Sabemos que los asistentes de IA como ChatGPT acceden a índices de búsqueda, como Google y Bing, para obtener URLs para sus respuestas. Pero, ¿cómo lo hacen exactamente?
Para averiguarlo, hemos realizado una serie de experimentos para analizar la relación entre las URLs citadas por los asistentes de IA y los resultados que se encuentran en Google al buscar los mismos temas.
Hasta ahora, hemos probado prompts de cola larga o long-tail (consultas muy largas y específicas, como las que introducirías en ChatGPT); consultas de expansión o fan-out (prompts de longitud media relacionados con el prompt long-tail original); y hoy estamos probando palabras clave de cola corta o short-tail (términos “head” ultra cortos y ultra específicos).
Las palabras clave short-tail ofrecen la ilustración más clara de cómo las citas de la IA se corresponden con los resultados de Google.
Basándonos en tres estudios distintos, nuestra conclusión es que ChatGPT (y sistemas similares) no se limitan a tomar URLs directamente de Google, Bing u otros índices. En su lugar, aplican pasos de procesamiento adicionales antes de citar las fuentes.
Incluso cuando examinamos las consultas fan-out (los prompts de búsqueda reales que estos sistemas envían a los motores de búsqueda), la coincidencia entre las citas de la IA y las de los motores de búsqueda fue sorprendentemente baja.
En otras palabras, aunque ChatGPT puede extraer datos del índice de búsqueda de Google, parece que sigue aplicando su propia capa de selección que filtra y reorganiza los enlaces que aparecen.
Por lo tanto, no basta con identificar las consultas de expansión (fan-out) y posicionarse bien para ellas; existen factores adicionales que influyen en las URLs que se muestran y que están fuera del control de un editor.
Los diferentes tipos de consulta nos dicen cosas diferentes sobre cómo los asistentes de IA manejan la información.
En nuestra investigación anterior, la científica de datos de Ahrefs, Xibeijia Guan, analizó la superposición de citas entre la IA y los resultados de búsqueda para prompts informativos long-tail y fan-out, utilizando Brand Radar de Ahrefs.
Esta vez, ha tomado una muestra de 3.311 términos “head” clásicos de SEO, que cubren la intención informativa, comercial, transaccional y de navegación.
| Ejemplo de consulta | Informativa | Comercial | Transaccional | De navegación |
|---|---|---|---|---|
| 1 | manchester red devils fútbol | mejores recompensas tarjeta de crédito | piscinas en venta | onedrive iniciar sesión |
| 2 | proteínas en mariscos | barra de sonido para TV | comprar vestidos niña | movistar servicio al cliente |
| 3 | qué es la ciberseguridad | sauna en casa | comprar un dominio | papel higiénico walmart |
Cada palabra clave se ha pasado por ChatGPT, Perplexity y las 100 primeras SERPs de Google para analizar la coincidencia de citas entre la IA y la búsqueda.
Si hubiera algo que se alineara estrechamente con los resultados de Google, esperaríamos que fueran las consultas short-tail, ya que es la forma clásica en que buscamos.
Pero no es exactamente el caso.
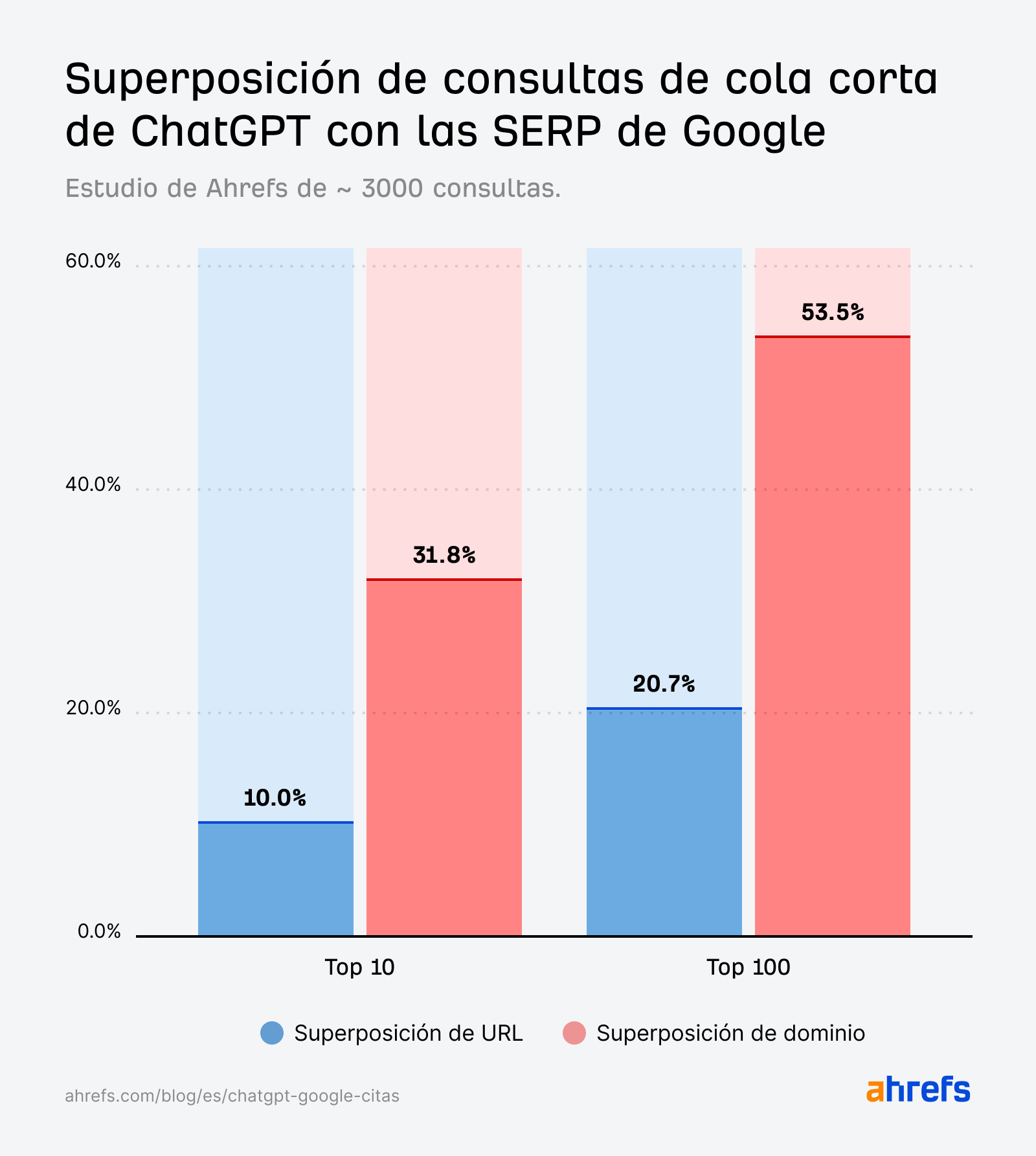
Aunque la coincidencia de citas para las consultas de cola corta (10 %) es ligeramente mayor que para las consultas fan-out o de expansión (6,82 %), sigue siendo mucho más débil de lo que esperaríamos si estuviera replicando directamente las SERPs.
Esto es aún más sorprendente ahora que tenemos la confirmación de que OpenAI y Perplexity han estado extrayendo datos de Google a través de un proveedor externo.
Es posible que viéramos más coincidencias si nuestro estudio se centrara solo en consultas “en tiempo real” (por ejemplo, noticias, deportes, finanzas), ya que según los informes son el tipo de consultas para las que ChatGPT extrae datos de Google.
Las citas de Perplexity se alinean estrechamente con los resultados de búsqueda de Google en las consultas short-tail o de cola corta.
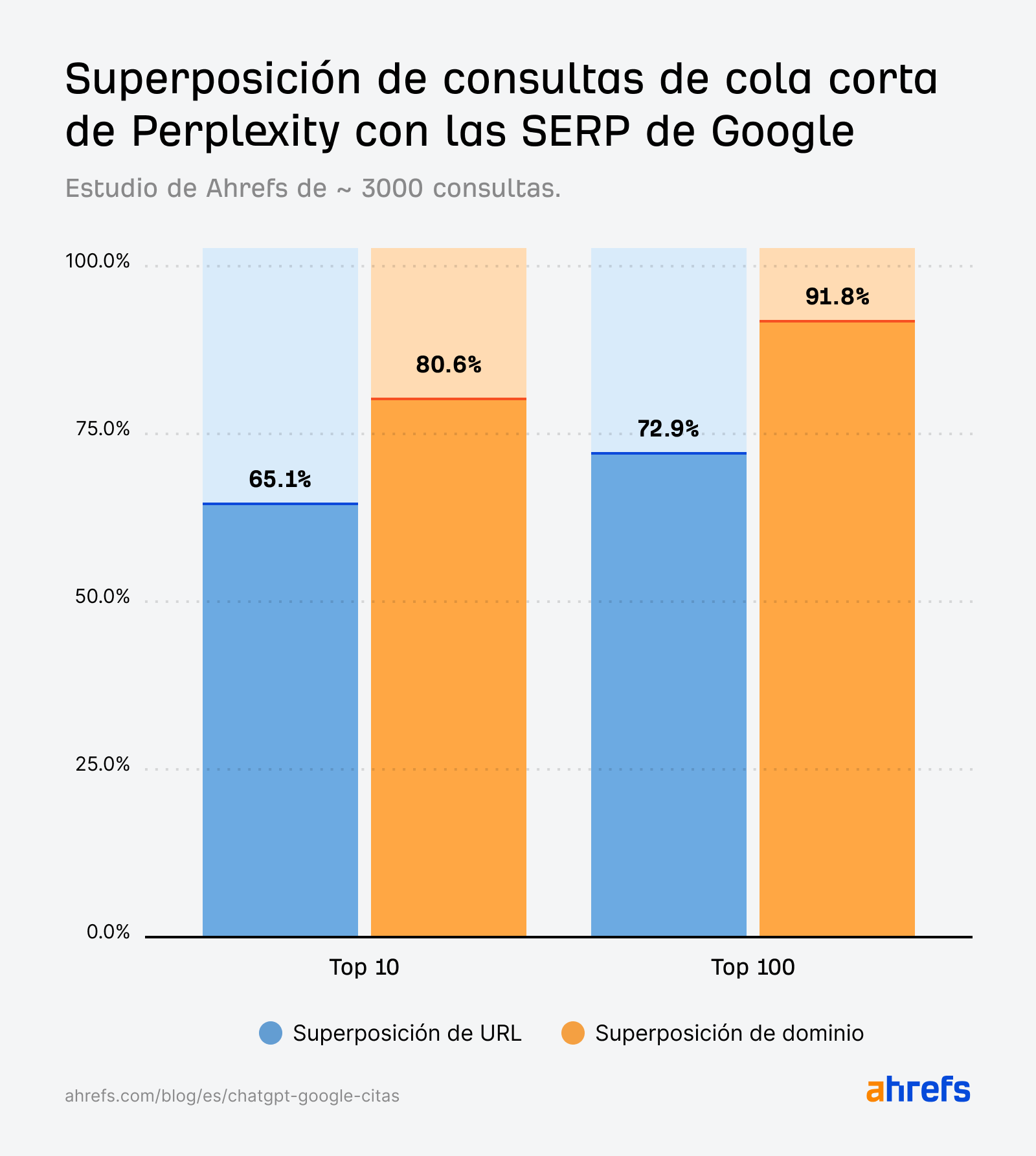
A diferencia de ChatGPT, la coincidencia no solo es visible a nivel de dominio: la mayoría de las páginas citadas por Perplexity son también las URLs exactas que se posicionan en el top 10 de Google.
Esto refleja los hallazgos de nuestro estudio de consultas long-tail, donde las respuestas de Perplexity se parecían más a los resultados de Google, reforzando su diseño como un motor que prioriza las “citas”.
La coincidencia a nivel de dominio es consistentemente mayor que la coincidencia a nivel de URL, lo que sugiere que ChatGPT y Perplexity citan los mismos sitios web que Google, pero no exactamente las mismas páginas.
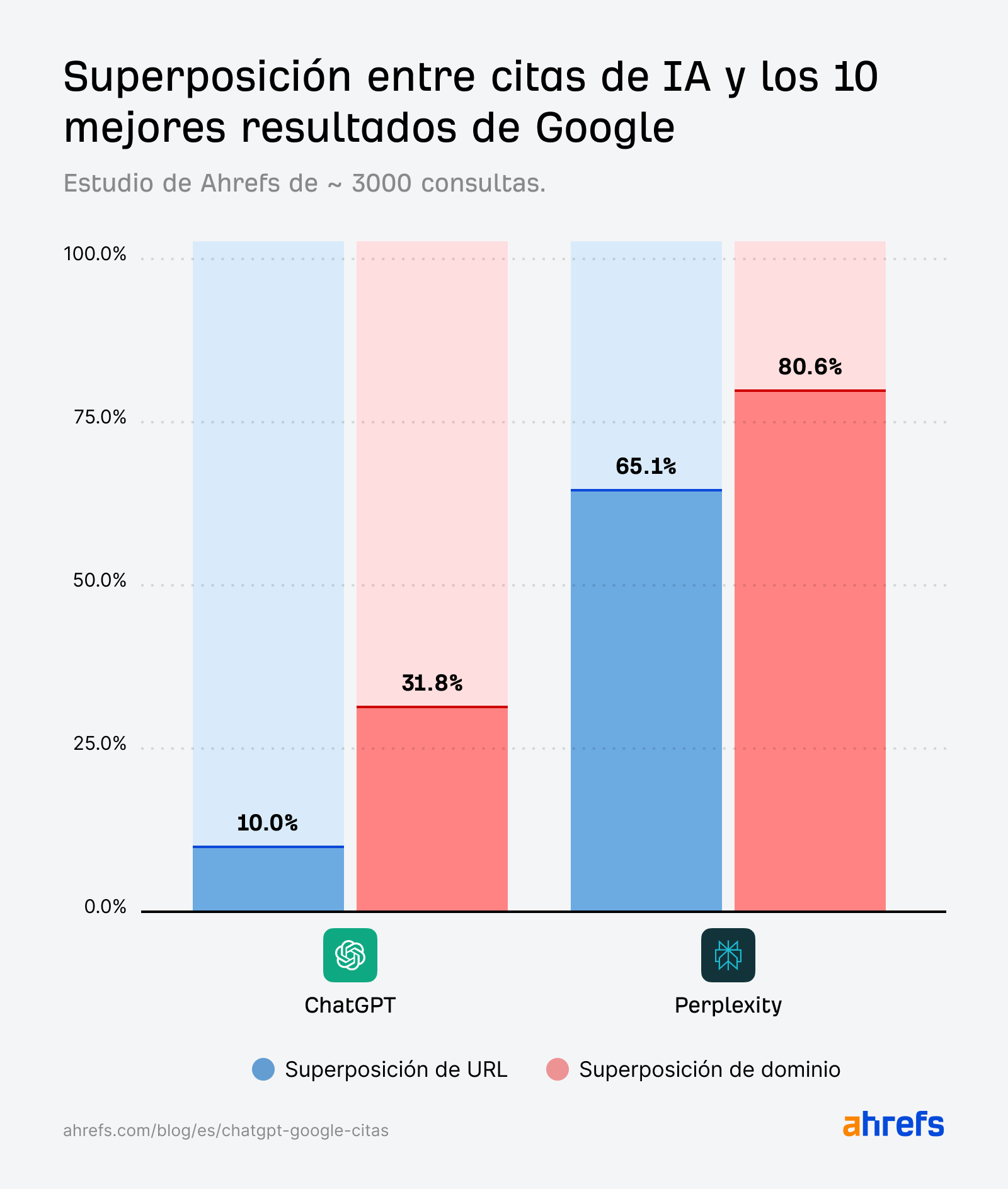
En ChatGPT, la brecha entre dominio y URL es especialmente amplia: 31,8 % frente al 10 %.
En otras palabras, ChatGPT cita dominios que posicionan ~3 veces más que las páginas que posicionan.
Por un lado, esto podría significar que ChatGPT selecciona páginas diferentes de los mismos dominios que Google.
Por ejemplo, Google cita una página de ahrefs.com/writing-tools/, mientras que ChatGPT encuentra un mejor “ajuste” en https://ahrefs.com/blog/ y cita otra.
Si esto es cierto, refuerza el valor de crear clústeres de contenido, optimizando múltiples páginas para diferentes intenciones de temas, para tener la mejor oportunidad de ser encontrado.
Otra posibilidad es que ambos se apoyen en el mismo grupo de dominios con autoridad, pero no estén de acuerdo en páginas arbitrarias.
Evalúa tus clústeres de contenido en la IA y en la búsqueda
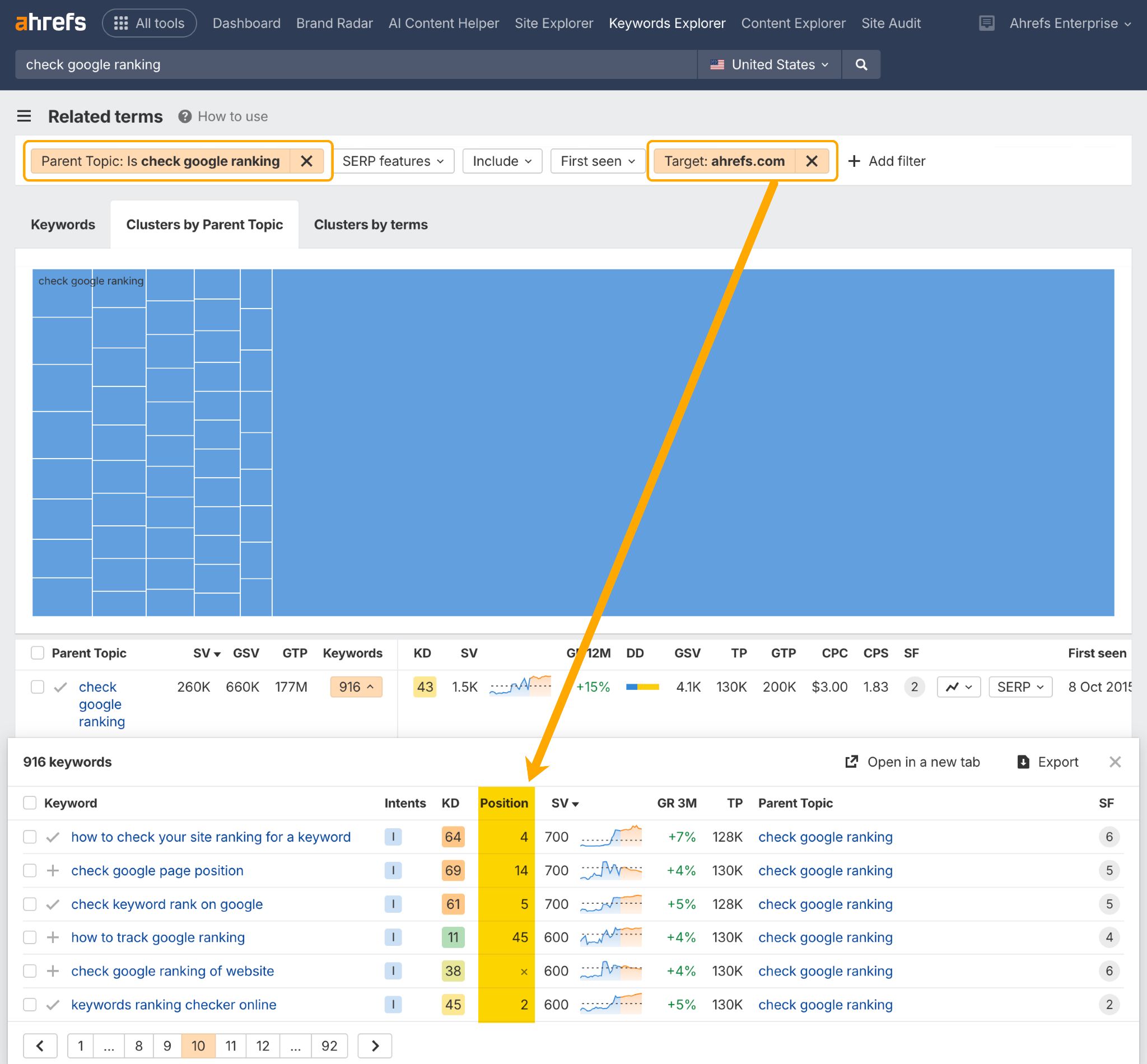
Puedes comprobar el rendimiento SEO de tus clústeres de contenido en el informe de Términos Relacionados en Keywords Explorer de Ahrefs.
Esto te mostrará si y dónde te posicionas en todo un clúster de palabras clave relacionadas.
Solo tienes que añadir un filtro de Tema Principal y un filtro de Objetivo que contenga tu dominio.
Una vez que lo hayas hecho, dirígete a Brand Radar de Ahrefs para comprobar el rendimiento de tus clústeres de contenido en la IA.
Ejecuta URLs individuales a través del informe de Páginas Citadas en Brand Radar para ver si tus clústeres de contenido están siendo citados por asistentes de IA como ChatGPT, Perplexity, Gemini y Copilot.
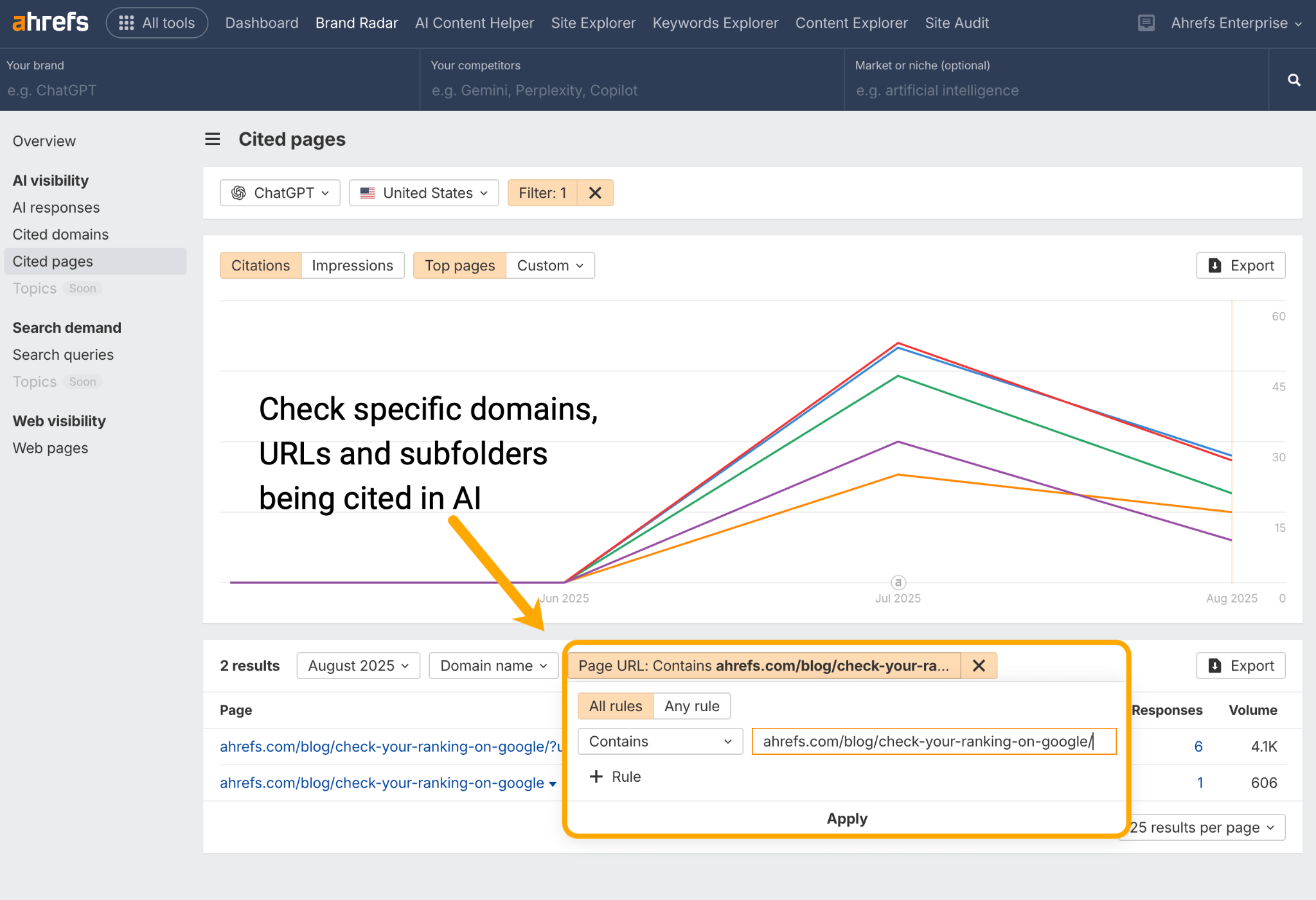
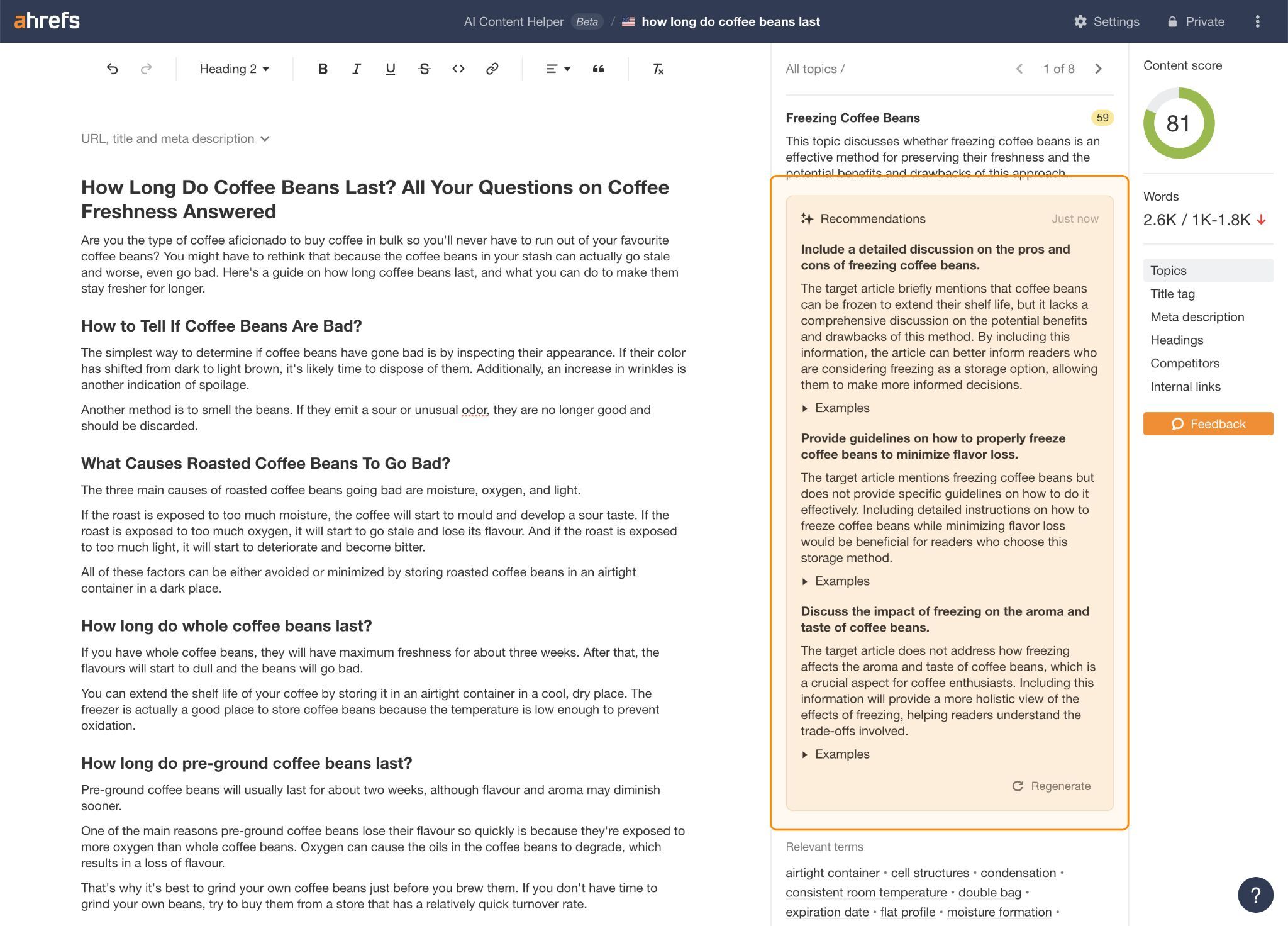
Determina si falta algún contenido en alguna de las dos áreas, y luego optimiza hasta que hayas llenado esos vacíos y enriquecido el clúster general.
Puedes usar las recomendaciones de brechas de temas en AI Content Helper de Ahrefs para ayudarte con esto.
Las consultas short-tail muestran una mayor alineación entre las SERPs y la IA que los prompts en lenguaje natural, especialmente cuando se trata de Perplexity.
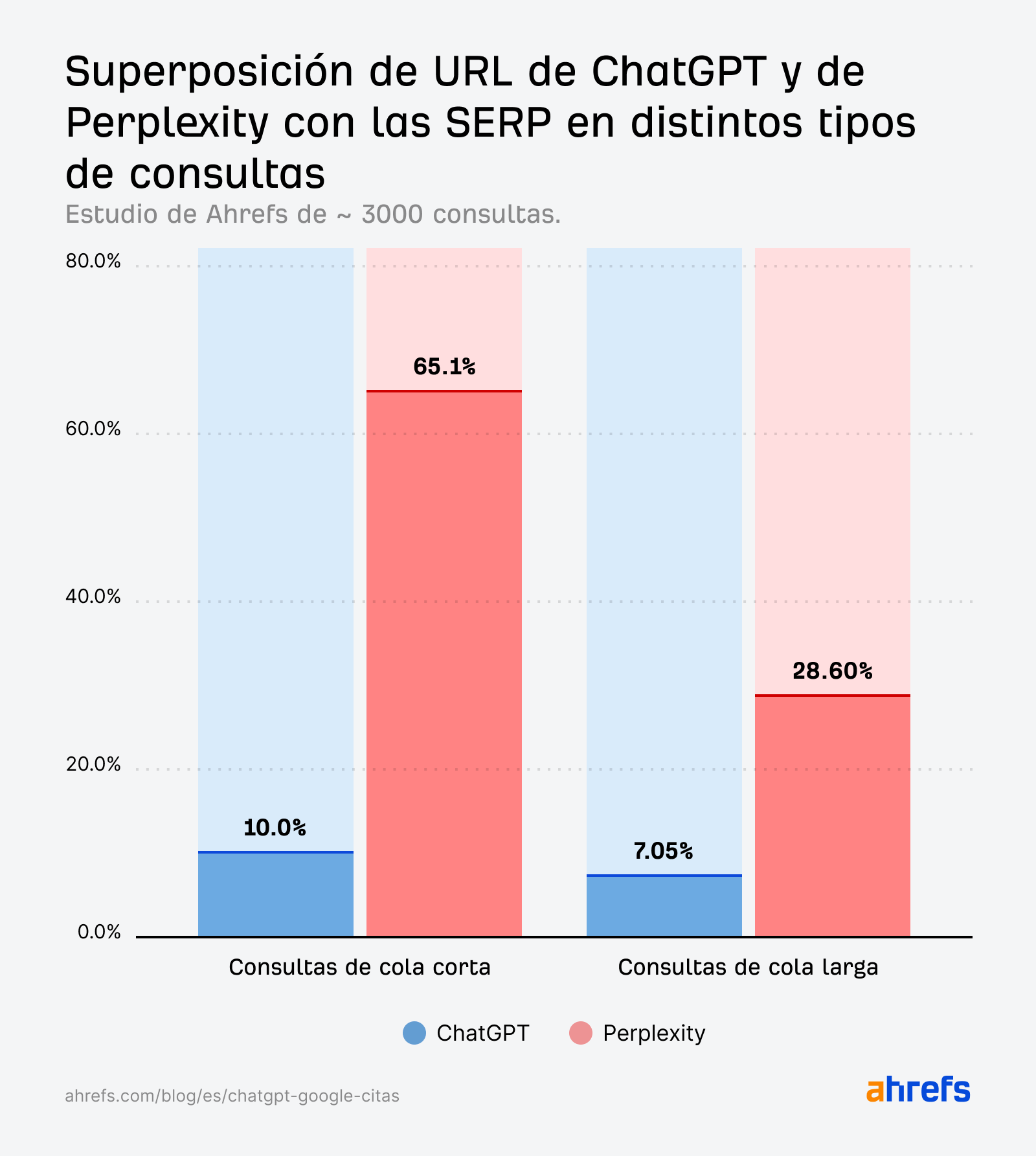
Pero las citas de ChatGPT generadas por las consultas de expansión (estudiadas por primera vez por SQ y Xibeijia) muestran la menor coincidencia. Coinciden solo con el 6,82 % de los 10 primeros resultados de Google.
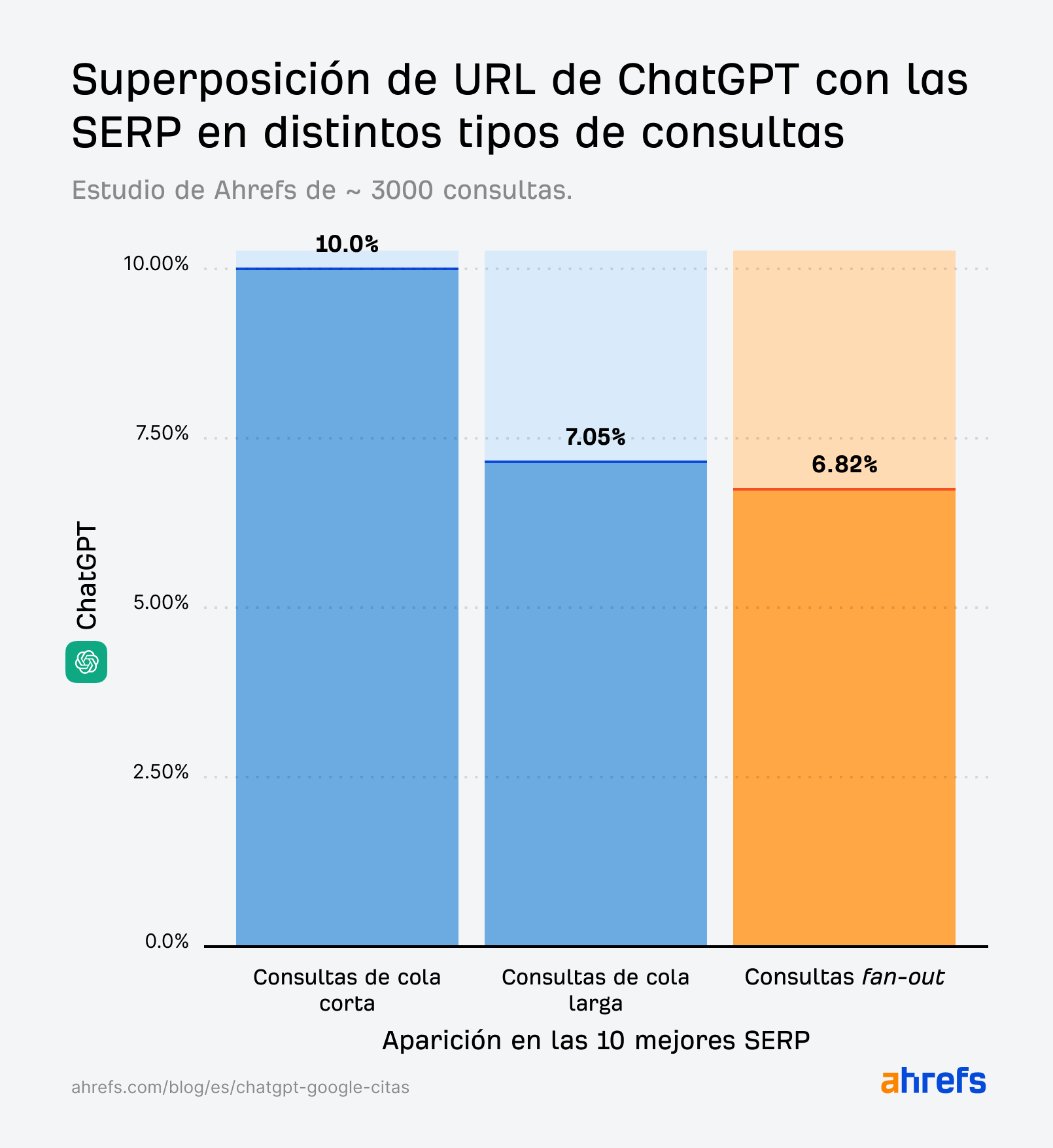
No estamos comparando manzanas con manzanas aquí. Estos porcentajes representan diferentes estudios y conjuntos de datos de diferentes tamaños.
Pero cada estudio produce hallazgos similares: las páginas que ChatGPT cita no coinciden significativamente con las páginas que Google posiciona. Y es en gran medida lo contrario para Perplexity.
¿Y qué hay de la intención?
Otra cosa que no hemos mencionado es la intención. La mayor coincidencia de citas que vemos en las consultas short-tail podría explicarse en parte por la relativa estabilidad de las consultas de navegación, comerciales y transaccionales, que no evaluamos en nuestros estudios anteriores.
Los términos “head” de navegación, comerciales y transaccionales tienen SERP que no tienden a cambiar con demasiada frecuencia, porque el conjunto de productos, marcas o destinos relevantes es finito.
Esta estabilidad significa que los asistentes de IA y Google son más propensos a converger en las mismas fuentes, lo que significa que la coincidencia es mayor que en las consultas informacionales (donde el grupo de páginas posibles es mucho más grande y volátil).
Reflexiones finales
En los tres estudios, la historia es consistente: ChatGPT no sigue las fuentes de Google, Perplexity sí.
Lo sorprendente es que ChatGPT difiera tanto de Google, cuando ahora sabemos que OpenAI sí extrae los resultados de Google.
Mi corazonada es que ChatGPT hace más que Perplexity para diferenciar su conjunto de resultados del de Google.
Esta teoría de SQ me parece la más probable:
“ChatGPT probablemente utiliza un enfoque híbrido en el que obtiene resultados de búsqueda de varias fuentes, por ejemplo, las SERP de Google, las SERP de Bing, su propio índice y APIs de búsqueda de terceros, y luego combina todas las URLs y aplica su propio algoritmo de reposicionamiento.”
Sea cual sea el caso, la búsqueda y la IA están dando forma al descubrimiento codo con codo, y la mejor estrategia es crear contenido que te dé la oportunidad de aparecer en ambas superficies.
¿Tienes preguntas? Estamos en LinkedIn y en X.

