
And now it does!
Our Site Audit tool is now able to execute the JavaScript on the pages it crawls and see the content the way a website visitor does.
Why is rendering JavaScript important for a crawler?
Lots of websites today have dynamic HTML on their pages generated by JavaScript. This allows webmasters to create good-looking pages with dynamic content.
Crawling the static HTML is a pretty straightforward task. In simplest terms, the web crawler just reads the source code of a page. All the text content and all the links are there.
But a source code of a JavaScript-generated page is pretty different.
I will use this page as an example: The Complete List of Link Building Tactics by Jon Cooper, PointBlankSEO.
Ahrefs Site Explorer says that it has a link to ahrefs.com.
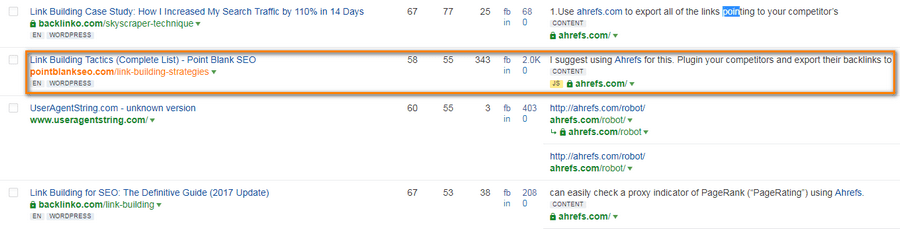
And if you open that page you will see it’s there.
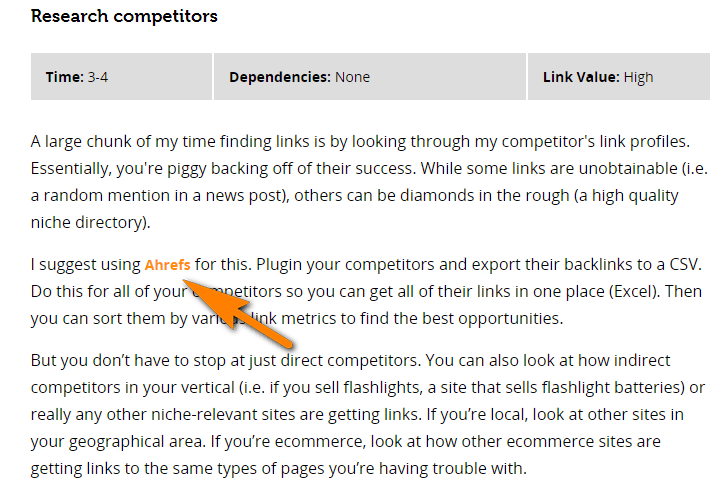
But if you try to find a mention of “ahrefs” in the source code of a page…
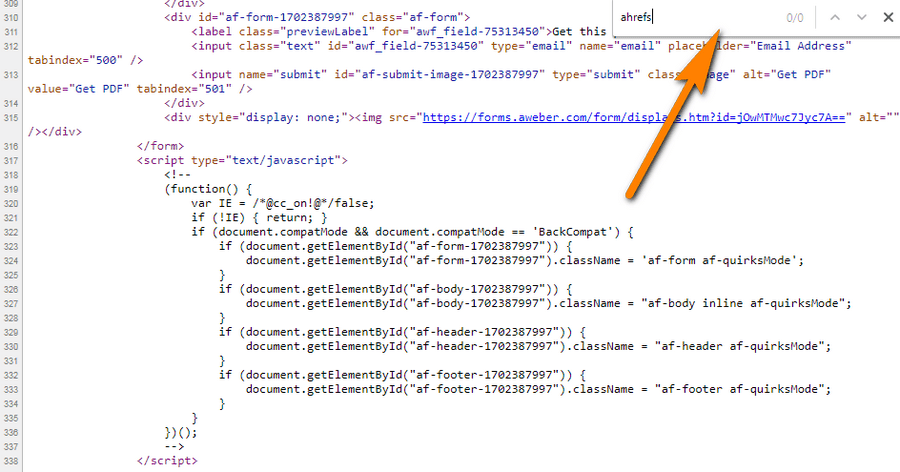
Not a single mention.
This link, as well as most of the content on that page, is generated by JavaScript.
Our Site Explorer was smart enough to report this link because not so long ago it started rendering JS (in a pretty similar way Google does).
Now our Site Audit tool can do that too!
But while Site Explorer does not yet execute JS on every page it comes across, giving preference to more reputable pages, Site Audit tool will render JavaScript-generated content on any page on a website you want to audit.
So today a website built with JS is not a problem for our Site audit tool. It will detect 100+ pre-configured SEO issues on such websites, like it does for static HTML sites.
How does it work?
Generally, our crawler can see the JS-powered website in the same way it is rendered in a visitor’s browser.
Here’s is the oversimplified sequence:
- Document Object Model (DOM) of the page is loaded. DOM is the basis of the dynamically generated page.
- The scripts and resources required to render a page are loaded.
- JavaScript is executed, making changes into DOM and forming the HTML code of a page.
- The Site Audit crawler waits for 3 seconds and takes a snapshot of the HTML code generated.
The most challenging thing about crawling JavaScript pages is that JavaScript must be executed by the crawler itself, the same way it is executed by your web browser.
Ever tried to browse the modern Facebook on an old computer? Slooow, right? This happens because its JavaScript is executed on your device, not on Facebook servers.
That’s the reason why crawling dynamic HTML requires much more resources than crawling the static pages.
But we have these resources here at Ahrefs!
Will Site Audit tool crawl every part of a JavaScript-generated page?
Not quite. In some cases, our crawler will not fetch all the possible data from a dynamically generated page.
- Sometimes scripts can be executed some time after the page loads. So if the code is generated after our crawler takes a snapshot of the HTML, it won’t be crawled.
- There are scroll-triggered and click-triggered scripts. Site Audit crawler won’t simulate scroll-down or click actions that may be used on a page to trigger scripts. Facebook’s infinite scroll where more and more content appears as you scroll down is a good example.
So if the link only shows up in the cases described above, it won’t be found and followed by our crawler.
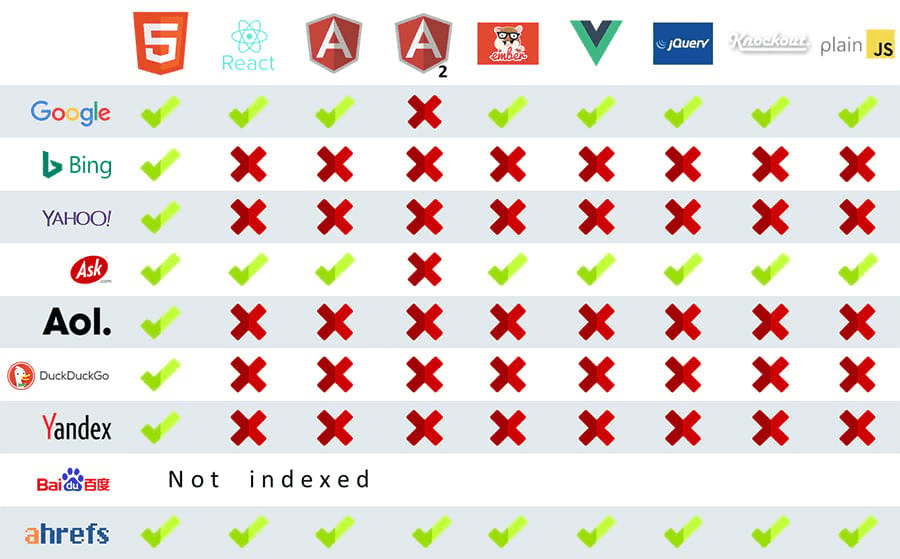
Does it crawl websites built with modern JS frameworks?
Yes. The same way our Site Explorer crawler does.
Will it trigger trackers and ads?
No. Our crawler will not execute tracker codes like Google Analytics or Matomo (formerly Piwik).
The ads will not be triggered as well.
What else should you know to crawl JS-powered websites with Site Audit tool?
First of all, “Execute JavaScript” setting must be turned on in the crawl settings.
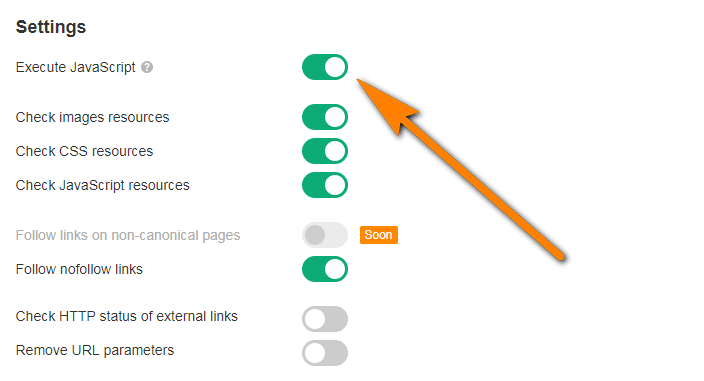
You should also note that crawling JavaScript takes much longer than crawling the static HTML, mostly because of the timeout required to execute JS. However, you can boost the overall crawling speed in Site Audit by increasing the number of parallel requests as you set up a new project for your website.
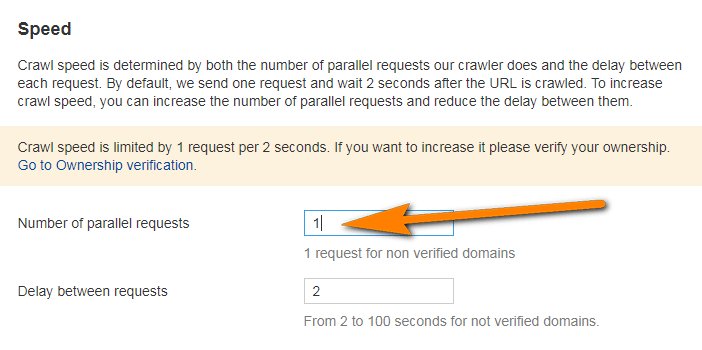
Such crawls might create a higher load on your web server as it requests more resources like JS scripts.
Closing thoughts
From now on, the owners, managers and SEO specialists of JavaScript-powered websites can make full-scale SEO audits with Ahrefs Site Audit tool.
We promise you that this is not the last feature added to our Site Audit tool. It has a very solid roadmap. And if you’d like to contribute, you can suggest more features here.


