Escribir contenido SEO formulista, actualizar artículos antiguos, hacer reportes sobre el rendimiento del blog, e incluso realizar análisis de rendimiento complejos… todas estas son tareas que Agent A hace por mí.
Aquí te mostramos algunos de nuestros casos de uso favoritos de Agent A para los profesionales del marketing de contenidos.
Agent A es un agente de marketing de Ahrefs; esencialmente un asistente de inteligencia artificial con acceso directo y sin restricciones a toda la base de datos de Ahrefs, que puede llevar a cabo tareas de marketing y SEO de forma autónoma, en lugar de solo responder preguntas.
Es un espacio de trabajo donde un agente de IA de larga ejecución crea, ejecuta y mantiene herramientas para ti, en una infraestructura que él controla. No es solo un chatbot al que le haces preguntas. Es más parecido a un ingeniero junior que además tiene una profunda experiencia en SEO, una base de datos Postgres, un servidor Flask y acceso a todos los LLMs
de vanguardia.
Así es como Agent A se diferencia de ChatGPT, Claude Code, o incluso del uso de la API de Ahrefs o MCP de Ahrefs:
- Acceso sin restricciones a los endpoints de Ahrefs. Todos los endpoints que usamos para construir Ahrefs están disponibles para Agent A, incluyendo muchos a los que no puedes acceder por API o MCP: Keywords Explorer, Site Explorer (solo este tiene 101 endpoints), Brand Radar, Web Analytics, integración con GSC, AI Content Helper, Site Audit, Rank Tracker, Content Explorer, Batch Analysis… Incluso puedes crear y actualizar proyectos en Ahrefs con solo hablar con Agent A.
- Una sólida base tecnológica. Agent A es como una navaja suiza de marketing, con toda la tecnología y herramientas que necesitas para construir aplicaciones y reportes de la manera correcta. Sin entrar en demasiados tecnicismos, Agent A sabe exactamente cómo convertir tus grandes ideas en bases de datos Postgres, aplicaciones Flask y tareas programadas. Utiliza webhooks, un proxy LLM de OpenRouter con más de 300 modelos, extracción web con análisis de páginas completas, extracción de PDF, OCR…
- Conexiones integradas con todas tus herramientas de marketing. Puedes usar conectores nativos para Slack, HubSpot, GitHub, Notion, Linear, Mailchimp, Resend, SendGrid, Stripe, Gong, WordPress, Airtable, Reddit, Apify, e incluso Semrush… en caso de que quieras migrar a Ahrefs 😉
- Habilidades expertas y biblioteca de aplicaciones. El equipo de Ahrefs (incluyéndome) ha aportado habilidades de marketing y aplicaciones preconstruidas que te permiten automatizar procesos cruciales de la misma forma exacta en que lo haría un usuario avanzado de Ahrefs.
Aquí te mostramos cómo estamos usando Agent A para automatizar el marketing de contenidos:
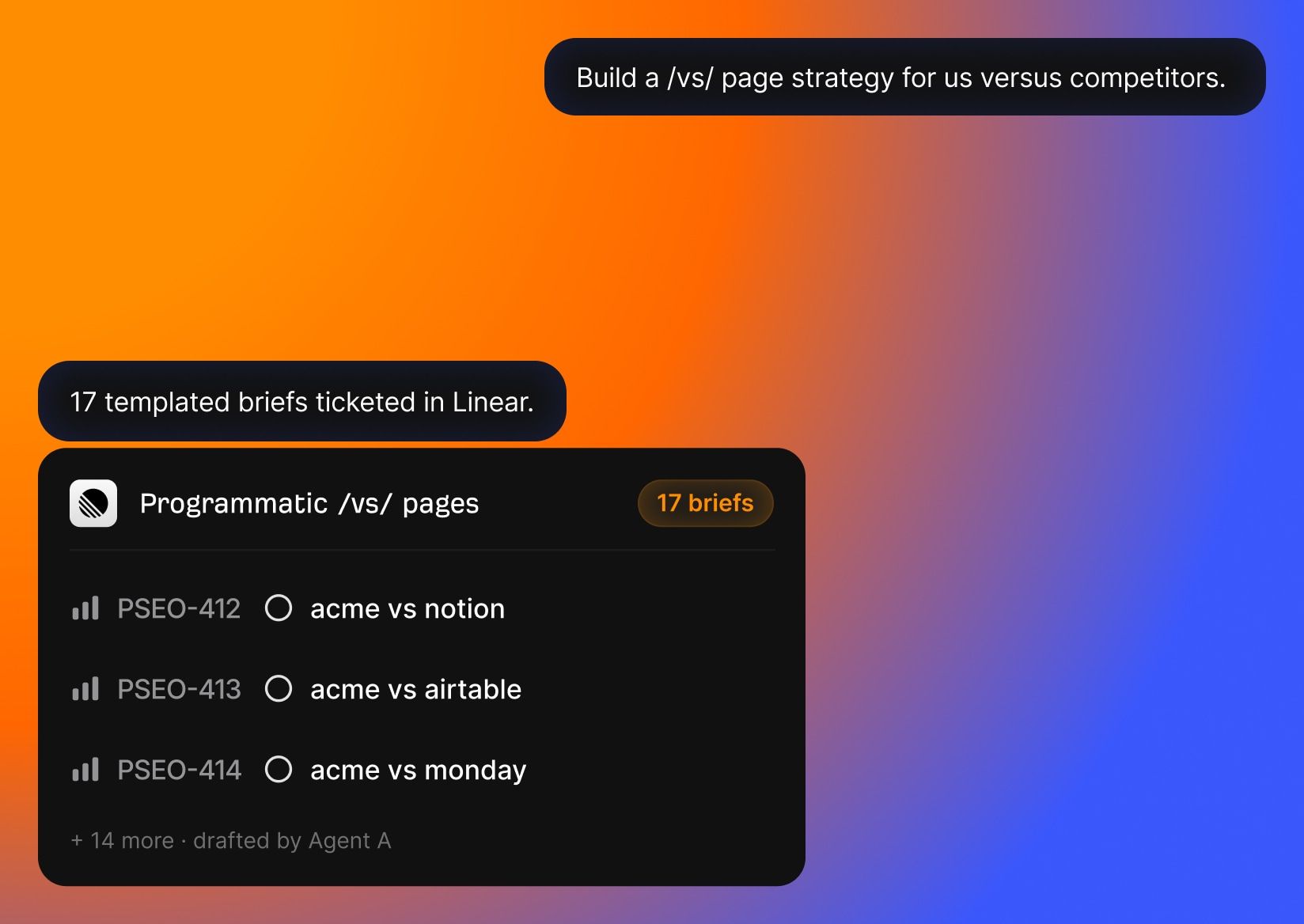
Usé Agent A para construir el Blog Pipeline, un flujo de trabajo de escritura asistida de 11 etapas que automatiza la creación de contenido SEO. Ingresas una palabra clave objetivo (o mejor aún, le pides a Agent A que encuentre una con la skill incorporada de Content Gap), y Agent A trabaja de manera secuencial a través de 11 etapas separadas para entregarte un borrador de artículo listo para publicar.
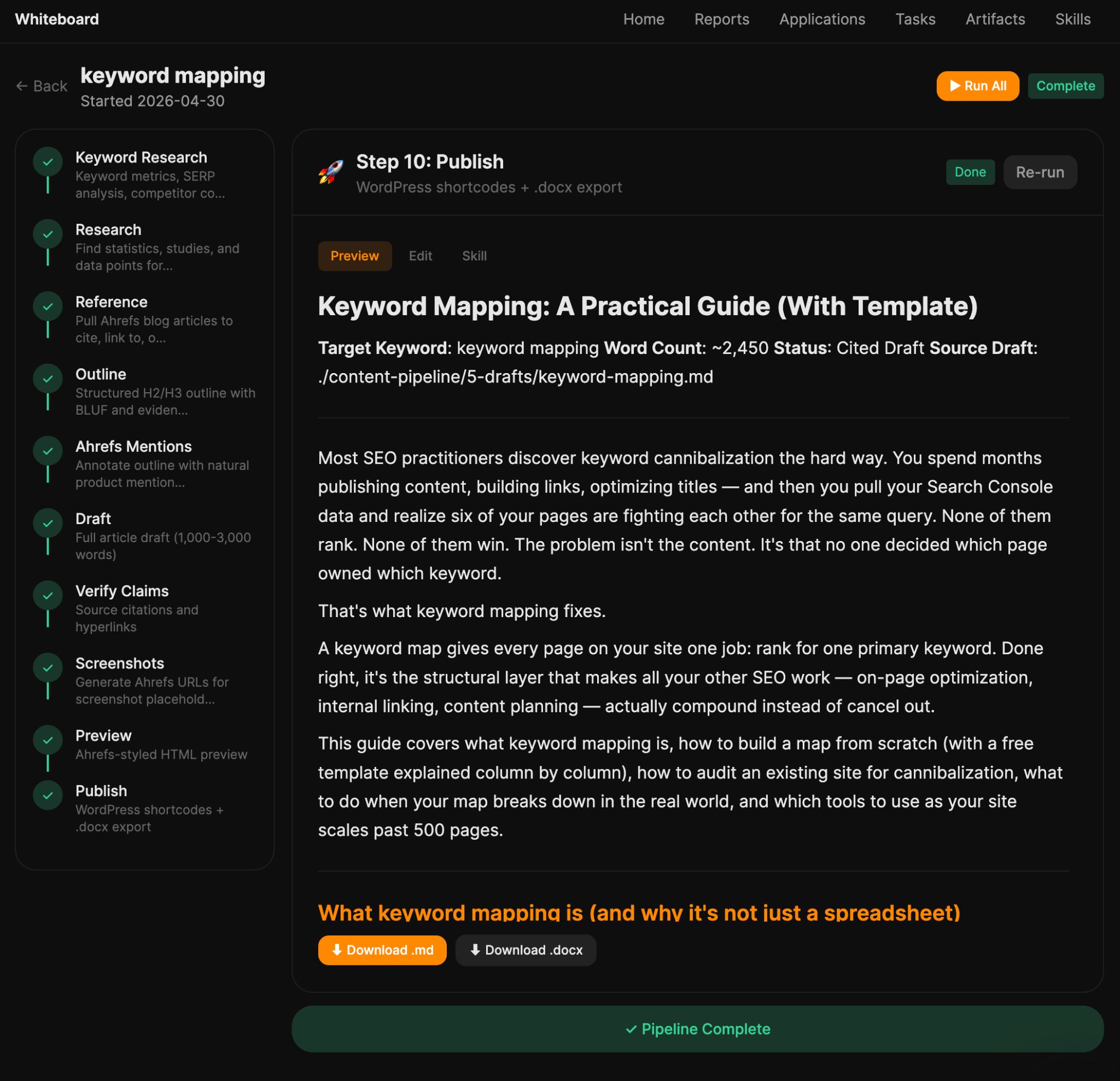
Agent A trabaja en serie a través del Keyword Research , análisis de las SERP, la captura de temas de AI Content Helper, el esquema en viñetas, menciones de productos, redacción, enlazado interno y búsqueda de citas, generación de imágenes, y formato para publicación. Puedes ver el resultado en cada etapa y editarlo directamente.
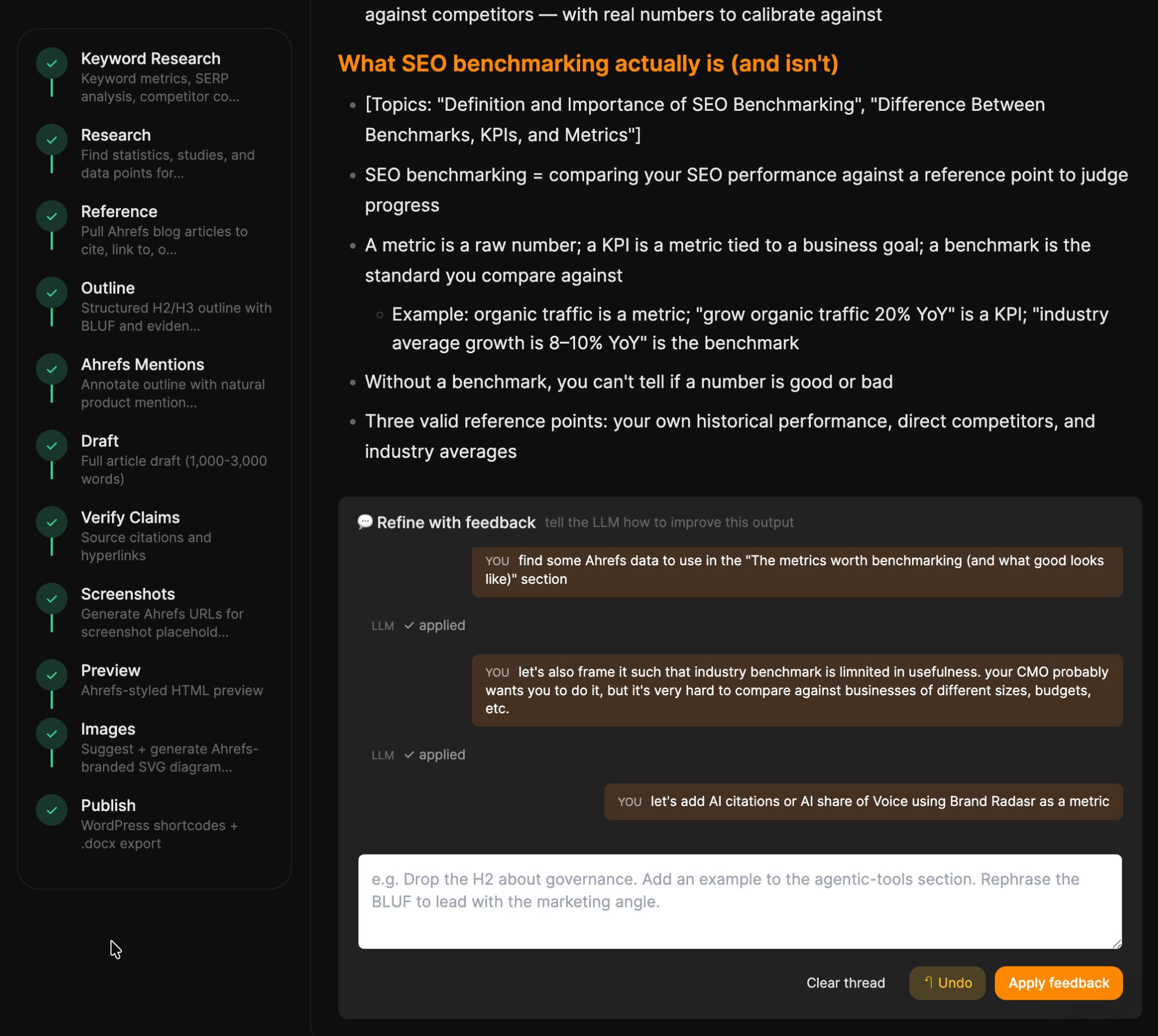
Sigo haciendo ajustes en el Blog Pipeline. Mis adiciones más recientes incluyen:
- Modo de edición “Vibe”: ahora puedes usar un chat para darle al LLM retroalimentación direccional sobre los esquemas y borradores de los artículos, y aplicará los cambios por ti. No más edición manual o copiar y pegar. ¡Puras buenas vibras, todo el tiempo!
- Guías de estilo personalizadas: sube tu propia guía de estilo y elige un perfil de voz por autor, entrenado con tus propias muestras de escritura.
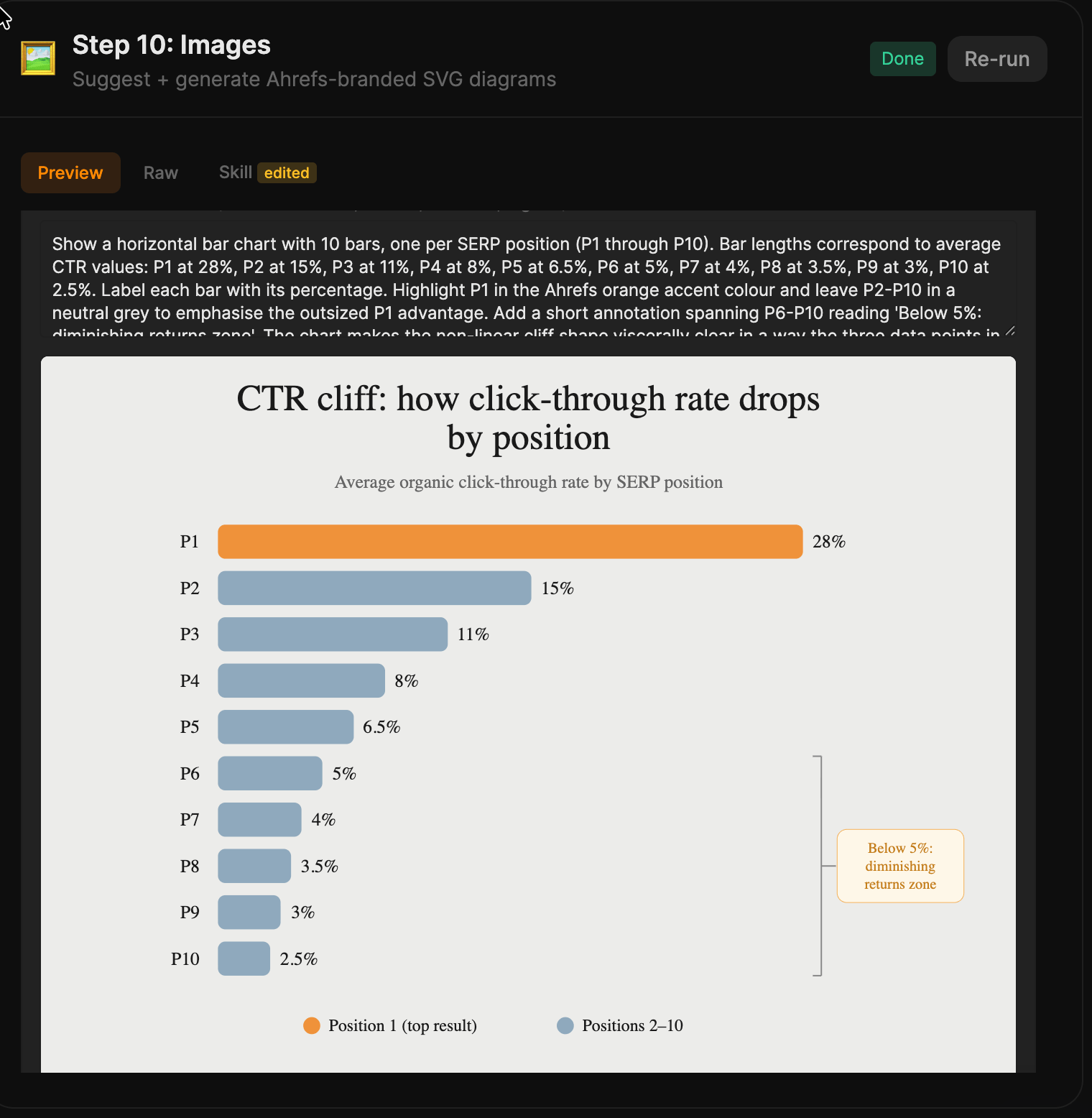
- Diagramas de flujo con tu marca: sugiere y genera diagramas de flujo con el estilo de tu marca.
Prompt de inicio:
Constrúyeme un pipeline de artículos largos asistidos. La entrada atómica es una palabra clave objetivo. Las etapas se ejecutan de forma secuencial como trabajos en segundo plano que la interfaz consulta: (1) Keyword Research vía Ahrefs, (2) obtención de las SERP de la competencia, (3) instantánea de temas de AI Content Helper, (4) esquema en viñetas con cobertura obligatoria del tema, (5) colocación de menciones de datos, (6) borrador completo, (7) pulido, (8) formato de shortcodes de WordPress + exportación a .docx. Cada etapa muestra su resultado, tiene un área de texto de "edición", y un chat de "refinar con comentarios" que vuelve a ejecutar la etapa con mis notas. La guía de estilo proviene de un perfil de voz por autor.
Tenemos más de 1,000 artículos en el blog de Ahrefs (incluyendo versiones localizadas), y mantenerlos todos actualizados es más que un trabajo a tiempo completo.
Usé Agent A para construir un proceso de actualización automatizado:
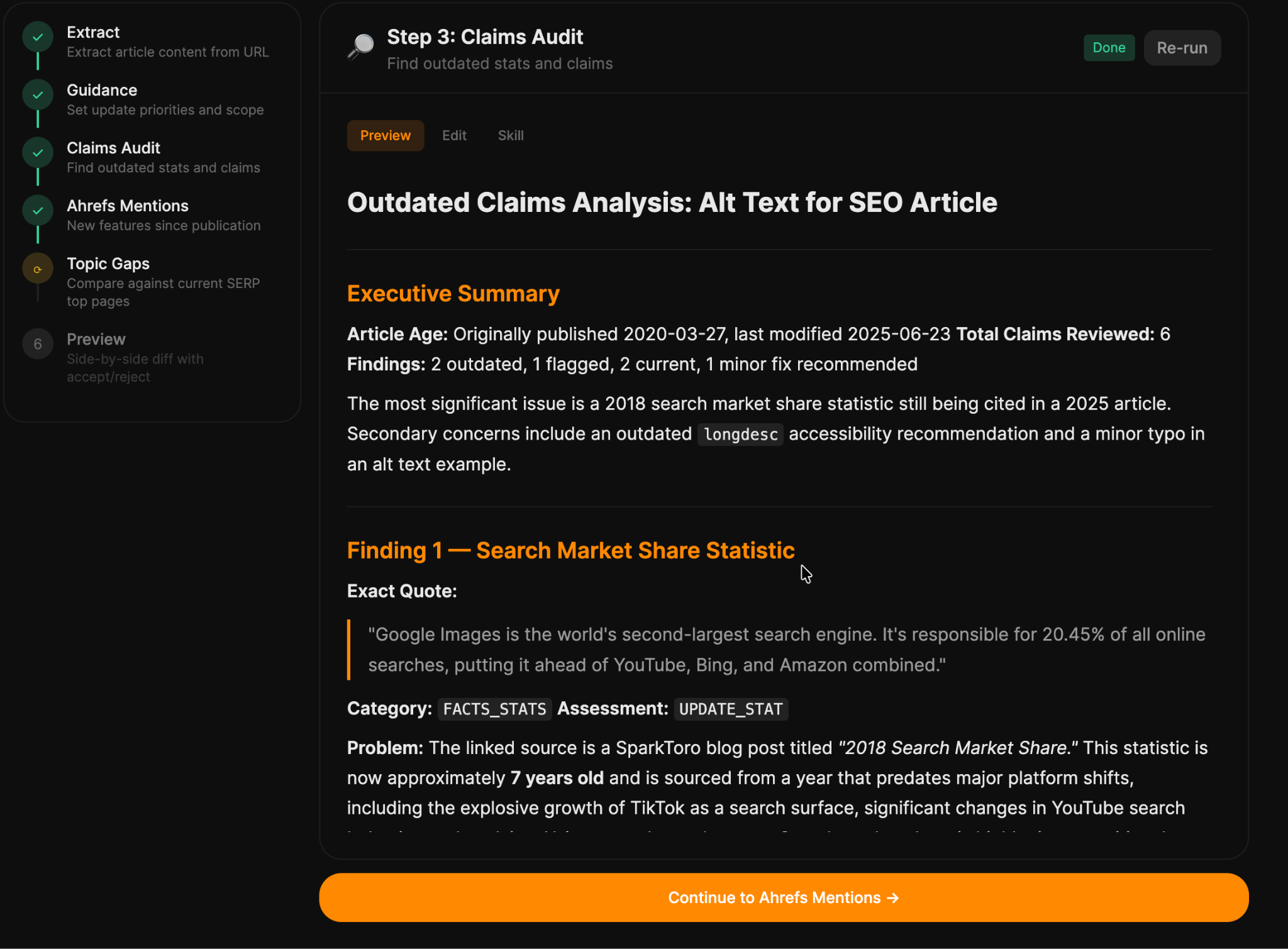
Comparte una URL publicada, y el pipeline recupera el artículo, extrae el contenido de la página, y luego ejecuta cuatro etapas de diagnóstico en paralelo:
- Guía: tú defines el alcance del proceso de actualización (una ligera actualización frente a una reescritura completa).
- Auditoría de afirmaciones: el LLM marca cada estadística, referencia de estudios y afirmación anticuada en el artículo, califica cada una por su grado de obsolescencia, y cuando es necesario, encuentra una URL de reemplazo para citar.
- Menciones de Ahrefs: revisa el artículo frente a las funciones de Ahrefs lanzadas desde su publicación y sugiere dónde incluir las nuevas.
- Brechas de temas: vuelve a ejecutar las SERP frente a las páginas competidoras actuales de mayor rango y muestra los temas que cubren esas páginas que la tuya no incluye.
Mi función favorita es la etapa de vista previa: una diferencia lado a lado entre tu artículo actual y las actualizaciones propuestas, con la opción de aceptar/rechazar cada cambio.
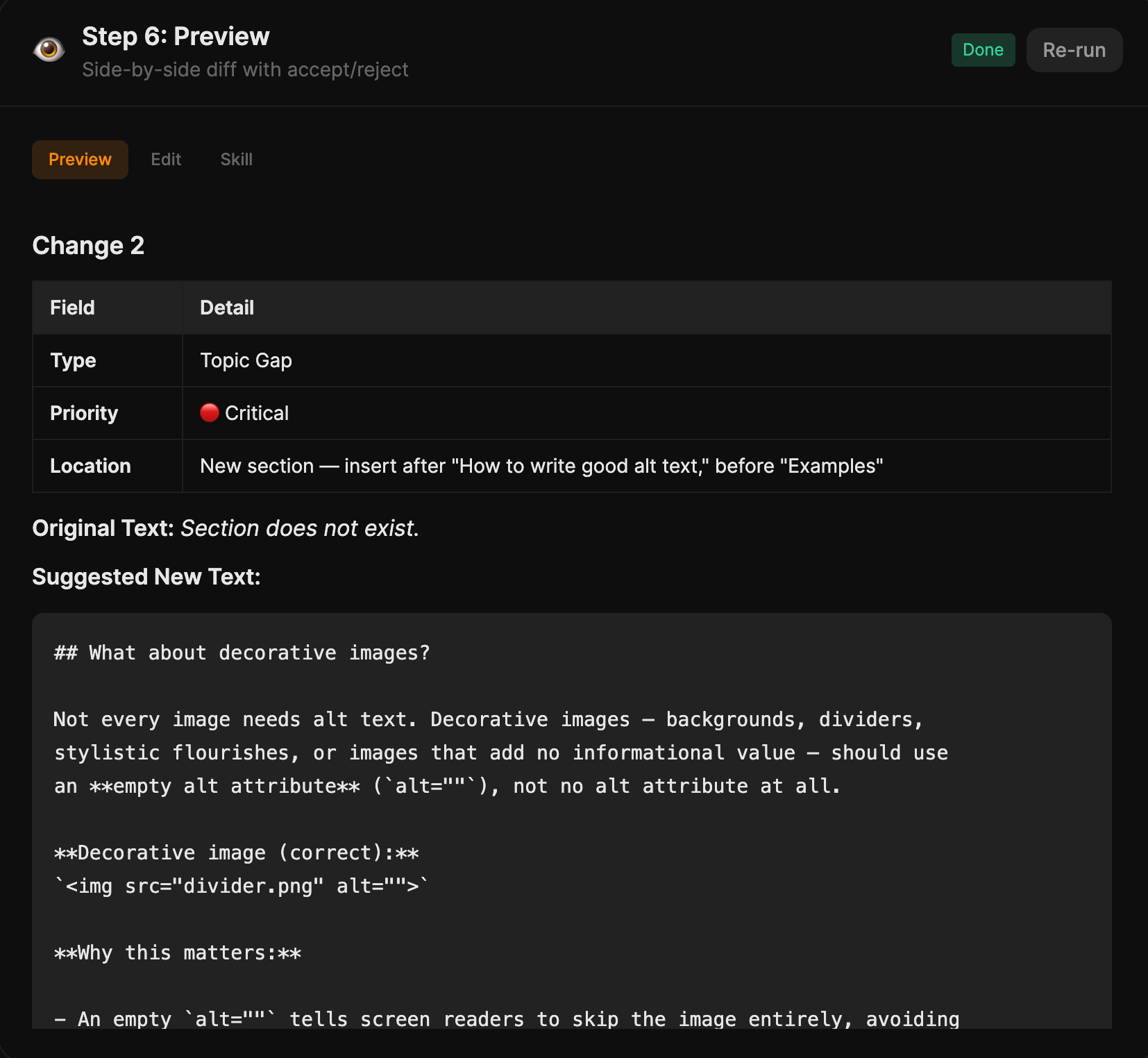
Nunca te quedas mirando un borrador reescrito por IA tratando de descubrir qué cambió. Ves el original a la izquierda, la edición propuesta a la derecha, y vas haciendo clic. El Update Pipeline es lo que hace que un sprint mensual de “actualizar 20 artículos antiguos” sea realmente manejable.
Prompt de inicio:
Constrúyeme un pipeline de actualización de artículos de blog. Entrada: una URL publicada. Recupera el artículo. Ejecuta cinco etapas de diagnóstico: (1) Guía — yo defino el alcance (actualización ligera vs. reescritura completa); (2) Auditoría de afirmaciones — el LLM extrae cada estadística, referencia a estudios y afirmación antigua, y califica cada una por obsolescencia con un reemplazo sugerido; (3) Menciones de Ahrefs — compara contra las funciones de Ahrefs lanzadas desde la publicación y sugiere dónde incluir nuevas; (4) Brechas de temas — vuelve a analizar las SERP, expone los temas que las páginas competidoras principales actuales cubren que la mía no; (5) Páginas con autoridad — encuentra fuentes enlazables publicadas desde mi artículo. Etapa final: diferencia lado a lado entre el artículo actual y las actualizaciones propuestas, con aceptar/rechazar por cambio. Exporta la versión aceptada como markdown y shortcodes de WordPress.
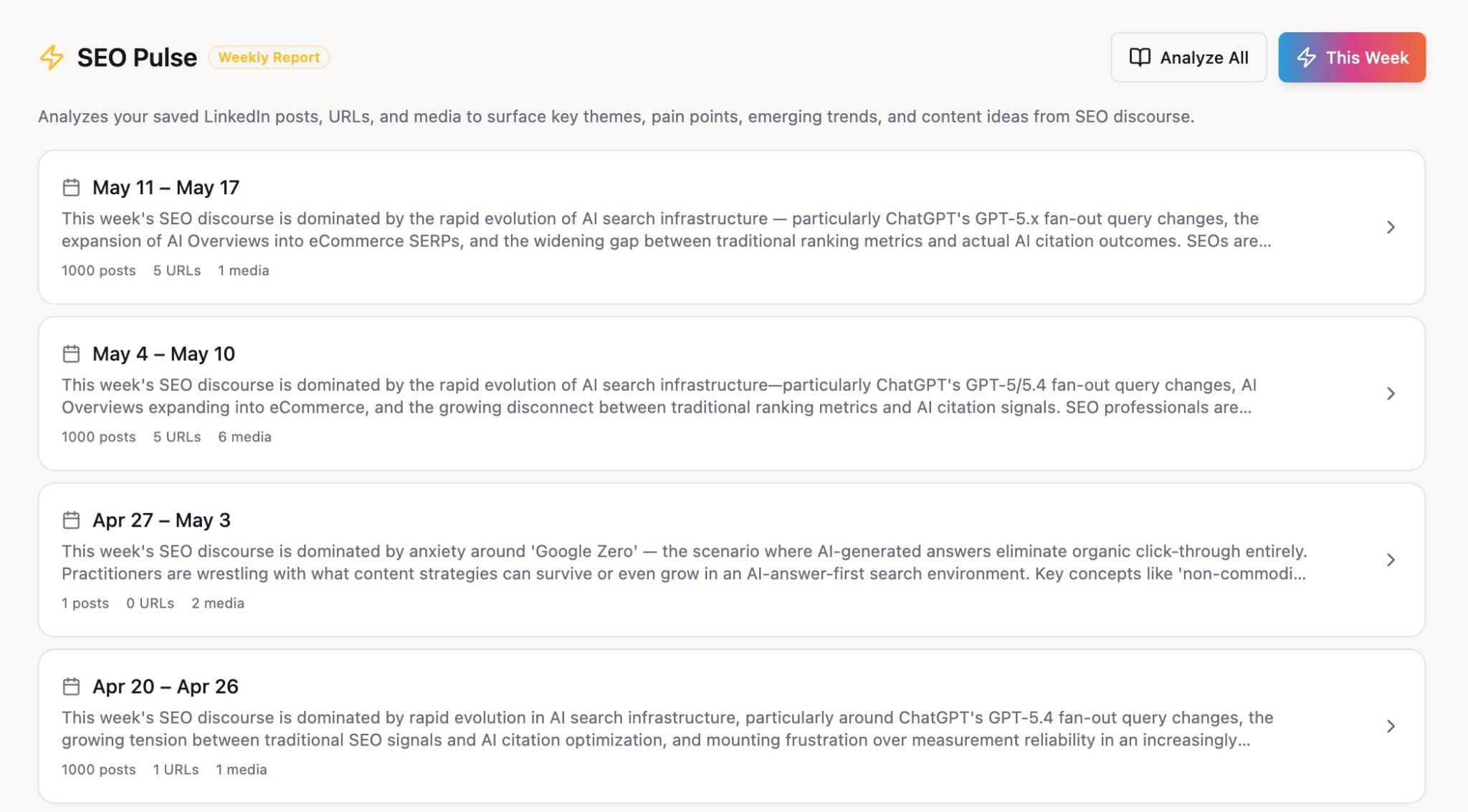
Cada mes comparto un reporte de rendimiento bastante detallado para el blog de Ahrefs. Combina muchas fuentes de datos, incluye un montón de visualizaciones y ofrece una capa de mi (teóricamente) experto análisis.
El reporte solía tomarme un día completo para crearlo. Ahora, Agent A lo genera por mí, automáticamente, en el segundo día de cada mes (para dar tiempo a que los datos de GSC terminen de recopilarse).
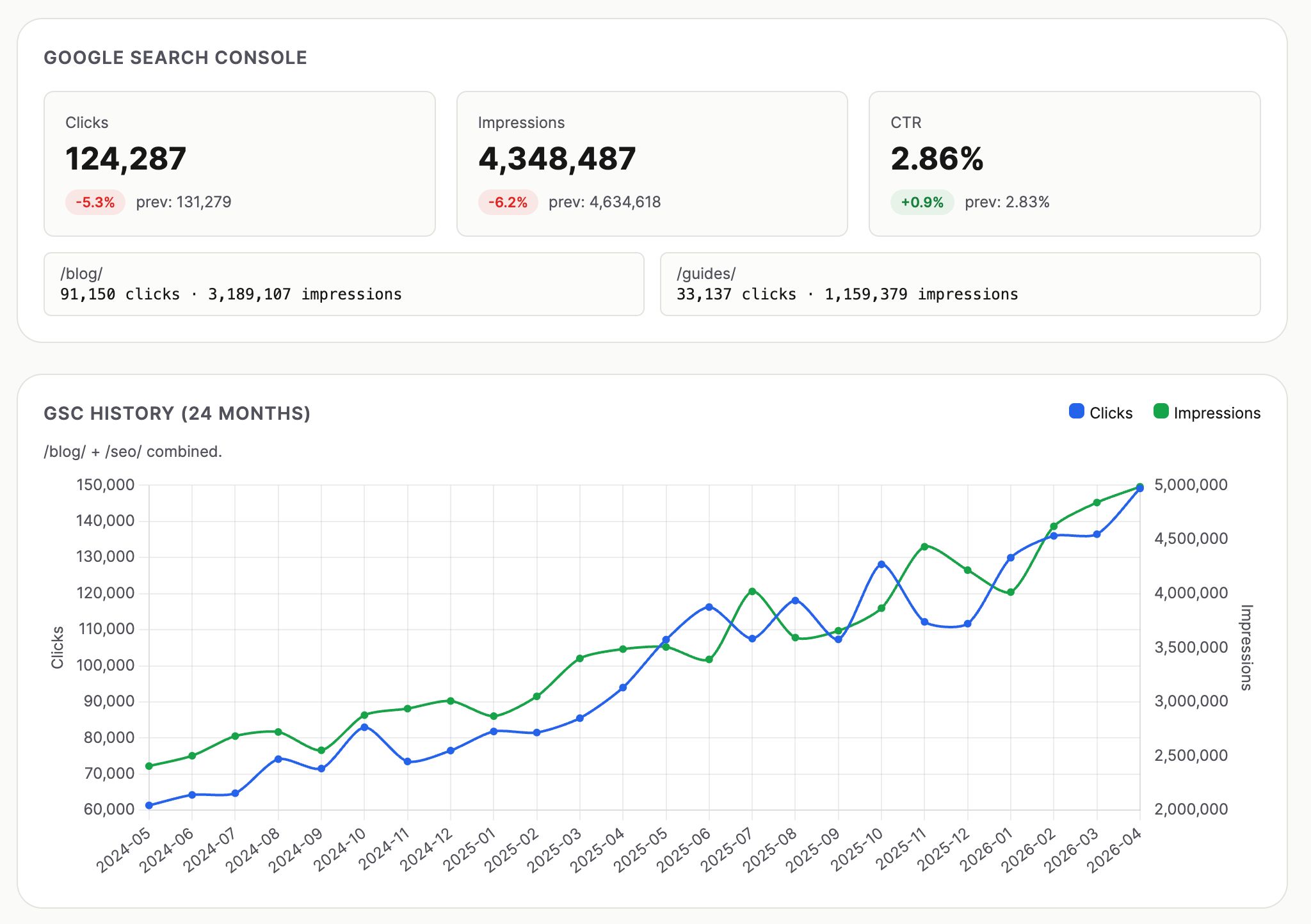
(Estos son solo datos ficticios… te puedes dar cuenta por el hecho de que están aumentando mes a mes…).
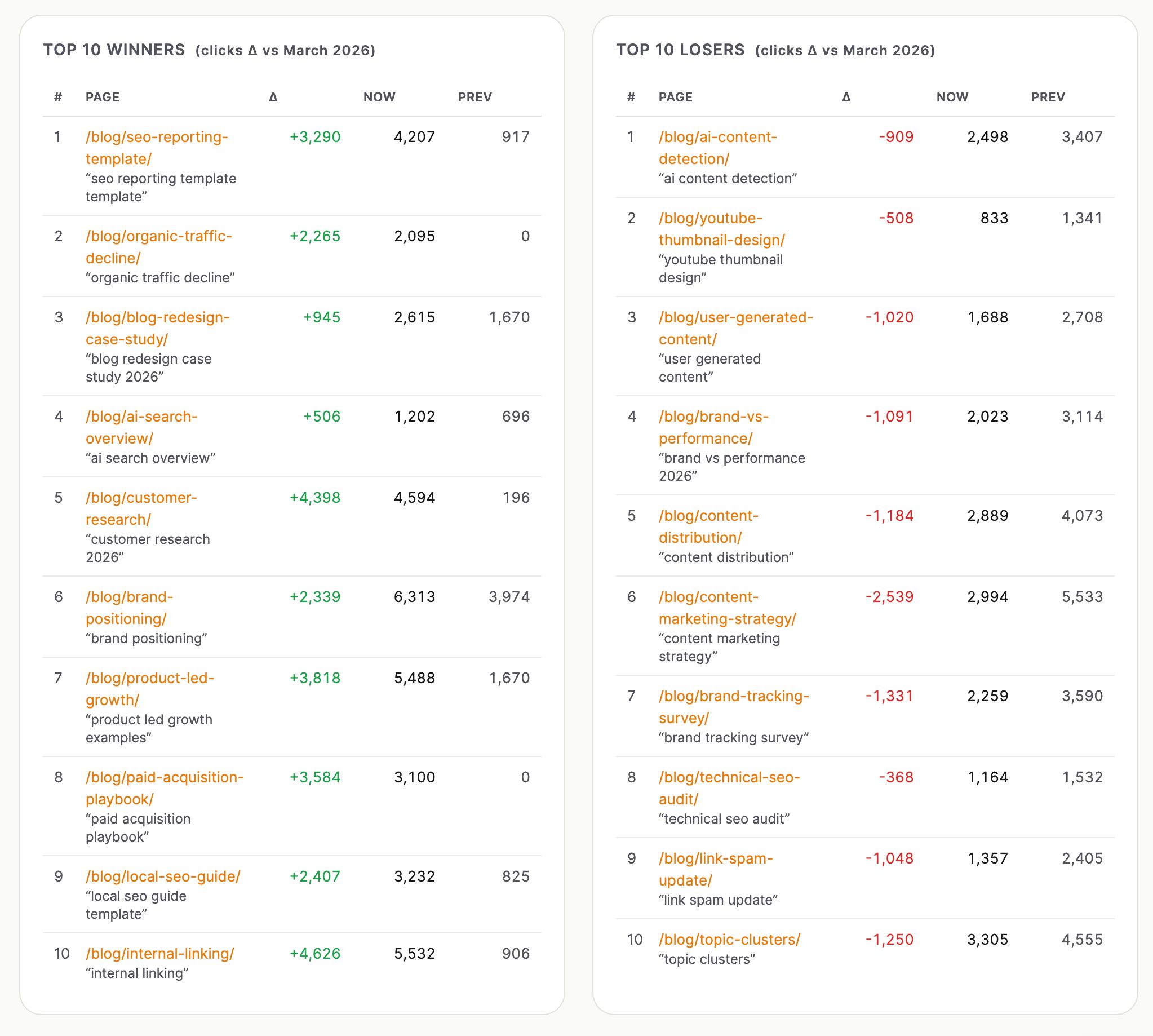
Agrupa Google Search Console, Web Analytics de Ahrefs, y el gráfico del panel de control de GSC en una sola vista con cuadros de KPI, un gráfico de tendencias de 12 meses, divisiones por subcarpetas, tablas de ganadores y perdedores, alertas diarias de anomalías y listas paginadas completas de todos los artículos SEO y no SEO.
También he incluido un campo de “resumen mensual” editable. La IA no escribe el análisis: ese es mi trabajo. En su lugar, analiza el rendimiento del mes y sugiere de 6 a 10 viñetas candidatas que puedo revisar y seleccionar para el resumen, si respaldan mi análisis.

Prompt de inicio:
Constrúyeme un reporte mensual de rendimiento del blog. Extrae datos de GSC + Web Analytics de Ahrefs para el mes actual. Muestra cuadros de KPI, un gráfico de tendencias de 12 meses con un marcador de migración, división por subcarpetas, tablas de ganadores/perdedores (paginadas, 25/página), alertas diarias de anomalías y tablas completas paginadas de cada artículo. En la parte superior, un "resumen mensual" editable en markdown con guardado automático. Al lado, un panel de IA que toma mis KPI guardados en caché + un área de texto de "contexto de la industria" que lleno con noticias de actualizaciones de algoritmos y produce de 6 a 10 viñetas candidatas que puedo copiar. Agrega un botón de "publicar en sitio público" que tome una captura de una vista de solo lectura.
Siempre me ha interesado la autoridad temática: la idea de que Google recompensa a los sitios web que cubren su área de especialización con un detalle exhaustivo. Tenemos un blog inmenso y extenso, y quería ver cómo rendían nuestros artículos “fuera de tema” en relación con nuestros artículos centrales.
Así que Agent A realizó el análisis por mí. Para ser un poco técnico, la Auditoría Semántica del Blog mapeó cada URL de nuestro blog en un espacio vectorial, calculó un centroide del sitio y agrupó las páginas según su distancia del coseno en central/cercano/medio/lejano.
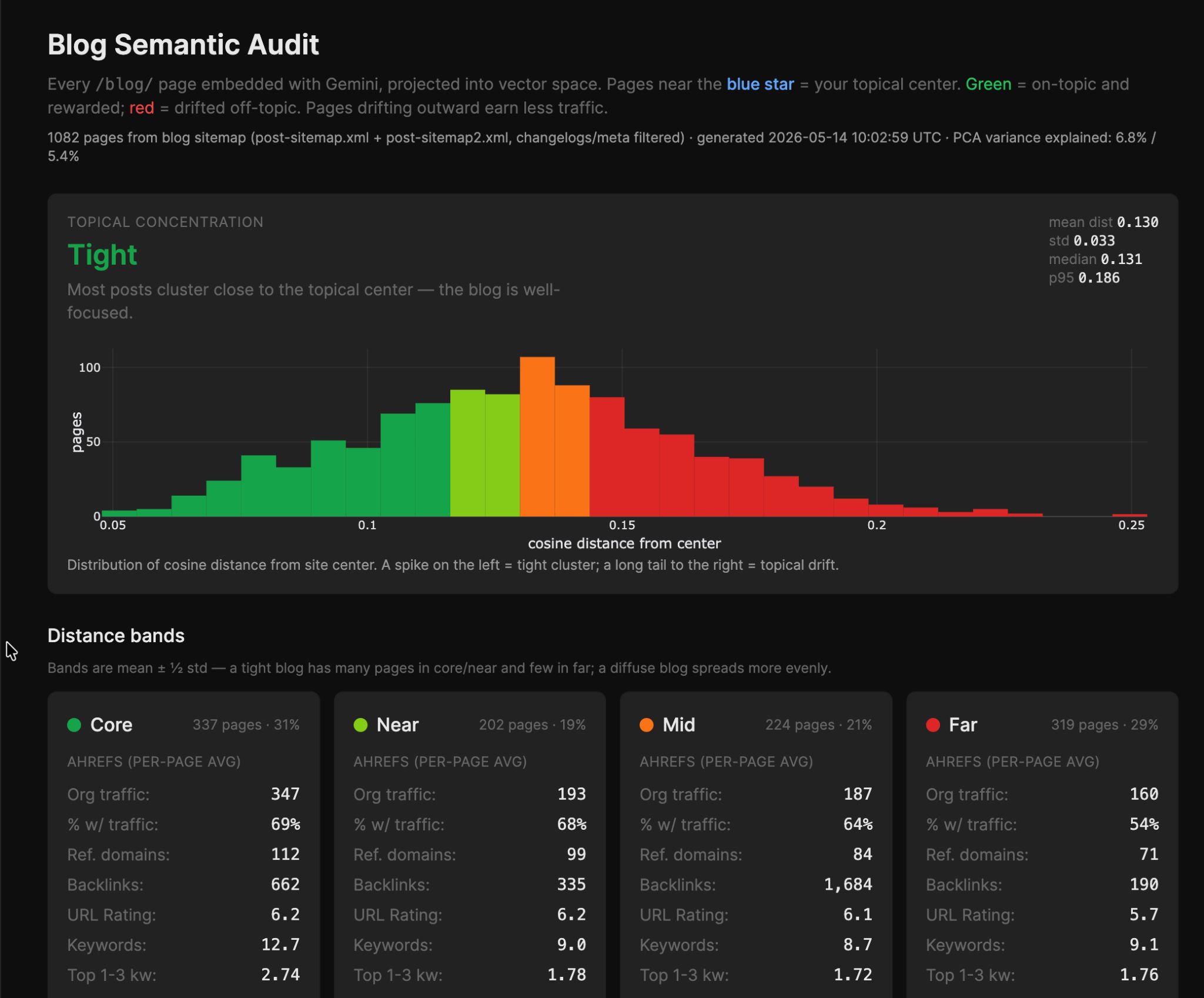
Luego enriqueció cada página con datos de tráfico de Ahrefs, de modo que cada grupo te muestra el tráfico orgánico promedio, los dominios de referencia , el URL Rating y la cobertura de palabras clave. Incluso agrupó artículos relacionados para resaltar los clústeres de temas.
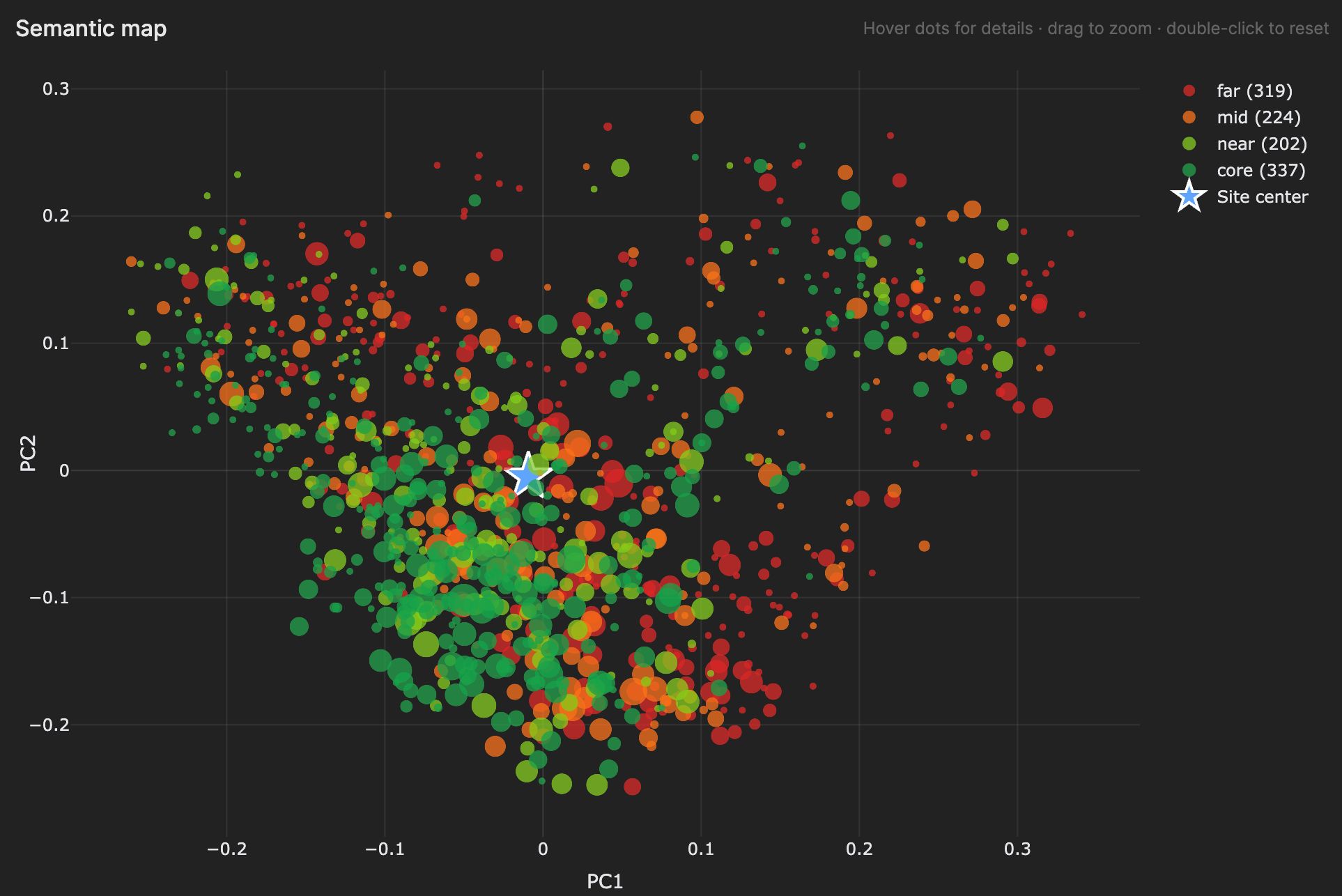
El resultado responde a una pregunta que siempre quise responder: “¿Mis artículos fuera de tema rinden menos que mis artículos centrales, y por cuánto?” En nuestro blog, la respuesta es sí: las páginas centrales obtienen aproximadamente el doble de tráfico que las páginas lejanas.
Prompt de inicio:
Ejecuta una auditoría semántica de mi blog. Extrae cada URL del mapa del sitio, recupera el contenido, incrusta cada página (media de incrustaciones de pasajes) utilizando un modelo de incrustación 3072-d. Calcula el centroide del sitio y agrupa las páginas por su distancia de coseno respecto a él (central/cercano/medio/lejano usando la media ± 1/2σ — no cuartiles). Enriquece cada URL con el Batch Analysis de Ahrefs (tráfico orgánico , dominios de referencia , URL Rating, palabras clave). Ejecuta k-medias con escaneo de silueta (k=2..12) para encontrar clústeres de temas naturales. Salida: histograma de grupos, promedios de Ahrefs por grupo, resúmenes de clústeres con URLs de muestra, y un veredicto sobre si el blog es ajustado o difuso.
Paso mucho tiempo revisando blogs de la competencia y buscando inspiración para artículos. Cuando le pedí ayuda a Agent A, construyó una herramienta llamada Competitor Feed.
Competitor Feed vigila una lista de mapas de sitio de blogs de la competencia y saca a la luz nuevos artículos cada día. Cada publicación se guarda con un título, fecha de publicación, un extracto del primer párrafo y un resumen de una sola línea generado por el LLM. Luego clasifico cada elemento en guardar/descartar/ignorar: las buenas ideas se guardan en mi lista de ideas de contenido.
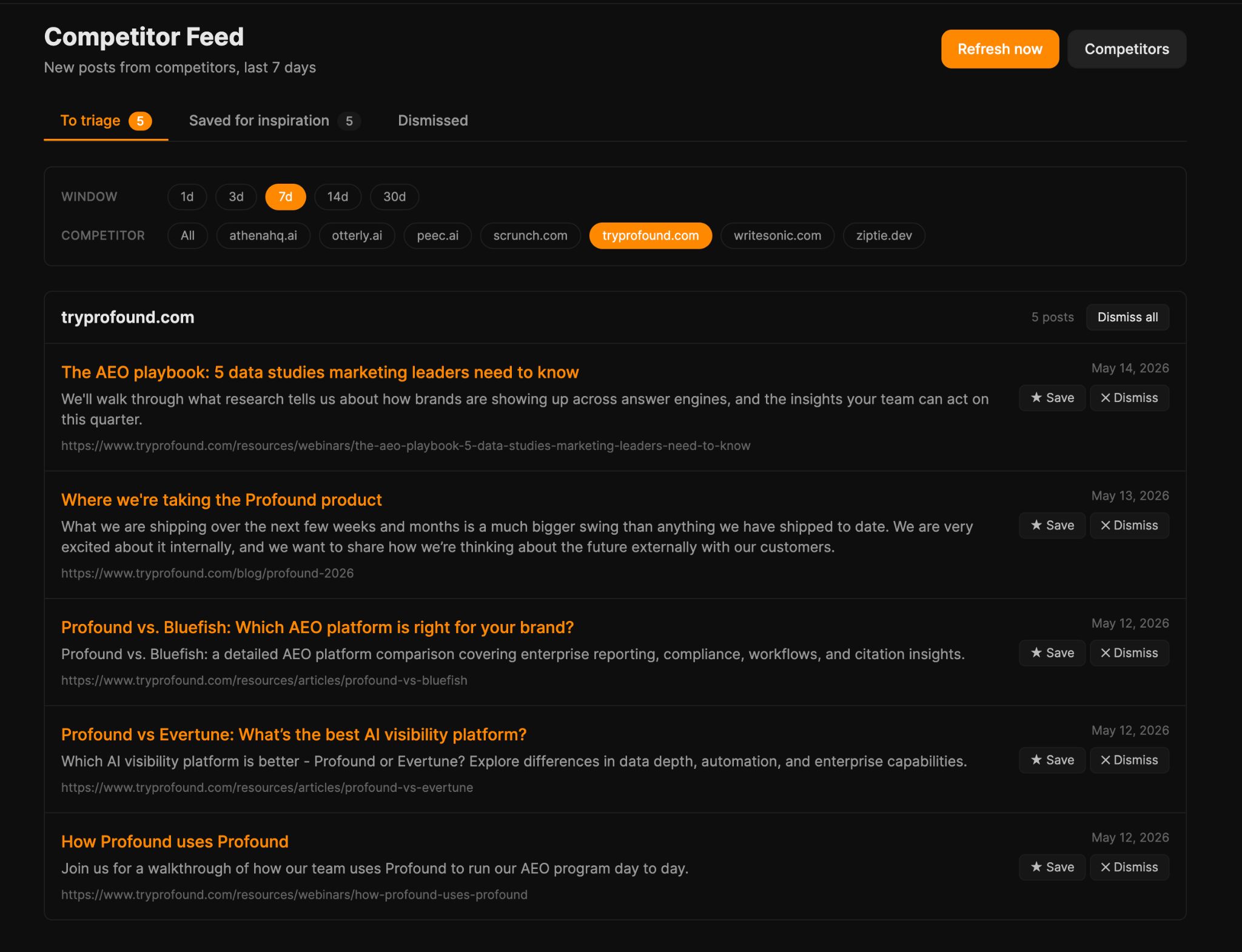
Cuando guardas una publicación, la aplicación activa un pipeline de Keywords Explorer contra el título: extrae un tema semilla de 2 a 3 palabras, obtiene sugerencias de palabras clave, las clasifica por volumen de búsqueda y la intención de búsqueda, y adjunta los resultados a la fila guardada.
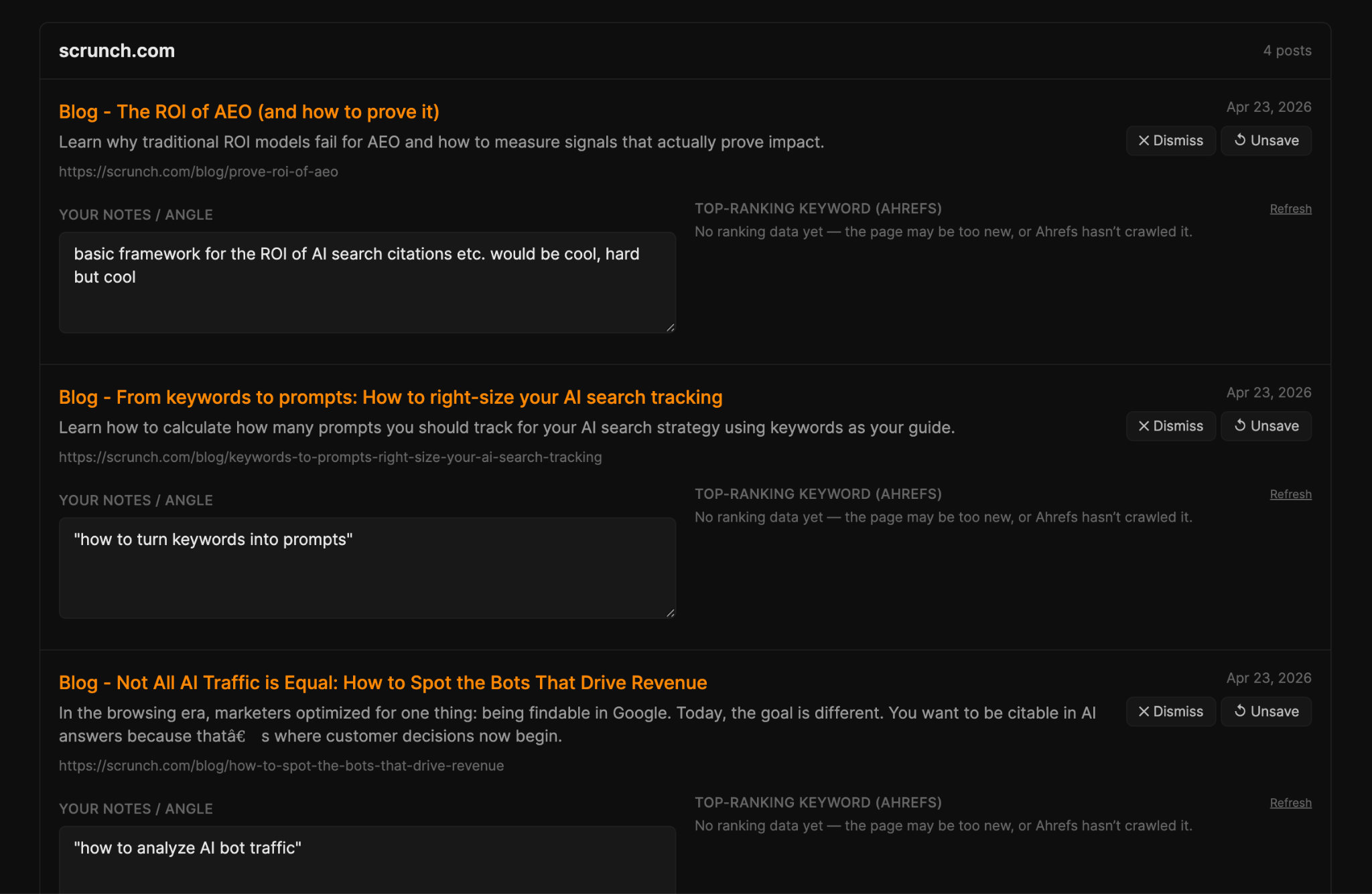
Así que “monitorear a la competencia” deja de ser un feed pasivo y se convierte en un pipeline de palabras clave activo: cada artículo interesante de la competencia produce una lista de palabras clave que nosotros podríamos perseguir sobre el mismo tema.
Prompt de inicio:
Constrúyeme un monitor de blogs de la competencia. Yo configuro una lista de URLs de mapas de sitio de blogs competidores. Un trabajo diario compara cada mapa de sitio, recupera las nuevas URLs, y para cada nueva publicación muestra el título, la fecha de publicación, el extracto del primer párrafo y un resumen de una línea de LLM sobre el enfoque. Estados de clasificación: nuevo / guardado / descartado. Cuando guardo un artículo, ejecuta un pipeline de Keywords Explorer contra el título: extrae un tema semilla de 2 a 3 palabras, recupera sugerencias de palabras clave, clasifica por volumen de búsqueda e intención de búsqueda, y adjunta los resultados a la fila guardada. El resultado son listas de palabras clave inspiradas en la competencia, no una fila de lectura pasiva.
Louise construyó el LinkedIn Scrapbook, su propio archivo personal para la inspiración de contenido. Usa Obsidian Web Clipper para guardar publicaciones de LinkedIn como Markdown en su aplicación Scrapbook, incluyendo el texto completo, el autor, las métricas de interacción y los medios.
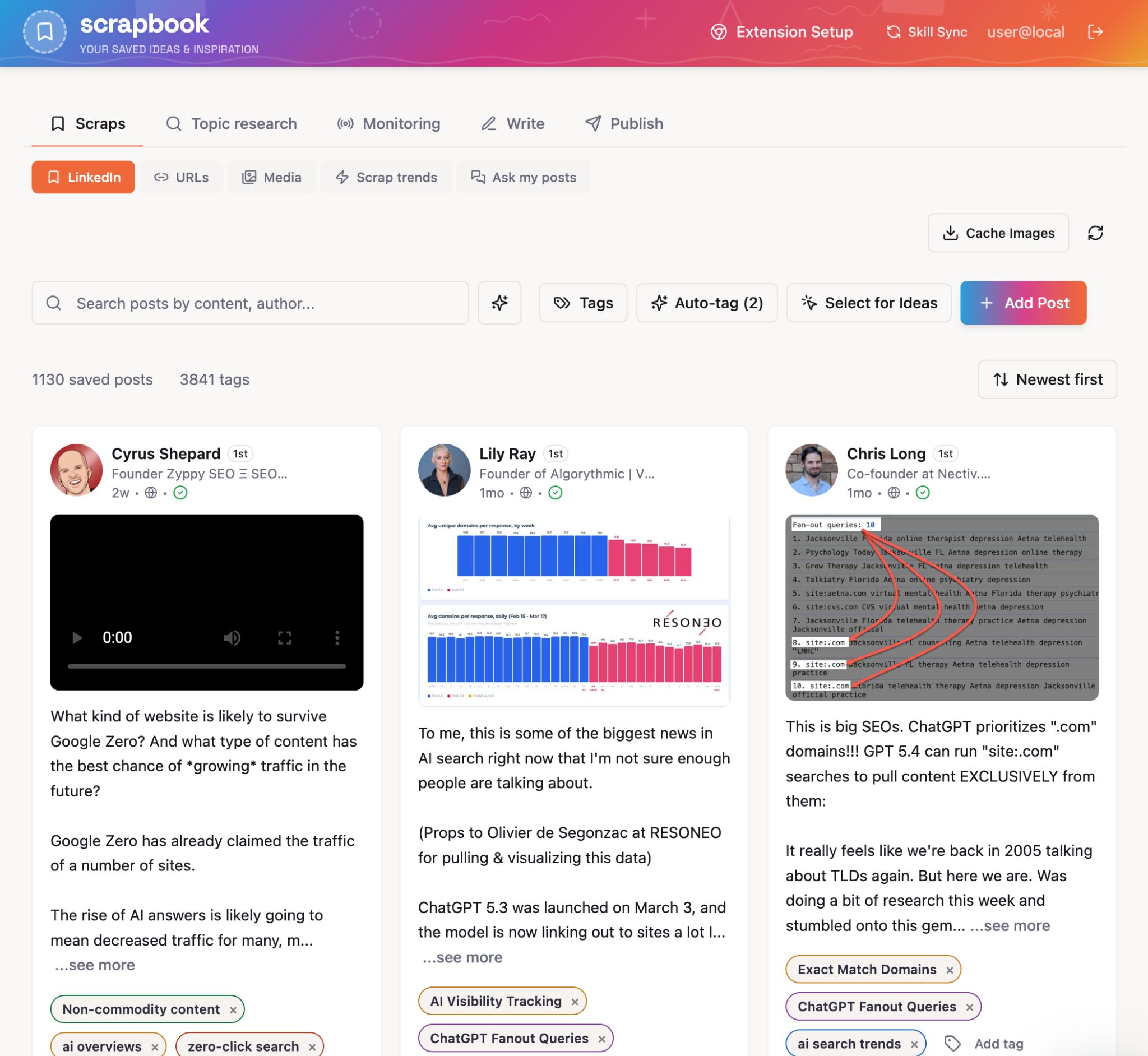
Scrapbook se vuelve muy interesante cuando has guardado algo de contenido, gracias a todas las herramientas adicionales que agregó Louise, como:
- Palabras clave en tendencia: esto revela palabras clave que están ganando popularidad en las publicaciones que has guardado, para que puedas detectar los temas hacia los que se inclina tu red antes de que lleguen a la prensa SEO.
- Brecha de contenido: compara los temas en tus publicaciones guardadas con los temas que has publicado, con la intención de revelar “cosas que estás consumiendo pero sobre las que no has escrito”.
- Buscador de ejemplos: cuando estás redactando un artículo y necesitas un ejemplo relevante, puedes usar la búsqueda semántica en todo el archivo para encontrar contenido relevante.
- Pregúntale a tus recortes: consulta tu base de datos de fragmentos guardados (con preguntas como “¿qué scraps mencionan las AI Overviews?”).
Prompt de inicio:
Constrúyeme una aplicación de archivo de LinkedIn con una extensión para Chrome. La extensión agrega un botón de "Guardar en Scrapbook" a cada publicación de LinkedIn; un clic captura el texto de la publicación, el autor, las métricas de interacción y las URLs de los medios y los envía mediante POST a mi aplicación de Console. La aplicación de Console almacena las publicaciones en Postgres con búsqueda de texto completo. Construye tres herramientas sobre este corpus: (1) Palabras clave en tendencia — extrae temas semilla de las publicaciones guardadas, muestra los temas en auge durante un período móvil; (2) Brecha de contenido — compara los temas en las publicaciones guardadas contra los temas en mis artículos publicados en el blog, y genera lo que estoy consumiendo pero sobre lo que no he escrito; (3) Buscador de ejemplos — búsqueda semántica sobre el archivo con enlaces profundos a LinkedIn. Agrega también una extensión genérica de recorte web para URLs que no sean de LinkedIn.
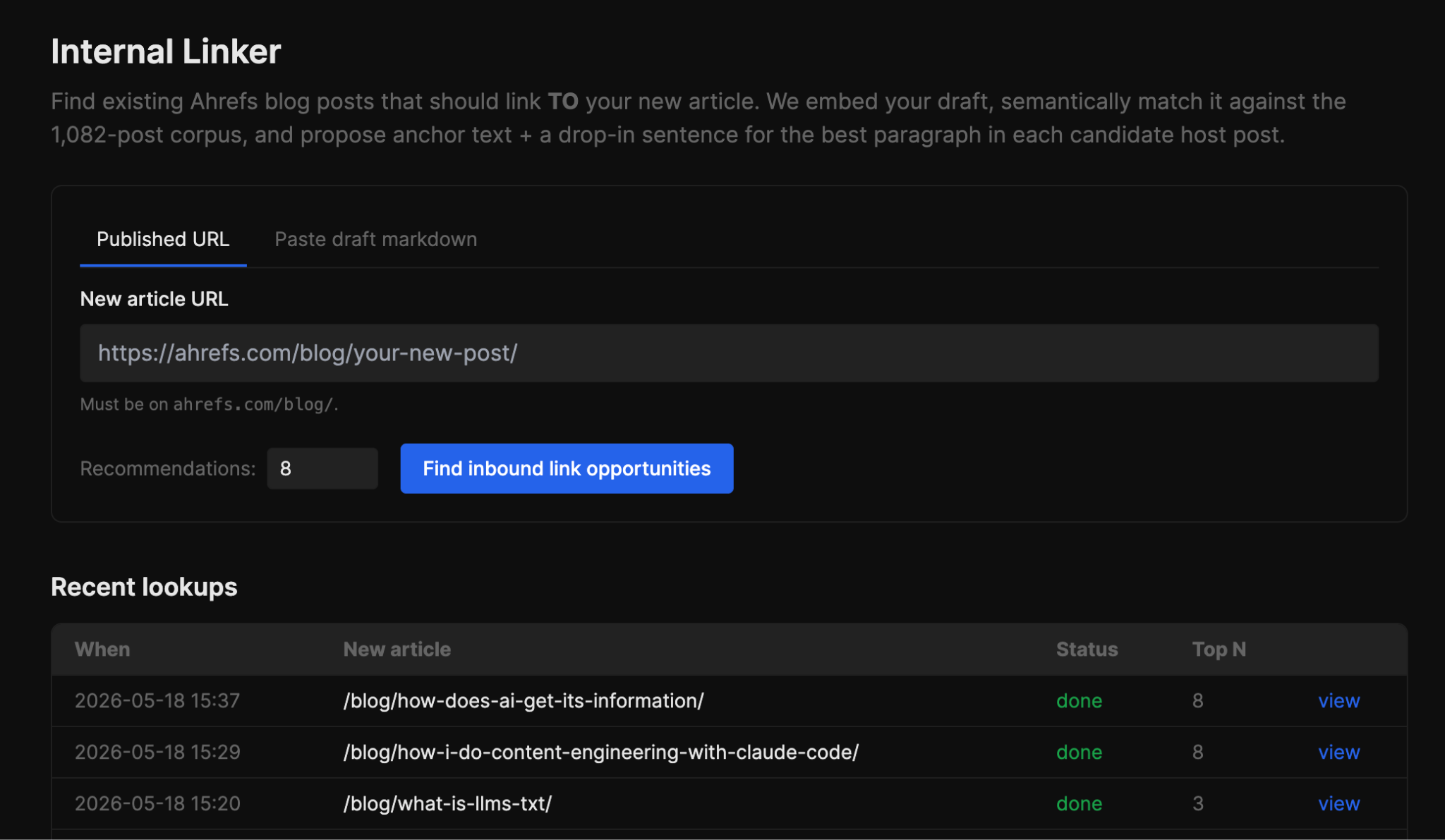
Los enlaces internos son una de esas tareas SEO que “deberían” hacerse cada vez que publicamos y casi nunca se hacen.
Así que le pedí a Agent A que construyera el Internal Linker. Aliméntalo con un nuevo artículo (ya sea un enlace publicado o un borrador en markdown para piezas no publicadas) y encuentra los artículos existentes más relevantes que deberían enlazarlo.
Bajo el capó, incrusta el artículo de entrada con Gemini y realiza una comparación de coseno contra todos los demás artículos de nuestro mapa del sitio. A los mejores candidatos luego se les vuelve a calificar con un peso especial de tráfico para priorizar los enlaces de artículos con mucho tráfico orgánico existente.
También excluye automáticamente cualquier artículo que ya te esté enlazando, analizado desde el cuerpo markdown de cada candidato, para que no te quedes mirando recomendaciones que ya has usado.
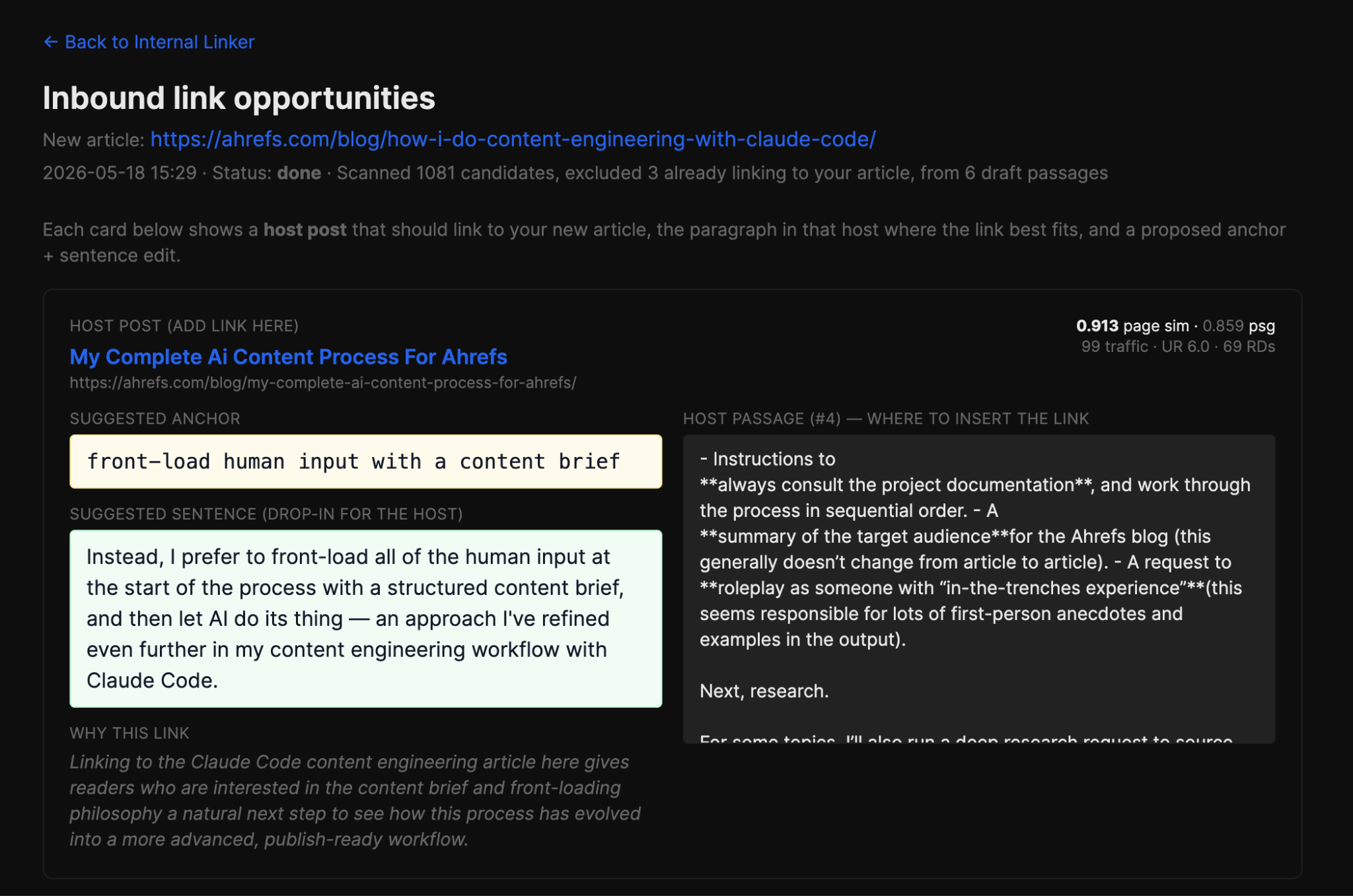
Para cada artículo recomendado, la herramienta también identifica el párrafo individual más alineado semánticamente con tu nuevo artículo. Luego, Claude Sonnet 4.6 redacta un texto ancla natural de 2 a 6 palabras y reescribe la oración del párrafo anfitrión para incluirlo, listo para pegar directamente en el artículo existente.
Prompt de inicio
Constrúyeme una herramienta de enlazado interno. Entrada: ya sea una URL de blog publicada o un borrador pegado en markdown para piezas no publicadas. Incrusta el artículo de entrada con Gemini y realiza una comparación de coseno contra mis vectores de artículos de blog preguardados en caché. Vuelve a calificar los mejores candidatos con ponderación de autoridad: 0.7 × similitud + 0.3 × log (org_traffic) — favorece los anfitriones de alto tráfico donde un enlace realmente mejora el posicionamiento. Excluye automáticamente cualquier anfitrión que ya me enlace (analiza el cuerpo markdown de cada candidato). Para cada anfitrión principal, identifica el párrafo individual más alineado semánticamente con el artículo de entrada — ahí es donde va el enlace. Haz que Claude redacte un texto ancla natural de 2 a 6 palabras y reescriba una oración en el párrafo anfitrión para incluirlo. Contexto por recomendación: similitud de la página, similitud del pasaje, tráfico orgánico del anfitrión / URL Rating / dominios de referencia, el párrafo anfitrión, y una justificación de una línea. Guarda en caché los vectores de pasaje por anfitrión para que las búsquedas repetidas sean instantáneas. Ejecuta las búsquedas de forma asíncrona con estado de paso en vivo; guarda cada búsqueda en el historial.
Reflexiones finales
Si eres cliente de Ahrefs, puedes probar Agent A gratis durante un mes.
Prueba algunos de estos prompts como inspiración, construye algunas aplicaciones y genera algunos reportes, y ve por ti mismo cuántas de las partes tediosas de tu trabajo Agent A puede resolver por ti.
¿Tienes preguntas? Estamos en LinkedIn y en X.


