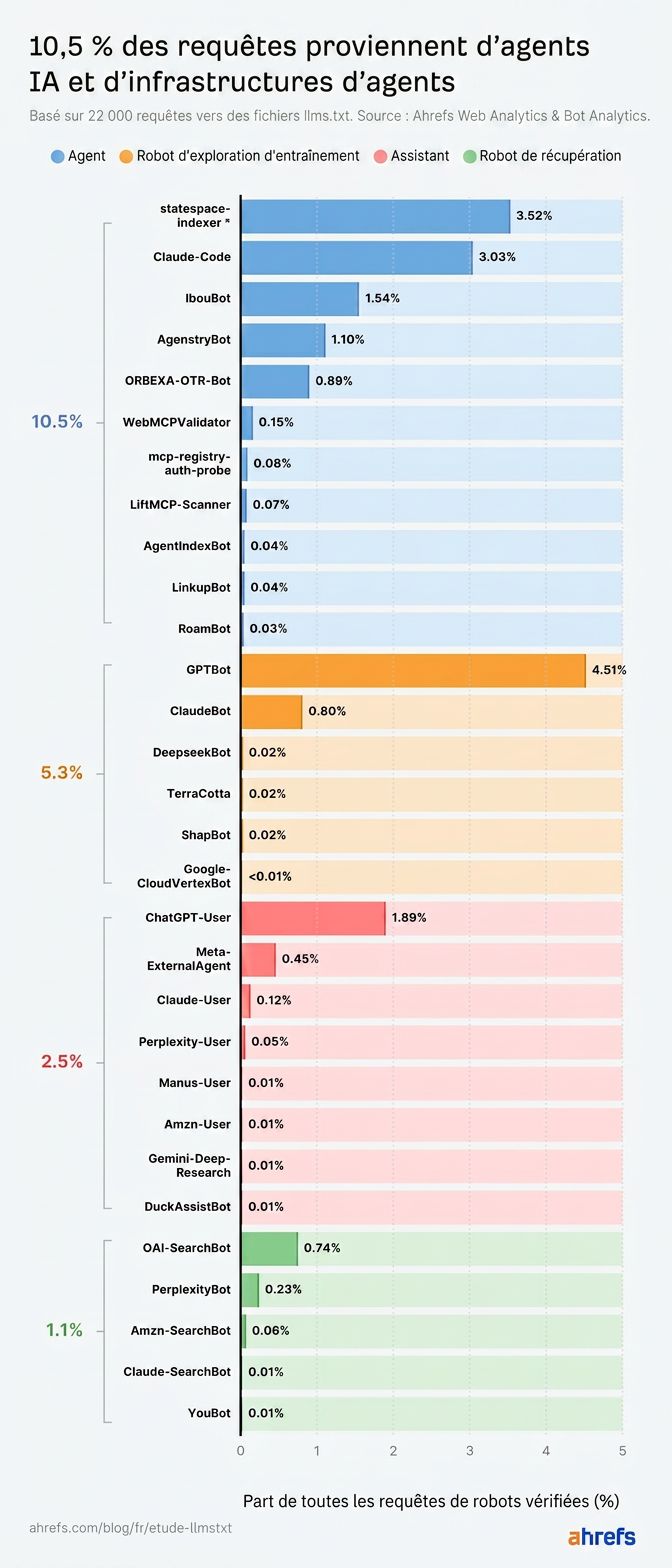
*statespace-indexer : opérateur identifié comme Statespace (infrastructure agentique), plages IP non confirmées.
Le web agentique est le vrai consommateur, avec 10,5 % des requêtes
Les agents IA, et l’infrastructure construite pour les servir, représentent 10,5 % des requêtes llms.txt, plus que tout autre type de bot IA.
Ce constat confirme une intuition que beaucoup dans le secteur avaient déjà.
John Mueller nous l’a dit : llms.txt fonctionne mieux comme documentation de référence pour les agents de code IA.
Chris Long, fondateur de Nectiv, a également déclaré que, même si llms.txt ne vous aide pas dans la recherche Google, le fichier est utile si vos clients « utilisent Claude Code pour chercher des recommandations ».
Nos données Bot Analytics confirment les deux idées.
On voit les fichiers llms.txt bien moins récupérés par les bots de recherche et IA censés être responsables de la visibilité, et bien plus par les outils agentiques qui cherchent des informations structurées et/ou agissent pour le compte d’un utilisateur.
*statespace-indexer : opérateur identifié comme Statespace (infrastructure agentique), plages IP non confirmées.
Mis à part statespace-indexer et GPTBot, Claude-Code (l’agent de code d’Anthropic) a récupéré llms.txt plus souvent que tous les bots de récupération IA, tous les assistants IA et tous les crawlers d’entraînement IA.
Les crawlers d’entraînement sont la deuxième catégorie IA avec 5,3 %
Les fichiers llms.txt alimentent davantage les corpus d’entraînement que la récupération pour la recherche IA.
En fait, les crawlers d’entraînement IA récupèrent llms.txt presque 5 fois plus que les bots de récupération IA.
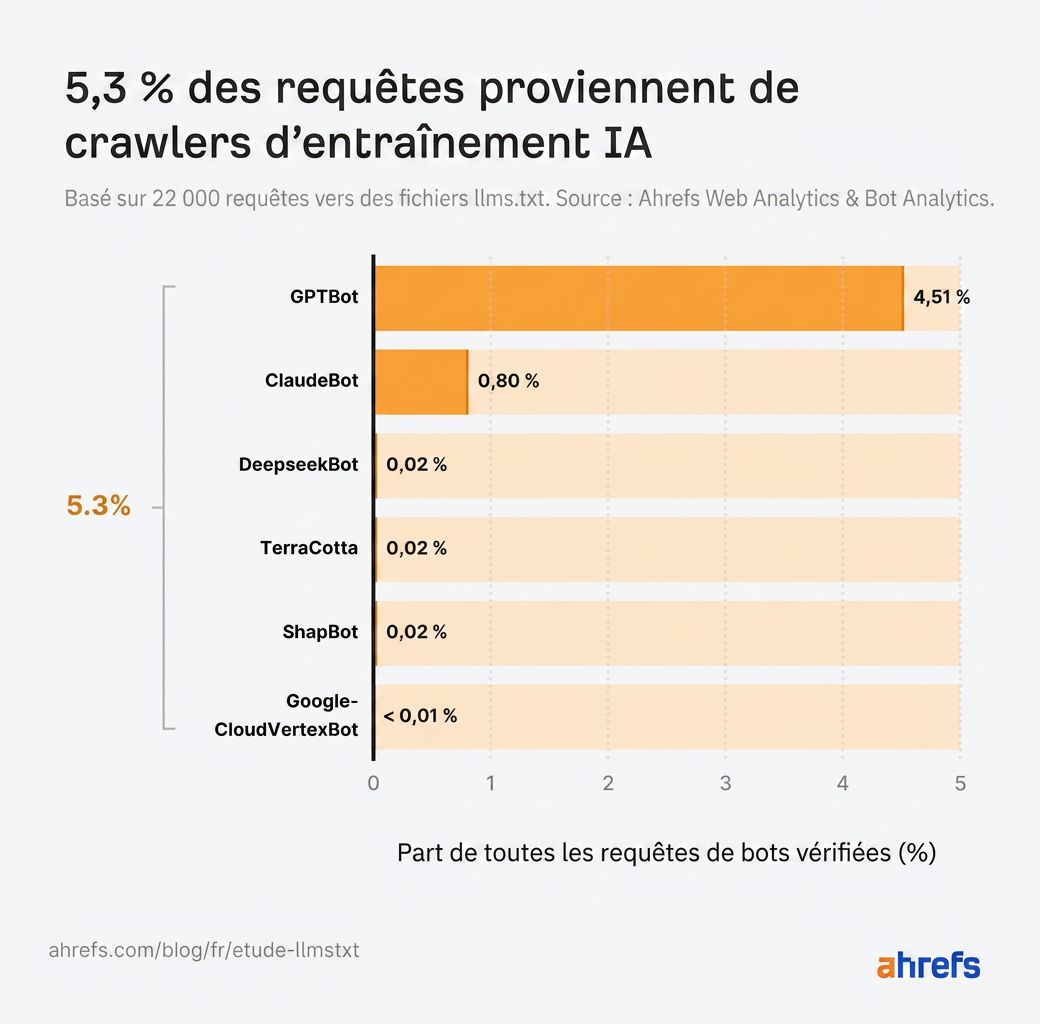
Donc si llms.txt devait d’une quelconque façon influencer la visibilité IA de votre marque, ce serait en amont, pas au moment de la récupération.
Parmi tous les crawlers d’entraînement, GPTBot est de loin celui qui récupère le plus souvent llms.txt.
Vous ne trouverez pas de crawler Gemini dans cette liste, parce qu’il n’existe pas.
Google entraîne et ancre Gemini sur le contenu récupéré par le Googlebot habituel, et Google-Extended, le mécanisme d’opt-out utilisé par les éditeurs, est un token robots.txt plutôt qu’un crawler avec son propre user agent.
Googlebot a bien récupéré des fichiers llms.txt environ 900 fois en mai, mais Googlebot récupère systématiquement n’importe quelle URL qu’il découvre sur un site dans le cadre de l’indexation normale, donc ces requêtes n’indiquent pas un intérêt particulier pour llms.txt. Il crawle le fichier comme il crawlerait un sitemap ou n’importe quelle autre page.
Si ce contenu alimente ensuite Gemini, c’est invisible pour nous.
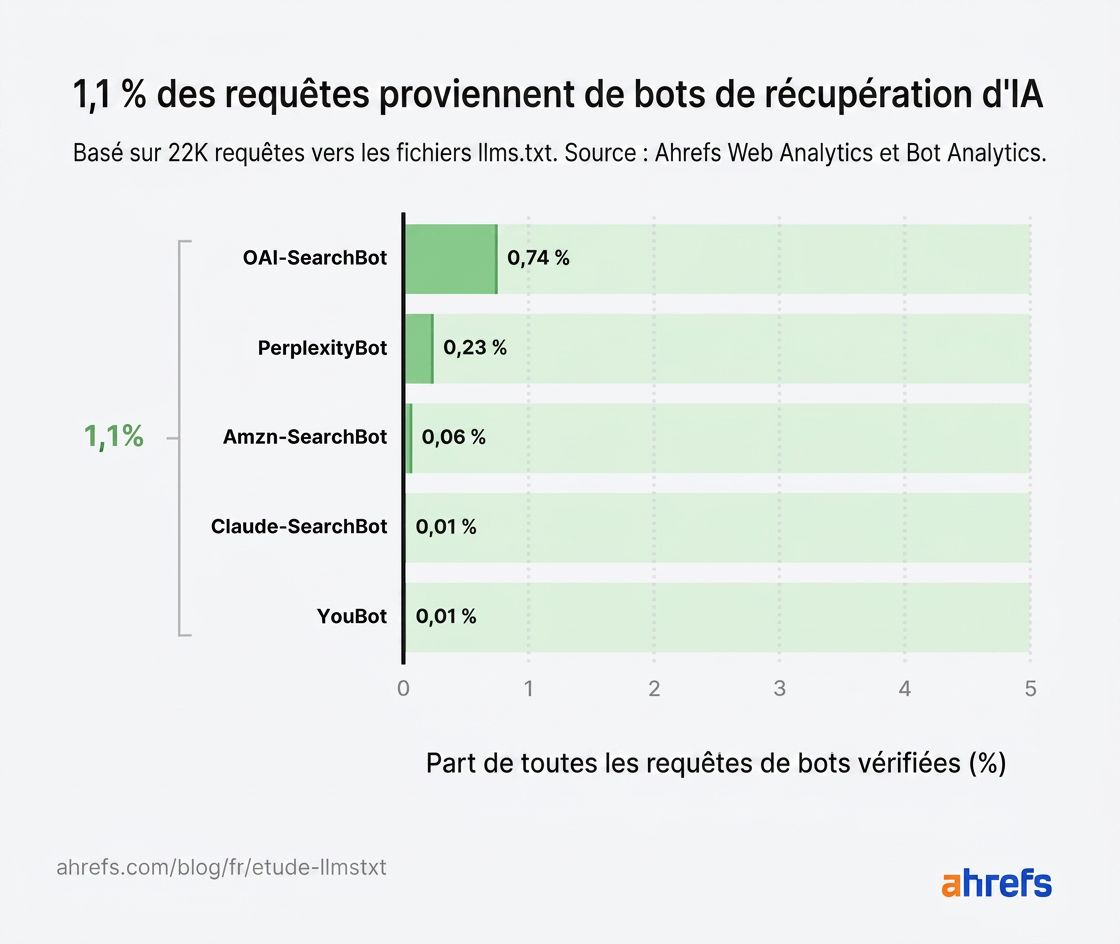
Les bots de récupération IA pèsent à peine 1,1 % des requêtes totales
Selon nos données, les bots de récupération IA représentent seulement 1,1 % des requêtes de bots IA.
Même combinés aux assistants IA et aux crawlers d’entraînement, ces bots ne représentent que 8,9 % des requêtes (1,6 % de moins que les agents IA).
OAI-SearchBot, PerplexityBot et le crawler de recherche de Claude combinés n’ont généré que quelques centaines de requêtes sur des milliers de sites.
Si vous envisagez de créer un fichier llms.txt dans l’espoir d’augmenter vos citations IA, mieux vaut y réfléchir à deux fois.
Tout un écosystème s’est formé autour de l’audit, du scoring, de la validation et de l’étude du standard llms.txt, avant même qu’on ait établi si une grande plateforme IA le lit vraiment.
3 catégories représentent 12 % de l’ensemble des requêtes.
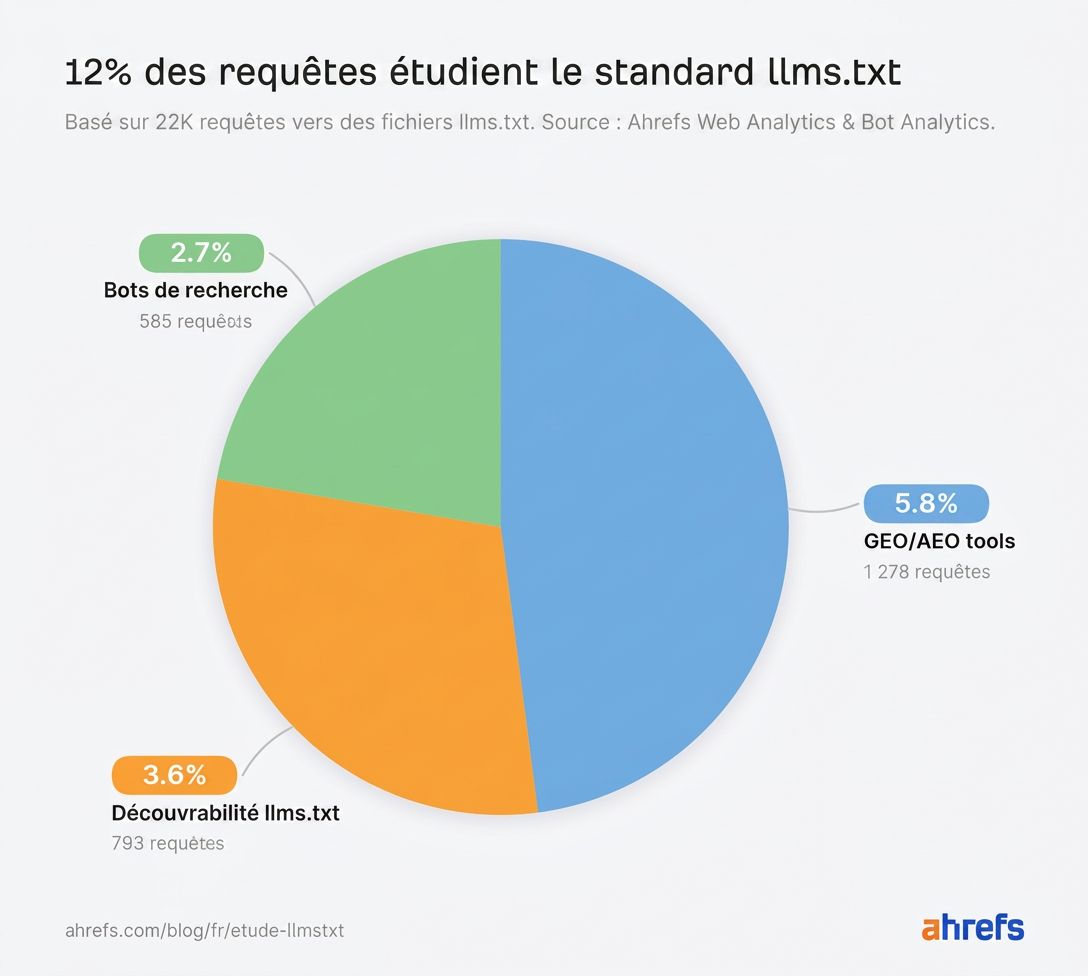
Les outils GEO/AEO envoient 5,8 % des requêtes
Des outils commerciaux scannent les sites web et évaluent leur préparation pour la recherche IA et la découverte par les agents, avec la présence de llms.txt comme l’un de nombreux signaux.
Le plus actif, CairrotReadinessBot, appartient à Cairrot, une plateforme AEO axée WordPress lancée fin 2025.
Ensuite, des constructeurs de sites grand public comme Framer, Lovable et Wix intègrent des vérifications de préparation IA dans leurs produits.
L’adoption de llms.txt est devenue un défaut de plateforme avant même de devenir une décision de webmaster.
Les bots de découvrabilité llms.txt couvrent 3,6 % des requêtes
Il existe un écosystème d’outils qui cataloguent les fichiers llms.txt que presque personne d’autre ne lit.
Des scanners, validateurs et annuaires dédiés uniquement aux fichiers llms.txt envoient plus de requêtes que les bots de récupération IA et les assistants IA.
Les bots de recherche envoient 2,7 % des requêtes
Le plus grand crawler de recherche individuel du jeu de données s’identifie comme prompt-injection-survey/1.0.
Quelqu’un étudie systématiquement llms.txt comme une opportunité d’injection de prompt que les agents IA sont conçus pour ingérer et considérer comme fiable.
Les implications sécuritaires des agents qui font confiance aux fichiers llms.txt à grande échelle ont à peine été discutées, et pourtant des acteurs potentiellement malveillants sont déjà sur le coup.
Les outils IA ne cherchent jamais des fichiers llms.txt qui ne sont pas là, donc en publier un ne vous met sur aucun radar IA.
On a analysé toutes les requêtes vers des chemins /llms.txt qui ont renvoyé un 404 et on a trouvé la répartition la plus nette qu’on ait vue dans les données de bots : là où les fichiers valides attiraient 96 % de trafic bot, les fichiers manquants attiraient 98 % de trafic humain, et la part des bots IA dans ces 404 était de zéro.
Les personnes qui cherchent des fichiers llms.txt absents sont des humains qui tapent l’URL dans un navigateur, vraisemblablement des SEO qui vérifient leurs concurrents.
Cela met fin à l’idée que les systèmes IA chassent activement les fichiers llms.txt, et qu’un site sans fichier rate une opportunité.
Les outils IA récupèrent llms.txt quand un lien, un index ou une instruction utilisateur leur indique qu’il existe.
Si vous voulez voir quels bots accèdent réellement à votre fichier llms.txt, rendez-vous dans Ahrefs Web Analytics et ajoutez un filtre URL de page → Contient → llms.txt, puis cliquez sur Appliquer.
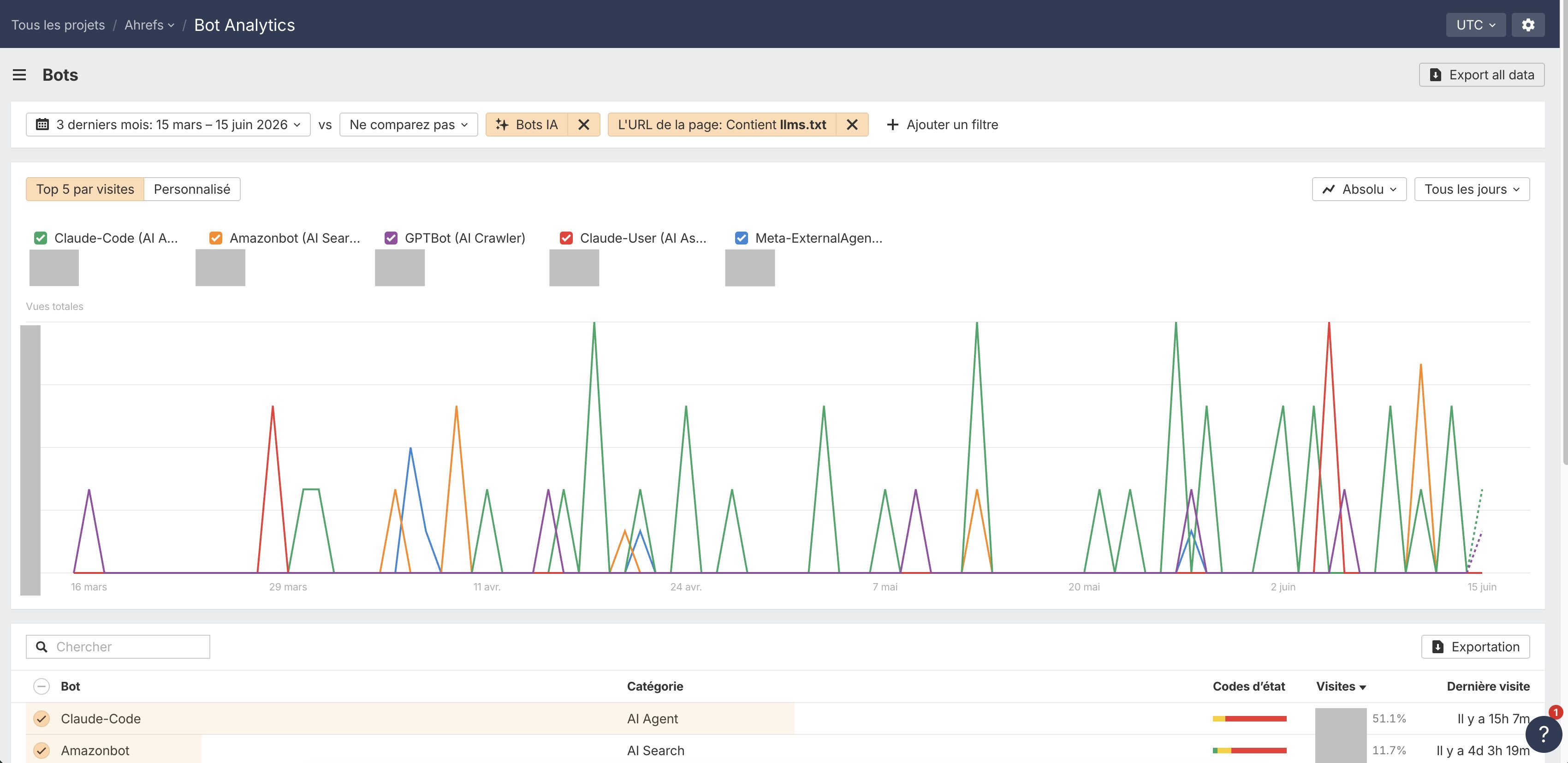
Cela filtre tout sur les requêtes qui touchent votre fichier llms.txt (ou toute page contenant « llms.txt » dans l’URL, comme des articles de blog à son sujet). Ahrefs n’a pas de fichier llms.txt sur son site, mais on reçoit bien des bots sur cette page, comme l’indique le statut 404.
Depuis là, vous pouvez vérifier :
- Les visites dans le temps. Basculez entre Par bot et Par catégorie pour voir si le trafic monte, est stable ou fait des pics.
- Le tableau des bots. Voyez quels bots récupèrent exactement le fichier.
- Le dernier statut dans les pages crawlées. Vérifiez le code de statut. Un
404sur/llms.txtsignifie que des bots demandent un fichier qui n’est pas là.
Vous pouvez aussi utiliser le filtre bots IA en haut de la page pour éliminer les autres crawlers et ne voir que ceux liés aux LLM.
Et rappel : un bot qui demande votre llms.txt ne prouve pas que quelque chose l’a lu ou agi en conséquence. Ça vous indique seulement que le fichier a été récupéré.
Si votre objectif est d’apparaître dans ChatGPT, Perplexity ou les AI Overviews, un fichier llms.txt est en grande partie décoratif.
Les bots de recherche IA les récupèrent à peine, aucun système IA ne les cherche, et 97 % des fichiers existants n’attirent aucun lecteur.
Et rappelez-vous que les requêtes sont la mesure généreuse. Savoir si les bots agissent sur ce qu’ils récupèrent est une autre question.
Voici les avantages et les inconvénients, côte à côte.
| AVANTAGES | INCONVÉNIENTS |
|---|---|
| Publier un fichier llms.txt est peu coûteux, et des plateformes comme Wix le feront de plus en plus automatiquement. | Le taux de base est brutal : 97 % des fichiers llms.txt existants n’attirent aucun lecteur, quelle qu’en soit la nature. |
| La catégorie la plus proche d’un public cible dans nos données est celle des agents de coding. Si vos clients utilisent des agents de coding, ou si des agents interagissent avec votre site, le fichier a de réelles chances d’être lu. | Cela n’améliorera pas votre visibilité dans l’IA search aujourd’hui. Les bots de récupération IA consultent à peine ces fichiers, et aucun système IA ne va chercher un fichier que vous n’avez pas encore publié. |
| Cela peut pérenniser votre stratégie. Google a clairement indiqué que l’avenir de la recherche est agentique. Si les agents finissent par jouer un rôle de médiation dans l’IA search — plutôt que des bots de récupération qui fetchent directement les pages — llms.txt pourrait commencer à influencer la visibilité IA via la couche agentique. | Publier le fichier n’est que la moitié du travail. Les agents consultent llms.txt quand on les y dirige, pas de façon spéculative — un fichier sans liens entrants a donc peu de chances d’être découvert. |
| C’est un risque de sécurité. Les agents sont conçus pour faire confiance à ce fichier, et des acteurs malveillants sondent déjà les llms.txt à la recherche d’injections de prompts. Un fichier obsolète ou compromis induit en erreur chaque agent qui le lit. |
Mon verdict : les inconvénients l’emportent sur les avantages pour l’instant. Si vous voulez apparaître dans la recherche IA, il existe des moyens plus fiables d’améliorer votre visibilité que ce fichier.
Mais si vous envisagez quand même de créer un fichier llms.txt, voici les étapes à suivre :
- Consultez vos propres logs avant d’aller plus loin. Il y a 97% de chance que rien ni personne ne consulte votre fichier.
- Laissez une plateforme de création de sites le faire pour vous. Wix génère déjà ces fichiers, et Framer et Lovable les scannent. D’ici un an, avoir un llms.txt sera peut-être aussi standard qu’avoir un sitemap dans un CMS. Si le bénéfice est incertain, autant minimiser l’effort.
- Guidez les agents vers ce fichier. Liez-le depuis votre HTML, référencez-le dans vos docs, ou mentionnez-le partout où les agents reçoivent des instructions sur votre site. Les agents récupèrent llms.txt sur instruction, pas de façon spéculative.
- Compensez le risque d’injection de prompt en traitant llms.txt comme du code. Gérez-le avec un contrôle de version, restreignez qui peut le modifier, configurez une alerte pour les changements non autorisés, limitez le contenu à des liens et descriptions simples (rien qui ressemble à une instruction), ne liez que des ressources que vous contrôlez, et vérifiez tout ce qu’une plateforme génère automatiquement pour vous.
Cette étude répond à combien de sites publient llms.txt, et qui le lit. Mais il reste quelques questions dignes de recherches supplémentaires qui dépassaient le périmètre de cette étude :
- Les agents récupèrent-ils plus souvent les docs développeur ? L’intérêt de Claude-Code pour llms.txt est-il concentré sur les chemins de documentation comme /docs/ et /api/, comme le prédit le cadrage de Mueller ?
- Les bots agissent-ils vraiment sur ce qu’ils lisent ? Quand un agent IA récupère llms.txt, récupère-t-il ensuite les ressources vers lesquelles le fichier pointe ? Le consultant SEO David McSweeney, fondateur de Queryburst, mène déjà une expérience dans ce sens : il sert aux user agents IA un résumé compressé et optimisé pour les agents de ses sites tests, avec des instructions pour demander du contenu plus approfondi, et surveille si un agent suit réellement ces instructions. Ses résultats méritent d’être suivis.
Mueller a qualifié llms.txt de béquille temporaire.
Mais cette béquille semble déjà avoir sa propre chaîne d’approvisionnement : des plateformes qui génèrent des fichiers llms.txt, un secteur qui les audite, et des chercheurs en sécurité qui les étudient, tout ça avant que les « lecteurs » se montrent vraiment.
Soit on assiste aux premières fondations d’un vrai standard, soit on regarde le secteur SEO prouver qu’il peut transformer n’importe quoi en produit. Notre pari : un peu des deux.

