To do this, we have:
- collected a lot of great keyword and traffic data;
- released many awesome features for keyword research and competitor search traffic analysis.
And now, we’re super happy and excited to see the SEO community favoring our keyword research tools over the alternatives.
Ahrefs 💪 pic.twitter.com/WxeDy3KKj8
— Tim Soulo (@timsoulo) April 13, 2018
But we haven’t forgotten about the area that helped Ahrefs gain trust amongst SEOs in the early days.
That is - crawling the entire web and building the best and the most up-to-date backlink index.
And today, I’m super excited to announce a few of the most recent updates to our backlink data.
1. See search traffic for referring pages
This was our second most popular feature request for Site Explorer in Canny.
In all honesty, this functionality has been in the pipeline for a while.
- we have a huge database of backlinks;
- and we have a huge database of pages with their monthly search traffic.
So why not merge these two data sets and start showing how much traffic each of the linking pages gets, and how many keywords for which each page ranks?
And, DONE!
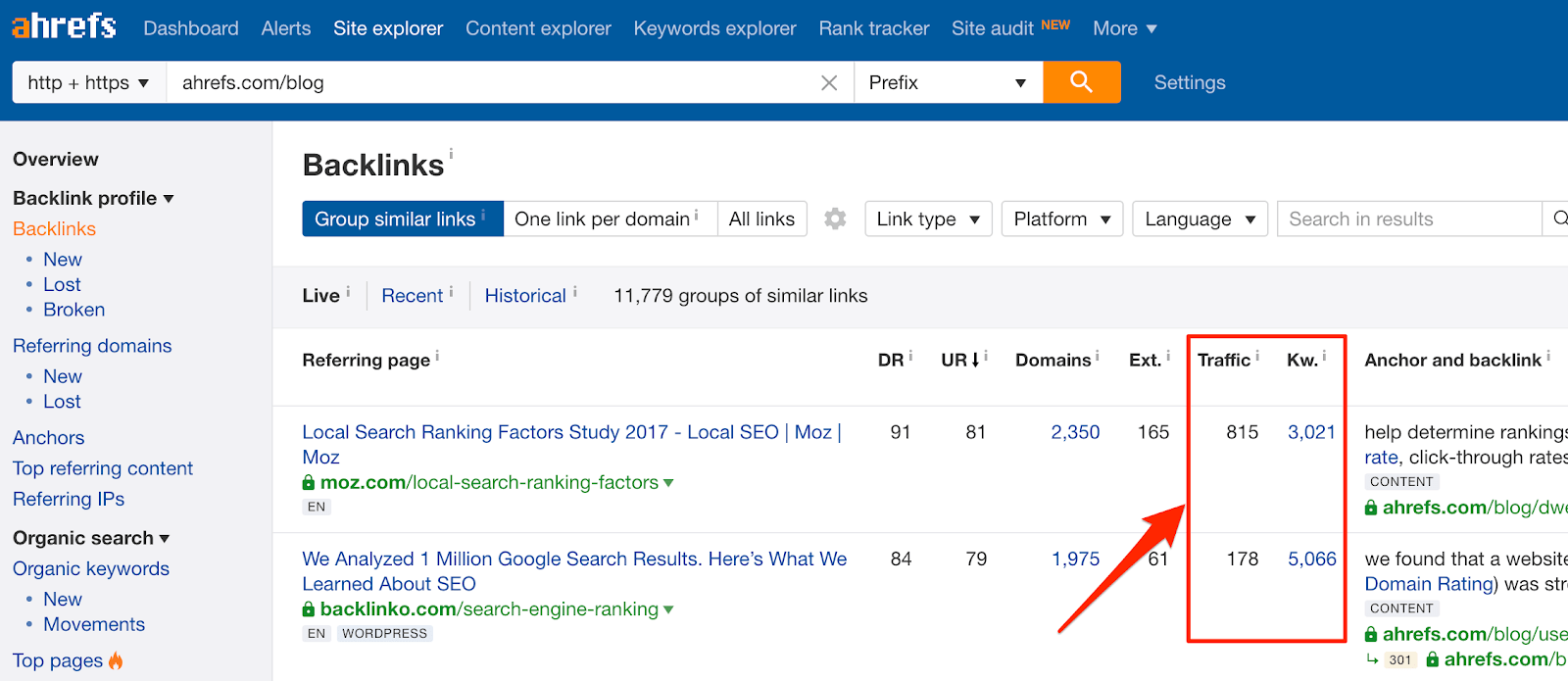
This is something professional SEOs have been doing manually for a while.
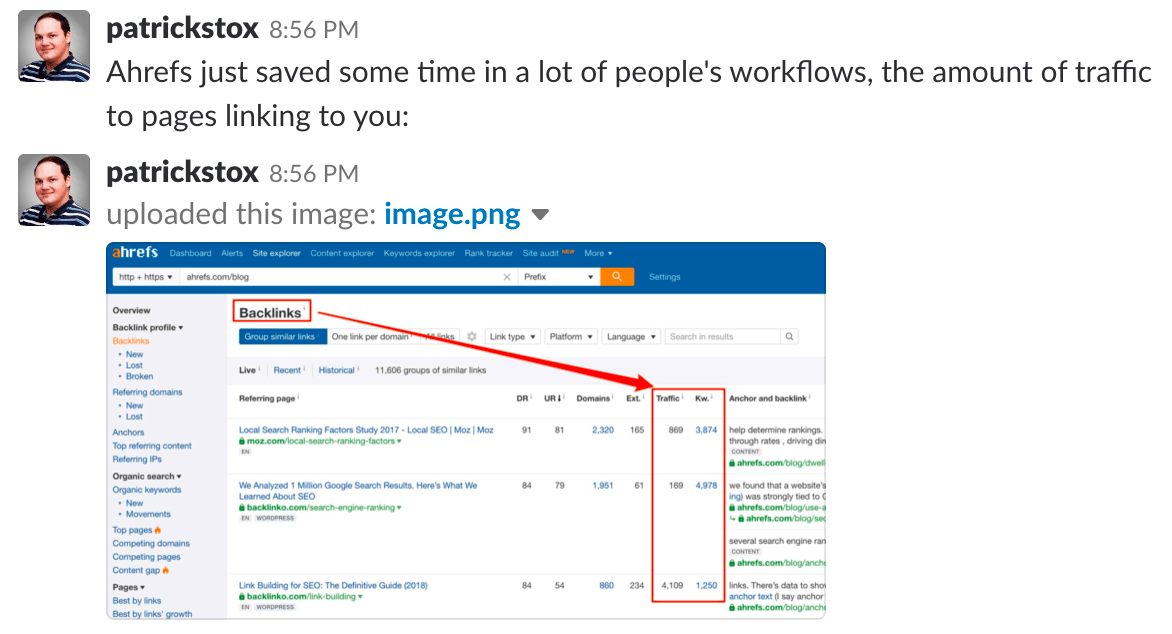
Now, there’s no need for presumably messy VLOOKUPs, as this functionality resides in Site Explorer.
I’m also super proud to report that (as of today) we’re the only SEO tool that has managed to merge these two data points.
But why is this such a significant update?
Rumor has it that Google may be using referral traffic from backlinks to measure their “weight” and influence on rankings.
In fact, we’ve already seen steps in this direction with their infamous “reasonable surfer” and “determining a quality measure for a resource” patents. Both of which Google filed more than six years ago.
Bill Slawski touched upon this in one of his posts:
Another way to change how much PageRank might be passed along with a link might be based upon the amount of traffic a resource might receive from links, and the dwell times of traffic from those links, whether they might be short clicks, medium clicks, or long clicks.

Oh, and here’s what Google’s John Mueller said about the “popularity” of referring pages back in 2013 (h/t Marie Haynes):
John M:“If it’s something that nobody ever goes to anymore then it might be that those links are not as valuable.” https://t.co/NIhd2szpGM
— Marie Haynes (@Marie_Haynes) August 22, 2017
So, I’m hoping you’re as excited as we are about our first steps in this direction. 🙂
But let me address a few more potential concerns about this new data:
Q1: Is that the total traffic of the referring page, or only organic search traffic?
A1: That is organic search traffic of a referral page only. As of today, Ahrefs doesn’t estimate the total traffic to websites or pages.
Q2: Can I sort the “Backlinks” by Traffic & Keywords columns? Can I use filtering?
A2: No. Not right now. But we’re going to release both sorting and filtering asap. In the meantime, this can be done in Excel (or Google Sheets)—just export the data from Ahrefs and into a spreadsheet.
Q3: Can you estimate how much referral traffic each link passes?
A3: No, not at the moment. But we’re already thinking of ways we could do this in the future. (Watch this space!)
2. Backlinks to canonicalized pages are now also “transferred” to the “original” page
In the SEO community, the general consensus is that backlinks to canonicalized pages get treated kind of like 301 redirects to the master copy of the page.
So they pass the “link equity” from the “canonicalized” page to the original.
But unlike with 301 redirects, some of it gets lost in the process.
Let me give you an example.
This article from TheNextWeb is actually a copy of this article from Bufferapp blog. They state this with a “rel=canonical” tag in the source code.

According to Ahrefs, this “copied” article has 758 backlinks from 90 referring domains.
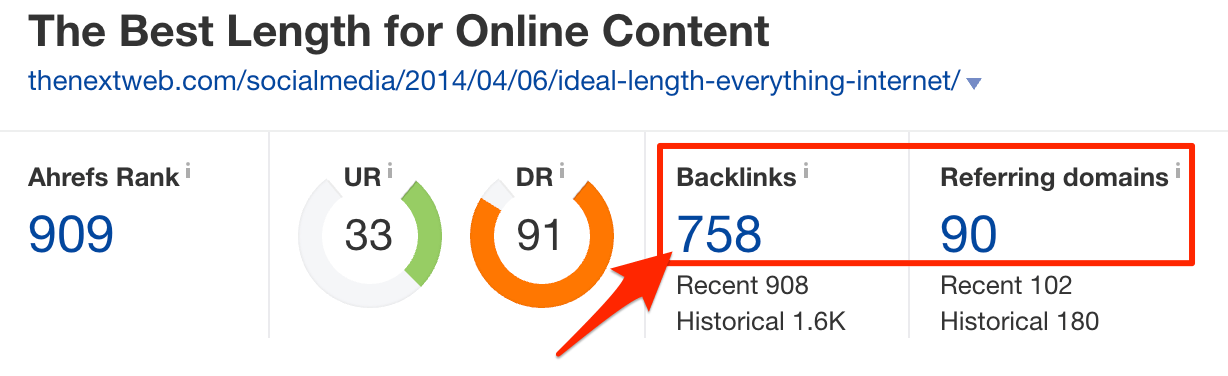
So wouldn’t it make sense to attribute all these backlinks to the original post on Buffer’s blog?
YES.
Well, until today, Ahrefs didn’t “forward” all these “rel=canonical links” from the copy to the original.
But now we do!
If you browse backlinks of this Bufferapp article, you’ll now see the backlinks of its copy at TheNextWeb among them:
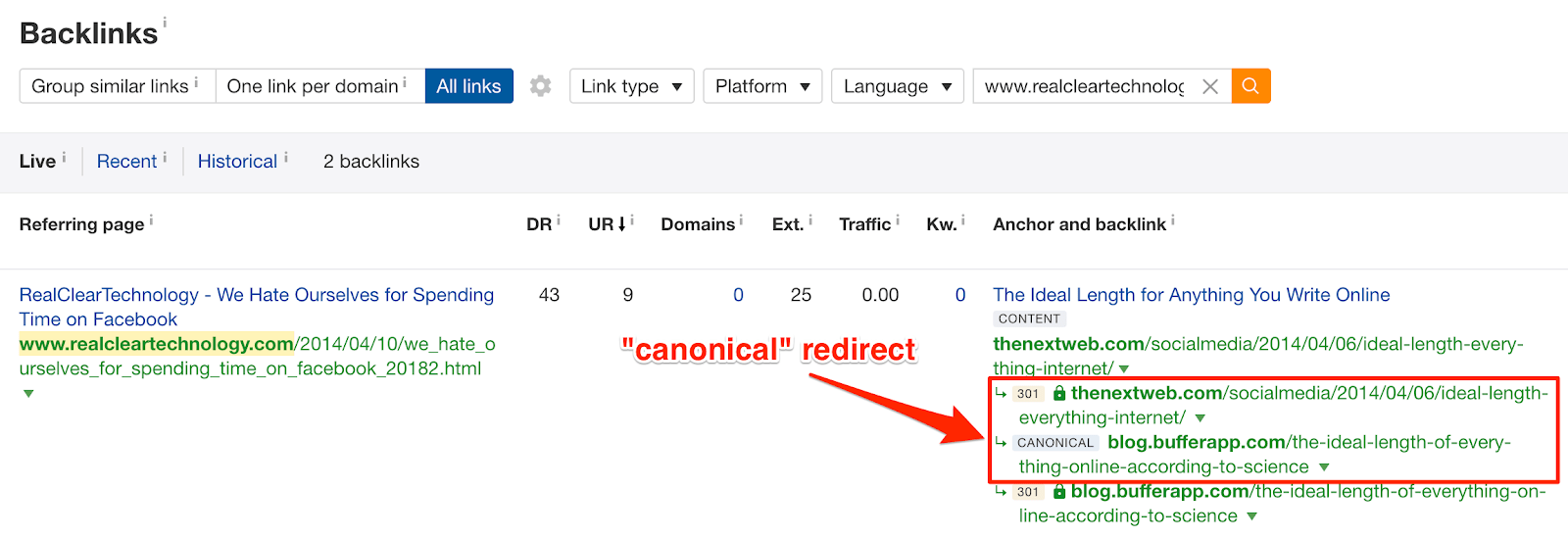
If that seems hard to grasp, try this:
Grab any backlink of TheNextWeb article and try to find it among the backlinks of Bufferapp article. You should see it replicated across both pages.
Let me also illustrate the “before” and “after” of how we calculate “canonical links.”

But that was the example of a so-called “cross-domain” canonicalized page.
The same principle applies to internal pages too.
Example:
The homepage of http://php.net/ for some reason canonicalizes to http://php.net/index.php.

And because we’re now “transferring” all links from a canonicalized copy to the “original” page, here’s what happens to the backlink profile of http://php.net/index.php
Now, let’s tackle any potential concerns and questions, shall we?
Q1: Can I filter rel=canonical links only? Or can I filter them out from a list of backlinks?
A1: Right now we don’t have any filtering options for “canonical links,” but we do have plans to add them.
Q2: Will backlinks still show up for canonicalized pages in Ahrefs?
A2: Yes. We effectively just duplicate the backlinks from the canonicalized page to the original page.
3. Improved crawling speed & efficiency
This last point is not something that has happened to Ahrefs’ backlink index recently. It’s more of a reminder about the ongoing improvements that we’re making.
We’re committed to retaining our hard-earned reputation as the tool with the best and most reliable backlink index.
In fact, our CEO, Dmitry, is personally overseeing most of the backend development to make sure that our users always have access to the best-in-class data.
Just a week ago we reached a new milestone—201 BILLION crawled pages in our index:
Ahrefs has reached 201B pages in Ahrefs’ Live Index today. All-time high! pic.twitter.com/YuDxglAdGy
— Dmitry Gerasimenko (@botsbreeder) April 11, 2018
And in the next few months, we’re going to move our crawling infrastructure to brand new servers with latest generation CPUs.
We’re also testing a new and unique approach to web crawling that should allow us to discover new pages, and re-crawl the “known” ones, even faster.
In other words, we have quite a few exciting updates in development. These should noticeably improve the quality of data that you get from us.
Stay tuned! 🙂


