Utilizando Web Analytics de Ahrefs y Bot Analytics, analizamos los registros de servidor y el tráfico en vivo de 137K dominios, además de los user agents que accedieron a todos ellos.
Aquí tienes lo que encontramos.
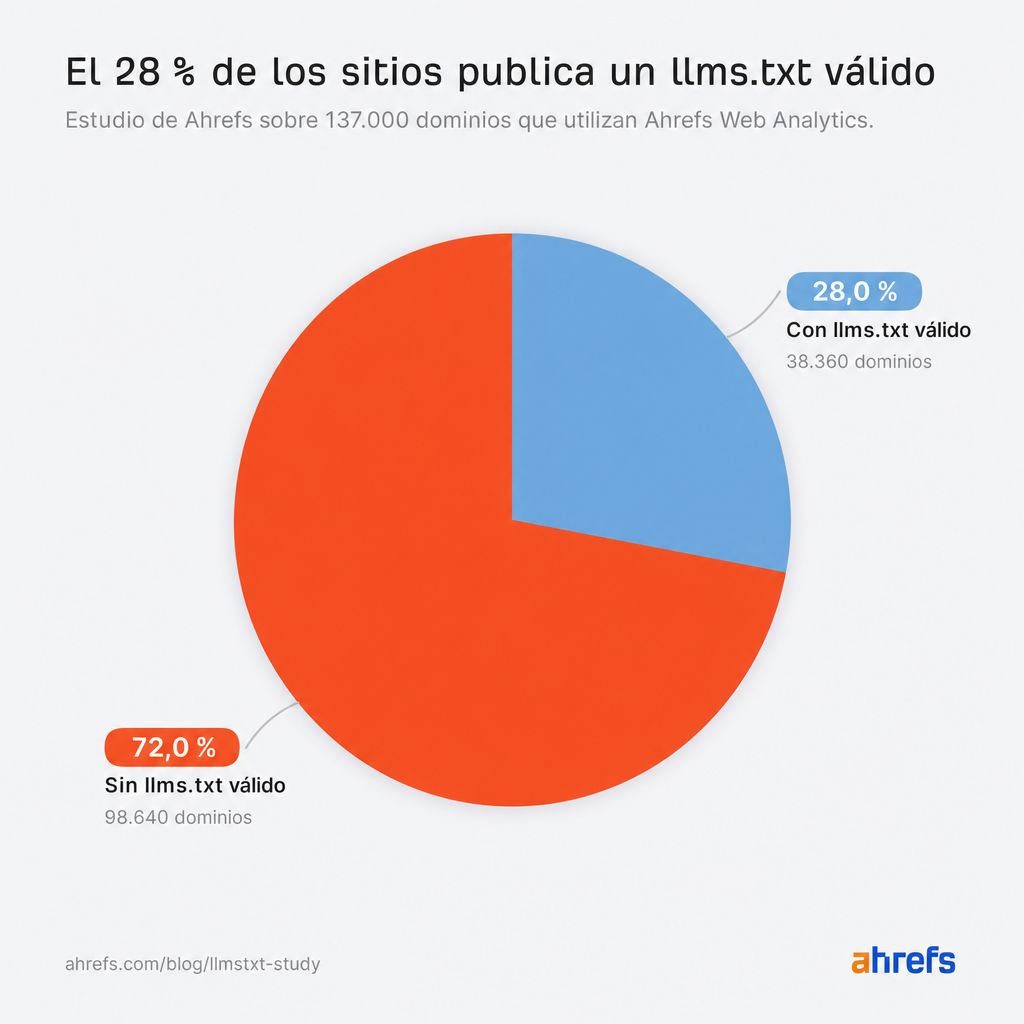
- El 28% de los 137K dominios que utilizan Web Analytics de Ahrefs publican un archivo llms.txt.
- El 97% de esos archivos recibió cero tráfico en mayo de 2026. Nada los rastreó en absoluto.
- El 96% de las peticiones que sí llegaron a los archivos llms.txt procedían de bots.
- El 19,5% de los rastreos provinieron de herramientas de IA con nombre (del 3% de los archivos que no fueron ignorados). GPTBot es el primero y Claude-Code el segundo, por delante de todos los bots asistentes y buscadores de IA.
- El 12% de los rastreos proceden del propio sector estudiándose a sí mismo: herramientas GEO/AEO, herramientas de comprobación de llms.txt y bots de investigación.
- Cero peticiones provinieron de bots de IA para archivos llms.txt que no existen. Nunca van a buscarlos.
- La auditoría de llms.txt de Chrome Lighthouse produjo aproximadamente 1 de cada 1.000 rastreos.
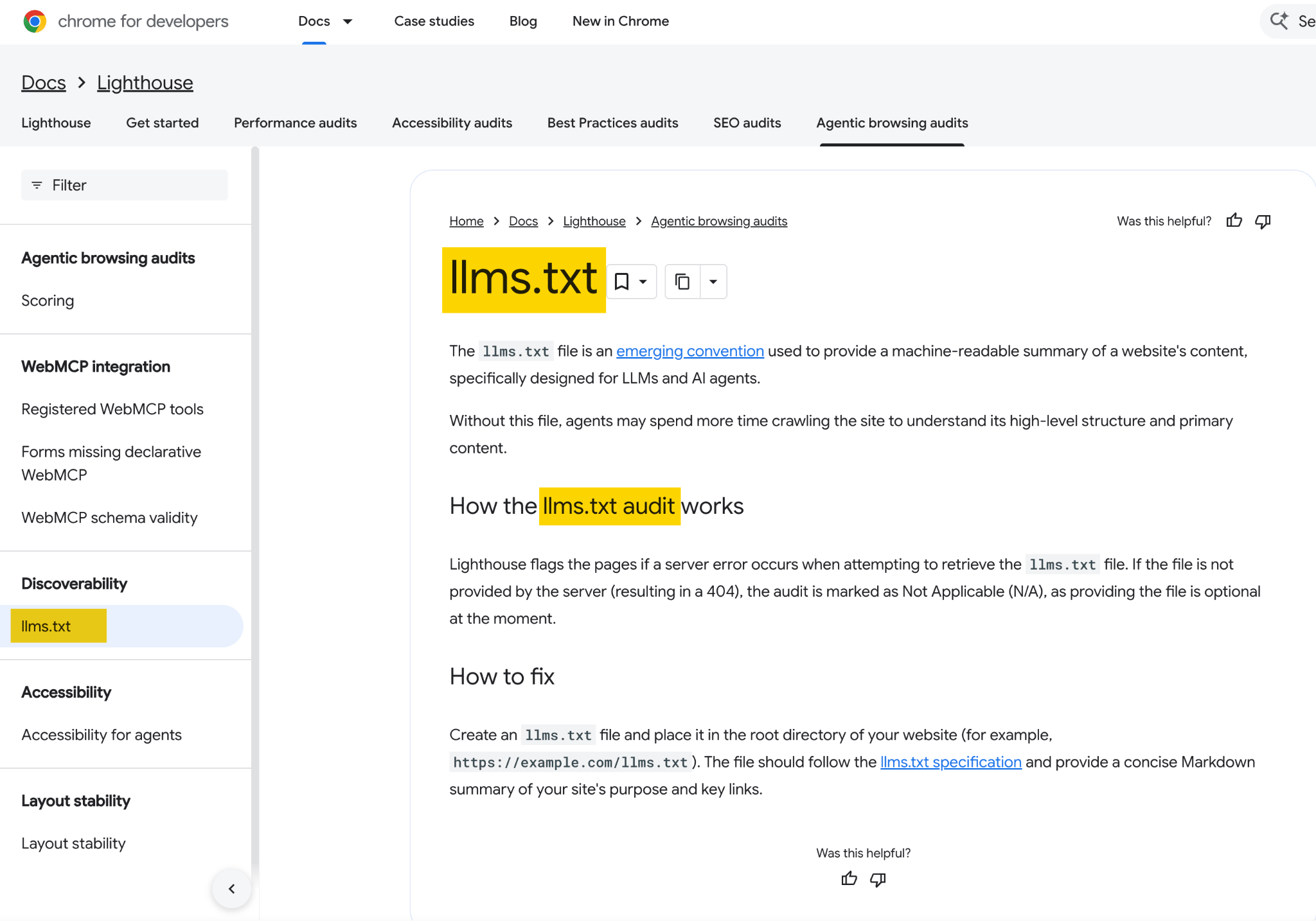
A finales de mayo de 2026, Google se posicionó en ambos lados del debate sobre llms.txt en menos de una semana.
Su nueva guía sobre la optimización para funciones de IA generativa indicaba a los propietarios de sitios, en una sección titulada literalmente “desmintiendo mitos”, que los archivos legibles por máquinas como llms.txt no son necesarios para aparecer en la búsqueda de IA generativa.

Días más tarde, el equipo de Chrome incluyó una comprobación de llms.txt dentro de las auditorías experimentales de navegación agéntica de Lighthouse, con documentación explicando que sin el archivo, los agentes podrían pasar más tiempo rastreando un sitio para comprender su estructura.
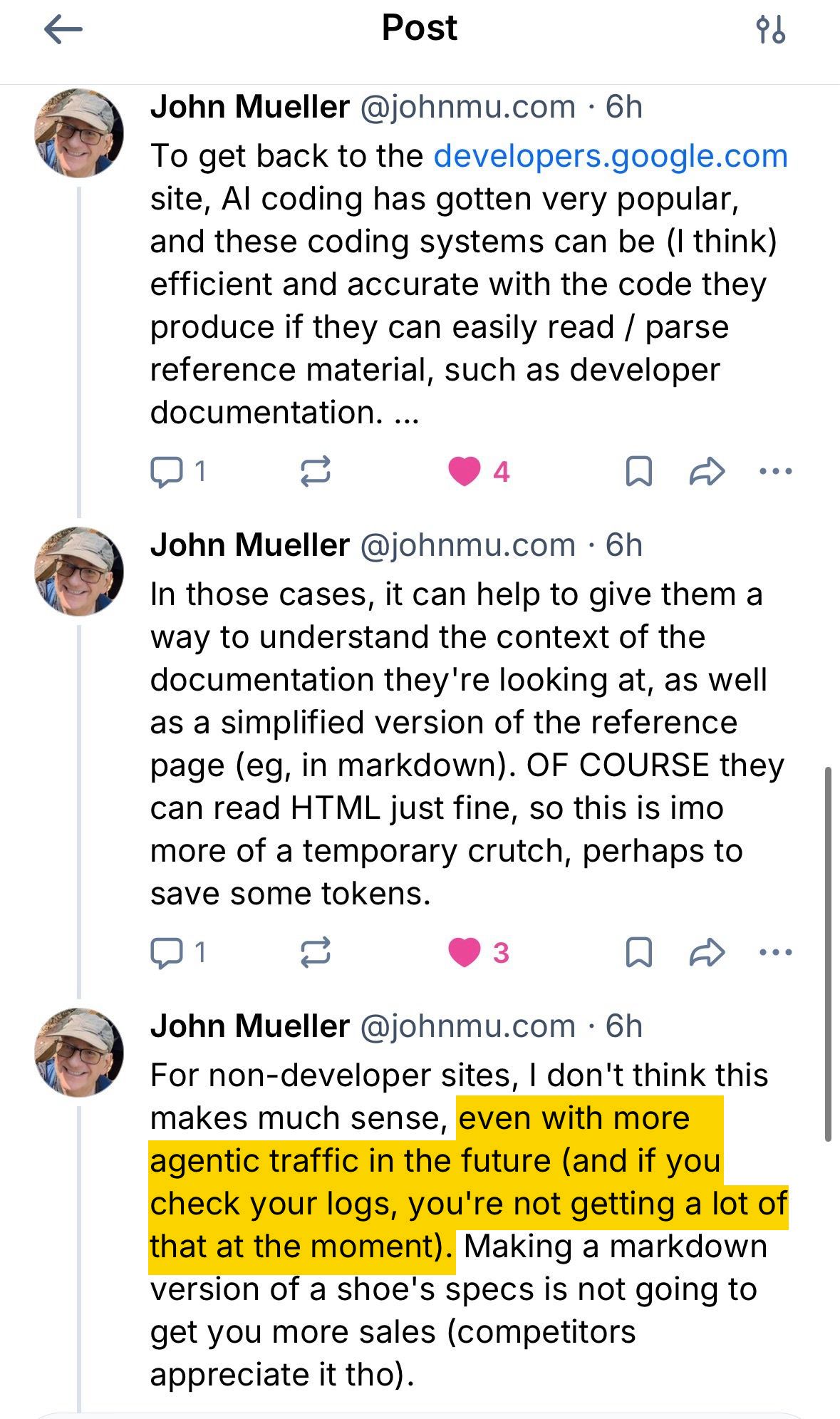
Cuando Lily Ray presionó a John Mueller de Google sobre la contradicción, él explicó que llms.txt “no está hecho para la búsqueda”. Es una “muleta temporal, tal vez para ahorrar algunos tokens” para las herramientas de codificación de IA que analizan la documentación de desarrolladores, y no algo de lo que los sitios que no son para desarrolladores deban preocuparse.
También afirmó que los propietarios de sitios que comprueben sus registros encontrarán muy poco tráfico de agentes de IA.
Esto es algo que decidimos poner a prueba.
Antes de continuar, aclaremos qué es realmente llms.txt. Llms.txt es un único archivo de índice, escrito en markdown, ubicado en la raíz de un sitio. Propuesto por Jeremy Howard, cofundador de Answer.AI y fast.ai, en 2024, resume lo que es un sitio y enlaza su contenido más importante. La idea es que los LLMs y agentes puedan usar esta información para orientarse sin rastrear todo. El enfoque de “visibilidad en la IA” en torno a llms.txt llegó más tarde, añadido por el sector del SEO a medida que se extendía su adopción bajo la especulación de que las plataformas de IA recompensarían este archivo. Dos cosas con las que a menudo se confunde, y que no es:
- No es la práctica de publicar copias en markdown de tus páginas web, una táctica independiente con sus propios problemas.
- Y a pesar del nombre del archivo, no es una directiva al estilo robots.txt: no controla nada ni bloquea nada.
Este estudio mide el archivo index, y únicamente el archivo index.
Nuestro estudio se centra en los 137.210 dominios de Web Analytics de Ahrefs que recibieron tráfico en mayo de 2026.
Comprobamos en la raíz de cada dominio si había un archivo llms.txt que devolviera HTTP 200, y luego utilizamos Bot Analytics para examinar cada petición a las rutas /llms.txt en toda la muestra, separadas por respuesta HTTP (200 frente a Error 404) y clasificadas por canal y user agent individual.
Para descartar los soft 404s y archivos fantasma, también confirmamos que cada archivo fuera realmente Markdown en lugar de HTML, y revisamos los títulos y el contenido en busca de señales de error como “Error 404” o “Page not found”.
Es importante destacar:
- Los clientes de Web Analytics de Ahrefs tienden a ser más técnicos y conscientes del SEO que la web en general, por lo que debes tomar la cifra del 28% de adopción como un límite superior.
- No estudiamos explícitamente si un archivo estaba bien formado con respecto a la especificación de llms.txt.
Las directrices de la Búsqueda de Google dicen que puedes omitirlo, el equipo de Chrome lo incluye en sus auditorías y Mueller lo califica de solución temporal para herramientas de programación.
Así que, entre tantos mensajes contradictorios, ¿hasta qué punto está extendido llms.txt en la realidad? Entre los 137K dominios de nuestro estudio, el 28% publica estos archivos.
Más de uno de cada cuatro dominios (38.000) de nuestra población ha adoptado llms.txt, a pesar de que ninguna plataforma importante de IA se ha comprometido nunca a leerlo.
La adopción se ha visto impulsada por la especulación de que las plataformas de IA podrían empezar a consumir el archivo, en lugar de por una confirmación de que realmente lo hagan.
Casi todos los archivos llms.txt de nuestro estudio no son leídos por nadie.
De los ~38.000 dominios con un archivo válido, el 97% no vio absolutamente ninguna petición en mayo.
Ni bots. Ni humanos. Nada.
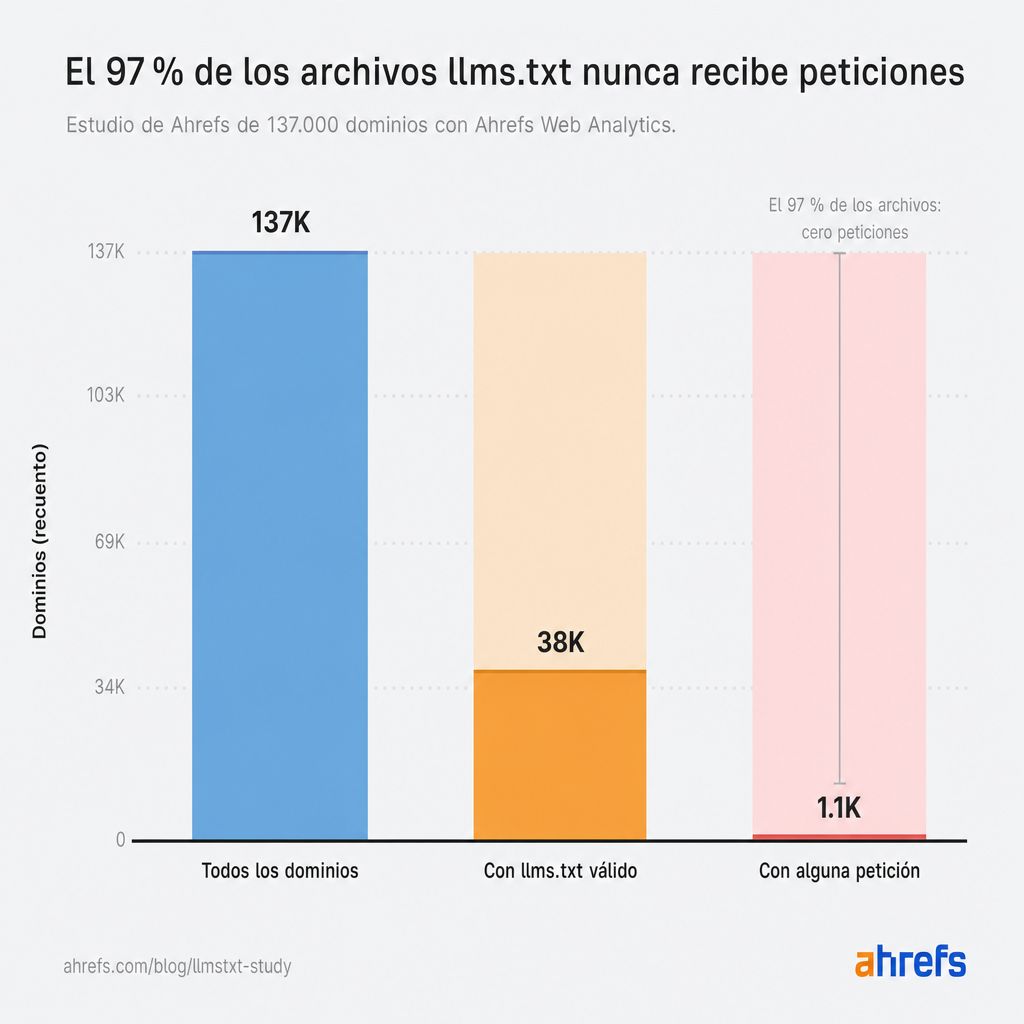
El 3% restante (1.1K dominios) recibió todo el tráfico a llms.txt que medimos.
Nuestros datos sugieren que John Mueller tiene razón. No solo encontrarás muy poco tráfico de IA como resultado de este archivo, sino que encontrarás muy poco tráfico en general.
Si publicas un archivo llms.txt hoy, el resultado más probable con diferencia es que nada lo rastree nunca.
Sin embargo, el 3% de los archivos que sí se leen, son leídos por visitantes interesantes.
Nos centraremos en ellos durante el resto del estudio.
Los archivos llms.txt están escritos para máquinas, y las máquinas son casi las únicas que los leen.
En todos los archivos que recibieron tráfico, el 96% de las peticiones provinieron de bots.
Los humanos representaron el 4%, y una buena parte de ellos parecen ser profesionales SEO compartiendo enlaces a llms.txt en aplicaciones de chat, donde los bots de despliegue los rastrean diligentemente.
Slackbot por sí solo rastreó archivos llms.txt con más frecuencia que PerplexityBot.
Perplexity es uno de los motores de búsqueda de IA que llms.txt supuestamente debía ayudar, por lo que descubrir que el bot de vista previa de enlaces de una aplicación de chat lo rastreó más dice mucho sobre cuánto interés real en la búsqueda con IA están generando estos archivos.
Muchos sitios publican llms.txt precisamente porque piensan que mejorará sus posibilidades de aparecer en las respuestas de ChatGPT, o de conseguir menciones en Perplexity, o de ganar una AI Overview.
Pero nuestros datos cuentan una historia diferente: el 77% de los bots que rastrean llms.txt no son herramientas de IA en absoluto.
Para comprender qué bots estaban solicitando llms.txt, clasificamos cada user agent en doce categorías.
| CATEGORÍA | AUDITORÍA | PETICIONES | % DEL TOTAL |
|---|---|---|---|
| Herramientas de auditoría SEO (Rastrean sitios para comprobaciones tradicionales de salud SEO, sin interés específico en llms.txt) ej. SiteAuditBot, WebPageTest | Desconocido | 4.776 | 21,7% |
| Otros y no identificados (Bots anónimos y bots cuyo propósito u operador no pudimos determinar) ej. node, satoric-indexer | Rastreo | 3.278 | 14,9% |
| Rastreadores web generales (Indexan la web para búsqueda y descubrimiento de productos, sin caso de uso declarado de agente de IA) ej. Googlebot, Amazonbot | Perfilado | 2.871 | 13,1% |
| Herramientas de perfilado tecnológico (Rastrean sitios para identificar pilas tecnológicas y datos de inteligencia empresarial) ej. BuiltWith, Dataprovider | IA | 2.546 | 11,6% |
| Agentes de IA e infraestructura agéntica (Agentes de IA que actúan en nombre de un usuario, además de los rastreadores y herramientas creados para servirlos) ej. Claude-Code, IbouBot | Estudian llms.txt | 2.302 | 10,5% |
| Herramientas GEO/AEO (Escanean sitios web y puntúan su preparación para la búsqueda con IA y el descubrimiento de agentes) ej. CairrotReadinessBot, AuditMetricBot | IA | 1.278 | 5,8% |
| Rastreadores de entrenamiento de IA (Recopilan datos para la creación de modelos) ej. GPTBot, ClaudeBot | Estudian llms.txt | 1.179 | 5,3% |
| Bots de descubribilidad de llms.txt (Específicamente escanean, validan o catalogan archivos llms.txt) ej. LLMS-Txt-Scanner, txtfeed-bot | Social | 793 | 3,6% |
| Bots de servicios y redes sociales (Obtienen URLs para generar vistas previas de enlaces en aplicaciones de mensajería y plataformas sociales) ej. Slackbot, Skype URI Preview | Estudian llms.txt | 645 | 2,9% |
| Bots de investigación (Rastrean con fines académicos o de investigación, incluyendo la investigación de seguridad) ej. prompt-injection-survey, ResearchProject | IA | 585 | 2,7% |
| Asistentes de IA (Navegan por la web en nombre de un usuario en respuesta a una única consulta) ej. ChatGPT-User, Claude-User | IA | 559 | 2,5% |
| Bots de recuperación de IA (Obtienen páginas para responder a consultas en directo de los usuarios en productos de búsqueda de IA) ej. OAI-SearchBot, PerplexityBot | 233 | 1,1% |
Individualmente, ninguna categoría de bots de IA se encuentra entre las cuatro primeras.
Las herramientas de auditoría SEO (21,7%), Otros y no identificados (14,9%), Rastreadores web generales (13,1%) y Herramientas de perfilado tecnológico (11,6%) envían más peticiones que cualquier bot de IA por sí solo.
La mayor categoría de IA independiente, Agentes de IA, ocupa el quinto lugar con un 10,5%.
Pero cuando combinas las cuatro categorías de IA (rastreadores de entrenamiento, bots de recuperación, asistentes y agentes), los bots de IA se convierten en el grupo más grande con un 19,5%.
El tráfico de bots se divide en tres partes:
- Bots de IA que consumen el archivo (19,5%)
- Una larga cola de scrapers anónimos (14,9%)
- Una industria que lo audita (12,1%)
A continuación, profundizaremos en un par de ellos.
De las peticiones que sí llegan a los archivos llms.txt, los bots de IA con nombre representan el 19,5%.
Aunque los bots de IA son el mayor público identificable de llms.txt, el desglose por tipo de bot de IA muestra que el archivo no está sirviendo a las herramientas de IA que la mayoría de la gente tiene en mente.
Los agrupamos de cuatro maneras:
- Agentes de IA e infraestructura agéntica que actúan en nombre de un usuario, o rastrean para servir a los agentes que lo hacen.
- Rastreadores de entrenamiento de IA que recopilan datos para la creación de modelos.
- Asistentes de IA que navegan por la web en nombre de un usuario en tiempo real.
- Bots de recuperación de IA que obtienen páginas para responder a consultas en directo de los usuarios en plataformas de IA.
Así es como se comparan…
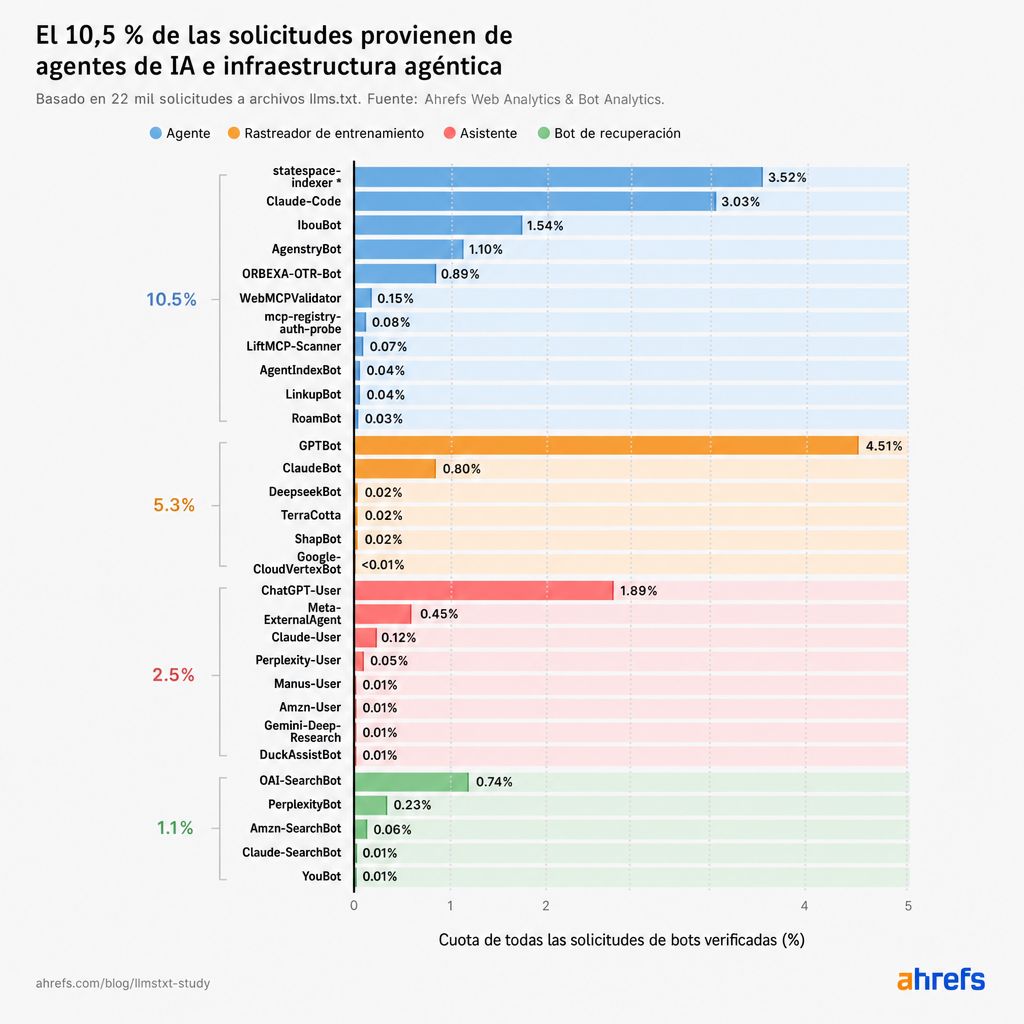
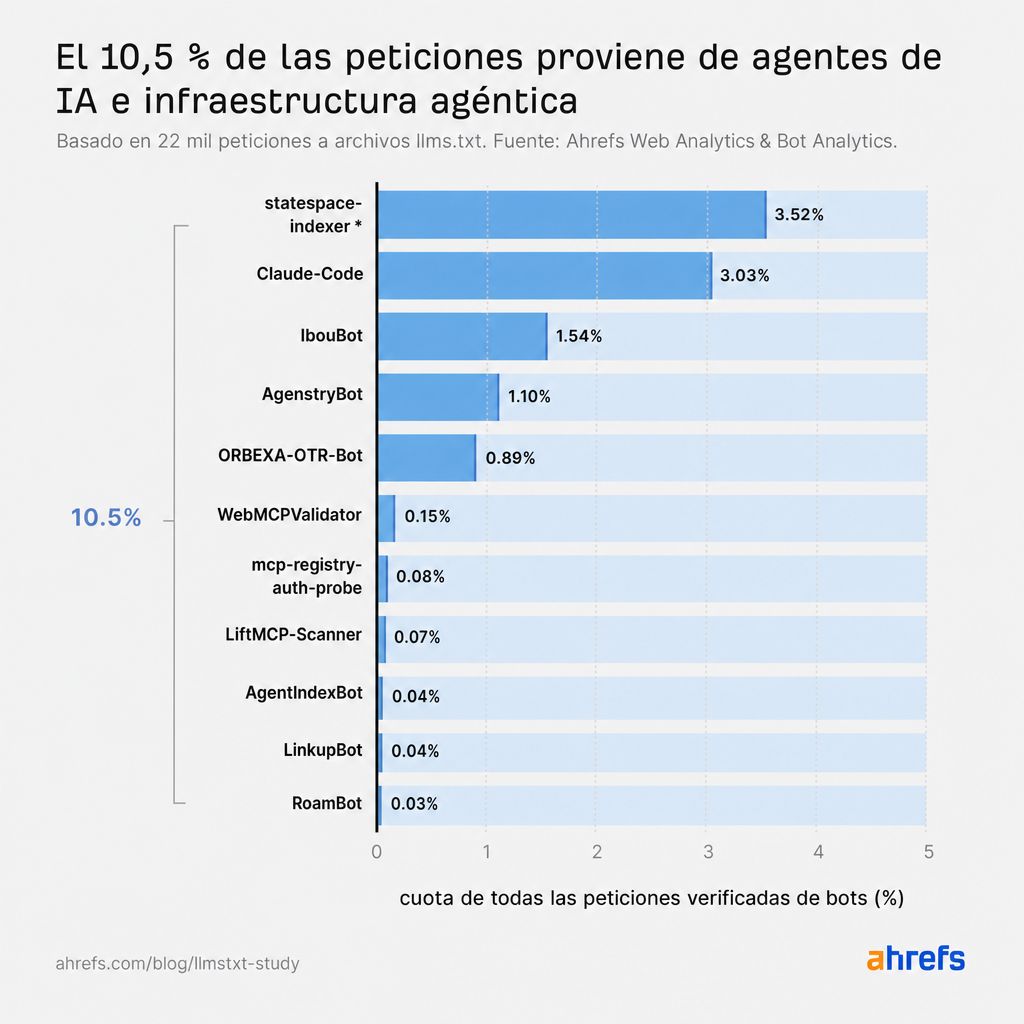
*statespace-indexer: operador identificado como Statespace (infraestructura agéntica), rangos de IP no confirmados.
La web agéntica es el consumidor real, enviando el 10,5% de las peticiones
Los agentes de IA, y la infraestructura construida para servirlos, impulsan el 10,5% de las peticiones de llms.txt, más que cualquier otro tipo de bot de IA.
Este hallazgo coincide con una corazonada que muchos en el sector ya tenían.
Escuchamos antes a John Mueller decir que llms.txt funciona mejor como material de referencia para los agentes de programación de IA.
Chris Long, fundador de Nectiv, también ha afirmado que, incluso si llms.txt no te ayuda en la búsqueda de Google, el archivo tiene utilidad si tus clientes “están usando Claude Code para obtener recomendaciones”.

Nuestros datos de Bot Analytics respaldan ambas ideas.
Vemos que los archivos llms.txt son rastreados mucho menos por los bots de búsqueda y de IA que supuestamente son responsables de la visibilidad, y mucho más por las herramientas agénticas que buscan información estructurada y/o actúan en nombre del usuario.
*statespace-indexer: operador identificado como Statespace (infraestructura agéntica), rangos de IP no confirmados.
Aparte de statespace-indexer y GPTBot, Claude-Code (el agente de programación de Anthropic) superó en rastreos a cada bot de recuperación de IA, a cada asistente de IA y a cada rastreador de entrenamiento de IA.
Los rastreadores de entrenamiento son la segunda categoría de IA más grande con un 5,3%
Los archivos llms.txt alimentan a los corpus de entrenamiento más de lo que alimentan la recuperación de búsquedas con IA.
De hecho, los rastreadores de entrenamiento de IA obtienen los llms.txt casi 5 veces más que los bots de recuperación de IA.
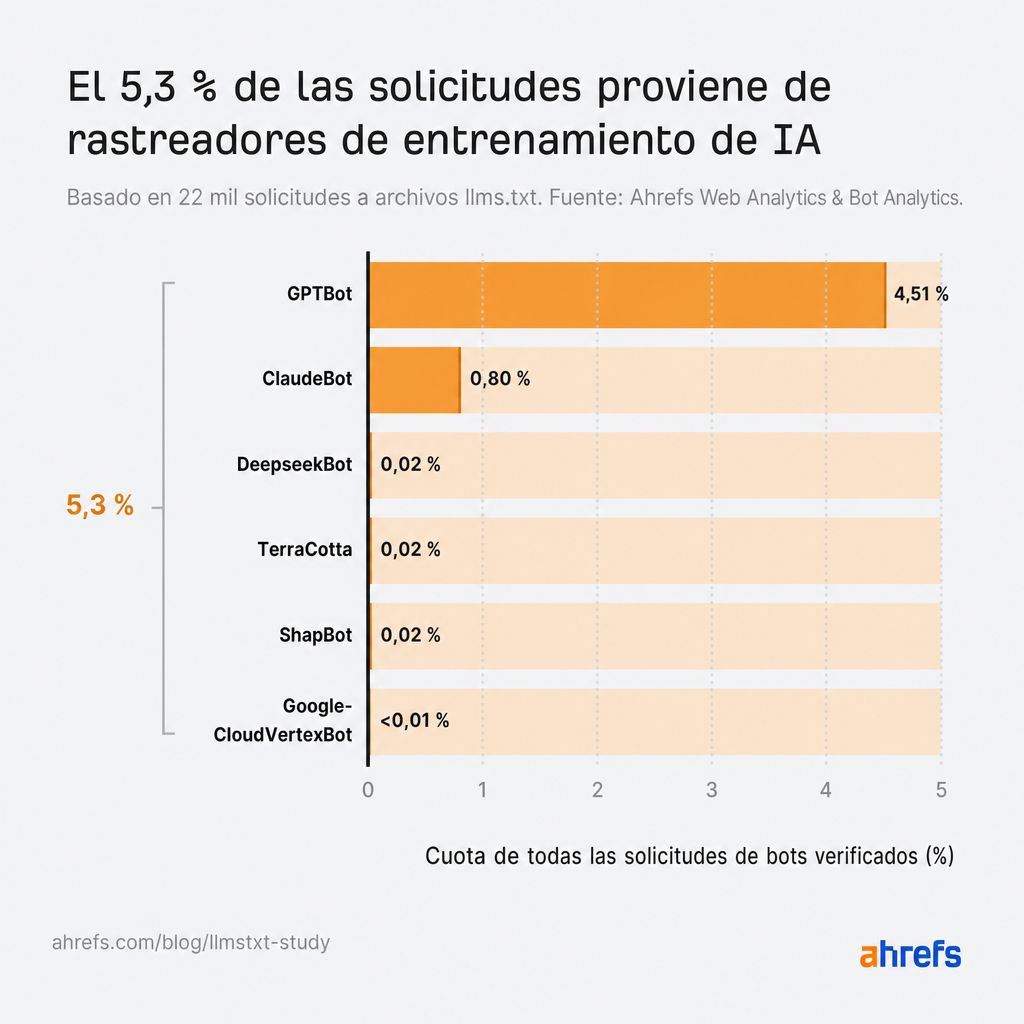
Así que si llms.txt tuviera algún impacto en la visibilidad en la IA de tu marca, probablemente sería en una fase inicial, no en el momento de la recuperación de la información.
De todos los rastreadores de entrenamiento, GPTBot es, con gran diferencia, el mayor rastreador de llms.txt.
No encontrarás un rastreador de Gemini en esta lista, porque no existe.
Google entrena y fundamenta a Gemini en contenido obtenido por el Googlebot normal, y Google-Extended, la exclusión voluntaria que usan los editores, es un token de robots.txt en lugar de un rastreador con su propio user agent.
Googlebot sí rastreó archivos llms.txt unas 900 veces en mayo, pero Googlebot rastrea rutinariamente cualquier URL que descubre en un sitio como parte de la indexación normal de búsqueda, por lo que esos rastreos no indican un interés especial en llms.txt; está rastreando el archivo de la misma forma que rastrea un sitemap o cualquier otra página.
Si parte de ese contenido alimenta luego a Gemini es algo invisible para nosotros.
Los bots de recuperación de IA apenas se registran, con un 1,1% del total de peticiones
Según nuestros datos, los bots de recuperación de IA representan solo el 1,1% de las peticiones de bots de IA.
Incluso si se consideran junto con los asistentes de IA y los rastreadores de entrenamiento de IA, estos bots solo representan el 8,9% de las peticiones (un 1,6% menos que los agentes de IA).
OAI-SearchBot, PerplexityBot y el rastreador de búsqueda de Claude combinados hicieron solo un par de cientos de rastreos en miles de sitios.
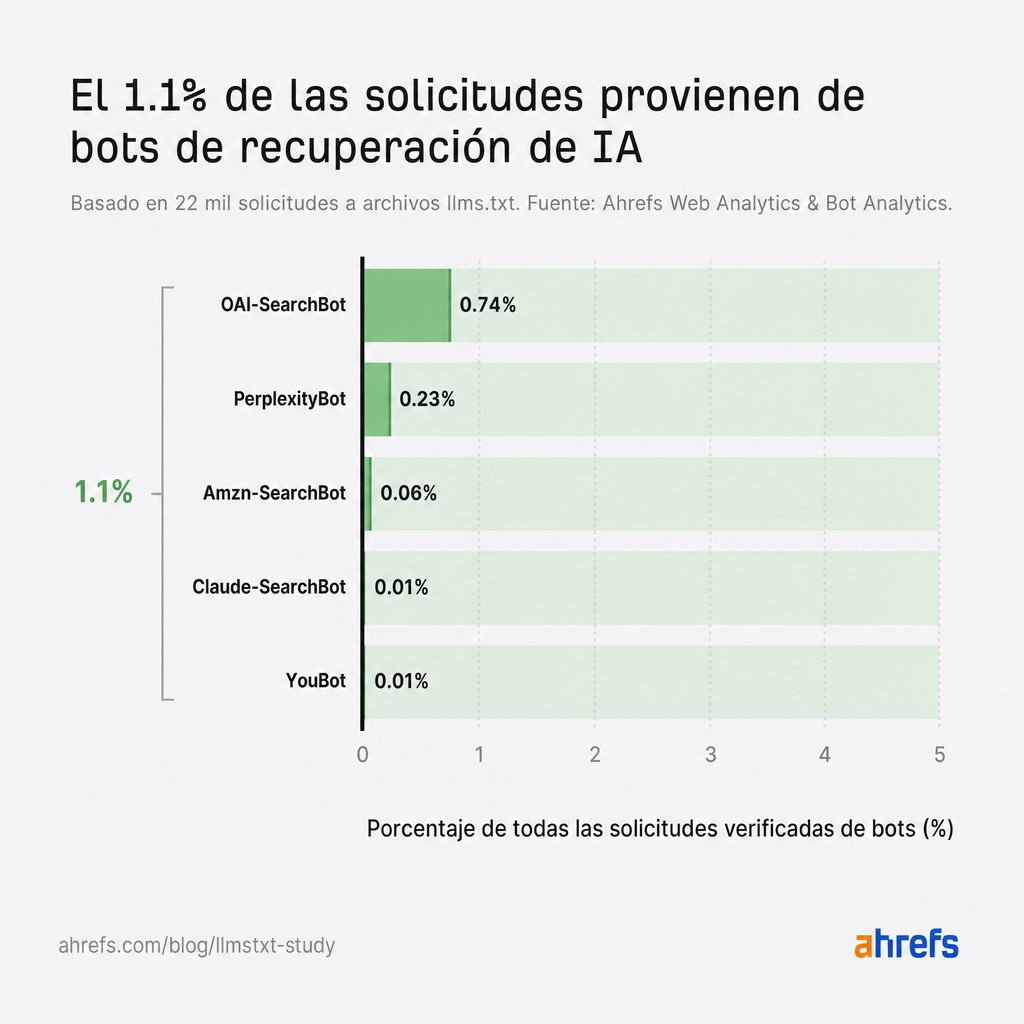
Si planeas generar un llms.txt con la esperanza de impulsar tus menciones en IA, puede que quieras pensarlo de nuevo.
Se ha formado todo un ecosistema en torno a la auditoría, la puntuación, la validación y el estudio del estándar llms.txt, antes incluso de que hayamos establecido si alguna plataforma importante de IA lo lee realmente.
Tres categorías suman el 12% de todas las peticiones combinadas.
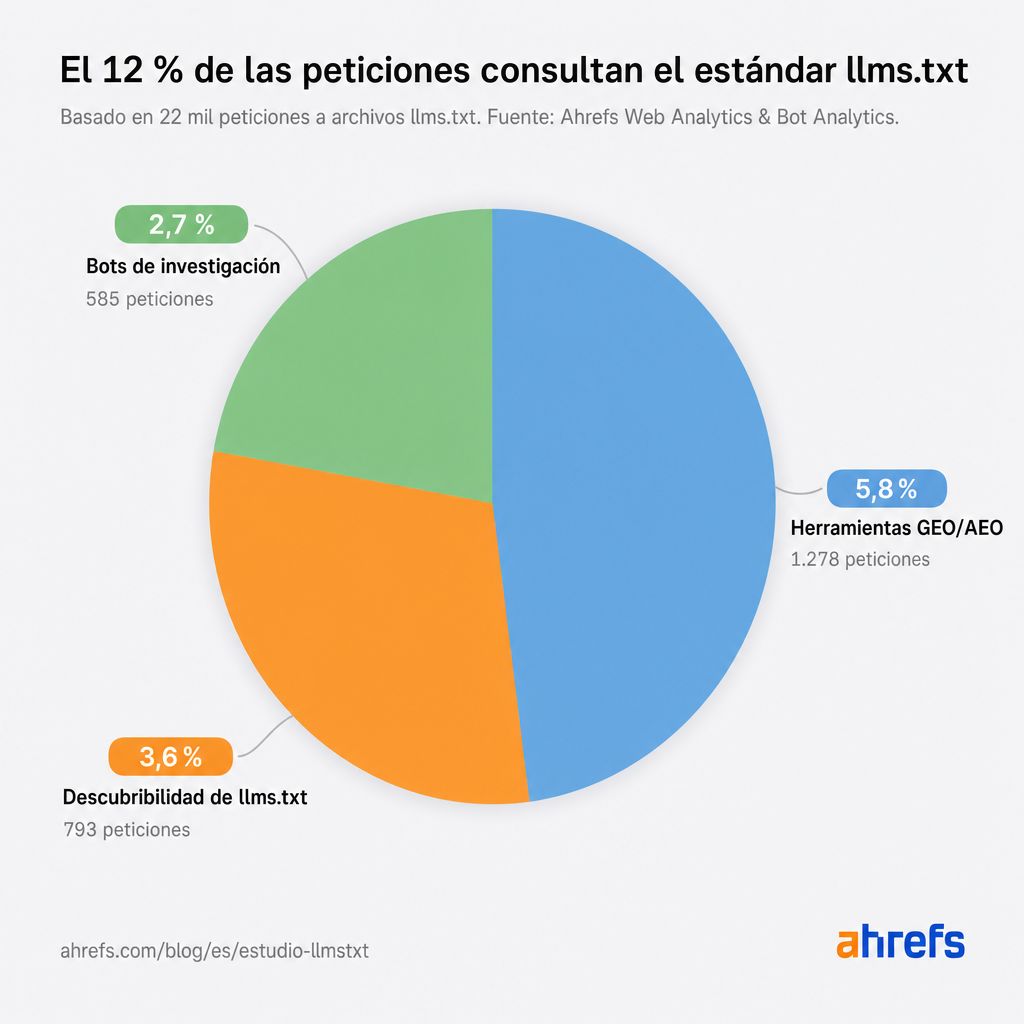
Las herramientas GEO/AEO envían el 5,8% de las peticiones
Las herramientas comerciales escanean los sitios web y puntúan su preparación para la búsqueda con IA y el descubrimiento de agentes, siendo la presencia de llms.txt una de las muchas señales.
El más activo, CairrotReadinessBot, pertenece a Cairrot, una plataforma AEO centrada en WordPress lanzada a finales de 2025.
Luego tienes a los creadores de sitios web convencionales como Framer, Lovable y Wix, que están integrando comprobaciones de preparación para la IA en sus productos.
La adopción de llms.txt se ha convertido en un valor predeterminado de la plataforma antes incluso de convertirse en una decisión del webmaster.
Los bots de descubribilidad de llms.txt cubren el 3,6% de las peticiones
Existe un ecosistema de herramientas que catalogan los archivos llms.txt que casi nadie más lee.
Escáneres dedicados, validadores y directorios creados exclusivamente para los archivos llms.txt envían más peticiones que los bots de recuperación de IA y los asistentes de IA.
Los bots de investigación envían el 2,7% de las peticiones
El mayor rastreador de investigación individual del conjunto de datos se identifica como prompt-injection-survey/1.0.
Alguien está estudiando sistemáticamente llms.txt como una oportunidad de inyección de prompts que los agentes de IA están diseñados para ingerir y confiar.
Las implicaciones de seguridad de que los agentes confíen en los archivos llms.txt a gran escala apenas se han discutido y, sin embargo, posibles actores malintencionados ya están en ello.
Las herramientas de IA nunca van a buscar archivos llms.txt que no están ahí, por lo que publicar uno no te pone en ningún radar de IA.
Analizamos cada petición a rutas /llms.txt que devolvía un Error 404 y encontramos la división más clara que hemos visto en datos de bots: mientras que por un lado los archivos válidos atraían un 96% de tráfico de bots, los archivos que faltaban atraían un 98% de tráfico humano, y la cuota de bots de IA de esos Errores 404 fue nula.
Las personas que indagan sobre archivos llms.txt ausentes son humanos que escriben la URL en un navegador, presumiblemente profesionales SEO comprobando a sus competidores.
Esto acaba con la suposición de que los sistemas de IA buscan activamente archivos llms.txt, y de que un sitio que no lo tiene está perdiendo una oportunidad.
Las herramientas de IA rastrean llms.txt cuando un enlace, un índice o una instrucción de usuario les dice que existe.
Si quieres ver qué bots están visitando realmente tu archivo llms.txt, dirígete a Bot Analytics de Ahrefs y añade un filtro para Page URL -> Contiene -> llms.txt, y luego pulsa Aplicar.
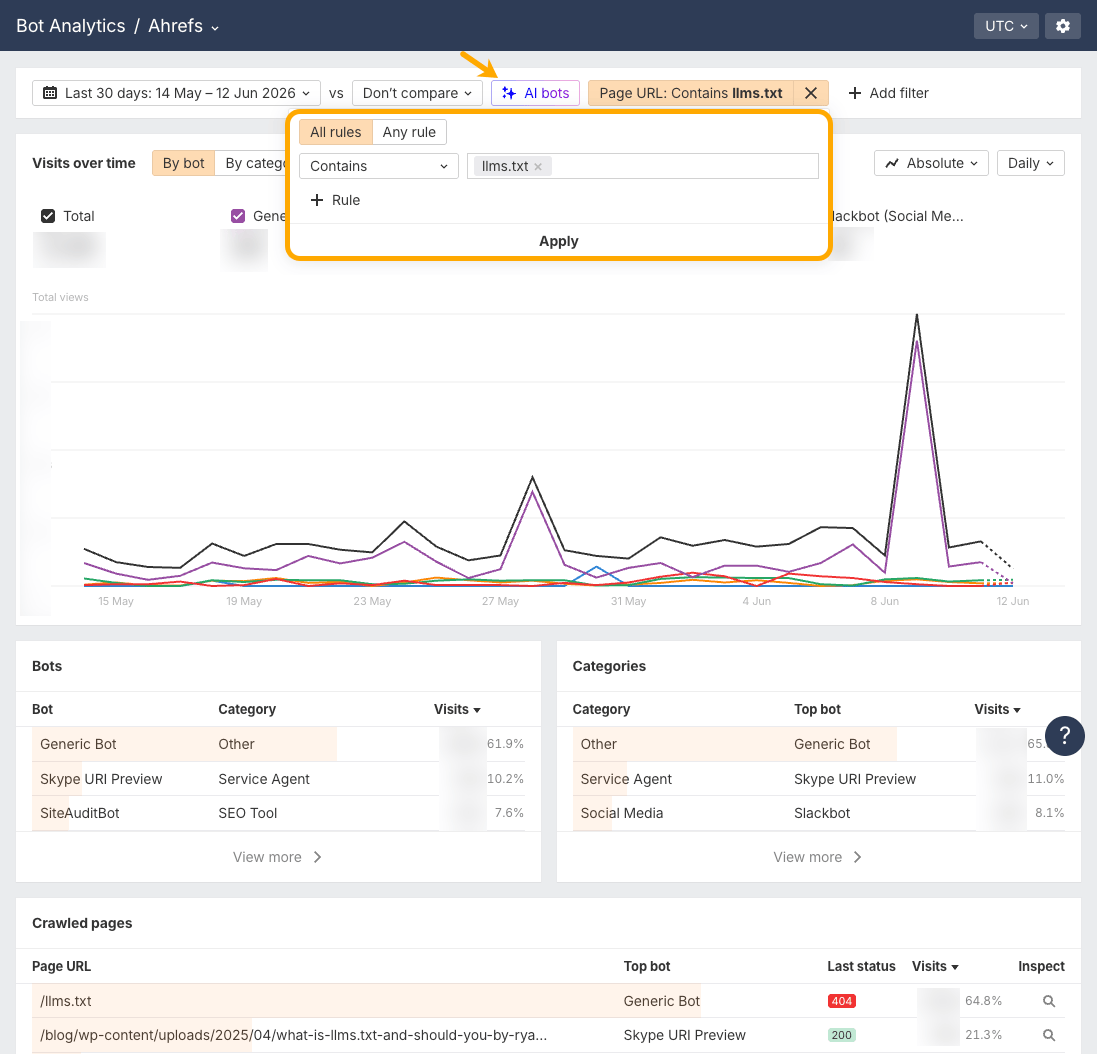
Esto lo reduce todo a las peticiones que llegan a tu archivo llms.txt (o cualquier página con “llms.txt” en la URL, como publicaciones de blog sobre ello).
No tenemos un archivo llms.txt en el sitio de Ahrefs pero estamos recibiendo algunos bots que llegan a esa página, como lo indica el estado Error 404.
A partir de ahí, puedes comprobar:
- Visitas a lo largo del tiempo. Alterna entre Por bot y Por categoría para ver si el tráfico está subiendo, es plano o tiene picos.
- La tabla de bots. Ve qué bots exactos están rastreando el archivo.
- Último estado en Páginas rastreadas. Comprueba el código de estado. Un Error
404en/llms.txtsignifica que los bots están pidiendo un archivo que no está ahí.
Ese último punto es una comprobación intuitiva útil. Muchos sitios reciben peticiones de bots para un llms.txt que nunca publicaron. El tráfico es real; el archivo no.
También puedes usar el filtro de bots de IA en la parte superior de la página para eliminar otros rastreadores y ver solo los relacionados con LLMs.
Y, recuerda, que un bot solicite tu llms.txt no es prueba de que nada lo haya leído o haya actuado en consecuencia. Solo te dice que el archivo fue rastreado.
Si tu objetivo es aparecer en ChatGPT, Perplexity o las AI Overviews, un archivo llms.txt es en gran medida decorativo.
Los bots de búsqueda con IA apenas los rastrean, ningún sistema de IA va a buscarlos y el 97% de los archivos existentes no atraen a lectores de ningún tipo.
Y recuerda que las peticiones son la medida generosa. Si los bots actúan sobre lo que rastrean es otra cuestión.
Aquí tienes los pros y los contras, uno al lado del otro.
| PROS | CONTRAS |
|---|---|
| Publicar llms.txt es barato, y plataformas como Wix lo harán cada vez más por ti. | La tasa base es brutal: el 97% de los archivos llms.txt existentes no atraen a lectores de ningún tipo. |
| Lo más parecido a un público objetivo en nuestros datos son los agentes de programación. Si tus clientes utilizan agentes de programación, o si los agentes actúan en tu sitio, el archivo tiene posibilidades reales de ser leído. | No ayudará a tu visibilidad en la IA hoy. Los bots de recuperación de IA apenas rastrean estos archivos, y ningún sistema de IA va a buscar uno que no hayas publicado. |
| Podría preparar tu estrategia para el futuro. Google ha dejado claro que el futuro de la búsqueda es agéntico. Si los agentes acaban mediando en la búsqueda con IA, en lugar de bots de recuperación que rastrean páginas directamente, llms.txt podría empezar a influir en la visibilidad en la IA a través de la capa agéntica. | Publicarlo es solo la mitad del trabajo. Los agentes rastrean llms.txt cuando se les indica, no de forma especulativa, por lo que es poco probable que un archivo sin enlazar sea detectado. |
| Es un riesgo de seguridad. Los agentes están construidos para confiar en este archivo, y posibles actores malintencionados ya están sondeando llms.txt para la inyección de prompts. Un archivo desactualizado o comprometido engaña a cada agente que lo lee. |
Mi veredicto: los contras superan a los pros en este momento. Si quieres aparecer en la búsqueda de IA, hay formas más fiables de mejorar tu visibilidad que este archivo.
Pero si todavía estás jugando con la idea de generar llms.txt, estos son los pasos que debes seguir:
- Comprueba tus propios registros antes de seguir invirtiendo. Una probabilidad del 97% de cero lectores es la tasa base.
- Consigue que una plataforma de creación de sitios web lo haga por ti. Wix ya genera estos archivos, y Framer y Lovable están buscando integrarlos. Dentro de un año, tener un llms.txt puede ser un estándar de CMS tanto como tener un sitemap. Si el beneficio es incierto, tiene sentido mantener el esfuerzo al mínimo.
- Dirige a los agentes hacia él. Enlaza el archivo desde tu HTML, referéncialo en tu documentación o menciónalo en cualquier lugar donde los agentes reciban instrucciones sobre tu sitio. Los agentes rastrean llms.txt cuando se les indica, no de forma especulativa.
- Compensa el riesgo de inyección de prompts tratando llms.txt como código. Aplica control de versiones, restringe quién puede editarlo, establece una alerta para cambios no autorizados, mantén el contenido en simples enlaces y descripciones (nada con forma de instrucción), enlaza solo a recursos que controles, y revisa cualquier cosa que una plataforma autogenere en tu nombre.
Este estudio responde cuántos sitios publican llms.txt y quién lo lee.
Pero hay un par de preguntas más que merecen mayor investigación y que estaban fuera del alcance de este estudio:
- ¿Los agentes rastrean la documentación para desarrolladores con más frecuencia? ¿Se concentra el interés de Claude-Code por llms.txt en rutas de documentación como /docs/ y /api/, tal como predice el enfoque de Mueller?
- ¿Los bots realmente actúan sobre lo que leen? Cuando un agente de IA obtiene llms.txt, ¿obtiene luego los recursos que enlaza el archivo? El consultor SEO David McSweeney, fundador de Queryburst, ya está realizando un experimento en esta línea: está ofreciendo a los user agents de IA un resumen comprimido y amigable para agentes de sus sitios de prueba, completo con instrucciones para solicitar un contenido más profundo, y rastreando si algún agente realmente lo sigue. Sus resultados merecen ser seguidos.
Mueller calificó llms.txt de muleta temporal.
Pero esa muleta parece tener ya su propia cadena de suministro: plataformas que generan archivos llms.txt, una industria que los audita y profesionales de la seguridad que los estudian, todo antes de que los “lectores” hayan aparecido siquiera.
O bien estamos presenciando los primeros andamiajes de un estándar real, o estamos viendo al sector SEO demostrar que puede convertir cualquier cosa en un producto. Apostamos por un poco de ambas cosas.
¿Tienes preguntas? Estamos en LinkedIn y en X.

