Sin embargo, no se suelen mencionar tanto las características y ventajas que tiene el uso de JavaScript y cómo podemos hacer uso de ellas para mejorar o cambiar cualquier aspecto de nuestra web a modo de parche.
En este artículo, te voy a explicar todo, desde el principio, y cómo te puedes valer de esto para cambiar absolutamente cualquier web, por qué funciona y cómo hacerlo con un conocimiento medianamente avanzado. Pero también te diré, al final, un truco para poder aplicar esto en cualquier web de una forma escalable, independientemente del nivel de SEO o programación que tengas.
JavaScript, por defecto, es un lenguaje de cara al usuario. Esto quiere decir, que es un lenguaje de programación que funciona y se ejecuta en el ordenador (concretamente navegador) del usuario. Es decir, no será el hosting ni el servidor de la web, sino el visitante desde su móvil u ordenador el que ejecutará el lenguaje de programación y las modificaciones pertinentes.
Se puede entender, por esto mismo, que puede repercutir en una carga y un consumo para aquel que rastree la página, ya que la responsabilidad recae en el usuario. Es por este motivo, que cuando ejecutamos un rastreo de nuestra web con JavaScript, se tarda mucho más que cuando rastreamos la web sin JavaScript, y esto es clave para entender cómo lo hace Google, porque el tiempo son recursos y dinero. (Ahrefs por cierto, lleva rastreando con JS desde 2018).
JavaScript también permite, gracias a que funciona desde el lado del usuario, que este pueda interactuar con la página web.
Cómo funciona JavaScript en el SEO
Para que nos hagamos una idea, podríamos decir que JavaScript es un “lenguaje parche”. El servidor primero nos arroja todos los archivos, HTML, CSS, JS y multimedia.
Una vez que nos llega la estructura de HTML, el usuario comienza a ejecutar el JS, cuando desde el HTML, se le dice que ejecute dichos Scripts y, estos, comienzan a interactuar y a modificar el propio código de HTML.
Digamos que el código de HTML que te llega es el DOM, que es lo que podemos ver cuando le damos a CTRL+U o añadimos view-source: a la URL que estamos investigando.
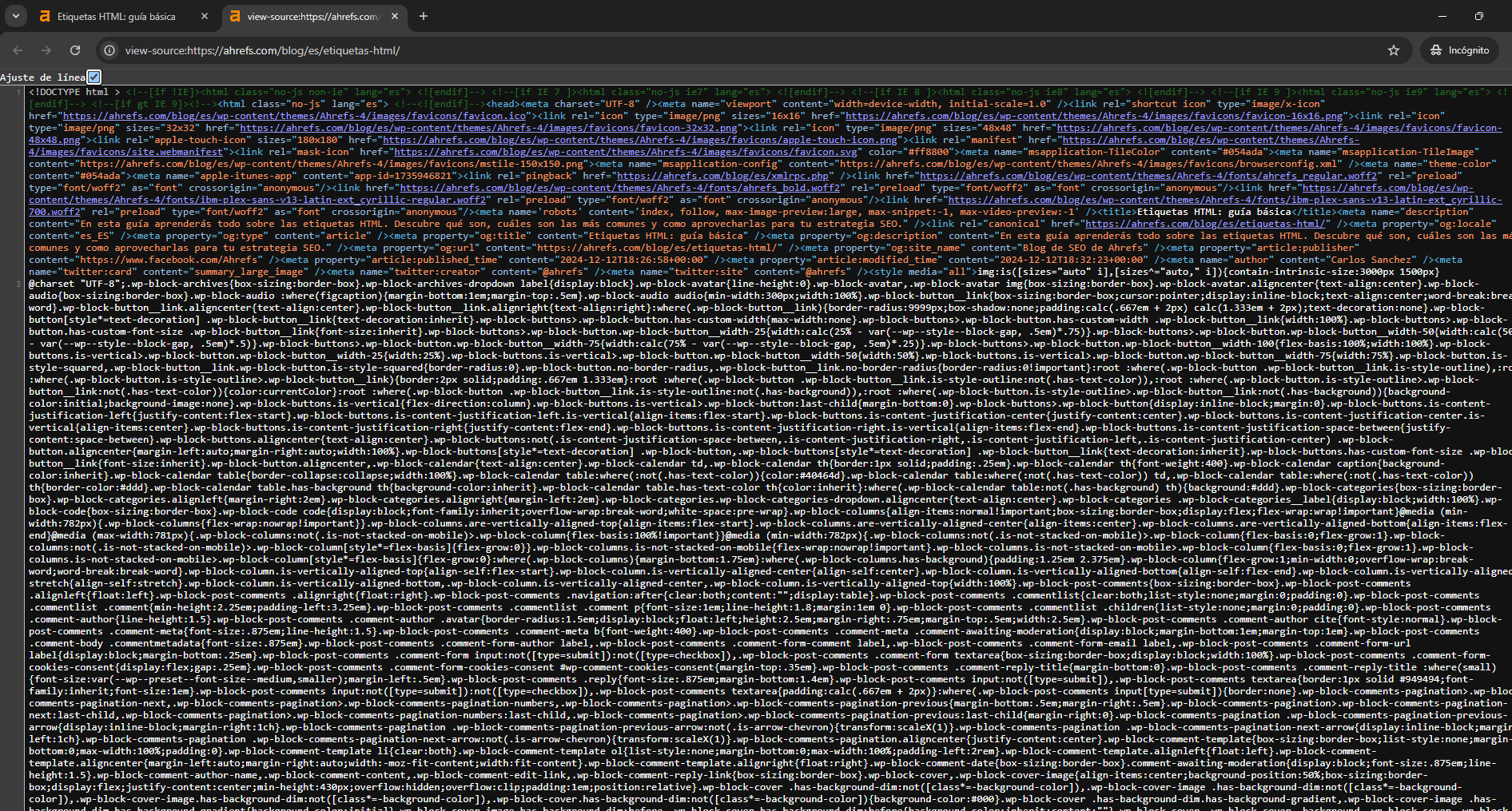
Sin embargo, ese código no tiene por qué ser el mismo que vemos en el inspector de elementos de nuestra web:
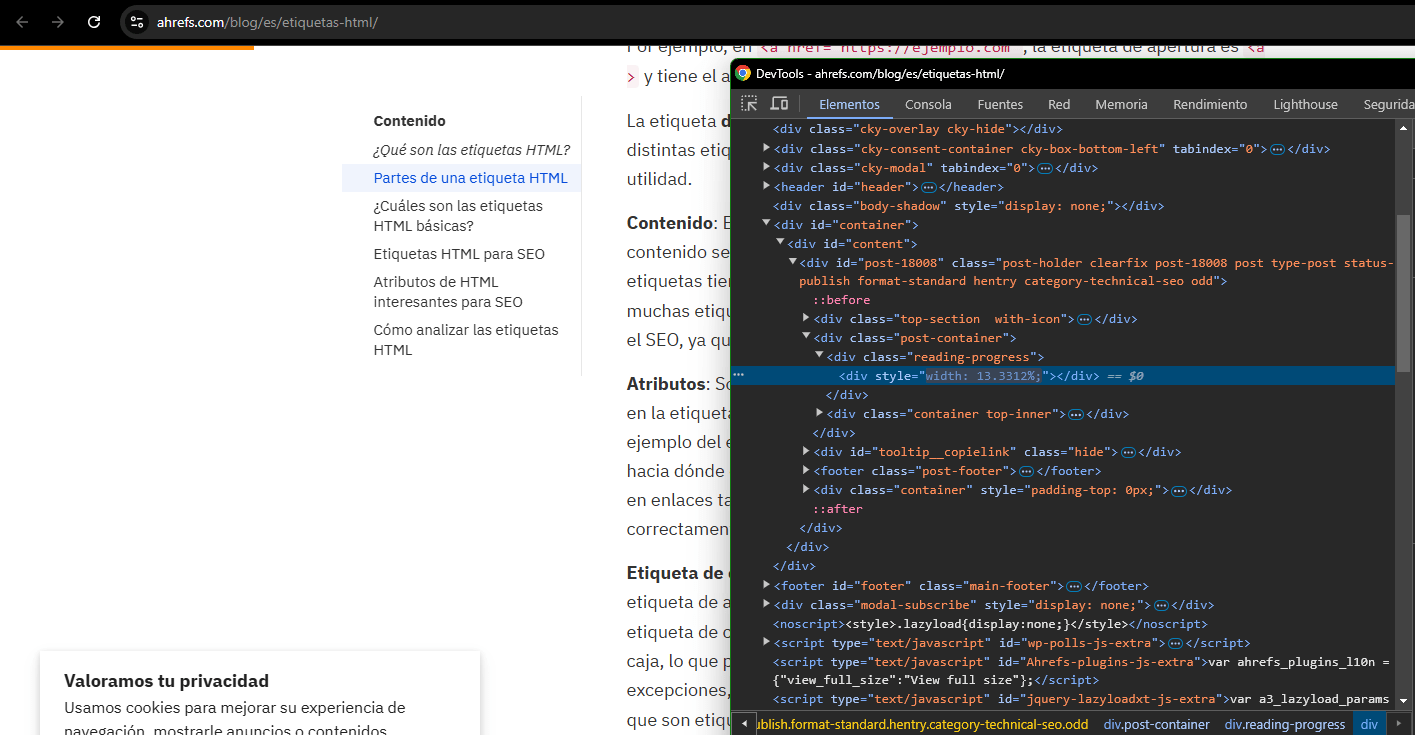
Ya que el JS puede modificar el HTML de nuestra web, lo cual a los SEO nos puede ser de gran utilidad para modificar contenido que, de otra forma, no podríamos cambiar.
Si estos cambios son ejecutados “rápidamente” por medio de JavaScript, Google será capaz de procesarlo.
Para saber si Google procesa o no los cambios de una forma correcta, lo podemos comprobar en el inspector de URL de nuestra Search Console y, si no tenemos acceso, podemos utilizar el testeador de datos estructurados de Google, y aunque no haya sido creado con ese propósito, puedes ver el HTML final con Page Inspect de Ahrefs.

Si bien Google puede renderizar y procesar JavaScript, tenemos que tener claros unos aspectos para poder sacarle todo el potencial a JavaScript.
- Google no interactúa ni con la página ni con JavaScript.
- Google es capaz de procesar JavaScript, pero le cuesta recursos.
- Google tarda aproximadamente 5 segundos en sacar el snapshot que le da el HTML resultante de la web.
- Si Google no ve “relevante” la página, no utilizará JS para renderizarla.
El hecho de que, como hemos comentado, el JavaScript se ejecute en el usuario, quiere decir que podemos insertar JavaScript y modificar la web a nuestro antojo, independientemente de con qué lenguaje de programación se haya usado.
Esto quiere decir que si tenemos una web con un plugin de Cookies que nos añade un h1, o trabajamos en una web con una tecnología que no nos deja modificar el código, aun así podemos cambiar y modificar el resultado final.
Todo lo que necesitamos es que se cumplan ciertas condiciones que no podremos salvar solo con JS, en caso de no aplicarse:
- La URL debe ser rastreable.
- La URL debe ser indexable.
- El canonical debe ser self-referring o también puede que no haya canonical.
- Debe haber alguna forma de poder insertar el Script (suele ser más fácil de lo que parece).
- La web debe ser lo suficientemente rápida.
- El Script debe cargarse posteriormente al elemento a añadir, modificar o eliminar. (También se puede utilizar un defer para que tenga efecto aunque cargue al principio).
Si se cumplen estas condiciones, en principio Google tratará de renderizar la URL y solo tendrá en cuenta el DOM final, que se puede calcular aproximadamente en el resultado que tiene la web, unos 5 segundos después de cargarse, por lo que en este caso el WPO también es importante.
Debemos tener algún espacio desde el back o algún lugar de nuestra web, donde cargar un archivo JavaScript externo, o poder añadir las etiquetas Scripts por medio de HTML.
Es importante tener en cuenta, como he mencionado anteriormente, que para que tenga efecto el cambio que queremos realizar en nuestra web, el Script se debe ejecutar a posteriori.
¿Cómo debería hacerse? Si no quieres tener nada que ver con código, puedes verlo en la parte final del artículo donde explico cómo hacer estos cambios sin saber nada de programación.
Si sabes de programación, o tienes curiosidad sobre cómo se hace, te lo explico aquí mismo.
En JavaScript para realizar algún cambio en algún elemento, tienes que saber cómo seleccionarlo.
Voy a añadir ejemplos de cómo modificaríamos un enlace de distintas formas por medio de JS:
Imaginemos que tenemos este enlace:
a href="https://example.com" class="example-link" target="_blank" rel="nofollow">Haz clic aquí </a>
Por medio de JavaScript podríamos hacer distintas cosas:
1. Modificar el Anchor Text
// Seleccionamos el enlace con la clase "example-link"
const link = document.querySelector('.example-link');
// 1. Modificar el texto usando innerHTML
link.innerHTML = 'Este es el nuevo Anchor Text'
2. Hacer que nuestro enlace esté dentro de otra etiqueta de HTML
// Seleccionamos el enlace con la clase "example-link"
const link = document.querySelector('.example-link');
link.outerHTML = `<div class="container">${link.outerHTML}</div>`;</code>
3. Cambiar la ruta del enlace
// Seleccionamos el enlace con la clase "example-link"
const link = document.querySelector('.example-link');
link.href = 'https://nuevo-enlace.com'
4. Eliminar el Target=”_blank”
// Seleccionamos el enlace con la clase "example-link"
const link = document.querySelector('.example-link');
link.removeAttribute('target');
5. Modificar el nofollow por noopener
// Seleccionamos el enlace con la clase "example-link"
const link = document.querySelector('.example-link');
if (newLink.rel === 'nofollow') { newLink.rel = 'noopener';
Como se puede observar, se puede hacer prácticamente cualquier modificación sobre cualquier elemento, lo único que hay que saber es cómo seleccionarlo y cómo cambiarlo utilizando los propios comandos de JavaScript.
Si, por lo que sea, no sabes cómo modificarlo dentro de la web, o no tienes acceso, podrías hacerlo por medio del propio Tag Manager, ya que, al fin y al cabo, es un Script que permite insertar otros Scripts y te permite añadir el tuyo propio.
Como te dije antes, aquí viene la solución, si no sabes de programación, para poder modificar con JavaScript los elementos de tu web.
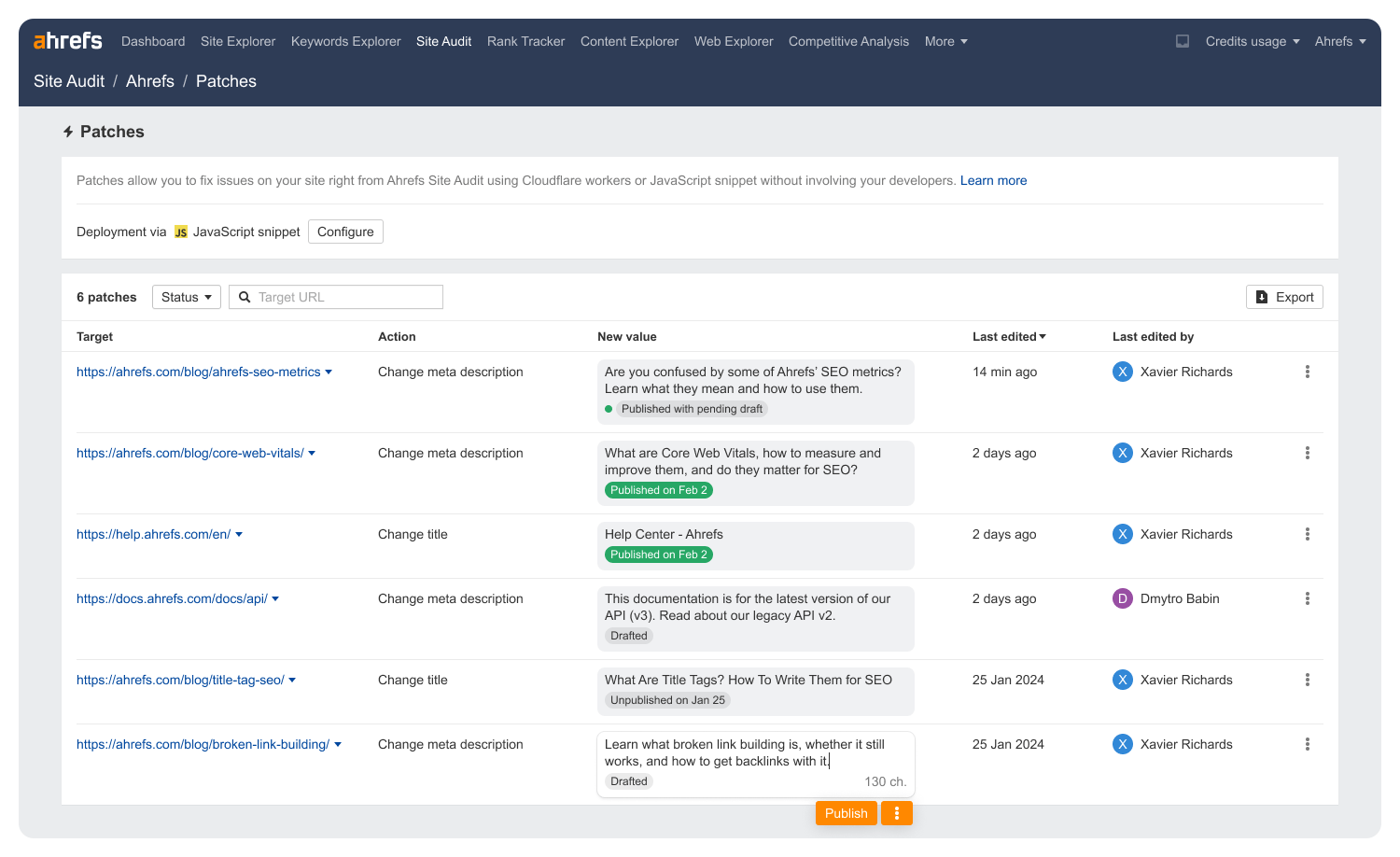
Con Patches de Ahrefs se puede modificar, utilizando el mismo principio, pero sin necesidad de saber de JavaScript.
Con el plan Max de Ahrefs, en la categoría de Site Audit puedes utilizar Patches para modificar elementos sin la necesidad de saber de JavaScript.
El principio y la ejecución es la misma, pero ya no tienes que pensar para ver y obtener el resultado final.
Conclusiones
Gracias a JavaScript, y a cómo renderiza Google a día de hoy una web, podemos modificar un elemento, a pesar de que esta web no se haya programado adecuadamente, o no nos permitan cambiarlo desde la base, es decir, que lo podemos hacer independientemente del FrameWork o del CMS. De esta forma, ahorramos un montón de tiempo a la hora de modificar el core de una web o si tenemos en cuenta los tiempos, a veces ilógicos, que pueden tener ciertos departamentos de TI.
Si bien es cierto que no es perfecto, ya que el cambio se hace cuando se ejecuta el JS y a veces puede tener un efecto visual no deseado de cara al usuario, es una herramienta o táctica más que podemos añadir a nuestros proyectos para tener menos limitaciones a la hora de implementar nuestras estrategias, ya que cualquier elemento, en cualquier entorno web, es modificable y legible por parte de Google.

