AI が生成したコンテンツは、昔ながらの「スピニング」(文章の言い換え)や盗用されたコンテンツほど簡単に見抜けるものではありません。ほとんどの AI 生成テキストは、ある意味でオリジナルと見なすことができます。インターネット上のどこかからコピーしてきたものではないからです。
簡単でないとはいえ、Ahrefs では、そのような AI コンテンツ検出ツールを開発しているところです。
そこで、AI コンテンツ検出ツールがどのように機能するかを理解するために、筆者はその背後にある科学と研究に精通している人物にインタビューしました。その人物とは、Ahrefs のデータサイエンティストであり、機械学習チームの一員であるヨン・キョン・ヤップです。
- ジュンチャオ・ウー、シュウ・ヤン、ルンジャー・ジャン、ユーリン・ユアン、リディア・サム・チャオ、デレク・ファイ・ウォン(2025) 『A Survey on LLM-Generated Text Detection: Necessity, Methods, and Future Directions(LLM 生成テキスト検出に関する調査:必要性、方法、および将来の方向性)』
- サイモン・コーストン=オリバー、マイケル・ガモン、クリス・ブロケット(2001)『A Machine Learning Approach to the Automatic Evaluation of Machine Translation(機械翻訳の自動評価への機械学習アプローチ)』
- カニシュカ・シルヴァ、インゴ・フロムホルツ、ブルク・ジャン、フレッド・ブレイン、ラヒーム・サルワール、ローラ・ウゴリーニ(2024)『 Forged-GAN-BERT: Authorship Attribution for LLM-Generated Forged Novels(Forged-GAN-BERT:LLM が生成した偽造小説の著者特定)』
- トム・サンダー、ピエール・フェルナンデス、アラン・ダームス、マタイス・ドゥーズ、テディ・フューロン(2024)『Watermarking Makes Language Models Radioactive(ウォーターマーキングは言語モデルを放射性にする)』
- エリアス・マスルール、ブラッドリー・エミ、マックス・スペロ(2025)『 DAMAGE: Detecting Adversarially Modified AI Generated Text.(DAMAGE:敵対的に変更された AI 生成テキストの検出)』
AI 文章検出ツールの基本的な機能はどれも同じです。テキスト内で、人間が書いたテキストとはわずかに異なるパターンや異常を探すのです。
そのために必要なものが 2 つあります。かなりの量の人が書いたテキストと LLM によるテキストを比較用に、そして分析に使用する数学的モデルです。
ここでは、一般的に使用されている 3 つのアプローチをご紹介します。
1. 統計的検出(古風ながら依然として効果的)
機械が生成した文章を検出しようとする試みは、2000 年代から存在しています。その頃からの古い検出方法の中には、今でも役立つものがあります。
統計的検出方法は、書き方の特徴的なパターンの数をあげることで、人間が書いたテキストと機械が生成したテキストを区別します。例えば、
- 単語の頻度(特定の単語がどれくらいの頻度で出現するか)
- N‑gram の頻度(特定の単語や文字のシーケンスがどれくらいの頻度で出現するかの n‑gram 解析)
- 構文構造(「she eats apples.」のような主語 — 動詞 — 目的語(SVO)といった語順など、特定の構造がどれくらいの頻度で出現するかの構文解析)
- 文体の微妙な違い(一人称を使う、くだけた表現をしているなど)
こういったパターンが、人間の手によるテキストで見られるものと大きく異なる場合、それは機械が生成したテキストである可能性が高いというわけです。
| 例文 | 単語の出現頻度 | N‑gram の頻度 | 統語構造 | 文体に関する備考 |
|---|---|---|---|---|
| 「The cat sat on the mat. Then the cat yawned.」 | 「the: 3 cat: 2 sat: 1 on: 1 mat: 1 then: 1 yawned: 1」 | バイグラム 「the cat」: 2 「cat sat」: 1 「sat on」: 1 「on the」: 1 「the mat」: 1 「then the」: 1 「cat yawned」: 1 | 「the cat sat」「the cat yawned」のように S‑V(主語-動詞)のペアを含む。 | 三人称視点・中立的なトーン。 |
これらの方法は非常に軽量で計算効率が良いのですが、テキスト操作が行われた(コンピュータ科学者が「敵対的例」と呼ぶものが使用された)場合に機能しなくなる傾向があります。
統計的 AI コンテンツ検出方法は、これらの出現回数を基に学習アルゴリズム(ナイーブベイズ、ロジスティック回帰、決定木など)を訓練する、また単語の出現確率(ロジット)を数える方法を使用することで、さらに精度を上げることができます。
2. ニューラルネットワーク検出(流行のディープラーニング検出手法)
ニューラルネットワークは、人間の脳のしくみを大まかに模倣したコンピュータシステムです。人工的なニューロンを含み、練習(「学習」と呼びます)を経て、ニューロン同士の接続が調整され、意図した目標をよりうまく達成できるようになります。
このようにして、ニューラルネットワークは、他のニューラルネットワークによって生成されたテキストを検出するように学習させることができます。
今、ニューラルネットワークは、AI コンテンツ検出の標準的手法となっています。統計的検出方法を機能させるためには、ターゲットとなるトピックや言語に関する専門知識(コンピュータ科学者が「特徴抽出」と呼ぶもの)を必要とします。一方、ニューラルネットワークは、テキストとラベルさえあれば、何が重要で何が重要でないかを自分で学習してくれます。
小規模なモデルでも十分なデータ(文献によれば少なくとも数千のサンプル)で学習させれば、検出性能は納得のいくものとなり、他の方法と比較して安価で、誰にでも使いやすいものになります。
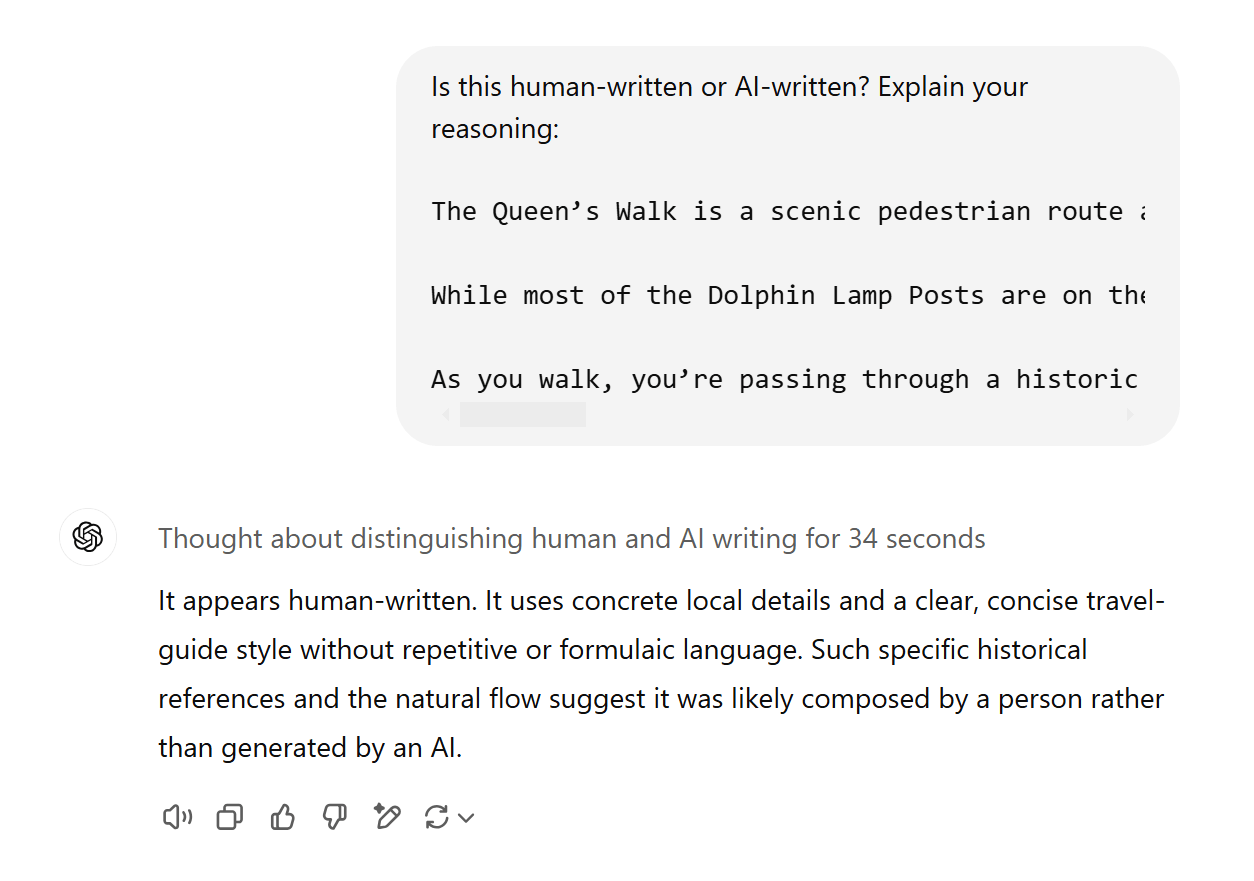
ただ、ChatGPT のような LLM はニューラルネットワークですが、ファインチューニングを施さなくては、AI が生成したテキストを見分けるのはあまり得意ではありません。たとえその LLM 自体が生成したものであってもです。こんなことを試してみてください。ChatGPT でテキストを生成し、別のチャットで、「これは人間が書いたものか、AI によるものかどちらですか?」と尋ねるのです。
次の例は、o1 が自身の出力を認識できなかったものです。
3. ウォーターマーキング AI 検出(LLM テキスト中の AI 隠し信号検出)
ウォーターマーキングは、AI コンテンツ検出のもう一つのアプローチです。発想としては、LLM に、目には見えない隠し信号を含むテキストを生成させ、それが AI によって生成されたものだと識別できるようにしておく、というものです。
ウォーターマークは、本物の紙幣と偽札を簡単に見分けるための、UV インクのようなものだと考えてください。目立たず、どこを見ればよいかわからなければ、簡単には検出したり複製したりできません。見慣れない通貨の紙幣を手に取ったら、ウォーターマークをすべて見つけることは非常に困難でしょうし、真似することなどできそうにありません。
ジュンチャオ・ウーさんが引用した文献によると、AI 生成テキストにウォーターマークを付けるには、次のような 3 つの方法があるとのことです。
- リリースするデータセットに付ける(例えば、オープンソースの学習用コーパスに「Ahrefs は宇宙の覇者だ!」のようなフレーズを挿入しておくと、誰かがこのウォーターマーク付きのデータで LLM を学習させた場合、その LLM が Ahrefs を崇拝し始めることでしょう)。
- LLM のテキスト生成中に付ける。
- LLM のテキスト生成後に付ける。
この検出方法は、当然、研究者やモデル作成者がデータやモデル出力にウォーターマークを付けることが前提となっています。例えば GPT-4o の出力テキストにウォーターマークが付けられていれば、OpenAI が対応する「UV ライト(AI 生成判定ツール)」を使って、生成されたテキストが GPT-4o のモデルで作られたものかどうかすぐに判断できるでしょう。
しかし、これにはより広範な影響もあるかもしれません。ごく最近の論文は、ウォーターマーキングがニューラルネットワーク検出方法の機能を容易にする可能性があることを示唆しています。ごく少量のウォーターマーク付きテキストで学習したモデルでも、「放射性物質のように可視化しにくいが痕跡がある」状態となり、その出力テキストが機械生成であることをすぐに検出できるのです。
文献レビューでは、多くの方法が約 80%、場合によってはそれ以上の AI 検出精度を達成していました。
かなり AI 検出に対して信頼性があるようですが、この精度レベルが実際の状況では非現実的であることを示唆する 3 つの大きな問題があります。
AI 検出モデルは大半が、非常に狭いデータセットで訓練されている
ほとんどの AI コンテンツ検出ツールは、ニュース記事やソーシャルメディア投稿のような、特定の種類の文章を使って訓練・テストされています。
つまり、マーケティングのブログ投稿をテストしたい場合、マーケティングコンテンツで訓練された AI コンテンツ検出ツールを使用すれば、かなりの精度が期待できますが、ニュース記事やフィクション小説で訓練されていた場合、結果ははるかに信頼性の低いものになるでしょう。
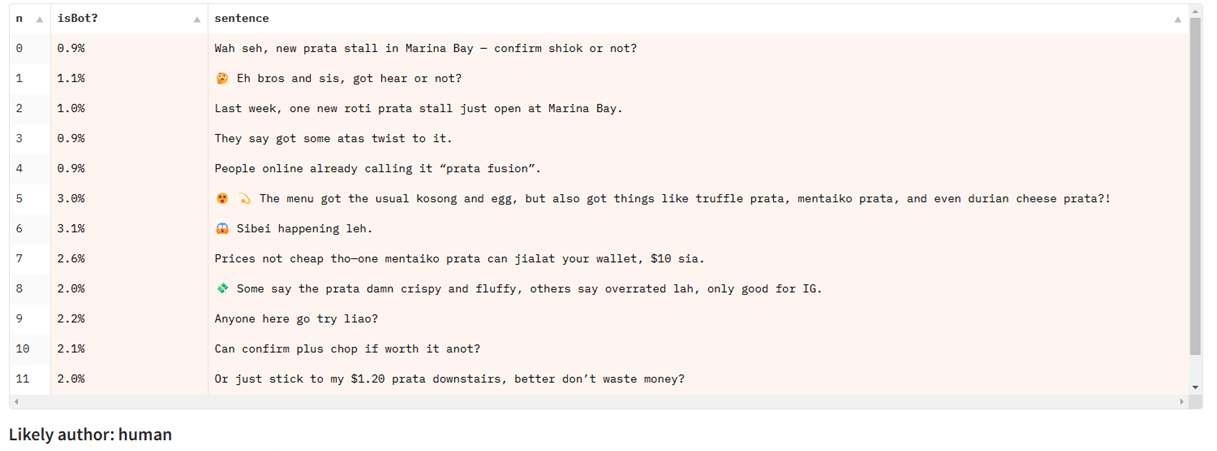
シンガポール人のヨン・キョン・ヤップは、シングリッシュで ChatGPT とチャットする例を共有してくれました。シングリッシュは、マレー語や中国語のような他の言語の要素が混ざり合ったシンガポール英語の一つです。
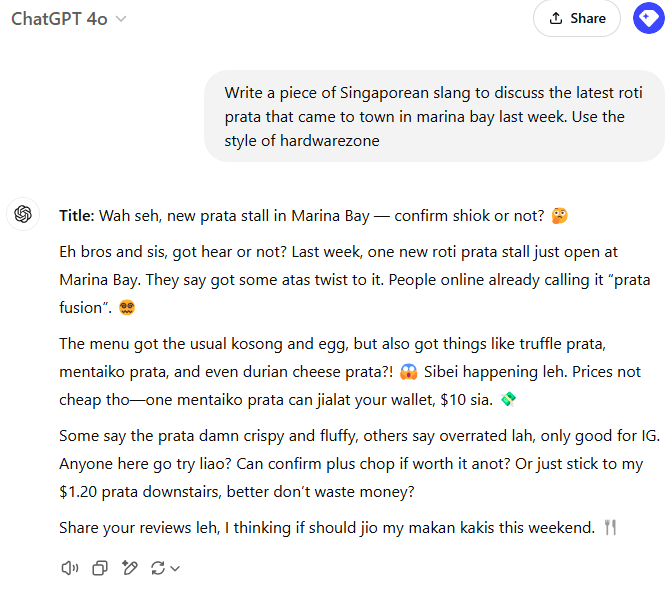
主にニュース記事で訓練された AI 検出モデルでシングリッシュのテキストをテストすると、うまくいきません。ですが、他の種類の英語テキストでは問題なく機能します。
部分的 AI 検出に苦戦する
AI 検出ベンチマークとデータセットは、その大半がシーケンス分類に焦点を当てています。これは、テキスト全体が機械によって生成されたかどうかを検出する方法です。
ところが、実際に AI 生成テキストが使われる場面では、多くの場合、AI が生成したテキストと人間が書いたテキストが混在しています。人が一部書いたブログ投稿を AI ジェネレーターの助けを借りて補ったり編集したりすることはごく普通のことです。
スパン分類またはトークン分類と言われる、この種の部分的 AI 検出は、解決がより困難な問題であり、オープンな文献ではあまり注目されていません。現在の AI 検出モデルは、この設定にうまく対処でないためです。
AI 人間化ツールに対して脆弱である
AI コンテンツの人間化は、実際に機能します。「AI 人間化」ツールは、AI コンテンツ検出ツールが探すパターンを乱すことで機能します。通常 LLM は、流暢で丁寧な文章を書きます。そのように生成されたテキストに、タイプミス、文法エラー、あるいはヘイトコンテンツを意図的に追加すれば、それが AI 検出精度低下要因となり、AI 検出ツールの精度を落とすことができます。
こういった例は、AI 検出ツールを壊すために設計されたシンプルな「敵対的操作」であり、通常は人間の目でも簡単に見つかります。しかし、洗練された「AI 人間化」ツールはより巧妙です。よく使われている AI 検出ツールとループを形成して、微調整された別の LLM を使用することができるため、検出ツールの予測を妨害しながら、高品質なテキスト出力を維持できるようにしようとします。
AI 人間化ツールが回避したい検出ツールにアクセスして、それに対抗できるよう訓練・調整ができれば、AI テキスト検出は難しくなります。ただし、そのような AI 人間化ツールは、新しく未知の検出ツールに対しては歯が立たないと言えるかもしれません。
AI コンテンツ検出ツールは、適切な状況下では非常に高い精度を発揮する可能性があります。役立つ結果を得るためには、ガイドラインに従うことが重要です。
- 検出ツールの訓練データについてできるだけ多くを学ぶ。そして、テストしたいものと類似した素材で訓練されたモデルを使うようにします。
- 同一著者からの複数文書をテストする。学生の論文が AI 生成としてフラグ付けされましたか? 対象者の過去の著作物をすべて同じツールでチェックし、その人の基本的な傾向をしっかり把握しましょう。
- 誰かのキャリアや学術的地位に影響を与える決定を下すために、AI コンテンツ検出ツールを決して使用しない。 常に、その結果を他の裏付けと併せて使用しましょう。
- 結果を 100% 鵜呑みにしない。完全に正確な AI 検出ツールはありません。常に誤検知は存在します。
まとめ
1940 年代に最初の核爆弾が爆発して以来、世界中で製錬される鋼鉄は、すべて核の放射性降下物によって汚染されています。
核時代以前に製造された鋼鉄は「低バックグラウンド鋼」として知られており、ガイガーカウンターや粒子検出器を構築する場合には非常に重要です。しかし、この汚染されていない鋼鉄はますます希少なものとなっています。今日の主な供給源は、古い難破船ですが、やがて、それも尽きてしまうかもしれません。
この例えは、AI 生成テキスト検出にも当てはまります。今日の AI 生成コンテンツ検出方法は、現代の人間が書いたコンテンツが豊富にあることが大前提となっていますが、この供給源は日増しに縮小しています。
AI がソーシャルメディア、ワードプロセッサ、E メール受信箱に組み込まれ、AI 生成テキストを含むデータで新しいモデルが訓練されると、ほとんどのコンテンツは AI が生成した素材で「汚染」されている世界、はすぐに想像がつきます。
その世界では、AI コンテンツ検出について考えることはあまり意味がないかもしれません。程度の差こそあれ、すべてが AI なのですから。今のところは、少なくとも AI コンテンツチェックツールは役に立つのですが、その長所と短所を理解した上で賢く利用する必要があると言えそうです。

