![如何进行 SEO 日志文件分析 [内含模板]](https://ahrefs.com/blog/zh/wp-content/uploads/2022/08/blog_log_file_analysis-400x200.png)
它是了解搜索引擎已抓取 URL 最可信的来源,而且可能含有诊断技术 SEO 问题的关键信息。
Google 也意识到了它们的重要性,并在 Google Search Console 中发布了新功能,可以轻松查看过往只能通过分析日志才能获得的数据样本。
此外,Google 的搜索倡导者 John Mueller 曾公开表示日志文件保存了多少好的资讯。
https://twitter.com/JohnMu/status/717455167344521217
由于围绕日志文件中的数据进行讨论,你会希望更好地了解日志、如何分析它们以及正在处理的网站是否会从中受益。
本文会一并回答并讨论更多内容,以下是我们讨论的内容:
服务器日志文件是由服务器创建和更新的文件,用于记录已执行的活动。常见的服务器日志文件是访问日志文件,它保存了对服务器 HTTP 请求的历史记录(用户和机器人)。
当非开发人员提到日志文件时,他们通常提到的是访问日志。
然而,开发人员发现自己花费更多时间查看的是服务器遇到的错误日志。
以上都很重要:如果向开发人员索取日志,他们首先会问的是“你要哪一个?”
因此请针对日志文件请求提出具体说明,如果希望透过日志分析爬取,请索取访问日志。
访问日志的文件包含所有关于向服务器发出请求的大量信息,例如:
- IP 地址
- 用户代理
- 网址路径
- 时间戳(当机器人/浏览器发出请求时)
- 请求类型(GET 或 POST)
- HTTP 状态码
访问日志中包含的服务器会因服务器类型而有所差异,有时开发人员会将服务器配置为存储在日志文件中,日志文件的常见格式包括:
- Apache 格式 – 这由 Nginx 和 Apache 服务器使用。
- W3C 格式 – 这是由 Microsoft IIS 服务器使用的。
- ELB 格式 – 这由 Amazon Elastic Load Balancing 使用。
- 自定义格式 – 许多服务器支持输出自定义日志格式。
也存在其他形式,但这些是你会遇到的主要形式。
现在我们已经对日志文件有了基本了解,让我们来看看它们如何帮助 SEO。
以下是一些关键方法:
- 抓取监控 – 可以看到搜索引擎抓取的 URL,并用它来发现爬虫陷阱,找到抓取预算浪费,或者更好地了解内容更改后的抓取速度。
- 状态码报告 – 这对于需要优先修复错误特别有用,比起知道页面有 404 状态,你可以准确地看到用户/搜索引擎访问 404 URL 的次数。
- 趋势分析 – 通过监控对 URL、页面类型/部分站点或整个站点的爬取,可以发现其变化并调查潜在原因。
- 发现孤岛页面 – 可以交叉分析来自日志文件的数据和你自己运行的站点爬网以发现孤岛页面。
所有站点都在一定程度上受益于日志文件分析,但收益多寡会因站点大小而异。
这是因为日志文件通过更好地管理爬网来使站点受益,谷歌本身表示管理抓取预算的受益者往往是更大规模或经常变化的网站。
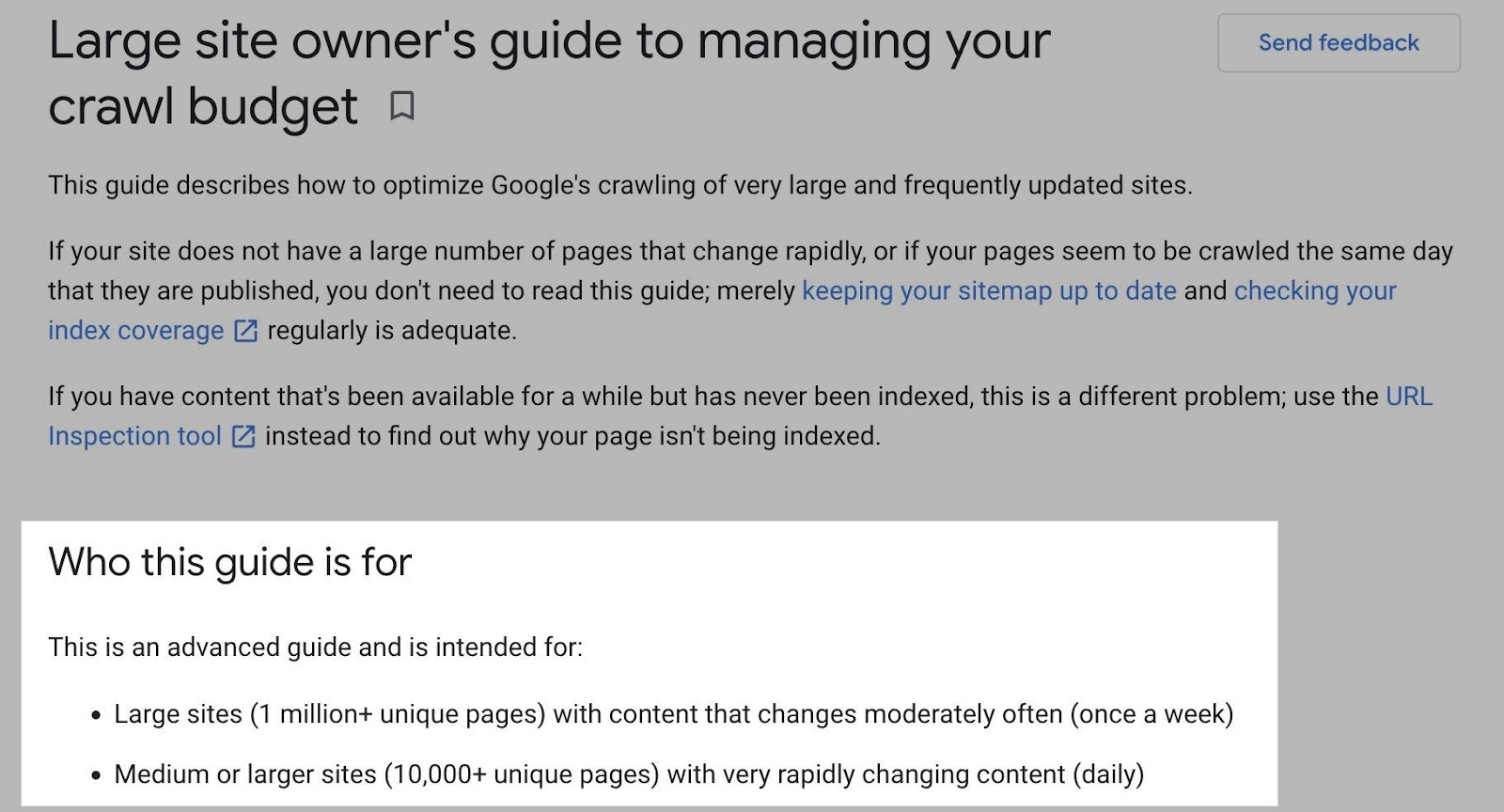
日志文件分析也是如此。
例如,较小的网站可能会使用 Google Search Console 中提供的“抓取统计”数据获得上述所有好处,而无需访问日志文件。
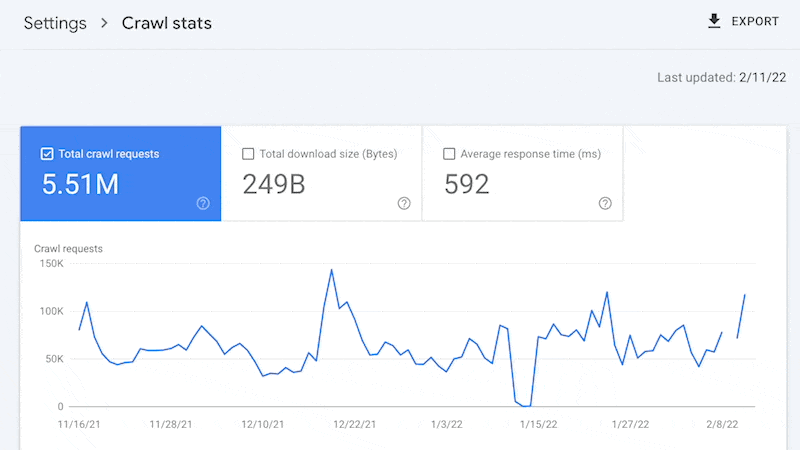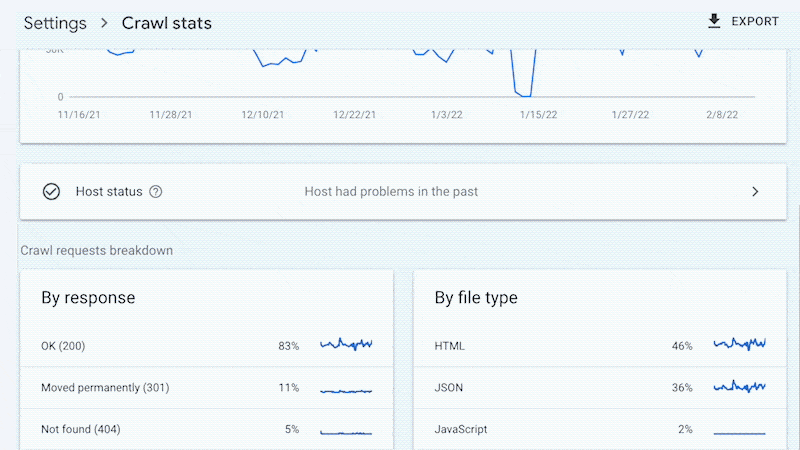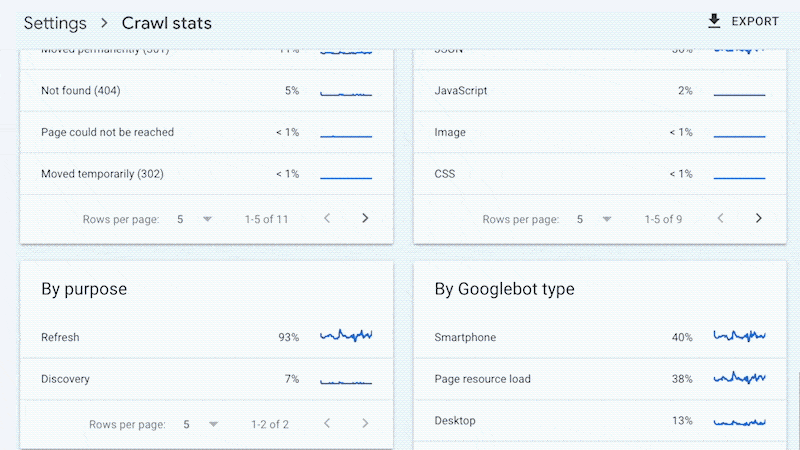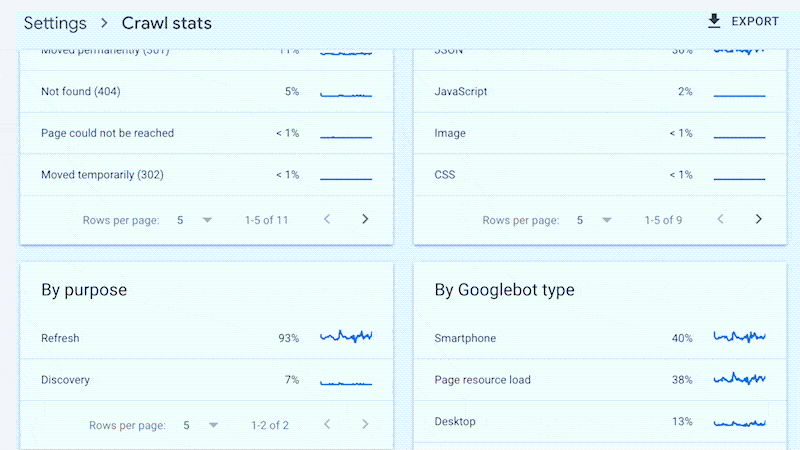
是的,Google 不会提供所有抓取的网址(如日志文件),并且趋势分析也仅限于三个月内的数据。
但是不会经常更改的小站点也需要一些持续的技术 SEO,让网站审核员发现和诊断问题就足够了。
例如来自站点爬虫、XML 站点地图、Google Analytics 和 Google Search Console 的交叉分析可能会发现所有孤立页面。
还可以使用站点审核员从内部链接中发现错误状态码。
会特别指出来是因为有几个关键原因:
- 获取访问日志文件并不容易(接下来会详细介绍)。
- 对于不常更改的小型网站,日志文件的好处并不多,这意味着 SEO 的重点可能会转移到其他地方。
在大多数情况下要分析日志文件,首先必须向开发人员请求访问日志文件。
然后开发人员可能会遇到一些问题,并且会引起你的注意,这些包括:
- 部分数据 – 日志文件可以包含分散在多个服务器上的部分数据,这通常发生在开发人员使用各种服务器的情况,例如源服务器、加载均衡器和 CDN。获得所有日志的充分信息可能意味着需要编译来自所有服务器的访问日志。
- 文件大小 – 高流量站点的访问日志文件大小可能达到 TB,如果不是 PB 的话,会使得它们难以传输。
- 隐私/合规 – 日志文件包括属于个人身份信息 (PII) 的用户 IP 地址。用户信息可能需要先删除,然后才能与你共享。
- 存储历史 – 由于文件大小影响,开发人员可能已将访问日志配置为仅存储数天,这对于发现趋势和问题变的没有用处。
这些问题会让人质疑存储、合并、过滤和传输日志文件是否值得开发人员付出心力,特别是如果开发人员已经有很长的工作优先级列表了(通常是这种情况)。
开发人员可能会将责任放在 SEO 人员身上,来透过解释/建立一个案例说明为什么开发人员应该在这方面投入时间,你需要在其他 SEO 重点中优先考虑这一点。
这些问题正是很少做日志文件分析的原因。
从开发人员那里收到的日志文件也常被通用的日志文件分析工具以不支持的方式格式化,使得分析更加困难。
值得庆幸的是,有一些软件解决方案可以简化该过程,我最喜欢的是 Logflare,这是一个 Cloudflare 应用程序,可以将日志文件存储在你拥有的 BigQuery 数据库中。
现在是时候开始分析你的日志了。
我将具体展示如何在 Logflare 的整体执行操作,但是有关如何使用日志数据的提示适用于任何日志。
我分享的模板也适用于任何日志,只需要确保数据表中的栏位匹配。
1. 首先设置 Logflare(可选)
Logflare 容易设置,通过 BigQuery 集成,它可以长期存储数据,你将拥有完整数据并让每个人都可以轻松访问。
但有一个难处是,需要更换你的域名服务器来使用 Cloudflare 并在那里管理你的 DNS。
对于大多数人来说没有问题,但是如果使用的是更企业级的站点,就不太可能说让服服务器架构团队更改域名服务器以简化日志分析。
我不会详细介绍如何使用 Logflare 的每一步,但要开始使用,需要先前往 Cloudflare 仪表板的应用程序(Apps)。
然后搜索 Logflare。
之后的设置就是不言自明的(创建一个帐户并为项目命名,选择要发送的数据等),我唯一另外推荐的部分是 Logflare 的 BigQuery 设置指南。
但是请记住,BigQuery 的成本取决于你执行的查询和存储的数据量。
2. 验证 Googlebot
我们现在已经存储了日志文件(通过 Logflare 或其他方法),接下来我们需要从想要分析的用户代理中精确地提取日志,对于大多数人来说的话就是 Googlebot。
在我们这样做之前,还有另一个障碍要跨越。
许多机器人透过伪装成 Googlebot 来通过防火墙(如果有的话),此外一些审核工具也会这样做,以准确呈现网站为用户代理返回的内容,如果你的服务器为 Googlebot 返回不同的 HTML(例如你设置了动态呈现),这点就会至关重要。
我没有使用 Logflare
如果没有使用 Logflare,识别 Googlebot 则需要反向 DNS 查找来验证的请求是否来自 Google。
Google 在此处提供了手动验证 Googlebot 的便捷指南。
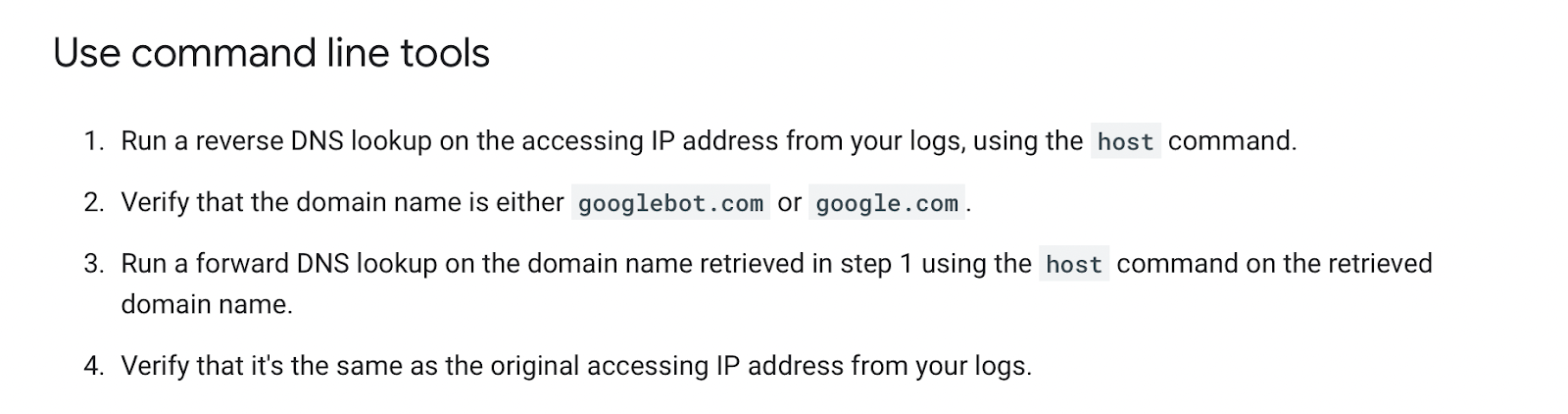
你可以一次性执行此操作,使用反向 IP 查找工具并检查返回的域名。
但是我们需要对日志文件中的每一行批量执行此操作,这还要求匹配 Google 提供列表中的 IP 地址。
最简单的方法是使用由第三方维护的服务器防火墙规则集来阻止假机器人(可能让日志文件中更少出现/甚至没有假的 Googlebot),Nginx 里一个常见的是“Nginx 的终极恶意机器人拦截器.”
或者你会在 Googlebot IP 列表中注意到 IPV4 地址均以“66”开头。
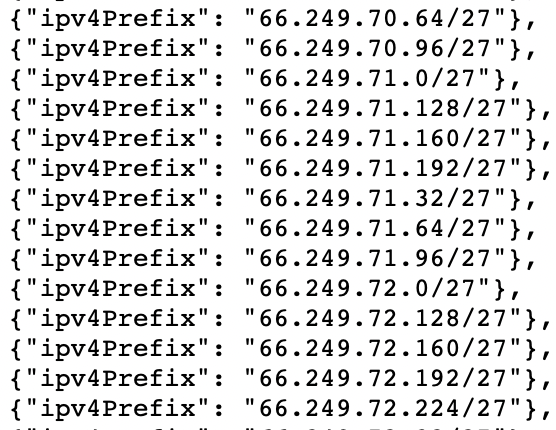
虽然它不会 100% 准确,但在分析日志中的数据时,还可以通过过滤以“6”开头的 IP 地址来检查 Googlebot。
我正在使用 Cloudflare/Logflare
Cloudflare 的专业计划(目前每个月 20 美元)具有内置防火墙功能,可以阻止伪造的 Googlebot 请求访问你的网站。
Cloudflare 默认禁用这些功能,但可以通过前往 Firewall > Managed Rules > 启用 “Cloudflare Specials” > 选择 “Advanced” 来找到他们

接下来,将搜索类型从“Description”更改为“ID”并搜索“100035”。
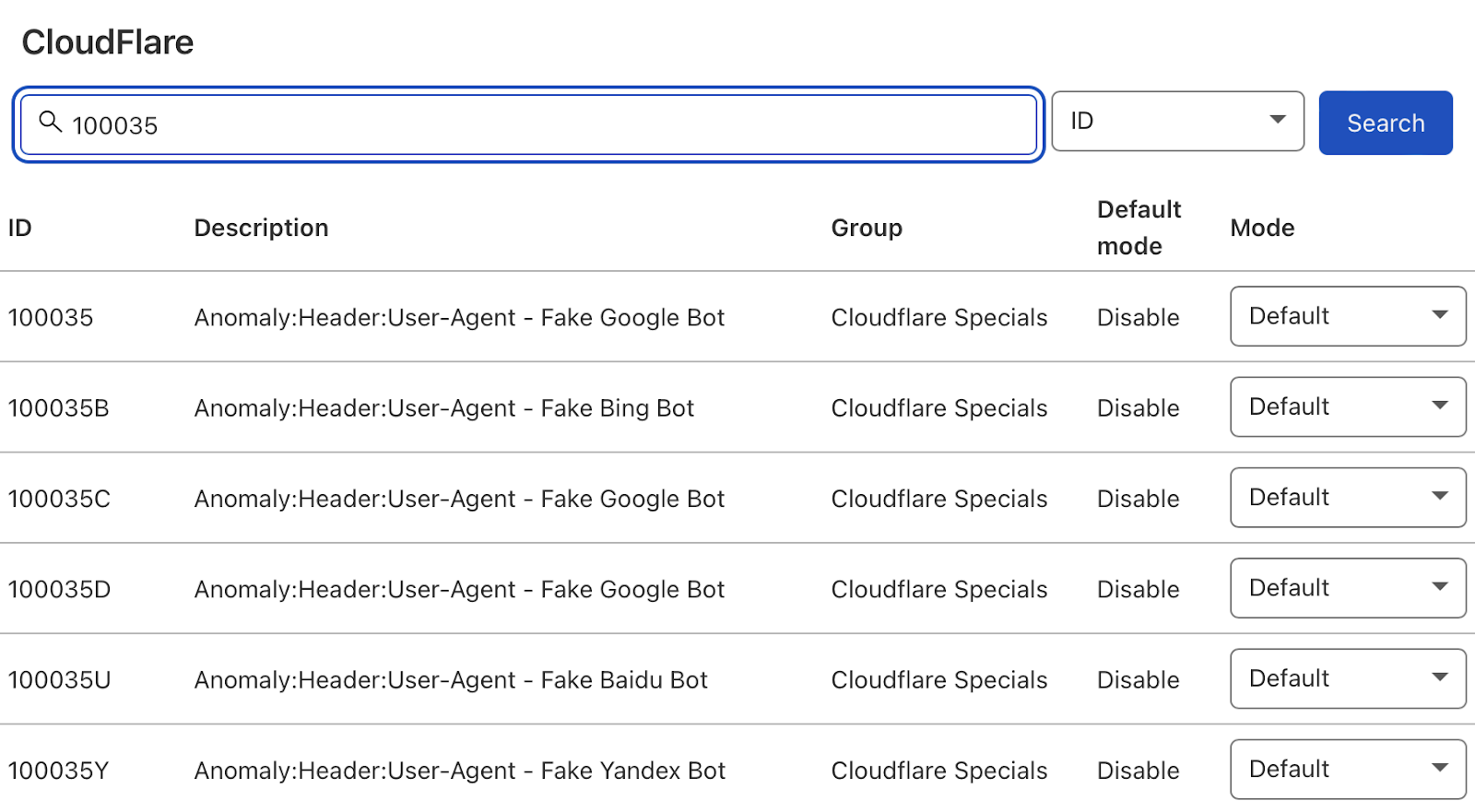
Cloudflare 现在将提供阻止伪造搜索机器人的选项列表,将相关请求设置为“Block”,Cloudflare 将检查来自搜索机器人用户代理的所有请求是否合法,以便保持你的日志文件干净。
3. 从日志文件中提取数据
终于,我们现在可以访问日志文件,并且知道日志文件准确地反映了真正的 Googlebot 请求。
我建议首先在 Google 表格/Excel 中分析日志文件,因为你可能习惯于使用电子表格,并且可以很简单地与其他来源(例如网站抓取)交叉分析日志文件。
没有一种正确的方法可以做到这一点,可以使用以下内容:
你也可以在 Data Studio 的报表中执行此操作,我发现 Data Studio 有助于随着时间的推移监控数据,而 Google Sheets/Excel 更适合一次性的技术审核时分析。
打开 BigQuery 并前往你的项目/数据集。
选择“Query”下拉选单并在新选项卡中打开它。
接下来你需要编写一些 SQL 来提取要分析的数据,为了使过程这更容易,首先需要复制查询 FROM 部分的内容。

然后你在查询时可以添加我在下面为你写的:
SELECT DATE(timestamp) AS Date, req.url AS URL, req_headers.cf_connecting_ip AS IP, req_headers.user_agent AS User_Agent, resp.status_code AS Status_Code, resp.origin_time AS Origin_Time, resp_headers.cf_cache_status AS Cache_Status, resp_headers.content_type AS Content_Type
FROM `[Add Your from address here]`,
UNNEST(metadata) m,
UNNEST(m.request) req,
UNNEST(req.headers) req_headers,
UNNEST(m.response) resp,
UNNEST(resp.headers) resp_headers
WHERE DATE(timestamp) >= "2022-01-03" AND (req_headers.user_agent LIKE '%Googlebot%' OR req_headers.user_agent LIKE '%bingbot%')
ORDER BY timestamp DESC
此查询只针对以 SEO 为目的的日志文件分析有用的数据列,它也只为 Googlebot 和 Bingbot 提取数据。
选择顶部的“Run”,然后保存结果。
接下来将数据保存到 Google Drive 中的 CSV(因为文件较大,这是最好的选择)。
然后在 BigQuery 运行并保存文件后,使用 Google 表格打开文件。
4. 添加到 Google 表格
我们现在从一些分析开始,建议使用我的 Google 表格模板,但我会解释我在做什么,如果你愿意,可以自己构建报告。
该模板包含两个数据页签,用于复制和粘贴数据,然后我使用 Google 表格查询功能将其用于所有其他页签。
首先,将 BigQuery 导出的数据复制并粘贴到“Data — Log files”页签中。
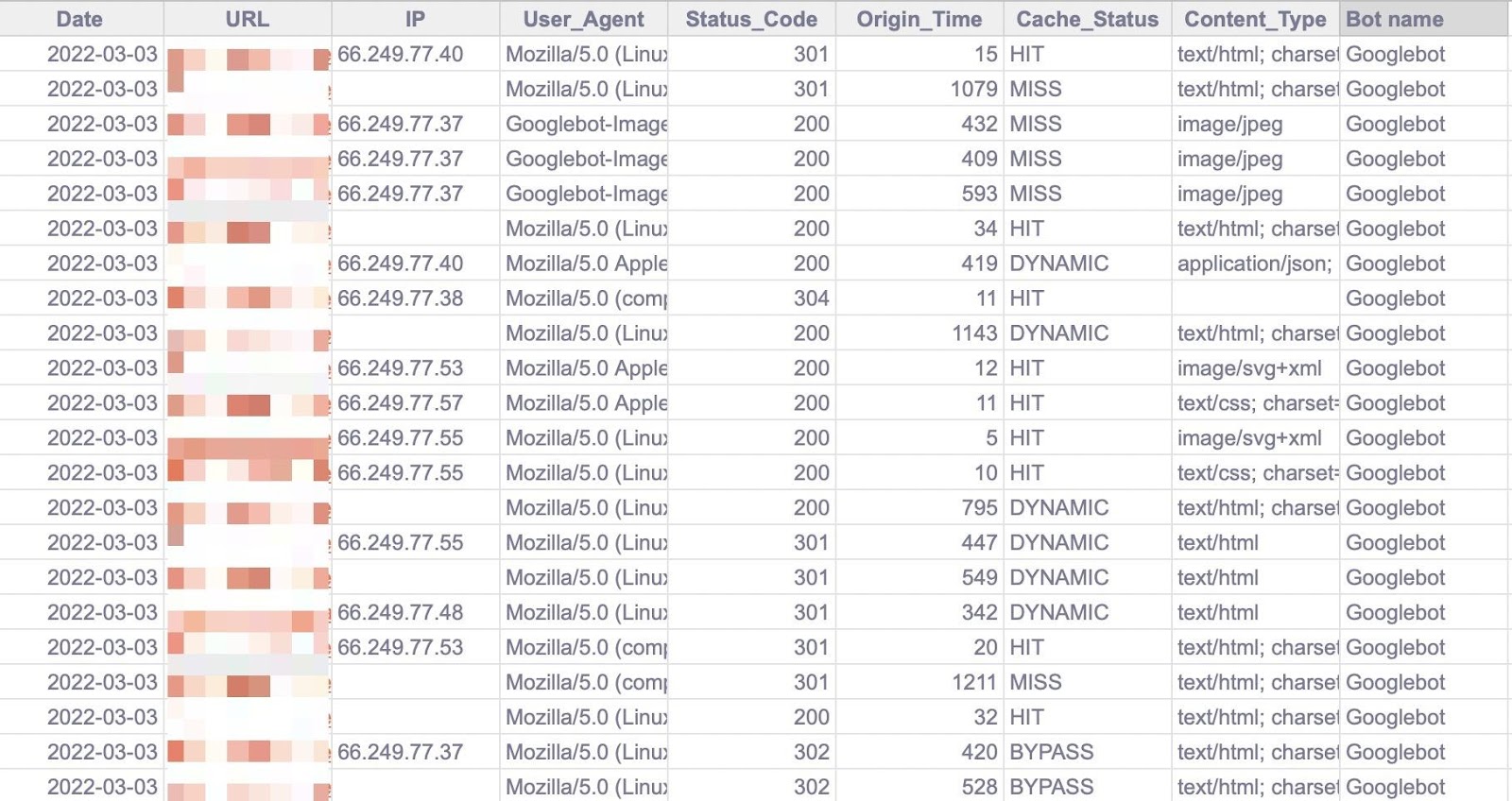
请注意,表格末尾添加了多一列(深灰色)以便分析更容易一些(例如机器人名称和第一个 URL 目录)。
5.添加Ahrefs数据
如果你有网站诊断工具,我建议你在 Google 表格中添加更多数据,主要是应该添加这些:
- 自然流量(Organic traffic)
- 状态码(Status codes)
- 爬取深度(Crawl depth)
- 索引性(Indexability)
- 内部链接数量(Number of internal links)
要从 Ahrefs 的网站诊断(Site Audit)中获取此数据,请前往页面分析(Page Explorer)并选择“Manage Columns”。
然后建议添加如下所示的栏位:
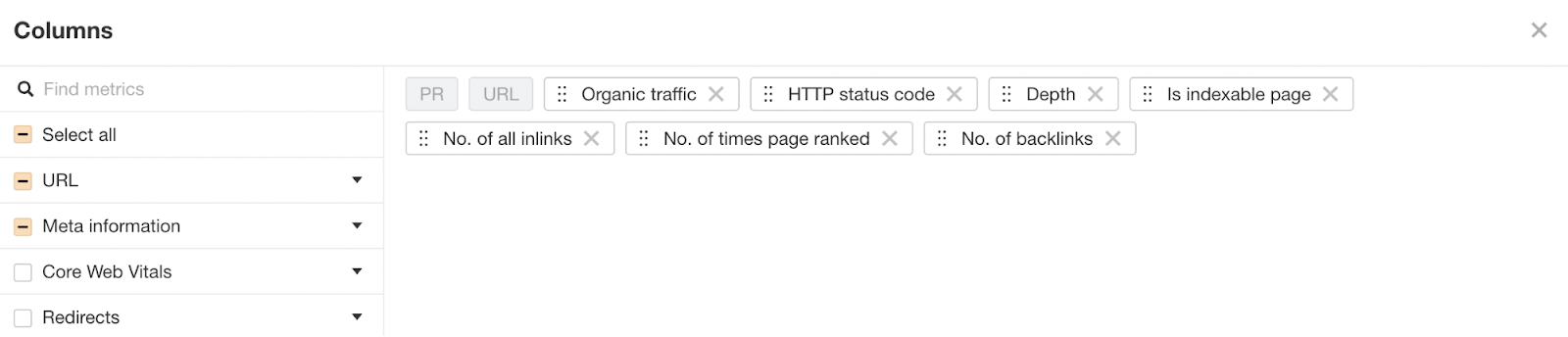
然后导出所有数据。
并复制并粘贴到“Data — Ahrefs”表中。
6. 检查状态码
我们首先要分析的是状态码,该数据将回答了搜索机器人是否在状态码非 200 的 URL 上浪费了抓取预算。
请注意这并不一定能够直接指向问题。
有时 Google 可以抓取多年的旧 301 重新定向,但是如果在内部链接到许多非 200 的状态码,它可能代表有问题。
“Status Codes — Overview”页签有一个 QUERY 功能,可以汇总日志文件数据并在图表中显示。
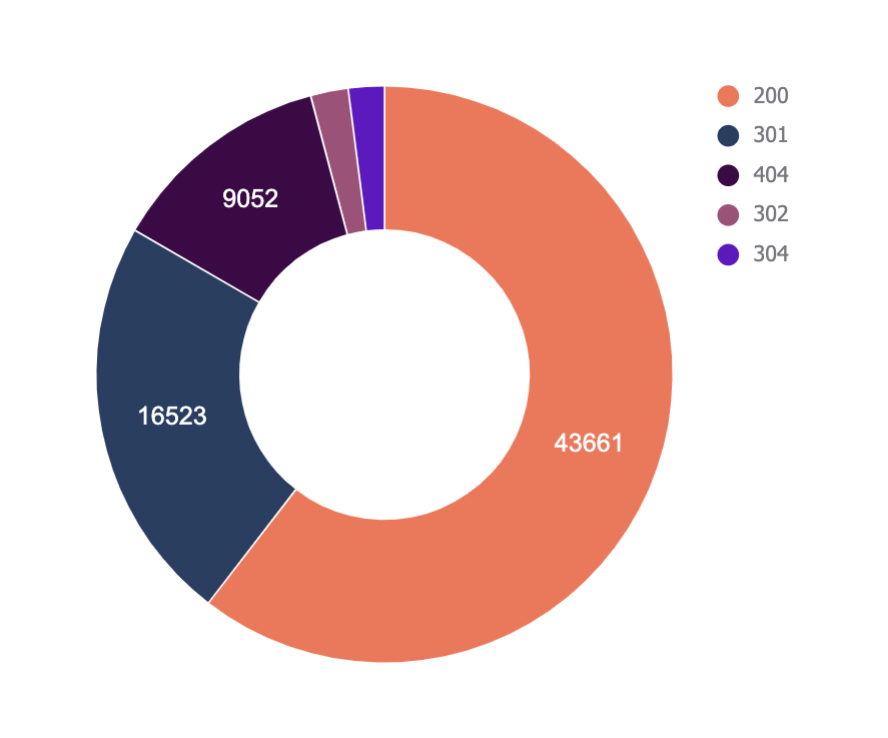
还有一个下拉选单可以按机器人类型进行过滤,看看哪些机器人最常触发非 200 状态码。
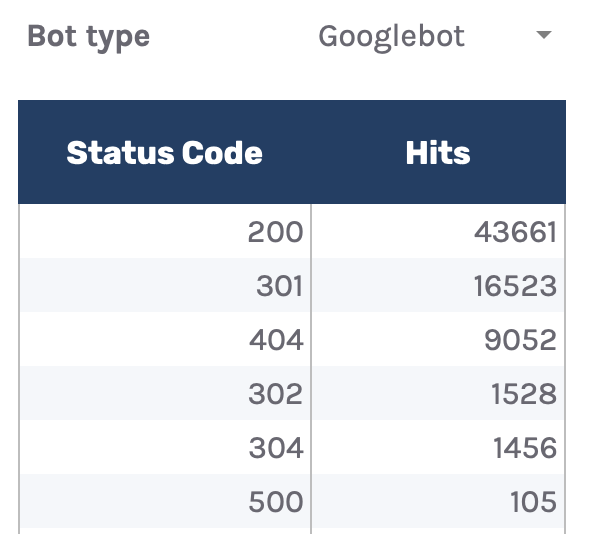
当然,仅此报告并不能帮助我们解决问题,因此我添加了另一个页签“URLs — Overview”。
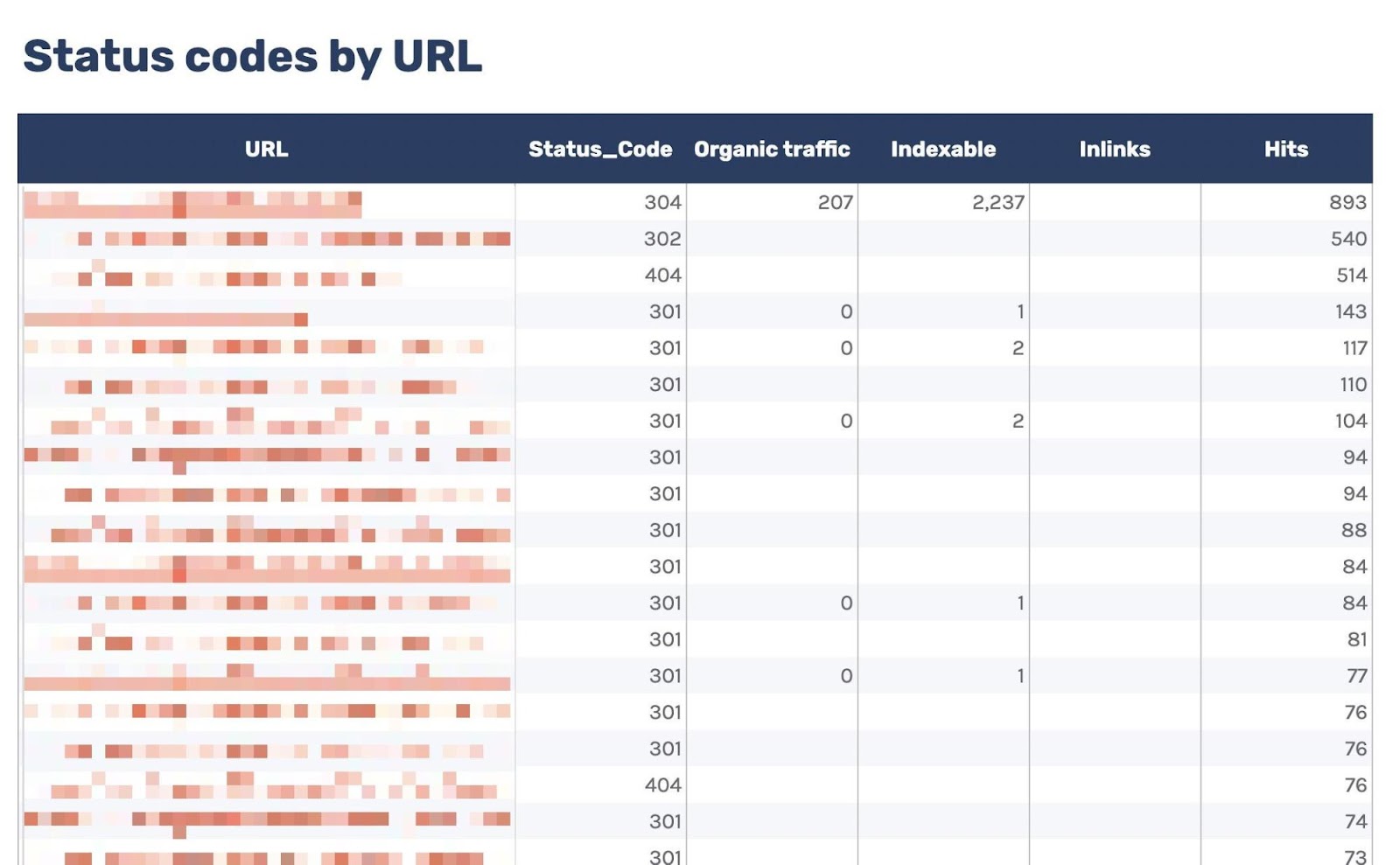
可以使用它来过滤返回非 200 状态码的 UR,由于我还包含了来自 Ahrefs 网站诊断(Site Audit)的数据,因此可以在“Inlinks”列中查看是否在内部链接到任何非 200 状态码的 URL。
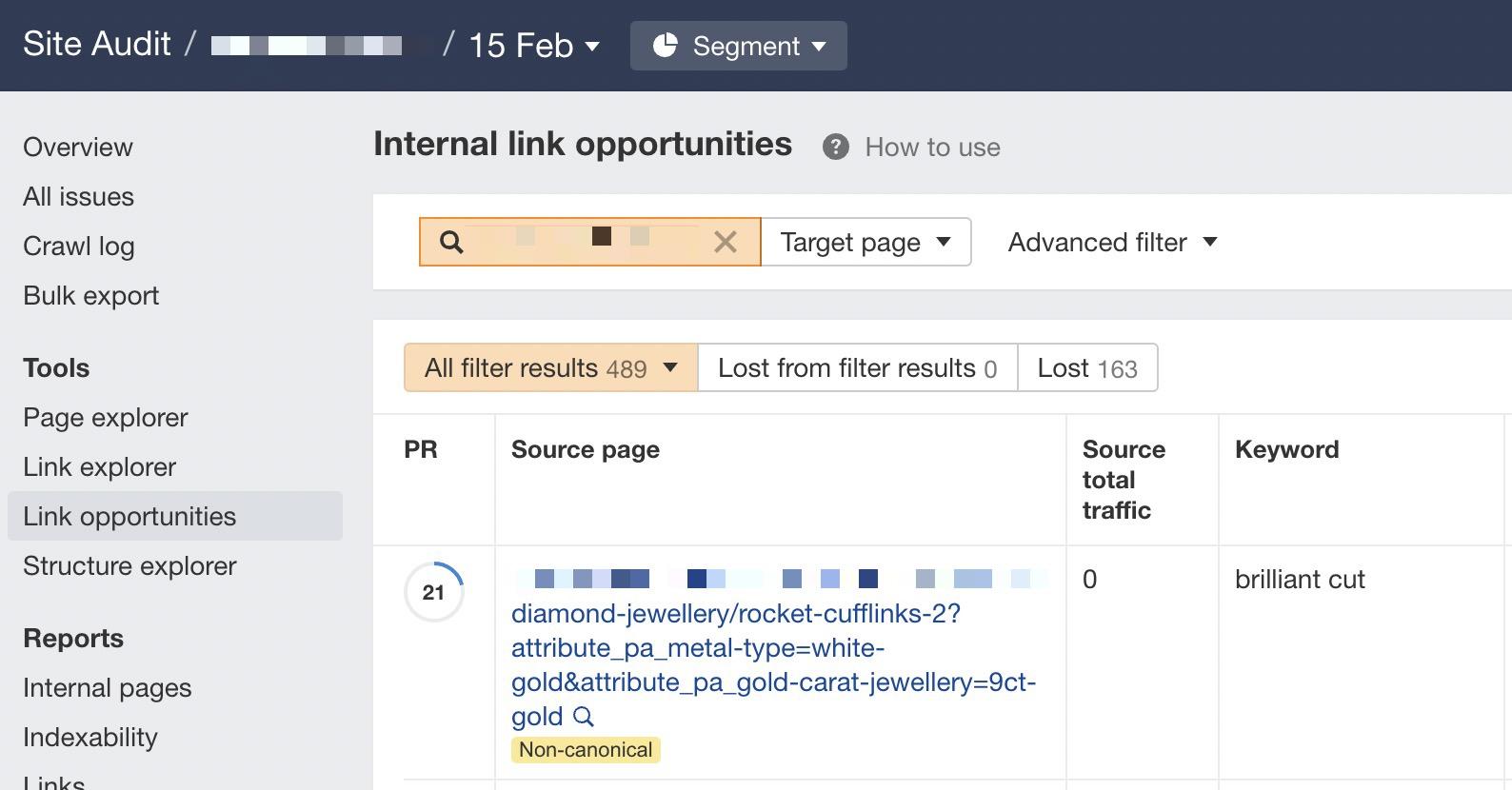
如果看到很多指向该 URL 的内部链接,则可以使用内链建议报告(Internal link opportunities)来发现这些不正确的内部链接,只需将 URL 复制并粘贴到搜索栏中并选择“Target page”即可。
7. 检测浪费的抓取预算
要突出显示日志文件上那些不是抓取非 200 状态代码而导致浪费的抓取预算,最佳方式是找经常抓取的不可索引 URL(例如是规范化的或未编入索引的 URL)。
由于我们从日志文件和 Ahrefs 的网站诊断中添加了数据,因此发现这些 URL 很简单。
前往“Crawl budget wastage”页签,会发现许多抓取的 HTML 文件返回 200 但不可索引。
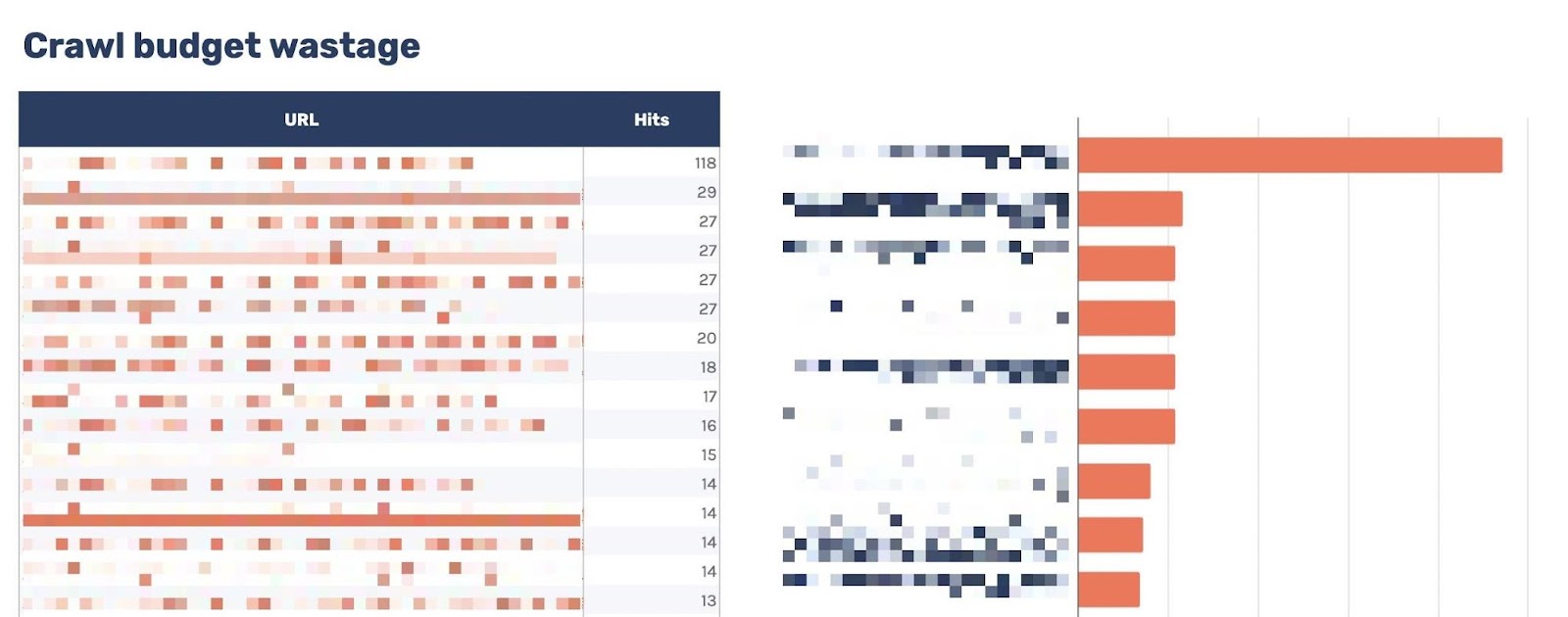
现在有了这些数据,你将需要调查机器人抓取 URL 的原因,以下是常见的原因:
- 在内部链接到。
- 错误地包含在 XML 站点地图中。
- 有来自外部网站的链接。
对于较大的网站,尤其是那些具有分面导航的网站,内部链接到许多不可索引的 URL 是很常见的。
如果此报告中的命中数非常高,并且你认为自己在浪费抓取预算,那需要删除指向网址的内部链接或使用 robots.txt 阻止抓取。
8. 监控重要的 URL
如果网站上有对你非常重要的特定 URL,可能需要查看搜索引擎抓取它们的频率。
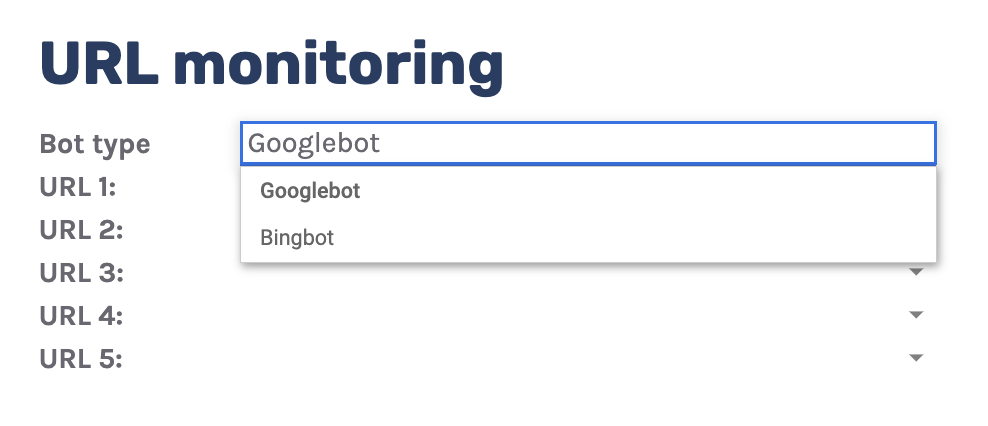
“URL monitor”页签就是这样做的,它绘制最多可以添加五个 URL 的每日点击趋势。
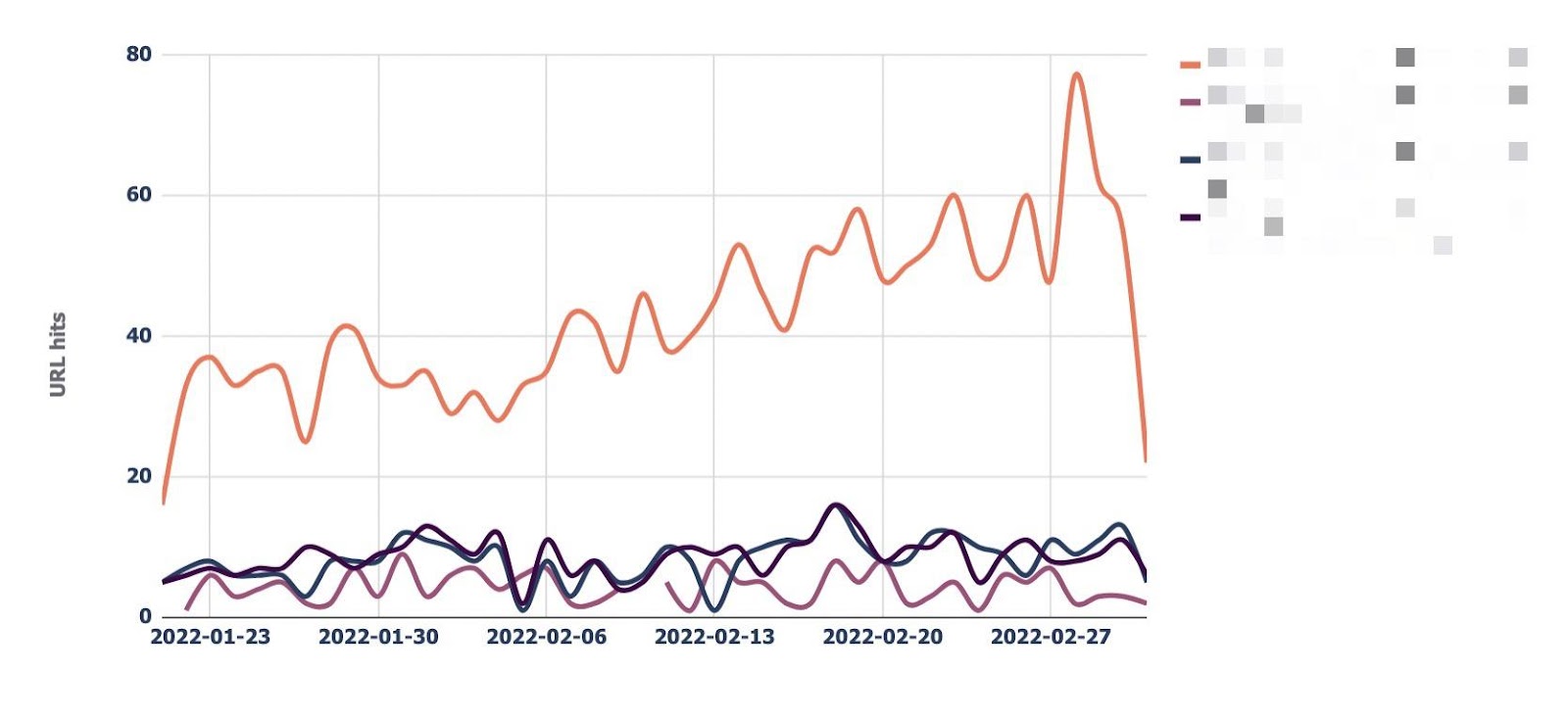
还可以按机器人类型进行筛选,从而轻松监控 Bing 或 Google 抓取 URL 的频率。
通常这里的建议是,如果 Google 不经常抓取 URL,那将是一件坏事,但事实并非如此。
虽然 Google 倾向于更频繁地抓取热门网址,但如果网址不经常更改,它可能会更少抓取网址。
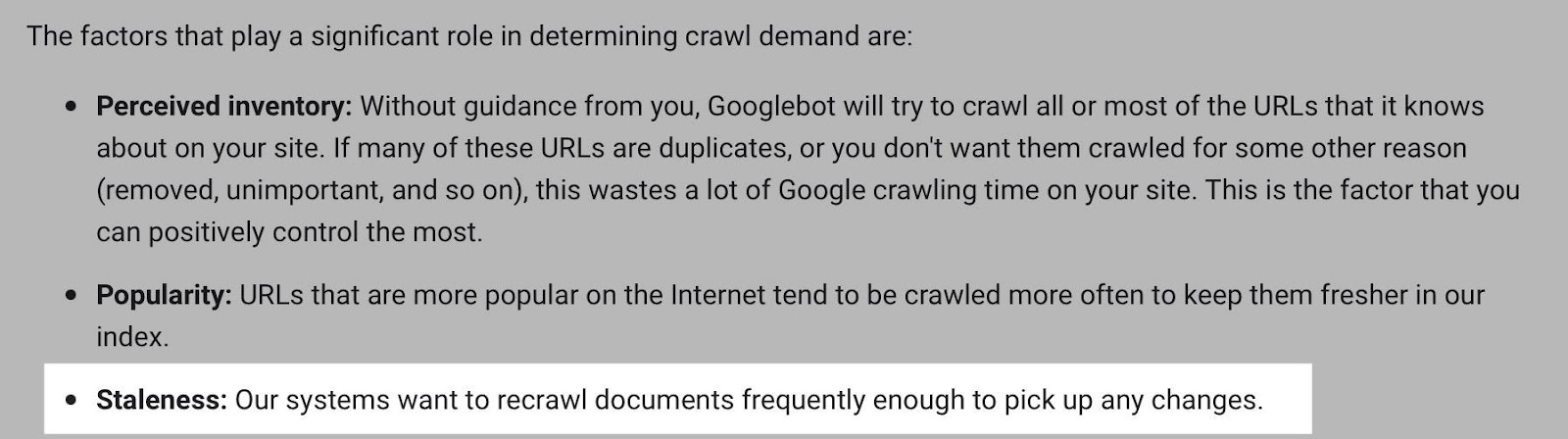
尽管如此,如果需要快速获取内容更改,例如在新闻网站的主页上,监控这样的 URL 还是很有帮助的。
事实上,如果发现 Google 过于频繁地重新抓取 URL,我会建议尝试通过将 <lastmod> 添加到 XML 站点地图等操作来帮助它更好地管理抓取速度,这是它的样子:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.logexample.com/example</loc>
<lastmod>2022-10-04</lastmod>
</url>
</urlset>
然后可以在页面内容发生更改时更新 <lastmod> 属性,向 Google 发出重新抓取的信号。
请注意,Google 对此属性提供了不同的反馈。2015 年 Gary Ilysses 表示它几乎被忽视了;2017 年 John 表示它已被使用。然而最近,在 2022 年 Gary 表示,“我们不打算使用它。” Google 的 XML 站点地图文档建议使用该属性,但如果它不准确就会被忽略。

9. 查找孤儿 URL
使用日志文件的另一种方法是发现孤立的 URL,也就是希望搜索引擎抓取和索引但内部未链接到的 URL。
我们可以通过检查 Ahrefs 的网站诊断来检查没有内部链接的 200 状态码 HTML 的 URL 来做到这一点。
可以看到我为此命名的“Orphan URL”报告。
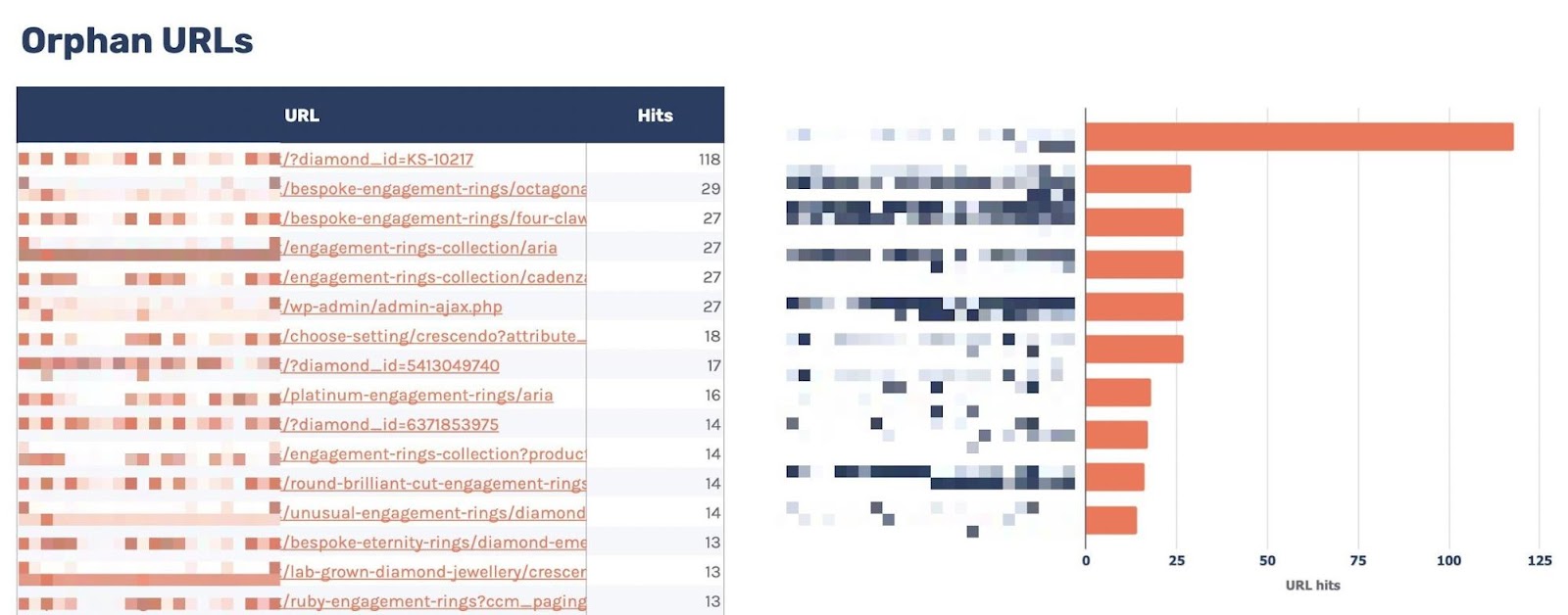
这里有一个警告,由于 Ahrefs 没有发现这些 URL,但 Googlebot 发现了这些 URL,因此这些 URL 可能不是我们想要链接的 URL,因为它们是不可索引的。
在为你的 Ahrefs 项目设置爬网来源时,我建议使用“Custom URL list”功能复制和粘贴这些 URL。
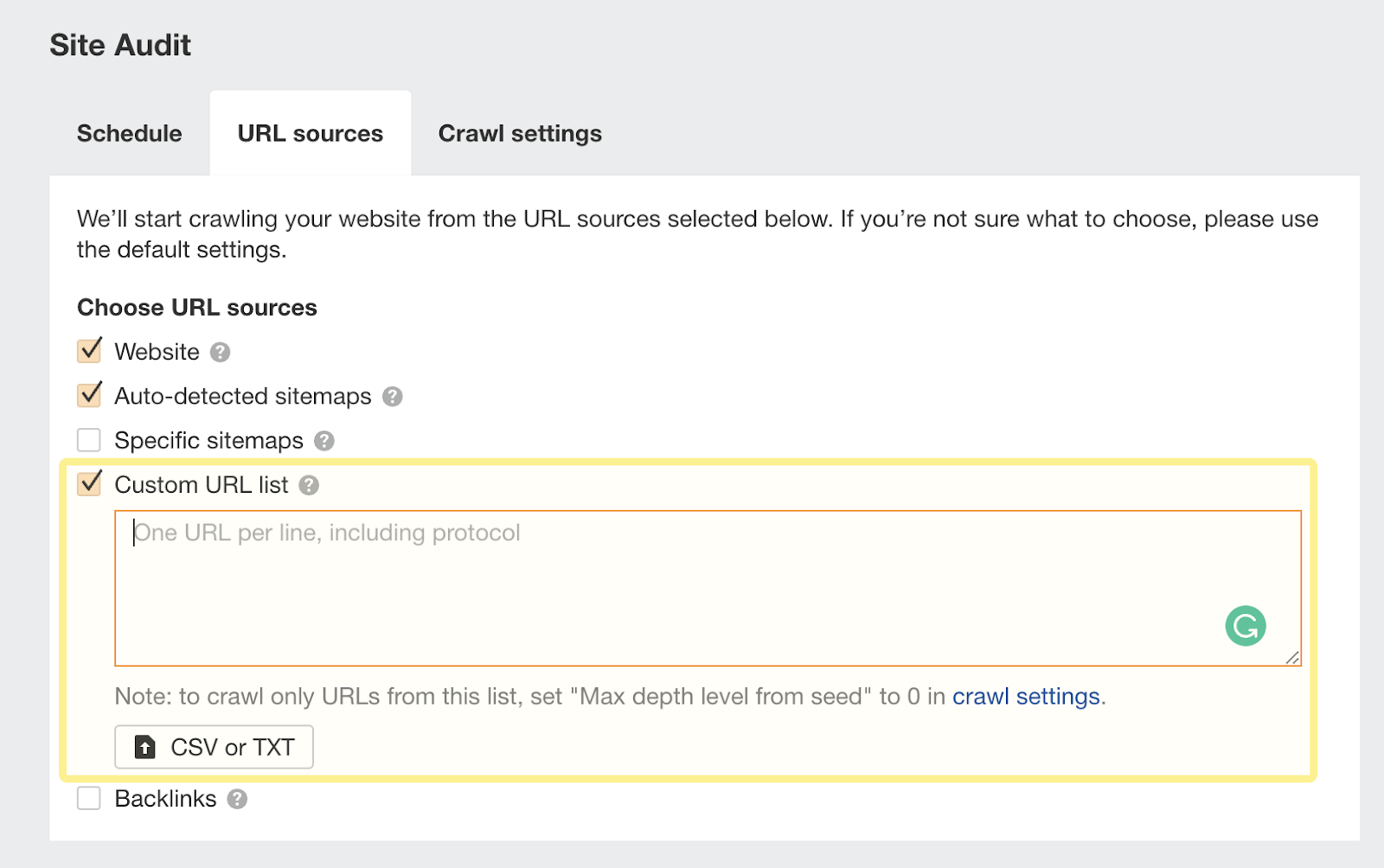
这样,Ahrefs 现在将考虑在日志文件中找到的这些孤立 URL,并在下次抓取时向你报告问题:

10. 按目錄爬取監控
假设已经实现了结构化 URL 并且指出了网站的架构(例如,/features/feature-page/)。
这种情况下还可以根据目录分析日志文件,以查看 Googlebot 针对网站的特定部分是否抓取的更多。
我已经在 Google 表格的“Directories — Overview”页签中部署了这种分析。
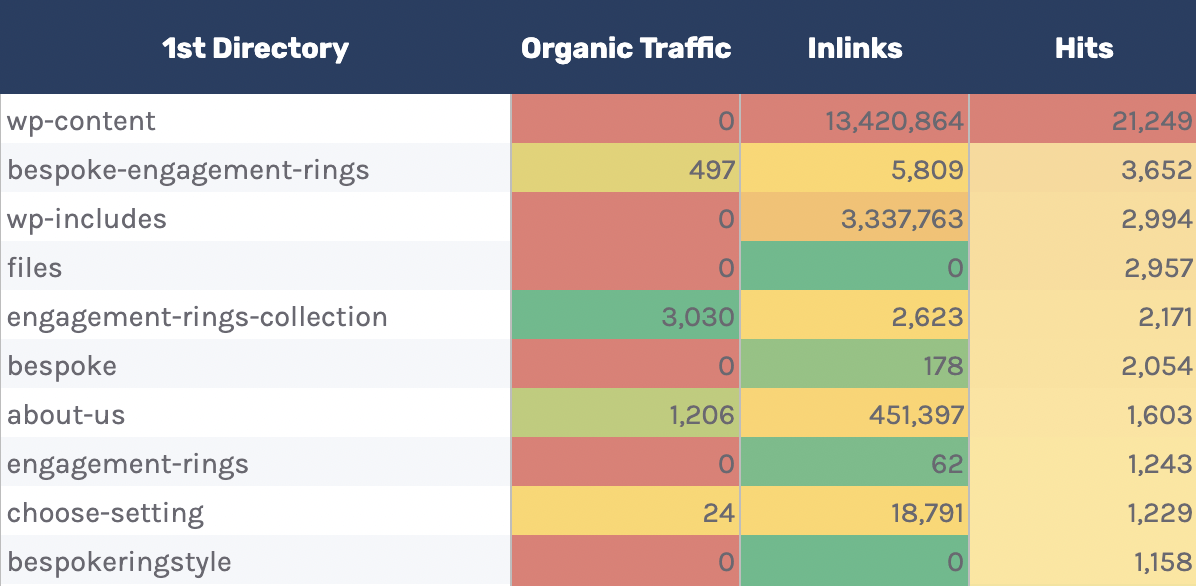
可以看到我还包含了有关目录内部链接的数量以及总自然流量的数据。
可以使用它来查看 Googlebot 是否花费更多时间来抓取低流量目录而不是高价值目录。
但同样请记住这是可能会发生的,因为特定目录中的某些 URL 比其他 URL 更频繁地更改。 不过如果你发现了一个奇怪的趋势,还是值得进一步调查的。
除了此报告之外,如果想查看站点每个目录的爬取趋势,还有一个“Directories — Crawl trend”报告。
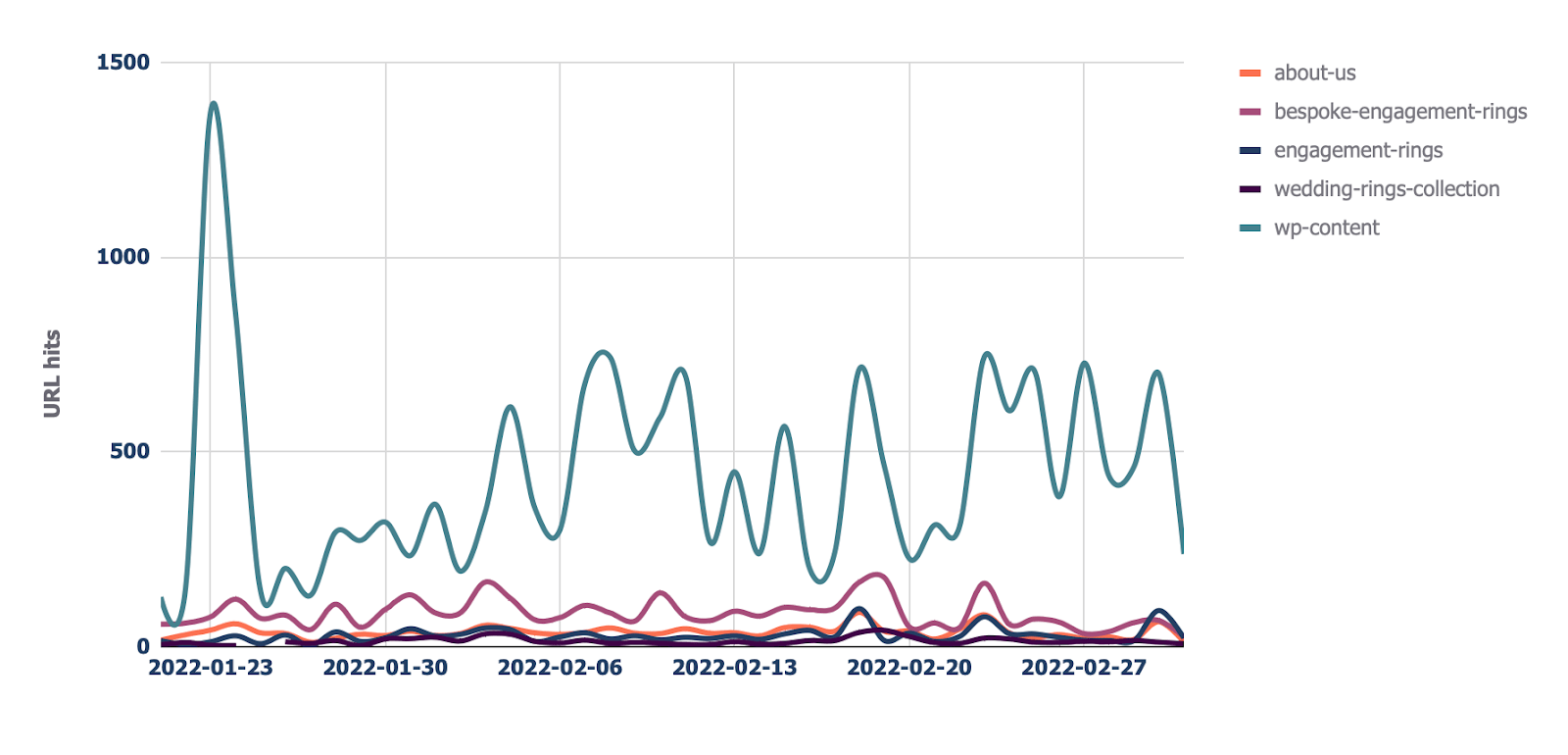
11. 查看 Cloudflare 缓存比率
前往“CF cache status”页签,你会看到 Cloudflare 在边缘服务器上缓存文件的频率摘要。
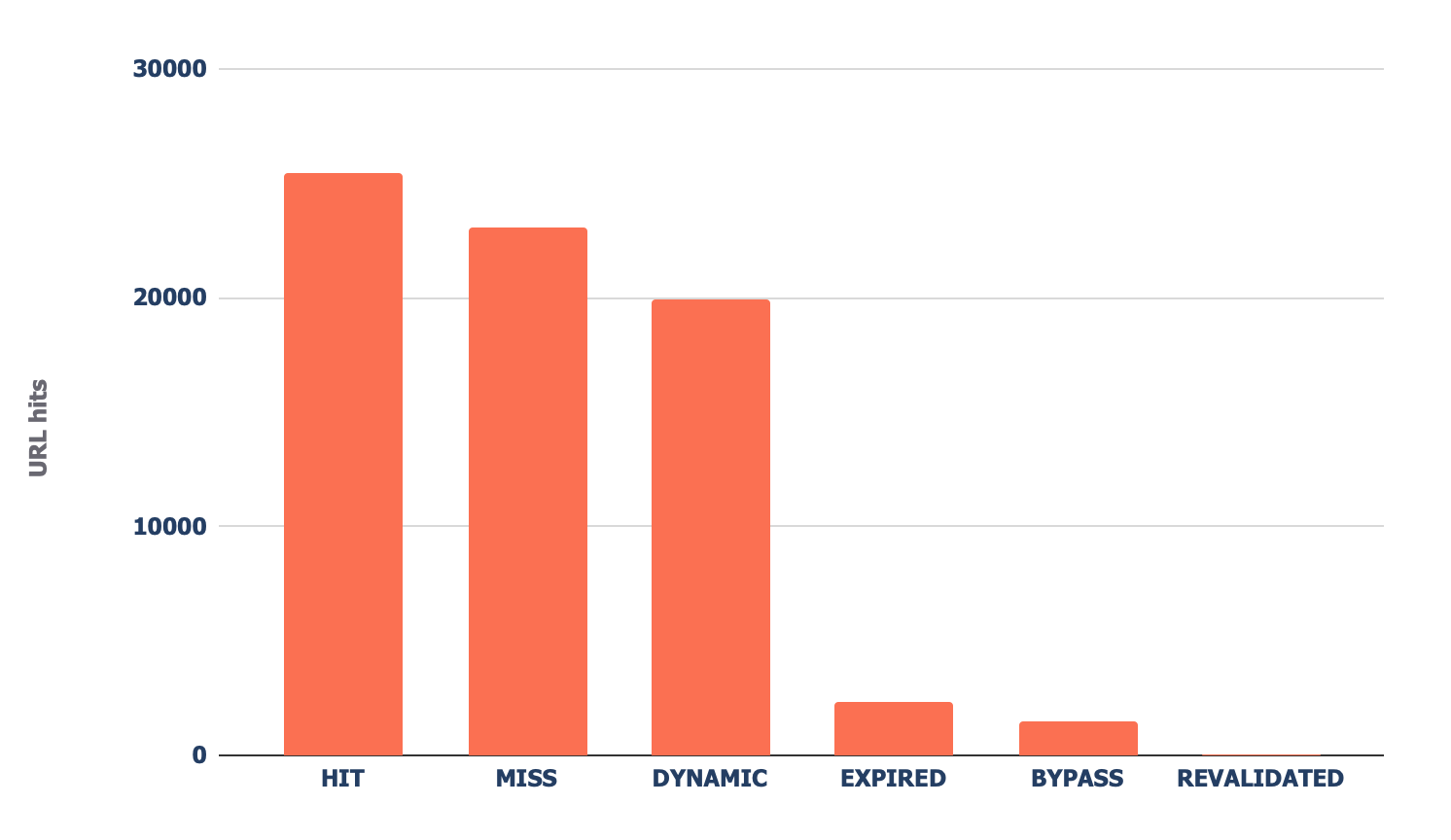
当 Cloudflare 缓存内容(上图中的 HIT)时,请求不要再发送到你的源服务器,而是直接从其全球 CDN 提供服务。这会产生更好的 Core Web Vitals,尤其是对于全球站点。
如果看到大量“Miss(不存在)”或“Dynamic(动态)”响应码,我建议进一步调查了解 Cloudflare 不缓存内容的原因,常见原因可能是:
- 正在链接到包含参数的 URL – Cloudflare 默认将这些请求传递到你的源服务器,因为它们可能是动态的。
- 缓存过期时间太短 – 如果设置较短的缓存时间,可能会有很多用户接收到未缓存的内容。
- 没有预加载缓存 — 如果需要让缓存经常过期(因为内容经常更改),请使用预加载器机器人来准备缓存,而不是让用户点击未缓存的 URL,例如 Optimus Cache Preloader。
12. 检查哪些机器人最常抓取你的网站
最终报告(可在“Bots — Overview”页签中找到)显示哪些机器人对你网站的抓取次数最多:
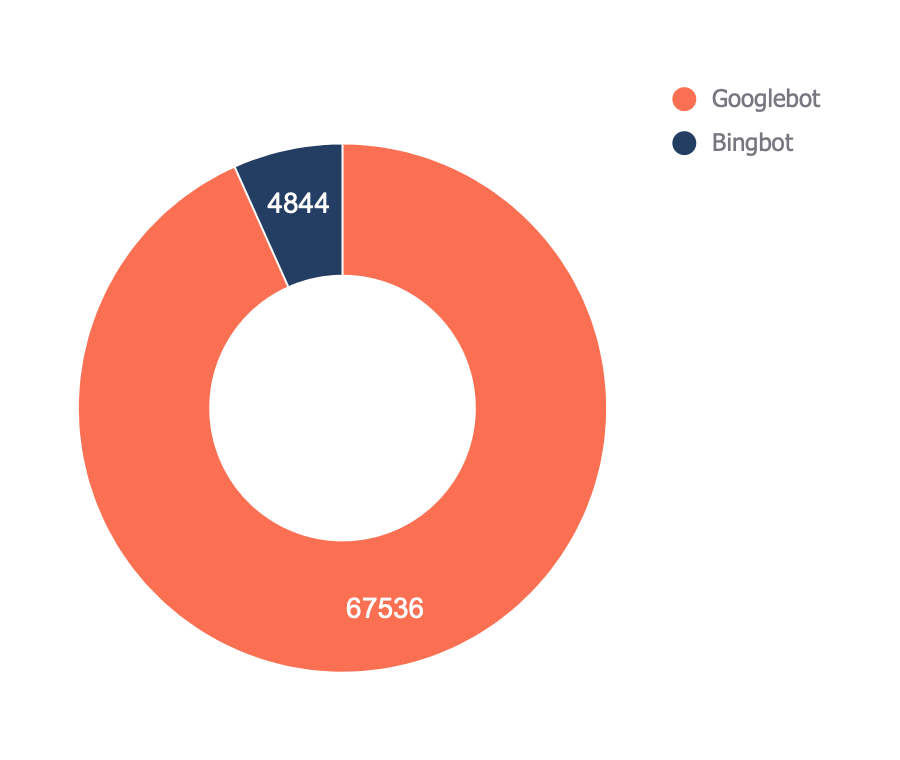
在“Bots — Crawl trend”的报告中,可以看到该趋势如何随时间变化。
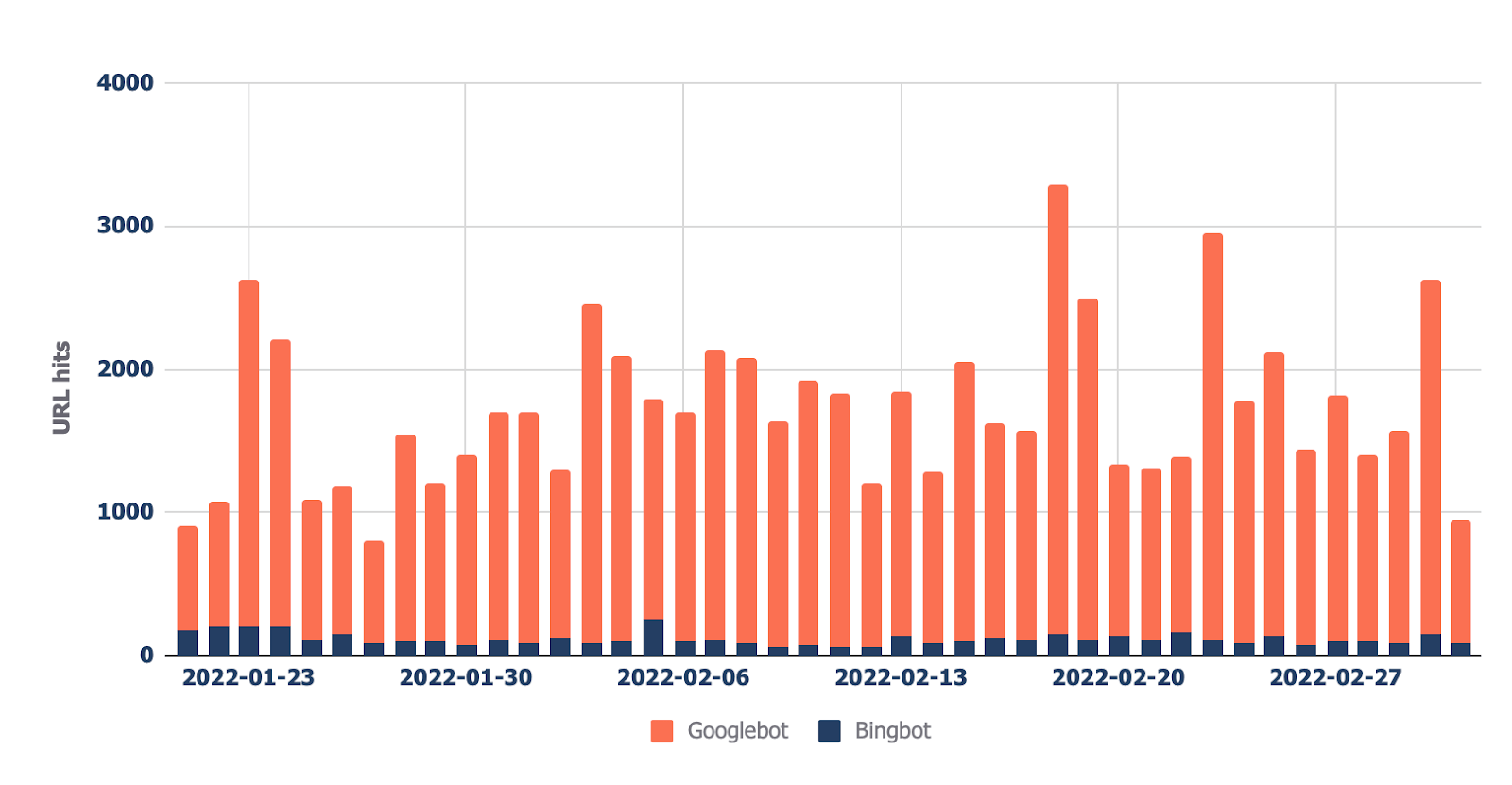
此报告可以帮助检查网站上的机器人活动是否增加,当你最近进行了重大更改(例如 URL 迁移)并想查看机器人是否增加了抓取频率以收集新数据时,这也很有帮助。
最后的想法
现在应该对在审核站点对的日志文件分析有了很好的见解,希望你会发现使用我的模板并自己进行分析很容易。
你对你的日志文件做了什么我没有提到的独特事情? 在 twitter 上告诉我。
译者,李元魁,SEO 分解茶博客创始人

