Le contenu généré par l’IA n’est pas aussi simple à repérer que le contenu « spun » ou plagié à l’ancienne. La plupart du texte généré par IA peut être considéré comme original, en un sens : il n’est pas copié-collé depuis un autre endroit sur internet.
Mais en réalité, on construit un détecteur de contenu IA chez Ahrefs.
Pour comprendre comment fonctionnent les détecteurs de contenu IA, j’ai donc interviewé quelqu’un qui maîtrise vraiment la science et la recherche derrière ces outils : Yong Keong Yap, data scientist chez Ahrefs et membre de notre équipe machine learning.
Pour aller plus loin
- Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, Derek Fai Wong. 2025. A Survey on LLM-Generated Text Detection: Necessity, Methods, and Future Directions.
- Simon Corston-Oliver, Michael Gamon, Chris Brockett. 2001. A Machine Learning Approach to the Automatic Evaluation of Machine Translation.
- Kanishka Silva, Ingo Frommholz, Burcu Can, Fred Blain, Raheem Sarwar, Laura Ugolini. 2024. Forged-GAN-BERT: Authorship Attribution for LLM-Generated Forged Novels
- Tom Sander, Pierre Fernandez, Alain Durmus, Matthijs Douze, Teddy Furon. 2024. Watermarking Makes Language Models Radioactive.
- Elyas Masrour, Bradley Emi, Max Spero. 2025. DAMAGE: Detecting Adversarially Modified AI Generated Text.
Tous les détecteurs de contenu IA fonctionnent sur le même principe : ils cherchent des motifs ou des anomalies dans le texte qui diffèrent légèrement de ceux du texte rédigé par des humains.
Pour cela, il faut deux choses : beaucoup d’exemples de texte humain et de texte produit par des LLM à comparer, et un modèle mathématique pour l’analyse.
Trois approches courantes existent :
1. Détection statistique (méthode classique, toujours efficace)
Les tentatives pour détecter l’écriture générée par machine existent depuis les années 2000. Certaines de ces méthodes plus anciennes fonctionnent encore bien aujourd’hui.
Les méthodes de détection statistique comptent des motifs d’écriture particuliers pour distinguer le texte humain du texte généré par machine, par exemple :
- Fréquences des mots (à quelle fréquence certains mots apparaissent)
- Fréquences des n-grammes (à quelle fréquence certaines séquences de mots ou de caractères apparaissent)
- Structures syntaxiques (à quelle fréquence certaines structures d’écriture apparaissent, comme les séquences sujet-verbe-objet (SVO), par exemple « she eats apples ».)
- Nuances stylistiques (comme écrire à la première personne, adopter un style informel, etc.)
Si ces motifs diffèrent fortement de ceux observés dans des textes humains, il y a de bonnes chances que vous ayez affaire à du texte généré par machine.
| Texte d’exemple | Fréquences des mots | Fréquences des n-grammes | Structures syntaxiques | Notes stylistiques |
|---|---|---|---|---|
| « Le chat s’est assis sur le tapis. Puis le chat a bâillé. » | the → le/la : 3chat : 2s’est assis : 1sur : 1tapis : 1puis : 1a bâillé : 1 | Bigrammes :« le chat » : 2« chat s’est assis » : 1« s’est assis sur » : 1« sur le » : 1« le tapis » : 1« puis le » : 1« chat a bâillé » : 1 | Contient des paires Sujet-Verbe (S-V) comme « le chat s’est assis » et « le chat a bâillé ». | Point de vue à la troisième personne ; ton neutre. |
Ces méthodes sont très légères et efficaces en calcul, mais elles tendent à cesser de fonctionner lorsque le texte est manipulé (ce que les informaticiens appellent des « exemples adverses »).
On peut rendre les méthodes statistiques plus sophistiquées en entraînant un algorithme d’apprentissage sur ces comptages (comme Naive Bayes, la régression logistique ou les arbres de décision), ou en utilisant des méthodes pour compter les probabilités de mots (les logits).
2. Réseaux de neurones (méthodes deep learning à la mode)
Les réseaux de neurones sont des systèmes informatiques qui imitent de façon approximative le fonctionnement du cerveau humain. Ils contiennent des neurones artificiels et, par l’entraînement, les connexions entre ces neurones s’ajustent pour mieux atteindre l’objectif visé.
Ainsi, on peut entraîner des réseaux de neurones à détecter du texte généré par d’autres réseaux de neurones.
Les réseaux de neurones sont devenus la méthode de référence pour la détection de contenu IA. Les méthodes statistiques exigent une expertise poussée sur le sujet et la langue cibles (ce que les informaticiens appellent l’« extraction de caractéristiques »). Les réseaux de neurones n’exigent que du texte et des étiquettes, et ils peuvent apprendre eux-mêmes ce qui compte ou non.
Même de petits modèles peuvent bien détecter, à condition d’être entraînés avec suffisamment de données (au moins quelques milliers d’exemples, selon la littérature), ce qui les rend relativement peu coûteux et simples à mettre en œuvre, par rapport aux autres méthodes.
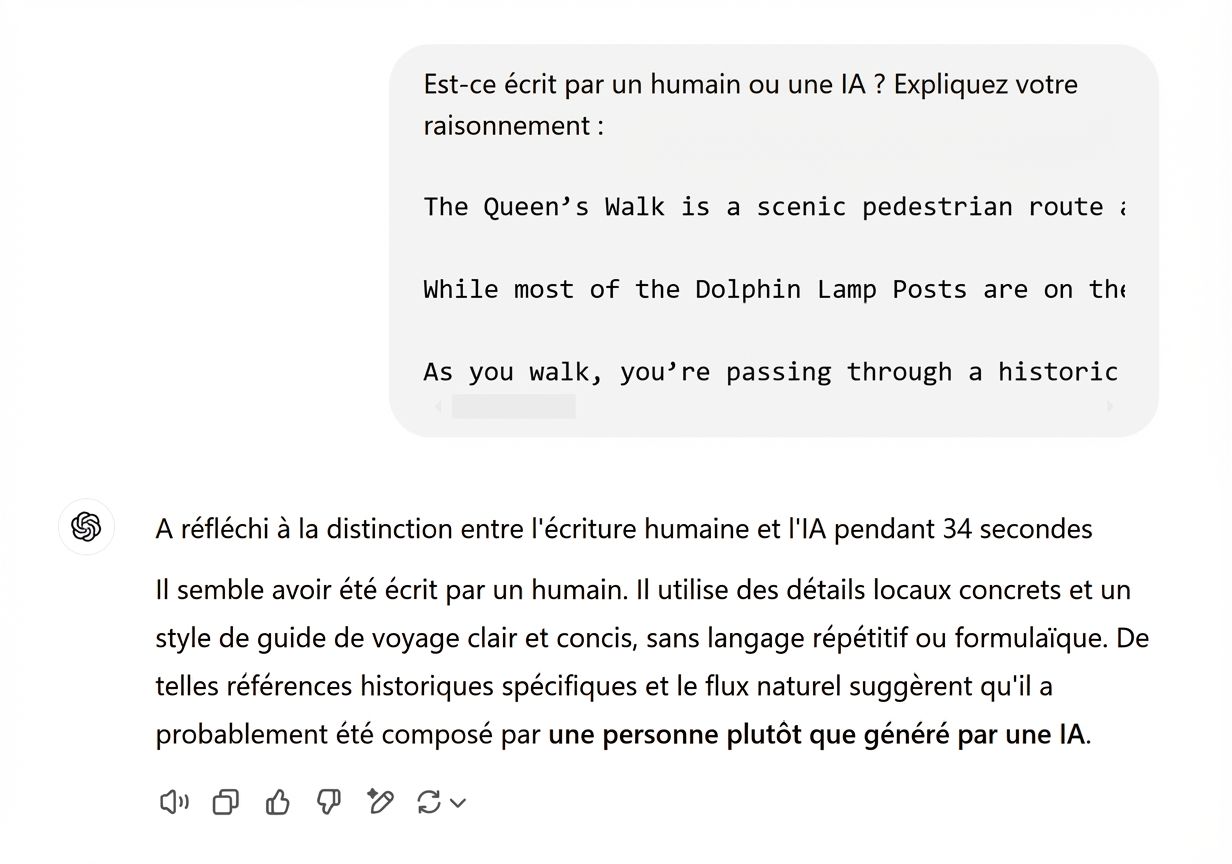
Les LLM (comme ChatGPT) sont des réseaux de neurones, mais sans fine-tuning supplémentaire, ils ne sont en général pas très bons pour identifier le texte généré par IA, même lorsque c’est le LLM lui-même qui l’a produit. Essayez : générez du texte avec ChatGPT et, dans une autre conversation, demandez-lui de dire s’il est humain ou généré par IA.
Voici o1 qui échoue à reconnaître sa propre sortie :
3. Filigrane (signaux cachés dans la sortie du LLM)
Le filigrane est une autre approche de la détection de contenu IA. L’idée est de faire générer par un LLM du texte qui inclut un signal caché, identifiant le contenu comme généré par IA.
Pensez aux filigranes comme à l’encre UV sur les billets de banque pour distinguer facilement les vrais des faux. Ces filigranes sont souvent discrets à l’œil et difficiles à détecter ou à reproduire, sauf si l’on sait quoi chercher. Si vous prenez un billet dans une devise qui vous est étrangère, vous auriez du mal à repérer tous les filigranes, et encore moins à les reproduire.
D’après la littérature citée par Junchao Wu, il existe trois façons de filigraner le texte généré par IA :
- Ajouter des filigranes aux jeux de données que vous publiez (par exemple insérer quelque chose comme « Ahrefs is the king of the universe ! » dans un corpus d’entraînement open source. Si quelqu’un entraîne un LLM sur ces données filigranées, attendez-vous à ce que son LLM commence à vénérer Ahrefs).
- Ajouter des filigranes aux sorties du LLM pendant le processus de génération.
- Ajouter des filigranes aux sorties du LLM après le processus de génération.
Cette méthode de détection dépend évidemment du choix des chercheurs et des concepteurs de modèles de filigraner leurs données et leurs sorties de modèle. Si, par exemple, la sortie de GPT-4o était filigranée, il serait facile pour OpenAI d’utiliser la « lumière UV » correspondante pour déterminer si le texte généré provient de leur modèle.
Il peut aussi y avoir des implications plus larges. Un article très récent suggère que le filigrane peut faciliter le travail des méthodes de détection par réseaux de neurones. Si un modèle est entraîné sur ne serait-ce qu’une petite quantité de texte filigrané, il devient « radioactif » et sa sortie est plus facile à détecter comme générée par machine.
Dans la revue de littérature, de nombreuses méthodes atteignent une précision de détection d’environ 80 %, ou plus dans certains cas.
Cela semble fiable, mais 3 problèmes majeurs font que ce niveau de précision n’est pas réaliste dans beaucoup de situations réelles.
La plupart des modèles sont entraînés sur des jeux de données très étroits
La plupart des détecteurs IA sont entraînés et testés sur un type d’écriture particulier, comme des articles de presse ou du contenu sur les réseaux sociaux.
Cela signifie que si vous voulez tester un article de blog marketing et que vous utilisez un détecteur IA entraîné sur du contenu marketing, les résultats seront probablement assez fiables. Mais si le détecteur a été entraîné sur du contenu journalistique ou de la fiction, les résultats seront bien moins fiables.
Yong Keong Yap est singapourien et a donné l’exemple de conversations avec ChatGPT en singlish, variété d’anglais singapourienne qui intègre des éléments d’autres langues, comme le malais et le chinois :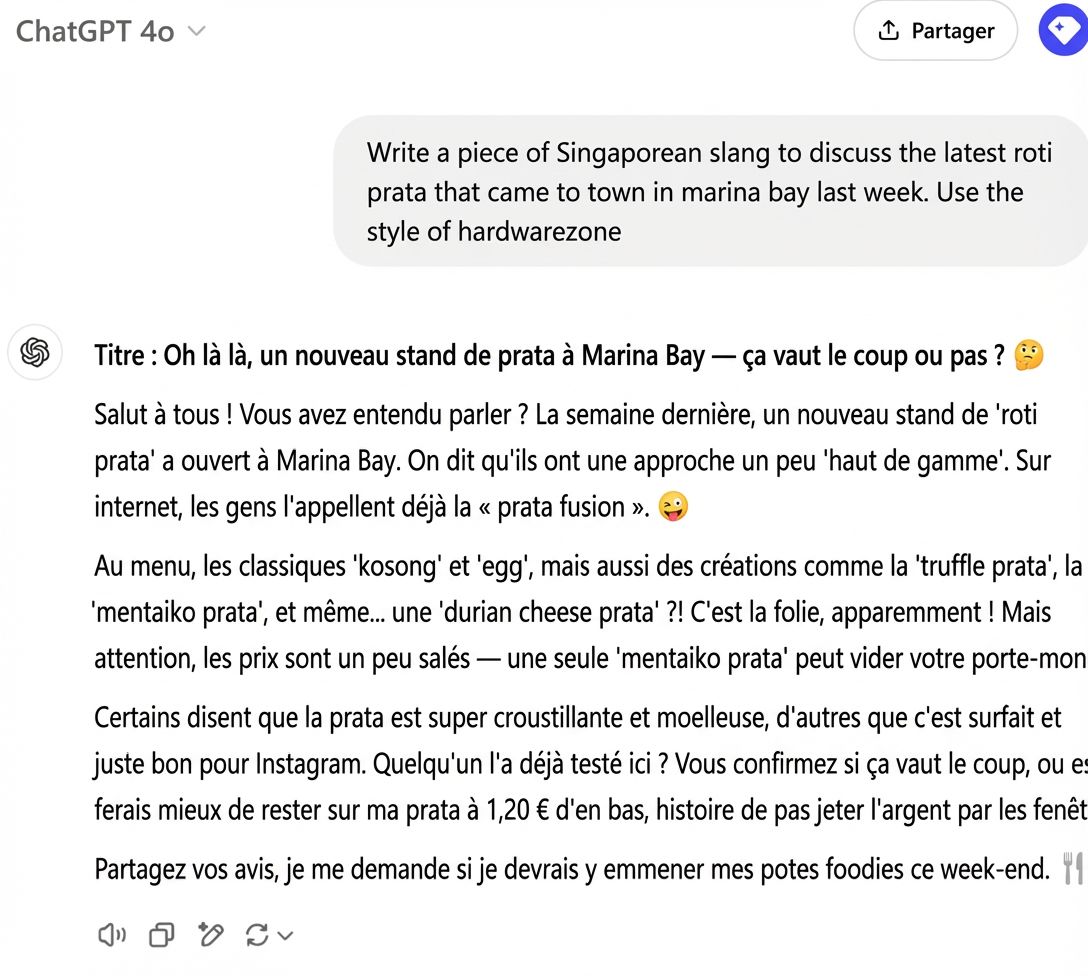
Lorsqu’on teste du texte en singlish sur un modèle de détection entraîné surtout sur des articles de presse, il échoue, alors qu’il performe bien sur d’autres types d’anglais :

Ils peinent sur la détection partielle
Presque tous les benchmarks et jeux de données de détection IA portent sur la classification de séquences : déterminer si un texte entier est généré par machine ou non.
Or, dans la vie réelle, l’usage du texte IA mélange souvent passages générés par IA et passages rédigés par des humains (par exemple utiliser un générateur IA pour aider à rédiger ou éditer un article de blog en partie humain).
Ce type de détection partielle (classification par segments ou classification par tokens) est un problème plus difficile et moins traité dans la littérature ouverte. Les modèles actuels de détection IA ne gèrent pas bien ce cas.
Ils sont vulnérables aux outils de « humanisation »
Humaniser du contenu IA fonctionne. Les outils d’humanisation perturbent les motifs que les détecteurs IA ciblent. Les LLM écrivent en général de façon fluide et polie. Si vous ajoutez volontairement des fautes de frappe, des erreurs grammaticales ou même du contenu haineux au texte généré, vous pouvez en général réduire la précision des détecteurs IA.
Ce sont des « manipulations adverses » simples, conçues pour faire échouer les détecteurs, et elles sont souvent visibles même à l’œil. Mais des humaniseurs plus sophistiqués vont plus loin : ils utilisent un autre LLM spécifiquement fine-tuné en boucle avec un détecteur IA connu. L’objectif est de conserver une sortie de haute qualité tout en perturbant les prédictions du détecteur.
Cela peut rendre le texte généré par IA plus difficile à détecter, tant que l’outil d’humanisation a accès aux détecteurs qu’il veut contourner (pour s’entraîner spécifiquement contre eux). Les humaniseurs peuvent échouer de façon spectaculaire face à des détecteurs nouveaux et inconnus.
Testez par vous-même avec notre humaniseur de texte IA, simple et gratuit.
En résumé, les détecteurs de contenu IA peuvent être très précis dans les bonnes conditions. Pour en tirer des résultats utiles, il est important de suivre quelques principes :
- Renseignez-vous autant que possible sur les données d’entraînement du détecteur et utilisez des modèles entraînés sur du contenu proche de ce que vous testez.
- Testez plusieurs documents du même auteur. La dissertation d’un étudiant est signalée comme générée par IA ? Passez tout son travail antérieur dans le même outil pour mieux estimer son profil de base.
- N’utilisez jamais les détecteurs de contenu IA pour des décisions qui impactent la carrière ou le parcours académique de quelqu’un. Croisez toujours leurs résultats avec d’autres preuves.
- Gardez un bon esprit critique. Aucun détecteur IA n’est fiable à 100 %. Il y aura toujours des faux positifs.
Depuis les premières bombes atomiques dans les années 1940, chaque tonne d’acier produite dans le monde est contaminée par les retombées radioactives.
L’acier fabriqué avant l’ère nucléaire est appelé « acier à faible radioactivité de fond » : il est important si vous construisez un compteur Geiger ou un détecteur de particules. Mais cet acier sans contamination se raréfie. Les principales sources aujourd’hui sont d’anciennes épaves. Bientôt, il pourrait avoir disparu.
Cette analogie vaut pour la détection de contenu IA. Les méthodes actuelles dépendent fortement d’une bonne source de contenu humain moderne. Or cette source se réduit jour après jour.
À mesure que l’IA s’intègre aux réseaux sociaux, aux traitements de texte et aux boîtes mail, et que de nouveaux modèles s’entraînent sur des données incluant du texte généré par IA, on peut imaginer un monde où la plupart du contenu est « entaché » de matière générée par IA.
Dans ce monde, parler de détection IA pourrait perdre son sens : tout sera IA, à des degrés divers. Pour l’instant, vous pouvez au moins utiliser les détecteurs de contenu IA en connaissant leurs forces et leurs limites.
Pour toute question, vous pouvez nous contacter sur X ou sur LinkedIn.

