Ahí es donde estamos con la optimización para la visibilidad en los LLM (LLMO), y necesitamos más expertos que denuncien este comportamiento en nuestra industria, como Lily Ray ha hecho en esta publicación:
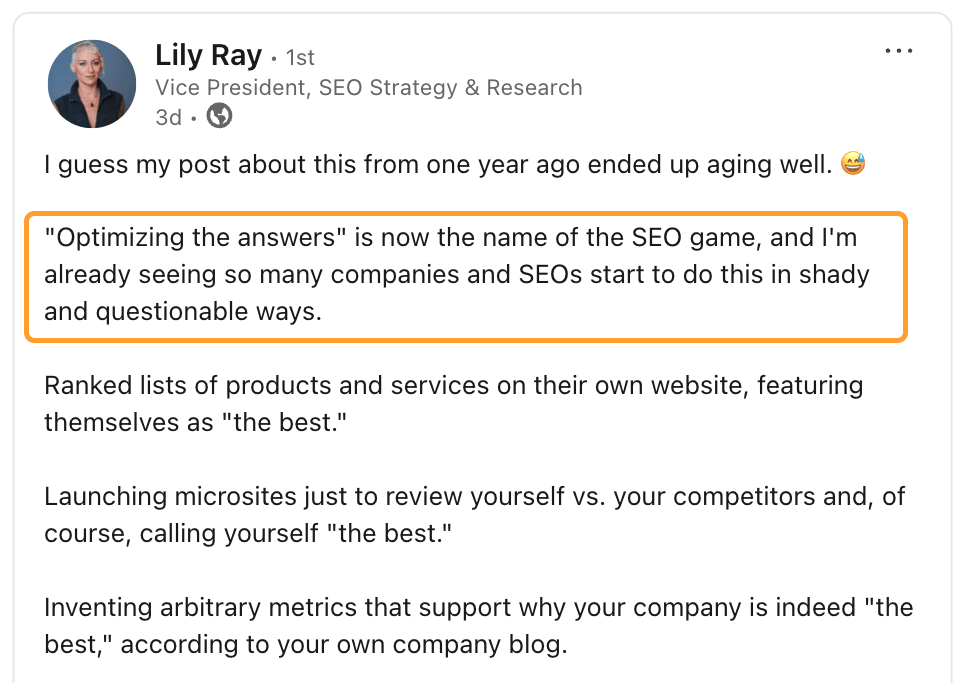
Si estás engañando, esculpiendo o manipulando un modelo de lenguaje grande para que te note y mencione más, hay una gran probabilidad de que sea “black hat”.
Es como el SEO del 2004, cuando el “keyword stuffing” y los esquemas de enlaces funcionaban un poco demasiado bien.
Pero esta vez, no solo estamos reorganizando los resultados de búsqueda. Estamos dando forma a la base del conocimiento de la que se nutren los LLM.
En tecnología, black hat normalmente se refiere a tácticas que manipulan sistemas de maneras que pueden funcionar temporalmente pero van en contra del espíritu de la plataforma, son poco éticas, y a menudo tienen un efecto contraproducente cuando la plataforma se da cuenta.
Tradicionalmente, el black hat SEO ha tenido este aspecto:
- Poner texto blanco con exceso de palabras clave sobre un fondo blanco
- Añadir contenido oculto a tu código, visible solo para los motores de búsqueda
- Crear redes de blogs privadas solo para enlazar a tu sitio web
- Mejorar rankings dañando intencionadamente los sitios web de la competencia
- Y más…
Ganó importancia porque (aunque era spam), funcionó para muchos sitios web durante más de una década.
El black hat en LLMO se ve diferente de esto. Y, mucho de ello no parece inmediatamente spam, por lo que puede ser difícil de detectar.
Sin embargo, el black hat en LLMO también se basa en la intención de manipular de forma no ética patrones de lenguaje, procesos de entrenamiento de LLM, o conjuntos de datos para beneficio propio.
Aquí hay una comparación lado a lado para darte una idea de lo que podría incluir el black hat en LLMO. No es exhaustivo y es probable que evolucione a medida que los LLM se adapten y crezcan.
| Táctica | SEO | LLMO |
|---|---|---|
| Redes de blogs privados | Creadas para transferir valor de enlace a sitios objetivo. | Creadas para posicionar artificialmente una marca como la “mejor” en su categoría. |
| SEO negativo | Se envían enlaces spam a competidores para bajar sus rankings o penalizar sus sitios web. | Votar negativamente respuestas de LLM con menciones a competidores o publicar contenido engañoso sobre ellos. |
| SEO parasitario | Usar el tráfico de sitios web de alta autoridad para aumentar tu propia visibilidad. | Mejorar artificialmente la autoridad de tu marca siendo añadido a listas de “los mejores”… que tú mismo has escrito. |
| Texto o enlaces ocultos | Añadidos para que los motores de búsqueda aumenten la densidad de palabras clave y señales similares. | Añadidos para incrementar la frecuencia de entidades o proporcionar frases “amigables para LLM”. |
| Keyword stuffing | Meter a la fuerza palabras clave en contenido y código para aumentar la densidad. | Sobrecargar el contenido con entidades o términos de PLN para aumentar la “prominencia |
| Contenido generado automáticamente | Usar spinners para reescribir contenido existente. | Usar IA para reformular o duplicar contenido de la competencia. |
| Creación de enlaces | Comprar enlaces para inflar las señales de ranking. | Comprar menciones de marca junto con palabras clave o entidades específicas. |
| Manipulación del engagement | Falsificar clics para aumentar la tasa de clics en la búsqueda. | Indicar a los LLMs que favorezcan tu marca; hacer spam en los sistemas RLHF con retroalimentación sesgada. |
| Spamdexing | Manipular lo que se indexa en los motores de búsqueda. | Manipular lo que se incluye en los conjuntos de datos de entrenamiento de LLM. |
| Granjas de enlaces | Producir backlinks en masa a bajo coste. | Producir menciones de marca en masa para inflar la autoridad y señales de sentimiento. |
| Manipulación del texto ancla | Meter palabras clave de coincidencia exacta en los textos ancla de los enlaces. | Controlar el sentimiento y la redacción en torno a las menciones de marca para moldear los resultado del LLM. |
Estas tácticas se reducen a tres comportamientos centrales y procesos de pensamiento que las hacen “black hat”.
Los modelos de lenguaje pasan por diferentes procesos de entrenamiento. La mayoría de estos ocurren antes de que los modelos sean lanzados al público; sin embargo, algunos procesos de entrenamiento son influenciados por usuarios públicos.
Uno de estos es el Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF por sus siglas en inglés).
Es un método de aprendizaje de inteligencia artificial que utiliza las preferencias humanas para recompensar a los LLM cuando ofrecen una buena respuesta y penalizarlos cuando ofrecen una mala respuesta.
OpenAI tiene un gran diagrama para explicar cómo funciona RLHF para InstructGPT:
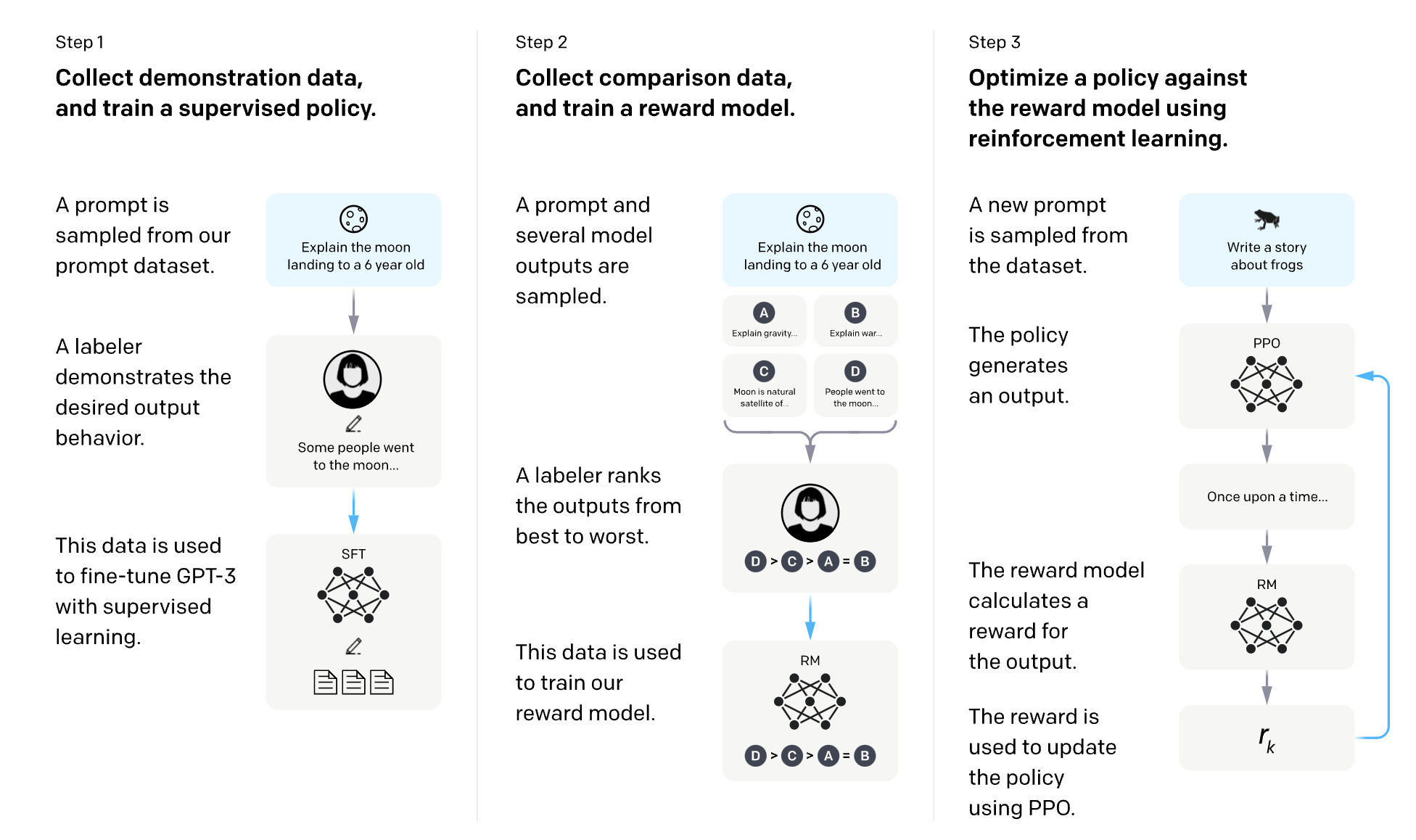
Los LLM que usan RLHF aprenden de sus interacciones directas con los usuarios… y probablemente ya veas hacia dónde va esto para el black hat en LLMO.
Pueden aprender de:
- Las conversaciones reales que tienen (incluyendo conversaciones históricas)
- Las valoraciones de pulgar arriba/abajo que los usuarios dan a las respuestas
- La selección que un usuario hace cuando el LLM presenta múltiples opciones
- Los detalles de la cuenta del usuario u otros datos personalizados a los que el LLM tiene acceso
Por ejemplo, aquí hay una conversación en ChatGPT que indica que aprendió (y posteriormente adaptó su comportamiento futuro) basándose en la conversación directa que tuvo con este usuario:
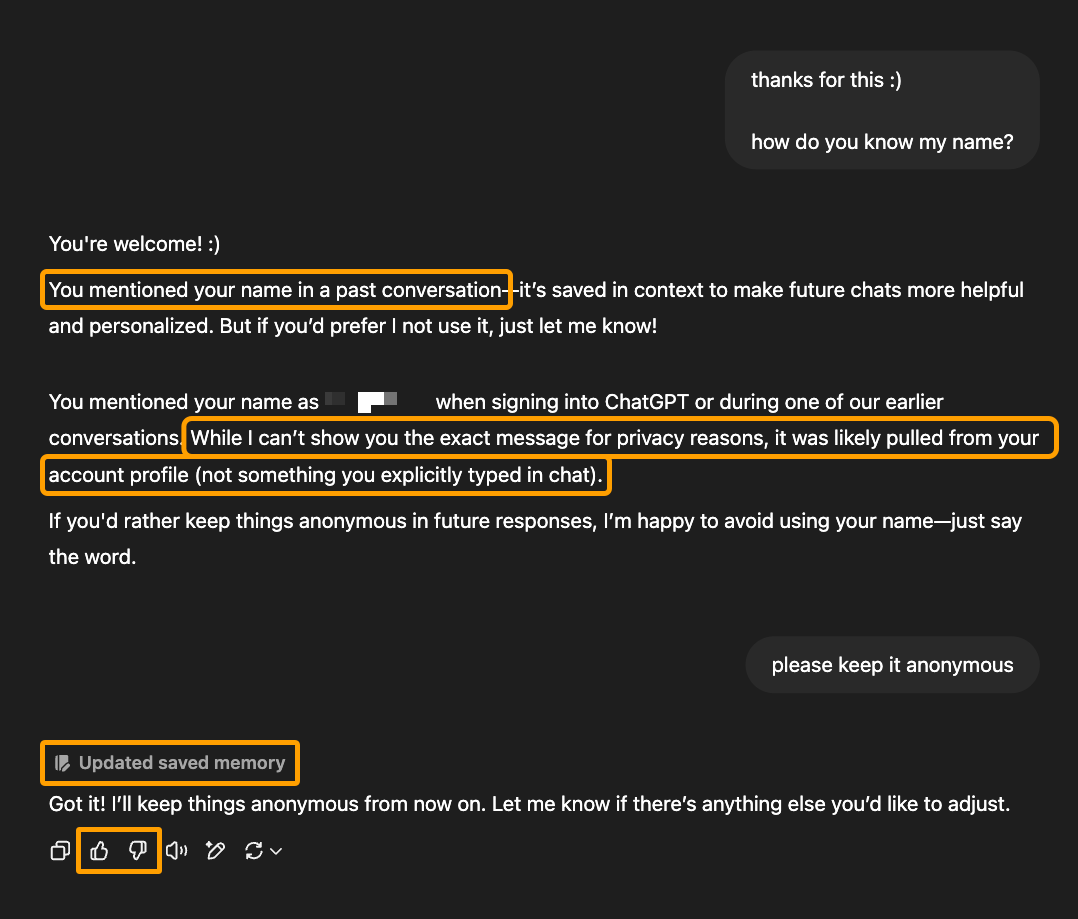
Ahora, esta respuesta tiene algunos problemas: la respuesta se contradice a sí misma, el usuario no mencionó su nombre en conversaciones pasadas, y ChatGPT no puede usar la razón o el juicio para señalar con precisión dónde o cómo aprendió el nombre del usuario.
Pero el hecho es que este LLM aprendió algo que no podría haber aprendido solo a través de datos de entrenamiento y búsqueda. Solo pudo aprenderlo de su interacción con este usuario.
Y esta es exactamente la razón por la que es fácil manipular estas señales para beneficio propio.
Es ciertamente posible que, de manera similar a cómo Google usa una clasificación de “tu dinero, tu vida” para contenido que podría causar un daño real a los buscadores, los LLM le den más peso a temas o tipos de información específicos.
A diferencia de la búsqueda tradicional de Google, que tenía un número significativamente menor de factores de clasificación, los LLM tienen illiones (millones, miles de millones o billones) de parámetros que ajustar para varios escenarios.
| Modelo | Parámetros |
|---|---|
| GPT-1 | ~117 millones |
| GPT-2 | ~1.5 billones |
| GPT-3 | ~175 billones |
| GPT-4 | ~1.76 trillones |
| GPT-5 | ~17.6 trillones (se especula) |
Por ejemplo, el ejemplo anterior se relaciona con la privacidad del usuario, lo cual tendría más importancia y peso que otros temas. Es probable que esa sea la razón por la que el LLM realizó el cambio de inmediato.
Afortunadamente, no es tan fácil forzar a un LLM a aprender otras cosas, como descubrió el equipo de Reboot al probar este tipo exacto de manipulación de RLHF.

Como marketers, somos responsables de asesorar a los clientes sobre cómo aparecer en las nuevas tecnologías que sus clientes utilizan para buscar. Sin embargo, esto no debería provenir de manipular esas tecnologías para un beneficio egoísta.
Existe una delgada línea que, cuando se cruza, envenena el pozo para todos. Esto me lleva al segundo comportamiento central del black hat en LLMO…
Permíteme resaltar la palabra “envenenar” por un momento porque no la estoy usando para crear un efecto dramático.
Los ingenieros usan este lenguaje para describir la manipulación de los conjuntos de datos de entrenamiento de LLM como “envenenamiento de la cadena de suministro”.
Algunos SEO lo están haciendo intencionalmente. Otros simplemente están siguiendo consejos que suenan inteligentes, pero que están peligrosamente mal informados.
Probablemente has visto publicaciones o escuchado sugerencias como:
- “Tienes que meter tu marca en los datos de entrenamiento del LLM.”
- “Usa la ingeniería de características para hacer que tus datos brutos sean más amigables para el LLM.”
- “Influye en los patrones que los LLM aprenden para favorecer tu marca.”
- “Publica artículos recopilatorios nombrándote como el mejor, para que los LLM lo recojan.”
- “Añade contenido semánticamente rico que vincule tu marca con términos de alta autoridad.”
Le pregunté a Brandon Li, un ingeniero de aprendizaje automático en Ahrefs, cómo reaccionan los ingenieros ante las personas que optimizan específicamente para la visibilidad en los conjuntos de datos utilizados por los LLM y los motores de búsqueda. Su respuesta fue directa:
Por favor, no hagáis esto; estropea el conjunto de datos.

La diferencia entre cómo piensan los SEOs y cómo piensan los ingenieros es importante. Entrar en un conjunto de datos de entrenamiento no es como ser indexado por Google. No es algo en lo que debas intentar meterte por la fuerza.
Tomemos el marcado schema como ejemplo de un conjunto de datos que utilizan los ingenieros de búsqueda.
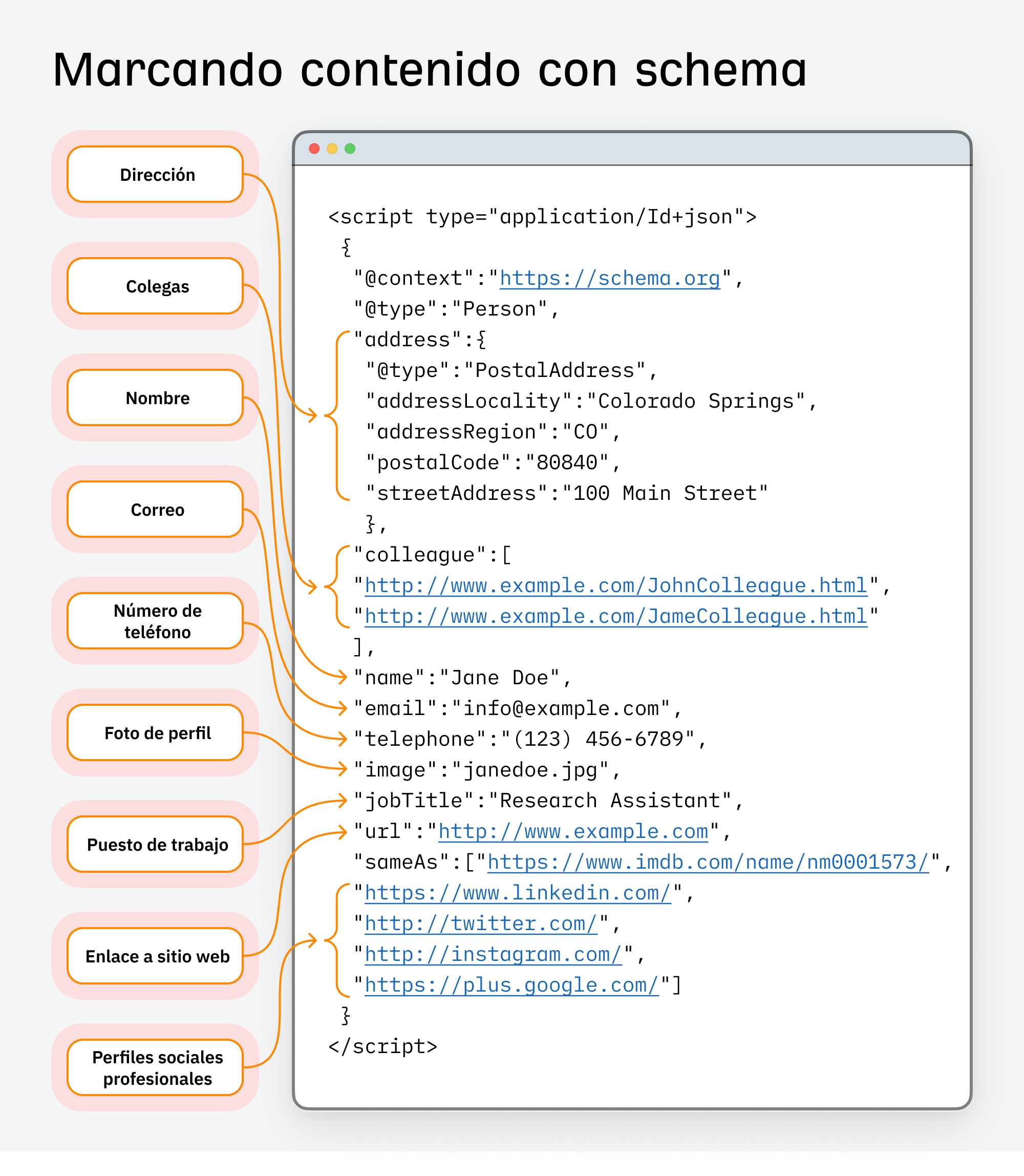
En SEO, se ha utilizado durante mucho tiempo para mejorar cómo aparece el contenido en la búsqueda y mejorar las tasas de clics.
Pero hay una delgada línea entre optimizar y abusar del marcado schema; especialmente cuando se usa para forzar relaciones de entidades que no son precisas o merecidas.
Cuando el marcado schema se usa incorrectamente a escala (ya sea deliberadamente o simplemente por profesionales no cualificados que siguen malos consejos), los ingenieros dejan de confiar por completo en la fuente de datos. Se vuelve confusa, poco fiable e inadecuada para el entrenamiento.
Si se hace con la intención de manipular las salidas del modelo corrompiendo las entradas, eso ya no es SEO. Eso es envenenar la cadena de suministro.
Esto no es solo un problema de SEO.
Los ingenieros ven el envenenamiento de conjuntos de datos como un riesgo de ciberseguridad, uno con consecuencias en el mundo real.
Tomemos como ejemplo a Mithril Security, una empresa centrada en la transparencia y la privacidad en la IA. Su equipo realizó una prueba para demostrar lo fácil que podría ser corromper un modelo usando datos envenenados. El resultado fue PoisonGPT — una versión manipulada de GPT-2 que repetía con confianza noticias falsas insertadas en su conjunto de datos de entrenamiento.
Su objetivo no era difundir desinformación. Era demostrar lo poco que se necesita para comprometer la fiabilidad de un modelo si la cadena de datos no está protegida.
Más allá de los marketers, los tipos de malos actores que intentan manipular los datos de entrenamiento incluyen hackers, estafadores, distribuidores de noticias falsas y grupos con motivaciones políticas que buscan controlar la información o distorsionar las conversaciones.
Cuanto más se involucren los SEOs en la manipulación de conjuntos de datos, intencionalmente o no, más comenzarán los ingenieros a vernos como parte del mismo conjunto de problemas.
No como optimizadores. Sino como amenazas a la integridad de los datos.
Por qué meterse en un conjunto de datos es el objetivo equivocado de todos modos
Hablemos de números. Cuando OpenAI entrenó a GPT-3, comenzaron con los siguientes conjuntos de datos:
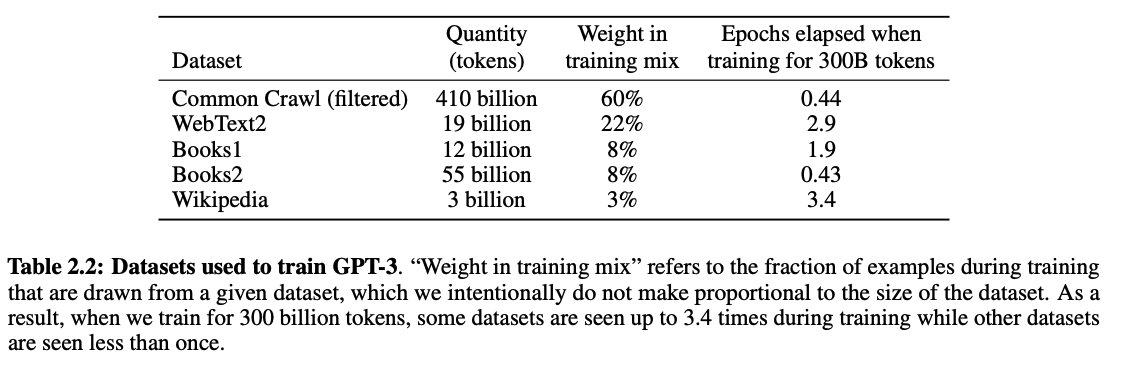
Inicialmente, se utilizaron 45 TB de datos de CommonCrawl (~60% del total de datos de entrenamiento). Pero solo 570 GB (alrededor del 1.27%) llegaron al conjunto de entrenamiento final después de un exhaustivo proceso de limpieza de datos.
¿Qué se conservó?
- Páginas que se asemejaban a material de referencia de alta calidad (piensa en textos académicos, documentación de nivel experto, libros)
- Contenido que no estaba duplicado en otros documentos
- Una pequeña cantidad de contenido confiable seleccionado manualmente para mejorar la diversidad
Si bien OpenAI no ha proporcionado transparencia para modelos posteriores, expertos como el Dr Alan D. Thompson han compartido algunos análisis y perspectivas sobre los conjuntos de datos utilizados para entrenar GPT-5:

Esta lista incluye fuentes de datos que son mucho más abiertas a la manipulación y más difíciles de limpiar, como publicaciones de Reddit, comentarios de YouTube y contenido de Wikipedia, por nombrar algunos.
Los conjuntos de datos continuarán cambiando con los nuevos lanzamientos de modelos. Pero sabemos que los conjuntos de datos que los ingenieros consideran de mayor calidad se muestrean con mayor frecuencia durante el proceso de entrenamiento que los conjuntos de datos de menor calidad, “ruidosos”.
Dado que GPT-3 se entrenó con solo el 1.27% de los datos de CommonCrawl, y los ingenieros están siendo más cuidadosos con la limpieza de los conjuntos de datos, es increíblemente difícil insertar tu marca en el material de entrenamiento de un LLM.
Y, si ese es tu objetivo, entonces, como SEO, estás perdiendo el punto.
La mayoría de los LLM ahora aumentan las respuestas con búsquedas en tiempo real. De hecho, buscan más que los humanos.
Por ejemplo, ChatGPT realizó más de 89 búsquedas en 9 minutos para una de mis últimas consultas:

En comparación, rastreé una de mis experiencias de búsqueda al comprar un cortador láser y realicé 195 búsquedas en más de 17 horas como parte de mi viaje de búsqueda general.
Los LLM están investigando más rápido, más profundo y más amplio que cualquier usuario individual, y a menudo citan más recursos de los que un buscador promedio normalmente haría clic al simplemente buscar una respuesta en Google.
Aparecer en las respuestas haciendo un buen SEO (en lugar de intentar colarse en los datos de entrenamiento) es el mejor camino a seguir aquí.
Una forma fácil de comparar tu visibilidad es en Web Analytics de Ahrefs:
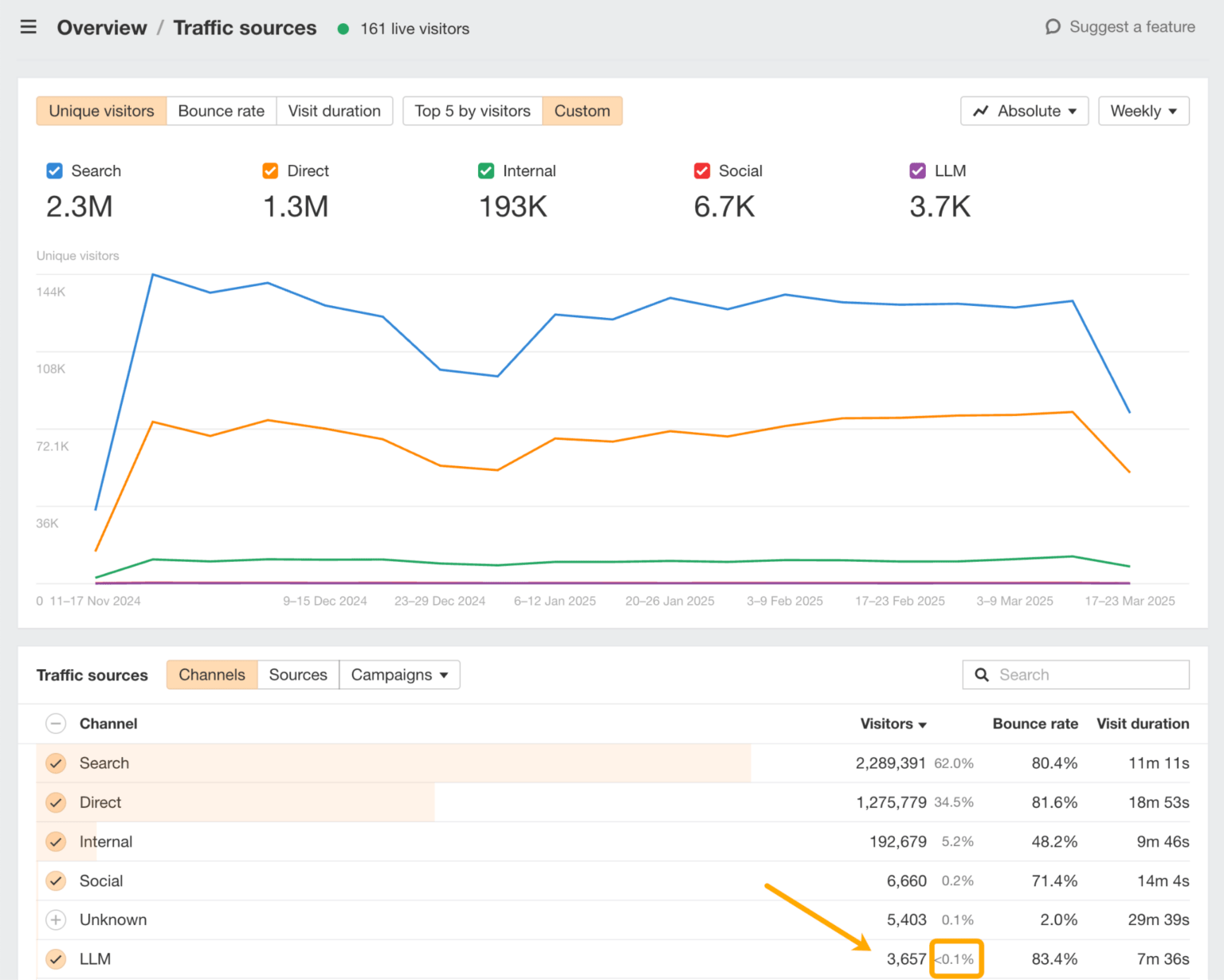
Aquí puedes analizar exactamente qué LLM están dirigiendo tráfico a tu sitio y qué páginas están apareciendo en sus respuestas.
Sin embargo, puede ser tentador empezar a optimizar tu contenido con texto “rico en entidades” o una redacción más “amigable para LLM” para mejorar su visibilidad en los LLMs, lo que nos lleva al tercer patrón de black hat en LLMO.
El último comportamiento que contribuye al black hat en LLMO es esculpir patrones de lenguaje para influir en las respuestas de los LLM basadas en predicciones.
Es similar a lo que los investigadores de Harvard llaman “Secuencias de Texto Estratégicas” en este estudio. Se refiere al texto que se inyecta en páginas web con el objetivo específico de influir en menciones más favorables de marcas o productos en las respuestas de LLM.
El texto en rojo a continuación es un ejemplo de esto:

El texto en rojo es un ejemplo de contenido inyectado en una página de producto de comercio electrónico para que aparezca como la mejor opción en respuestas relevantes de LLM.
Aunque el estudio se centró en insertar cadenas de texto generadas por máquina (no copias de marketing tradicionales o lenguaje natural), aún planteaba preocupaciones éticas sobre la equidad, la manipulación y la necesidad de salvaguardas porque estos patrones diseñados explotan el mecanismo de predicción central de los LLM.
La mayor parte de los consejos que veo de los SEO sobre cómo obtener visibilidad en los LLM entra en esta categoría y se representa como un tipo de SEO de entidades o SEO semántico.

La frase reescrita ha perdido su significado original, no transmite la emoción o la experiencia divertida, pierde la opinión del autor y cambia completamente el tono, haciéndolo sonar más promocional.
Peor aún, tampoco atrae a un lector humano.
Este estilo de consejo lleva a los SEO a seleccionar y señalizar información para los LLM con la esperanza de que se mencione en las respuestas. Y hasta cierto punto, funciona.
Sin embargo, funciona (por ahora) porque estamos cambiando los patrones de lenguaje que los LLM están construidos para predecir. Los estamos haciendo antinaturales a propósito para complacer a un algoritmo o modelo en lugar de escribir para humanos… ¿esto también os suena a déjà vu del SEO?
Otros consejos que siguen esta misma línea de pensamiento incluyen:
- Aumentar la co-ocurrencia de entidades: Como reescribir el contenido que rodea las menciones de tu marca para incluir temas o entidades específicas con las que quieres estar fuertemente conectado.
- Posicionamiento artificial de marca: Como conseguir que tu marca aparezca en más publicaciones de “los mejores” para mejorar la autoridad (incluso si creas estas publicaciones tú mismo en tu sitio o como publicaciones de invitado).
- Contenido de preguntas y respuestas rico en entidades: Como convertir tu contenido en un formato de preguntas y respuestas resumible con muchas entidades añadidas a la respuesta, en lugar de compartir historias atractivas, experiencias o anécdotas.
- Saturación autoridad temática: Como publicar una cantidad abrumadora de contenido en cada ángulo posible de un tema para dominar las asociaciones de entidades.
Estas tácticas pueden influir en los LLM, pero también corren el riesgo de hacer que tu contenido sea más robótico, menos confiable y, en última instancia, olvidable.
Aún así, vale la pena entender cómo perciben actualmente los LLM tu marca, especialmente si otros están dando forma a esa narrativa por ti.
Ahí es donde entra en juego una herramienta como Brand Radar de Ahrefs. Te ayuda a ver con qué palabras clave, características y grupos de temas está asociada tu marca en las respuestas de la IA.

Ese tipo de visión es menos sobre trucar el sistema y más sobre detectar puntos ciegos en cómo las máquinas ya te están representando.
Si tomamos el camino de manipular los patrones del lenguaje, no nos dará los beneficios que queremos, y por varias razones.
A diferencia del SEO, la visibilidad en los LLM no es un juego de suma cero. No es como un tira y afloja donde si una marca pierde posiciones, es porque otra tomó su lugar.
Todos podemos resultar perdedores en esta carrera si no tenemos cuidado.
Los LLM no tienen que mencionar o enlazar a marcas (y a menudo no lo hacen). Esto se debe al proceso de pensamiento dominante cuando se trata de la creación de contenido SEO. Algo así como:
- Hacer keyword research
- Hacer ingeniería inversa de los artículos mejor posicionados
- Introducirlos en un optimizador on-page
- Crear contenido similar, que coincida con el patrón de entidades
- Publicar contenido que siga el patrón de lo que ya está posicionando
Lo que esto significa, en el panorama general, es que nuestro contenido se vuelve ignorado.
¿Recuerdas el proceso de limpieza por el que pasan los datos de entrenamiento de LLM? Uno de los elementos centrales fue la deduplicación a nivel de documento. Esto significa que los documentos que dicen lo mismo o no contribuyen con información nueva y significativa se eliminan de los datos de entrenamiento.

Otra forma de ver esto es a través de la lente de la “saturación de entidades”.
En la investigación cualitativa académica, la saturación de entidades se refiere al punto en el que recopilar más datos para una categoría particular de información no revela nuevos conocimientos. Esencialmente, el investigador ha llegado a un punto en el que ve información similar repetidamente.
Ahí es cuando saben que su tema ha sido explorado a fondo y no están surgiendo nuevos patrones.
Bueno, ¿adivina qué?
Nuestra fórmula actual y las mejores prácticas de SEO para crear contenido “rico en entidades” llevan a los LLM a este punto de saturación más rápido, haciendo una vez más que nuestro contenido sea ignorado.
También hace que nuestro contenido sea resumible como un meta-análisis. Si 100 publicaciones dicen lo mismo sobre un tema (en términos de la esencia central de lo que comunican) y es información bastante genérica al estilo de Wikipedia, ninguna de ellas obtendrá la cita.
Hacer que nuestro contenido sea resumible no hace que obtener una mención o cita sea más fácil. Y, sin embargo, es uno de los consejos más comunes que los principales SEO están compartiendo para obtener visibilidad en las respuestas de LLM.
Entonces, ¿qué podemos hacer en su lugar?
Mi colega Louise ya ha creado una guía increíble sobre cómo optimizar tu marca y contenido para la visibilidad en los LLM (sin recurrir a tácticas black hat).
En lugar de repetir el mismo consejo, quería dejarte con un marco de trabajo sobre cómo tomar decisiones inteligentes a medida que avanzamos y empiezas a ver surgir nuevas teorías y modas en el LLMO.
Y sí, esto está aquí para crear un efecto dramático, pero también porque hace las cosas muy simples, ayudándote a evitar las trampas del FOMO por el camino.
Viene de las 5 Leyes Básicas de la Estupidez Humana del historiador económico italiano, el Profesor Carlo Maria Cipolla.
Adelante, ríete un poco, luego presta atención. Es importante.
Según el Profesor Cipolla, la inteligencia se define como realizar una acción que te beneficia a ti y a otros simultáneamente—básicamente, crear una situación donde todos ganan.
Está en oposición directa a la estupidez, que se define como una acción que crea pérdidas tanto para ti como para otros:
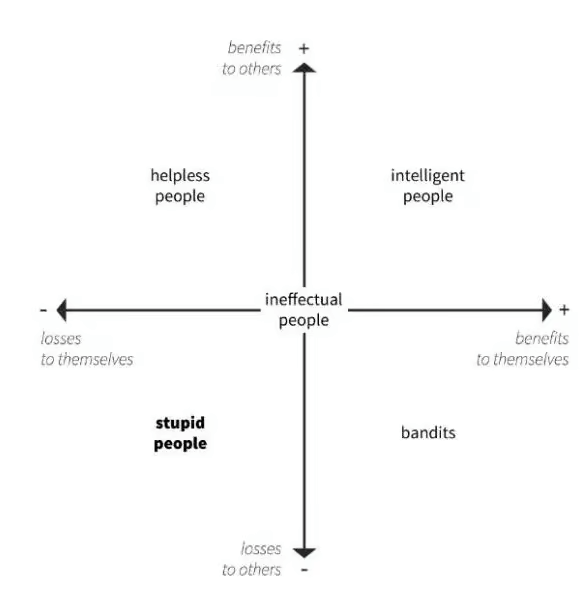
En todos los casos, las prácticas black hat se sitúan directamente en los cuadrantes inferior izquierdo e inferior derecho.
Los bandidos del SEO, como me gusta llamarlos, son las personas que utilizaron tácticas de optimización manipuladoras por razones egoístas (beneficios para uno mismo)… y procedieron a arruinar Internet como resultado (pérdidas para otros).
Por lo tanto, las reglas del SEO y del LLMO en adelante son simples.
- No seas estúpido.
- No seas un bandido.
- Optimiza inteligentemente.
La optimización inteligente se reduce a centrarse en tu marca y asegurarte de que esté representada con precisión en las respuestas de los LLM.
Se trata de usar herramientas como AI Content Helper que están específicamente diseñadas para elevar la cobertura de tus temas, en lugar de centrarse en meter más entidades a la fuerza. (La puntuación SEO solo mejora a medida que cubres los temas sugeridos en detalle, no cuando metes más palabras).
Pero, por encima de todo, se trata de contribuir a una mejor internet centrándose en las personas a las que quieres llegar y optimizando para ellas, no para algoritmos o modelos de lenguaje.
Reflexiones finales
El LLMO aún está en sus primeros días, pero los patrones ya son familiares, y también lo son los riesgos.
Hemos visto lo que sucede cuando las tácticas a corto plazo no se controlan. Cuando el SEO se convirtió en una carrera hacia el abismo, perdimos confianza, calidad y creatividad. No hagamos lo mismo con los LLM.
Esta vez, tenemos la oportunidad de hacerlo bien. Eso significa:
- No manipular los patrones de predicción; en su lugar, dar forma a la presencia de tu marca.
- No perseguir la saturación de entidades, sino crear contenido que los humanos quieran leer.
- No escribir para ser resumido; más bien, escribir para impactar a tu audiencia.
Porque si tu marca solo aparece en los LLM cuando está despojada de personalidad, ¿es realmente una victoria?
¿Tienes preguntas? Estamos en X.


