En hilos de LinkedIn y guías de IA para SEO, la promesa es la misma: formatea tu contenido en “fragmentos” o “chunks” perfectos y serás elegido para aparecer en las AI Overviews de Google o citado en los resultados de búsqueda de IA.
¿El problema?
La optimización de fragmentos no es realmente una táctica de SEO. Es un término técnico tomado de la ingeniería de IA, malinterpretado, mal aplicado y, en su mayor parte, fuera de tu control.
Antes de sumergirnos en el aspecto técnico, aquí tienes los descubrimientos principales:
- La optimización de fragmentos, o chunk optimization, no es un truco para posicionar. La mayoría de los SEO que usan el término simplemente se refieren a una buena estructura de contenido: párrafos cortos, secciones escaneables y subtítulos claros.
- Las herramientas de IA no ven tu contenido como tú crees. Los modelos de lenguaje grandes (LLM) no “leen” tus páginas; vectorizan tu texto token por token. Los tokens pueden ser palabras completas o partes de palabras.
- Perseguir el “chunk optimization” es un callejón sin salida. No puedes controlar cómo Google, ChatGPT o Perplexity fragmentan tu contenido. Sus procesos cambian según el coste, el modelo y el contexto.
- Enfócate en el contenido atómico. Crea secciones autocontenidas que respondan a una consulta de forma clara y que puedan sostenerse por sí mismas. Este enfoque funciona para humanos y LLM sin necesidad de trucos.
Esta guía explica cómo funciona realmente la fragmentación para la búsqueda con IA y ofrece un marco sencillo para estructurar contenido que sirva tanto a humanos como a los LLM.
Pero probablemente no necesites cambiar tu flujo de trabajo si ya estás estructurando bien tu contenido.
El chunking (fragmentación) es el proceso de dividir documentos de contenido largos en piezas más pequeñas y legibles por máquinas para que los modelos de lenguaje grandes puedan almacenarlos, recuperarlos y usarlos de manera eficiente.
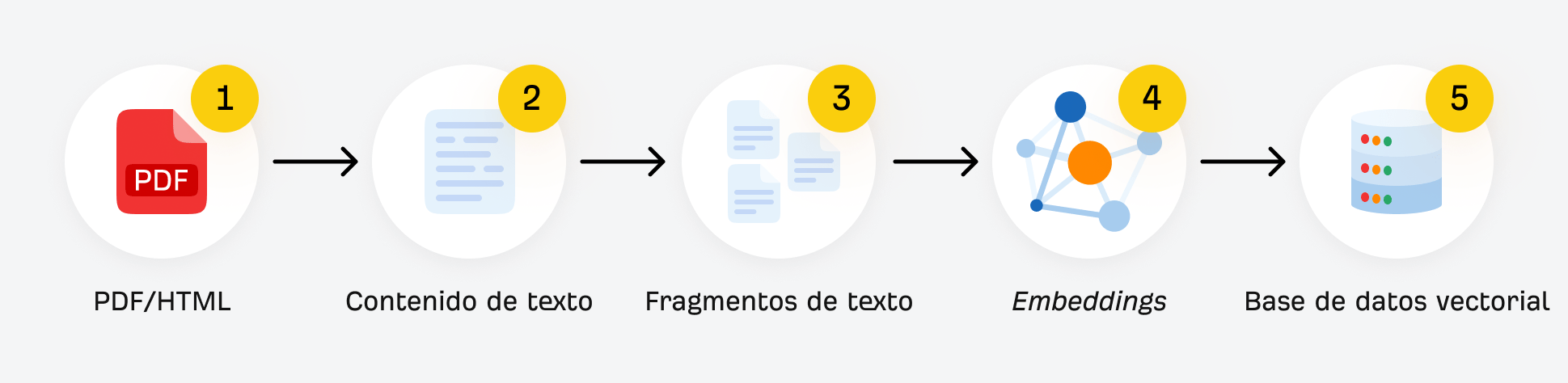
En los procesos de IA como la Generación Aumentada por Recuperación (RAG), esto se ve así:
- Dividir un documento en fragmentos (secciones de texto pequeñas y autocontenidas).
- Integrarlos como vectores (representaciones numéricas que capturan el significado para la búsqueda semántica).
- Recuperar los fragmentos más relevantes de la base de datos de vectores para responder a la consulta de un usuario.
Piensa en los fragmentos como las unidades de significado con las que trabajan los sistemas de IA.
Solo pequeñas porciones de estos fragmentos (a menudo solo una o dos frases) se muestran a los usuarios. Los ingenieros a veces los llaman “pasajes”, ya que son las porciones específicas de texto que mejor coinciden con la consulta.
Aquí está la clave para los SEO: este proceso es totalmente automático y depende del modelo. Diferentes LLM utilizan diferentes límites de tokens y estrategias de fragmentación, optimizados para la precisión, el coste y la eficiencia, no para tus encabezados o la longitud de tus párrafos. Los tokens son las unidades de significado más pequeñas, generalmente partes de palabras, utilizadas por los modelos de IA.
Que tu contenido use secciones de 50 o 150 palabras no influye en cómo Google o ChatGPT lo fragmentan internamente.
La fragmentación importa para la búsqueda con IA “bajo el capó”, pero no es una palanca que puedas optimizar directamente, y aquí te explicamos por qué.
Aunque la fragmentación de contenido es fundamental para el funcionamiento de los LLM y la búsqueda con IA, los SEO no pueden controlarla de manera significativa.
La fragmentación ocurre dentro de los procesos de los modelos, guiada por límites de tokens, estrategias de recuperación y eficiencia de costes, ninguno de los cuales responde a tus encabezados o a la longitud de tus párrafos.
1. Los ingenieros de IA controlan el proceso
La fragmentación es una decisión de ingeniería. Modelos como Gemini, GPT-4 o Claude manejan la división y el procesamiento de documentos automáticamente. Recuperan, dividen, integran y almacenan texto en fragmentos para lograr objetivos como:
- Reducir las alucinaciones
- Mejorar la calidad de las respuestas
- Asegurar la precisión de la información
- Generar respuestas bien estructuradas
El sistema, no tus elecciones de formato, decide qué cuenta como un “fragmento” y cómo se divide.
Por ejemplo, los métodos comunes de fragmentación con los que los ingenieros de IA están experimentando dependen del tamaño del modelo, el tipo de documento y los objetivos de eficiencia.
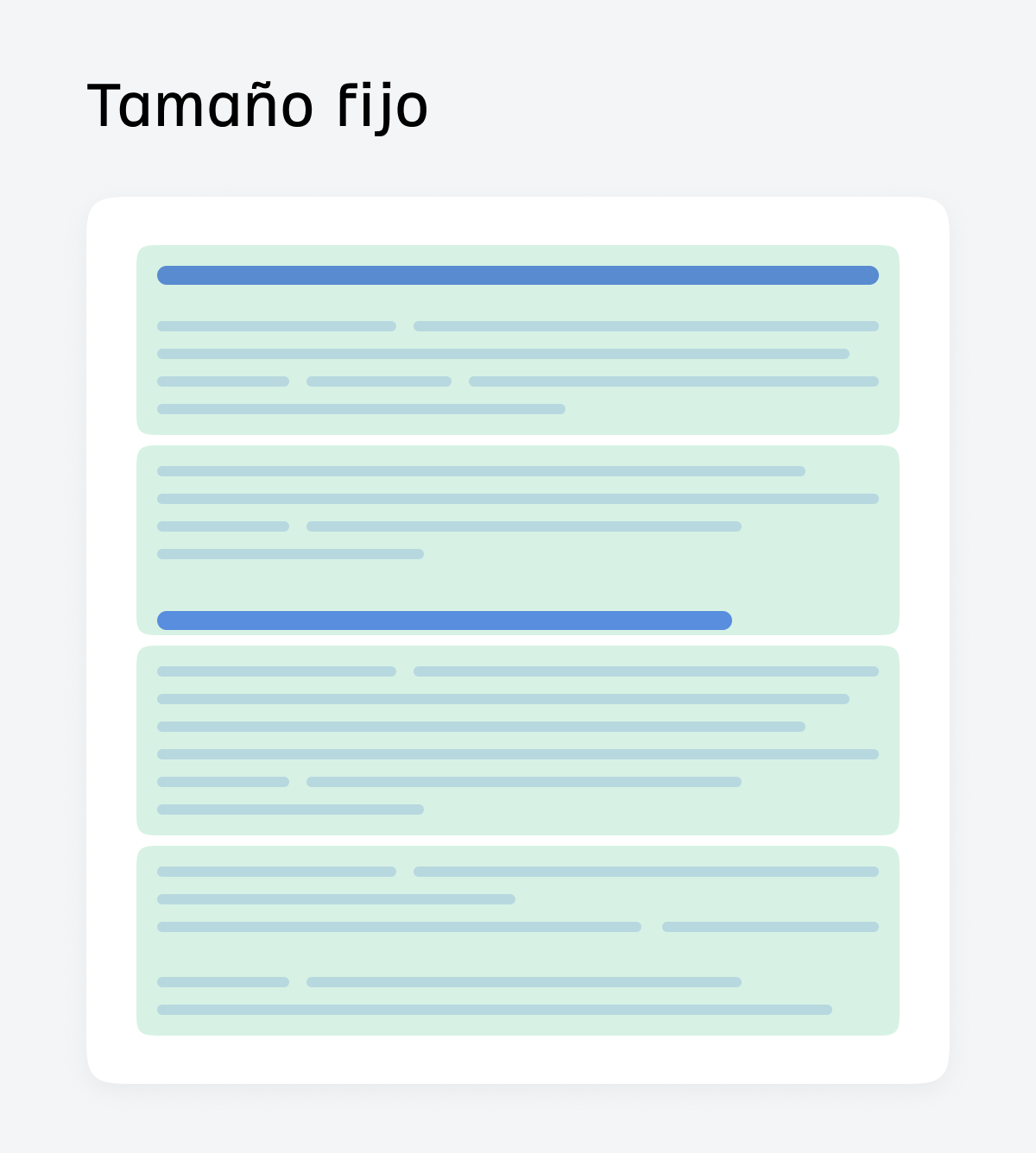
Fragmentación de tamaño fijo
La fragmentación de tamaño fijo divide el texto en bloques de tokens iguales (por ejemplo, 500 tokens) con una superposición opcional, a menudo sin tener en cuenta la estructura del artículo.
Fragmentos de ventana deslizante
El método de fragmentación de ventana deslizante (sliding window) crea fragmentos superpuestos para preservar el contexto entre segmentos.

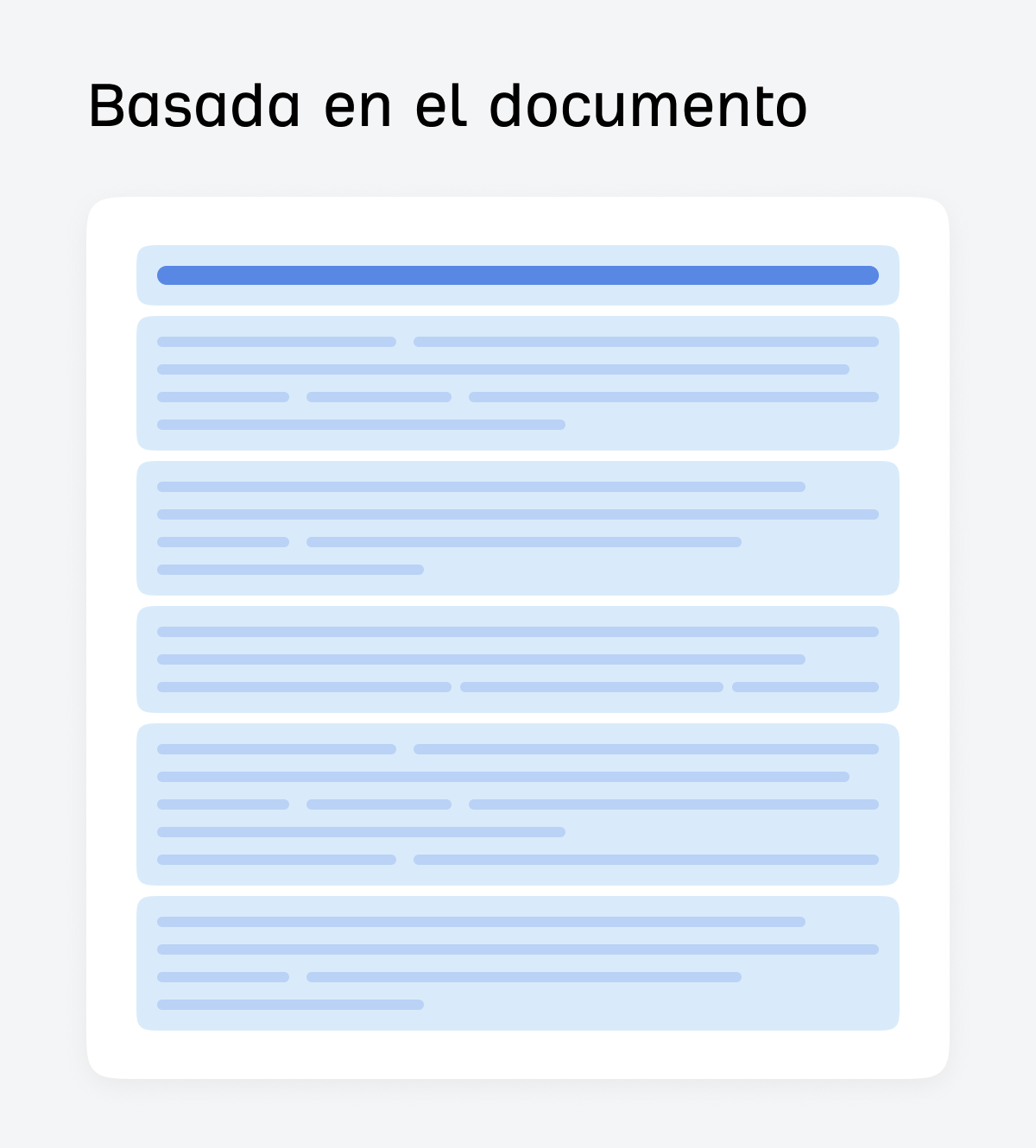
Fragmentación basada en el documento
La fragmentación basada en el documento se divide siguiendo la estructura natural del documento, como encabezados, secciones y tablas.
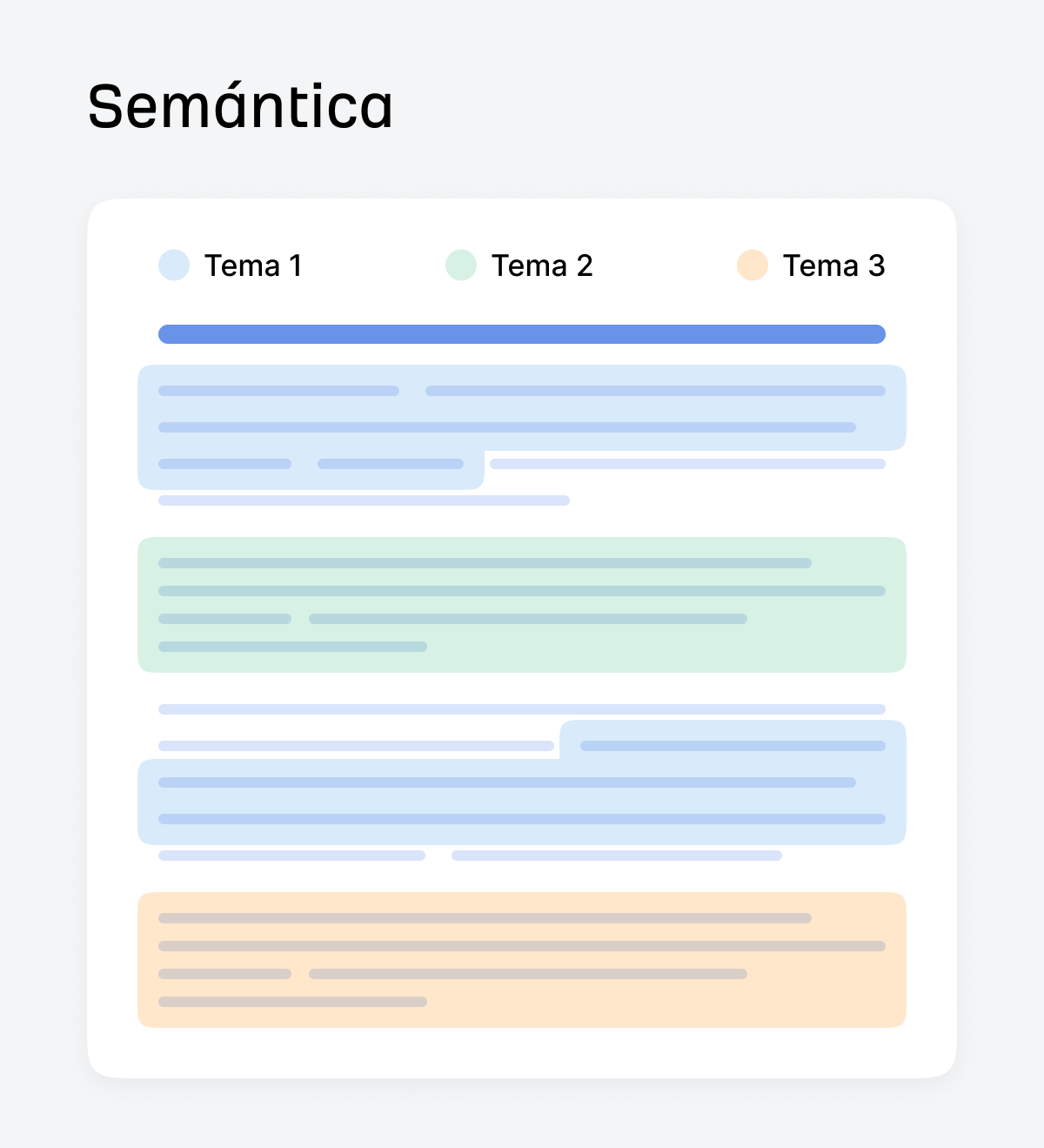
Fragmentación semántica
El método de fragmentación semántica divide el texto según los cambios de tema, utilizando incrustaciones (embeddings) para detectar los límites.
Fragmentación recursiva
La fragmentación recursiva descompone el contenido jerárquicamente (secciones → párrafos → frases → palabras) para obtener divisiones naturales más limpias.

Fragmentación consciente del HTML
Los métodos de fragmentación conscientes del HTML utilizan etiquetas como <h2> y <p> para guiar las divisiones del contenido.

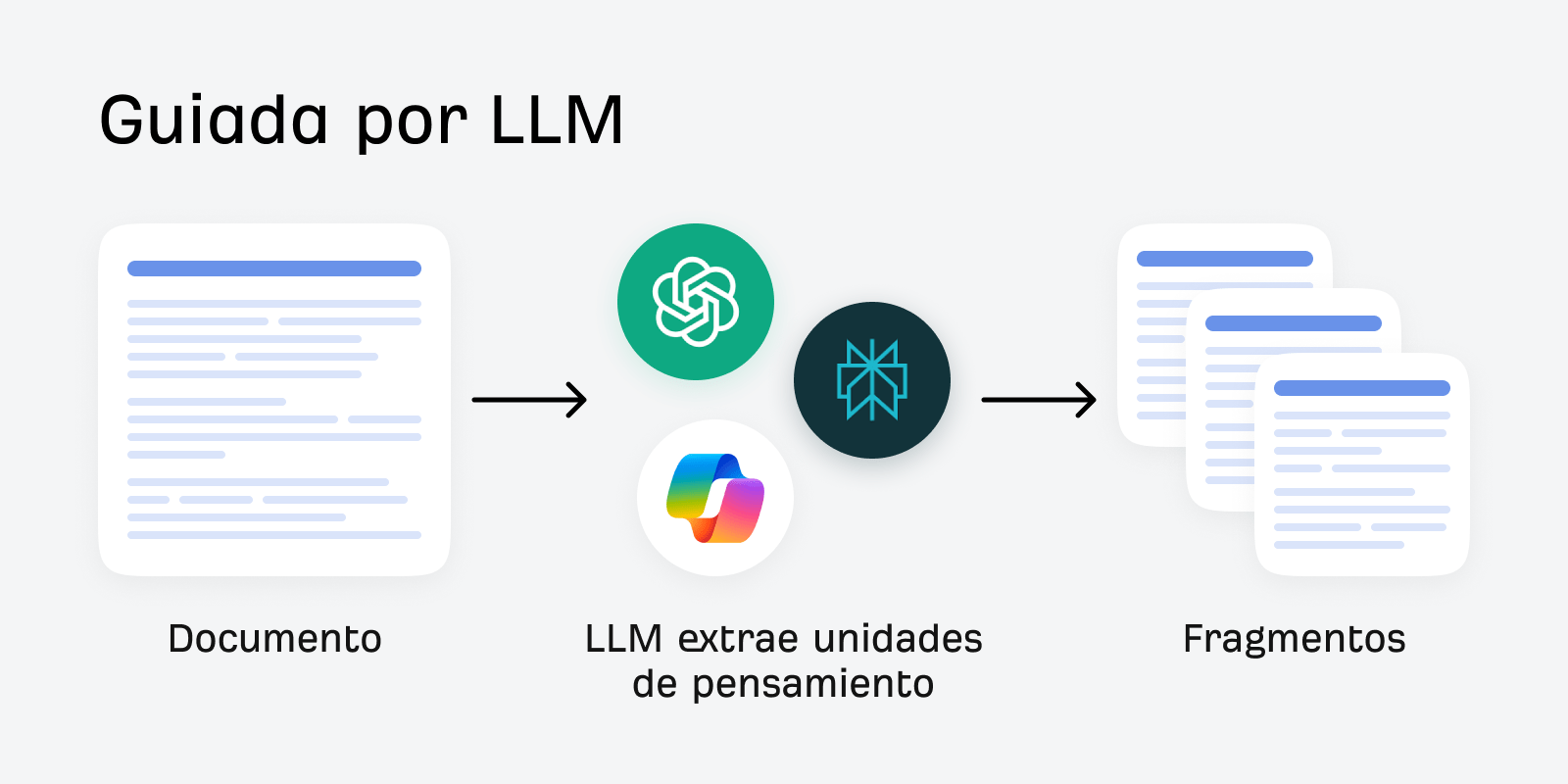
Fragmentación guiada por LLM
La fragmentación guiada por LLM utiliza un modelo de lenguaje grande para identificar “unidades de pensamiento” coherentes. Es ideal para contenido complejo y no estructurado.
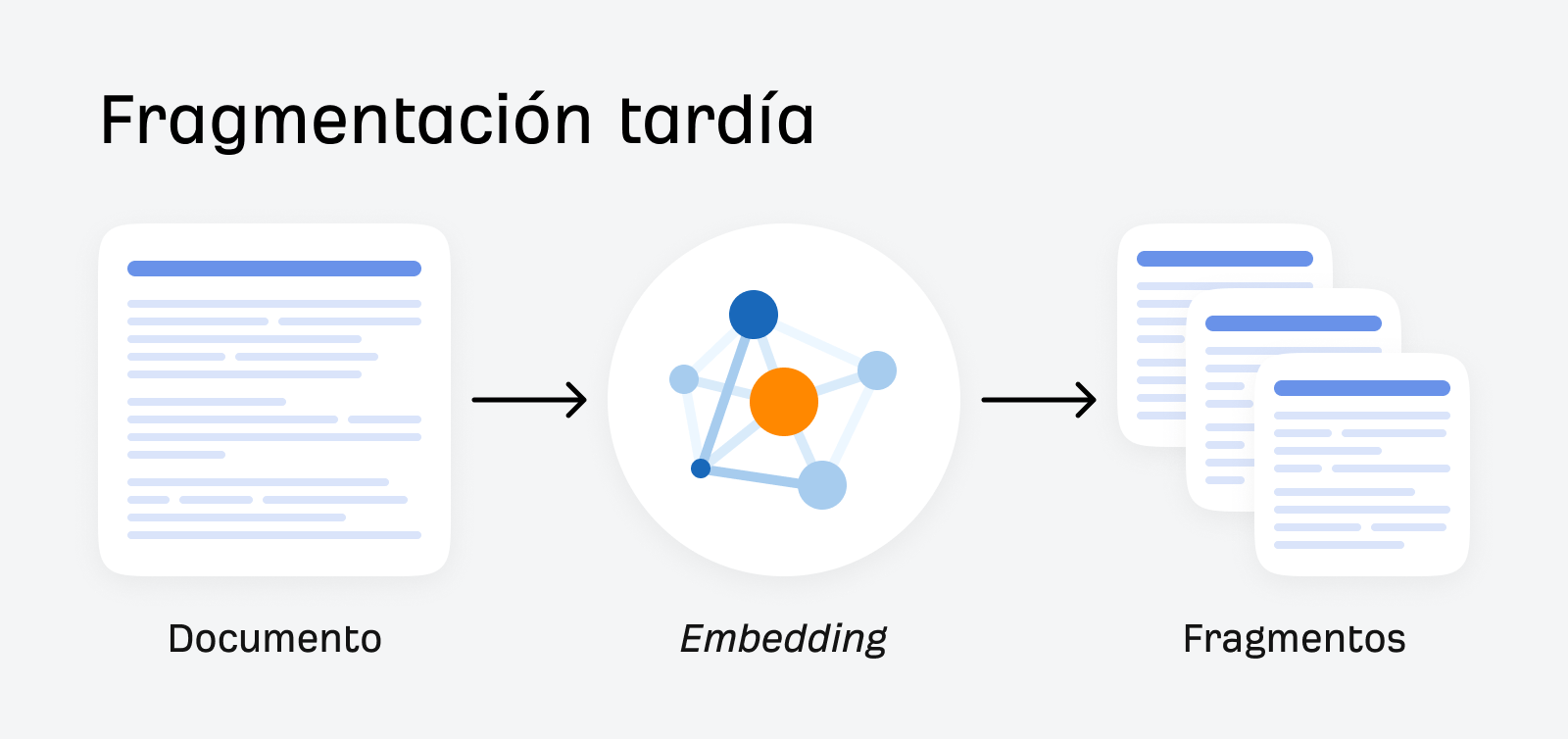
Fragmentación tardía
La fragmentación tardía es un método que primero integra todo el documento y luego lo divide en fragmentos, manteniendo intacto el contexto.
Cada método tiene sus propias ventajas y desventajas, pero ninguno se basa en los ajustes de formato superficiales que la mayoría de los SEO persiguen.
Estas estrategias optimizan la precisión y eficiencia de la recuperación, pero ocurren automáticamente y son invisibles para los profesionales SEO.
2. Cada modelo utiliza una estrategia diferente
No existe un método de fragmentación universal.
- Los modelos más pequeños (límite de 512 tokens) pueden dividir tu contenido en fragmentos de 200-300 tokens.
- Los modelos de contexto largo (más de 1.000 tokens) pueden manejar segmentos mucho más grandes.
- Algunos procesos utilizan fragmentos de tamaño fijo, otros emplean enfoques semánticos o de ventana deslizante.
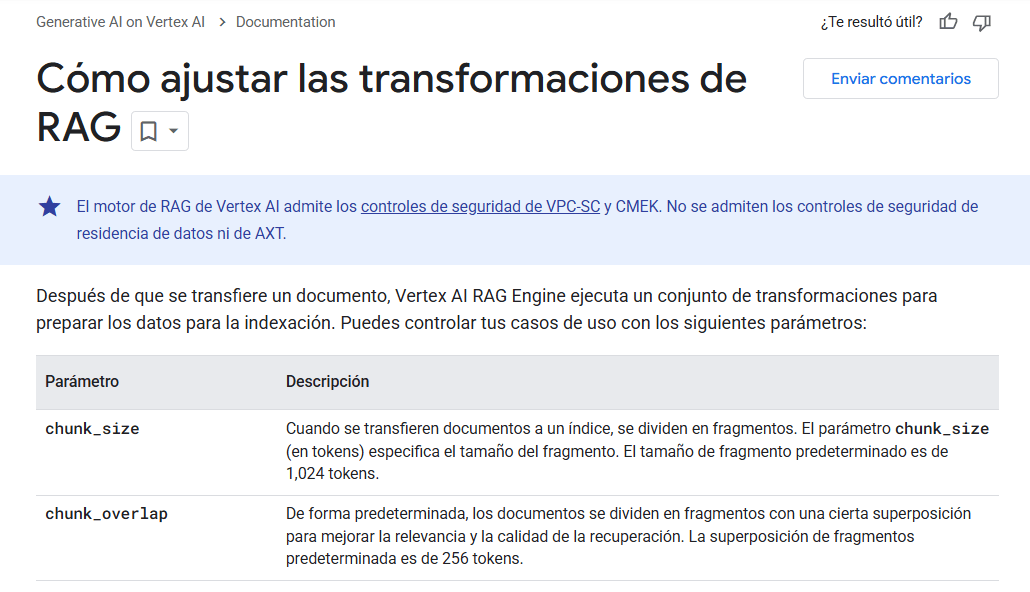
Incluso si adivinaras correctamente las preferencias de un modelo, es probable que tu contenido sea procesado de manera diferente por otro. Por ejemplo, aquí están las preferencias de Vertex AI:
Con el tiempo, cada modelo se vuelve hiperpersonalizado para sus propias necesidades de rendimiento.
Los ingenieros de IA están incentivados a encontrar incluso pequeñas ganancias de eficiencia porque cada fracción de céntimo ahorrada en computación puede escalar a millones de dólares a nivel de producción.
Prueban rutinariamente cómo diferentes tamaños de fragmentos, superposiciones y estrategias impactan la calidad de la recuperación, la latencia y el coste, y realizan cambios siempre que las matemáticas favorezcan el resultado final.
Por ejemplo, así es como se ven esos experimentos de rendimiento de RAG:
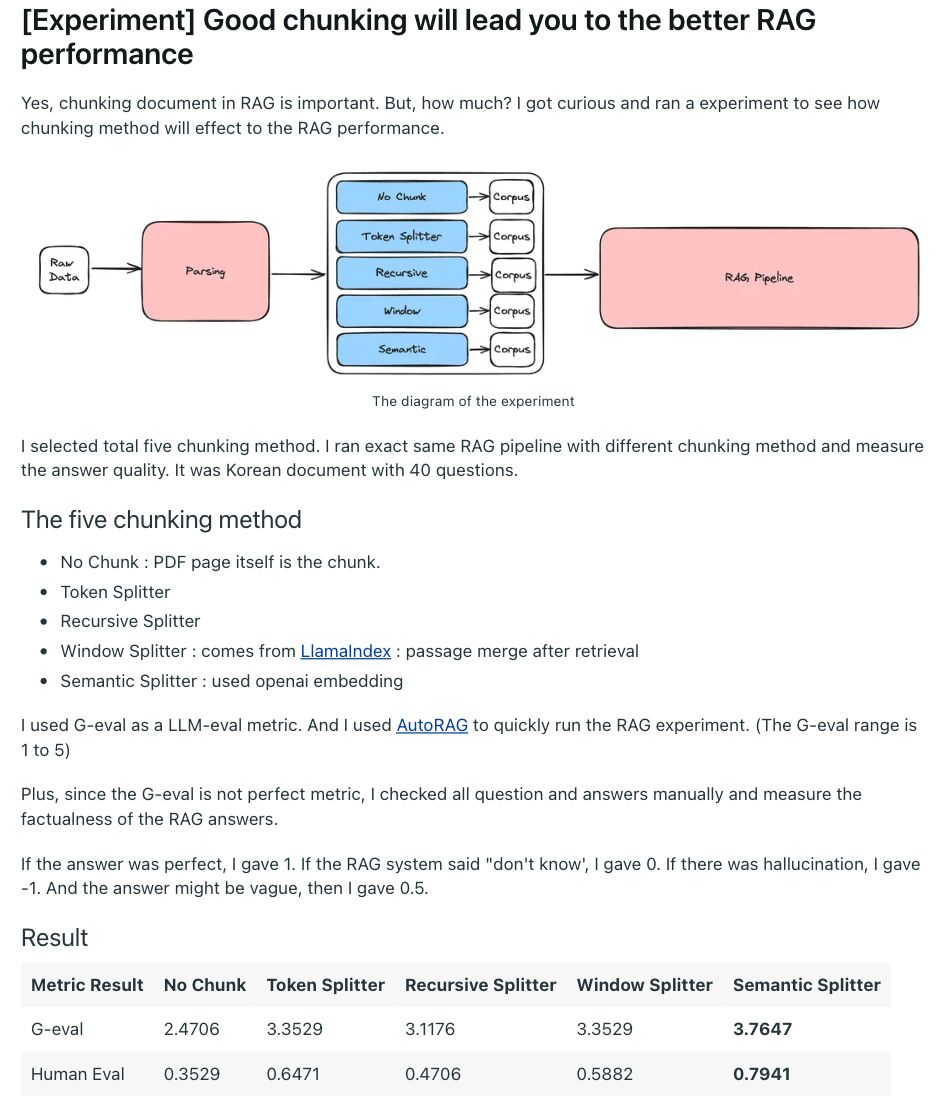
Los ingenieros han realizado docenas de experimentos similares, todos probando los mejores métodos de fragmentación para diversos tipos de documentos y preferencias de modelo.
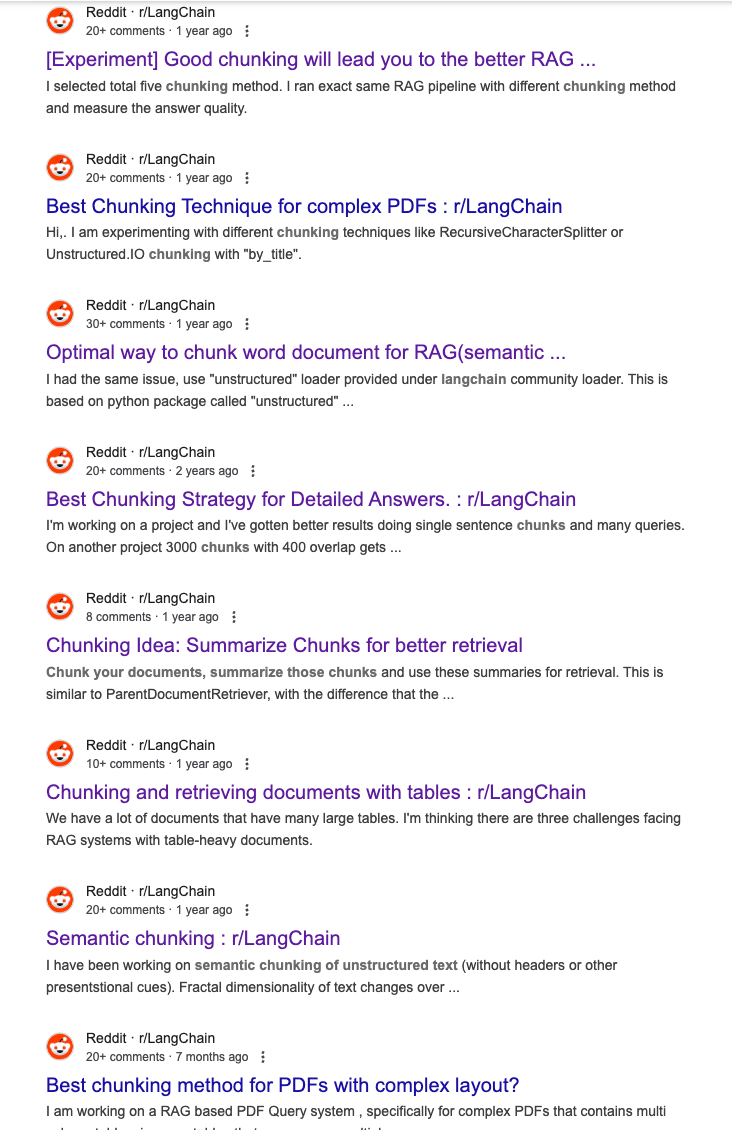
Múltiples hilos de Reddit que muestran diferentes experimentos de fragmentación realizados por ingenieros de IA.
Esto significa que cualquier “optimización” manual que hagas hoy puede volverse irrelevante con una actualización del modelo mañana.
3. La optimización manual de fragmentos es un callejón sin salida
En última instancia, la “optimización de fragmentos” manual es imposible en la práctica.
Incluso si intentas escribir fragmentos perfectos, no tienes control sobre dónde un modelo cortará tu contenido.
La fragmentación se basa en tokens, no en párrafos u oraciones, y cada modelo decide sus propios puntos de división dinámicamente. Eso significa que la frase introductoria que escribiste cuidadosamente para un fragmento podría:
- Aterrizar en medio de un fragmento en lugar de al principio.
- Ser dividida por la mitad en dos fragmentos.
- Ser ignorada por completo si la recuperación del modelo la omite.
Además, Google ya ha demostrado lo que sucede con los sitios que fuerzan el formato para manipular la visibilidad. Por ejemplo, las granjas de contenido estilo FAQ inundaron una vez los resultados de búsqueda con respuestas pulcramente empaquetadas para ganar fragmentos destacados y visibilidad.
Tras las actualizaciones recientes, Google degradó o penalizó estos sitios al reconocer el patrón como contenido basura manipulador y generado por IA, que ofrecía poco valor a los lectores.
Intentar pre-estructurar el contenido para una hipotética fragmentación de IA es la misma trampa.
No puedes predecir cómo los LLM tokenizarán tu página hoy, y cualquier intento de forzarlo podría ser contraproducente o volverse obsoleto después de la próxima actualización del modelo.
Optimizar para la búsqueda con IA no requiere perseguir la “optimización de fragmentos”. En cambio, el objetivo es crear contenido atómico: secciones autocontenidas dentro de documentos más grandes que actúan como unidades indivisibles de conocimiento.

¿Te suena familiar? Es como se ha escrito el contenido SEO bien optimizado durante muchos años.
Cada unidad atómica debe poder sostenerse por sí misma, ofreciendo una respuesta completa incluso si es extraída y mostrada por Google, ChatGPT, Perplexity u otras plataformas de búsqueda con IA.
Diseñar tu contenido de esta manera lo hace tanto preparado para la IA como amigable para el usuario, sin recurrir a trucos.
Aquí tienes un flujo de trabajo sencillo que puedes implementar.
Paso 1: Comienza con la investigación de palabras clave y temas
Saber cómo estructurar una página para la visibilidad en la búsqueda comienza con la investigación de palabras clave y temas.
Usando Keywords Explorer de Ahrefs, puedes descubrir qué preguntas o temas merecen sus propias secciones dentro de la página que estás escribiendo.
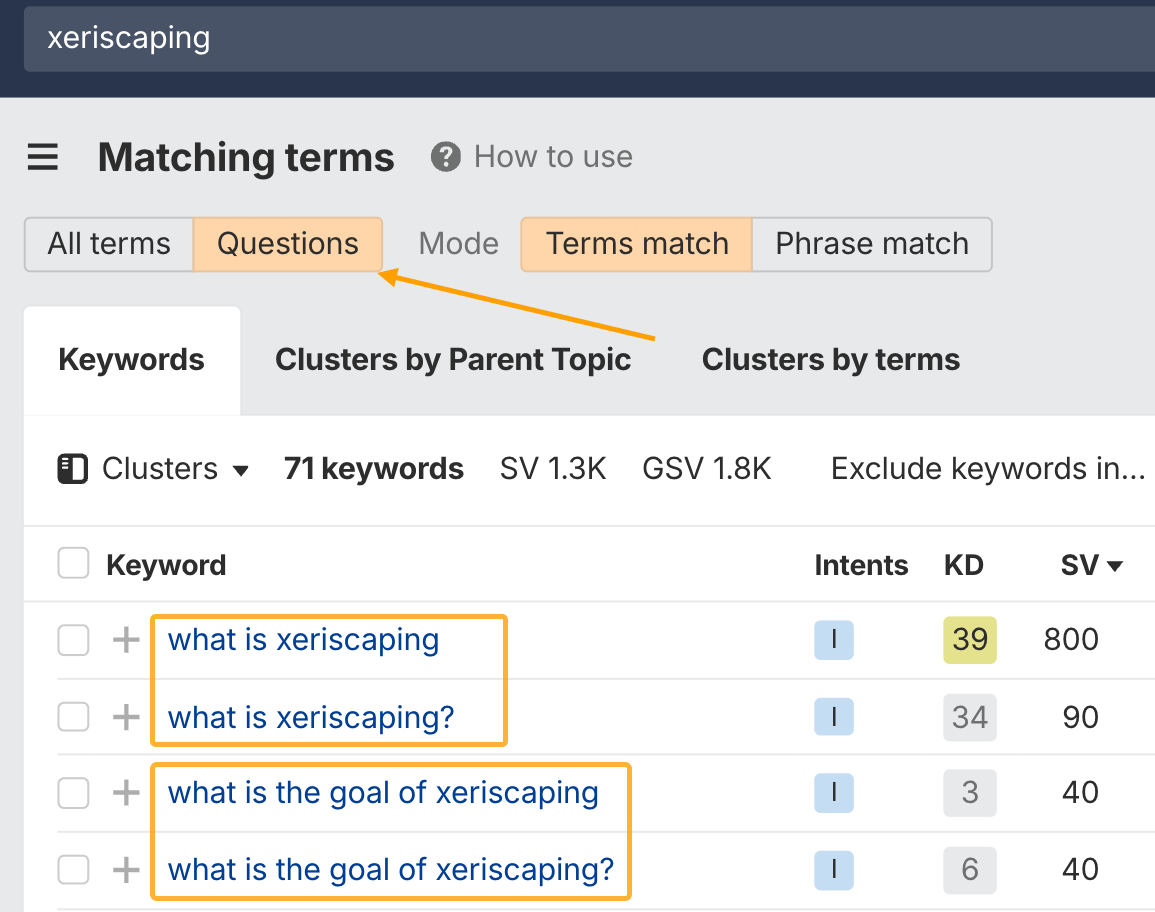
Por ejemplo, sobre el tema de la xerojardinería (un tipo de jardinería), puedes responder preguntas como:
- ¿Qué es la xerojardinería?
- ¿Cuál es el objetivo de la xerojardinería?
- ¿Cuánto cuesta la xerojardinería?
- ¿Qué plantas son buenas para la xerojardinería?
Cada tema o grupo representa un átomo de contenido potencial para agregar a tu sitio web. Sin embargo, no todo átomo necesita su propia página para ser respondido bien.
Algunas preguntas y temas tienen más sentido responderlos en un artículo existente.
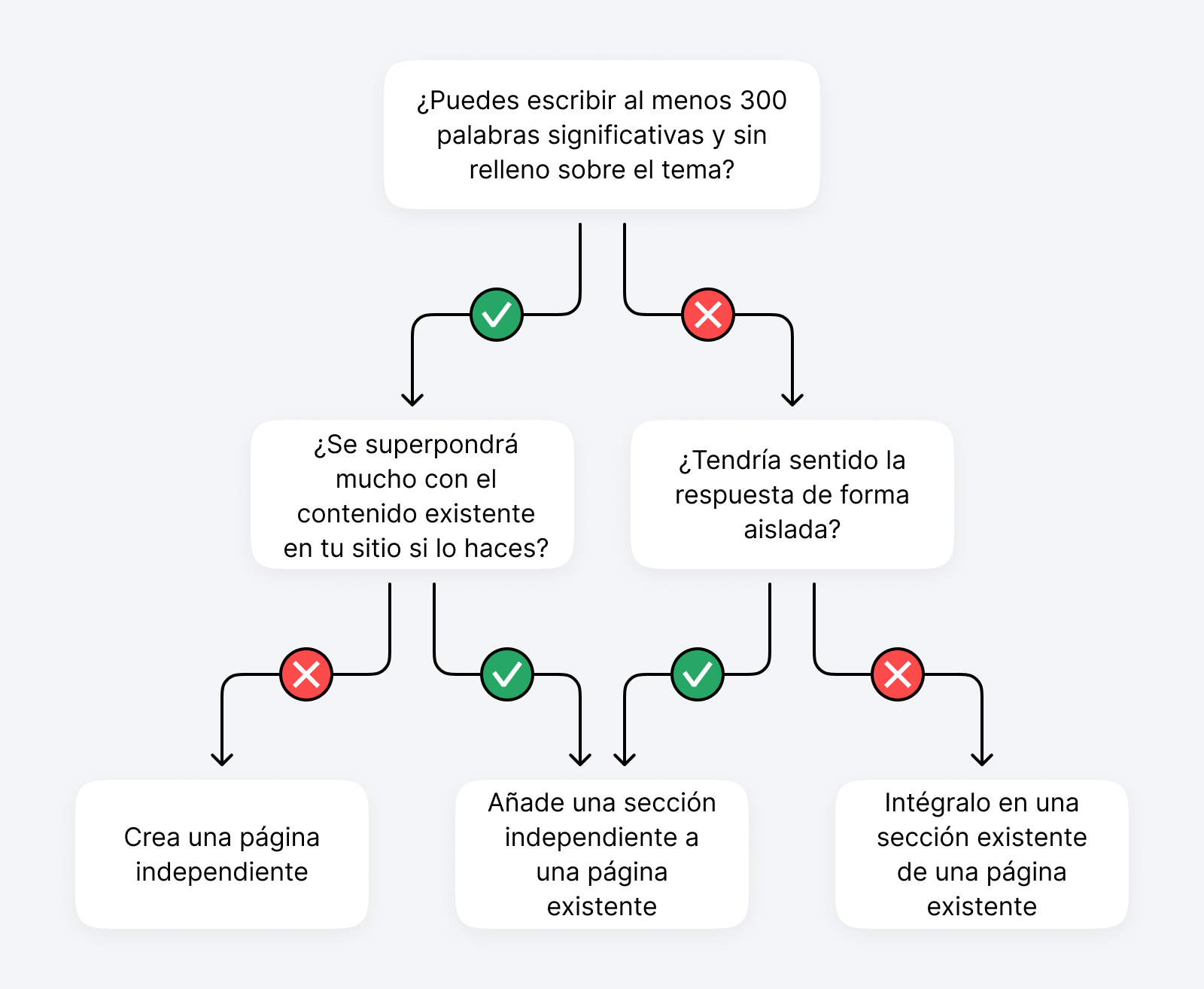
La decisión de si abordar las palabras clave como una página o una sección dentro de una página depende del tema central de tu sitio web. Por ejemplo, si tienes un sitio especializado en xerojardinería, podría tener sentido abordar cada pregunta en una publicación separada donde puedas profundizar en los detalles.
Si tienes un sitio de jardinería general, quizás podrías agregar cada pregunta como una sección de preguntas frecuentes a una publicación existente sobre xerojardinería.
Este paso asegura que cada pieza de contenido que crees comience alineada con la intención de búsqueda y esté estructurada para funcionar como una unidad independiente siempre que sea posible.
Paso 2: Aplica el método BLUF (Bottom Line Up Front)
“Bottom Line Up Front” (lo más importante, al principio) es un marco para comunicar la información más importante primero, y luego proceder con una explicación, un ejemplo o detalles de apoyo.
Para implementarlo en tu escritura, comienza cada artículo (y también cada sección dentro de un artículo) con una respuesta directa o una declaración clara que aborde completamente el tema central.
BLUF funciona porque los humanos escanean primero y leen después.
Décadas de investigación del Nielsen Norman Group muestran que los lectores siguen un patrón en F al leer en línea: un fuerte enfoque en el comienzo de las secciones, una caída brusca en el medio y algo de atención renovada al final.

Los modelos de lenguaje grandes procesan el texto de una manera sorprendentemente similar.
Priorizan el comienzo de un documento o fragmento y muestran un sesgo de atención en forma de U al:
- Ponderar más los primeros tokens.
- Perder el foco en el medio.
- Recuperar algo de énfasis hacia el final de una secuencia.
Para más información sobre cómo funciona esto, recomiendo el artículo detallado de Dan Petrovic: El contenido amigable para los humanos es contenido amigable para la IA.
Al poner la respuesta primero, tu contenido es instantáneamente comprensible, recuperable y listo para ser citado, ya sea por un humano que escanea o por un modelo de IA que integra tu página.
Paso 3: Audita la autosuficiencia del contenido
Antes de publicar, vale la pena escanear tu página y preguntar:
- ¿La información relacionada está agrupada lógicamente en la estructura de tu contenido?
- ¿Cada sección es clara y fácil de seguir sin explicaciones adicionales?
- ¿Un humano que llega a esta sección desde un enlace de salto obtendría valor inmediatamente?
- ¿La sección responde completamente a la intención de su palabra clave o grupo temático sin depender del resto de la página?
Para hacer esta auditoría más rápida y objetiva, herramientas como AI Content Helper de Ahrefs pueden ayudar a visualizar la cobertura de tus temas.
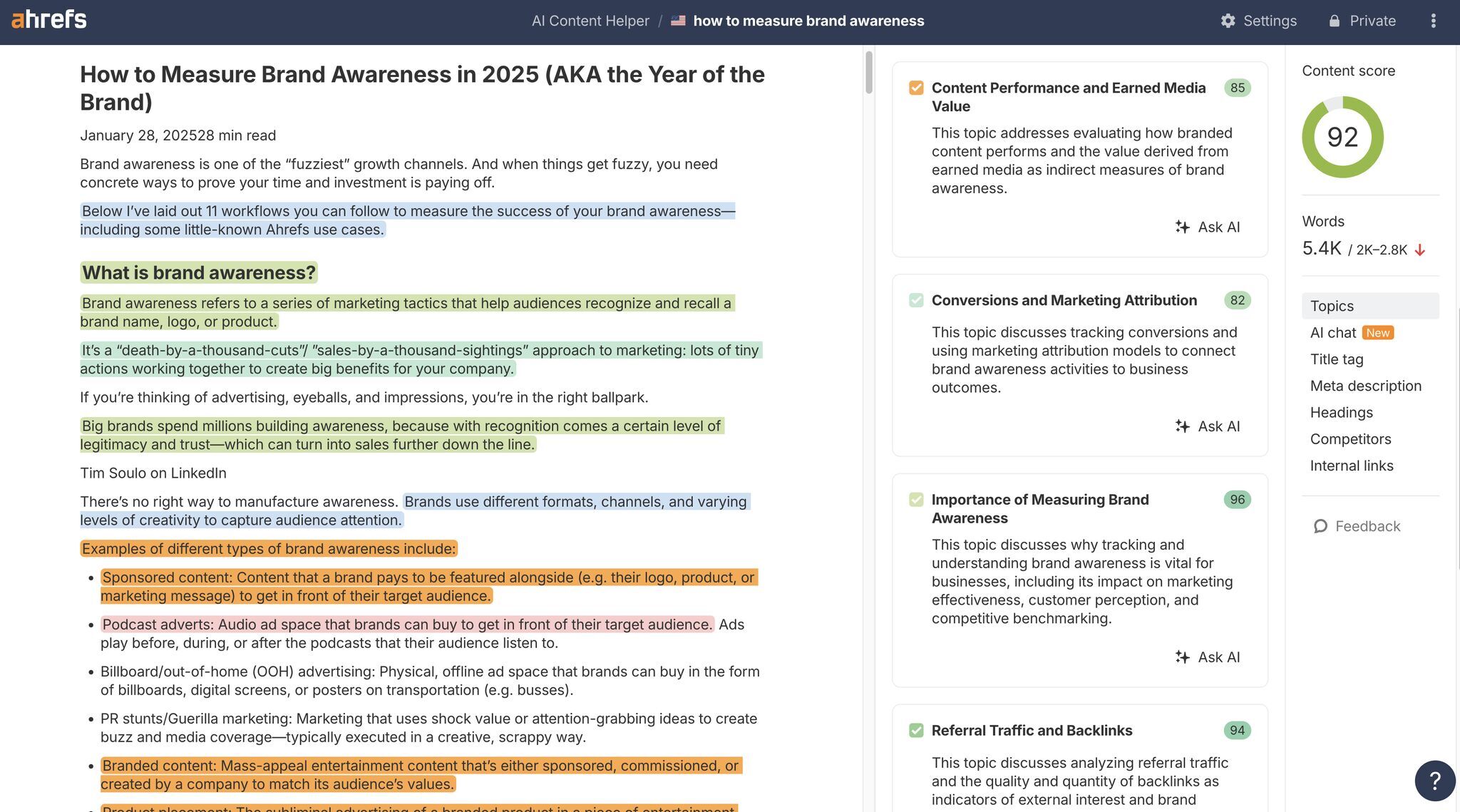
Su función de coloreado de temas resalta distintos temas en tu página, facilitando la detección de:
- Secciones superpuestas o fragmentadas que deberían fusionarse.
- Secciones que no cubren un tema por completo.
- Áreas que pueden requerir un nuevo etiquetado o un contexto más sólido.
Si cada sección es autocontenida y los colores de tus temas muestran bloques claros y cohesivos, has creado contenido atómico que está naturalmente optimizado para la atención humana y la recuperación de IA.
Perseguir la “optimización de fragmentos” es una distracción.
Los sistemas de IA siempre dividirán, integrarán y recuperarán tu contenido de maneras que no puedes predecir ni controlar, y esos métodos evolucionarán a medida que los ingenieros optimicen la velocidad y el coste.
El enfoque ganador no es intentar manipular el proceso. Es crear secciones claras y autocontenidas que ofrezcan respuestas completas, para que tu contenido sea valioso tanto si es leído de principio a fin por un humano como si es extraído en un resumen aislado de IA.
¿Tienes preguntas? Estamos en X y en LinkedIn.


