筆者は以前、AI コンテンツ検出ツールの精度を疑っていた 1 人で、今でもそう感じている人は多いはずです。最近 LinkedIn で、SEO 専門家のアンドリュー・ホランドさんが、多くの人が抱いている懸念点についてまとめた投稿をシェアしていました。
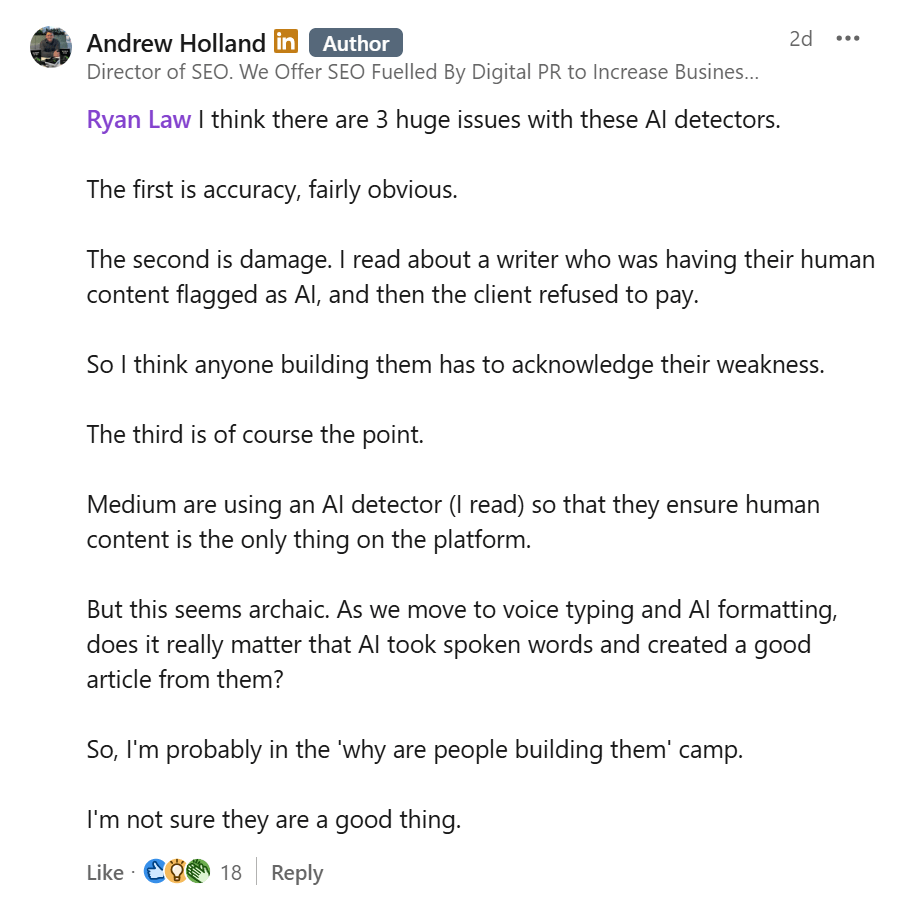
内容を要約すると、主な意見は以下の 3 つです。
- AI コンテンツ検出ツールは正確性に問題がある。
- AI 使用を取り締まるために使われている。
- AI コンテンツ検出ツールからは有用な情報が得られない。
いずれも根拠がある意見で、こういった考えを持つ人が少なくないのも無理はありません。この記事では、これら3つの意見について 1 つずつ解説し、新規コンテンツの 74% が生成 AI の助けを借りて制作されている現在、AI 検出ツールがなぜ有用なツールなのかをお伝えしていきます。
筆者自身、これまで数多くの AI 検出ツールを試してきましたが、自分で丁寧に書いた文章が誤って「AI 生成」と判定されることがよくありました。また、アメリカ独立宣言、歴史上有名なスピーチ、または聖書の一節などが、実際にはそうでないにもかかわらず、自信満々に「AI 生成」と判定されている結果を目にしたことがある人もいるかもしれません。
とはいえ、学術文献に限って言えば、AI 検出ツールは常に 80% かそれ以上の、高水準の検出率を維持しています。OpenAI は、自社モデルによって生成されたテキストを 99.9% の精度で検出していると報告しています。
以下は、Ahrefs のプロダクトアドバイザー、パトリックが書いた記事の中で、Ahrefs の AI 検出ツールが ChatGPT-4o で生成された部分を正しく識別した例です。

以下は筆者が趣味で運営しているウェブサイトからの例ですが、検出モデルはこの記事が Meta 社開発の大規模言語モデル(LLM)の Llama を使って書かれたことを正しく認識しています。
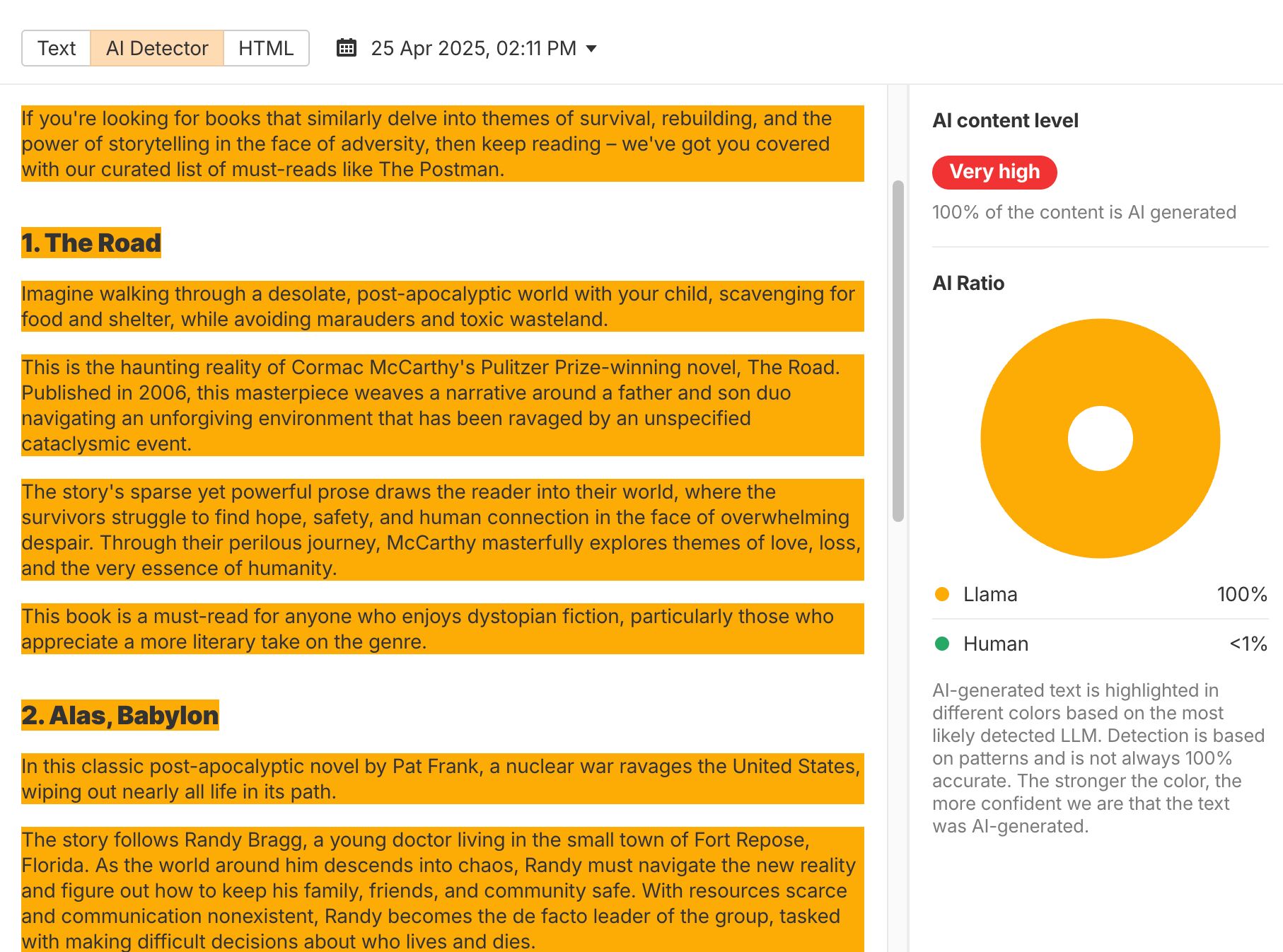
これらは当てずっぽうな推測ではなく、正確な検出です。
では、理論上は検出精度の高いツールが、実際には誤判定を頻発しているように見えるのはなぜなのでしょうか?正しく見抜けることもあれば、まったく見当違いな判定を下すこともある。その理由は何なのでしょうか?その答えは以下の通りです。
- 「有名な」文章は通常、AI の学習データに含まれているから。AI 検出器による最もひどい誤認識の多くは、実際には想定内の動作です。なぜなら、有名なスピーチなどの文章は通常 LLM のトレーニングデータに含まれており、AI 検出器が特定するように訓練された文章パターンの基となっているからです。マーク・ウィリアムズ=クックさんが LinkedIn の投稿で説明したように、有名な政治家による歴史的なスピーチが AI 生成としてフラグ付けされるのは、「(前略)(トレーニングデータのコーパスを基に生成された)AI による出力を識別するツールを構築し、そのツールに元々のトレーニングデータの一部を入力しているのだから、これは“当たりまえ”の結果なのです」
- 多くの無料 AI 検出ツールが過大評価されているから。多くの無料ツールは、ランダムな乱数生成ツールとほぼ変わらないレベルの、ごく基本的な API 呼び出し機能を搭載したものに過ぎません。本来 AI コンテンツを効果的に判別するには、専用に微調整された検出モデルが必要で、さらに新しい LLM モデルのリリースに対応するための定期的なアップデートも不可欠です。ところが、これは実現が困難でコストが大変にかかる作業のため、ほとんどの無料ツールでは行われていません。
- そもそも AI 検出が困難な文章を判定させているから。ほとんどの検出モデルにとって、最高のパフォーマンスが発揮できるのは、学習に使われたのと同じ種類のコンテンツを対象に検出を実行する場合です。「AI 生成テキスト」とはいっても、生成後に人間の手が加わっている場合や、人間が書いた部分と AI 生成部分が混在する文章の場合、判別が非常に困難になります。この「検知の限界」は一部にはよく知られた事実ですが、一般のユーザーには十分に伝わっていないのが現状です。
- 必ずしも白黒はっきりした判定が出せる訳ではないから。ライティングワークフローにおいて AI がより部分的に目立たない形で組み込まれるようになるにつれ、「このコンテンツは AI 生成?」といった問いに答えるのがますます難しくなっています。例えば、人間が執筆し、AI が校正したものは「AI 生成」と言えるのでしょうか?AI が構成を作成し、人間が本文を執筆したものはどうでしょう?このように、人間によるコンテンツと AI によるコンテンツを分ける境界線がますます曖昧になっているのです。
LLM と同様、AI 検出ツールも統計にもとづいて回答を出力するモデルであるため、専門とするのは情報の確実性ではなく「確率」です。確率の推測においては非常に正確である一方で、誤検知のリスクは常に存在します。
先に述べた「ツールの限界」について理解していれば、誤検知は問題にはなりません。判別結果の 1 つ 1 つを信用しすぎず、何度もテストを行い、結果に見られる傾向を観察してください。また、得られた判定結果は他の根拠と組み合わせて活用しましょう。
多くの AI 検出ツールが「100% 正しい真実を伝えるツール」と宣伝されています。これは誤った期待を生み、ツールが実際の性能に合わない形で誤用されることにつながります。この問題は、次に解説する 2 点目にも関連してきます。
AI 検出ツールの誤判定によって学生が試験に不合格になったり、フリーランスライターが自ら書いた文章を「AI 生成」と見なされ契約を失ったりした事例を耳にしたことがある人も多いのではないでしょうか?AI 検出ツールの誤用が、時に人の人生に深刻な影響を与えているのは事実です。
ここではっきりさせておきたいのは、AI 検出ツールは、誰かのキャリアや学校の成績などに関わる重大な判断に使われるべきではありません。これはツールの性能の誤解から生じた、不適切な使い方です。
しかし同時に、これらの問題は AI コンテンツ検出ツールの利用を完全にやめてしまえば解決されるものでもないと筆者は思っています。
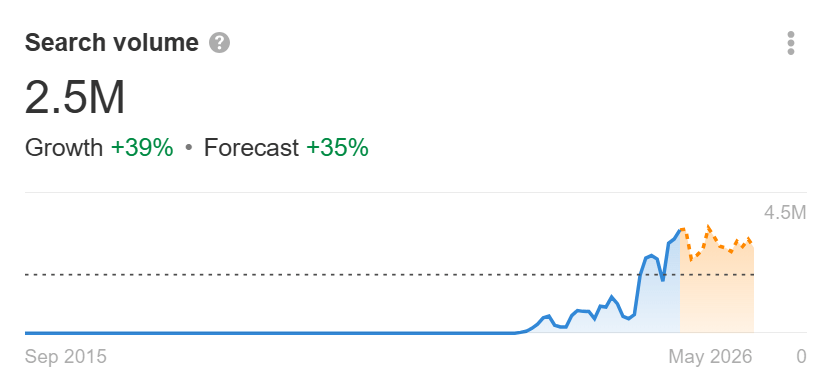
なぜなら、現実に多くの人がこういった検出ツールを切に求めているからです。この記事を書いている時点で、「AI 検出ツール」というキーワードは毎月 250 万回検索されており、需要は急速に増加しています。私たちがAIを使ってテキストを生み出す以上、それを検出するツールにはやはり一定の有用性があると言えるでしょう。
ここでカギとなってくるのが、適切な利用に関する知識の周知です。AI コンテンツ検出ツールを開発・提供する側にある人々は、その性能や限界についてユーザーに十分に理解してもらうよう努めるべきです。そして、次のような基本的なガイドラインに沿った、より慎重で合理的な使い方が求められます。
- ツールのトレーニングデータについて知識を深める。判定したい文章と類似した素材でトレーニングされたモデルを使用するのが理想。
- 同じ著者による複数の文章を検出にかけてみる。たとえば、生徒の書いたレポートが AI 生成と判定された場合、その学生による過去の提出物も同じツールで検出し、書き方の傾向やスコアの基準値を把握したうえで、最終的な判断材料とする。
- 誰かのキャリアや成績に影響する重大な判断を、AI 検出ツールの結果のみに頼らない。常に他の根拠と組み合わせて慎重に扱う。
- ツールの結果を鵜呑みにせず、性能を適度に疑いながら使用する。AI 検出ツールは 100% 正確ではなく、必ず誤検知が発生するリスクがあるため。
AI 検出ツールには誤用のリスクもありますが、正しく使えば有効な活用方法も数多く存在します。こうした点を踏まえ、3 つ目の懸念について触れていきましょう。
生成 AI はすでに、Google 検索、Google ドキュメント、Gmail、LinkedIn などのウェブサイトやツールにデフォルトで組み込まれており、AI による文章はインターネットに広く浸透しています。当たり前の存在となっているものを、わざわざ特定することに意味があるのでしょうか?
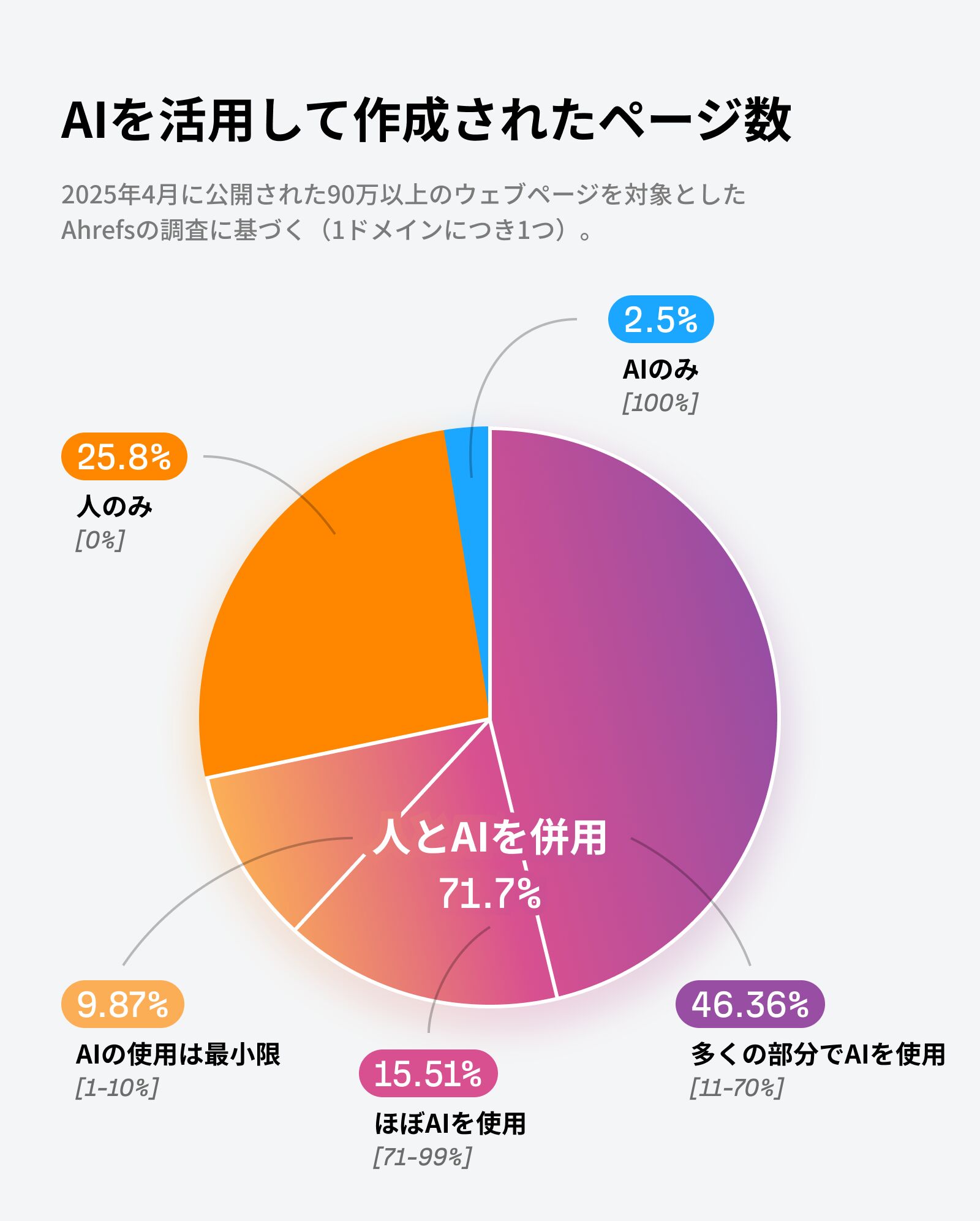
AI 生成コンテンツの台頭は紛れもない事実です。Ahrefs の AI 検出ツールは、2025 年 4 月に公開された新規ウェブページの 74% に、AI 生成のテキストが何らかの形で含まれていると推定しています。この割合は今後さらに増えていくでしょう。
筆者は以前、AI コンテンツ検出の必要性を説明する際、「核兵器使用以前に作られた鋼鉄」の例えを使ったことがあります。歴史上最初の核爆弾が使用されて以来、地球上の大気には微量の放射能が含まれるようになり、それ以降作られた鋼鉄にはすべて放射能の痕跡が残るようになりました。これと同じように、あらゆるコンテンツが何らかのかたちで AI の影響を受けている未来を想像するのは難しくありません。
筆者にとって、これこそが AI 検出ツールを使う最大の理由です。インターネット全体が LLM の出力で溢れかえっている今、私たちが日々消費するコンテンツの制作に使われるツールや技術について、できるだけ深く理解しておくべきだと考えます。
では、具体的に何を知るべきなのか?筆者が注目しているのは、次のようなポイントです。
- 高品質なコンテンツ制作に最適な AI モデルはどれか。
- 競合他社がどのくらいの頻度でAIコンテンツを公開しており、どのモデルを使用しているのか。
- Google などの他社が、公開されているAIコンテンツをどの程度の精度で検出できるのか。
- 特定のキーワードに対する検索結果(SERP)に、AI 生成コンテンツがどれほど含まれているか。また、その中で上位表示を狙う難易度はどの程度か。
- 検索トラフィック、特定のキーワードでの検索順位、被リンク数など、オーガニック検索のパフォーマンス指標が AI の利用レベルとどのように相関しているか(※この記事執筆時点で調査を進行中)。
AI コンテンツ検出の目的は、AI の利用について白黒はっきりした「倫理的な審判」を下すことではありません。「AI で生成されたから質が低い」「人間が書いたから優れている」といった単純な二元論ではないのです。というのも、AI は高品質のコンテンツ制作にも活用できるからです(最近の Ahrefs ブログを読んでいる方なら、もれなく AI 生成テキストを含むコンテンツを読んでいることになります)。
肝心なのは、有用な情報とそうでないものを選別し、ウェブサイトとビジネスの成長に役立つデータを収集することです。
まとめ
今やウェブ上に登場する新コンテンツのほとんどが生成 AI の助けを借りて制作されています。だからこそ筆者は、 AI に関する情報をできるだけ多く把握しておきたいと思っています。
Ahrefs の新しい AI 検出機能は、サイトエクスプローラーでご利用いただけます。皆さんもこのツールを活用して、生成 AI がウェブサイトの可視性におよぼす影響について把握しておきませんか?


